Arxiv: https://arxiv.org/pdf/2502.00654v1
Awesome: https://github.com/Kedreamix/Awesome-Talking-Head-Synthesis?utm_source=chatgpt.com

-
배경 및 필요성:
- 감정 다양성 부족: 기존 3D Gaussian Splatting 기반의 Talking Head 모델들은 주로 짧은 비디오 데이터셋으로 학습되므로, '기쁨', '슬픔', '화남' 등과 같은 연속적이고 다양한 감정을 표현하는 데 어려움이 있다.
- EmoStyle의 한계: EmoStyle [4]과 같은 기존 감정 조절 모델은 입력 이미지의 감정을 밸런스(Valence) 및 어라우절(Arousal) 값에 따라 변경할 수 있지만, 이때 입술 모양이 원본 오디오에 맞춰 정렬되지 않고 감정에 과도하게 맞춰 변형되는 문제가 발생한다. 이는 립 싱크(lip-sync) 불일치로 이어진다.
-
Lip-aligned Emotional Face Generator () 구조:
이 문제를 해결하기 위해, 이 논문은 Lip-aligned Emotional Face Generator ()를 제안한다. 이 생성기는 EmoStyle [4] 프레임워크를 기반으로 하되, 원본 이미지의 입술 랜드마크를 추가 조건으로 활용하여 생성된 이미지의 입술 모양이 원본과 정확히 일치하도록 보장한다.- 입력:
- 원본 이미지 (): 감정을 조절할 대상이 되는 얼굴 이미지이다.
- 밸런스 및 어라우절 값 (): 생성하고자 하는 감정의 연속적인 척도이다 (예: 기쁨, 슬픔, 놀람 등을 나타내는 특정 값).
- 내부 구성 요소 및 흐름:
- EmoStyle 기반 초기화: EmoStyle [4]은 원본 이미지 로부터 잠재 코드 를 생성하고, 여기에 밸런스/어라우절 로부터 파생된 감정 수정 벡터 를 더하여 감정 잠재 코드 를 생성한다.
- Lip Detector () [7]: 원본 이미지 에서 입술 랜드마크를 추출하여 입술 히트맵(heatmaps) 를 생성한다.
- 2D Convolutional Encoder (E): 입술 히트맵 를 처리하여 입술 임베딩 벡터()를 생성한다.
- LipExtract Module (): 입술 임베딩 벡터 과 감정 잠재 코드 를 연결한(concatenation) 입력을 받아, 입술 수정 벡터()를 출력한다.
- 최종 잠재 코드 생성: 입술 수정 벡터 을 감정 잠재 코드 에 더하여 최종적으로 입술 정렬 감정 잠재 코드()를 얻는다 ().
- StyleGAN2 [29]: 이 최종 잠재 코드 를 사용하여 입술이 정렬된 감정 표현 이미지()를 생성한다.
- 학습 손실 함수: 는 다음과 같은 여러 손실 함수를 조합하여 학습된다.
- 입술 랜드마크 손실 (): 생성 이미지의 입술 랜드마크와 원본 이미지의 입술 랜드마크 간의 L2 거리 차이를 최소화하여 입술 위치 및 모양의 정확한 정렬을 유도한다.
- 입술 픽셀 손실 (): 입술 영역 마스크()를 적용하여 생성 이미지의 입술 픽셀과 원본 이미지의 입술 픽셀 간의 L2 거리 차이를 최소화한다.
- 정규화 손실 (): 입술 수정 벡터 의 크기를 제한하여 발산을 방지한다.
- 감정 손실 (): EmoNet [61]을 사용하여 생성 이미지에서 추출된 밸런스/어라우절 값이 목표 감정 값과 일치하도록 유도한다.
- 정체성 손실 (): VggFace2 [8]를 사용하여 생성 이미지의 얼굴 정체성 임베딩이 원본 이미지의 정체성을 유지하도록 보장한다.
- 입력:
-
Seamless Cloning 후처리:
가 생성한 초기 감정 이미지()는 원본 이미지와의 도메인 갭(domain gap)이 존재할 수 있다 (예: 흐릿한 머리카락, 피부 질감의 불규칙성). 또한, 를 단순히 원본 이미지에 잘라 붙이면 경계면에 아티팩트(artifacts)가 발생할 수 있다. 이 문제를 해결하기 위해 Seamless Cloning [49] 기법을 사용한다.- 과정: 로 생성된 이미지 에서 감정 표현이 풍부한 눈과 입 주변의 사각형 영역을 잘라내어 원본 이미지 에 붙여 넣는다. 이때 단순 잘라 붙이기가 아닌 Seamless Cloning을 적용하여 질감과 색상을 자연스럽게 혼합함으로써 경계면 아티팩트를 제거하고 사실적인 합성을 이룬다.
- 결과: 이렇게 생성된 고품질의 현실적인 합성 감정 이미지가 "emotional synthetic data"가 되어 EmoTalkingGaussian 모델의 학습에 활용된다.
Training
Optimizing Canonical Gaussians
이 섹션은 EmoTalkingGaussian 모델에서 입 안쪽(inside-mouth)과 얼굴(face) 영역의 Canonical Gaussians를 최적화하는 방법을 설명합니다. Canonical Gaussians는 3D 장면의 초기 기하학적 구조를 나타내는 기본적인 3D 가우시안 집합을 의미합니다. 이들은 모델이 동적인 움직임을 표현하기 위한 기준점이 됩니다.
최적화 과정은 다음과 같은 손실 함수들을 사용하여 진행됩니다.
-
RGB 손실 ():
- 이 손실은 렌더링된 이미지의 시각적 품질을 향상시키기 위해 사용됩니다.
- 수식은 다음과 같습니다:
- :
inside-mouth또는face영역의Canonical Gaussians( 또는 )로부터 렌더링된 이미지를 나타냅니다. - :
inside-mouth또는face영역에 해당하는 마스크된 실제(ground truth) 이미지를 의미합니다. 이 마스크는 원본 이미지 에서 TalkingGaussian을 따라 추출됩니다. - : 렌더링된 이미지와 실제 이미지 간의 픽셀 단위 차이를 측정하는
L1 loss입니다. - : 이미지의 구조적 유사성을 측정하는
D-SSIM loss입니다. - : 두 손실 항의 가중치를 조절하는 하이퍼파라미터입니다.
- 이 손실을 통해 렌더링된
Canonical Gaussians가 실제 이미지와 픽셀 및 구조적으로 유사해지도록 합니다.
-
노멀 맵 손실 ():
- 이 손실은 얼굴 영역(
face region)의Canonical Gaussians()에 대해 추가적으로 적용됩니다. 이는 렌더링된 노멀 맵의 품질을 개선하고, 3D 가우시안의 위치()와 노멀 잔차()를 업데이트하는 데 사용됩니다. - 수식은 다음과 같습니다:
- : 3D
Gaussians로부터 렌더링된 노멀 맵을 나타냅니다. - : 마스크된 실제 노멀 맵입니다.
- : 렌더링된 노멀 맵과 실제 노멀 맵 간의 픽셀 단위 차이를 측정하는
L1 loss입니다. - : 렌더링된 노멀 맵의 공간적 부드러움(
spatial smoothness)을 강화하기 위한total variation loss입니다. - :
노멀 잔차이 발산하는 것을 방지하기 위한 정규화 손실(regularization loss)입니다. - : 각 손실 항의 가중치를 조절하는 하이퍼파라미터입니다.
- 이 손실을 통해 얼굴의 3D 형태를 더 정확하게 표현하고, 렌더링된 노멀 맵이 실제 노멀 맵과 일치하도록 합니다.
- 이 손실은 얼굴 영역(
-
의 생성 방법:
- 마스크 추출: 먼저 원본 이미지 에서 얼굴 영역에 해당하는 마스크가 추출됩니다. 이 마스크는 BiSeNet [68]과 Teeth parser [37]를 사용하여 얻어지며, 특히 얼굴 영역(
face region)을 구분하는 "파란색 영역"의 마스크가 사용됩니다. (더 자세한 내용은Supplementary Material의Sec. S4.2 Processing Mask참조) - 노멀 맵 생성: 추출된 얼굴 마스크와 함께
normal estimatorCross-modal Deep Face Normals를 사용하여 원본 이미지의 노멀 맵이 생성됩니다. 노멀 맵은 이미지의 각 픽셀에 대한 표면의 방향(법선 벡터)을 인코딩하는 이미지로, 3D 형태 정보를 담고 있습니다. - 마스킹: 생성된 노멀 맵에 앞서 추출된 얼굴 마스크를 적용하여, 얼굴 영역에 해당하는 노멀 맵()만 남깁니다. 이렇게 얻어진 는 모델 학습 시 실제 값(
ground truth)으로 사용됩니다.
- 마스크 추출: 먼저 원본 이미지 에서 얼굴 영역에 해당하는 마스크가 추출됩니다. 이 마스크는 BiSeNet [68]과 Teeth parser [37]를 사용하여 얻어지며, 특히 얼굴 영역(
-
(Total Variation Loss)의 계산 방법:
-
Total Variation Loss는 이미지의 공간적 부드러움(spatial smoothness)을 강제하기 위해 사용됩니다. 즉, 이미지에서 인접한 픽셀 간의 급격한 변화를 줄여 노이즈를 제거하거나 자연스러운 경계를 생성하는 데 도움을 줍니다. -
이 논문에서는 에 대한 구체적인 수식은 제공하고 있지 않지만, 일반적으로 다음과 같이 계산됩니다. 이미지 에 대한
Total Variation Loss는 보통 각 픽셀의 가로 및 세로 방향 이웃 픽셀과의 강도 변화의 절댓값 합으로 정의됩니다. -
수식:
- : 노멀 맵 와 같이 손실을 적용할 렌더링된 이미지를 나타냅니다.
- : 이미지 내 픽셀의 좌표를 나타냅니다.
- : 가로 방향으로 인접한 픽셀 간의 차이의 절댓값입니다.
- : 세로 방향으로 인접한 픽셀 간의 차이의 절댓값입니다.
- 이 수식은 이미지 전체의 모든 픽셀에 대해 가로 및 세로 방향으로 인접한 픽셀 값의 차이의 절댓값을 합산하여 계산됩니다.
-
목적:
는 렌더링된 노멀 맵이 너무 거칠거나 노이즈가 많지 않고, 부드럽고 자연스러운 표면을 표현할 수 있도록 돕습니다. 이는 특히 3D 형태를 추정하거나 생성할 때 중요한 요소입니다.
-
Training Networks for Inside-Mouth and Face Regions
이 섹션은 EmoTalkingGaussian 모델의 내부 입 영역(inside-mouth region)과 얼굴 영역(face region)을 담당하는 네트워크, 즉 tri-plane hash encoder (, )와 manipulation network (, )를 훈련하는 방법에 대해 설명합니다.
-
훈련 대상 네트워크:
Tri-plane hash encoder H: 3D 가우시안의 변형을 제어하는 오프셋을 계산하기 위해 사용되는 인코더입니다.inside-mouth를 위한 과face를 위한 가 있습니다.Manipulation network f:inside-mouth를 위한 과face를 위한 가 있으며, 이 네트워크들은 입력 오디오 기능(audio features a)과action units u를 기반으로 가우시안의 위치, 스케일링, 회전 오프셋을 추정합니다.
-
손실 함수 (
Loss Function L): 이 네트워크들은 다음 세 가지 손실의 합으로 구성된 손실 함수를 사용하여 훈련됩니다. -
각 손실 함수의 상세 설명:
-
(RGB 손실):
- 목적: 렌더링된 이미지의 시각적 품질을 평가하고, 모델이 실제 이미지에 가깝게 렌더링하도록 유도합니다.
- 구성:
- : 렌더링된 이미지 ()와 마스크된 실제 이미지 () 간의 픽셀 단위 차이를 측정하는 L1 손실입니다.
- : 이미지의 구조적 유사성을 측정하는 D-SSIM 손실입니다.
- : 렌더링된 이미지와 실제 이미지 간의 지각적 유사성을 측정하는 LPIPS 손실입니다. 인간의 시각 시스템이 인지하는 방식으로 이미지 품질을 평가합니다.
- : 내부 입 변형 가우시안() 또는 얼굴 변형 가우시안()에서 렌더링된 RGB 이미지입니다.
- : 마스크된 실제 이미지 데이터입니다.
- , : 각 손실 항의 중요도를 조절하는 가중치입니다.
-
(노말 맵 손실):
- 목적: 렌더링된 노말 맵의 품질을 향상시키고, 얼굴 영역의 지오메트리 디테일을 보존합니다.
- 구성:
- : 렌더링된 노말 맵 ()과 마스크된 실제 노말 맵 () 간의 L1 손실입니다.
- :
Total Variation loss로, 렌더링된 노말 맵의 공간적 부드러움(spatial smoothness)을 강제합니다. - : 노말 잔차(
normal residual) 에 대한 정규화(regularization) 항으로, 이 과도하게 발산하는 것을 방지합니다. - : 얼굴 변형 가우시안()에서 렌더링된 노말 맵입니다.
- : [3]에서 예측된 마스크된 실제 노말 맵입니다.
- , , : 각 손실 항의 중요도를 조절하는 가중치입니다.
-
(싱크 손실):
- 목적: 렌더링된 이미지의 립 움직임이 입력 오디오와 정확하게 동기화되도록 합니다.
- 구성:
- 및 :
SyncNet의 이미지 인코더와 오디오 인코더입니다. - : 오디오 입력입니다.
- : EmoTalkingGaussian에 의해 렌더링된 이미지로, 에 따라 조건화됩니다.
- 이 손실은 원본 오디오 데이터와
text-to-speech network를 통해 합성된 오디오 데이터를 모두 활용하여 립 싱크 정확도를 향상시킵니다.
- 및 :
-
Training Network for Emotion
감정 브랜치는 Valence와 Arousal 값에 따라 얼굴의 연속적인 감정 표현을 조작하도록 훈련됩니다. 이는 이미 오디오와 액션 유닛(AUs)에 의해 변형된 얼굴에 추가적으로 감정 변형을 적용하는 것이 특징입니다. 감정 브랜치 훈련에도 위와 동일한 함수가 사용됩니다.
-
(RGB 손실)
- 는 감정 브랜치 에 의해 렌더링된 감정 얼굴 이미지이며, 는 합성된 감정 얼굴 이미지의 마스킹된 실제(ground truth) RGB 이미지입니다.
- 이 손실은 렌더링된 이미지가 원하는 감정 표현을 정확히 반영하고 시각적 품질을 유지하도록 돕습니다.
-
(Normal Map 손실)
- 는 감정 브랜치 에 의해 렌더링된 노멀 맵이며, 는 합성된 감정 얼굴 이미지에서 추출된 마스킹된 실제 노멀 맵입니다.
- 이 손실은 렌더링된 얼굴의 3D 표면 기하학적 구조가 실제와 일치하도록 보장하며, 감정 표현 시 얼굴 형태의 왜곡을 최소화하는 데 기여합니다.
-
(동기화 손실)
- 는 오디오와 렌더링된 이미지() 간의 립 싱크 정확도를 강화합니다. 원본 및 합성 오디오 데이터를 모두 사용하여 모델의 일반화 능력을 향상시킵니다.
Experiments
Setup
-
데이터셋 (Dataset):
- 공개적으로 사용 가능한 비디오 데이터셋을 활용하며, 주로 Ad-NeRF, ER-NeRF, GeneFace와 같은 이전 연구들의 설정 TalkingGaussian을 따른다.
- 'Macron', 'Obama', 'Lieu', 'May' 4명의 인물을 포함하며, 각 비디오는 얼굴이 중앙에 오도록 잘리고 크기가 조정된다.
- 평균 비디오 길이는 25 FPS에서 6,500 프레임(약 4분 20초)이며, 해상도는 512x512 픽셀이다 ('Obama' 비디오는 450x450 픽셀).
- 각 비디오는 학습(train) 세트와 테스트(test) 세트로 10:1 비율로 분할된다.
-
베이스라인 (Baselines):
- 본 연구의 방법론은 NeRF 기반 접근 방식인 ER-NeRF와 3DGS(3D Gaussian Splatting) 기반 접근 방식인 GaussianTalker 및 TalkingGaussian과 비교된다.
- 이러한 베이스라인 방법들은 눈 깜박임과 같은 기본적인 표정만 처리할 수 있으며, 연속적인 감정 조작은 불가능하다는 한계가 있다.
- 학습에 대규모 데이터셋이 필요한 2D 기반의 Talking Head 생성 방법들은 비교 대상에서 제외되었다.
Quantitative Results
Self-reconstruction
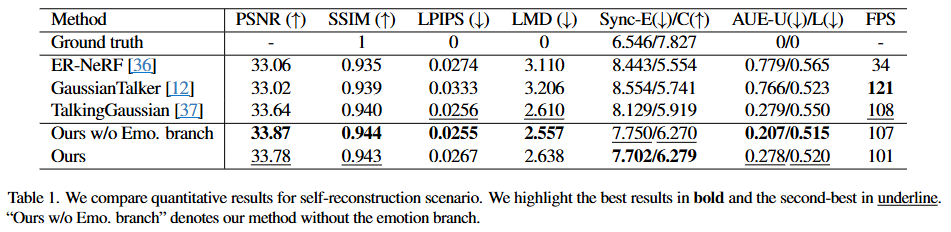
모델이 학습에 사용된 테스트 셋의 오디오, 액션 유닛(Action Units), 밸런스(Valence)/어라우절(Arousal) 값을 사용하여 얼마나 원본에 가깝게 이미지를 재구성하는지 평가한다. 이는 모델의 기본 재구성 능력을 측정하는 시나리오이다.
-
평가 지표:
- PSNR (Peak Signal-to-Noise Ratio, ↑): 생성된 이미지의 화질을 평가하는 지표이다. 원본 이미지와 비교하여 픽셀 값의 오차를 측정하며, 값이 높을수록 원본에 가깝고 화질이 좋다는 것을 의미한다.
- SSIM (Structural Similarity Index Measure, ↑): 이미지의 구조적 유사성을 평가하는 지표이다. 밝기, 대비, 구조의 세 가지 요소를 고려하여 원본 이미지와의 유사도를 측정하며, 값이 높을수록 시각적으로 더 유사하다는 것을 의미한다.
- LPIPS (Learned Perceptual Image Patch Similarity, ↓): 인공 신경망을 사용하여 인간의 지각적 유사성을 더 잘 반영하도록 학습된 이미지 품질 평가 지표이다. 값이 낮을수록 두 이미지가 인간의 눈으로 보기에 더 유사하다는 것을 의미한다.
- LMD (Mouth Landmark Distance, ↓): 생성된 얼굴의 입술 랜드마크와 실제 입술 랜드마크 사이의 평균 거리를 나타낸다. 립 싱크(lip synchronization) 정확도를 측정하며, 값이 낮을수록 입술 움직임이 입력 오디오에 더 정확하게 동기화된다는 것을 의미한다.
- Sync-E (Synchronization Error, ↓) / Sync-C (Synchronization Confidence, ↑): SyncNet [14]을 사용하여 오디오와 비디오 간의 동기화 정도를 평가하는 지표이다. Sync-E는 동기화 오류를, Sync-C는 동기화 신뢰도를 나타낸다. Sync-E는 낮을수록, Sync-C는 높을수록 동기화가 잘 되었음을 의미한다.
- AUE-U (Upper-face Action Unit Error, ↓) / AUE-L (Lower-face Action Unit Error, ↓): OpenFace [6]를 사용하여 생성된 얼굴의 액션 유닛(Action Units, AU)이 원본의 AU와 얼마나 일치하는지를 측정한다. AUE-U는 상부 얼굴(눈썹, 눈)의 AU 오류를, AUE-L은 하부 얼굴(입)의 AU 오류를 나타낸다. 두 값 모두 낮을수록 표정 일관성이 높다는 것을 의미한다.
- FPS (Frames Per Second): 모델이 초당 렌더링할 수 있는 프레임 수를 나타내며, 실시간 처리 속도를 측정하는 지표이다. 값이 높을수록 렌더링 속도가 빠르다는 것을 의미한다.
-
결과 분석:
-
"Ground truth": 이는 실제 원본 영상의 지표로, 모든 모델이 목표로 하는 이상적인 성능의 기준점이다.
-
"Ours w/o Emo. branch" (감정 브랜치 없는 본 연구 모델):
- 이 모델은 감정 브랜치를 제외한 본 연구의 기본 모델로, PSNR, SSIM, LPIPS, LMD, AUE-U/L 등 대부분의 화질 및 동기화, 표정 일관성 지표에서 가장 우수한 성능을 보여준다. 이는 감정 표현 조작 기능 없이 순수하게 화질과 립 싱크에 집중할 경우, 이 모델이 기존 최첨단 모델인 TalkingGaussian [37]을 능가함을 의미한다.
-
"Ours" (완전한 본 연구 모델):
- 감정 브랜치를 포함한 EmoTalkingGaussian의 완전한 모델이다. 해당 모델은 원래 데이터 뿐만 아니라 제안된 emotional synthetic data를 추가로 학습하였기 때문에 정확도가 약간 낮아질 수 있다.
- "Ours w/o Emo. branch"에 비해 PSNR, LPIPS, LMD 등의 화질 및 립 랜드마크 거리 지표에서 약간의 성능 저하가 있지만, 여전히 TalkingGaussian [37]과 유사하거나 더 나은 성능을 보인다. 특히 Sync-E/C에서는 "Ours w/o Emo. branch"와 함께 기존 모델들보다 확실히 우수한 립 싱크 정확도를 보여준다.
- AUE-L에서도 "Ours w/o Emo. branch" 다음으로 좋은 성능을 보이며, 이는 하부 얼굴 표정의 일관성을 잘 유지함을 나타낸다. 이러한 결과는 감정 표현의 다양성을 추가했음에도 불구하고, 여전히 높은 이미지 품질과 뛰어난 립 싱크 정확도를 유지함을 시사한다.
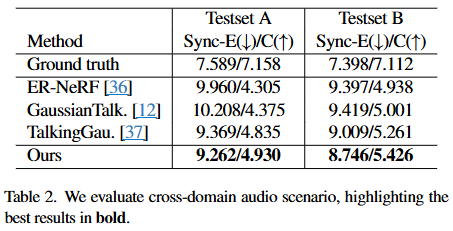
Cross-domain audio
이 시나리오는 모델이 훈련 시에는 사용되지 않았던, 즉 'in-the-wild' 환경의 Suwajanakorn et al.에서 추출된 두 가지 오디오 샘플 (Testset A와 Testset B)에 대해 얼마나 잘 작동하는지를 평가한다. 이는 실제 환경에서 모델의 일반화 능력과 robustness를 측정하는 데 중요하며, 예상치 못한 다양한 음성 입력에 대한 모델의 대응력을 가늠하게 한다.
-
평가 지표:
- Sync-E (Synchronization Error): 동기화 오류를 나타내는 지표이다.
- 값이 낮을수록 입술 움직임과 오디오 간의 동기화가 더 정확하다는 것을 의미한다.
- 표에서 (↓) 표시는 낮은 값이 좋은 성능임을 나타낸다.
- Sync-C (Synchronization Confidence): 동기화 신뢰도를 나타내는 지표이다.
- 값이 높을수록 모델이 입술 움직임과 오디오 간의 동기화가 잘 이루어졌다고 얼마나 '확신'하는지를 보여준다.
- 표에서 (↑) 표시는 높은 값이 좋은 성능임을 나타낸다.
- 측정 방식: 두 지표 모두 SyncNet을 사용하여 측정된다.
- SyncNet은 오디오 인코더 ()와 이미지 인코더 ()를 사용하여 오디오 특징과 렌더링된 이미지 특징 간의 L2 손실()을 계산한다.
- 여기서 는 이미지 인코더(Image Encoder)로, 렌더링된 이미지 로부터 시각적 특징을 추출한다.
- 는 오디오 인코더(Audio Encoder)로, 입력 오디오 로부터 음성 특징을 추출한다.
- 는 EmoTalkingGaussian이 오디오 에 조건화되어 렌더링한 이미지이다.
- 는 두 벡터(여기서는 시각적 특징과 음성 특징) 간의 유클리드 거리의 제곱을 의미하며, 이 값이 작을수록 두 모달리티(시각, 청각) 간의 동기화가 잘 이루어졌음을 나타낸다.
- Sync-E (Synchronization Error): 동기화 오류를 나타내는 지표이다.
-
결과 분석:
- Ground truth: 실제 원본 영상의 동기화 수준을 나타내며, Sync-E가 낮고 Sync-C가 높은 이상적인 값을 보여준다.
- 기존 모델들 (ER-NeRF [36], GaussianTalker [12], TalkingGaussian [37]): 이들은
Ground truth에 비해 Sync-E가 높고 Sync-C가 낮게 나타났다. 이는 훈련 데이터에 없던 새로운 오디오 입력에 대해서는 입술 동기화 성능이 저하됨을 시사한다. 특히GaussianTalker [12]는 가장 높은 Sync-E와 가장 낮은 Sync-C를 기록하여, 교차 도메인 오디오에 대한 동기화 성능이 가장 취약함을 보여준다. - Ours (EmoTalkingGaussian): 본 논문의 EmoTalkingGaussian 모델은
Testset A에서 Sync-E 9.262 / Sync-C 4.930을,Testset B에서 Sync-E 8.746 / Sync-C 5.426을 기록하였다. 이는 다른 모든 기존 모델들보다 Sync-E가 낮고 Sync-C가 높아, 교차 도메인 오디오에 대해 훨씬 더 우수하고 신뢰할 수 있는 입술 동기화 성능을 제공함을 입증한다.
Emotion-conditioned
특정 밸런스/어라우절 값을 조건으로 주어 모델이 원하는 감정을 얼마나 정확하고 다양하게 표현하는지 평가한다. 기존의 액션 유닛 기반 모델들과 비교하여 감정 표현의 풍부함을 측정하는 핵심 시나리오이다.
- 실험 설계:
이 논문은 "감정 조건 시나리오(Emotion-conditioned scenario)"에서 모든 모델을 평가하기 위해 일관된 기준을 마련했다. 핵심은 "원하는 감정(Valence/Arousal) → 중간 매개체 → 모델 렌더링 → 감정 분석"의 흐름이다.
1. 감정 조건 설정 (Target Valence/Arousal)
- 평가를 위해 먼저 12가지의 특정 Valence/Arousal (V/A) 값 쌍이 정의된다. 이 값들은 감정 원(Valence-Arousal circle) 상에 고르게 분포하며, 각각 특정 감정(예: 행복, 놀람, 분노, 슬픔 등)을 나타낸다. (예: (0.74, 0.31)은 Happy, (-0.31, 0.74)는 Angry 등)
- 이 정의된 V/A 값들이 "진정한 감정 값 ()"의 역할을 한다.
2. 감정 표현을 위한 입력 준비 (중간 매개체 활용)
이 단계에서 Ours 모델과 다른 Baseline 모델들의 작동 방식이 나뉜다.
-
Ours (EmoTalkingGaussian) 모델의 경우:
- Ours 모델은 Valence/Arousal 값을 직접 입력으로 받도록 설계되었다. 즉, 정의된 V/A 값()이 모델의 감정 브랜치(emotion branch)로 바로 들어간다.
- 모델은 이 V/A 값을 기반으로 얼굴의 3D Gaussian 파라미터 오프셋을 조절하여 감정 표현이 된 얼굴을 렌더링한다.
-
Baseline 모델들 (ER-NeRF, GaussianTalker, TalkingGaussian)의 경우:
- 이 모델들은 Valence/Arousal 값을 직접 받을 수 없다. 대신, Action Units (AUs)를 통해 얼굴 표정을 제어한다.
- 따라서, 정의된 V/A 값()을 직접 사용하는 대신, 다음과 같은 우회적인 방법을 사용한다:
- EmoStyle을 이용한 감정 얼굴 이미지 생성: 정의된 Valence/Arousal 값()을 입력으로 하여, EmoStyle이라는 별도의 GAN 기반 모델을 사용하여 해당 감정을 표현하는 정적인 얼굴 이미지를 생성한다. (EmoStyle은 입력 이미지의 감정을 V/A 값에 따라 변형하는 모델이다.)
- OpenFace를 이용한 Action Units (AUs) 추출: EmoStyle이 생성한 감정 표현이 된 얼굴 이미지로부터 OpenFace와 같은 얼굴 분석 도구를 사용하여 해당 이미지의 AUs를 추출한다.
- Baseline 모델에 AUs 입력: 이렇게 추출된 AUs를 ER-NeRF, GaussianTalker, TalkingGaussian과 같은 Baseline 모델의 입력으로 제공하여 Talking Head를 렌더링하게 한다. 이 AUs는 원래의 V/A 값에 "의도된" 감정을 담고 있다고 가정된다.
3. 모델 렌더링 (Generated Image)
- 각 모델(Ours 및 Baseline)은 위에서 준비된 입력(Ours는 V/A 직접, Baseline은 AUs)을 바탕으로 Talking Head 비디오의 프레임을 렌더링한다. 이것이 최종 생성된 이미지 ()이다.
4. 감정 분석 및 지표 계산 (Evaluation)
- 생성된 이미지() 자체를 직접 Valence/Arousal 지표 계산에 사용하지는 않는다. 대신, 생성된 이미지()에서 감정 특징을 추출하는 별도의 객관적인 도구를 사용한다.
- EmoNet을 이용한 감정 값 예측:
- 각 모델이 렌더링한 프레임을 EmoNet이라는 사전 학습된 감정 분석 네트워크에 입력한다.
- EmoNet은 입력된 얼굴 이미지에서 Valence와 Arousal 값, 그리고 감정 클래스 레이블을 예측하여 출력한다. 이 예측된 값들이 "예측된 감정 값 ()"의 역할을 한다.
- 지표 계산:
- V-RMSE / A-RMSE: 처음 정의된 "진정한 감정 값 ()"과 EmoNet이 생성된 이미지에서 예측한 "예측된 감정 값 ()" 사이의 평균 제곱근 오차를 계산한다.
- V-SA / A-SA: 와 의 부호(양수/음수)가 얼마나 일치하는지 비율을 계산한다.
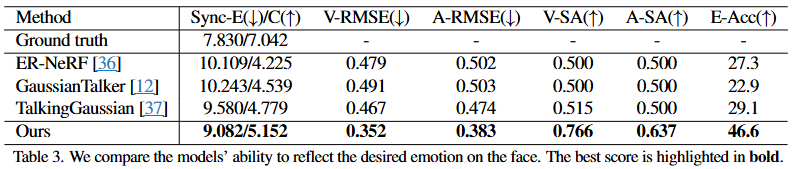
-
평가 지표:
-
Sync-E(↓) / C(↑):
- 이 두 지표는 SyncNet을 사용하여 측정되었다.
- Sync-E (Synchronization Error): 생성된 이미지의 립싱크와 입력 오디오 간의 동기화 오류를 측정한다. 값이 낮을수록 립싱크 정확도가 높음을 의미한다.
- Sync-C (Synchronization Confidence): 립싱크의 신뢰도를 나타낸다. 값이 높을수록 립싱크가 더 견고하고 자연스럽다는 것을 의미한다
-
V-RMSE(↓) / A-RMSE(↓):
- V-RMSE (Valence Root Mean Square Error): 생성된 이미지에서 EmoNet으로 예측된 valence 값과 실제 목표 valence 값 사이의 평균 제곱근 오차이다.
- A-RMSE (Arousal Root Mean Square Error): 생성된 이미지에서 EmoNet으로 예측된 arousal 값과 실제 목표 arousal 값 사이의 평균 제곱근 오차이다.
- 두 값 모두 낮을수록 모델이 원하는 valence와 arousal 강도를 더 정확하게 표현한다는 의미이다.
- 수식으로 표현하면 다음과 같다:
여기서,- : 번째 프레임에서 EmoNet이 예측한 valence 또는 arousal 값.
- : 조건으로 사용된 목표 valence 또는 arousal 값.
- : 전체 프레임 수.
-
V-SA(↑) / A-SA(↑):
- V-SA (Valence Sign Agreement): 예측된 valence 값의 부호와 목표 valence 값의 부호가 일치하는 비율이다.
- A-SA (Arousal Sign Agreement): 예측된 arousal 값의 부호와 목표 arousal 값의 부호가 일치하는 비율이다.
- 두 값 모두 높을수록 모델이 감정의 긍정/부정(valence) 또는 흥분/평온(arousal) 방향을 올바르게 반영한다는 의미이다. 논문에서는 다른 baseline 모델들이 0.5 근처의 V-SA 및 A-SA 값을 보이는 것은 생성된 이미지의 valence 및 arousal 값이 감정 원의 특정 사분면에만 집중되어 있음을 시사한다고 언급한다.
- 수식으로 표현하면 다음과 같다:
여기서,- : 괄호 안의 조건이 참이면 1, 거짓이면 0을 반환하는 지시 함수(indicator function).
- : 입력이 양수이면 1, 음수이면 -1, 0이면 0을 반환하는 함수.
-
E-Acc(↑):
- Emotion Classification Accuracy (Top-3): EmoNet이 생성된 이미지에서 예측한 감정 클래스 레이블이 미리 정의된 목표 감정 클래스 레이블과 일치하는 Top-3 정확도이다. 값이 높을수록 모델이 의도한 감정을 시각적으로 잘 표현함을 의미한다.
-
결과 분석:
-
립싱크 성능 (Sync-E, Sync-C): 제안하는 EmoTalkingGaussian (Ours)은 Sync-E 9.082, Sync-C 5.152를 기록하여, ER-NeRF, GaussianTalker, TalkingGaussian 등의 기존 SOTA 모델들보다 더 우수한 립싱크 정확도와 신뢰도를 보인다. 이는 오디오에 맞춰 입 모양을 정확히 동기화하는 데 강점이 있음을 나타낸다.
-
감정 일관성 (V-RMSE, A-RMSE, V-SA, A-SA):
- RMSE: EmoTalkingGaussian은 V-RMSE 0.352, A-RMSE 0.383으로, 다른 모든 baseline 모델들보다 훨씬 낮은 오차율을 보인다. 이는 제안하는 모델이 목표로 하는 valence/arousal 값의 '강도(intensity)'를 매우 정확하게 반영한다는 것을 의미한다.
- SA: EmoTalkingGaussian은 V-SA 0.766, A-SA 0.637로, 다른 모델들(대부분 0.500~0.515)에 비해 현저히 높은 '부호 일치율'을 보인다. 이는 모델이 감정의 긍정/부정, 흥분/평온 '방향'을 매우 효과적으로 표현하고 있음을 의미한다. 기존 모델들은 감정 원의 한 사분면에만 감정 표현이 집중되는 한계가 있었다.
-
감정 분류 정확도 (E-Acc): EmoTalkingGaussian은 46.6%의 Emotion Classification Accuracy를 달성하여, 기존 모델들(22.9%~29.1%)보다 월등히 높은 성능을 보인다. 이는 생성된 얼굴 이미지에서 의도된 감정이 시각적으로 명확하게 드러나며, AI 모델도 이를 정확하게 인식할 수 있음을 의미한다.
Ablation Study
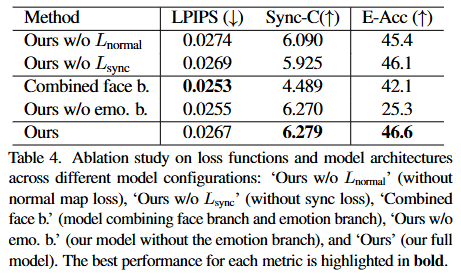
-
측정 지표
- LPIPS (): Learned Perceptual Image Patch Similarity
- LPIPS는 렌더링된 이미지와 실제 이미지 사이의 지각적 유사성을 측정하는 지표이다. 사람이 인지하는 이미지의 품질 차이를 더 잘 반영하기 위해 딥러닝 피처를 활용한다.
- 이 값은 낮을수록 원본 이미지와 더 유사하며, 이는 생성된 이미지의 시각적 품질이 더 높다는 것을 의미한다.
- Sync-C (): Synchronization Confidence
- Sync-C는 생성된 인물의 입술 움직임이 입력 오디오와 얼마나 잘 동기화되는지에 대한 신뢰도를 나타내는 지표이다. SyncNet [14]을 통해 측정된다.
- 이 값은 높을수록 입술 움직임과 오디오 간의 동기화가 더 정확하고 자연스럽다는 것을 의미한다.
- E-Acc (): Emotion Classification Accuracy
- E-Acc는 렌더링된 이미지에서 의도된 감정(valence/arousal)이 얼마나 정확하게 표현되었는지를 측정하는 지표이다. EmoNet [61]을 사용하여 감정 레이블을 분류하고 정확도를 계산한다.
- 이 값은 높을수록 모델이 다양한 감정을 더 잘 표현할 수 있음을 나타낸다.
- LPIPS (): Learned Perceptual Image Patch Similarity
-
모델 구성
- Ours w/o : 제안하는 EmoTalkingGaussian 모델에서 손실 함수를 제거한 경우이다.
- 은 노멀 맵(normal map)의 품질을 향상시켜 렌더링된 이미지의 디테일과 사실감을 높이는 데 기여한다. 이 손실을 제거함으로써 이미지 품질에 미치는 영향을 평가한다.
- Ours w/o : 제안하는 EmoTalkingGaussian 모델에서 손실 함수를 제거한 경우이다.
- 는 입술 움직임과 오디오 간의 동기화를 강화하는 역할을 한다. 이 손실을 제거함으로써 입술 동기화 정확도에 미치는 영향을 평가한다.
- Combined face b.: 얼굴 브랜치(face branch)와 감정 브랜치(emotion branch)를 하나의 네트워크로 통합하여 사용하는 모델 구성이다.
- 이 경우, 단일 네트워크가 오디오 피처(), 액션 유닛(), 감정 입력()을 모두 받아 얼굴의 위치, 스케일링, 회전 오프셋을 추정한다. 이는 모델의 파라미터 수를 줄이고 계산 효율성을 높일 수 있는지 확인하려는 시도이다.
- Ours w/o emo. b.: 제안하는 EmoTalkingGaussian 모델에서 감정 브랜치(emotion branch)를 완전히 제외한 경우이다.
- 이는 TalkingGaussian [37]과 유사하게, 오디오와 액션 유닛만을 사용하여 얼굴 표현을 제어하는 베이스라인 모델에 가깝다. 감정 표현 능력에 대한 감정 브랜치의 중요성을 보여준다.
- Ours: 이 논문에서 제안하는 EmoTalkingGaussian의 완전한 모델이다. 즉, 내부 입(inside-mouth) 브랜치, 얼굴(face) 브랜치, 감정(emotion) 브랜치를 독립적으로 사용하고, 및 를 포함한 모든 손실 함수를 적용한 결과이다.
- Ours w/o : 제안하는 EmoTalkingGaussian 모델에서 손실 함수를 제거한 경우이다.
-
결과 분석
-
의 영향: 'Ours w/o '의 LPIPS(0.0274)는 'Ours'(0.0267)보다 높다. 이는 이 렌더링된 이미지의 품질을 향상시키는 데 효과적임을 보여준다. 노멀 맵 손실은 미세한 표면 디테일을 보존하고 아티팩트를 줄이는 데 기여한다.
-
의 영향: 'Ours w/o '의 Sync-C(5.925)는 'Ours'(6.279)보다 낮다. 이는 가 입술 동기화 정확도를 높이는 데 결정적인 역할을 함을 명확히 보여준다. Self-supervised learning과 TTS 생성 오디오 데이터를 활용한 는 모델이 in-the-wild 오디오 샘플에 대해서도 견고한 동기화 성능을 발휘하도록 돕는다.
-
Combined face b.의 한계: 'Combined face b.'는 LPIPS(0.0253)에서 가장 낮은 값을 보여 이미지 품질 자체는 가장 좋다. 이는 단일 브랜치에서 모든 정보를 처리할 때 더 일관된 외관을 생성할 수 있음을 시사한다. 그러나 Sync-C(4.489)와 E-Acc(42.1)는 다른 모델들(특히 'Ours')에 비해 현저히 낮다. 이는 하나의 브랜치로 모든 복잡한 변형(오디오, 액션 유닛, 감정)을 처리하는 것이 입술 동기화의 정밀도와 감정 표현의 정확도를 저해할 수 있음을 나타낸다. 즉, 각 기능에 특화된 독립적인 브랜치를 사용하는 것이 더 나은 제어력과 성능을 제공한다.
-
Emotion branch의 중요성: 'Ours w/o emo. b.'의 E-Acc(25.3)는 모든 모델 중 가장 낮다. 이는 감정 브랜치(emotion branch)가 없으면 모델이 Valence/Arousal 값에 따라 다양한 감정을 효과적으로 표현할 수 없다는 것을 명확하게 보여준다. 반면, Sync-C(6.270)는 'Ours'와 거의 동일하게 높은 성능을 유지하는데, 이는 오디오 동기화는 감정 브랜치와 독립적으로 잘 작동함을 의미한다.
-
제안하는 모델('Ours')의 강점: 'Ours'는 LPIPS에서 최저값은 아니지만 경쟁력 있는 수준(0.0267)을 유지하며, Sync-C(6.279)와 E-Acc(46.6)에서 모두 가장 높은 성능을 보인다. 이는 제안하는 EmoTalkingGaussian 모델이 고품질 이미지 렌더링, 정확한 입술 동기화, 그리고 다양한 감정 표현 능력을 동시에 효과적으로 달성했음을 입증한다. 약간의 이미지 품질 저하는 다양한 감정 표현과 동기화를 위한 트레이드오프라고 볼 수 있다.
-
