Method


Experiments
Datasets & Experimental Setting
이 논문은 총 7개의 'in-the-wild' 얼굴 표정 데이터셋을 사용하여 실험을 수행했으며, 이는 크게 두 가지 유형으로 나뉜다: 정적(Static) 얼굴 표정 인식(SFER) 데이터셋과 동적(Dynamic) 얼굴 표정 인식(DFER) 데이터셋이다. 또한, 투영 헤드(projection head)를 학습시키기 위한 실험 설정도 상세히 설명되어 있다.
-
정적 얼굴 표정 인식 (SFER) 데이터셋
- RAF-DB:
- 30,000개의 얼굴 이미지를 포함한다.
- 기본 또는 복합 표정으로 주석이 달려있으며, 대부분의 이전 연구와 마찬가지로 행복(happiness), 슬픔(sadness), 분노(anger), 놀람(surprise), 혐오(disgust), 공포(fear)의 6가지 기본 감정과 중립(neutral) 표정만을 사용한다.
- 테스트 데이터는 3,068개의 이미지로 구성된다.
- AffectNet:
- 약 450,000개의 이미지로 구성되며, 11가지 표정 카테고리로 수동 주석이 달려있다.
- AffectNet-7(6가지 기본 감정 + 중립)은 3,500개의 테스트 이미지를 포함하며, AffectNet-8(6가지 기본 감정 + 경멸(contempt) + 중립)은 8가지 표정 카테고리를 사용한다.
- FERPlus:
- FER2013의 확장 버전으로, 35,887개의 이미지를 포함한다.
- AffectNet-8과 동일하게 8가지 표정 카테고리를 사용하며, 3,589개의 이미지가 테스트 데이터로 활용된다.
- RAF-DB:
-
동적 얼굴 표정 인식 (DFER) 데이터셋
- DFEW:
- 11,697개의 'in-the-wild' 비디오 클립으로 구성된다.
- 모든 샘플은 중복 없이 5개의 동일한 크기 부분으로 나뉘며, 각 비디오는 6가지 기본 감정과 중립 중 하나로 주석이 달려있다.
- 평가 프로토콜로 5-fold 교차 검증(cross-validation)이 사용된다.
- FERV39k:
- 현재 가장 큰 'in-the-wild' DFER 데이터셋으로, 38,935개의 비디오 클립을 포함한다.
- 모든 비디오 클립은 6가지 기본 감정과 중립 중 하나로 할당된다.
- 학습(80%)과 테스트(20%) 세트로 무작위로 분할된다.
- MAFW:
- 10,045개의 'in-the-wild' 비디오 클립으로, 최초의 대규모 다중 모달(multi-modal), 다중 레이블(multi-label) 감정 데이터베이스이다.
- 11가지 단일 표정 카테고리(6가지 기본 감정, 경멸(contempt), 불안(anxiety), 무력감(helplessness), 실망(disappointment), 중립)와 32가지 다중 표정 카테고리, 그리고 감정 서술 텍스트를 포함한다.
- 5-fold 교차 검증이 평가에 사용된다.
- AFEW:
- 1,809개의 'in-the-wild' 비디오 클립으로 구성된다.
- 학습(773), 검증(383), 테스트(653) 세트로 나뉘며, 테스트 분할은 공개적으로 이용할 수 없으므로 검증 세트의 결과가 보고된다.
- DFEW:
-
실험 설정: 투영 헤드 학습
- 학습 데이터셋: 투영 헤드(projection head)의 대조 학습(contrastive learning) 단계에서는 CAER-S 학습 세트의 45K개 얼굴 이미지를 사용한다.
- 투영 헤드 구성:
- 이 투영 헤드는 모델의 비전-언어 공간을 얼굴 표정 인식을 위한 특정 태스크 공간으로 매핑하는 역할을 한다.
- ViT-B-32/B-16 백본 사용 시 크기의 행렬이며, ViT-L-14 백본 사용 시 크기의 행렬이다.
- 단일 MLP(Multi-Layer Perceptron) 레이어로 구현되어 있다.
- 학습 파라미터:
- 학습 가능한 투영 헤드의 학습률(learning rate)은 으로 설정되었다.
- 5 에포크(epochs) 동안 엔드-투-엔드(end-to-end) 방식으로 학습된다.
- SGD(Stochastic Gradient Descent) 옵티마이저와 512의 미니 배치(mini-batch) 크기로 최적화된다.
- LLM 인코더: LLM으로는 11B 파라미터를 가진 Flan-T5-XXL [5] 모델이 사용되었다.
-
제로샷(Zero-shot) 예측 설정
- 이미지 전처리: SFER의 경우 모든 이미지는 크기로 조정된다. DFER의 경우, [11, 17, 45]의 샘플링 전략에 따라 고정된 16프레임 시퀀스를 추출하고 로 크기를 조정한다.
- 결과 신뢰성: 보다 안정적이고 신뢰할 수 있는 결과를 얻기 위해, 서로 다른 무작위 시드(random seeds)로 모델을 세 번 학습시키고 그 평균을 최종 결과로 사용한다.
-
평가 지표
- 대부분의 이전 연구와 마찬가지로, 가중 평균 재현율(Weighted Average Recall, WAR)과 비가중 평균 재현율(Unweighted Average Recall, UAR)이 방법론의 성능을 평가하는 데 사용된다.
- WAR은 전체 정확도(accuracy)를 의미하며, 모든 클래스의 샘플 수를 고려한 전체 정확도이다.
- UAR은 각 클래스별 정확도를 클래스 수로 나눈 값으로, 클래스별 샘플 수의 불균형을 고려하지 않고 모든 클래스에 동일한 가중치를 부여한다.
- 대부분의 이전 연구와 마찬가지로, 가중 평균 재현율(Weighted Average Recall, WAR)과 비가중 평균 재현율(Unweighted Average Recall, UAR)이 방법론의 성능을 평가하는 데 사용된다.
Ablation Study
-
Projection Head의 효과:
- Exp-CLIP은 CLIP 모델을 기반으로 하며, 학습된 Projection Head의 효과를 검증하기 위해 다양한 ViT 모델(ViT-B-32, ViT-B-16, ViT-L-14)과 다양한 제로샷 프롬프트(zero-shot prompts)에 대해 CLIP 모델과 비교 평가를 수행했다.
- Exp-CLIP은 모든 테스트 세트에서 일반 CLIP 모델보다 우수한 성능을 보였다. 특히, ViT-B-32에서는 평균 UAR 2.71%, 평균 WAR 4.42% 향상을, ViT-B-16에서는 평균 UAR 5.47%, 평균 WAR 6.75% 향상을, ViT-L-14에서는 평균 UAR 8.07%, 평균 WAR 8.23% 향상을 달성했다.
- 이는 Projection Head가 CLIP의 일반적인 특징 표현을 안면 표정 인식(FER) 작업에 특화된 표현으로 효과적으로 변환했음을 시사한다.
-
다양한 Instruction의 평가:
- LLM으로부터 작업별 지식을 이끌어내기 위한 'Instruction'의 효과를 검증하기 위해 'Task-unrelated' Instruction과 'Task-related' Instruction 두 가지 유형으로 실험을 진행했다.
- 결과적으로 'Task-related' Instruction이 'Task-unrelated' Instruction보다 모든 SFER 및 DFER 데이터셋에서 우수한 성능을 보였다. 이는 작업과 관련된 Instruction이 LLM이 작업 인지(task-aware) 의미 특징(semantic features)을 생성하도록 촉진하여 Projection Head 최적화에 더 나은 목표를 제공한다는 것을 의미한다.
-
Projection Head 네트워크의 구조에 따른 평가:
- 원래 CLIP 특징 표현을 LLM의 작업별 지식 공간으로 정렬하기 위해 Projection Head를 선형 매핑으로 사용했다.
- Projection Head의 복잡성(2-layer MLP, 3-layer MLP, Transformer Encoder)이 정렬 성능에 미치는 영향을 확인하는 실험을 수행했다.
- 단순한 학습 가능한 행렬(learnable linear matrix, LM)을 사용하는 본 논문의 방법이 더 복잡한 MLP나 Transformer Encoder보다 우수하거나 유사한 성능을 보였다. 저자들은 복잡한 비선형 모델이 LLM 특징 공간에 과적합(overfitting)될 수 있어 제로샷 FER 작업에서 성능이 저하될 수 있다고 추측한다. 선형 Projection Head가 기존 모델의 강력한 일반 목적 표현 능력을 유지하면서 FER 도메인에 맞게 조정하는 데 더 적합하다고 설명한다.
-
Projection Head 유무에 따른 결과:
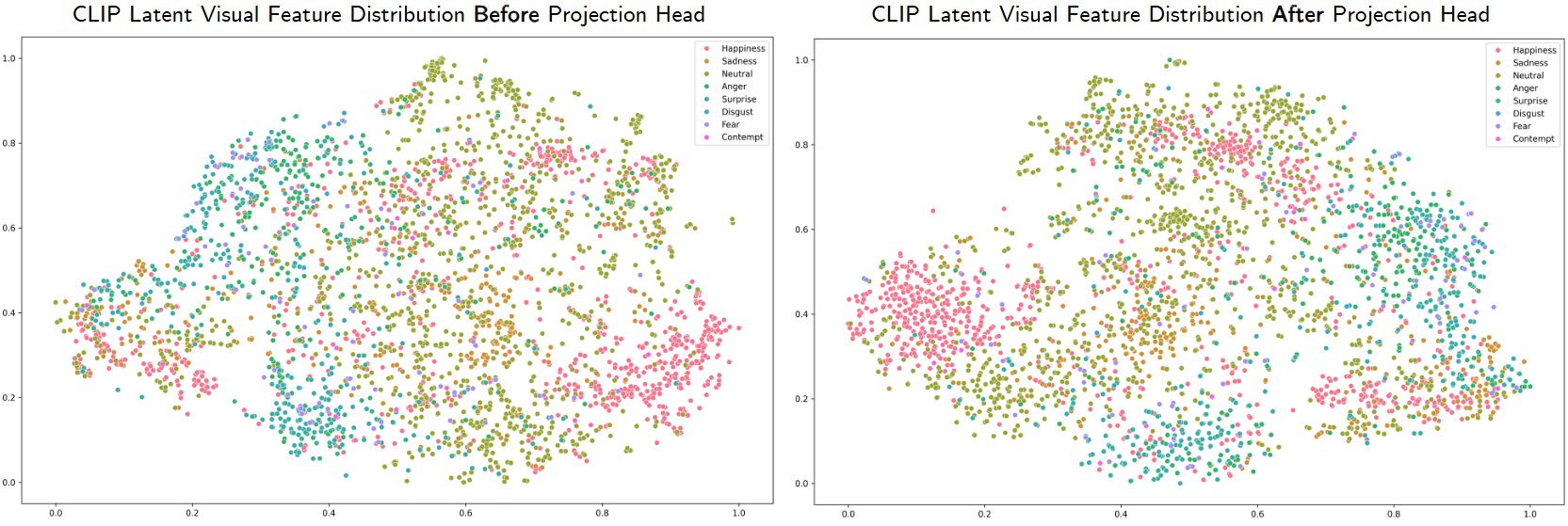
- t-SNE 📄 Visualizing Data using t-SNE: 이 논문에서는 t-SNE(t-Distributed Stochastic Neighbor Embedding)라는 비선형 차원 축소 기법을 활용한다. t-SNE는 고차원 데이터의 유사성을 저차원 공간에 보존하면서 시각화하는 데 사용되는 기술이다. 이는 특히 고차원의 특징 벡터들을 2차원 또는 3차원 공간에 매핑하여 시각적으로 군집화 정도를 파악하기 용이하게 한다.
- 대상 데이터: FERPlus 데이터셋의 이미지들을 사용하며, ViT-L-14 모델에서 추출된 특징을 기반으로 한다.
-
시각화 결과 분석:
- 그림: CLIP의 원본 잠재 시각 특징 분포와 프로젝션 헤드를 거친 후의 잠재 시각 특징 분포를 보여준다.
- 원본 CLIP 특징 공간에서는 같은 범주의 샘플들이 명확하게 군집화되지 않고 흩어져 있는 경향을 보인다. 이는 CLIP 모델이 일반적인 특징 표현을 학습하여 특정 작업(FER)에 대한 미묘한 차이를 잘 포착하지 못하기 때문으로 해석된다.
- 프로젝션 후의 특징 공간에서는 같은 범주의 샘플들이 더 잘 모여(군집화되어) 있는 것을 확인할 수 있다. 특히 '행복(happiness)'과 '혐오(disgust)' 같은 감정에서 이러한 군집화 효과가 두드러지게 나타난다. 이는 프로젝션 헤드가 원본 CLIP 특징 공간을 안면 표정 인식 작업에 특화된(task-aware) 공간으로 성공적으로 매핑했음을 시사한다.
- 그림: CLIP의 원본 잠재 시각 특징 분포와 프로젝션 헤드를 거친 후의 잠재 시각 특징 분포를 보여준다.
-
다양한 Image 및 Text Encoder의 평가:
- LLM이 제로샷 FER 작업에서 Exp-CLIP보다 더 나은 성능을 낼 수 있는지 확인하기 위해 LLM을 이미지 인코더(I2T 모듈 포함) 또는 텍스트 인코더, 또는 둘 다로 사용하는 실험을 진행했다.
- LLM을 이미지 인코더나 텍스트 인코더로 단독 사용할 경우, 그리고 LLM을 둘 다로 사용할 경우에도 Plain CLIP 모델이나 Exp-CLIP보다 성능이 현저히 낮았다.
- 이는 LLM이 이미지의 의미론적 인식(semantic perception)에는 뛰어나지만, 인식 작업(recognition tasks)에는 약하다는 것을 보여준다. 반면, CLIP 모델을 기반으로 하는 Exp-CLIP은 제로샷 FER 작업에서 더 효율적이고 정확하다는 결론을 내린다.
추가 질문과 답변
Pretrain Projection Head 과정에서, text instruction을 주는 것만으로 task speicific한 knowledge를 모델에 전이할 수 있는가?
Exp-CLIP은 LLM에 text instruction을 제공하는 것만으로도 모델이 얼굴 표정 인식(FER)이라는 task-specific knowledge을 학습하도록 유도한다. 이는 LLM의 거대한 언어 모델이 가진 방대한 세계 지식과 상식적 추론 능력을 활용하는 핵심 전략이다.
-
어떻게 학습되는가:
- 논문에서는 "Please play the role of a facial action describer. Objectively describe the detailed facial actions of the person in the image."와 같은 명확한 지시를 LLM에 전달한다.
- 이 지시와 함께 입력된 얼굴 이미지의 시각 정보는 I2T 모듈을 통해 언어 토큰으로 변환되고, 둘은 concat 되어 LLM 인코더에 입력된다.
- LLM 인코더는 단순한 이미지 설명이 아닌, 주어진 '얼굴 동작 묘사 전문가' 역할 지시에 따라 얼굴 표정의 미묘한 차이를 강조하는 Task-specific 임베딩()을 생성한다.
- 프로젝션 헤드()는 CLIP 이미지 인코더에서 추출된 원본 시각 임베딩()을 이 LLM이 생성한 Task-specific 임베딩()과 정렬(align)되도록 학습된다. 이 정렬 과정에서 프로젝션 헤드는 얼굴 표정 인식을 위해 필요한 시각적 특징에 집중하는 방법을 비지도 학습 방식으로 배우게 된다.
- 즉, 텍스트 지시는 LLM이 어떤 지식을 더욱 활성화하고 추출할지 안내하는 역할을 하며, 이 추출된 지식이 프로젝션 헤드의 학습을 위한 '참조점(reference point)'이 되어 모델이 작업별 지식을 효과적으로 전이받을 수 있게 한다.
- 투사 헤드는 대조 학습(contrastive learning)을 통해, 같은 이미지로부터 파생된 CLIP의 시각 임베딩()을 투사한 결과()가 해당 이미지에 대해 LLM이 생성한 의미 임베딩()과는 가깝게, 그리고 다른 이미지에 대해 LLM이 생성한 의미 임베딩과는 멀어지도록 학습된다. 이 과정은 레이블 없이도 의미 있는 특징을 학습하게 한다.
-
지식 전이의 효과:
- LLM은 인간의 언어와 상식으로부터 표정에 대한 방대한 지식(예: '미소 짓는 얼굴'이 무엇인지, '눈썹을 찌푸리는 것'이 무엇을 의미하는지)을 이미 내재하고 있다.
- 투사 헤드가 CLIP의 일반적인 시각 특징을 이 LLM 기반의 작업별 의미 공간에 정렬시킴으로써, CLIP 모델은 LLM이 가진 표정 관련 '지식'을 시각 도메인으로 효과적으로 '전이'받게 된다.
- 결과적으로 투사 헤드는 미묘한 얼굴 동작을 식별하고 이를 감정적 의미와 연결하는 방법을 배우게 되며, 이는 레이블된 데이터 없이도 제로샷 얼굴 표정 인식 성능을 향상시키는 기반이 된다. 이는 사람이 일일이 표정 레이블을 붙이는 수고를 덜면서도 강력한 모델을 구축할 수 있게 하는 중요한 진전이다.
와 는 생성 원리가 다른데, 어떻게 모델이 일반적인 성능을 낼 수 있는가?
질문
-
모델 훈련 과정(Pretrain Projection Head):
- : CLIP 이미지 인코더와 프로젝션 헤드를 통해 생성된 특징
- : I2T 모듈, 피처 concat 등의 복잡한 전처리 과정을 거친 후 LLM 인코더를 통과한 결과
- 이 와 가까워지도록 프로젝션 헤드를 학습
-
모델 추론 과정(Zero shot Prediction):
- 이미지는 CLIP 이미지 인코더에 입력.
- 감정을 묘사한 텍스트는 CLIP 텍스트 인코더에 입력.
- 두 피처를 위에서 학습한 projection head에 각각 입력
- 둘의 코사인 유사도가 가장 높은 감정을 정답으로 채택.
-
의문점:
- projection head는 CLIP 이미지 인코더를 통해 생성된 피처가 에 가까워지도록 학습.
- 그런데 Zero shot Prediction에서는 생성된 피처를 전혀 다른 방식(CLIP text encoder)를 통해 생성된 피처와 코사인 유사도 비교.
답변
모델 추론 과정 (Zero-shot Prediction)에서의 투사 헤드의 적용:
- 학습이 완료된 투사 헤드()는 이제 CLIP의 원본 비전-언어 공간을 LLM이 정의한 '얼굴 표정 특화 공간'으로 변환하는 능력을 갖게 된다.
- 이미지 피처 변환: 입력 이미지의 CLIP 시각 임베딩()에 를 적용하면, 는 이제 LLM의 지식을 흡수하여 얼굴 표정 인식에 더 적합하게 정제된 시각 특징이 된다. (즉, 가 정의한 공간에 정렬된 시각 특징이 된다.)
- 텍스트 피처 변환: 마찬가지로, 감정 클래스에 대한 텍스트 프롬프트('a photo of a face with an expression of [happiness].')의 CLIP 텍스트 임베딩()에도 동일한 투사 헤드 를 적용한다. 는 이제 일반적인 텍스트 특징이 아니라, '얼굴 표정 특화 공간'에 있는 텍스트 특징이 된다.
어떻게 성능을 낼 수 있는가:
- 공유된 공간으로의 매핑: 와 가 생성 방식은 다르지만, 투사 헤드는 이들을 하나의 통일된 '작업별 공동 공간'으로 변환하는 역할을 한다.
- 훈련 단계에서 투사 헤드는 CLIP의 이미지 특징을 LLM이 인지하는 얼굴 표정의 의미론적 공간(로 대표되는)으로 옮기는 법을 배웠다.
- 추론 단계에서는 이 학습된 투사 헤드를 CLIP의 텍스트 특징()에도 적용하여, 텍스트 특징 또한 동일한 '얼굴 표정 특화 공간'으로 매핑한다.
- 의미론적 일관성: CLIP 모델 자체가 원래 이미지와 텍스트를 유사한 의미론적 공간에 정렬하는 능력을 가지고 있다. 투사 헤드는 이 CLIP의 기본적인 정렬 능력을 유지하면서, LLM의 지식을 통해 해당 공간을 '얼굴 표정'이라는 특정 작업에 더 미묘하고 정교하게 최적화하는 역할을 한다.
- 예를 들어, CLIP은 '행복'이라는 단어와 '웃는 얼굴' 이미지를 연관 지을 수 있지만, 투사 헤드는 LLM의 지도를 받아 '미소의 강도', '눈가의 주름' 등 표정을 구성하는 미세한 동작 정보까지 반영하도록 특징을 강화한다.
- 교사의 역할: 는 투사 헤드에게 "얼굴 표정의 특징이 어떤 식으로 표현되어야 하는지"를 알려주는 교사(teacher) 신호의 역할을 한다. 이 교사 신호 덕분에 투사 헤드는 CLIP의 범용적인 시각-언어 특징을 얼굴 표정 인식에 최적화된 특징으로 '재형상화(re-shaping)'할 수 있다. 학습된 투사 헤드는 이제 이미지를 보고 LLM이 해석했던 방식으로 표정 특징을 뽑아낼 수 있고, 텍스트 설명을 보더라도 그 특징을 동일한 공간에서 표현할 수 있게 되는 것이다.

상어 인형을 좋아하는 사람