Introduction
기존 연구
- 텍스트 기반 비지도학습
- 그러나 캡션은 이미지의 풍부한 정보에 근사할 뿐
- 세그멘테이션 같은 픽셀 레벨의 태스크를 수행할 수 없었음
- 이미지-언어 모델 내부의 시맨틱 연결이 잘 안 될 경우 텍스트 정보에 대응하는 이미지를 잘 못 찾을 수 있음
- 자기 지도 학습
- 엄선되지 않은 방대한 데이터셋 학습시 모델의 피처 추출 능력이 많이 떨어짐
- 엄선된 데이터셋이 부족함
저자들의 제안
- Data Processing
- 엄선된 데이터셋 LVD-142M을 소개
- 데이터 엄선 과정을 하나의 파이프라인으로 자동화
- 매뉴얼 어노테이션이 전혀 필요 없음
- Discriminative Self-supervised Pre-training
- 기존에 있는 방법들을 간단히 조합하여 모델의 훈련 안정성과 효율을 높임
- Model Distillation
- 거대한 트랜스포머 모델을 훈련시킨 후, 지식 증류를 통해 작은 모델로 전이
Method
Data Processing
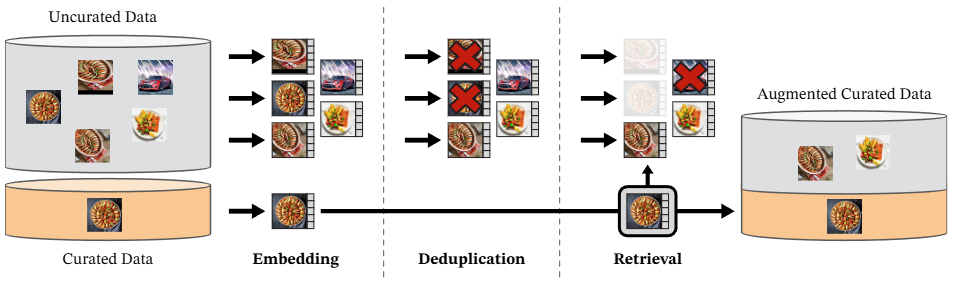
-
Uncurated Data (정제되지 않은 데이터):
- 이것은 웹에서 수집된 방대하고 필터링되지 않은 이미지 데이터셋을 의미합니다. 품질이 낮거나 중복되거나 관련 없는 이미지가 포함되어있습니다. 본 논문에서는 12억 개의 고유한 이미지로 구성된 원본 데이터를 사용했다고 언급합니다.
-
Curated Data (정제된 데이터):
- 이는 ImageNet-22k, ImageNet-1k 학습 데이터셋, Google Landmarks와 같은 기존의 잘 선별된 고품질 이미지 데이터셋을 의미합니다. 이 데이터는 새로운 고품질 데이터셋을 구축하기 위한 기준점 역할을 합니다.
-
Embedding (임베딩):
- 이 단계에서는 "Uncurated Data"와 "Curated Data"에 있는 모든 이미지를 임베딩(embedding)으로 변환합니다.
- 본 논문에서는 미리 학습된 ViT-H/16 네트워크를 사용하여 이미지 임베딩을 계산하고 코사인 유사도(cosine similarity)를 거리 측정 지표로 사용한다고 명시합니다.
-
Deduplication (중복 제거):
- 임베딩된 "Uncurated Data"에서 거의 똑같은 이미지를 제거하는 단계입니다. 이는 데이터셋의 다양성을 높이고 학습 과정에서 모델이 특정 이미지에 과적합(overfitting)되는 것을 방지합니다.
- 본 논문에서는
Pizzi et al. (2022)의 복사본 감지 파이프라인을 사용하여 중복을 제거하며, 평가 데이터셋의 이미지와 유사한 이미지도 제거한다고 설명합니다. 이미지와 이미지 사이의 유사성이 0.6 이상인 경우 중복으로 간주하여 제거합니다.
-
Retrieval (검색/추출):
- 쿼리 기반 검색
- 이 단계에서는 중복 제거된 "Uncurated Data"에서 "Curated Data"의 이미지와 시각적으로 유사한 이미지를 검색하여 새로운 학습 데이터셋을 만듭니다. 이는 자가 지도(self-supervised) 검색 시스템을 통해 이루어지며, 수동으로 레이블을 지정할 필요 없이 데이터를 확장할 수 있습니다.
- "Curated Data"의 이미지를 쿼리(query)로 사용하여 "Uncurated Data"에서 이 쿼리 이미지와 가장 유사한 N개(nearest neighbors)의 이미지를 검색하여 가져옵니다. 이미지 유사도는 코사인 유사도를 통해 측정됩니다. (일반적으로 N은 4로 설정되지만, LVD-142M 데이터셋의 핵심 부분을 구성하기 위해서는 N을 32로 설정하기도 합니다.)
- 클러스터링 기법 사용
- 정제되지 않은 전체 데이터셋을 100,000개의 별도 클러스터로 k-means 클러스터링합니다. 각 클러스터는 시각적으로 유사한 이미지들을 그룹화하여, 서로 다른 이미지 개념과 내용을 포착하는 것을 목표로 합니다.
- 정제된 데이터셋의 이미지가 3개 이상 포함된 각 클러스터에서 10,000개의 이미지를 샘플링하여 가져옵니다.
- 이러한 과정은 정제된 데이터셋의 개념적 다양성을 바탕으로 정제되지 않은 데이터에서 해당 개념과 관련된 다양한 이미지를 포괄적으로 가져와 데이터셋의 다양성을 높이는 데 기여합니다.
- 쿼리 기반 검색
-
Augmented Curated Data (증강된 정제 데이터):
- "Curated Data"와 "Retrieval" 단계에서 선별된 "Uncurated Data"의 고품질 이미지를 결합하여 생성된 최종 데이터셋입니다. 이 데이터셋은 다양하고 선별된 이미지를 대량으로 포함하여 DINOv2 모델 학습에 사용됩니다.
- 이 과정을 통해 총 1억 4,200만 개의 이미지를 포함하는 LVD-142M 데이터셋이 구축되었습니다.
Discriminative Self-supervised Pre-training
Image-level objective
전체적인 이미지 수준에서 특징(feature)을 학습하기 위한 손실 함수로, 이전 논문인 DINO의 접근 방식을 그대로 따릅니다.
- 학생(Student) 및 교사(Teacher) 네트워크 구조: 이 학습 방법은 두 개의 신경망, 즉 학생 네트워크와 교사 네트워크를 사용합니다. 이들은 동일한 이미지를 서로 다르게 크롭한 뒤 각각의 특징을 추출합니다.
- 클래스 토큰(Class Token) 활용: Vision Transformer(ViT) 모델에서 이미지 전체를 대표하는 '클래스 토큰'으로부터 특징을 얻습니다.
- DINO 헤드: 학생 및 교사 네트워크의 클래스 토큰은 각각 'DINO 헤드'라고 불리는 MLP(Multi-Layer Perceptron) 모델을 통과합니다. 이 헤드는 '프로토타입 스코어(prototype scores)'라는 벡터를 출력합니다.
- 이렇게 ViT 백본 모델과 MLP 헤드를 별도로 두면, 백본(ViT)은 일반적인 이미지 특징 추출기로서의 역할을 유지하면서, 헤드 부분은 자기 지도 학습의 특정 목표에 최적화될 수 있습니다.
- 이는 백본이 다양한 다운스트림 작업에 전이될 때, 불필요한 자기 지도 학습 특유의 편향이 덜 생기도록 돕는 역할을 합니다.
- 확률 분포 생성:
- 학생 네트워크의 프로토타입 스코어에는 소프트맥스(softmax) 함수를 적용하여 확률 분포 를 얻습니다.
- 교사 네트워크의 프로토타입 스코어에는 소프트맥스 함수를 적용한 후, Sinkhorn-Knopp 센트링(SwAV Unsupervised learning of visual features by contrasting cluster assignments에서 자세히 설명됨)을 적용하여 확률 분포 를 얻습니다.
- 교사 네트워크 업데이트: 교사 네트워크의 파라미터는 학생 네트워크의 과거 반복(iterates)에 대한 지수 이동 평균(exponential moving average)으로 업데이트됩니다 (Momentum contrast for unsupervised visual representation learning 참조). 이는 교사 네트워크가 학생 네트워크보다 더 안정적인 학습 목표를 제공하도록 돕습니다.
DINO 손실 함수 ()
- : DINO 손실 함수입니다. 이 값을 최소화하는 것이 학습의 목표입니다.
- : 모든 가능한 프로토타입(prototype)에 대한 합을 나타냅니다.
- : 교사 네트워크의 출력 확률 분포입니다. 이는 학생 네트워크가 모방해야 할 '타겟(target)' 분포 역할을 합니다. 교사 네트워크는 학생 네트워크보다 더 부드럽고 안정적인 예측을 제공하도록 설계됩니다.
- : 학생 네트워크의 출력 확률 분포 에 로그를 취한 값입니다.
이 손실 함수는 교차 엔트로피(Cross-Entropy) 손실의 형태를 띠고 있습니다. 교차 엔트로피는 두 확률 분포(와 ) 간의 유사성을 측정하며, 이 값이 작을수록 두 분포가 더 가깝다는 것을 의미합니다. 즉, 학생 네트워크가 교사 네트워크의 예측을 얼마나 잘 모방하는지를 평가합니다.
Classification이 아님에도 Softmax를 사용하는 이유
- 확률로 변환: 입력 이미지를 통해 MLP에서 나온 로짓을 특정 클러스터에 속할 확률로 표현하기 위해.
- 크로스 앤트로피 적용 가능: 크로스 엔트로피 손실 함수는 두 확률 분포 간의 유사성을 측정하는 데 사용됩니다. 소프트맥스를 통해 분포 형태로 만들면, 두 네트워크의 출력을 크로스 엔트로피로 직접 비교할 수 있게 됩니다.
- 클러스터링 효과: DINO는 본질적으로 '한 이미지로부터 크롭된 두 이미지가 유사한 특징 공간을 가지도록' 학습합니다. 소프트맥스를 통해 각 이미지를 '가상의 클러스터' 또는 '프로토타입'에 할당하는 확률 분포를 생성하고, 같은 이미지에서 나온 다른 증강들이 동일한 프로토타입 분포를 가지도록 강제함으로써, 모델이 이미지의 두 크롭에 대한 특징을 군집화하고 구분하는 능력을 배우게 됩니다.
선생과 학생에게 서로 다른 크롭 이미지를 주는 이유
-
뷰(View) 변화에 대한 불변성(Invariance) 학습:
- DINO의 가장 핵심적인 아이디어는 같은 이미지에서 파생된 다양한 뷰(크롭)들이 특징 공간에서 유사한 표현을 가져야 한다는 것입니다.
- 학생 모델은 이미지의 아주 작은 부분만을 보더라도, 교사 모델이 전체 이미지를 본 것과 동일한 의미론적(semantic) 정보를 인코딩하도록 강제됩니다.
- 예를 들어, 학생 모델이 자동차 바퀴 부분만 보고도 그것이 자동차의 바퀴임을 파악하고, 교사 모델이 전체 자동차를 보고 얻은 특징과 일치하도록 학습해야 합니다. 이는 모델이 부분과 전체 간의 관계를 이해하고, 객체의 스케일, 위치, 자세 변화에 덜 민감한 견고한(robust) 특징을 학습하게 만듭니다.
-
자기 증류(Self-Distillation) 메커니즘:
- 교사 네트워크는 학생 네트워크 파라미터의 지수 이동 평균(Exponential Moving Average, EMA)으로 업데이트됩니다. 이는 교사 네트워크가 학생 네트워크보다 더 안정적이고, 학습 진행에 따라 점진적으로 개선되는 '더 나은 버전의 학생' 역할을 하도록 만듭니다.
- 교사가 학생보다 안정적인 타겟을 제공함으로써, 학습이 불안정해지거나 모든 입력에 대해 동일한 출력을 내는 "붕괴(collapse)" 현상을 방지합니다. 학생은 항상 "약간 더 나은 버전의 자신"을 모방하려고 노력함으로써 지속적으로 발전합니다.
-
암시적인 클러스터링 및 의미론적 학습:
- DINO는 명시적인 클러스터링 알고리즘을 사용하지 않지만, 소프트맥스를 통해 '프로토타입 스코어'를 확률 분포로 변환하고 크로스 엔트로피 손실을 사용하는 과정에서 암시적인 클러스터링 효과가 발생합니다.
- 모델은 학습 과정에서 데이터 내의 자연스러운 의미론적 그룹(예: "자동차", "새", "건물" 등)을 스스로 식별하고, 각 이미지를 이러한 가상의 프로토타입에 할당하는 방법을 학습합니다. 같은 이미지의 다른 크롭들이 동일한 프로토타입 분포를 갖도록 학습함으로써, 모델은 단순히 픽셀 패턴을 넘어선 의미론적 일관성을 포착합니다.
-
객체 분할 능력의 출현(Emergent Properties):
- DINO의 가장 놀라운 발견 중 하나는 명시적인 분할(segmentation) 레이블 없이도 CLS 토큰이 이미지의 주요 객체를 구분하고 배경과 분리하는 능력을 스스로 학습한다는 것입니다.
- 이는 모델이 다양한 크롭에 대해 불변적인 특징을 학습하기 위해서는, 배경처럼 쉽게 변하는 요소보다는 객체와 같이 일관되게 나타나는 중요한 요소에 집중해야 하기 때문입니다. 이러한 학습 과정에서 모델은 객체의 경계나 의미론적 영역을 자연스럽게 이해하게 됩니다.
Patch-level objective
"Patch-level objective"는 이미지의 각 패치(patch) 수준에서 특징을 학습하는 방법 중 하나로, iBOT (Zhou et al., 2022a)의 아이디어를 활용합니다. 이 목적은 모델이 이미지 전체의 특징뿐만 아니라, 이미지 내의 작은 부분들에 대한 특징도 잘 이해하도록 돕습니다.
주요 내용은 다음과 같습니다:
- 마스킹(Masking): 학습 과정에서 학생(student) 네트워크에는 입력 이미지의 일부 패치들이 무작위로 가려진(masked) 상태로 주어집니다. 반면, 선생님(teacher) 네트워크에는 마스킹되지 않은 원본 이미지가 주어집니다. 이는 학생 네트워크가 가려진 부분의 정보를 예측하도록 학습하여, 더욱 견고한 특징을 학습하게 합니다.
- iBOT 헤드 적용:
- 학생 네트워크는 마스킹된 패치 토큰(masked token)에 대해 학생 iBOT 헤드(student iBOT head)를 적용하여 출력값을 생성합니다.
- 선생님 네트워크는 학생 네트워크에서 마스킹된 패치에 해당하는, 원본 이미지의 '보이는(visible)' 패치 토큰에 대해 선생님 iBOT 헤드(teacher iBOT head)를 적용하여 출력값을 생성합니다.
- Softmax 및 Centering: 두 네트워크의 출력값에는 소프트맥스(softmax) 함수가 적용되어 확률 분포와 유사한 형태로 변환됩니다. 또한, "centering"이라는 과정이 적용되는데, 이는 학습 안정성을 높이고 'collapse' 현상(모든 입력이 동일한 출력으로 매핑되는 현상)을 방지하는 역할을 합니다. 본 논문에서는 SwAV (Caron et al., 2020)에서 제안된 Sinkhorn-Knopp centering을 사용한다고 언급합니다.
- iBOT 손실 함수 (Loss Term): 최종적으로 학생 네트워크의 예측값(
ps)과 선생님 네트워크의 목표값(pt) 사이의 차이를 줄이는 방향으로LiBOT손실이 계산됩니다.LiBOT손실 함수는 다음과 같습니다:
- 여기서 는 마스킹된 패치들의 인덱스를 나타냅니다.
- 는 선생님 네트워크의 i번째 패치 토큰에 대한 '프로토타입 점수(prototype scores)'에 소프트맥스와 센트링을 적용하여 얻은 목표 분포입니다.
- 는 학생 네트워크의 i번째 마스킹된 패치 토큰에 대한 '프로토타입 점수'에 소프트맥스를 적용하여 얻은 예측 분포입니다.
- 이 공식은 교차 엔트로피(cross-entropy) 손실의 형태를 띠며, 학생 네트워크가 선생님 네트워크의 예측을 모방하도록 학습시키는 역할을 합니다.
- 교사 헤드의 구축: 선생님 헤드(teacher head)는 과거 반복(iterate)들의 지수 이동 평균(exponential moving average)을 통해 구축됩니다. 이는 선생님 네트워크가 학생 네트워크보다 더 안정적이고 점진적으로 업데이트되는 특징을 갖게 하여, 학습의 목표가 되는 "더 나은" 특징 표현을 제공합니다.
이러한 패치 수준의 목표는 모델이 이미지의 지역적인(local) 특징을 학습하고, 가려진 정보를 재구성하는 능력을 개발하여, 픽셀 수준의 작업(예: 세분화)에서 좋은 성능을 발휘하는 데 기여합니다.
Untying head weights between both objectives
- DINO 및 iBOT 손실 함수의 헤드: DINO와 iBOT은 모두 MLP 프로젝션 헤드를 사용하여 출력 토큰(output tokens)에 적용하고, 이 위에 손실(loss)을 계산합니다.
- 기존 연구와의 차이:
- 기존 iBOT 논문(Zhou et al., 2022a)에서는 DINO와 iBOT 헤드 간에 파라미터를 공유하는 것이 성능 향상에 도움이 된다는 연구 결과가 있었습니다.
- 하지만 DINOv2 연구팀은 '대규모(at scale)' 환경에서 이와 반대되는 현상을 관찰했습니다. 즉, DINO와 iBOT 손실 함수에 대해 두 개의 별도 헤드를 사용하는 것이 더 나은 성능을 보였다는 것입니다.
- DINOv2의 결정: 이러한 관찰을 바탕으로 DINOv2는 모든 실험에서 DINO와 iBOT 손실을 위해 별도의 헤드를 사용했습니다. 이는 모델을 대규모로 학습할 때 안정성과 성능을 높이는 데 기여한 기술적 개선 사항 중 하나입니다. 이러한 설계 결정은 대규모 모델 학습 시 특정 최적화 목표(예: 이미지 레벨 목표와 패치 레벨 목표)에 대한 헤드를 분리함으로써 모델이 각 목표에 더 특화된 특징을 학습하고 전체적인 성능을 향상시킬 수 있음을 시사합니다.
Sinkhorn-Knopp centering
Sinkhorn-Knopp 중앙화(Centering)는 자기 지도 학습(Self-Supervised Learning)에서 발생하는 문제인 모드 붕괴(mode collapse)를 방지하고, 모델이 이미지 특징을 학습할 때 클러스터, 피처, 혹은 프로토타입(prototype)들을 균등하게 사용하도록 유도하는 중요한 기술입니다.
이 알고리즘은 기본적으로 주어진 양의 행렬(positive matrix)을 이중 확률 행렬(doubly stochastic matrix)로 변환하는 반복적인 과정입니다. 이중 확률 행렬은 모든 행과 열의 합이 1이 되는 행렬을 의미합니다.
-
배경: 프로토타입 스코어 행렬()
- Teacher 네트워크는 주어진 이미지 배치(개의 이미지)에 대해 여러 개의 프로토타입(가상의 클러스터 중심)에 대한 스코어를 출력합니다.
- 이 스코어들은 크기의 행렬 로 표현될 수 있습니다. 여기서 는 배치 크기, 는 프로토타입의 개수입니다. 는 번째 이미지의 특징이 번째 프로토타입에 속할 확률 또는 유사도를 나타냅니다.
- 이 행렬에 softmax를 적용하여 각 이미지에 대한 프로토타입 분포를 확률로 변환합니다.
-
Sinkhorn-Knopp 중앙화 과정:
이 알고리즘은 다음 두 단계를 반복하여 행렬을 이중 확률 행렬에 가깝게 만듭니다.-
행 정규화(Row Normalization):
- 행렬의 각 행(즉, 각 이미지에 대한 프로토타입 스코어)을 정규화하여 해당 행의 합이 1이 되도록 만듭니다. 이는 각 이미지가 여러 프로토타입에 할당될 때의 확률 분포를 의미합니다.
- 수학적으로는 각 를 해당 행의 모든 요소의 합으로 나눕니다.
-
열 정규화(Column Normalization):
- 정규화된 행렬의 각 열(즉, 각 프로토타입에 할당된 모든 이미지의 스코어)을 정규화하여 해당 열의 합이 1이 되도록 만듭니다. 이는 각 프로토타입이 전체 이미지 배치에서 균등하게 사용되도록 강제하는 역할을 합니다.
- 수학적으로는 각 를 해당 열의 모든 요소의 합으로 나눕니다.
-
반복: 위 1번과 2번 단계를 정해진 횟수만큼 (DINOv2에서는 3회) 반복합니다. 반복할수록 행렬은 이중 확률 행렬에 더 가까워집니다.
-
-
모드 붕괴 방지 원리:
- 일반적인 군집화(clustering)나 자기 지도 학습 방식에서는 모델이 단순히 가장 흔한 특징에만 집중하거나, 소수의 프로토타입에만 대부분의 이미지를 할당하여 나머지 프로토타입들이 거의 사용되지 않는 모드 붕괴 현상이 발생할 수 있습니다.
- Sinkhorn-Knopp의 열 정규화 단계()는 모든 프로토타입()이 전체 배치 내에서 일정량의 "할당"을 받도록 강제합니다. 즉, 어떤 프로토타입이 다른 프로토타입보다 훨씬 더 많은 이미지에 할당되는 것을 막아, 모델이 모든 프로토타입을 활성화하고 다양한 특징을 학습하도록 유도합니다.
- 결과적으로, Teacher 네트워크는 각 프로토타입이 이미지 배치 내에서 대략적으로 동일한 빈도로 사용되도록 하는 분포를 출력하게 되며, 이는 모델이 보다 균형 잡히고 일반화 가능한 특징을 학습하는 데 기여합니다.
직관적인 예시
- 배치(Batch): 고양이 이미지 1개, 강아지 이미지 1개
- 프로토타입/의미론적 특징 (Feature/Prototype): '귀', '꼬리', '다리' (3차원 피처)
- Teacher 네트워크의 출력: 각 이미지(고양이, 강아지)가 각 프로토타입('귀', '꼬리', '다리')에 얼마나 잘 매핑되는지에 대한 점수 행렬.
-
행 정규화 (Row Normalization)의 효과:
- 개념: 각 이미지(행)의 점수들을 정규화하여 합이 1이 되도록 만듭니다.
- 예시 적용:
- 개 이미지:
[귀 점수, 꼬리 점수, 다리 점수] - 행 정규화를 하면, 이 점수들이
[정규화된 귀 점수, 정규화된 꼬리 점수, 정규화된 다리 점수]처럼 각 부위에 대한 상대적인 중요도를 나타내는 확률 분포가 됩니다.
- 개 이미지:
- 효과 해석:
"개 이미지에 대해 행 정규화를 하면 '개'의 특징이 귀, 꼬리, 다리에 골고루 분포하여 모델이 개를 구성하는 다양한 부위를 보도록 유도한다."
-
열 정규화 (Column Normalization)의 효과:
- 개념: 각 프로토타입(열)에 대한 점수들을 정규화하여 합이 1이 되도록 만듭니다.
- 예시 적용:
- '귀' 프로토타입:
[개 이미지의 귀 점수, 고양이 이미지의 귀 점수] - 열 정규화를 하면, 이 점수들이
[정규화된 개 이미지의 귀 점수, 정규화된 고양이 이미지의 귀 점수]처럼 '귀'라는 프로토타입이 배치 내의 여러 이미지(개, 고양이)에 걸쳐 얼마나 활성화되는지에 대한 상대적인 기여도를 나타내는 분포가 됩니다.
- '귀' 프로토타입:
- 효과 해석:
"귀 피처에 대해 열 정규화를 하면, '귀'라는 의미론적 특징이 강아지와 고양이처럼 다른 종이 가지는 보편적인 특징을 이해하도록 하여, 특정 동물에만 해당 피처가 과도하게 활성화되는 것을 막는다."
이전 DINO의 센터링 방법
- 강아지 이미지로부터 나온 귀, 고리, 다리에 대한 로짓에 softmax를 취해 정규화 해줍니다.
- 그리고 이전까지의 스텝에서 누적하여 계산된 평균 소프트맥스 값을 빼줍니다.
- 이렇게 하면 계산된 softmax 값은 평균으로부터 얼마나 떨어져 있는지를 나타내는 값으로 바뀝니다.
- 해당 방식은 선생 모델의 출력 분포를 항상 평균에 가깝게 하여 모델 훈련을 안정화할 수 있습니다.
- 그러나 DINOv2에선 행과 열 모두에 softmax를 취해 이러한 모델 학습을 더욱 안정화 합니다.
KoLeo regularizer
KoLeo 정규화(KoLeo regularizer)는 주어진 배치(batch) 내의 특징(feature)들이 특징 공간(feature space)에 균일하게 분포(uniform span)되도록 장려하는 역할을 합니다. 이는 특히 유사성 기반 작업에서 모델의 성능을 향상시키는 데 기여합니다.
이 정규화 손실()은 Kozachenko-Leonenko 미분 엔트로피 추정량에서 파생되었으며, 다음과 같이 정의됩니다:
각 항의 의미는 다음과 같습니다:
- : 현재 배치에 포함된 벡터()의 총 개수입니다.
- : 배치 내의 모든 벡터 에 대해 계산된 값을 합산합니다.
- : 합산된 값을 벡터 개수 으로 나누어 평균을 계산하고, 손실 함수이므로 최소화하기 위해 음수 부호(-)를 붙입니다.
- : 각 벡터 에 대해 계산된 값에 자연 로그()를 적용한 것입니다.
- : 이는 배치 내에서 벡터 와 다른 모든 벡터 간의 유클리드 거리() 중 최소값을 나타냅니다. 즉, 로부터 가장 가까운 이웃까지의 거리를 의미합니다.
작동 원리 및 목적:
- 이 손실 함수는 각 특징 벡터 가 배치 내의 다른 벡터들로부터 최대한 멀리 떨어져 있도록 유도합니다.
- 값이 커질수록(가 이웃들로부터 멀어질수록) 값도 커집니다. 손실 함수 앞에 음수 부호가 붙어 있으므로, 가 커질수록 는 작아지게(더 좋은 값이 되게) 됩니다.
- 따라서 모델은 특징들이 특징 공간의 특정 영역에 집중되지 않고, 전체 공간에 고르게 퍼지도록 학습됩니다.
- 논문의 Ablation Studies (Table 3a)에 따르면, KoLeo 손실 항을 사용했을 때 인스턴스 검색(instance retrieval) 성능이 8% 이상 향상되는 것으로 나타났습니다. 이는 특징들이 고르게 분산됨으로써 각 인스턴스(객체)를 더 잘 구별할 수 있게 되어 검색 성능이 개선되었음을 시사합니다.
Efficient Stochastic Depth
-
스토캐스틱 뎁스(Stochastic Depth)란?
- 원래 스토캐스틱 뎁스는 Huang et al., 2016에서 제안된 기법으로, 딥 뉴럴 네트워크 훈련 시 각 학습 배치(batch)마다 네트워크의 일부 레이어(정확히는 잔차 연결(residual) 부분)를 무작위로 건너뛰는 방식입니다.
- 이는 모델이 특정 레이어에 과도하게 의존하는 것을 방지하여 일반화(generalization) 성능과 강건함(robustness)을 높이는 데 도움을 줍니다.
-
DINOv2의 효율적인 구현:
- 기존 스토캐스틱 뎁스 구현 방식은 건너뛰기로 결정된 잔차(residuals)에 대한 계산을 수행한 후, 그 결과를 마스킹(masking)하거나 0으로 만드는 방식이었습니다.
- 하지만 DINOv2는 'specific fused kernels' 덕분에 이 잔차 계산 자체를 완전히 건너뛰도록 구현하여 훨씬 더 효율적입니다.
- 이점: 이러한 개선을 통해 드롭률(drop rate)에 비례하여 메모리 사용량과 연산량(compute)을 크게 절약할 수 있습니다. 예를 들어, 이 논문에서는 의 높은 드롭률을 사용함으로써 연산 효율성 및 메모리 사용량에서 획기적인 개선을 달성했습니다.
- 구현 방식: 이는 배치 차원(batch dimension)에서 개의 샘플을 무작위로 섞은 다음, 첫 번째 개의 샘플만 해당 블록의 계산에 사용하고 나머지 샘플은 계산을 건너뛰는 방식으로 이루어집니다.
- 여기서 는 배치 크기(batch size)를, 는 드롭률을 의미합니다. 예를 들어, 이고 라면, 개의 샘플만 연산에 참여합니다.
-
연구 진행 연결:
- 이러한 효율성 개선은 대규모 모델 학습에서 매우 중요합니다. 특히, DINOv2와 같이 거대한 Vision Transformer (ViT) 모델을 수십억 개의 파라미터로 학습시키고 방대한 데이터셋을 처리할 때는 GPU 메모리 및 연산 시간에 대한 최적화가 필수적입니다. 이 효율적인 스토캐스틱 뎁스 구현은 모델 크기와 데이터셋 규모를 확장하는 데 기여하며, 이는 Llama: Open and Efficient Foundation Language Models나 Training Compute-Optimal Large Language Models와 같은 대규모 언어 모델 연구에서 컴퓨팅 효율성을 강조하는 추세와 맥락을 같이합니다.
Model Distillation
이렇게 훈련한 모델을 간단한 지식 증류 과정을 통해 더 작은 모델로 전이시키는 것입니다.
- 가장 큰 모델인 ViT-g은 위에 소개된 방식으로 훈련됩니다.
- 이후에 이를 동결시킨 후 선생 모델로 할당합니다.
- 그리고 이보다 더 작은 모델 (ViT-s 등)을 학생 모델로 할당합니다.
- 이후 지식 증류를 진행하는데 과정이 위와 약간 다릅니다.
- 선생과 학생 모두 글로벌 크롭 이미지를 받습니다. 왜냐하면 이 과정에선 학생 모델이 선생 모델의 확률 분포를 따라하며 global feature를 추출하는 능력을 학습시키기 때문입니다.
- 그리고 학생 모델이 local feature도 잘 학습하기 위해 다음과 같은 방법을 씁니다. 위의 iBOT loss의 사용 방식과 달리, 학생 모델에 임베딩 되는 이미지 패치는 마스킹 과정을 거치지 않습니다. 국소 패치들로부터 계산된 피처들이 선생이 추론한 피처와 유사하도록 강제하여 지역적인 특징을 잘 학습시키는 방법입니다.
- 또한 학생 모델의 학습 과정이 불안정할 수 있기 때문에, EMA를 학생 모델에 적용시켜, 이전 스텝의 파라미터를 조금씩 반영하도록 합니다.
- 학생 모델은 방대한 네트워크가 아니므로 스토캐스틱 뎁스 방법 또한 사용하지 않습니다.
Result
(추후 작성)
