논문: https://arxiv.org/pdf/2404.05052
1. Introduction
(생략)
2. Related Works
(생략)
3. Dataset and Benchmark
3.1. Instruction-following FABA dataset
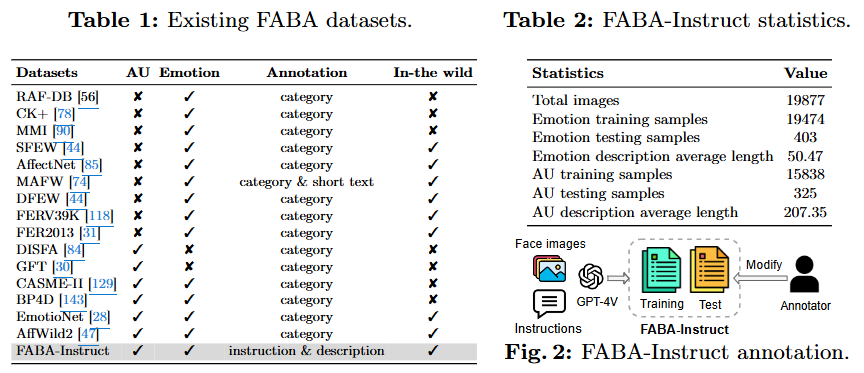
-
FABA 데이터셋의 필요성:
- 기존 FABA 데이터셋은 MLLM의 instruction tuning을 수행하기에 적합하지 않다는 문제가 있다.
- 주된 이유는 주석(annotation)이 너무 추상적이거나(coarse-grained), 감정 묘사가 제한적이거나(limited emotion descriptions), AU(Action Unit)와 같은 세부적인 주석 작업이 노동 집약적이고 비용이 많이 들기 때문이다.
- 따라서, 세밀한 감정과 AU 설명을 제공하며 MLLM이 "지시(instruction)"에 따라 행동하도록 훈련할 수 있는 새로운 데이터셋의 필요성이 대두되었다.
-
FABA-Instruct의 특징 및 기여:
- 최초의 Instruction-following FABA 데이터셋: MLLM의 instruction tuning을 위해 특별히 설계된 첫 번째 FABA 데이터셋이다. 이는 FABA 연구에 MLLM의 이점을 가져오는 중요한 단계이다.
- 두 가지 FABA 태스크 포함: 얼굴 감정 인식(Facial Emotion Recognition, FER)과 액션 유닛 인식(Action Unit Recognition, AUR)의 두 가지 핵심 FABA 태스크를 다룬다.
- 세밀한(Fine-grained) 주석: GPT-4V를 활용하여 19,877개의 'in-the-wild' 얼굴 이미지에 약 30,000개의 세밀한 감정 및 AU 주석을 제공한다. 기존의 이산적인 카테고리(예: 행복, 슬픔)나 이진 벡터(AU 활성화 여부)와 달리, 자연어 설명을 통해 복잡하고 미묘한 얼굴 행동을 포착한다.
- 추론 능력: 이 데이터셋의 주석은 단순한 레이블을 넘어, 얼굴 움직임에 대한 추론 과정과 그 움직임이 어떤 감정으로 이어지는지에 대한 설명을 포함한다(Fig. 1, Fig. 3, Fig. 4 참조). 이는 모델이 단순 분류를 넘어 "이해"하고 "설명"하는 능력을 개발하는 데 도움을 준다.
- In-the-wild 이미지: 실제 환경에서 촬영된 다양한 얼굴 이미지(AffectNet에서 샘플링)를 사용하여 모델의 일반화 능력을 향상시키는 데 기여한다.
-
데이터 구축 과정 (Fig. 2 참조):
- 이미지 샘플링 및 전처리: 대규모 in-the-wild 얼굴 표정 데이터베이스인 AffectNet에서 약 19,877개의 얼굴 이미지를 샘플링하고, Dlib 라이브러리를 사용하여 얼굴 정렬 및 크롭을 수행한다.
- GPT-4V 기반 주석 생성: 100개의 신중하게 고안된 템플릿(예: "이 얼굴의 감정은 무엇인가요?", "이 얼굴에 나타난 액션 유닛을 설명해주세요?")을 사용하여 GPT-4V [76, 110]에 쿼리하여 감정과 AU에 대한 설명을 생성한다.
- 주석 필터링 및 검수: 낮은 해상도나 가림(occlusion) 문제로 인해 유용하지 않은 주석은 필터링하고, 특히 테스트 세트의 주석은 부정확성을 줄이기 위해 수동으로 검수 및 수정한다.
-
기존 데이터셋과의 차별점 (Table 1 참조):
- FABA-Instruct는 감정 및 AU를 모두 다루면서, 실제 환경(in-the-wild) 이미지에 대한 instruction-following 주석을 제공하는 최초의 데이터셋이다.
- 기존 데이터셋은 대부분 특정 태스크에만 초점을 맞추거나(task-specific), 통제된 실험실 환경에서 수집되었으며(laboratory collected), instruction-following 형태의 주석은 제공하지 않는다.


- 감정/AU 설명 분석 (Fig. 3, Fig. 4 참조):
- 감정 설명의 풍부함:
- 기존 7가지 기본 감정 카테고리(행복, 슬픔 등)는 복합적이고 미묘한 감정(예: 슬픔과 억지 미소가 섞인 표정), 과장된 감정, 감정의 정도, 정의되지 않은 감정(예: 걱정, 회의감) 등을 포착하기 어렵다.
- FABA-Instruct의 자연어 감정 설명은 이러한 문제들을 해결하며 훨씬 더 풍부한 감정적 뉘앙스를 표현할 수 있다.
- AU 설명의 깊이:
- 기존 AU 데이터셋의 이진 벡터 방식은 AU 활성화 정도나 원인(어떤 근육 움직임인지), 결과(어떤 감정으로 이어지는지), 그리고 다른 AU나 감정과의 관계에 대한 설명을 제공하지 않는다.
- FABA-Instruct의 AU 설명은 "작은 찡그림"이나 "까마귀 발자국"과 같은 세부적인 묘사를 통해 AU 활성화의 정도를 포착하고, "웅크림이나 찌푸림을 나타냄", "강한 감정과 관련됨"과 같이 AU 간 또는 AU와 감정 간의 추론 능력을 보여주어 모델의 해석 가능성을 높인다.
- 감정 설명의 풍부함:
3.2. Instruction-following FABA benchmark
-
배경 및 동기:
- 기존 FABA 접근 방식은 주로 안면 감정 인식(FER)이나 액션 유닛 인식(AUR)을 다중 클래스 또는 다중 레이블 분류 문제로 간주하는 판별 모델(discriminative models)에 기반하고 있다.
- 이러한 모델들은 감정 묘사가 거칠고(coarse-grained), 복합적인 감정을 설명하기 어렵고, 추론 능력이 부족하다는 한계가 있었다.
- 최근 MLLMs는 대규모 사전 학습 후 명령어 튜닝(instruction tuning)을 통해 미세하고 복잡한 시각적 단서에 대한 설명 및 추론 능력을 보여주며 성공을 거두었다. 이는 판별 작업을 시퀀스-투-시퀀스 생성 작업으로 전환하는 가능성을 제시했다.
- 그러나 MLLM을 FABA에 직접 활용하기에는 다음과 같은 세 가지 주요 과제가 존재했다:
- 적합한 FABA 데이터셋 부족: 명령어 튜닝을 위한 fine-grained 주석을 가진 데이터셋이 없었다.
- MLLM 평가의 어려움: FABA 작업에 특화된 언어 사용을 고려하지 않은 언어 중심의 기존 MLLM 평가 지표가 존재했다.
- 안면 사전 지식 활용 부족: 기존 MLLM의 비전 인코더가 안면 특징(예: 랜드마크)을 잘 포착하지 못하여, 안면 사전 지식의 영향이 충분히 탐구되지 않았다.
- 이러한 문제들을 해결하기 위해, 저자들은 명령어 따르기 FABA 데이터셋인 "FABA-Instruct"를 구축하고, 이를 기반으로 "FABA-Bench"라는 새로운 벤치마크를 제안했다.
-
FABA-Bench의 목적:
- FABA-Bench는 명령어 따르기 FABA 작업에서 다양한 MLLM의 시각적 인식(visual recognition) 성능과 텍스트 생성(text generation) 성능을 모두 평가하는 것을 목표로 한다.
- 기존의 Natural Language Generation (NLG) 지표(예: BLEU, ROUGE)는 생성된 텍스트의 일관성과 유창성에만 초점을 맞추어 FABA 관련 고려 사항을 무시한다.
- 기존 FABA 지표(예: 정확도, F1 score)는 모델의 인식 성능에만 초점을 맞추고 추론 및 설명과 같은 텍스트 측면의 평가가 부족하다.
- FABA-Bench는 이러한 두 가지 유형의 지표가 가진 단점을 보완하기 위해 REGE (REcognition and GEneration) 점수라는 새로운 지표를 도입한다.
-
REGE (REcognition and GEneration) 점수:
- REGE 점수는 모델의 텍스트 생성 능력과 이미지 인식 능력을 동시에 고려하여 정의된다.
- 수식은 다음과 같다:
$$ S{\text{rege}} = S{\text{re}} + S_{\text{ge}} $$- 여기서 는 REGE 점수이다.
- 는 인식 성능(Recognition performance)을 나타낸다.
- 는 생성 성능(Generation metric)을 나타낸다.
- 각 항에 대한 자세한 설명은 다음과 같다:
- (인식 성능):
- FER (Facial Emotion Recognition) 작업: 7가지 기본 감정 범주(행복, 슬픔, 분노, 두려움, 혐오, 놀라움, 중립) 중 하나로 안면 이미지를 분류한다.
- 모델이 생성한 텍스트에서 각 감정 범주의 동의어 빈도를 계산하여 가장 높은 빈도를 가진 감정을 해당 텍스트의 감정 레이블로 간주한다.
- 이후 실제 레이블과의 정확도(accuracy)를 계산하여 인식 성능을 평가한다.
- AUR (Action Unit Recognition) 작업: 하나 또는 여러 개의 AU 범주로 안면 이미지를 분류한다.
- 기존 연구[28, 143]를 따라 12가지 AU를 평가 대상으로 선정한다.
- F1 점수(F1 score)를 계산하여 AU 인식 성능을 평가한다.
- FER (Facial Emotion Recognition) 작업: 7가지 기본 감정 범주(행복, 슬픔, 분노, 두려움, 혐오, 놀라움, 중립) 중 하나로 안면 이미지를 분류한다.
- (생성 성능):
- ROUGE 점수(ROUGE score)를 사용한다. ROUGE는 생성된 텍스트와 참조 텍스트 간의 n-그램(n-gram), 단어 시퀀스(word sequences), 단어 쌍(word pairs)의 중복도를 비교하여 텍스트의 일관성과 유창성을 평가하는 자연어 생성(NLG) 분야의 일반적인 지표이다.
- (인식 성능):
4. EmoLA: An Instruction-tuned MLLM for FABA
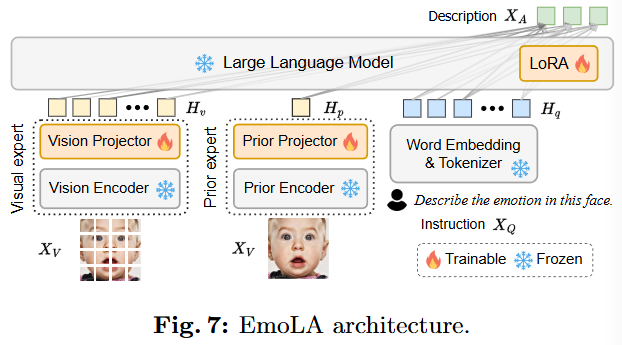
해당 이미지는 EmoLA(Emotion-aware Low-rank Adaptation) 모델의 전체 아키텍처를 보여준다. EmoLA는 얼굴 감정 행동 분석(Facial Affective Behavior Analysis, FABA)을 위해 Instruction Tuning 방식을 활용한 멀티모달 대규모 언어 모델(Multi-modal Large Language Model, MLLM)이다. 이 모델은 입력된 얼굴 이미지와 텍스트 지시(Instruction)를 바탕으로 해당 얼굴의 감정 또는 Action Unit(AU)에 대한 상세한 설명을 생성하는 것을 목표로 한다.
-
입력 (, ):
- Face Image (): 분석 대상이 되는 얼굴 이미지이다. 왼쪽 Vision Expert와 중앙 Prior Expert 모두 이 이미지를 입력으로 받는다.
- Instruction (): 사용자가 모델에 내리는 지시(예: "Please describe the emotion in this face.")로, 모델이 어떤 종류의 분석을 수행해야 하는지 알려주는 텍스트 프롬프트이다.
-
Visual Expert:
- Vision Encoder (Frozen): 이 모듈은 CLIP-L/14 [94]와 같은 사전 학습된 이미지 인코더이다. 일반적인 이미지-텍스트 쌍으로 학습되었기 때문에 이미지에서 일반적인 시각적 특징을 추출하는 데 탁월하다. 하지만 얼굴의 미세한 구조 정보나 FABA 태스크에 특화된 특징은 놓칠 수 있다는 한계가 있다. 파란색 눈꽃 아이콘은 이 모듈의 파라미터가 훈련 중에 고정(Frozen)됨을 의미한다.
- Vision Projector (Trainable): Vision Encoder에서 추출된 시각적 특징들을 언어 모델이 이해할 수 있는 시각 임베딩 토큰()으로 변환하는 역할을 한다. 이 모듈은 두 개의 레이어로 구성된 MLP(Multi-Layer Perceptron)이며, 빨간색 불꽃 아이콘은 이 모듈의 파라미터가 훈련 중에 학습 가능(Trainable)함을 의미한다.
-
Prior Expert:
- Prior Encoder (Frozen): 이 모듈은 Insightface [7]의 사전 학습된 얼굴 랜드마크(facial landmark) 감지기와 같이 얼굴 관련 데이터셋으로 학습된 인코더이다. Vision Encoder가 놓칠 수 있는 얼굴 구조 정보(facial prior knowledge)를 보다 정확하게 포착하기 위해 도입되었다. 입력 이미지 로부터 얼굴 랜드마크 Prior Feature ()를 추출한다. 파란색 눈꽃 아이콘은 이 모듈의 파라미터가 고정됨을 의미한다.
- Prior Projector (Trainable): Prior Encoder에서 추출된 얼굴 랜드마크 Prior Feature 를 언어 모델의 토큰 임베딩 공간으로 매핑하여 얼굴 Prior 토큰()을 생성한다. 이는 다음과 같은 수식으로 표현된다.
- : Facial Prior Token.
- : Prior Projector를 나타내는 MLP (Multi-Layer Perceptron) 함수.
- : Prior Encoder 에 의해 추출된 Facial Prior Feature.
- : Prior Projector의 학습 가능한 파라미터.
빨간색 불꽃 아이콘은 이 모듈의 파라미터가 훈련 중에 학습 가능함을 의미한다.
-
Language Expert:
- Word Embedding & Tokenizer (Frozen): 입력 Instruction 를 언어 모델이 처리할 수 있는 언어 임베딩 토큰() 시퀀스로 변환한다. 이 모듈의 파라미터는 고정되어 있다.
-
Large Language Model (LLM) (Frozen with LoRA):
- LLM Decoder (Frozen, Vicuna [15]): Vicuna와 같은 대규모 언어 모델을 디코더로 활용한다. Visual Expert의 , Prior Expert의 , 그리고 Language Expert의 토큰들을 입력으로 받아 최종적인 설명 텍스트 를 생성한다. 이 LLM 자체의 파라미터는 대부분 고정되어 있다.
- LoRA (Low-Rank Adaptation) (Trainable): LLM 전체를 미세 조정하는 대신, LLM 내의 특정 dense layer에 낮은 랭크를 가지는 추가적인 행렬()을 삽입하여 효율적으로 훈련시키는 기법이다 [39]. 이를 통해 메모리 및 계산 비용을 크게 줄이면서도 효과적인 성능 향상을 달성한다. LoRA 모듈의 파라미터는 학습 가능하다.
-
Description (): 모델이 Instruction 에 따라 생성한 FABA 관련 상세 텍스트 설명이다.
-
FABA-Instruct 데이터셋 및 FABA-Bench 벤치마크 활용:
EmoLA는 GPT-4V를 활용하여 구축된 FABA-Instruct 데이터셋을 사용하여 Instruction Tuning을 거친다. 이 데이터셋은 감정과 AU에 대한 상세하고 추론적인 설명을 포함하며, 기존의 이산적인 감정 카테고리나 이진 AU 벡터보다 훨씬 풍부한 정보를 제공한다. 또한, EmoLA는 인식 능력과 텍스트 생성 능력을 모두 평가하는 새로운 메트릭인 REGE를 사용하는 FABA-Bench 벤치마크에서 평가된다.
5. Experiments
-
실험 설정 및 구현 세부 사항:
- 기반 모델: EmoLA는 LLaVA-1.5 7b 모델을 기반으로 초기화된다.
- 학습 대상: 전체 MLLM(Multi-modal Large Language Model)을 파인튜닝하는 대신, 효율성을 위해 LoRA (Low-Rank Adaptation) 모듈과 Facial Prior Projector (얼굴 사전 지식 투영기)만 튜닝한다.
- 최적화: AdamW 옵티마이저를 사용하여 1 epoch 동안 학습하며, 초기 학습률은 로 설정된다. LoRA의 랭크는 128이다.
- 하드웨어: 모든 실험은 8개의 A6000 GPU를 사용하여 수행된다.
-
데이터셋 및 평가 프로토콜:
- 기존 FABA 데이터셋: Facial Emotion Recognition (FER)을 위한 RAF-DB와 Action Unit Recognition (AUR)을 위한 BP4D, DISFA, GFT의 네 가지 전통적인 데이터셋에서 실험한다.
- FABA-Instruct 데이터셋: 제안하는 FABA-Instruct 데이터셋을 사용하여 FER 및 AUR 태스크에 대한 모델 성능을 평가한다.
5.1 Comparison on traditional FER and AUR datasets
5.1.1. FER (Facial Emotion Recognition) 실험 세팅
-
목표: 얼굴 이미지로부터 감정을 인식하는 task이다. EmoLA는 기존의 이산적인 감정 카테고리(discrete emotion categories) 분류를 넘어, 감정에 대한 세밀한 묘사를 생성하는 것을 목표로 하지만, 전통적인 FER 데이터셋에서는 분류 성능으로 평가한다.
-
사용 데이터셋:
- RAF-DB [56]: 이 연구에서 전통적인 FER task 평가를 위해 사용된 유일한 감정 데이터셋이다.
- 특징: 29,672개의 "in-the-wild"(실제 환경) 얼굴 이미지를 포함한다. 40명의 주석가(annotator)에 의해 7가지 단일 레이블(single-label) 및 두 가지 복합 감정 카테고리(compound emotion categories)로 주석이 달렸다. EmoLA는 주로 7가지 단일 레이블 감정(예: happiness, sadness, anger, fear, disgust, surprise, neutral) 인식에 중점을 두어 비교되었다.
- RAF-DB [56]: 이 연구에서 전통적인 FER task 평가를 위해 사용된 유일한 감정 데이터셋이다.
-
주석(Annotation) 및 출력 방식:
- 기존 RAF-DB 데이터셋은 이미지에 대한 감정 클래스 인덱스나 카테고리 레이블을 제공한다.
- EmoLA는 이 레이블들을 "Happy"와 같은 자연어 형태의
instruction-following출력으로 변환하여 사용한다. 즉, 모델은 특정 감정 클래스를 출력하도록 학습된다.
-
평가 지표:
- Accuracy (정확도): 모델이 예측한 감정 클래스가 실제 감정 클래스와 일치하는 비율을 사용하여 인식 성능을 평가한다.
-
훈련 및 테스트 프로토콜:
- Original Dataset Division: RAF-DB의 원본 데이터셋 분할 프로토콜(즉, 훈련 세트와 테스트 세트가 미리 정해져 있는 방식)에 따라 훈련 및 테스트를 수행한다. 이는 기존 연구들과의 공정한 비교를 가능하게 한다.
5.1.2. AUR (Action Unit Recognition) 실험 세팅
-
목표: 얼굴 이미지에서 얼굴 근육의 특정 움직임인 액션 유닛(AU)의 활성화 여부를 인식하는 task이다. EmoLA는 AU 레이블뿐만 아니라 각 AU에 대한 설명 및 추론 과정을 생성하는 것을 목표로 하지만, 전통적인 AUR 데이터셋에서는 AU 활성화 여부 인식 성능으로 평가한다.
-
사용 데이터셋:
- BP4D [143]:
- 특징: 41명의 피험자(23명 여성, 18명 남성)로부터 수집된 328개의 비디오를 포함하는 자발적인(spontaneous) 얼굴 AU 데이터셋이다. 총 140,000프레임에 대해 12가지 AU(AU1, 2, 4, 6, 7, 10, 12, 14, 15, 17, 23, 24)의 주석이 포함되어 있다.
- DISFA [84]:
- 특징: 26명의 피험자(12명 여성, 14명 남성)로부터 수집된 130,000프레임으로 구성된다. AU 강도(intensity)가 0부터 5까지 주석으로 달려 있다. [148]의 방식을 따라, 강도가 2 이상인 AU는 활성화된 것으로 간주된다. 평가에는 12가지 AU 중 8가지 AU(AU1, 2, 4, 6, 9, 12, 25, 26)가 사용된다.
- GFT [30]:
- 특징: 32개의 3인 그룹에서 96명의 참가자를 포함한다. 10가지 AU(AU1, 2, 4, 6, 10, 12, 14, 15, 23, 24)가 평가를 위해 선택되었으며, 이는 머리 움직임과 가려짐(occlusion)으로 인한 어려움을 고려한 것이다. 총 108,000개의 훈련 이미지와 24,600개의 평가 이미지를 포함한다.
- BP4D [143]:
-
주석(Annotation) 및 출력 방식:
- 기존 AUR 데이터셋은 각 AU의 활성화 여부를 나타내는 이진 벡터(binary vector)를 제공한다.
- EmoLA는 이를 "AU1, AU4"와 같은 자연어 형태의
instruction-following출력으로 변환하여 사용한다. 모델은 활성화된 AU 레이블을 직접 생성하도록 학습된다. EmoLA는 양성 레이블(positive labels)만을 예측하여 음성 레이블로 인한 불균형 문제를 완화하는 전략을 사용한다.
-
평가 지표:
- F1 score: 다중 레이블 분류(multi-label classification) task인 AU 인식 성능을 평가하기 위해 F1 score를 사용한다. 이는 정밀도(precision)와 재현율(recall)의 조화 평균으로, AU 인식과 같이 클래스 불균형이 존재할 수 있는 task에 적합하다. 각 AU에 대한 F1 score를 계산한 후, 이를 평균하여 최종 성능을 나타낸다.
-
훈련 및 테스트 프로토콜:
- BP4D 및 DISFA:
subject-exclusive 3-fold cross-validation방식을 사용한다. 이는 특정 피험자의 이미지가 훈련 세트와 테스트 세트에 동시에 나타나지 않도록 데이터셋을 세 부분으로 나누어 교차 검증하는 방식이다. 이 방법은 모델이 학습되지 않은 새로운 피험자의 얼굴에서도 AU를 잘 인식하는지, 즉 일반화 능력을 평가하는 데 중요하다. - GFT: GFT의 원본 데이터셋 분할 프로토콜에 따라 훈련 및 테스트를 수행한다.
- BP4D 및 DISFA:
5.2 Comparison on FABA-Bench
- 비교 대상 모델: LLaVA-1.5 [70], MiniGPT4-V2 [10], Shikra [11], mPLUG-Owl2 [131]와 같은 기존 MLLM들과 이 논문에서 제안하는 EmoLA 모델의 성능을 비교한다.
- 평가 방법:
- FABA-Bench는 얼굴 감정 행동 분석(FABA) 작업에 특화된 벤치마크로, 시각적 인식 능력(visual recognition)과 텍스트 생성 능력(text generation)을 동시에 평가하도록 설계되었다.
- 평가 지표로는 REGE(REcognition and GEneration) 점수를 도입했다. REGE 점수()는 인식 성능()과 생성 성능()을 합산하여 계산한다 ().
- 인식 성능(): 감정 인식(FER) 작업에서는 정확도(accuracy)를, AU(Action Unit) 인식 작업에서는 F1 스코어를 사용한다.
- 생성 성능(): 텍스트 생성의 일관성과 유창성을 평가하는 데 주로 사용되는 ROUGE 점수를 사용한다.
- 주요 발견:
- EmoLA는 다른 MLLM들과 비교했을 때 두 가지 FABA 작업(감정 인식 및 AU 인식) 모두에서 가장 좋은 결과를 달성했다.
- 특히 EmoLA는 LLaVA-1.5에 비해 훨씬 적은 수의 파라미터를 튜닝했음에도 더 나은 성능을 보였다.
- EmoLA의 성공 요인:
- 효율적인 튜닝: 전체 LLM 디코더를 튜닝하는 대신, LoRA(Low-Rank Adaptation) 모듈을 사용해 파라미터 효율적인 미세 튜닝을 수행했다. LoRA는 모델 가중치 적응이 낮은 내재 랭크(low intrinsic rank)를 가진다는 사실에 착안하여, 밀집 레이어의 잔차에 대한 낮은 랭크로 인수분해된 행렬만 최적화한다.
- 얼굴 사전 전문가(Facial Prior Expert) 모듈: 이 모듈은 CLIP [94]과 같은 범용 비전 인코더가 놓칠 수 있는 얼굴 랜드마크와 같은 얼굴 구조 정보(facial structure knowledge)를 추출하여 보완적인 정보를 제공한다. 이는 FABA 작업의 인식 능력 향상에 기여한다.
- REGE 지표의 중요성: 기존 MLLM 평가 지표들은 주로 언어 생성에 중점을 두어 FABA 작업의 특수성을 반영하지 못했다. REGE 지표는 인식 능력과 생성 능력을 모두 고려함으로써 MLLM의 FABA 작업 성능을 더욱 포괄적으로 평가할 수 있게 한다.
