논문 링크: https://arxiv.org/abs/2406.07803
1. Introduction
이 섹션은 감정적인 텍스트 음성 변환(Emotional Text-to-Speech, TTS) 분야의 최신 연구 동향과 한계점을 제시하고, 이를 해결하기 위해 EmoSphere-TTS 모델을 제안하는 내용이다.
-
감정 TTS의 발전과 한계점:
- 최근 TTS 기술은 빠르게 발전하고 있으며, 감정 TTS에 대한 관심도 증가하고 있다.
- 하지만, 높은 수준으로 감정을 해석하고 제어하는 데는 여전히 한계가 존재한다.
- 특히, 동일한 감정 레이블로 분류된 음성이라도 연기자의 표현 방식에 따라 다양한 감정 표현을 나타낼 수 있어, 이를 제어하는 것이 어렵다.
-
기존 감정 TTS 접근 방식의 한계:
- 감정 레이블 기반 접근 방식:
- 특정 감정의 평균적인 스타일을 모방하는 데 초점을 맞추어 감정을 이산적인 레이블로만 처리한다.
- 이로 인해 감정의 복잡하고 미묘한 변화를 반영하지 못하고, 표현을 획일적인 스타일로 단순화하는 경향이 있다. 예를 들어, '슬픔'은 '외로움'이나 '아픔'과 같은 다양한 감정을 포함하지만, 이산적인 레이블은 이러한 뉘앙스를 간과한다.
- 대표적인 방법으로는 Relative attribute와 EmoQ-TTS가 있다.
- 참조 오디오 기반 접근 방식:
- 참조 오디오에서 감정 임베딩을 추출하고, 스케일링 팩터(scaling factor)를 곱하여 감정 강도를 제어하는 방식이다.
- 하지만 참조 오디오와 합성된 음성 간의 불일치로 인해 미묘한 뉘앙스를 포착하기 어렵다.
- 또한, 적절한 스케일링 팩터를 찾기 어렵고, 조정 시 오디오 품질이 불안정해지는 문제가 있다. Scaling Factor가 이러한 접근 방식의 예이다.
- 감정 레이블 기반 접근 방식:
-
감정 차원(Emotional Dimensions) 활용의 시도와 문제점:
- Russell [16]은 인간의 감정을 연속적인 공간으로 표현하는 circumplex 모델을 제안하였고, 이를 바탕으로 연구자들은 AVD (Arousal, Valence, Dominance)와 같은 감정 차원을 활용하여 감정 표현을 제어하려고 시도한다.
- AVD는 이산적인 감정보다 더 연속적이고 세밀한 감정 제어를 가능하게 한다.
- 그러나 AVD 주석이 포함된 감정 음성 데이터베이스가 극히 적으며, 이러한 데이터 수집은 주관성이 강하고 비용이 많이 든다는 문제가 있다.
- 또한, 모델이 AVD 차원을 직관적이고 명확하게 제어하는 것이 어렵다.
-
EmoSphere-TTS의 제안:
- 위에서 언급된 한계점들을 해결하기 위해 EmoSphere-TTS가 제안되었다.
- 구형 감정 벡터 공간(Spherical Emotion Vector Space): 감정 스타일과 강도를 제어하기 위해 구형 감정 벡터 공간을 도입한다. 이 공간은 복잡한 감정의 본질을 모델링하는 데 핵심적인 역할을 한다.
- AVD 의사 레이블(Pseudo-labels) 활용: 사람의 주석 없이 음성 감정 인식(SER)에서 AVD 의사 레이블을 추출하여 사용한다.
- 직교-구형 변환(Cartesian-spherical Transformation): 직교 좌표계에서 AVD 의사 레이블을 구형 좌표계로 변환하여 감정의 복잡한 특성을 모델링한다.
- 이중 조건부 적대적 네트워크(Dual Conditional Adversarial Network): 감정과 화자 특정 특성을 반영하여 생성된 음성의 품질을 향상시킨다.
- 실험 결과, EmoSphere-TTS는 다른 모델보다 우수한 오디오 품질과 감정 유사성을 보이며, 제어 가능한 감정 TTS에서 뛰어난 성능을 입증한다.
기존 연구들은 감정을 이산적인 형태로 다루거나, 참조를 통해 간접적으로 제어하는 방식이었지만, EmoSphere-TTS는 AVD 차원을 구형 공간으로 변환하여 감정의 연속성과 복잡성을 직접적으로 모델링하고 제어하려는 새로운 접근 방식을 제시한다. 이는 기존 방식의 한계를 극복하고, 더욱 세밀하고 풍부한 감정 표현 합성의 가능성을 열어준다.
2. EmoSphere-TTS
2.1. Emotional style and intensity modeling
AVD encoder
AVD 인코더는 EmoSphere-TTS 시스템에서 오디오로부터 감정 표현을 추출하는 구성 요소이다. 이 부분에 대한 자세한 설명은 다음과 같다.
- 인간 주석(human annotation) 대체: 이 연구는 인간이 직접 감정을 주석하는 대신, wav2vec 2.0 기반의 SER (Speech Emotion Recognition) 모델을 채택한다. 이 모델은 오디오로부터 일관되고 연속적이며 상세한 감정 표현을 추출하는 데 사용된다.
- AVD 의사 레이블(pseudo-labels) 추출: SER 모델은 감정의 Arousal, Valence, Dominance 차원()에 대한 예측을 생성한다.
- : 번째 감정의 번째 좌표를 의미한다.
- : Arousal (각성)을 나타낸다. 감정의 강도나 활성화 수준을 의미한다.
- : Valence (쾌락)을 나타낸다. 감정의 긍정적/부정적 정도를 의미한다.
- : Dominance (지배)를 나타낸다. 감정을 제어하는 정도나 통제력을 의미한다.
- Cartesian 좌표계 값: 추출된 값들은 각각 Cartesian 좌표계에서 대략 0에서 1 사이의 범위를 가진다.
- 활용 목적: 이렇게 얻은 AVD 값들은 이후 Cartesian-spherical 변환 과정을 거쳐 구형 감정 벡터 공간을 구축하는 데 활용되며, 이는 합성 음성의 감정 스타일과 강도를 효과적으로 제어하기 위한 핵심 요소이다.
Cartesian-spherical transformation
EmoSphere-TTS는 감정의 복잡한 특성을 모델링하기 위해 Cartesian-spherical 변환을 활용하여 구면 감정 벡터 공간을 도입한다. 이 변환은 감정 스타일과 강도를 연속적인 스칼라 값으로 쉽게 제어할 수 있도록 돕는다.
- 변환의 목적: 감정을 중립 감정 센터로부터의 상대적인 거리(강도)와 각도(스타일) 벡터로 표현하는 구면 감정 벡터 공간을 구축하는 것이다.
- 주요 가정:
- 감정 강도는 중립 감정 센터에서 멀어질수록 증가한다.
- 중립 감정 센터로부터의 각도가 감정 스타일을 결정한다.
- 변환 과정:
- Cartesian 좌표 이동: AVD (Arousal, Valence, Dominance) 가상 레이블의 모든 점을 중립 감정 센터 을 원점으로 설정하여 변환된 Cartesian 좌표 를 얻는다.
- 중립 감정 센터 은 다음과 같이 정의된다:
,- : k-번째 감정의 i-번째 AVD Cartesian 좌표이다. 이 값들은 Arousal (), Valence (), Dominance ()를 나타내며 각각 0에서 1 사이의 값을 가진다.
- : 전체 중립 감정 좌표들의 평균으로 계산된 중립 감정 센터이다.
- : 총 중립 좌표의 수이다.
- : i-번째 중립 감정 좌표이다.
- : k-번째 감정의 i-번째 변환된 Cartesian 좌표로, 에서 을 뺀 값이다. 이는 중립 센터를 원점으로 이동시킨 효과를 가진다.
- 중립 감정 센터 은 다음과 같이 정의된다:
- 구면 좌표계로 변환: 이동된 Cartesian 좌표 를 구면 좌표계 로 변환한다.
- 반지름 (감정 강도):
,- : 변환된 Cartesian 좌표의 Arousal, Valence, Dominance 값이다.
- : 원점(중립 감정 센터)으로부터의 유클리드 거리로, 감정의 강도를 나타낸다.
- 극각 (감정 스타일):
,- : -축(Dominance 축)과 반지름 벡터가 이루는 각도이다. 이는 감정 스타일의 한 측면을 결정한다.
- 방위각 (감정 스타일):
,- : -축(Arousal 축)과 -평면에 투영된 반지름 벡터가 이루는 각도이다. 이는 감정 스타일의 다른 측면을 결정한다.
- 반지름 (감정 강도):
- 정규화 및 양자화:
- 강도 정규화: 계산된 방사형 거리 (감정 강도)를 0에서 1 범위로 스케일링하여 정규화한다. 이를 위해 사분위 범위 기술(A review of statistical outlier methods)을 활용한 최소-최대 정규화가 사용된다.
- 스타일 양자화: 방향 각도 와 (감정 스타일)를 A, V, D 축의 양수 및 음수 방향에 따라 8개의 팔분공간(octants)으로 분할하여 양자화한다.
- Cartesian 좌표 이동: AVD (Arousal, Valence, Dominance) 가상 레이블의 모든 점을 중립 감정 센터 을 원점으로 설정하여 변환된 Cartesian 좌표 를 얻는다.
이러한 과정을 통해 EmoSphere-TTS는 복잡한 감정의 본질을 더 세밀하게 제어할 수 있는 구면 감정 벡터 공간을 구축한다.
2.2. Spherical emotion encoder
Spherical emotion encoder는 구형 감정 벡터 공간의 정보를 감정 ID와 결합하여 구형 감정 임베딩을 구성하는 부분이다. 이는 복잡한 감정의 본질을 담은 음성 합성을 가능하게 하는 핵심 요소이다.
-
구축 과정:
- 감정 스타일 벡터와 감정 클래스 임베딩의 차원 정렬: 먼저 감정 스타일 벡터 ()와 감정 클래스 임베딩 ()의 차원을 맞추기 위해 프로젝션 레이어를 사용한다.
- 결합 및 활성화 함수 적용: 차원 정렬된 와 를 연결(concatenate)하고, 그 결과에 Softplus 활성화 함수를 적용한다 . Softplus는 ReLU와 유사하지만 0에서 미분 가능하고 부드러운 곡선 형태를 가지며, 양의 값을 유지하여 신경망 학습에 도움을 준다.
- 레이어 정규화 (Layer Normalization, LN) 적용: Softplus 결과에 LN을 적용한다 Layer Normalization. LN은 미니 배치 내의 각 샘플에 대해 특징의 평균과 분산을 정규화하여 학습의 안정성을 높이고 수렴 속도를 향상시키는 역할을 한다.
- 감정 강도 벡터 추가: 마지막으로 프로젝션된 감정 강도 벡터 ()를 앞선 결과에 더하여 최종 구형 감정 임베딩 ()을 완성한다.
-
수식 설명:
구형 감정 임베딩 는 다음 수식으로 표현된다.- : 최종적으로 생성되는 구형 감정 임베딩이다.
- : Layer Normalization 함수이다.
- : Softplus 활성화 함수이다. 이다.
- : 두 벡터를 연결하는(concatenation) 함수이다.
- : AVD 로부터 계산된 와 에서 파생된다.
- : 감정 클래스 임베딩이다. 이산적인 감정 ID(예: 행복, 슬픔, 분노)로부터 생성된 임베딩이다.
- : 감정 강도 벡터이다. 중립 감정 중심으로부터의 방사형 거리 을 0에서 1 사이로 정규화하여 얻는다.
이러한 과정을 통해, EmoSphere-TTS는 감정의 스타일과 강도 정보를 감정 클래스 정보와 통합하여 TTS 시스템에 제공한다. 이는 단순히 감정 레이블을 사용하는 것보다 훨씬 미묘하고 다양한 감정 표현을 합성하는 데 기여한다.
2.3. Dual conditional adversarial training
이 섹션은 EmoSphere-TTS 모델에서 합성된 음성의 품질과 표현력을 개선하기 위한 이중 조건부 적대적 학습(Dual conditional adversarial training) 방법을 설명한다.
-
목표: TTS(Text-to-Speech) 모델이 생성하는 음성의 품질을 높이고, 감정과 화자(speaker)의 특징을 더 효과적으로 반영하여 표현력을 향상하는 것이다.
-
적대적 학습 구조:
- Discriminator (판별자): 여러 개의 CNN 기반 Discriminator를 사용한다. 이는 다중 Conv2D 스택(Convolutional layers)과 완전 연결(Fully Connected, FC) 레이어로 구성된다.
- 입력: Discriminator의 입력은 랜덤하게 클립된 멜-스펙트로그램(Mel-spectrogram clip)이다. 이 클립은 다양한 길이 의 랜덤 윈도우를 사용하여 추출된다.
- 조건부 정보 활용:
- Discriminator 중 하나는 오직 멜-클립만을 입력으로 받는다.
- 다른 Discriminator들은 '조건 임베딩(condition embedding)'과 멜-클립을 결합하여 입력으로 받는다. 이 조건 임베딩은 음성 품질과 표현력을 향상시키기 위해 감정(emotion)과 화자(speaker)의 다면적 특징을 포착한다.
- 조건 임베딩은 멜-클립의 길이와 일치하도록 확장된 후, 멜-클립과 연결(concatenation)되어 Discriminator에 입력된다.
-
손실 함수(Loss Functions):
- Discriminator 의 손실 함수 와 Generator 의 손실 함수 는 다음과 같다.
- : Discriminator의 손실 함수이다.
- : Generator의 손실 함수이다.
- : 조건 유형(condition type)을 나타내며, 화자(speaker, spk)와 감정(emotion, emo) 두 가지 조건을 의미한다. 이 식은 두 조건 각각에 대해 손실을 계산하여 합산한다.
- : 기댓값(expectation)으로, 데이터 분포에 대한 평균적인 손실을 나타낸다.
- : 실제(ground truth) 멜-스펙트로그램이다.
- : Generator가 생성한 멜-스펙트로그램이다.
- : Discriminator가 실제 멜-스펙트로그램 와 조건 를 입력받아 '진짜'일 확률을 예측하는 출력값이다. Discriminator는 이 값이 1에 가까워지도록 학습된다.
- : Discriminator가 생성된 멜-스펙트로그램 와 조건 를 입력받아 '진짜'일 확률을 예측하는 출력값이다. Discriminator는 이 값이 0에 가까워지도록 학습된다.
- : Discriminator가 실제 데이터를 '진짜'()로 잘 판별할수록 이 값은 0에 가까워진다.
- : Discriminator가 생성된 데이터를 '가짜'()로 잘 판별할수록 이 값은 0에 가까워진다.
- 는 Discriminator가 실제와 생성된 데이터를 정확하게 구별하도록 훈련시킨다.
- 는 Generator가 Discriminator를 속여 자신이 생성한 멜-스펙트로그램이 실제 데이터()라고 믿게 만들도록 훈련시킨다.
- Discriminator 의 손실 함수 와 Generator 의 손실 함수 는 다음과 같다.
-
결과: 이 이중 조건부 적대적 학습을 통해, 모델은 감정과 화자 고유의 특성을 모두 반영하여 더 높은 품질과 표현력을 가진 음성을 생성할 수 있게 된다.
예시 시나리오: 감정을 가진 특정 화자의 음성 생성
EmoSphere-TTS의 목표는 단순히 텍스트를 음성으로 변환하는 것을 넘어, 특정 감정(예: 행복, 슬픔, 분노)과 특정 화자(예: "김철수", "이영희")의 목소리 특징을 모두 반영하여 자연스러운 음성을 합성하는 것이다.
이것을 달성하기 위해 'Generator'와 'Discriminator'라는 두 개의 신경망 모델이 서로 경쟁하며 학습한다. 여기에 '이중 조건부'라는 요소가 추가된다.
1. Generator (생성자)의 역할: 감정을 가진 화자의 음성 만들기
- 입력: Generator는 "나는 행복해"라는 텍스트, '행복'이라는 감정 정보, 그리고 '김철수'라는 화자 정보를 입력받는다.
- 목표: '김철수'의 목소리로 '행복한' 감정을 담아 "나는 행복해"라고 말하는 음성(멜-스펙트로그램)을 합성하는 것이다. Generator는 마치 위조 지폐범처럼 실제와 구별하기 어려운 음성을 만들려고 노력한다.
2. Discriminator (판별자)의 역할: 진짜 음성과 가짜 음성 구별하기 (이중 조건부)
Discriminator는 경찰관과 같아서 Generator가 만든 음성이 진짜인지, 어떤 감정을 가지고 있는지, 어떤 화자의 목소리인지 판별하는 역할을 한다. 여기에서 '이중 조건부'의 중요성이 드러난다. Discriminator는 단순히 "진짜/가짜"만 판단하는 것이 아니라, "진짜 김철수의 행복한 음성인지"를 판단한다.
이를 위해 Discriminator는 여러 개의 서브 판별자로 구성되거나, 하나의 판별자 내에서 조건부 정보를 활용한다. 예시에서는 두 가지 조건(화자, 감정)을 명시적으로 활용하는 손실 함수를 사용하고 있으므로, 다음과 같이 동작한다고 이해할 수 있다.
-
실제 데이터 학습:
- 입력: 실제 녹음된 '김철수'가 '행복한' 감정으로 말하는 "나는 행복해"라는 음성(멜-스펙트로그램)을 받는다.
- 판별: Discriminator는 이 음성이 '김철수'의 목소리이고 '행복한' 감정이라는 것을 "진짜"라고 판단하도록 학습된다.
- 손실 계산: 만약 Discriminator가 이 진짜 음성을 "가짜"라고 잘못 판단하면, 이 판단 오류에 대해 큰 벌칙(손실)을 받는다.
-
생성된 데이터 학습:
- 입력: Generator가 만든 '김철수'가 '행복한' 감정으로 말하는 "나는 행복해"라는 합성 음성(멜-스펙트로그램)을 받는다.
- 판별: Discriminator는 이 합성 음성이 '김철수'의 목소리이더라도 '행복한' 감정이 제대로 반영되지 않았거나, 전반적으로 자연스럽지 않다면 "가짜"라고 판단하도록 학습된다. 즉, 단순히 '김철수'의 목소리를 흉내내는 것을 넘어, 지정된 감정이 제대로 담겨 있는지도 판별한다.
- 손실 계산: 만약 Discriminator가 이 가짜 음성을 "진짜"라고 잘못 판단하면, 이 판단 오류에 대해 큰 벌칙(손실)을 받는다.
3. Generator와 Discriminator의 경쟁 및 학습
- Discriminator의 훈련: Discriminator는 실제 음성을 진짜로, Generator가 만든 음성을 가짜로 정확하게 구별하는 능력을 키운다.
- Generator의 훈련: Generator는 Discriminator를 속여 자신이 만든 음성이 '김철수'의 '행복한' 감정을 담은 "진짜" 음성이라고 믿게 만들려고 노력한다. 즉, Discriminator가 진짜라고 판단하는 음성을 만들 수록 Generator는 보상(낮은 손실)을 받는다.
4. 이중 조건부의 역할 강조
손실 함수를 다시 보면, 는 '화자'와 '감정'이라는 두 가지 조건이 모두 고려된다는 것을 의미한다.
- 화자 조건: Discriminator는 생성된 음성이 특정 화자()의 목소리 특징(음색, 톤 등)을 얼마나 잘 모방했는지 평가한다.
- 감정 조건: Discriminator는 생성된 음성이 특정 감정()의 특징(피치, 강도, 속도 변화 등)을 얼마나 잘 표현했는지 평가한다.
이 두 가지 조건이 독립적으로 또는 결합하여 판별 과정에 반영되므로, Generator는 음성을 합성할 때 화자 고유의 특성과 감정적인 표현력을 동시에 최적화하도록 학습된다.
결론적으로, 이중 조건부 적대적 학습은:
- Generator가 텍스트, 화자, 감정 세 가지 정보를 바탕으로 음성을 생성한다.
- Discriminator는 실제 음성과 생성된 음성을 구별할 때, 화자 특징과 감정 특징이라는 두 가지 조건을 모두 고려하여 판별한다.
- 이 경쟁 과정을 통해 Generator는 궁극적으로 주어진 텍스트에 대해 원하는 화자의 목소리로 원하는 감정을 표현하는 고품질의 자연스러운 음성을 합성하는 능력을 갖추게 된다.
이 방식은 단순히 감정이나 화자 중 하나만 고려하는 것보다 훨씬 더 미묘하고 복잡한 음성 표현을 가능하게 한다.
2.4 전체 아키텍처
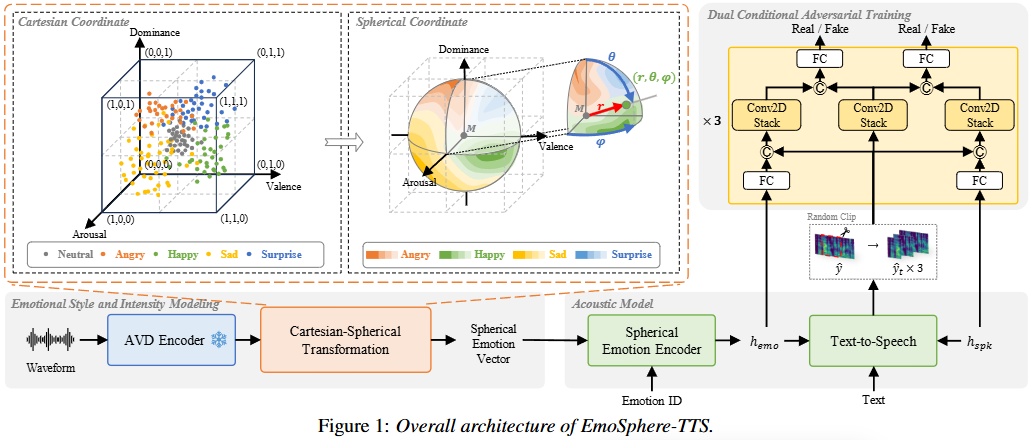
위의 설명과 수식을 아울러 EmoSphere-TTS의 전체 아키텍처를 다시 한 번 서술한다.
-
Emotional Style and Intensity Modeling (감정 스타일 및 강도 모델링)
- AVD Encoder (AVD 인코더)
- 음성 웨이브폼(Waveform)을 입력으로 받아 Arousal, Valence, Dominance (AVD)라는 세 가지 감정 차원에 대한 의사(pseudo) 레이블을 추출한다. 이 의사 레이블은 wav2vec 2.0 기반의 음성 감정 인식(SER) 모델 [9]을 통해 얻어지며, 각 (Arousal), (Valence), (Dominance)는 카르테시안 좌표계에서 0과 1 사이의 값을 가진다.
- Cartesian-Spherical Transformation (카르테시안-구형 좌표 변환)
- AVD 인코더에서 얻은 카르테시안 AVD 의사 레이블을 구형 좌표계로 변환하여 감정의 복잡한 특성을 모델링한다.
- 이 변환의 핵심 아이디어는 감정의 강도(intensity)는 중립 감정 중심에서 멀어질수록 증가하며, 감정의 스타일(style)은 중립 감정 중심으로부터의 각도에 의해 결정된다는 것이다.
- 중립 감정 중심 설정: 먼저 중립 감정 중심 을 원점으로 설정하여 카르테시안 좌표 를 얻는다.
여기서 이다.- : 번째 감정의 번째 의사 레이블 에서 중립 감정 중심 을 뺀 변환된 카르테시안 좌표이다.
- : 번째 감정의 번째 AVD 의사 레이블 ()이다.
- : 개의 중립 감정 좌표 의 평균으로 계산된 중립 감정 중심이다.
- : 중립 좌표의 총 개수이다.
- 구형 좌표 변환: 변환된 카르테시안 좌표 를 구형 좌표 로 변환한다.
- 감정 강도 (): 중립 감정 중심으로부터의 방사형 거리(radial distance) 은 감정의 강도를 나타낸다.
- : 감정의 강도를 나타내는 방사형 거리이다.
- : 중립 감정 중심을 원점으로 설정한 후의 Arousal, Valence, Dominance 차원의 값이다.
- 감정 스타일 (): 방향 각도 와 는 감정의 스타일을 결정한다.
- : Z축(Dominance)으로부터의 극각(polar angle)으로 감정 스타일의 한 측면이다.
- : X축(Arousal)으로부터 XY 평면에서의 방위각(azimuthal angle)으로 감정 스타일의 다른 측면이다.
- : 중립 감정 중심을 원점으로 설정한 후의 Dominance, Valence, Arousal 차원의 값이다.
- : 위에서 계산된 방사형 거리이다.
- 감정 강도 (): 중립 감정 중심으로부터의 방사형 거리(radial distance) 은 감정의 강도를 나타낸다.
- 변환 후에는 방사형 거리 을 0에서 1 사이로 정규화하여 감정 강도를 스케일링한다. 또한, 방향 각도 와 를 8개의 팔분공간(octants)으로 양자화하여 감정 스타일을 세분화한다.
- 이 과정의 결과로 Spherical Emotion Vector (구형 감정 벡터)가 생성된다.
- AVD Encoder (AVD 인코더)
-
Acoustic Model (음향 모델)
-
Spherical Emotion Encoder (구형 감정 인코더)
- 생성된 구형 감정 벡터(Spherical Emotion Vector)를 감정 ID와 결합하여 감정 임베딩 를 생성한다.
-
- : 최종적으로 TTS 모델에 입력되는 구형 감정 임베딩이다.
- : Layer Normalization [3]을 나타낸다.
- : softplus 활성화 함수 [11]를 나타낸다.
- : 벡터를 연결(concatenate)하는 연산이다.
- : 감정 스타일 벡터(emotional style vector)의 Projection Layer 출력이다.
- : 감정 클래스 임베딩(emotion class embedding)의 Projection Layer 출력이다.
- : 감정 강도 벡터(emotional intensity vector)의 Projection Layer 출력이다.
-
Text-to-Speech (TTS) (텍스트-음성 변환)
-
FastSpeech 2의 아키텍처를 기반으로 하며, 텍스트, 감정 임베딩 , 그리고 화자 임베딩 를 입력으로 받아 멜-스펙트로그램(Mel-spectrogram) 를 생성한다.
-
화자 ID는 임베딩으로 매핑되어 다양한 화자 특성을 표현하며, 감정 및 화자 임베딩은 Variance Adaptor에 제공된다.
-
FastSpeech 2 기반 아키텍처: EmoSphere-TTS는 FastSpeech 2의 기존 아키텍처와 목적 함수를 유지한다. 이는 이미 검증된 고품질 TTS 모델을 기반으로 한다는 의미이다.
-
화자 ID 임베딩: 다양한 화자의 특성을 표현하기 위해 화자 ID는 임베딩 로 매핑된다. 이 는 각 화자 고유의 음색이나 발화 특징을 담고 있다.
-
임베딩 결합: 화자 임베딩 와 감정 임베딩 는 결합(concatenation)되어 variance adaptor(분산 어댑터)에 제공된다. variance adaptor는 음성의 길이, 피치, 에너지와 같은 운율(prosody) 특성을 조절하는 역할을 한다. 이처럼 화자와 감정 정보를 함께 제공함으로써, 모델은 특정 화자가 특정 감정을 표현할 때 나타나는 미묘한 운율 변화를 더 잘 학습할 수 있다.
-
추론(Inference) 시 제어: 모델이 훈련된 후, 음성 합성(inference) 단계에서는 사용자가 수동으로 감정 스타일 및 강도 벡터를 조작하여 원하는 감정 표현을 생성할 수 있다. 예를 들어, 특정 감정의 강도를 '약함'에서 '강함'으로 바꾸거나, '화남'과 '슬픔' 사이의 미묘한 감정 스타일을 조절하는 것이 가능하다.
-
구형 감정 벡터 공간의 역할: 구형 감정 벡터 공간에서 감정의 스타일과 강도를 조작함으로써, 모델은 복잡한 감정의 본질을 효율적으로 합성하고 합성된 음성에서 다양한 감정 표현을 정밀하게 제어할 수 있다. 이는 이산적인 감정 레이블만 사용하는 기존 방식의 한계를 극복하는 핵심적인 부분이다.
-
-
-
Dual Conditional Adversarial Training (이중 조건부 적대적 학습)
-
생성된 음성의 품질과 표현력을 향상시키기 위해 적대적 학습(Adversarial Training)을 사용한다.
-
Discriminator (판별자): 여러 개의 CNN 기반 판별자로 구성되며, Conv2D Stack과 Fully Connected (FC) Layer로 이루어져 있다.
- 입력: TTS 모델에서 생성된 멜-스펙트로그램 의 랜덤 클립(Random Clip) 와 조건 임베딩(Condition Embedding)이다. 조건 임베딩은 화자(speaker) 및 감정(emotion) 특성을 반영하기 위해 사용된다.
- 하나의 Conv2D Stack은 멜 클립만 받지만, 다른 Conv2D Stack은 조건 임베딩()과 멜 클립을 결합하여 입력으로 받는다. 조건 임베딩은 멜 클립의 길이와 일치하도록 확장된다.
-
손실 함수: 판별자 와 생성자 의 손실 함수는 다음과 같다.
- : 판별자의 손실 함수이다. 실제()를 실제라고, 생성()을 가짜라고 정확하게 판별하도록 학습시킨다.
- : 생성자의 손실 함수이다. 생성된() 것을 실제라고 판별하도록 판별자를 속이는 방향으로 학습된다.
- : 실제(ground truth) 멜-스펙트로그램이다.
- : 생성된(generated) 멜-스펙트로그램이다.
- : 조건 유형(condition type)으로, 화자(speaker, ) 또는 감정(emotion, ) 임베딩을 나타낸다.
- : 기대값(expected value)을 나타낸다.
-
