EmoVIT (CVPR 2024)
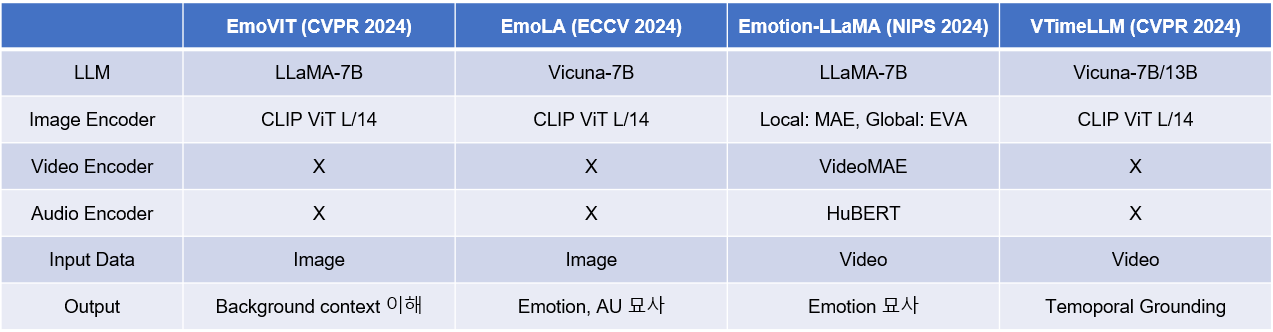
감정 시각 명령 데이터 생성 (Emotion Visual Instruction Data Generation)
이 섹션은 EmoVIT의 핵심적인 혁신 중 하나로, 시각 감정 인식 분야의 주석이 달린 명령 데이터 부족 문제를 해결하기 위해 GPT-4 [3]를 활용하여 명령 데이터를 자동 생성하는 파이프라인이다.
-
단계별 프로세스:
-
입력 이미지 (Input Image): 감정 명령 데이터를 생성할 원본 이미지가 입력된다.
-
GPT-4.0 활용: GPT-4 [3]는 이미지 관련 세 가지 주요 맥락 정보를 입력으로 받아 감정 명령 데이터를 생성한다.
-
캡션 (Caption): 이미지의 전반적인 내용을 설명하는 텍스트 캡션. BLIP2 [4] 모델로 생성.
- 예: "A baby is being lifted into the air by an adult on a sunny beach, smiling happily."
-
감정 속성 목록 (Emotion Attributes): 이미지에서 감정을 식별하는 데 중요한 시각적 단서들을 포함하는 속성 목록이다. 이는 다음과 같은 다중 레벨 속성을 통합한다.
- 로우 레벨 속성: 밝기(Brightness), 색상(Colorfulness).
- 미드 레벨 속성: 장면 유형(Scene type), 객체 클래스(Object class).
- 하이 레벨 속성: 얼굴 표정(Facial expression), 인간 행동(Human action).
-
시스템 프롬프트 (System Prompt): GPT-4 [3]가 특정 작업 요구 사항을 이해하도록 돕기 위해 설계된 지침이다.
- 예: "You are an expert in visual emotion analysis. Your task is to generate diverse and insightful instructions about the emotions depicted in an image, considering various visual attributes."
-
In-context Samples: GPT-4 [3]의 소수 학습(few-shot learning) 능력을 활용하기 위해 수동으로 설계된 몇 가지 예제들이다.
-
-
감정 명령 (Emotion Instruction) 생성: GPT-4 [3]는 위 정보들을 바탕으로 세 가지 유형의 명령 데이터를 생성한다.
-
범주형 (Categorical): 이미지의 관련 감정 클래스를 구조화된 형식으로 변환한 것으로, 감정 명령 데이터의 기본 구성 요소이다.
- Q: "What emotion is primarily conveyed in this image? Choose from [joy, sadness, anger, surprise, fear, disgust, contentment, neutral]."
A: "Contentment."
- Q: "What emotion is primarily conveyed in this image? Choose from [joy, sadness, anger, surprise, fear, disgust, contentment, neutral]."
-
대화형 (Conversation): GPT [3] 조수가 질문자와 대화하며 이미지의 감정 속성에 초점을 맞춘다.
-
기본 상호작용 (Basic Interaction): 제공된 감정 속성 목록에 초점을 맞춘 간단하고 직접적인 대화이다.
- Q: "Tell me about the facial expression in this image."
A: "The baby's facial expression shows contentment, suggesting happiness."
- Q: "Tell me about the facial expression in this image."
-
고급 상호작용 (Advanced Interaction): 기본 유형을 기반으로 더 복잡하고 정교한 대화이다.
- Q: "Can you elaborate on why the baby might be feeling contentment, considering the scene and action?"
A: "The baby is laughing and being lifted into the air at a sunny beach. The bright, colorful environment combined with the playful human action of being lifted likely contributes to a feeling of contentment and joy."
- Q: "Can you elaborate on why the baby might be feeling contentment, considering the scene and action?"
-
-
추론 (Reasoning): 단순한 질문-답변 형식을 넘어 복잡한 추론 질문을 생성하도록 모델에 요청한다. 이는 대화의 신뢰성과 구조를 향상하기 위해 논리적 추론 단계와 함께 상세한 예제를 포함한다.
-
Q: "Based on the visual cues, what specific elements in the image contribute most to the overall feeling of contentment, and how do they interact?"
A: "The high brightness and colorfulness of the sky and beach scene create a positive atmosphere. The facial expression of contentment and the action of laughing by the baby, combined with being playfully lifted by an adult, strongly indicate joy and contentment. These elements collectively suggest a happy and carefree moment, reinforcing the emotion."
-
-
-
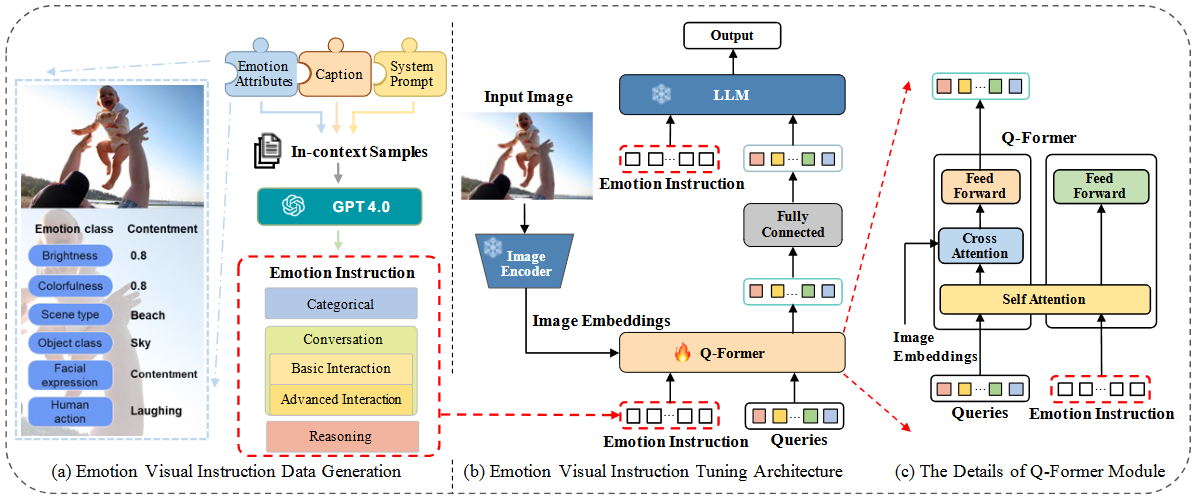
감정 시각 명령 튜닝 아키텍처 (Emotion Visual Instruction Tuning Architecture)
생성된 감정 시각 명령 데이터를 활용하여 기존의 시각 명령 튜닝 모델을 감정 이해 도메인에 맞게 개선하는 과정이다. 이 아키텍처는 InstructBLIP [8]을 기반으로 구축되었다.
-
입력 이미지 (Input Image) 처리:
-
이미지 인코더 (Image Encoder): 입력 이미지에서 시각적 특징을 추출한다. 이 이미지 인코더는 학습 중에 고정된 상태를 유지한다. ViT-G/14 혹은 ViT/L-14를 사용한다.
-
이미지 임베딩 (Image Embeddings): 이미지 인코더를 통해 추출된 시각적 특징이다.
-
-
Q-Former 모듈 (Q-Former Module): InstructBLIP [8]의 Instruction-aware Q-Former 모듈을 활용한다. 이 모듈은 감정 명령에 특화된 태스크 관련 특징 추출을 강화한다.
-
입력: 감정 명령(Emotion Instruction)과 쿼리(Queries), 그리고 이미지 임베딩(Image Embeddings)을 입력으로 받는다. 쿼리는 InstructBLIP [8]의 사전 학습된 Q-Former에서 생성된 학습 가능한 쿼리이다.
-
기능: 내부적으로 Self Attention 및 Cross Attention 레이어를 통해 감정 명령 및 쿼리 임베딩과 시각 정보를 통합한다. 이를 통해 LLM의 명령 수행 요구 사항에 맞춰 시각 정보를 정렬한다. Q-Former는 학습 가능한 부분으로, 이 논문에서 미세 조정된다.
-
-
LLM (Large Language Model): Q-Former를 통해 처리된 시각 정보를 받아 명령을 따른다. 이 LLM 또한 학습 중에 고정된 상태를 유지한다. FlanT5-XL, FlanT5-XXL, LLaMA-7B, LLaMA-13B 등 InstructBLIP의 기본 설정을 따른다.
-
출력 (Output): LLM이 명령에 따라 생성하는 최종 결과이다.
EmoLA (ECCV 2024)
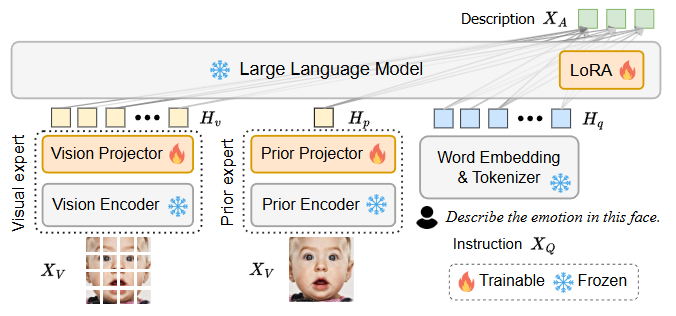
Vision Encoder (Visual Expert)
- 모델명: CLIP-L/14 [94]
- 스펙:
- 아키텍처: CLIP(Contrastive Language-Image Pre-training)은 이미지 인코더와 텍스트 인코더로 구성된 멀티모달 모델이다. 여기서 사용된 "L/14"는 CLIP 모델 중 Vision Transformer의 라지(Large) 버전을 의미하며, 패치 크기가 14x14픽셀임을 나타낸다.
- 사전 학습: CLIP은 대규모의 이미지-텍스트 쌍 데이터셋(예: 웹에서 수집된 4억 개의 이미지-텍스트 쌍)을 사용하여 이미지와 텍스트 임베딩이 서로 유사한 공간에 매핑되도록 대조 학습(contrastive learning) 방식으로 사전 학습되었다.
- 역할: FABA 태스크의 입력 이미지 로부터 일반적인 시각적 특징을 추출하여 시각 임베딩 토큰 를 생성한다. 이 토큰은 이미지의 내용과 관련된 고수준의 의미 정보를 포함한다.
- Fine-tuning 여부: EmoLA 아키텍처에서는 이 Vision Encoder의 파라미터는 고정(frozen)된 상태로 유지된다. 즉, 훈련 과정에서 가중치가 업데이트되지 않는다.
Prior Encoder (Facial Prior Expert Module)
- 모델명: Insightface [7]의 사전 학습된 Facial Landmark Detector
- 스펙:
- 아키텍처: 일반적으로 얼굴 랜드마크 디텍터는 이미지에서 눈, 코, 입 등의 특정 지점(랜드마크)의 위치를 감지하도록 설계된 CNN(Convolutional Neural Network) 기반의 모델이다. Insightface는 얼굴 인식 및 분석을 위한 다양한 모델과 데이터셋을 제공하는 오픈소스 프로젝트이다.
- 사전 학습: 얼굴 랜드마크 감지 태스크에 특화된 데이터셋(예: 랜드마크가 정밀하게 주석된 얼굴 이미지)으로 사전 학습되었다.
- 역할: 입력 얼굴 이미지 로부터 얼굴 랜드마크 특징과 같은 얼굴 구조 정보를 추출하여 선험 특징 를 생성한다. 이 특징은 CLIP Vision Encoder가 놓칠 수 있는 얼굴의 미세한 형태 변화에 대한 정보를 제공한다.
- Fine-tuning 여부: 이 Prior Encoder 의 파라미터 또한 EmoLA 아키텍처에서는 고정(frozen)된 상태로 유지된다. 추출된 는 별도의 Prior Projector 를 통해 LLM이 이해할 수 있는 토큰 임베딩 공간으로 투영된다.
Word Embedding & Tokenizer (Language Expert)
- 모델명: Vicuna [15] LLM에 내장된 Tokenizer 및 Word Embedding
- 스펙:
- Tokenizer: Vicuna는 일반적으로 SentencePiece와 같은 바이트 쌍 인코딩(BPE) 기반의 토크나이저를 사용하여 텍스트를 서브워드(subword) 단위의 토큰 시퀀스로 분할한다. 이는 OOV(Out-Of-Vocabulary) 문제를 줄이고 다양한 언어 표현을 처리할 수 있게 한다.
- Word Embedding: 토크나이저를 통해 생성된 각 토큰은 임베딩 레이어를 거쳐 고차원 벡터 공간에 매핑된다. 이 임베딩 벡터는 토큰의 의미론적 정보를 담고 있으며, LLM의 입력으로 사용된다.
- 역할: 입력 Instruction 를 토큰화하고, 각 토큰을 임베딩하여 언어 임베딩 토큰 를 생성한다.
- Fine-tuning 여부: 이 Word Embedding 및 Tokenizer의 파라미터는 EmoLA 아키텍처에서 고정(frozen)된 상태로 유지된다.
Large Language Model (LLM Decoder)
- 모델명: Vicuna [15] (LLaVA-1.5 [70]의 백본 LLM)
- 스펙:
- 아키텍처: LLaMA를 기반으로 한 트랜스포머(Transformer) 디코더 온리(decoder-only) 아키텍처이다. 트랜스포머는 자기 주의(self-attention) 메커니즘을 사용하여 입력 시퀀스의 토큰들 간의 관계를 학습하고 다음 토큰을 예측하는 데 특화되어 있다.
- 사전 학습: Vicuna는 LLaMA 모델을 대규모의 대화 데이터셋(예: ShareGPT 데이터셋)으로 미세 조정하여 대화 및 지시 이행 능력을 강화한 모델이다. 논문에서는 LLaVA-1.5 7b(70억 개 파라미터) 모델을 기반으로 한다고 명시되어 있다.
- 역할: Visual Embedding Token , Facial Prior Token , Language Embedding Token 를 입력받아 이를 바탕으로 FABA 태스크에 대한 자연어 설명 를 auto-regressive 방식으로 생성한다.
- Fine-tuning 여부: Vicuna LLM 디코더의 대부분 파라미터는 고정(frozen)된 상태로 유지된다. 대신, LLM 내부에 Low-Rank Adaptation (LoRA) 모듈 이 추가되어 이 LoRA 모듈의 파라미터만 튜닝된다. 이는 효율적인 훈련과 계산 비용 절감을 위한 핵심 전략이다.
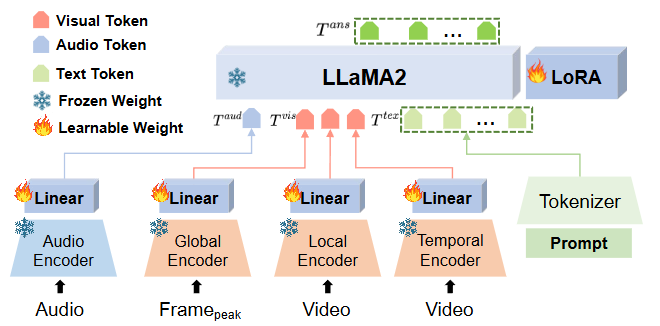
Emotion-LLaMA (NIPS 2024)
-
Audio Encoder (오디오 인코더):
- 모델: HuBERT (HuBERT: Self-Supervised Speech Representation Learning by Masked Prediction of Hidden Units)
- 역할: 오디오 신호에서 음색, 음조와 같은 청각적 감정 단서를 추출한다. HuBERT는 대규모 비라벨 음성 데이터로 사전 학습되어 음성 표현 학습에서 뛰어난 성능을 보인다. 텍스트 정보만으로는 파악하기 어려운 감정의 미묘한 뉘앙스(예: 비꼬는 어조, 망설임)를 포착하는 데 필수적이다.
- 스펙: 이 논문에서는 "HuBERT-Chinese large model"을 사용했다고 명시되어 있다. HuBERT 모델은 일반적으로 인코더-디코더 Transformer 구조를 가지며, 마스크된 음성 유닛 예측을 통해 자기 지도 학습(self-supervised learning) 방식으로 훈련된다. "large" 모델은 일반적으로 더 많은 파라미터와 레이어를 포함하여 더 풍부한 표현을 학습한다. 이 모델의 가중치는 Frozen Weight(동결) 상태로 유지되어, 사전 학습된 강력한 음성 표현 학습 능력을 그대로 활용한다.
-
Global Encoder (전역 인코더):
-
모델: EVA (EVA: Exploring the Limits of Masked Visual Representation Learning at Scale)
-
역할: 비디오의 'peak emotional expression frame'(감정 표현 절정 프레임)에서 얼굴 표정뿐만 아니라 배경 문맥을 포함한 전역적인 시각적 특징을 포착한다.
-
스펙: ViT(Vision Transformer) 구조를 기반으로 하며, MAE(Masked AutoEncoder) 방식으로 대규모 이미지 데이터셋에 사전 학습된 모델이다. 이 논문에서는 입력 이미지 크기가 448x448 픽셀인 EVA 모델을 사용한다. 이 모델의 가중치 또한 Frozen Weight(동결) 상태로 유지되어, 광범위한 시각적 이해 능력을 활용하면서 특정 감정 학습에 집중하도록 한다.
-
-
Local Encoder (지역 인코더):
- 모델: MAE (Masked Autoencoders Are Scalable Vision Learners)
- 역할: 비디오의 얼굴 시퀀스에서 정적인 얼굴 표정 특징을 추출한다. 얼굴의 미세한 움직임과 표정 변화에 집중하여 감정 단서를 포착한다.
- 스펙: 역시 ViT 구조를 기반으로 하며, MAE(Masked AutoEncoder) 방식으로 사전 학습된 모델이다. 얼굴 영역을 크롭하고 정렬한 후, 16개의 얼굴 이미지를 입력으로 받아 프레임별 특징을 추출하고 평균 풀링(average pooling)을 통해 지역 시각 특징을 생성한다. 이 모델의 가중치는 Frozen Weight(동결) 상태로 유지된다.
-
Temporal Encoder (시간 인코더):
-
모델: VideoMAE (VideoMAE: Masked Autoencoders Are Data-Efficient Learners for Self-Supervised Video Pre-Training)
-
역할: 얼굴 시퀀스의 시간적 동역학(temporal dynamics)을 학습하여 얼굴 움직임의 시간적 변화, 즉 동적인 감정 상태 변화를 포착한다. 이는 감정의 흐름이나 강도 변화를 이해하는 데 중요하다.
-
스펙: VideoMAE는 비디오 데이터를 위한 MAE 모델의 확장 버전이다. 마스크된 비디오 프레임을 예측하는 방식으로 자기 지도 학습을 수행한다. 이 논문에서는 얼굴 영역을 크롭하고 정렬한 후, 16개의 얼굴 이미지를 입력으로 받아 시간적 특징을 생성한다. 이 모델의 가중치 또한 Frozen Weight(동결) 상태로 유지된다.
-
-
Tokenizer (토크나이저):
-
모델: LLaMA 토크나이저 (Llama 2: Open Foundation and Fine-tuned Chat Models)
-
역할: 텍스트 프롬프트()를 LLaMA 모델이 처리할 수 있는 토큰 시퀀스()로 변환한다. 이는 대규모 언어 모델이 텍스트를 이해하고 처리하는 데 필수적인 단계이다.
-
스펙: SentencePiece (Sentencepiece: A simple and language independent subword tokenizer and detokenizer for neural text processing) 기반의 BPE(Byte-Pair Encoding) 모델을 사용한다. BPE는 자주 나타나는 문자열 쌍을 하나의 새로운 토큰으로 병합하여 어휘 크기를 효율적으로 관리하고 희귀 단어를 처리하는 데 강점을 보인다. 이를 통해 오픈 보캐뷸러리(open vocabulary) 문제를 해결하고 효율적인 텍스트 처리를 가능하게 한다.
-
-
LLaMA2 (대규모 언어 모델):
-
모델: LLaMA2-chat (7B) (Llama 2: Open Foundation and Fine-tuned Chat Models)
-
역할: 각 인코더를 통해 변환된 오디오 토큰, 시각 토큰, 그리고 텍스트 토큰을 통합하여 감정 인식 및 추론을 수행하는 핵심 언어 모델이다. 다중 모달 정보를 기반으로 질의응답, 설명 생성 등 다양한 감정 관련 작업을 처리한다.
-
스펙: LLaMA2는 Meta에서 개발한 대규모 언어 모델로, "7B"는 약 70억 개의 파라미터를 가진 모델임을 의미한다. Transformer 아키텍처를 기반으로 하며, 대규모 텍스트 데이터에 사전 학습되어 강력한 언어 이해 및 생성 능력을 가지고 있다. Emotion-LLaMA에서는 LLaMA2의 주요 가중치는 Frozen Weight(동결) 상태로 유지된다. 이는 사전 학습된 언어 지식을 보존하면서, LoRA(LLaMA-Adapter: Efficient Fine-tuning of Language Models with Zero-init Attention)를 통해 감정 관련 특정 지식을 효율적으로 학습하도록 한다. LoRA는 LLaMA2 모델 내의 쿼리() 및 값() 투영 행렬을 미세 조정하며, 이때 낮은 랭크의 행렬()을 사용하여 학습 가능한 파라미터 수를 최소화한다. 이 논문에서는 전체 파라미터의 0.495%에 해당하는 3천 4백만 개의 파라미터만 학습시킨다.
-