Abstract
-
Visual Instruction Tuning (VIT)정의 및 한계:VIT는 사전 학습된 언어 모델을 특정 작업 지침을 사용하여 미세 조정하는 새로운 학습 패러다임이다.- 이는 다양한 자연어 처리(
NLP) 작업에서 유망한 제로샷(zero-shot) 결과를 보였으나, 시각 감정 이해(vision emotion understanding) 분야에서는 아직 탐구되지 않은 영역이었다.
-
EmoVIT의 주요 목표:
- 모델이 감정적 맥락과 관련된 지침을 이해하고 따르는 능력을 향상하는 데 중점을 둔다.
-
핵심 방법론:
- 시각적 단서 식별: 시각적 감정 인식에 중요한 핵심 시각적 단서들을 식별한다.
- GPT 기반 감정 시각 지침 데이터 생성 파이프라인: 주석이 달린 지침 데이터의 부족 문제를 해결하기 위해, GPT-4의 도움을 받아 감정 시각 지침 데이터를 생성하는 새로운 파이프라인을 도입한다.
- EmoVIT 아키텍처:
InstructBLIP을 기반으로 감정 특정 지침 데이터를 통합하여Large Language Models (LLMs)의 강력한 기능을 활용, 성능을 향상한다.
1. Instruction
-
시각적 감정 인식의 중요성:
- 인공지능 및 컴퓨터 비전의 핵심 분야로, 얼굴 표정이나 신체 언어와 같은 시각적 단서를 기반으로 인간의 감정을 예측하는 것을 목표로 한다.
- 인간-컴퓨터 상호작용 개선, 정신 건강 평가 지원, 사용자 경험 향상, 감정 조작 및 허위 정보 방지를 통한 정보 보안 강화 등 다양한 응용 분야를 가진다.
-
기존 대규모 멀티모달 모델의 한계:
- Flamingo, LLaVA, BLIP2와 같은 최근의 기초 비전 모델들은 보편적인 시각 이해(분류, 탐지, 분할, 캡션)에 탁월한 성능을 보인다.
- 하지만 감정 인식 측면에서는 여전히 초기 단계에 머물러 있다.
- 예를 들어, GPT-4에 이미지의 감정 범주를 직접 질의할 경우 잘못된 응답을 제공하는 경향이 있지만, 수정된 지침(instruction)이 주어지면 정확한 응답을 제공한다. 이는 대규모 모델에서 감정 이해를 위한 'instruction-following ability'의 중요성을 부각한다.
-
EmoVIT의 제안 및 주요 기여:
- Instruction Tuning의 활용: 기존 VLM의 잠재력을 최대한 활용하기 위해, 언어 모델이 자연어 지침을 따르도록 훈련하는 효과적인 전략인 Instruction Tuning 개념에 기반을 둔다. 이를 통해 모델의 일반화 성능을 향상시킨다.
- 감정 관련 지침 이해 능력 향상: 모델이 감정적 맥락과 관련된 지침을 이해하고 따르는 능력을 개발하는 데 중점을 둔다. 이는 감정 특화 아키텍처 없이도 기존 지식 기반을 활용하여 감성 콘텐츠를 효과적으로 해석하고 반응하게 한다.
- GPT-assisted 감정 시각 지침 데이터 생성 파이프라인: 시각적 감정 인식에서 지침 데이터 부족 문제를 해결하기 위해 GPT-4를 활용한 새로운 자기 생성 파이프라인을 도입한다. 이는 이미지의 고유한 특성을 포착하고, 복잡한 추론을 요구하는 다양한 인스턴스를 생성하여 데이터 다양성을 높인다. 밝기, 색상, 장면 유형, 객체 클래스, 얼굴 표정, 인간 행동 등 시각적 단서를 포함한다.
- EmoVIT 아키텍처: InstructBLIP의 기반 위에 감정 도메인 특화 지침 데이터를 통합하여, LLM의 강력한 기능을 활용해 성능을 향상시킨다.
- InstructBLIP: 높은 성능을 보인 BLIP-2에 Instruction Tuning 기법을 적용하여 성능을 더욱 끌어올린 모델.
- 효율성 및 성능: 이전 시각적 감정 인식 방법 및 인기 있는 Visual Instruction Tuning 방법과 비교하여, EmoVIT는 필요한 훈련 데이터의 거의 50%만으로도 뛰어난 성능을 달성한다.
- 광범위한 역량 입증: 감정 분류, 감성 추론(affective reasoning), 유머 이해 능력에서 탁월함을 보여준다.
2. Related Work
-
2.1. Visual Emotion Recognition (시각 감정 인식)
- 주요 과제: 시각적 단서(facial expressions, body language 등)와 그것이 나타내는 인간의 감정 상태 사이의 '감정적 간극(affective gap)'을 연결하는 것이 핵심 과제이다.
- 멀티모달 모델의 한계: GPT 시리즈와 같은 멀티모달 모델의 발전이 Vision-Language Recognition 분야를 크게 발전시켰음에도 불구하고, 감정 인식 분야에서는 아직 초기 단계에 머물러 있었다.
-
2.2. Visual Instruction Tuning (시각 명령어 튜닝)
- Instruction Tuning의 부상: 최신 Large Language Model은 방대한 지식 기반을 가지고 있으나, 사용자 지침을 정확히 해석하고 따르는 데 어려움이 있었다. Instruction Tuning은 모델이 자연어 지침을 따르도록 학습시켜 보지 못한 작업에 대한 일반화 성능을 크게 향상시키는 효과적인 전략으로 입증되었다.
- 시각-언어 태스크로의 확장: 이 접근 방식은 BLIP-2와 같은 연구들을 통해 시각-언어 태스크로 확장되었다. InstructBLIP은 Instruction-aware Query Transformer를 도입하여 주어진 지침에 맞춰 시각적 특징을 보다 유연하게 추출할 수 있게 했다.
- 감정 지침 데이터의 부족: 그러나 Visual 'Emotion' Instruction Tuning은 아직 새로운 분야이므로, 감정 지침 데이터 생성에 대한 벤치마크나 가이드라인이 부재한 상황이다. 본 연구는 이러한 한계를 극복하기 위해 대규모 모델을 활용하여 감정 지침 데이터 생성 파이프라인을 구축하는 데 선구적인 역할을 한다. 이는 수동 주석의 제약을 뛰어넘는 혁신적인 접근 방식이다.
3. Method
3.1. Preliminary of Visual Instruction Tuning
- 시각 튜닝 패러다임의 변화:
- 기존 튜닝 방법: Full fine-tuning, Head-oriented, Backbone-oriented 기술을 포함한다. Full fine-tuning은 효과적이지만, 각 작업별로 백본 파라미터의 별도 복사본을 유지해야 하므로 저장 및 배포에 어려움이 있다.
- Visual Prompt Tuning (VPT): 대규모 Vision Transformer 모델에서 full fine-tuning에 대한 효율적인 대안이다. 모델 백본을 고정하고 입력 공간에 최소한의 학습 가능한 파라미터인 프롬프트 파라미터 를 사용한다.
- VPT의 목적 함수는 다음과 같다:
- : 프롬프트 파라미터 에 대한 최소화를 나타낸다. 여기서 는 학습 가능한 파라미터이다.
- : 손실 함수(loss function)이다.
- : 입력 이미지 , 프롬프트 파라미터 , 학습 가능한 모델 파라미터 를 입력으로 받는 모델 함수이다.
- : 타겟(목표) 출력이다.
- VPT의 목적 함수는 다음과 같다:
- Visual Instruction Tuning (VIT):
- VPT가 소수의 파라미터 최적화를 통해 대규모 언어 모델(LLM)을 개선하는 데 중점을 두는 반면, VIT는 모델의 지시 이해 능력을 향상시키는 것을 목표로 한다.
- 이 접근 방식은 InstructBLIP과 같은 최신 파운데이션 모델의 강력한 기능을 활용하여 모델이 지시를 효과적으로 해석하고 응답하도록 한다.
- 지시(Instructions)의 역할: 지시는 모델의 출력을 특정 응답 특성과 도메인 관련 지식에 맞게 형성하는 가이드라인 역할을 한다. 이를 통해 사람들은 모델의 행동을 모니터링하고 원하는 결과와 일치하는지 확인할 수 있다.
- 효율성: Instruction Tuning은 계산적으로 효율적이며, 광범위한 재훈련이나 아키텍처 변경 없이 LLM이 특정 도메인에 빠르게 적응할 수 있도록 한다.
- VIT의 목적 함수는 다음과 같다:
- : Instruction Tuning Module의 튜닝 가능한 파라미터 에 대한 최소화를 나타낸다.
- : 손실 함수(loss function)이다.
- (Optional Context): 이미지 캡션과 같이 입력 처리 방식이나 수행할 작업을 안내하는 설명적 또는 지시적 정보를 포함하는 보조 데이터이다.
- : 지시(Instruction) , 이미지 , 기타 컨텍스트(Optional Context) , 튜닝 가능한 파라미터 를 입력으로 받는 모델 함수이다.
- : 타겟(목표) 출력이다.
3.2. GPT-assisted Emotion Visual Instruction Data Generation
-
기존 방법의 한계점:
- 이전 연구들, 예를 들어 InstructBLIP 등은 특정 작업에 대해 데이터셋의 모든 이미지에 일관된 템플릿 기반의 지침(예: "이미지의 내용을 간략하게 설명하시오")을 사용했다.
- 이러한 '획일적(one-size-fits-all)' 접근 방식은 각 이미지의 고유한 특성을 충분히 포착하지 못하며, 미묘하고 모호한 감성 클래스의 구분이 필요한 감성 인식 작업에서는 최적의 성능을 내기 어렵다.
-
새로운 접근 방식의 필요성 및 개척:
- Emotion Visual Instruction Tuning 분야는 아직 초기 단계이기 때문에 감성 지침 데이터를 구축하기 위한 표준 벤치마크나 가이드라인이 부재하다.
- 본 연구는 Visual Instruction Tuning에서 보여준 기계 생성 지침의 성공에 기반하여, 기존 LLM(Large Language Model)을 활용한 감성 지침 데이터의 자가 생성(self-generation) 파이프라인을 최초로 제안한다.
- 이는 수동 주석(manual annotation)의 제약을 뛰어넘어, GPT-4를 활용하여 시각적 콘텐츠에 동적으로 상응하는 'Instance-wise' 맞춤형 지침 데이터를 생성한다.
-
감성 인식을 위한 핵심 시각 단서 식별:
- 시각 감성 인식(visual emotion recognition) 작업을 위한 지침 데이터 개발에 앞서, 어떤 시각적 단서들이 감성 식별에 중요한지에 대한 근본적인 질문에 답하는 것이 중요하다고 언급한다.
- 이에 따라 EmoSet 연구에서 얻은 통찰력을 바탕으로 다층적인 감성 속성들을 통합한다. 이 포괄적인 전략은 감성의 복잡한 본질과 일치하며, 모델이 시각적 감성 단서를 더욱 정확하고 전체적으로 해석하고 이해하는 능력을 크게 향상시킨다.
- 저수준(Low-level) 속성: 밝기(brightness), 색상(colorfulness) 등.
- 중간수준(Mid-level) 속성: 장면 유형(scene type), 객체 클래스(object class) 등.
- 고수준(High-level) 속성: 얼굴 표정(facial expressions), 인간 행동(human actions) 등.
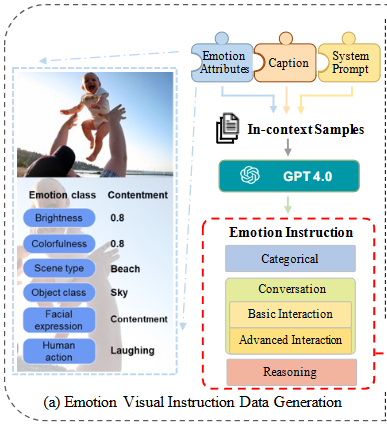
- GPT-assisted 감성 시각 명령 데이터 생성 파이프라인 (Fig. 4 (a) 참조):
-
GPT-4가 감성 지침 데이터를 생성하는 데 필수적인 세 가지 유형의 이미지 관련 문맥(context)이 입력된다.
-
(i)
Emotion Attributes(): 감정 클래스(예: contentment), 밝기(Brightness), 색상(Colorfulness), 장면 유형(Scene type), 객체 클래스(Object class), 얼굴 표정(Facial expression), 인간 행동(Human action)과 같은 다중 레벨의 감정 속성 목록이다. 이는 감정 해석의 주관성과 모호성을 제거하기 위해 통합된다. -
(ii)
Caption(): BLIP2 모델을 사용하여 생성된 이미지 캡션이다. -
(iii)
System Prompt: GPT-4가 특정 작업 요구사항을 이해하도록 설계된 지침. (예: 주어진 이미지를 보고 감정을 분석하라.) -
(iv)
seed examples(몇 가지 수동으로 설계된 예시): 인-콘텍스트 학습(in-context learning)을 위한 시드 예시로 사용되어 GPT-4에 쿼리된다. 이는 LLaVA와 같은 기존 연구의 'few-shot learning' 원리를 활용하여 모델의 이해도와 응답 정확도를 높인다.
-
-

- 생성되는 감성 지침 데이터의 유형 (대화 형식, Fig. 5 참조):
- 생성된 감성 지침 데이터는 세 가지 유형으로 구성되며, LLaVA의 이전 연구를 기반으로 대화 형식(dialogue format)을 따른다.
- 범주형(Categorical): 이미지의 연관 감성 클래스를 구조화된 형식으로 변환하여 감성 지침 데이터의 기초를 이룬다.
- 대화형(Conversation): GPT 어시스턴트가 이미지의 감성 속성에 초점을 맞춰 질문자와 상호작용하는 대화를 생성한다. 이는
Basic Interaction(단순하고 직접적인 특성)과Advanced Interaction(더 높은 대화 복잡성)의 두 가지 범주로 나뉜다. - 추론형(Reasoning): 시각적 콘텐츠를 넘어 모델이 심층적인 추론 질문을 생성하도록 유도한다. 대화의 신뢰성과 구조를 강화하기 위해 논리적 추론 단계와 함께 상세한 예시가 포함된다.
- 생성된 감성 지침 데이터는 세 가지 유형으로 구성되며, LLaVA의 이전 연구를 기반으로 대화 형식(dialogue format)을 따른다.
3.3. Emotion Visual Instruction Tuning
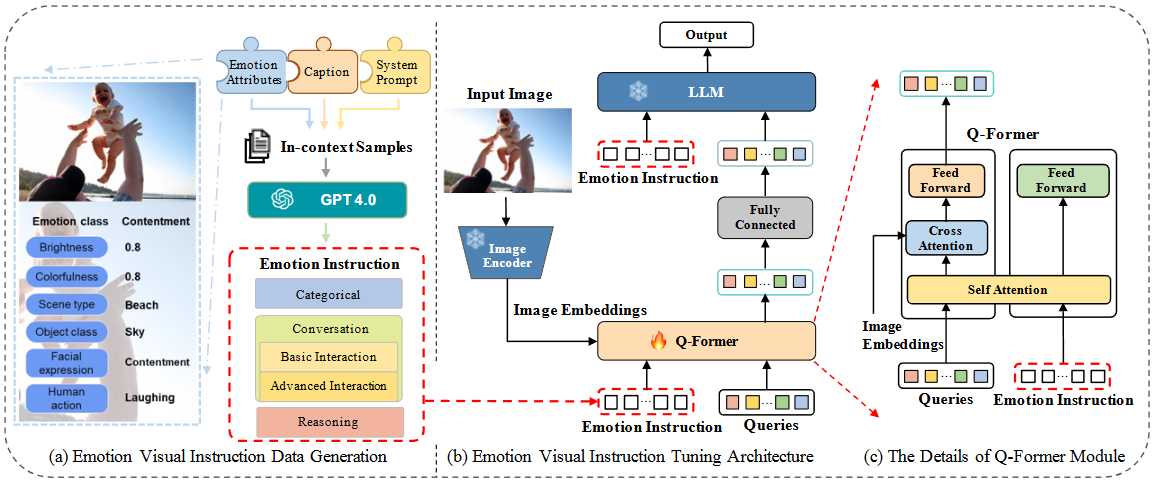
-
(a) 감정 시각 지시 데이터 생성 (Emotion Visual Instruction Data Generation)
- 시각 감정 인식 분야에서 주석이 달린 지시 데이터의 부족 문제를 해결하기 위해 고안된 새로운 GPT-지원 파이프라인. (3.2 절에서 자세히 설명하였으므로 간단히 넘어감)
-
(b) 감정 시각 지시 튜닝 아키텍처 (Emotion Visual Instruction Tuning Architecture)
- 이 아키텍처는 InstructBLIP을 기반으로 하며, LLM의 기존 지식을 감정 이해 도메인에 맞춰 조정하는 것을 목표로 한다.
- Image Encoder (고정): 입력 이미지에서 시각적 특징을 추출하는 역할을 한다. 이 인코더는 학습 과정에서 파라미터가 고정되어 있다.
- Image Embeddings: Image Encoder를 통해 추출된 이미지 특징을 임베딩 형태로 변환한 결과이다.
- Q-Former (학습 가능): InstructBLIP의 Instruction-aware Q-Former Module을 활용한다. 이는 감정 지시 토큰(
Emotion Instruction)과 이미지 임베딩(Image Embeddings), 그리고 초기화된 쿼리(Queries)를 입력으로 받아, 주어진 지시에 맞게 이미지에서 관련 특징을 추출하는 학습 가능한 모듈이다. 이 모듈은 감정 지시와 쿼리 임베딩을 Self-Attention 레이어 내에서 통합하여 시각 정보를 LLM의 지시 따르기 요구 사항과 일치시킨다. - Fully Connected: Q-Former에서 추출된 특징들을 LLM에 전달하기 위해 연결하는 레이어이다.
- LLM (고정): Large Language Model로, Q-Former에서 처리된 시각 정보와 감정 지시를 받아 최종 출력을 생성한다. 이 모델 역시 학습 과정에서 파라미터가 고정되어 있어 효율적인 도메인 적응을 가능하게 한다.
- Output: 최종적으로 생성된 감정 관련 응답이다.
-
(c) Q-Former 모듈의 상세 설명 (The Details of Q-Former Module)
- Q-Former는 EmoVIT 아키텍처의 핵심 구성 요소로,
Emotion Instruction과Image Embeddings,Queries간의 복잡한 상호 작용을 통해 태스크별 특징 추출을 최적화한다. - Emotion Instruction: (a)에서 생성된 감정 지시 토큰들이다.
- Queries: InstructBLIP의 사전 훈련된 Q-Former에서 초기 생성된 학습 가능한 쿼리들이다. 이들은 어텐션 매커니즘에 의해
Emotion Instruction과Image Embeddings의 정보를 순차적으로 융합하여, 감정에 대한 텍스트 정보와 이미지 정보 사이의 도메인 갭을 연결하는 브릿지 역할을 한다. - Self Attention:
Queries와Emotion Instruction토큰들이 서로 간의 관계를 학습하여 내부적인 표현을 강화하는 부분이다. 이를 통해 지시의 의미론적 정보를 쿼리에 주입한다. - Cross Attention:
Image Embeddings와Self Attention을 통해 강화된Queries및Emotion Instruction이 상호 작용하는 부분이다. 이 과정에서 Q-Former는 주어진 감정 지시에 가장 적합한 시각적 특징을 이미지 임베딩에서 선택적으로 추출한다. - Feed Forward: 어텐션 레이어 이후에 적용되는 신경망으로, 특징 변환 및 최종 출력을 위해 사용된다.
- 이러한 상호작용을 통해 Q-Former는 LLM이 감정 관련 지시를 효과적으로 따를 수 있도록 시각 정보를 추출하고 정렬하는 핵심적인 역할을 수행한다.
- Q-Former는 EmoVIT 아키텍처의 핵심 구성 요소로,
