project: https://tanshuai0219.github.io/EDTalk/
1. Introduction
-
배경 및 기존 연구의 한계점:
- Talking head animation은 교육, 영화 제작, 가상 디지털 휴먼 등 다양한 분야에서 중요성이 커지고 있는 연구 분야이다.
- 기존의 방법론들은 talking head 비디오를 전체적인 방식(holistic manner)으로 생성하여 입 모양, 머리 자세, 감정 표현과 같은 다양한 얼굴 움직임에 대한 세밀하고 개별적인 제어(fine-grained individual control)가 부족하다.
- 또한, 대부분의 기존 접근 방식은 오디오 또는 비디오 중 한 가지 구동 소스에만 초점을 맞춰 다중 모달(multimodal) 환경에서의 적용 가능성이 제한적이다.
-
얼굴 특징 분리(Facial Disentanglement)의 도전 과제:
- 얼굴 움직임은 복잡하게 상호작용하기 때문에(예: 입 모양이 감정 표현에 큰 영향을 미침) 얼굴 역학 전체를 개별 구성 요소에 전념하는 별개의 잠재 공간으로 분리하는 것은 쉽지 않다.
- 기존 얼굴 분리 연구들([31, 38, 58, 71, 78])은 다음과 같은 세 가지 주요 한계를 가진다:
- (1) 외부 정보 및 사전 지식에 대한 과도한 의존: 구강 공간 분리를 위해 외부 오디오 데이터(대조 학습)나 사전 정의된 6D 자세 계수(3D 얼굴 재구성 모델)에 크게 의존한다. 이는 데이터 요구량을 증가시키고 데이터 전처리 과정을 복잡하게 하며, 정보의 부정확성은 모델 오류로 이어질 수 있다.
- (2) 내부 제약 없는 잠재 공간 분리: 각 잠재 공간이 해당 구성 요소의 움직임만을 담당하고 다른 구성 요소의 간섭 없이 작동하는 것을 보장하는 내부 공간 간 제약(inter-space constraints)이 부족하다. 이로 인해 불완전한 분리, 훈련 복잡성, 효율성 감소 및 성능 저하가 발생한다.
- (3) 비효율적인 훈련 전략: 새로운 서브스페이스를 분리할 때 전체 네트워크를 처음부터 다시 훈련해야 하는 경우가 많아 높은 시간과 계산 비용이 발생한다.
-
EDTalk의 목표 및 핵심 아이디어:
- 이러한 문제점을 해결하기 위해 EDTalk는 입 모양, 머리 자세, 감정 표현을 정밀하게 제어할 수 있는 효율적인 분리(Efficient Disentanglement) 프레임워크를 제안한다.
- 핵심 통찰은 분리된 공간의 요구 사항에 있다:
- (a) 분리된 공간은 서로 독립적(disjoint)이어야 하며, 각 공간은 해당 구성 요소의 움직임만을 포착하고 다른 공간의 간섭을 받지 않아야 한다. 이는 새로운 공간을 분리할 때 기존 훈련된 모델에 영향을 미치지 않아 처음부터 다시 훈련할 필요가 없게 만든다.
- (b) 일단 비디오 데이터로부터 분리된 공간은 오디오 입력과 공유될 수 있도록 저장되어야 한다.
- 이를 위해, EDTalk는 전체 움직임 공간을 입, 자세, 표현을 나타내는 세 가지 고유한 컴포넌트 인지 잠재 공간(component-aware latent spaces)으로 혁신적으로 분리하며, 각 공간은 학습 가능한 기저(learnable bases)들로 특징 지어진다.
- 다른 잠재 공간 간의 간섭을 방지하기 위해, 기저들 간의 직교성(orthogonality)을 공간 내(intra-space)뿐만 아니라 공간 간(inter-space)에도 강제한다.
- 사전 정보 없이 분리를 달성하기 위해 교차 재구성(cross-reconstruction) 및 자기 재구성 보완 학습(self-reconstruction complementary learning)을 포함하는 점진적 훈련 전략을 도입한다. 이 훈련 과정은 경량의 Latent Navigation 모듈만을 훈련하고 다른 무거운 모듈의 가중치를 고정하여 효율성을 높인다.
- 분리된 잠재 공간의 기저 세트를 해당 은행(banks)에 저장하여 오디오 구동 talking head 생성을 위한 사전 시각적 지식(visual priors)으로 활용한다.
- 각 공간의 특성을 고려하여 Audio-to-Motion 모듈을 제안하며, 이는 오디오 인코더를 사용하여 립 모션을 오디오와 동기화하고, 정규화 흐름(normalizing flows)을 사용하여 확률적이고 사실적인 자세를 생성하며, 오디오 및 텍스트에서 감정적 단서를 추출하여 감정 표현을 유도한다.
-
주요 기여:
- 입 모양, 머리 자세, 감정 표현에 대한 정밀한 제어를 가능하게 하는 효율적인 분리 프레임워크 EDTalk를 제시한다.
- 직교 기저(orthogonal bases)와 효율적인 훈련 전략을 도입하여 세 가지 공간의 완전한 분리를 성공적으로 달성한다. 각 공간의 특성을 활용하여 오디오 구동 talking face 생성을 위한 Audio-to-Motion 모듈을 구현한다.
- 광범위한 실험을 통해 EDTalk가 정량적, 정성적 평가 모두에서 경쟁 방법론들을 능가함을 입증한다.
2. Related Works
-
2.1 얼굴 표정 분리(Disentanglement on the face)
- 얼굴 움직임(입 모양, 머리 자세, 감정 표현)은 복합적으로 연결되어 있어 개별적으로 제어하기 어렵다.
- 기존 연구들(PC-AVS, PD-FGC, TH-PAD, DPE)은 다음과 같은 한계를 가진다.
- 외부 정보에 대한 과도한 의존: 입 모양을 분리하기 위해 외부 오디오 데이터나 3D 얼굴 재구성 모델에서 추출한 6D 자세 계수와 같은 외부 정보에 크게 의존한다. 이는 데이터 요구량을 증가시키고 전처리 과정을 복잡하게 하며, 정보의 부정확성은 모델 오류로 이어진다.
- 불완전한 분리: 각 잠재 공간이 해당 구성 요소만 처리하도록 하는 내부 제약이 부족하여, 다른 구성 요소와의 간섭이 발생하고 이는 훈련 복잡성, 효율성 저하 및 성능 감소를 야기한다.
- 비효율적인 훈련 전략: 새로운 하위 공간을 분리할 때 전체 네트워크를 처음부터 다시 훈련해야 하는 경우가 많아 시간 및 계산 비용이 많이 든다.
- EDTalk는 이러한 문제들을 해결하기 위해 다음과 같은 방법을 제안한다.
- 효율적인 분리 접근 방식: 입, 머리 자세, 감정 표현을 개별 구성 요소로 분리하여 각기 다른 소스로 제어할 수 있도록 한다.
- 통합된 제너레이터 사용: 하나의 통합된 제너레이터만 필요하며, 새로운 분리 공간을 탐색할 때 최소한의 추가 리소스만 요구한다.
-
2.2 오디오 기반 말하는 얼굴 생성(Audio-driven Talking Head Generation)
- 이 분야는 크게 두 가지 방식으로 나뉜다.
- 중간 표현 기반 방법: 오디오에서 랜드마크나 3DMM 파라미터와 같은 중간 표현을 예측한 후, 이 표현을 바탕으로 이미지를 합성한다.
- 한계: 중간 표현을 얻는 과정이 노동 집약적이고 시간이 많이 소요되며, 얼굴 움직임의 세부 묘사가 제한적이다. 또한, 두 하위 모듈을 개별적으로 훈련할 경우 오류가 누적될 수 있다.
- 재구성 기반 방법: 인코더를 통해 다양한 모달리티(오디오, 이미지)에서 특징을 추출하고, 이를 통합하여 말하는 얼굴 영상을 종단 간(end-to-end) 방식으로 재구성한다.
- EDTalk는 이 접근 방식을 따르며, Wav2Lip, Zhou et al. (2021)과 같은 기존 방법들의 한계점을 보완한다.
- 기존 방법들이 자연스러운 움직임의 비결정론적 특성(non-deterministic nature)을 간과하는 경향이 있는데, EDTalk는 확률론적 모델을 사용하여 머리 움직임의 분포를 설정한다.
- 또한, 기존 방법들은 얼굴 표정(facial expressions)을 고려하지 않아 현실감을 떨어뜨릴 수 있지만, EDTalk는 이를 모델에 통합하여 현실감을 향상시키는 것을 목표로 한다.
- 중간 표현 기반 방법: 오디오에서 랜드마크나 3DMM 파라미터와 같은 중간 표현을 예측한 후, 이 표현을 바탕으로 이미지를 합성한다.
- 이 분야는 크게 두 가지 방식으로 나뉜다.
-
2.3 감정 기반 말하는 얼굴 생성(Emotional Talking Head Generation)
- 감정 표현이 가능한 말하는 얼굴 생성은 응용 및 엔터테인먼트 분야에서 중요성이 커지고 있다.
- 기존 방법들은 주로 두 가지 방식으로 감정을 처리한다.
- 개별 감정 레이블 사용: Gan et al. (2023), Ji et al. (2021)
- 한계: 제어 가능하고 미세한 감정 표현을 생성하기 어렵다.
- 감정 이미지 또는 비디오 참조: Ji et al. (2022), Wang et al. (2023)
- 한계: 입 모양이 감정 전달에 중요한 역할을 함에도 불구하고, 감정을 전체 얼굴에서 완전히 분리하지 못해 생생한 표정 합성에 어려움을 겪는다.
- 개별 감정 레이블 사용: Gan et al. (2023), Ji et al. (2021)
- EDTalk는 기존 연구의 한계를 극복하기 위해 다음과 같은 기여를 한다.
- 직교 기저(orthogonal base) 및 효율적인 훈련 전략: 입 모양과 감정 표현과 같은 다른 모션 공간을 완전히 분리하여 정교하게 제어되는 말하는 얼굴 합성을 가능하게 한다.
- 오디오 및 대본에서 감정 추론: 오디오 톤과 텍스트에서 적절한 감정을 자동으로 추론하여 일관된 감정적인 말하는 얼굴 비디오를 생성하며, 명시적인 이미지/비디오 참조가 필요 없다는 점에서 새로운 접근 방식이다.
3. Methodology
3.1 EDTalk Framework
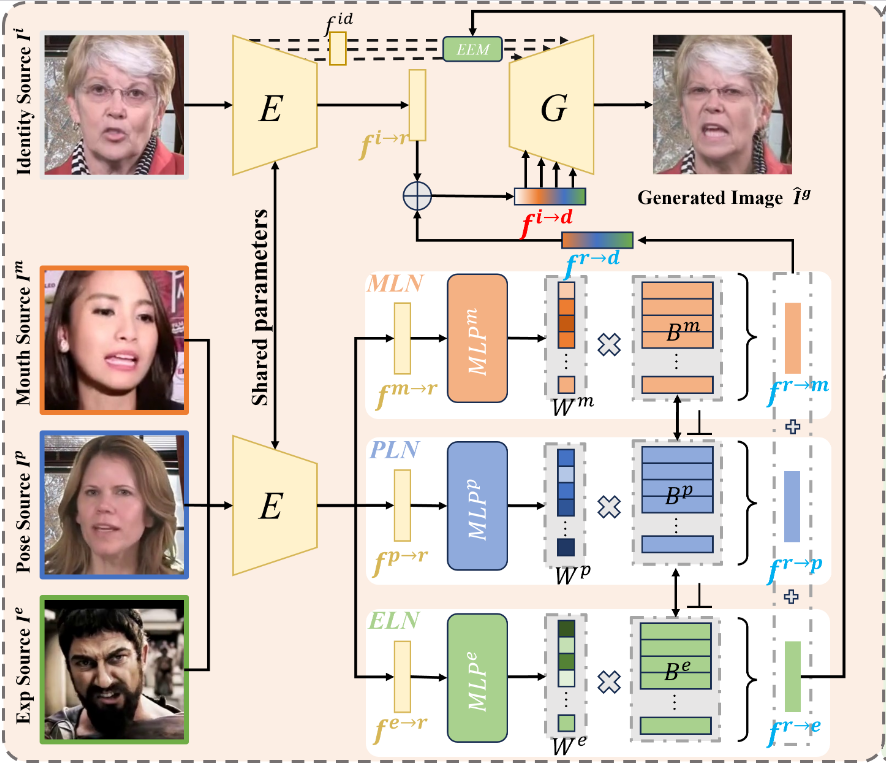
-
EDTalk 프레임워크의 구성
- EDTalk은 Autoencoder 구조를 기반으로 하며, 인코더(Encoder E), 세 가지 Component-aware Latent Navigation modules (CLNs), 그리고 제너레이터(Generator G)로 구성된다.
- 인코더 E (Encoder E): 신원 이미지 와 다양한 드라이빙 소스 이미지 를 latent feature인 와 로 매핑하는 역할을 한다.
- Canonical Feature () 개념: FOMM과 LIA에서 영감을 받아, 논문은 신원 특징과 드라이빙 특징 사이의 모션 전달을 용이하게 하는
canonical feature의 존재를 가정한다. 이는 와 같이 표현된다. - Component-aware Latent Navigation modules (CLNs): 인코더 E에서 추출된 latent feature 를 로 변환하는 모듈이다. 이 모듈들이 얼굴 움직임의 구성 요소를 분리하는 핵심적인 역할을 수행한다.
-
포즈 제어를 위한 PLN (Pose-aware Latent Navigation) 모듈 (수식 1)
-
CLNs 중 포즈(pose)를 예로 들어 PLN(Pose-aware Latent Navigation) 모듈에 대해 자세히 설명하고 있다.
-
포즈 뱅크 (): PLN 모듈 내에는 개의 학습 가능한 기저(base) 를 저장하는
pose bank가 존재한다. 각 기저는 고유한 포즈 모션 방향을 나타낸다. -
직교성(Orthogonality) 제약: 각 기저 와 () 사이에 이라는 내적(dot product)을 통한 직교성 제약이 가해진다. 이는 각 기저가 서로 독립적인 포즈 움직임을 담당하도록 보장하여, 간섭 없이 정확한 분리를 가능하게 한다.
-
선형 결합을 통한 포즈 표현: 이러한 기저들의 선형 결합으로 다양한 머리 포즈 움직임을 표현할 수 있다.
-
MLP 레이어 ():
Multi-Layer Perceptron레이어인 는 latent feature 로부터 포즈 기저들의 가중치 를 예측한다. -
수식 (1)의 상세 설명:
- : 포즈 뱅크 에 있는 개의 학습 가능한 기저 각각에 대한 가중치(weight) 집합이다.
- : Multi-Layer Perceptron이다. 입력 latent feature 로부터 이 가중치 를 예측하는 신경망이다.
- : 인코더 E에 의해 드라이빙 포즈 이미지 로부터 추출된 latent feature이다. 이 feature는 포즈 정보를 담고 있다.
- : -번째 포즈 기저 에 해당하는 가중치이다.
- : 포즈 뱅크 에 저장된 -번째 학습 가능한 포즈 기저이다. 이는 특정 포즈 모션 방향을 의미한다.
- : 예측된 가중치 와 포즈 기저 의 선형 결합으로 생성된 포즈 관련 모션 feature이다. 이는 canonical feature 에서 포즈 특징 로의 변환을 나타낸다. 즉, 가 예측한 가중치들을 사용하여 특정 포즈를 표현하는 모션 벡터를 구성하는 방식이다.
-
-
Latent Navigation Module의 역할:
Mouth-aware Latent Navigation (MLN),Pose-aware Latent Navigation (PLN),Expression-aware Latent Navigation (ELN)세 가지 모듈은 각각 입 모양(), 머리 자세(), 감정 표현()에 특화된 잠재 특징을 추출한다.- 이 특징들은 해당 구성 요소의 학습 가능한 '기저(learnable bases)'()들의 선형 조합으로 표현된다. 예를 들어, 입 모양 특징 와 같이 가중치 과 기저 의 곱으로 나타내어지는 것이다.
-
직교성(Orthogonality)을 통한 독립성 확보:
- 얼굴 구성 요소들의 완전한 분리(disentanglement)를 달성하고, 한 구성 요소의 변화가 다른 구성 요소에 영향을 미 주지 않도록, 세 가지 '은행(banks)'()에 저장된 기저들 사이에 직교성 제약을 적용한다.
- 이러한 직교성 덕분에 각 구성 요소의 잠재 특징들이 서로 간섭하지 않고 독립적으로 작동할 수 있다.
-
구동 특징(Driving Feature)의 결합:
- 독립적으로 추출된 입 모양 특징 , 머리 자세 특징 , 감정 표현 특징 는 단순히 합산되어 전체 얼굴 움직임을 제어하는 구동 특징 를 형성할 수 있다.
- 여기에 신원 이미지(identity image) 에서 추출된 신원 특징 를 더하여 최종 구동 특징 를 얻는다.
-
최종 이미지 생성 과정:
- 생성자(Generator) 는 최종 구동 특징 를 입력으로 받아 최종 결과 이미지 를 합성한다.
- 신원 일관성 유지를 위해, 는 스킵 연결(skip connections)을 통해 신원 이미지 의 신원 특징 를 추가로 통합한다.
- 감정 표현력을 향상하기 위해,
Emotion Enhancement Module (EEM)이 감정 표현 특징 를 보조적으로 활용하며, 이는 감정 토킹 헤드 생성 시에만 사용된다.
-
생성 과정 요약 수식 (2) 설명:
- : 최종적으로 합성되는 감정 토킹 헤드 이미지이다.
- : 입력 특징들을 기반으로 이미지를 생성하는 생성자(Generator) 네트워크이다.
- : 신원 이미지에서 추출된 특징()과 구동 소스에서 추출된 개별 얼굴 구성 요소 특징들()이 결합된, 전체 얼굴 움직임을 제어하는 잠재 특징이다.
- : 원본 신원 이미지의 신원 정보를 인코딩한 특징이다. 이는 스킵 연결을 통해 에 전달되어 신원 일관성을 유지하는 데 도움을 준다.
- : 감정 표현 특징 를 입력으로 받아 감정 표현을 강화하는
Emotion Enhancement Module의 출력이다. 이 모듈은 감정적인 토킹 헤드 생성 시에만 활성화되며, 더 생생한 감정 표현을 가능하게 한다.
-
를 로 그냥 바로 되돌릴 수 없는 이유 및 복잡한 변환 과정의 목적
-
와 의 의미 차이:
- 는 인코더 가 드라이빙 포즈 이미지 에서 추출한 latent feature이다. 이 feature는 에 담긴 포즈 정보뿐만 아니라, 다른 얼굴 요소(예: 입 모양, 표정)와 얽혀있는(entangled) 정보도 포함할 수 있다. 즉, 라는 원본 이미지의 "모든" 특징을 압축해 놓은 것이다.
- 는
Component-aware Latent Navigation (CLN)모듈, 특히Pose-aware Latent Navigation (PLN)모듈을 거쳐 생성된 포즈에 "특화된" 모션 feature이다. 이것은 에서 포즈 정보만을 분리하고, 다른 정보는 제거되거나 최소화된 형태이다.
-
Disentanglement (분리) 목표:
- 이 논문의 핵심 목표는 입술, 포즈, 표정과 같은 얼굴 움직임의 각 구성 요소를 독립적으로 제어하는 것이다. 는 이러한 요소들이 섞여 있을 수 있으므로, 이를 그대로 사용하면 독립적인 제어가 어렵다.
- MLP를 태우고 직교 기저들의 선형 결합으로 를 만드는 것은 에서 "포즈"라는 특정 모션만 뽑아내어 정규화된(canonical) 형태로 표현하려는 과정이다. 이 과정에서 다른 얼굴 요소로부터의 간섭을 최소화하고, 순수한 포즈 정보만을
pose bank에 저장된 기저들로 표현하여 분리하는 것이다.
-
-
MLP를 태우고 직교하는 벡터들에 가중치가 곱해진 합으로 만드는 이유
-
구성 요소별 정보 분리 (Disentanglement):
- 직교 기저 ():
pose bank에 저장된 각 는 고유하고 독립적인 "포즈 모션의 방향"을 나타낸다. 예를 들어, 하나는 고개를 왼쪽으로 돌리는 방향, 다른 하나는 고개를 위로 드는 방향 등을 나타낼 수 있다. 이 기저들이 서로 직교한다는 것은 각 기저가 담당하는 모션 방향이 서로 겹치지 않고 독립적이라는 의미이다. - MLP의 역할 (가중치 예측): 는 입력된 에서 어떤 포즈가 표현되어 있는지를 해석하고, 그 포즈를 가장 잘 나타낼 수 있는 직교 기저들의
가중치를 예측한다. 즉, "이 얼굴에는 고개를 왼쪽으로 20% 돌리고, 위로 10% 드는 포즈가 담겨 있다"는 식으로 가 가진 포즈 정보를 특정 기저들의 조합으로 맵핑하는 것이다. MLP는 이러한 비선형적인 맵핑을 학습한다. - 선형 결합 (): 예측된 가중치 와 직교 기저 의 선형 결합은 에 담긴 포즈 정보를 "표준화된(canonical) 포즈 모션 벡터"로 재구성한다. 이렇게 재구성된 는 오직 포즈 정보만을 담고 있으며, 다른 얼굴 요소의 정보는 제거되거나 분리된다.
- 직교 기저 ():
-
모션의 정규화 및 재사용성 (Canonical Representation & Reusability):
- 는 특정 드라이빙 이미지 에 강하게 의존하는 특징일 수 있다. 반면 는
pose bank의 직교 기저들을 통해 일반화된,canonical한 포즈 표현이 된다. - 이렇게 정규화된
latent space는 나중에 다른 신원 이미지에 동일한 포즈를 적용하거나, 오디오 입력에서 포즈를 예측하여 적용할 때 재사용성이 높아진다. 즉, 학습된 포즈 기저들은 "포즈"라는 개념을 추상화하여 저장해 둔 것이므로, 다양한 상황에서 유연하게 활용될 수 있다.
- 는 특정 드라이빙 이미지 에 강하게 의존하는 특징일 수 있다. 반면 는
-
효율적인 학습 및 제어 (Efficient Training & Control):
직교성은 각 기저가 독립적인 책임을 가지도록 하여, 학습 시 특정 기저가 다른 기저의 역할을 침범하는 것을 방지한다. 이는 학습의 안정성과 효율성을 높인다.MLP는 가볍고 빠르게 가중치를 예측할 수 있어 전체 네트워크의 학습 및 추론 효율성을 증가시킨다.- 이러한 방식을 통해, 사용자는 값을 조절하거나, 여러 들을 결합하여 원하는 포즈를 정밀하게 생성하고 제어할 수 있다.
-
3.2 Efficient Disentanglement
Mouth-Pose Decouple
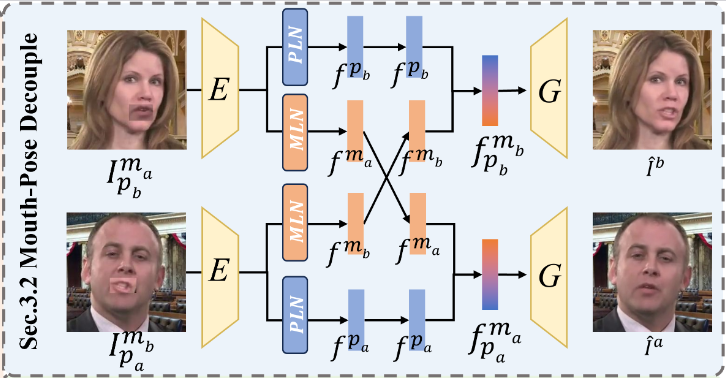
이 과정의 핵심은 입 모양(mouth shape)과 머리 포즈(head pose)라는 두 가지 얼굴 움직임 구성 요소를 서로 간섭 없이 효과적으로 분리하고, 이를 통해 새로운 조합의 얼굴 이미지를 생성하는 것이다. 여기서는 남자(a)의 입 모양과 여자(b)의 포즈를 결합하여 최종적으로 온전한 여자 얼굴 를 예측하는 과정을 자세히 설명한다.
1. 입력 이미지 준비 및 특징 추출 (Inferred Features)
-
원본 이미지:
- 남자 원본 이미지 (남자의 입 모양 와 포즈 를 포함)
- 여자 원본 이미지 (여자의 입 모양 와 포즈 를 포함)
-
합성 이미지 생성 ():
- 먼저
cross-reconstruction기법을 사용하여 합성 이미지 를 생성한다. - 는 여자 얼굴 에 남자 얼굴 의 입 영역을 덮어씌운 이미지이다.
- 이는 본질적으로 여자(b)의 포즈 와 남자(a)의 입 모양 를 가진 얼굴 이미지이다.
- 먼저
-
인코더 E의 역할:
- 합성 이미지 는 인코더 E에 입력된다.
- 인코더 E는 이 이미지를 내부의
canonical feature공간으로 매핑한다. 이 공간은 얼굴의 신원(identity)과 움직임 정보를 포함하는 추상적인 특징을 나타낸다. 여기서latent features가 추출된다. - 즉, 는 이미지의 모든 시각적 정보를 압축한 고차원 특징 벡터이다.
-
Component-aware Latent Navigation modules (PLN, MLN)의 역할:
-
에서 추출된 latent feature는 두 개의 전용 모듈인 PLN (Pose-aware Latent Navigation)과 MLN (Mouth-aware Latent Navigation)에 각각 입력된다.
-
PLN() :
- PLN 모듈은 입력된 feature에서 포즈 관련 정보만을 분리하여 라는 포즈 특징 벡터로 변환한다.
- 가 여자 얼굴 의 포즈를 기반으로 하므로, 는 여자(b)의 머리 포즈 에 해당하는 특징을 나타낸다.
- 이 과정에서 PLN은 학습된
pose bank에 저장된learnable bases의 선형 조합을 사용하여 포즈를 표현한다. 직교성 제약 덕분에 는 입 모양이나 표정 정보와 독립적으로 포즈만을 나타낸다.
-
MLN() :
- MLN 모듈은 입력된 feature에서 입 모양 관련 정보만을 분리하여 라는 입 모양 특징 벡터로 변환한다.
- 가 남자 얼굴 의 입 모양을 기반으로 하므로, 는 남자(a)의 입 모양 에 해당하는 특징을 나타낸다.
- 마찬가지로 MLN은 학습된
mouth bank에 저장된learnable bases의 선형 조합을 사용하여 입 모양을 표현하며, 이 역시 다른 구성 요소와 독립적이다.
-
결과: 식 (3)에서 추출된 특징은 다음과 같다:
- : 여자(b)의 포즈 특징
- : 남자(a)의 입 모양 특징
-
2. 제너레이터 G를 통한 최종 이미지 재구성 ()
-
재구성 입력 준비:
- 우리의 목표는 여자(b)의 온전한 얼굴 를 예측하는 것이다. 이를 위해 필요한 구성 요소는 여자(b)의 포즈와 여자(b)의 입 모양이다.
- 위에서 추출한 특징 중 는 여자(b)의 포즈 특징이므로 그대로 사용한다.
- 하지만 현재 우리는 남자(a)의 입 모양 특징 만 가지고 있다. 온전한 여자 얼굴 를 만들려면 여자(b)의 입 모양 특징 가 필요하다. 이 는 식 (4)에서 PLN과 MLN을 통과하여 얻은 특징 중 하나이다 (즉, 이다).
-
합성 이미지 생성 ():
cross-reconstruction기법으로 또 다른 합성 이미지 를 생성한다.- 는 남자 얼굴 에 여자 얼굴 의 입 영역을 덮어씌운 이미지이다.
- 이는 본질적으로 남자(a)의 포즈 와 여자(b)의 입 모양 를 가진 얼굴 이미지이다.
-
인코더 E 및 CLN (PLN, MLN)을 통한 특징 추출 (식 4):
- 는 인코더 E를 통해 로 변환된다.
- MLN() : MLN 모듈은 에서 여자(b)의 입 모양 에 해당하는 특징 를 추출한다.
- PLN() : PLN 모듈은 에서 남자(a)의 포즈 에 해당하는 특징 를 추출한다.
- 결과: 식 (4)에서 추출된 특징은 다음과 같다:
- : 여자(b)의 입 모양 특징
- : 남자(a)의 포즈 특징
-
제너레이터 G의 역할:
- 이제 우리는 여자(b)의 포즈 특징 (식 3에서 얻음)와 여자(b)의 입 모양 특징 (식 4에서 얻음)를 가지고 있다.
- 이 두 특징은 결합되어
driving feature를 형성하고, 이는 다시identity feature와 결합하여 가 된다. - 는 제너레이터 G에 입력된다.
- 또한, 제너레이터 G는 원본 신원 이미지 에서 추출된
identity features를skip connections를 통해 입력받아 최종 생성 이미지의 신원 일관성을 유지한다. (설명 간소화를 위해 이 부분은 문맥에서 "substitute the extracted mouth features and feed them into the generator G to perform cross reconstruction of the original images"라고 표현되어 있다.) - 제너레이터 G는 이 특징들을 바탕으로 여자(b)의 포즈와 여자(b)의 입 모양을 가진 온전한 얼굴 이미지 를 재구성한다.
- 즉, (여기서 는 생략될 수 있다고 논문에 명시됨)
정리:
이 과정은 두 인물(남자 a, 여자 b)로부터 각자의 입 모양과 포즈를 분리하여 추출한 후, 이 분리된 특징들을 조합하여 원본 이미지와 같은 신원을 가지면서도 특정 포즈와 입 모양을 가진 얼굴 이미지를 재구성하는 cross-reconstruction의 예시이다.
- 인코더 E: 입력 이미지에서 압축된
latent feature를 추출하는 역할을 한다. - PLN (Pose-aware Latent Navigation): latent feature에서
머리 포즈정보만을 추출하는 모듈이다. - MLN (Mouth-aware Latent Navigation): latent feature에서
입 모양정보만을 추출하는 모듈이다. - 제너레이터 G: 추출된 포즈 및 입 모양 특징, 그리고 신원 특징을 입력받아 최종 얼굴 이미지를 재구성하는 역할을 한다.
이러한 분리 및 재구성 과정을 통해 EDTalk는 얼굴 움직임 구성 요소들이 서로 독립적으로 제어될 수 있음을 학습하고 보장한다. 직교 기저(orthogonal bases)와 효율적인 훈련 전략은 이러한 독립성을 강화하고, 각 모듈이 오직 지정된 구성 요소의 움직임에만 "책임"을 지도록 만든다.
Mouth-Pose Decouple Loss
1. 재구성 손실 (): 픽셀 단위의 정확성 보장
- 수식:
- 에 대한 작용:
- 원본 여자 B의 이미지 와, 생성자 G에 의해 재구성된 이미지 간의 픽셀 값 차이의 절댓값을 합하여 계산한다.
- 목표: 재구성된 가 픽셀 수준에서 원본 와 최대한 동일하게 보이도록 강제한다. 이는 생성자가 여자 B의 얼굴, 입 모양, 포즈를 정확하게 재현하는 기본적인 능력을 갖추도록 하는 데 필수적인 역할을 한다.
2. 지각 손실 (): 고수준의 시각적 유사성 보장
- 수식:
- 에 대한 작용:
- VGG19 [49]와 같은 사전 학습된 네트워크의 특징 추출기 를 사용하여 원본 와 재구성된 에서 고수준의 특징 맵(feature map)을 각각 와 로 추출한다.
- 이 두 특징 맵 간의 차이 제곱을 합한 값(L2 노름의 제곱)을 최소화한다.
- 목표: 재구성된 가 단순히 픽셀만 일치하는 것을 넘어, 여자 B의 얼굴 구조, 질감, 스타일 등 인간의 시각 시스템이 인지하는 고수준의 시각적 특징 면에서도 원본 와 유사하도록 만든다. 이는 생성된 얼굴의 사실감을 높이는 데 중요하다.
3. 적대적 손실 (): 사실적인 이미지 생성 유도
- 수식:
- 에 대한 작용 (판별자 D의 관점):
- 판별자 D는 원본 이미지 를 입력받아 이것이 '실제' 이미지임을 정확히 예측해야 한다 (가 1에 가깝게). 값을 최대화한다.
- 판별자 D는 생성자 G에 의해 재구성된 이미지 를 입력받아 이것이 '가짜' 이미지임을 정확히 예측해야 한다 (가 0에 가깝게). 값을 최대화한다.
- 목표 (판별자): 판별자는 실제 여자 B의 이미지와 생성된 를 정확하게 구별하도록 학습된다.
- 에 대한 작용 (생성자 G의 관점):
- 생성자 G는 판별자를 속이는 것이 목적이다. 따라서 G는 가 실제 이미지처럼 보이도록 만들어 가 1에 가깝게 되도록 유도한다. 이는 를 최소화하는 것을 의미한다. 일반적으로 생성자는 를 최소화하는 방향으로 학습한다.
- 목표 (생성자): 생성된 가 매우 사실적이어서 판별자조차 실제 이미지와 구별하기 어렵게 만드는 것이다. 이를 통해 여자 B의 얼굴이 전체적으로 자연스럽고 실제 사람처럼 보이도록 만든다.
4. 피처 수준 제약 손실 (): 특징 공간의 분리 보장
- 수식:
- 에 대한 작용:
- 이 손실은 Mouth-Pose Decouple 과정의 핵심적인 분리(disentanglement)를 강제하는 데 사용된다.
- 포즈 특징 측면: 원본 이미지 에서 추출된 포즈 특징 와, 를 인코더 와 Pose-aware Latent Navigation 모듈(PLN)을 거쳐 얻은 포즈 특징 사이의 코사인 유사도 를 최대화한다. 손실 함수를 최소화하기 위해 형태를 사용한다.
- 입 특징 측면: 원본 이미지 에서 추출된 입 특징 와, 를 인코더 와 Mouth-aware Latent Navigation 모듈(MLN)을 거쳐 얻은 입 특징 사이의 코사인 유사도를 최대화한다. 마찬가지로 를 최소화한다.
- 목표: 각 Latent Navigation 모듈(PLN, MLN)이 여자 B의 해당 구성 요소(포즈, 입 모양)의 특징만을 정확하게 추출하고, 다른 구성 요소의 정보는 포함하지 않도록 강제한다. 이는 여자 B의 입 특징 공간과 포즈 특징 공간이 서로 간섭 없이 독립적으로 존재하게 만드는 핵심적인 역할을 한다.
정리:
여자 B의 이미지 를 예로 들었을 때, Mouth-Pose Decouple 모듈은 , , 를 통해 여자 B의 얼굴을 픽셀 및 지각 수준에서 사실적으로 재구성하도록 학습된다. 동시에 를 통해 여자 B의 포즈 특징과 입 특징이 각각의 전용 모듈(PLN, MLN)에서 정확하고 독립적으로 추출되도록 강제된다. 이 네 가지 손실의 에 대한 기여 항들이 함께 작용하여, 모델이 여자 B의 입 모양과 헤드 포즈를 효과적으로 분리하고 동시에 고품질의 얼굴 이미지를 생성하는 능력을 학습하게 된다.
와 의 on-the-fly 생성 여부
-
on-the-fly 생성: 와 와 같은 합성 이미지들은 훈련 과정에서 on-the-fly(실시간으로) 생성되는 것이 맞다. 논문 5페이지 "Mouth-Pose Decouple" 부분에서 "we introduce cross-reconstruction technical, which involves synthesized images of switched mouths: and ."라고 명시하고 있다. 이는 훈련 데이터셋에 미리 이런 합성 이미지가 준비되어 있는 것이 아니라, 훈련 중 배치(batch) 단위로 원본 이미지 를 가져와 입 영역을 서로 교체하여 합성 이미지를 만들고 이를 모델에 입력하는 방식이다.
-
생성 메커니즘: "Here, we superimpose the mouth region of onto and vice versa."라는 문장을 통해, 이 합성 과정은 의 입 영역 픽셀을 의 입 영역 픽셀 위에 그대로 덮어씌우는 방식으로 이루어지는 것으로 보인다. 이는 간단하면서도 효과적으로
입 모양과나머지 얼굴(포즈)을 분리하는 시각적 입력 페어를 만들어낸다.
disentanglement를 위한 프레임 페어 개수 추정
-
정확한 수치 제시의 어려움: 논문은 disentanglement를 달성하기 위해 필요한 "최소 프레임 페어 개수"를 명확하게 제시하지는 않는다. 이러한 최적의 개수는 모델 아키텍처, 데이터셋의 다양성, 훈련 목표, 그리고 목표하는 disentanglement의 수준에 따라 매우 유동적이다.
-
간접적인 유추: 하지만 논문에서 제공하는 정보들을 통해 필요한 데이터의 규모를 간접적으로 추정할 수 있다.
- HDTF 데이터셋 사용: Mouth-Pose Decouple 단계에서는 HDTF 데이터셋(15.8시간 분량의 영상)을 주로 사용한다. 이 데이터셋은 고품질의 고해상도 영상을 포함하며, 300명 이상의 다양한 인물을 포함한다.
- 훈련 반복 (iterations): Mouth-Pose Decouple 단계에서는 "4k iterations"를 수행한다고 언급한다.
- 배치 크기 (batch size): 훈련 시 "batch size of 4"를 사용한다.
- 총 프레임 수: 만약 각 배치에서 4개의 원본 이미지(, 등)를 사용하고, 각 원본 이미지에서 합성 이미지를 생성한다면, 최소 개의 합성 이미지가 각 배치에 사용될 수 있다.
- 이를 단순 계산하면 는 총 개의 개별 프레임 또는 그 이상의 합성 이미지가
Mouth-Pose Decouple단계에서 모델의 입력으로 사용된다고 볼 수 있다. - 15.8시간의 영상 데이터는 수십만, 수백만 프레임에 달할 수 있으므로, 훈련 과정에서 굉장히 다양한 프레임 페어가 실시간으로 구성되어 사용된다고 할 수 있다.
-
다양성과 충분한 데이터: disentanglement의 성공은 단순히
개수를 넘어다양성이 중요하다. 입 모양과 포즈의 다양한 조합을 모델이 충분히 경험해야 각 구성 요소를 효과적으로 분리할 수 있다. HDTF와 같이 다양한 인물과 움직임을 포함하는 대규모 영상 데이터셋을 사용하는 것은 이러한 다양성을 확보하는 데 기여한다.
결론적으로, EDTalk는 대규모 영상 데이터셋에서 훈련 중 실시간으로 다양한 프레임 페어를 생성하여 입 모양과 포즈를 분리하는 학습을 진행한다. 특정 최소 개수가 정해져 있기보다는, 데이터셋의 규모와 훈련 반복 횟수에 따라 수만, 수십만 개 이상의 동적인 프레임 페어가 학습에 활용된다고 볼 수 있다.
Expression Decouple
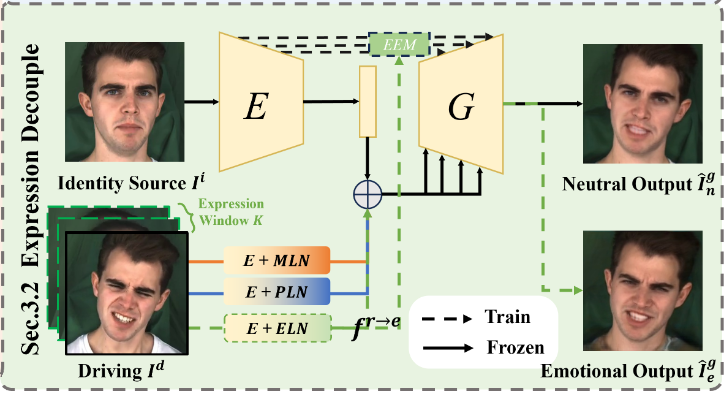
이 부분은 EDTalk 프레임워크에서 driving image 로부터 표정 정보를 효율적으로 분리하는 "Expression Decouple" 단계에 대해 설명하고 있다. 이는 "self-reconstruction complementary learning"이라는 방식을 통해 Expression-aware Latent Navigation module (ELN)과 Emotion Enhancement Module (EEM)을 학습시키는 과정이다.
-
표정 분리의 필요성: Identity source 와 driving image 가 주어졌을 때, 로부터 표정 정보를 분리하여 의 얼굴에 적용하는 것이 목표이다. 는 와 동일한 인물이지만, 입 모양, 머리 자세, 표정 등은 다를 수 있다.
-
사전 학습된 모듈의 역할:
- 이전 단계에서 미리 학습된 Encoder (E), Mouth-aware Latent Navigation (MLN) 모듈, Pose-aware Latent Navigation (PLN) 모듈, 그리고 Generator (G)가 사용된다.
- 이 모듈들은 에서 입 모양과 머리 자세 정보를 효과적으로 분리하는 역할을 수행한다.
- 이들을 통해 생성된 이미지 는 의 입 모양과 머리 자세를 따라 하지만, 의 표정을 유지하게 된다.
-
ELN의 표정 학습 강제:
- 가 의 표정까지 충실하게 재구성하기 위해서는 ELN이 MLN과 PLN이 분리해내지 못한 '보완적인 정보'를 학습해야 한다. 이 보완적인 정보가 바로 '표정 정보'이다.
- 즉, MLN과 PLN이 입 모양과 머리 자세를 담당하는 동안, ELN은 오직 표정에 대한 정보를 학습하도록 유도되는 방식이다.
-
깨끗한 표정 특징 추출:
- 비디오 시퀀스에서 표정 변화는 다른 움직임(입 모양, 머리 자세)보다 덜 빈번하게 발생한다는 관찰 [58]에 착안한다.
- 이를 활용하여, driving image 를 중심으로 크기 의 윈도우를 설정하고, 해당 윈도우 내의 개 프레임에서 추출된 표정 특징들을 평균하여 '깨끗한 표정 특징' 를 얻는다.
-
Generator G에 대한 입력:
- 이렇게 얻은 깨끗한 표정 특징 는 추출된 입 모양 특징 및 자세 특징과 함께 Generator G의 입력으로 사용되어 최종 이미지를 생성하게 된다.
-
Emotion Enhancement Module (EEM)의 역할
- EEM은 감정 특징 를 입력으로 받아, 두 가지 아핀 변환 파라미터 를 생성한다. 여기서 는 스케일(scale) 파라미터이고 는 바이어스(bias) 파라미터이다.
- 생성된 이 파라미터들은 Adaptive Instance Normalization (AdaIN) 연산을 제어하는 데 사용된다.
- AdaIN 연산을 통해 신원 특징(identity feature) 는 감정 조건부 특징(emotion-conditioned feature) 로 변환된다.
- AdaIN 연산은 다음 수식으로 정의된다.
- 는 EEM을 통해 감정 정보가 적용된 신원 특징이다.
- 는 신원 특징 에 EEM 모듈을 적용한 결과를 나타낸다.
- 는 EEM에서 생성된 스케일 파라미터로, 특징을 스케일링하는 역할을 한다.
- 는 입력 신원 특징 를 인스턴스 정규화(instance normalization)하는 과정이다.
- 는 의 평균 연산을 나타낸다.
- 는 의 분산 연산을 나타낸다.
- 이 과정을 통해 는 평균이 0이고 표준 편차가 1이 되도록 정규화된다.
- 는 EEM에서 생성된 바이어스 파라미터로, 정규화된 특징에 오프셋을 더하는 역할을 한다.
- 결과적으로 이 AdaIN 연산은 신원 고유의 특징은 유지하면서, EEM이 생성한 와 를 통해 원하는 감정 스타일을 특징에 입히는 효과를 얻는다.
- 이 감정 조건부 특징 는 생성자 G에 입력되어, driving image 의 감정을 충실히 재현하는 출력 이미지 를 생성하는 데 기여한다 (Eq. 2 참조).
-
Emotion Enhancement Module (EEM)의 예시
-
입력 준비:
- 아이디티 이미지 (): 사용자가 제공한 "중립적인" 표정의 아이디티 이미지이다.
- 드라이빙 이미지 (): 드라이빙 비디오에서 추출된, "슬픈" 감정을 표현하고 있는 특정 프레임이다. 이 는 또한 입 모양과 머리 포즈 정보도 포함한다.
-
인코더 (E)와 CLN (Component-aware Latent Navigation) 모듈을 통한 특징 추출:
- 신원 특징 (): 인코더 (E)는 아이디티 이미지 에서 고유한 신원 정보(얼굴 생김새, 피부색 등)를 나타내는 특징 를 추출한다. 이 특징은 주로 얼굴의 정적인 정보를 담고 있다.
- 감정 특징 (): 인코더 (E)는 드라이빙 이미지 에서 특징 를 추출하고, Expression-aware Latent Navigation (ELN) 모듈은 이 로부터 "슬픔" 감정에 해당하는 순수한 감정 특징 를 분리하여 추출한다. ELN은 감정 외의 다른 움직임(입 모양, 포즈)이 섞이지 않도록 훈련되어 있다.
- (참고: 입 모양 특징 과 머리 포즈 특징 도 에서 각각 MLN과 PLN을 통해 추출된다.)
-
EEM의 아핀 변환 파라미터 () 생성:
- EEM은 추출된 "슬픈" 감정 특징 를 입력받는다.
- 이 를 바탕으로 EEM은 두 가지 아핀 변환 파라미터, 즉 스케일 ()과 바이어스 ()를 생성한다.
- 이 와 는 "슬픔"이라는 감정 표현에 필요한 특정 스타일과 강도를 제어하는 값이다.
- 예시: "슬픔" 감정을 표현하기 위해, 는 얼굴 특징을 "수축"시키는 경향(예: 눈썹 안쪽이 올라가고 눈이 약간 찌푸려지는 움직임)을, 는 "아래로 처지는" 경향(예: 입꼬리 처짐, 얼굴 윤곽의 변화)을 지시하는 값을 생성할 수 있다.
-
AdaIN (Adaptive Instance Normalization) 연산을 통한 신원 특징 변형:
- EEM은 이어서 아이디티 특징 에 "슬픔" 감정 스타일을 주입하기 위해 AdaIN 연산을 수행한다.
- 단계 1: 신원 특징 정규화:
- 원본 아이디티 특징 의 인스턴스별 평균 과 표준 편차 를 계산한다.
- 를 인스턴스 정규화한다: .
- 이 단계는 의 원래 스타일(이 경우에는 "중립적인" 표정의 통계적 특성)을 제거하고, 순수한 신원의 '콘텐츠' 정보만 남기는 효과가 있다. 마치 얼굴의 '형태'와 '구조'만을 남겨두는 것과 같다.
- 단계 2: 감정 스타일 주입:
- 정규화된 신원 특징에 EEM이 생성한 "슬픔" 감정의 스케일 와 바이어스 를 적용한다:
- 이 과정은 정규화된 신원 특징에 "슬픔" 감정의 통계적 특성(평균, 분산)을 '덮어씌우는' 것과 같다. 이는 아이디티의 얼굴 구조에 드라이빙 이미지 에서 추출된 "슬픔"이라는 표정의 움직임과 형태적 변화를 적용하는 것에 해당한다.
- 결과적으로, 는 신원 고유의 특성을 유지하면서 "슬픈" 감정 표현이 인코딩된 새로운 특징이 된다.
- 정규화된 신원 특징에 EEM이 생성한 "슬픔" 감정의 스케일 와 바이어스 를 적용한다:
-
생성자 (Generator G)로 전달 및 최종 이미지 생성:
- 이렇게 감정이 조건화된 특징 는 생성자 G의 skip connection을 통해 입력되어, 감정 표현을 강화하는 데 기여한다.
- 생성자 G는 (아이디티의 레퍼런스 특징, 드라이빙의 입, 포즈, 감정 특징의 결합)와 (신원 정보), 그리고 (감정 특징 자체 또는 AdaIN으로 변형된 가 G의 별도 입력으로 활용되는 방식)를 종합하여 최종 결과 이미지 를 합성한다.
- 최종 는 "중립적인" 아이디티의 얼굴을 유지한 채, 드라이빙 비디오 의 "슬픈" 표정, 입 모양 및 머리 포즈를 정확하게 따라 하는 아바타의 얼굴이 된다.
-
-
Expression Decouple 단계의 손실 함수
- 모션 재구성 손실 ():
- 이 손실은 생성된 이미지 의 모션이 driving image 의 모션과 일치하도록 강제한다.
- 수식은 다음과 같다.
- 는 EMOCA에서 가져온 3D 얼굴 재구성 네트워크(3D face reconstruction network)를 통해 추출된 특징이다. 이는 주로 얼굴의 3D 형태와 포즈 정보를 포착한다.
- 는 EMOCA에서 가져온 감정 네트워크(emotion network)를 통해 추출된 특징이다. 이는 주로 얼굴의 감정 표현 정보를 포착한다.
- 이 손실은 생성된 얼굴의 3D 모션과 감정 표현이 원본과 동일하게 재구성되도록 돕는다.
- 입 일관성 손실 ():
- 이 손실은 생성된 이미지 의 입 모양이 driving frame 의 입 모양을 정확하게 모방하도록 보장한다.
- 수식은 다음과 같다.
- 는 코사인 유사도(cosine similarity) 연산을 나타낸다. 코사인 유사도가 높을수록 두 벡터가 유사함을 의미한다.
- 는 생성된 이미지 에서 인코더 E와 Mouth-aware Latent Navigation (MLN) 모듈을 통해 추출된 입 특징이다.
- 는 driving image 에서 인코더 E와 MLN 모듈을 통해 추출된 입 특징이다.
- 이 손실은 두 입 특징 벡터의 코사인 유사도를 최대화하여, 생성된 이미지의 입 모양이 driving image의 입 모양과 일치하도록 한다.
- 기타 손실: 재구성 손실 , 지각 손실 Perceptual Losses for Real-Time Style Transfer and Super-Resolution, 적대적 손실 (Eq. 5 및 Eq. 6 참조) 또한 이 단계에서 함께 적용된다.
- 모션 재구성 손실 ():
-
훈련 효율성
- 이 단계에서는 Expression-aware Latent Navigation (ELN) 모듈과 Emotion Enhancement Module (EEM)과 같이 새로 제안된 경량(lightweight) 모듈만 훈련된다.
- 이전 단계에서 훈련된 Encoder (E), Mouth-aware Latent Navigation (MLN), Pose-aware Latent Navigation (PLN), Generator (G)의 가중치는 고정된다.
- 이러한 접근 방식은 훈련 시간을 크게 단축하고 계산 비용을 절감하여 효율적인 훈련을 가능하게 한다.
이러한 과정을 통해 EDTalk은 입 모양, 머리 포즈, 감정 표현을 개별적으로 제어할 수 있는 disentangled space를 성공적으로 학습하여, 한 번의 훈련으로 비디오 기반의 감정적인 말하는 얼굴 생성을 가능하게 한다.
-
Identity source (정체성 소스 이미지) 선정:
- 논문 16페이지 'A.2.2 Data Processing' 섹션에 따르면, MEAD와 같은 감정 레이블이 있는 데이터셋의 경우, 동일한 화자(speaker)로부터 'Neutral' 감정의 프레임을 로 사용한다.
- 이는 생성될 Talking Head의 정체성을 유지하면서, 감정 변화는 및 로부터 오도록 하기 위함이다.
- 일반적인 데이터셋(감정 레이블이 없는 경우)에서는 비디오의 첫 번째 프레임을 로 사용한다고 명시되어 있지만, MEAD의 EEM 훈련에는 감정 제어를 위한 특수 설정이 적용되는 것이다.
-
Driving image (구동 이미지) 선정:
- 는 와 동일한 화자이지만, 입 모양, 머리 자세, 감정 표현이 다른 프레임이다.
- 정확히 몇 프레임이 로 사용되는지에 대한 명확한 언급은 없지만, 일반적으로 비디오 시퀀스 내의 다양한 순간을 나타내는 프레임 중 하나가 될 수 있다.
- 자체는 단일 프레임이지만, 의 표정 특징을 추출할 때 주변 프레임의 정보를 활용한다.
-
윈도우 사용 및 깨끗한 표정 특징 추출:
- 논문 6페이지 'Expression Decouple' 섹션에 따르면, "expression variation in a video sequence is typically less frequent than changes in other motions" (비디오 시퀀스에서 표정 변화는 다른 움직임보다 덜 빈번하다)는 관찰에 기반하여 윈도우를 사용한다.
- 를 중심으로 크기 의 윈도우를 정의하고, 이 개 프레임에서 추출된 표정 특징들을 평균하여 깨끗한 표정 특징 를 얻는다.
- 논문 8페이지 'Implement Details' 섹션에서는 Mouth, Pose, Expression Latent Navigation 모듈의 기저(bases) 개수가 각각 20, 6, 10으로 설정되어 있다고 명시되어 있지만, 윈도우의 구체적인 크기( 값)에 대한 명확한 수치는 논문에 직접적으로 명시되어 있지 않다.
- 다만, "average extracted expression features"라는 표현으로 미루어 보아, 실제 구현에서는 5~10 프레임 정도의 작은 윈도우가 사용되었을 가능성이 높다. 이러한 값은 일반적으로 표정 변화의 빈도와 평균화의 효과를 고려하여 설정된다.
-
이터레이션 및 학습 시간:
- 논문 17페이지 'A.3 Training Details'에 따르면, Expression Decouple 단계의 훈련은 약 6시간이 소요된다.
- 이전 Mouth-Pose Decouple 단계는 4k 이터레이션(약 1시간)이었지만, Expression Decouple 단계의 구체적인 이터레이션 횟수는 명시되어 있지 않다. 다만 6시간 동안 훈련된다는 점과 배치 크기를 고려했을 때 상당한 이터레이션이 진행될 것으로 추정된다.
- "Self-reconstruction complementary learning" 방식의 훈련은 이미 학습된 Encoder E, MLN, PLN, Generator G를 고정하고 ELN, , EEM만 업데이트하기 때문에 효율적이다.
-
와 페어의 개수:
- 훈련 데이터셋으로 MEAD와 HDTF를 모두 사용하며 (총 54.8시간 분량), 배치 크기는 10이다.
- 이러한 정보로 볼 때, 매 이터레이션마다 배치 크기 10에 해당하는 와 페어(또는 시퀀스)가 동적으로 샘플링되어 훈련에 사용된다.
- 정확히 몇 개의 고정된 페어가 사용되는지보다는, 전체 데이터셋에서 랜덤 샘플링을 통해 다양한 페어를 구성하며 학습이 진행되는 방식이다.
요약:
- : MEAD 데이터셋에서 동일 화자의 'Neutral' 감정 프레임을 사용한다.
- : 와 동일 화자이지만, 다른 감정, 입 모양, 머리 자세를 가진 프레임을 사용한다.
- 윈도우 크기: 논문에 명시된 구체적인 값은 없지만, 주변 개 프레임의 표정 특징을 평균하여 를 얻는다.
- 이터레이션: 구체적인 횟수는 명시되지 않았지만, 약 6시간 동안 훈련된다.
- 페어 개수: 배치 크기 10에 맞춰 동적으로 샘플링된 와 페어가 훈련에 사용된다.
3.3 Audio-to-Motion
이 섹션은 오디오 입력만으로 얼굴의 입술 움직임을 생성하는 EDTalk의 Audio-to-Motion 모듈 중 하나인 오디오 기반 입술 생성(Audio-Driven Lip Generation) 방법에 대해 설명한다.
-
Audio-Driven Lip Generation
-
기존 연구의 문제점
- 표정으로 인한 방해: 이전의 많은 연구(StyleTalk, EMMN)는 입술 움직임과 표정을 통합적으로 생성했으나, 표정(acoustic-irrelevant motions)은 오디오와 직접적인 관련이 없어서 입술 동기화(lip synchronization)를 방해하는 경향이 있었다. SadTalker 또한 이 문제를 겪었다.
- 시각 정보 부족: 오디오 입력만으로는 음소(phoneme) 수준의 미세한 입술 움직임을 생성하는 데 필요한 시각적 정보가 부족하여 세부적인 합성이 어려웠다. Synctalkface와 같은 일부 방법은 추가적인 시각적 메모리를 사용했다.
-
EDTalk의 해결책
- 분리된 입술 공간 활용: EDTalk은 이전 단계에서 입술(mouth) 움직임이 다른 요소(표정, 포즈)와 완전히 분리된 잠재 공간(disentangled mouth space)으로 학습되었기 때문에, 표정이 입술 동기화에 미치는 영향을 자연스럽게 줄일 수 있다. 특별한 훈련 전략이나 손실 함수 없이도 이러한 분리가 가능했다.
- 풍부한 시각적 사전 정보 활용: 비디오 기반의 얼굴 생성 과정에서 학습된 입술 베이스()가 뱅크에 저장되어 있다. 이는 오디오 기반 생성 시 충분한 시각적 사전 정보를 제공하므로, Synctalkface처럼 별도의 추가 시각적 메모리가 필요 없다.
- 간소화된 예측: 이전에 학습된 입술 베이스 가 있으므로, 오디오 입력으로부터는 각 베이스의 가중치 만 예측하면 미세한 입술 움직임을 생성할 수 있다.
-
Audio-Driven Lip Generation 모듈의 구성 및 학습
- Audio Encoder : 오디오 입력 시퀀스 로부터 오디오 특징 를 잠재 공간으로 임베딩하는 역할을 한다.
- Linear layer : Audio Encoder 에서 추출된 오디오 특징으로부터 입술 가중치 을 디코딩하는 선형 레이어이다.
- 학습 과정: 훈련 중에는 이전에 학습된 다른 모든 모듈의 가중치를 고정하고, 와 만 다음의 손실 함수들을 사용하여 업데이트한다.
-
- 이것은 입 모양 특징(feature)에 대한 손실 함수이다.
- : Mouth Feature Loss를 나타낸다. 이 손실은 오디오에서 예측된 입 모양 가중치()와 실제(Ground Truth) 입 모양 가중치() 간의 차이를 최소화하는 데 사용된다.
- : 실제 입 모양 가중치 집합이다. 이 값은 Mouth-aware Latent Navigation (MLN) 모듈이 실제 이미지 에서 추출한 Ground Truth 가중치이다.
- : Audio Encoder가 오디오 입력으로부터 예측한 입 모양 가중치 집합이다.
- : L2 norm (유클리드 거리)을 나타낸다. 두 벡터 간의 차이의 제곱합의 제곱근을 계산하여, 예측된 가중치 벡터가 실제 가중치 벡터에 얼마나 가까운지 측정한다. 이 값이 작을수록 예측이 정확하다는 것을 의미한다.
- 이 손실 함수는 오디오에서 추출된 정보가 입 모양을 잘 표현하는 특징을 학습하도록 유도한다.
-
- 이것은 재구성(reconstruction)에 대한 손실 함수이다.
- : Mouth Reconstruction Loss를 나타낸다. 이 손실은 생성된 이미지()와 실제 이미지() 간의 시각적 유사성을 측정하고, 픽셀 수준에서 두 이미지 간의 차이를 최소화하는 데 사용된다.
- : 실제(Ground Truth) 이미지이다.
- : Audio Encoder가 예측한 입 모양 가중치()와 다른 얼굴 구성 요소(머리 포즈, 감정 등)의 특징을 결합하여 Generator G로 생성된 이미지이다.
- : L2 norm (유클리드 거리)을 나타낸다. 두 이미지의 픽셀 값 간의 차이의 제곱합의 제곱근을 계산하여 시각적 유사도를 측정한다. 이 값이 작을수록 생성된 이미지가 원본 이미지와 픽셀 단위로 더 유사하다는 것을 의미한다.
- 이 손실 함수는 생성된 얼굴 이미지가 실제 얼굴 이미지와 시각적으로 구별하기 어려울 정도로 사실적이고 정확하게 재구성되도록 보장한다.
-
- : 입술 동기화 손실(mouth synchronization loss)이다. 생성된 입술 움직임이 오디오와 얼마나 잘 동기화되는지 측정하는 지표이다.
- : 음의 로그 함수이다. 이 함수는 괄호 안의 값이 커질수록 값이 작아지도록 한다. 이는 동기화 점수가 높을수록 손실이 낮아지는 것을 의미한다. 일반적으로 로그 함수는 확률이나 유사도 점수를 손실 함수에 통합할 때 사용된다.
- : SyncNet [12]의 스피치 인코더(speech encoder)에서 추출된 오디오 특징 벡터이다. 오디오 콘텐츠의 시맨틱(semantic) 및 음성 정보를 인코딩한다.
- : SyncNet [12]의 이미지 인코더(image encoder)에서 추출된 이미지 특징 벡터이다. 생성된 얼굴 이미지의 입술 움직임과 관련된 시각적 특징을 인코딩한다.
- : 와 의 내적(dot product)이다. 두 특징 벡터 간의 유사도를 측정한다. 내적 값이 클수록 두 벡터가 비슷한 방향을 가리키며, 이는 오디오와 입술 움직임이 더 잘 동기화됨을 의미한다.
- : 벡터의 L2 노름(Euclidean norm, 길이)이다.
- : 벡터의 L2 노름(Euclidean norm, 길이)이다.
- : 와 의 L2 노름 곱과 아주 작은 양수 상수 () 중 더 큰 값을 선택한다. 은 분모가 0이 되거나 너무 작은 값이 되어 수치 불안정성을 일으키는 것을 방지하는 역할을 한다.
- : 이 항은 와 벡터 간의 코사인 유사도(cosine similarity)를 나타낸다 (단, 분모가 에 의해 클램핑될 수 있다). 코사인 유사도는 두 벡터가 가리키는 방향의 유사성을 -1에서 1 사이의 값으로 측정한다. 1에 가까울수록 두 벡터가 동일한 방향을 가리키며, 이는 오디오와 시각적 정보가 강하게 동기화됨을 의미한다.
-
-
Flow-Based Probabilistic Pose Generation
이 섹션은 오디오 입력만으로 다양하고 사실적인 머리 움직임(head pose)을 생성하기 위해 EDTalk가 Normalizing Flow를 어떻게 활용하는지 설명한다.
-
문제점 인식:
- 오디오 입력에서 머리 포즈를 생성하는 것은 '하나의 입력에 여러 가능한 출력'이 존재하는 다대일(one-to-many) 매핑 문제이다.
- 기존의 결정론적(deterministic) 매핑 방식은 항상 동일한 결과만 생성하여 모호하고 시각적으로 품질이 낮은 결과를 초래할 수 있다.
-
해결책: Normalizing Flow () 활용:
- EDTalk는 Normalizing Flow 를 사용하여 포즈 가중치 를 예측한다.
- 이는 확률적(probabilistic) 모델링을 통해 다양하고 사실적인 머리 움직임을 생성하기 위함이다.
-
학습 과정 (Training):
- 비디오에서 실제(Ground Truth, GT) 포즈 가중치 를 추출하여 에 입력한다.
- Maximum Likelihood Estimation (MLE) 손실 함수를 사용하여 오디오 특징 에 조건화된 가우시안 분포 에 를 임베딩하도록 를 학습시킨다.
-
추론 과정 (Inference):
- 학습된 분포 에서 임의로 를 샘플링한다.
- 와 오디오 특징 를 Normalizing Flow 에 입력하여 포즈 가중치 를 생성한다.
- 이 과정을 통해 다양한 머리 움직임을 생성하면서도 오디오 리듬과의 일관성을 유지한다.
-
수식 설명:
-
Maximum Likelihood Estimation (MLE) 손실 ():
다음은 Normalizing Flow 가 실제 포즈 가중치 를 오디오 특징 에 조건화된 가우시안 분포 의 잠재 공간 로 매핑하고, 이 매핑의 확률을 최대화하는 손실 함수이다.
- : 시간 에서의 잠재 코드(latent code)이다. Normalizing Flow의 역함수 를 통해 실제 포즈 가중치 와 오디오 특징 로부터 얻어진다.
- : Normalizing Flow 의 역함수이다. 입력된 포즈 가중치와 오디오 특징을 잠재 공간의 로 변환한다.
- : 시간 에서의 실제(Ground Truth) 포즈 가중치이다.
- : 시간 에서의 오디오 특징이다 (Audio Encoder 에서 추출된 값).
- : Maximum Likelihood Estimation(최대 우도 추정) 손실이다. 모델이 실제 데이터를 얼마나 잘 설명하는지 나타내며, 이 값이 최소화되도록 학습한다. 음의 로그 가능도(negative log-likelihood)를 사용하여 분포 의 확률을 최대화하는 효과를 가진다.
- : 오디오 시퀀스 또는 프레임의 전체 개수이다.
- : 잠재 코드 가 따르는 가우시안 분포의 확률 밀도 함수이다.
-
포즈 재구성 손실 () 및 시간적 일관성 손실 ():
이 손실 함수들은 Normalizing Flow 가 포즈 가중치를 정확하게 재구성하고, 시간적으로도 자연스러운 움직임을 생성하도록 돕는다.
- : 포즈 재구성 손실(pose reconstruction loss)이다. 실제 포즈 가중치 와 를 통해 재구성된 포즈 가중치 간의 L2 노름(Euclidean distance) 차이를 최소화한다. 이는 생성된 포즈가 실제 포즈와 유사하도록 강제한다.
- : 실제 포즈 가중치이다.
- : Normalizing Flow 를 통해 재구성된 포즈 가중치이다.
- : 시간적 일관성 손실(temporal loss)이다. 연속적인 두 프레임 간의 실제 포즈 변화량()과 재구성된 포즈 변화량() 간의 차이를 최소화한다. 이는 생성된 머리 움직임이 시간적으로 부드럽고 자연스럽게 이어지도록 보장한다.
-
-
학습 과정 (Training Process) 예시
모델은 실제 비디오 데이터()에서 추출된 정보를 학습한다.
-
실제 포즈 가중치 () 추출:
- 예시: 10초짜리 비디오 클립이 25fps(초당 25프레임)라고 가정하면, 총 개의 프레임이 있다.
- 각 프레임 ()에 대해, Encoder 와 Pose-aware Latent Navigation (PLN) 모듈을 통해 해당 프레임의 실제 머리 포즈를 나타내는 가중치 벡터 를 추출한다.
- 이 논문에서는 포즈 뱅크 가 6개의 기저(bases)를 갖는다고 명시되어 있으므로, 각 는 6차원 벡터가 된다.
- 숫자 예시: 특정 프레임 에서 추출된 실제 포즈 가중치 는 와 같은 6개의 실수 값으로 구성된 벡터일 수 있다. 이 값들은 고개를 오른쪽으로 10도, 위로 3도 기울이는 등 특정 포즈를 나타낸다고 가정한다.
-
오디오 특징 () 추출:
- 동일한 비디오 클립의 오디오로부터 Audio Encoder 를 사용하여 각 시간 에 해당하는 오디오 특징 를 추출한다.
- 숫자 예시: 는 512차원 벡터(의 출력 차원에 따라 달라짐)일 수 있으며, 특정 음절이나 말의 리듬과 관련된 정보가 담겨 있다.
-
Normalizing Flow () 학습:
- 각 와 쌍을 Normalizing Flow의 역함수 에 입력하여, 를 오디오 특징 에 조건화된 잠재 코드 로 변환한다.
- 숫자 예시: 와 같은 연산을 통해 6차원의 잠재 코드 (예: )를 얻는다.
- Maximum Likelihood Estimation (MLE) 손실: 이 들이 가우시안 분포 를 잘 따르도록 를 최소화한다. 이는 가 특정 분포에 "잘 맞도록" 네트워크를 훈련시키는 과정이다.
- 숫자 예시: 만약 이 가우시안 분포의 중심에서 멀리 떨어져 있다면( 값이 매우 작다면), 값은 커질 것이고, 이는 값을 증가시켜 모델이 를 가우시안 분포에 더 가깝게 매핑하도록 학습된다.
-
포즈 재구성 및 시간적 일관성 손실:
- 학습된 에 와 를 다시 입력하여 포즈 가중치 를 재구성한다.
- 숫자 예시: 연산을 통해 재구성된 포즈 가중치 (예: )를 얻는다.
- (포즈 재구성 손실): 실제 와 재구성된 의 차이를 최소화한다.
- 숫자 예시: 는 두 6차원 벡터 간의 유클리드 거리가 되고, 이 값이 작아지도록 모델을 학습시킨다.
- (시간적 일관성 손실): 연속된 포즈 변화의 유사성을 보장한다.
- 숫자 예시: 와 사이의 차이를 최소화한다. 예를 들어 실제 고개가 오른쪽으로 10도 움직였다면, 생성된 포즈도 유사하게 오른쪽으로 10도 움직이도록 학습한다. 이 손실은 갑작스러운 고개 떨림(jitter)을 줄이는 데 기여한다.
-
-
추론 과정 (Inference Process) 예시
학습이 완료된 모델은 새로운 오디오 입력만으로 다양하고 자연스러운 머리 포즈를 생성할 수 있다.
-
새 오디오 입력 및 특징 추출:
- 예시: "안녕하세요"라는 새로운 오디오 클립이 주어졌다. 이 오디오는 학습에 사용되지 않은 새로운 입력이다.
- Audio Encoder 를 통해 이 오디오의 특징 를 각 시간 에 대해 추출한다.
-
잠재 코드 () 샘플링:
- 학습 과정에서 구축된 가우시안 분포 에서 임의로 잠재 코드 를 샘플링한다.
- 숫자 예시: 6차원의 벡터(예: )를 무작위로 추출한다.
-
포즈 가중치 () 생성:
- 샘플링된 와 해당 오디오 특징 를 Normalizing Flow 에 입력하여, 새로운 포즈 가중치 를 생성한다.
- 숫자 예시: 연산을 통해 6차원의 포즈 가중치 (예: )를 얻는다.
- 이 과정을 통해 "안녕하세요"라는 같은 오디오에 대해서도, 를 다르게 샘플링할 때마다 고개를 끄덕이거나 약간 기울이는 등 미묘하게 다른, 그러나 자연스러운 머리 포즈를 생성할 수 있다.
-
-
수식 상세 설명 (예시 포함)
-
Maximum Likelihood Estimation (MLE) 손실 ():
- :
- 이 식은 Normalizing Flow의 핵심 변환이다. 실제 포즈 가중치 를 오디오 특징 에 조건화하여 잠재 공간의 로 매핑한다.
- 숫자 예시: 만약 이고 가 특정 오디오 특징 벡터라면, 는 이를 와 같은 표준 가우시안 분포에 가까운 6차원 벡터로 변환하려고 시도한다.
- :
- 잠재 코드 가 표준 가우시안 분포 를 따를 '확률'을 최대화하는 손실 함수이다. 음의 로그(log)를 취하므로, 가 클수록 도 커지고, 는 작아진다.
- 숫자 예시: 만약 가 의 중심에 매우 가깝다면, 는 높은 값(예: 0.8)을 가질 것이고, 는 음수지만 비교적 작은 절대값(예: )을 갖는다. 반대로 가 분포에서 멀다면 는 매우 작은 값(예: 0.001)을 갖고 는 큰 음수값(예: )을 갖게 되어 를 증가시킨다. 목표는 이 손실을 최소화하여 모든 가 가우시안 분포에 잘 부합하도록 만드는 것이다.
- :
-
포즈 재구성 손실 () 및 시간적 일관성 손실 ():
- :
- 실제 포즈 가중치 와 Normalizing Flow의 순방향 연산 으로 재구성된 사이의 유클리드 거리(L2 노름)의 제곱이다. 생성된 포즈가 원본 포즈와 최대한 유사하게 만들어지도록 한다.
- 숫자 예시: 가 250개의 6차원 실제 포즈 벡터 묶음이고, 가 250개의 6차원 재구성 포즈 벡터 묶음이라면, 이 손실은 각 프레임의 벡터 차이 제곱을 합산하여 최소화한다. 예를 들어, 이고 일 때, 와 같은 계산으로 차이를 측정한다.
- :
- 연속적인 두 프레임(와 ) 사이의 실제 포즈 변화량과 재구성된 포즈 변화량 사이의 유클리드 거리 제곱이다. 이는 생성된 머리 포즈의 움직임이 시간적으로 부드럽고 자연스럽도록 돕는다.
- 숫자 예시: 만약 실제 포즈가 에서 로 갈 때 고개가 5도 오른쪽으로 움직였다면, 생성된 포즈도 유사하게 5도 오른쪽으로 움직이도록 제어한다. 즉, 와 두 벡터가 서로 가까워지도록 한다. 이 손실은 비디오에서 흔히 발생하는 '고개 떨림(jitter)' 현상을 방지하는 데 중요하다.
- :
-
-
Semantically-Aware Expression Generation
EDTalk 프레임워크에서 의미론적으로 인식되는 표정(Semantically-Aware Expression)을 생성하는 과정은 다음과 같다. 원하는 표정을 담은 비디오를 항상 찾기 어렵다는 점 때문에 발생하는 한계를 극복하기 위해 오디오와 텍스트에 포함된 감정 정보를 활용한다.
-
목표: 주어진 오디오와 텍스트에서 감정 정보를 추출하여, 해당 감정에 맞는 표정(expression)을 가진 토킹 헤드 비디오를 생성하는 것이다.
-
핵심 모듈:
- Semantics Encoder (): 오디오 입력에서 의미론적 특징을 추출하는 인코더이다.
- 사전 학습된 HuBERT 모델 [22]을 기반으로 구축되었다.
- HuBERT 모델은 CNN 기반 특징 인코더와 트랜스포머 기반 인코더로 구성된다.
- EDTalk에서는 CNN 기반 특징 인코더는 동결(freeze)하고, 트랜스포머 블록만 미세 조정(fine-tune)한다.
- Text Encoder (): 텍스트 입력에서 전반적인 감정적 맥락을 인코딩하는 인코더이다.
- 사전 학습된 Emoberta 모델 [29]에서 파라미터를 가져와 사용한다.
- MLP (): 와 가 생성한 임베딩(embeddings)을 연결(concatenate)하여 표정 가중치 를 생성한다.
- Semantics Encoder (): 오디오 입력에서 의미론적 특징을 추출하는 인코더이다.
-
훈련 중 마스킹 전략 (Equation 15):
- 추론 시 오디오나 텍스트에 항상 감정 정보가 내재되어 있지 않을 수 있다 (예: TTS(Text-To-Speech)로 생성된 음성). 이러한 상황에서도 단일 모달리티(modality)로부터 감정을 예측할 수 있도록, HuBERT [22]에서 영감을 받아 훈련 중에 확률 로 하나의 모달리티를 무작위로 마스킹(masking)한다.
- 수식은 다음과 같다:
- 여기서 은 해당 모달리티를 마스킹하는 연산이다.
- 가 0.5 이상 1 이하일 때: 오디오 와 텍스트 모두의 임베딩을 사용한다.
- 가 0.25 이상 0.5 미만일 때: 오디오 임베딩 를 마스킹하고 텍스트 임베딩 만 사용한다.
- 가 0 이상 0.25 미만일 때: 텍스트 임베딩 를 마스킹하고 오디오 임베딩 만 사용한다.
-
손실 함수 ():
- 가 사전 학습된 ELN(Expression-aware Latent Navigation) 모듈이 감정 프레임에서 생성한 실제 표정 가중치 에 가깝도록 유도하기 위해 손실을 사용한다: .
이러한 과정을 통해 EDTalk은 신원 이미지와 구동 오디오만으로 확률론적이며 의미론적으로 인식되는 표정의 토킹 헤드 비디오를 생성할 수 있다.
-
-
