0. 문제 상황
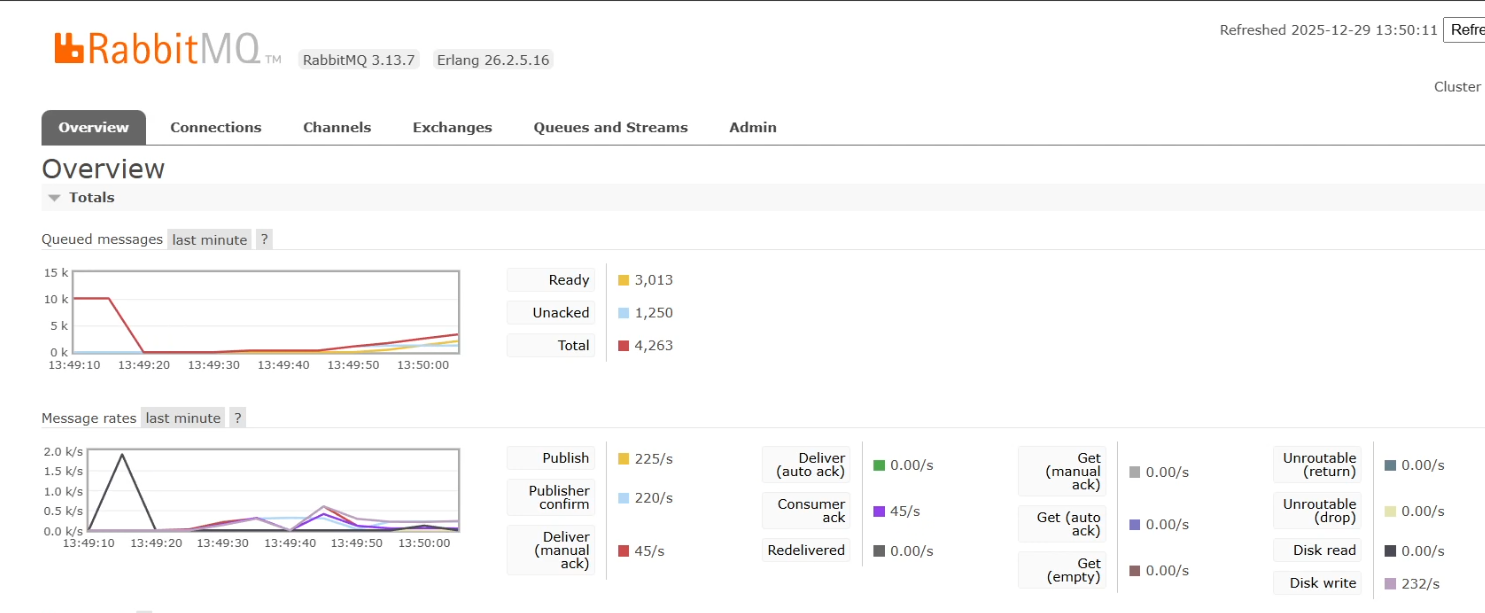
컨슈머 처리량이 20~40 msg/s 정도로 매우 느렸습니다.
publish는 300~400 msg/s 까지 발행되었는데, 컨슈머가 따라가지 못해서 snapshot의 반영이 지연되었습니다.
1. 조건
DB: MySQL (동일 인스턴스)
테이블: 변경 없음(최적화 실험 전/후 동일)
메시지: 동일 DTO(SnapshotMsg)
테스트: Locust로 동일 패턴/부하로 발행
측정: RabbitMQ 관리 페이지 deliver/ack rate 기준 msg/s 측정
실험 모두 동일합니다.
2. consumer늘리기 (20~40 => 100초반)
처음에는 코드를 보기전에 단순 consumer를 늘리면 해결될 것이라고 생각했습니다.
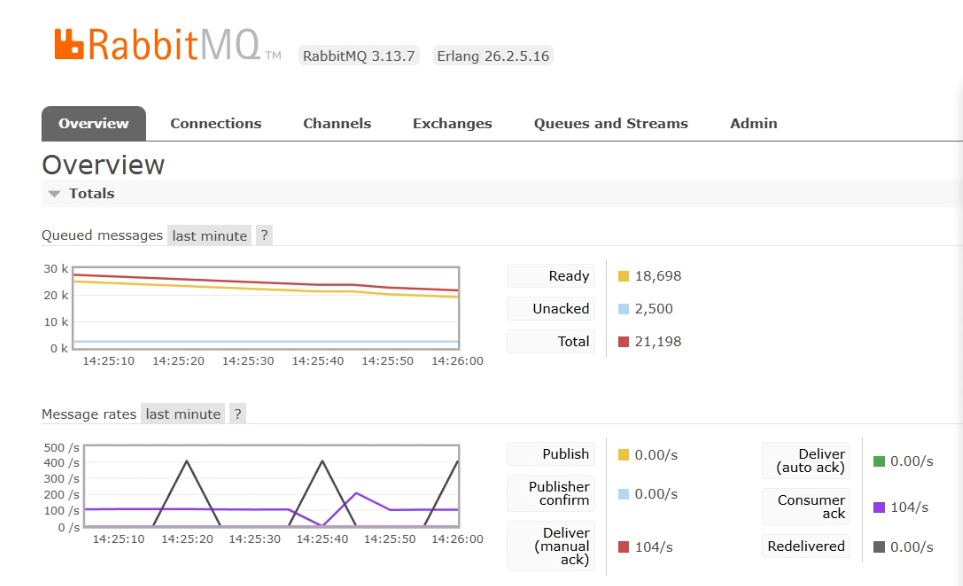
2.1 변경내용
RabbitListener concurrency를 늘렸습니다.
@RabbitListener(queues = RabbitConfig.Q, concurrency = "#")2.2 결과
concurrency 증가 전 : 약 20 msg/s
concurrency 증가 후 : 약 60~100 msg/s
처리량은 올라갔지만 여전히 너무 느렸습니다. 그리고 1개에서 10개로 늘렸지만 200이 아닌 100이 된 이유는 로컬머신의 한계라고 생각했습니다. 테스트를 할때 CPU는 100% 이용을 하고 있었고 한계치라고 생각했습니다.
그래서 결국 메시지를 처리하는 consumer 시간 자체를 줄여야한다고 생각했습니다.
실제로 메시지 한건의 처리 속도는 약 100~200 ms로 매우 느렸습니다.
3. 느린 이유에 대한 생각
당시 로직은 아래와 같습니다.
@Transactional
public void processOneMessage(SnapshotMsg msg) {
validate(msg);
ledgerRepository.existsByTxIdAndSideAndStatus // ledger상태 조회
snapshotAppliedRepository.save(SnapshotApplied.of(msg.accountId(), msg.txId())); // 멱등 처리
availableBalanceRepo.credit(msg.accountId(), msg.amount()); // 잔액 업데이트
snapshotRepository.applyDelta(msg.accountId(), msg.amount()); // 스냅샷 업데이트
ledgerRepository.markCommitted(msg.txId(), msg.accountId(), msg.entrySide()); // ledger 상태 업데이트
outboxRepository.markSent(msg.outboxId()); // outbox 상태 업데이트
}메시지 1건당 DB왕복이 너무 많았고 생각해본건 아래 3가지였습니다.
- DB왕복이 너무 많다
- balance 업데이트가 쿼리가 2개라 오래걸릴 것이다.
- existsBy 조회가 비쌀것 같다
4. outbox 업데이트를 조건부로 변경
먼저 쿼리문들을 한번 봤습니다. 이 쿼리는 이미 SENT인 row에도 매번 UPDATE를 시도합니다. 메시지가 중복되거나 재시도되면 이 UPDATE가 계속 찍힙니다.
UPDATE outbox
SET status = 'SENT'
WHERE outbox_id = ?;4.1 변경내용
아래와 같이 이미 SENT라면 굳이 다시 쓰지 않도록 수정했습니다. 작지만 얼마나 개선되는가를 확인해 보고싶었습니다.
UPDATE outbox
SET status = 'SENT'
WHERE outbox_id = ?
AND status <> 'SENT';4.2 결과
큰 차이가 없었습니다.
5. 쿼리 합치기
이번에는 쿼리의 개수를 줄여보고자 해보았습니다. 원래는 가용잔액 테이블에 + 연산을 해주고 스냅샷 테이블에서 + 연산을 해줍니다. 여기서 account_id가 같으니까 두개를 합쳐보자는 생각을 해보았습니다.
5.1 변경내용
아래와 같이 JOIN을 하여 묶어서 처리를 하도록 했습니다.
UPDATE available_balance ab
JOIN snapshot_balance sb
ON sb.account_id = ab.account_id
SET ab.balance = ab.balance + :amt,
ab.ver = ab.ver + 1,
sb.balance = sb.balance + :amt,
sb.update_time = NOW()
WHERE ab.account_id = :accountId5.2 결과
이것 또한 차이가 없었습니다. 쿼리 수는 줄었지만, 전체 병목이 잔액+스냅샷 업데이트보다 ledger existsBy/트랜잭션 비용 쪽에 있었던 것으로 보였습니다.
6. existsBy 제거
처음 로직에는 이런 쿼리가 있었습니다.
ledgerRepository.existsByTxIdAndSideAndStatus(...)이 쿼리는 이미 COMMITTED이면 처리하지 않기위한 의도로 넣었습니다.
6.1 변경내용
markCommittedIfPending으로 한번에 처리하고 변수(int updated)로 빼서 분기를 하였습니다. 이렇게 하면 existsBy(SELECT)가 없어지고, UPDATE한번으로 할 수 있습니다.
@Modifying
@Query("""
update Ledger l
set l.status = com.maeng.toss.ledger.domain.Status.COMMITTED
where l.txId = :txId
and l.accountId.accountId = :accountId
and l.side = :side
and l.status = com.maeng.toss.ledger.domain.Status.PENDING
""")
int markCommittedIfPending(String txId, Long accountId, EntrySide side);int updated = ledgerRepository.markCommittedIfPending(msg.txId(), msg.accountId(), msg.entrySide());
if (updated == 0) { // 변경된 것이 없다 => 이미 다른 컨슈머가 처리했거나 중복 메시지이므로 스킵
return;
}6.2 결과
existsBy(SELECT)를 제거하고 조건부 UPDATE로 통합한 뒤, 메시지 처리 시간이 눈에 띄게 줄었습니다.
메시지 한건의 처리 속도가 6~20 ms 수준으로 빨라지며, ACK rate기준 약 2000 msg/s를 찍기도 하였습니다.
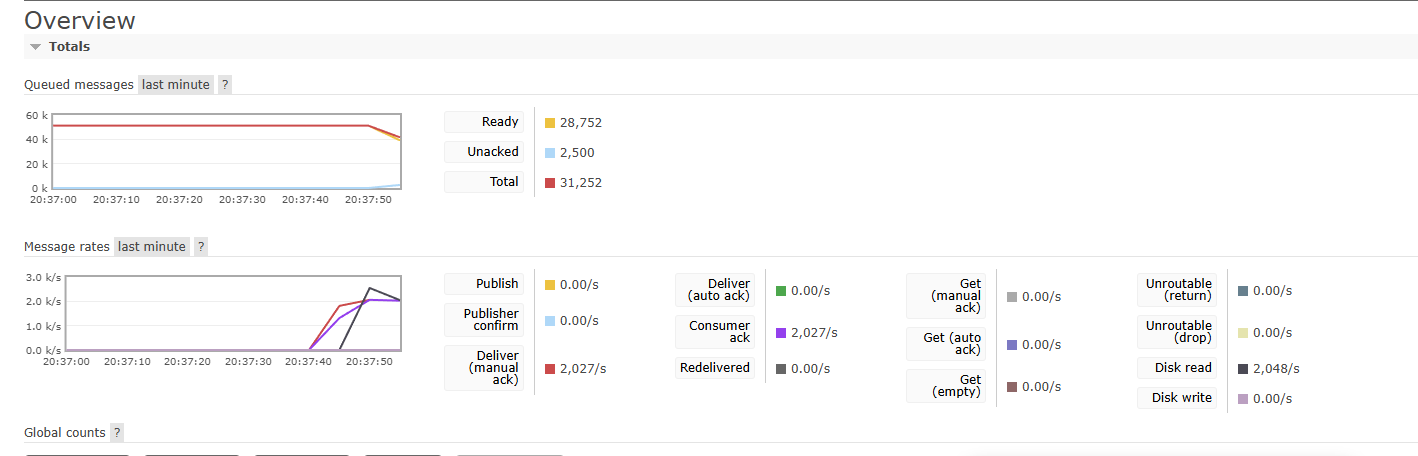
6.3 왜 차이가 컸을까
제가 생각한 existsBy가 느린 이유는 이렇습니다.
-
일단 메시지 1건에서 SELECT가 한번 늘어나는 구조입니다. 처리량이 많아질 수록 그게 손해라고 생각했습니다. 즉 메시지 한건당 DB왕복이 SELECT + UPDATE에서 UPDATE 하나로 줄었습니다.
-
Time-of-check to time-of-use 가 발생할 수도 있다고 생각했습니다. 이건 검사 시점과 사용 시점 사이에 발생하는 레이스 컨디션입니다. existsBy로 확인 후 UPDATE는 분리되어 레이스가 일어날 수 있습니다.
-
existsBy는 결국 내부적으로 limit 1 형태의 조회 SQL이 실행됩니다.
실제로 아래 SQL 로그에서 LIMIT 1 조회로 나가는 것을 확인할 수 있습니다.
DB작업이 이미 많이 있는 상황에서 읽기 하나 추가가 느리게 만든다고 생각했습니다.
DEBUG org.hibernate.SQL -
select
l1_0.ledger_id
from
ledger_entry l1_0
where
l1_0.tx_id=?
and l1_0.side=?
and l1_0.status=?
limit
?
...
binding parameter (3:ENUM) <- [COMMITTED]
binding parameter (4:INTEGER) <- [1]7. 정리
최종 변경 코드
@Transactional
public void processOneMessage(SnapshotMsg msg) {
snapshotAppliedRepository.insertIgnore(msg.accountId(), msg.txId());
outboxRepository.markSentIfNotSent(msg.outboxId());
balanceRepository.applyDeltaBoth(msg.accountId(), msg.amount());
ledgerRepository.markCommitted(msg.txId(), msg.accountId(), msg.entrySide());
}existsBy는 읽기-판단이라서 DB왕복도 늘리고 동시성도 완벽하지 않다고 생각했습니다.
같은 조건의 작업이면 조건부 UPDATE로 합치는게 더 빠르고 안전할 것 같습니다.
