1. Introduction
-
오디오 기반 얼굴 애니메이션 분야의 발전과 한계:
- 최근 GAN(18) 및 Diffusion Model(DM)(13, 22)과 같은 생성 모델의 발전에 힘입어, 오디오 기반 얼굴 애니메이션은 가상 비서, 교육, 가상 현실 등 다양한 분야에서 유망한 응용 가능성을 보여주며 사실감과 표현력이 크게 향상되었다.
- 그러나 기존 방법론들은 긴 오디오 입력에 대해 오류 누적(error accumulation) 및 정체성 변화(identity drift)와 같은 문제로 인해 초기 몇 초 이후에는 품질 저하가 발생하는 한계를 가졌다(52, 65).
- 이러한 문제를 해결하기 위해 일부 연구는 타겟 머리 위치나 랜드마크와 같은 외부 공간 정보(11, 56, 63)를 사용했지만, 이는 애니메이션을 미리 정의된 움직임에 제한하여 표현력을 떨어뜨렸다. 다른 방법들은 이전 움직임 프레임(52, 65)을 문맥 정보로 활용했지만, 자기회귀(autoregressive) 방식의 특성상 작은 오류들이 시간에 따라 누적되어 전반적인 품질을 저하시켰다.
-
긴 시퀀스에서의 감정 및 NSV 처리의 중요성 간과:
- 기존의 감정 기반 오디오-구동 모델들은 대개 고정된 감정 상태(17, 27, 55)를 가정하거나 이산적인 감정 레이블(17, 19)에 의존하여, 실제 인간의 감정처럼 지속적으로 변화하는 미묘하고 유동적인 표현을 포착하지 못했다(62). Valence(긍정/부정) 및 Arousal(각성/진정)과 같은 연속적인 감정 차원은 감정 상태를 더 정확하게 묘사하는 데 중요하지만(2, 62), 이에 대한 연구는 부족했다.
- 웃음, 한숨과 같은 비음성 발성(Non-Speech Vocalizations, NSVs) 또한 자연스러운 의사소통에 필수적이지만(45, 48), 대부분의 오디오 기반 얼굴 애니메이션 모델에서는 간과되었다.
-
KeyFace의 제안 및 주요 기여:
- 이러한 한계점들을 해결하기 위해, KeyFace는 키프레임 기반 접근 방식(43, 67, 69)에서 영감을 받아 새로운 2단계 확산 기반 프레임워크를 제안한다.
- 1단계: 키프레임 생성(Keyframe generation): 오디오 입력과 정체성 프레임(identity frame)에 기반하여 낮은 프레임 레이트로 키프레임을 생성한다. 이는 확장된 시간 범위에 걸쳐 필수적인 얼굴 표정과 움직임을 포착하며, 긴 시퀀스에서도 정체성 일관성을 유지하고 오류 누적을 방지하는 앵커 포인트 역할을 한다.
- 2단계: 보간(Interpolation): 보간 모델이 키프레임 사이의 간격을 채워 부드러운 전환과 시간적 일관성을 보장한다. 이 2단계 분리를 통해 움직임 제어와 정체성 제어를 암묵적으로 분리하여 더 자연스러운 움직임과 향상된 정체성 보존을 달성한다.
- 추가적인 현실감 향상:
- 연속적인 감정 표현(continuous emotion representations)을 통합하여 미묘한 감정 변화를 포착한다 (valence 및 arousal 활용).
- 비음성 발성(NSVs)을 처리하여 웃음이나 한숨 같은 비언어적 소리까지 자연스러운 애니메이션에 포함한다.
- 평가 지표 도입: 립 싱크(lip synchronization) 및 NSV 생성을 평가하기 위한 새로운 지표인 LipScore와 NSV accuracy를 도입하였다.
- 실험 결과: KeyFace는 기존 최첨단 방법론보다 확장된 시간 동안 자연스럽고 일관성 있는 얼굴 애니메이션을 생성하며, NSV 및 연속적인 감정까지 성공적으로 포괄함을 보여준다.
2. Related Works
생략
3. Method
3.1 Latent diffusion
-
확산 모델(Diffusion Models)
- Denoising Diffusion Probabilistic Models [13, 22]은 마르코프 연쇄(Markov chains)와 가우시안 커널(Gaussian kernel)을 기반으로 하는 생성 모델이다.
- 두 가지 주요 과정으로 구성된다:
- 순방향 과정 (Forward Process): 초기 데이터 포인트(예: 깨끗한 이미지)에 점진적으로 가우시안 노이즈를 추가하여 완전히 노이즈가 섞인 상태로 만든다.
- 역방향 과정 (Reverse Process): 노이즈가 섞인 샘플에서 노이즈를 제거하여 여러 단계에 걸쳐 원래의 데이터를 재구성한다. 이 과정은 학습된 신경망에 의해 수행된다.
- 한계: 전통적인 확산 모델은 고품질 이미지를 생성하기 위해 많은 샘플링 단계가 필요하여 계산 비용이 매우 높다는 단점이 있다.
-
EDM(Elucidating the Design Space of Diffusion-Based Generative Models) 프레임워크
- Elucidating the design space of diffusion-based generative models [31]는 이러한 계산 비용 문제를 완화하기 위해 도입되었다.
- 확산 과정을 확률 미분 방정식(stochastic differential equation)으로 정의하고, 노이즈 제거를 위해 오일러 솔버(Euler solver)를 활용한다.
- 이를 통해 필요한 확산 단계를 줄여 효율성을 높인다.
- 학습 가능한 디노이저 는 다음 공식으로 매개변수화된다:
- : 이 식은 훈련될 디노이저 모델 가 노이즈가 섞인 입력 와 노이즈 레벨 를 받아들이는 방식을 나타낸다. 이 모델은 노이즈가 섞인 입력에서 노이즈를 제거하여 깨끗한 데이터에 가까운 출력을 생성하는 역할을 한다.
- : 모델의 입력으로, 현재 노이즈가 추가된 상태의 데이터이다.
- : 현재 데이터에 추가된 노이즈의 강도 또는 레벨을 나타낸다. 이 값은 확산 과정의 각 단계에서 변한다.
- : 실제로 학습되는 신경망(주로 U-Net 아키텍처를 가짐)을 의미한다. 이 네트워크는 입력 와 노이즈 조건 를 바탕으로 노이즈 예측 또는 깨끗한 데이터 예측과 같은 핵심 노이즈 제거 작업을 수행한다.
- : 이들은 노이즈 레벨 에 따라 동적으로 결정되는 스케일링 팩터(scaling factors)이다. 이 팩터들은 모델의 입력 와 의 출력을 적절히 조절하여, 확산 모델의 학습을 안정화하고 다양한 노이즈 레벨에서 고품질 생성을 가능하게 한다. 특히, 는 원본 입력 의 정보를 유지하면서 노이즈 제거된 결과를 생성하는 데 기여하며, 이는 잔차 연결(residual connection)과 유사한 역할을 한다.
-
잠재 확산 모델(Latent Diffusion Models, LDMs)
- High-resolution image synthesis with latent diffusion models [47]는 계산 비용을 더욱 절감하기 위해 도입되었다.
- 사전 학습된 VAE(AUTO-ENCODING VARIATIONAL BAYES) [35]를 통합한다.
- 작동 방식:
- 원본 고차원 데이터(예: 고해상도 이미지 또는 비디오 프레임)를 VAE 인코더를 통해 더 작고 압축된 잠재 공간(latent space)으로 매핑한다.
- 확산 과정은 이 저차원의 잠재 공간에서 효율적으로 적용된다.
- 잠재 공간에서 노이즈 제거된 샘플은 VAE 디코더를 통해 다시 원래의 고차원 공간으로 복원된다.
- 장점: 고차원 픽셀 공간에서 직접 확산 과정을 수행하는 대신, 압축된 잠재 공간에서 작업을 수행함으로써 계산 비용을 크게 줄이고 메모리 효율성을 높여, 고해상도 이미지 및 비디오 생성에 특히 유리하다. KeyFace 역시 Stable Video Diffusion (SVD) [3]를 기반으로 하는데, SVD 또한 LDM의 원리를 활용한다.
3.2 Keyframe generation
-
개념 및 목표:
- 이 단계는 긴 시간 동안의 오디오 입력으로부터 필수적인 얼굴 표정 및 움직임을 나타내는 키프레임 시퀀스를 생성하는 것이다.
- 생성된 키프레임은 이후 보간(interpolation) 단계의 '기준점(anchor points)'으로 작용하며, 최종 애니메이션이 오디오 내용과 관련 감정 표현을 정확하게 반영하도록 보장한다.
- 이를 통해 장기적인 시간적 일관성(temporal coherence)과 사실성(realism)을 유지하는 것을 목표로 한다.
-
저프레임률(Low Frame Rate) 생성:
- 모델은 전체 비디오 시퀀스를 한 번에 생성하는 대신,
T개의 키프레임을S프레임 간격으로 생성한다. - 이러한 저프레임률 접근 방식은 장기적인 시간적 의존성(long-range temporal dependencies)을 효율적으로 포착하면서도 계산 부담을 줄이고, 전체 시퀀스에 걸쳐 일관된 얼굴 정체성과 움직임을 유지하는 데 유리하다.
- 모델은 전체 비디오 시퀀스를 한 번에 생성하는 대신,
-
입력 및 조건화(Conditioning):
- 노이즈 처리된 입력 시퀀스 (): 모델은 확산(diffusion) 과정의 입력으로 노이즈가 추가된 잠재 공간(latent space) 시퀀스 를 받는다. 여기서 는 채널 수, 는 생성할 키프레임 수, 는 공간 해상도를 나타낸다.
- 정체성 프레임 (): 생성될 인물의 정체성(identity)과 배경 정보를 제공하기 위해, 단일 '정체성 프레임' 가 VAE(Variational Autoencoder) 인코더를 통과하여 잠재 공간으로 매핑된 후, 노이즈 처리된 입력 시퀀스와 채널 방향으로 연결(concatenate)된다. 이는 U-Net 아키텍처의 스킵 연결(skip connections)을 효과적으로 활용하여 입력의 세부 정보를 보존하는 데 기여한다.
- 오디오 임베딩: Section 3.4에서 설명하는 WavLM [8]과 BEATs [9] 같은 사전 학습된 오디오 인코더에서 추출된 임베딩이 모델의 크로스 어텐션(cross-attention) 레이어 및 타임스텝 임베딩(timestep embeddings)에 조건으로 주입되어, 오디오 내용과 동기화된 얼굴 움직임을 유도한다. WavLM은 언어적 내용에, BEATs는 비음성 보컬(NSVs) 포함한 광범위한 음향 신호에 특화되어 있다.
- 감정(Valence & Arousal) 표현: Section 3.5에서 논의되는 연속적인 감정 표현인 '가치(Valence)'와 '각성(Arousal)'이 사전 학습된 감정 인식 모델 [50]을 통해 추출되어 사인파 임베딩(sinusoidal embeddings) 형태로 확산 타임스텝 임베딩에 추가된다. 이는 이산적인 감정 레이블 대신 미묘하고 연속적으로 변화하는 감정을 반영한 표정 생성을 가능하게 하며, 특히 키프레임 모델에만 적용되어도 효과적인 감정 제어가 가능하다.
3.3 Interpolation
-
동일한 아키텍처 활용: 보간 모델은 키프레임 생성 모델과 동일한 U-Net 기반의 아키텍처를 사용하지만, 보간 작업에 맞게 컨디셔닝 입력 방식이 조정된다. 이는 모델의 재사용성을 높이고, 두 단계 간의 일관성을 유지하는 데 도움이 된다.
-
컨디셔닝 프레임 (Conditioning Frames):
- 키프레임 시퀀스에서 연속된 두 프레임, 즉 시작 프레임()과 끝 프레임()을 컨디셔닝 입력으로 사용한다.
- 이 두 프레임은 보간될 중간 시퀀스의 '앵커 포인트(anchor points)' 역할을 한다.
-
입력 시퀀스 구성 (Input Sequence Construction):
- 보간 모델의 입력 형태()에 맞추기 위해, 시작 프레임()과 끝 프레임() 사이에 학습된 임베딩()을 채워넣어 시퀀스 를 구성한다.
- 여기서 는 "누락된 프레임"을 대표하는 학습 가능한 임베딩으로, 모델이 이 임베딩을 통해 중간 프레임의 일반적인 특징을 학습하도록 유도한다.
- 이렇게 구성된 는 노이즈가 추가된 입력과 채널 방향으로 연결(concatenate)되어 모델에 입력된다.
-
이진 마스크 (Binary Mask):
- 모델에 컨디셔닝된 프레임()과 보간해야 할 프레임(이 위치한 곳)을 명확하게 구분시키기 위해 이진 마스크 를 사용한다.
- 마스크 은 해당 프레임이 컨디셔닝 프레임(시작 프레임 또는 끝 프레임)임을 나타내고, 은 해당 프레임이 보간되어야 할 중간 프레임임을 나타낸다.
- 이 마스크는 모델이 컨디셔닝 정보에 더 집중하고, 중간 프레임의 생성에 더 많은 자원을 할애하도록 돕는다.
3.4. Audio encoding
KeyFace 프레임워크에서 오디오 인코딩은 오디오 입력에서 의미 있는 특징을 추출하여 얼굴 애니메이션 생성에 활용하는 과정이다. 특히 이 과정은 음성(speech)과 더불어 웃음이나 한숨 같은 비음성 발화(Non-Speech Vocalizations, NSVs)를 효과적으로 처리하도록 설계되었다.
-
두 가지 사전 학습된 오디오 인코더 결합:
- WavLM (): WavLM은 음성에서 언어적 내용(linguistic content)을 포착하는 데 뛰어난 성능을 보인다.
- BEATs (): BEATs는 비음성 사운드를 포함한 더 넓은 범위의 음향 신호에서 특징을 추출하도록 훈련되었다. 이 두 인코더의 결합은 음성뿐만 아니라 다양한 NSV를 자연스럽게 처리하는 데 기여한다.
-
임베딩 결합:
- 각 인코더에서 얻은 임베딩 와 를 채널 방향으로 연결(concatenate)하여 결합된 오디오 임베딩 를 생성한다.
- 수식은 다음과 같다:
- 여기서 은 사용되는 모델(keyframe 또는 interpolation)에 따라 시퀀스 길이 또는 를 나타내며, 는 각 오디오 임베딩의 차원이다.
-
모델에 오디오 임베딩을 주입하는 두 가지 메커니즘:
- Audio Attention Blocks: 결합된 임베딩 는 U-Net 아키텍처 내의 cross-attention 레이어에서
key와value로 사용된다. 이는 모델이 오디오 특징 중 어떤 부분이 현재 생성 중인 시각적 프레임과 가장 관련이 있는지 파악하여 집중할 수 있도록 돕는다. - Timestep Embeddings: 는 MLP(Multi-Layer Perceptron)를 통과한 후, diffusion timestep embedding 에 더해진다. 이 과정을 통해 오디오 정보가 확산 과정의 시간적 진행에 통합되어 이미지와 오디오 프레임 간의 정렬(alignment)을 강화한다.
- 수식은 다음과 같다:
여기서 는 timestep embedding의 차원이다.
- Audio Attention Blocks: 결합된 임베딩 는 U-Net 아키텍처 내의 cross-attention 레이어에서
이러한 오디오 인코딩 방식은 KeyFace가 긴 시퀀스에서도 높은 품질과 시간적 일관성을 유지하며, 다양한 감정과 비음성 발화까지 표현할 수 있는 자연스러운 얼굴 애니메이션을 생성하는 데 중요한 역할을 한다. 특히 기존 오디오 기반 얼굴 애니메이션 연구들이 주로 음성에만 집중했던 한계를 극복하고, Laughing Matters 등 특정 NSV에 대한 연구를 넘어 더 포괄적인 접근을 제시하는 부분이다.
3.5. Emotion modelling with valence and arousal
이 섹션은 KeyFace 모델이 복잡하고 지속적으로 변화하는 감정 표현을 어떻게 포착하고 애니메이션에 적용하는지에 대해 설명한다. 특히, 감정을 valence와 arousal이라는 연속적인 차원으로 모델링하는 방식과 이를 디퓨전 모델의 timestep embedding에 통합하는 과정을 다룬다.
-
Valence와 Arousal 기반의 연속적인 감정 표현:
- 이론적 배경: 전통적인 감정 모델링은 '기쁨', '슬픔', '화남'과 같은 이산적인(discrete) 감정 레이블을 사용하는 경우가 많다. 그러나 실제 인간의 감정은 훨씬 더 미묘하고 유동적이다. 이를 포착하기 위해
KeyFace는valence(긍정성-부정성)와arousal(활성화-비활성화)이라는 두 가지 연속적인 차원을 사용한다.- Valence: 감정이 얼마나 긍정적인지(행복) 또는 부정적인지(슬픔)를 나타내는 척도이다. 예를 들어, 매우 행복한 상태는 높은
valence를 가지며, 매우 슬픈 상태는 낮은valence를 가진다. - Arousal: 감정의 강도 또는 활성화 정도를 나타내는 척도이다. 예를 들어, 흥분된 상태는 높은
arousal을 가지며, 차분한 상태는 낮은arousal을 가진다.
- Valence: 감정이 얼마나 긍정적인지(행복) 또는 부정적인지(슬픔)를 나타내는 척도이다. 예를 들어, 매우 행복한 상태는 높은
- 장점:
valence와arousal을 사용하면 이산적인 레이블로는 표현하기 어려운 감정의 미묘한 변화와 혼합된 감정 상태(예: 초조함, 놀라움 등)를 보다 정교하게 모델링할 수 있다. 이는[2, 62]와 같은 연구에서도 그 효과가 입증된 바 있다. 기존 감정 관련 연구들(EDTalk, EAT, EAMM)이 주로 고정된 감정 상태나 이산적인 레이블에 의존했던 한계를 극복하고, 실제 대화에서 나타나는 감정의 흐름을 반영할 수 있게 된다.
- 이론적 배경: 전통적인 감정 모델링은 '기쁨', '슬픔', '화남'과 같은 이산적인(discrete) 감정 레이블을 사용하는 경우가 많다. 그러나 실제 인간의 감정은 훨씬 더 미묘하고 유동적이다. 이를 포착하기 위해
-
감정 정보 추출 및 임베딩:
KeyFace는 각 프레임에 대해 미리 학습된 감정 인식 모델(HSEmotion)을 사용하여valence및arousal값을 추출한다.- 추출된
valence와arousal값은sinusoidal embeddings Ev, Ea ∈ RCs로 인코딩된다.Sinusoidal embedding은 시간적 또는 연속적인 정보를 모델이 이해하기 쉬운 고차원 벡터 공간으로 매핑하는 효과적인 방법이다. 여기서RCs는timestep embedding의 차원을 의미한다.
-
Diffusion Timestep Embedding과의 통합:
-
인코딩된
Ev와Ea는diffusion timestep embedding과 오디오 임베딩이 결합된t's에 추가된다. 이는 다음 수식으로 표현된다: -
각 항의 의미:
- :
valence와arousal정보까지 최종적으로 통합된diffusion timestep embedding이다. 디퓨전 모델의 각 노이즈 제거 단계에서 이 임베딩이 조건으로 사용되어, 특정 감정 상태의 얼굴 애니메이션을 생성하도록 유도한다. - : 이전 섹션(3.4. Audio encoding)에서 설명된 대로, 오리지널
diffusion timestep embedding(ts)에WavLM과BEATs를 통해 얻은 오디오 임베딩 (Awb)을MLP를 거쳐 추가한 결과이다. 즉,t's = ts + MLP(Awb)이다. 이t's는 오디오와 이미지 프레임 간의 정렬을 촉진한다. - : 현재 프레임의
valence값을sinusoidal embedding으로 인코딩한 벡터이다. 이 벡터가timestep embedding에 추가되어 모델이valence정보에 따라 감정 표현을 조절하도록 한다. - : 현재 프레임의
arousal값을sinusoidal embedding으로 인코딩한 벡터이다. 이 벡터 또한timestep embedding에 추가되어 모델이arousal정보에 따라 감정 강도를 조절하도록 한다.
- :
-
통합의 목적: 이처럼
timestep embedding에 오디오와 감정 정보를 함께 주입함으로써, 디퓨전 모델은 노이즈 제거 과정에서 오디오에 동기화되고 원하는valence및arousal에 해당하는 얼굴 표정을 생성할 수 있게 된다.
-
-
키프레임 모델에만 감정 통합하는 이유:
KeyFace연구에서는 감정 정보를 오직키프레임 생성 모델에만 통합하는 것으로도 효과적인 감정 제어가 충분하다는 것을 발견했다.- 이는 키프레임이 긴 시퀀스에 걸쳐 핵심적인 얼굴 표현과 움직임의 앵커 포인트 역할을 하기 때문이다. 키프레임에 감정 정보가 잘 반영되면, 이후 보간(interpolation) 모델은 추가적인 감정 조건 없이도 키프레임 사이의 프레임들을 채우면서 감정 표현을 자연스럽게 전파(propagate)할 수 있다. 결과적으로, 감정 정보가 키프레임에 "압축"되어 장기적인 일관성을 유지하게 된다. 이 방식은 모델의 복잡성을 줄이면서도 충분한 감정 제어 능력을 제공하는 효율적인 접근 방식이다.
3.6. Losses
KeyFace 모델은 사실적이고 일관성 있는 얼굴 애니메이션을 생성하기 위해 다양한 손실 함수를 사용한다. 특히, latent space에서 작업하는 것이 계산 효율적이지만, 원본 이미지의 미세한 semantic detail을 유지하기 어렵다는 문제점을 해결하기 위해 여러 손실 구성 요소를 통합하고 있다. 이는 특히 인간의 얼굴에 있어서 작은 결함이라도 애니메이션의 현실감과 감정 표현력을 저해할 수 있기 때문에 매우 중요하게 다뤄진다.
-
잠재 공간(Latent Space) L2 손실 ():
- 개념: Diffusion 모델에서 노이즈가 제거된 예측 잠재값()과 실제 잠재값() 사이의 평균 제곱 오차(L2)를 계산하는 손실 함수이다.
- 목적: Latent Diffusion Models (LDMs) [47]은 고해상도 이미지를 직접 처리하는 대신 VAE(Variational Autoencoder) [35]를 통해 데이터를 압축된 잠재 공간으로 매핑하여 계산 효율성을 높인다. 이 손실은 모델이 잠재 공간에서 정확하게 노이즈를 제거하고 원본 데이터 분포를 학습하도록 유도하는 핵심적인 역할을 한다.
-
픽셀 공간(Pixel Space) L2 손실 ():
- 개념: Latent space에서 디코딩된 RGB 이미지()와 실제 RGB 이미지() 사이의 L2 손실이다.
- 목적: 잠재 공간의 압축된 표현은 미세한 시각적 디테일을 손상시킬 수 있다 [72]. 특히 얼굴 애니메이션의 경우, 이러한 미세 디테일의 손상은 현실감을 크게 떨어뜨릴 수 있다. 픽셀 공간 손실은 최종 결과물이 원본 이미지의 시각적 품질과 디테일을 최대한 가깝게 유지하도록 강제하여, 잠재 공간에서의 손실이 야기할 수 있는 문제를 보완한다. 모델은 잠재 공간에서만 학습하는 것이 아니라, 최종 픽셀 결과물에 대해서도 명시적으로 학습하게 된다.
-
지각 손실(Perceptual Loss, ):
- 개념: 미리 학습된 VGG 네트워크 [29]에서 추출된 feature들을 기반으로 계산되는 손실이다. VGG와 같은 CNN은 이미지의 특징(edge, texture, object parts 등)을 계층적으로 학습하며, 이 특징 공간에서의 유사성은 픽셀 단위의 유사성보다 인간의 시각적 인지에 더 가깝다고 알려져 있다.
- 목적: 생성된 이미지가 픽셀 단위로 완벽히 일치하지 않더라도, 지각적으로(perceptually) 원본과 유사하도록 유도하여 시각적 품질을 향상시킨다. 이는 단순히 픽셀값을 맞추는 것보다 실제 사람이 보기에 더 자연스러운 이미지를 만드는 데 기여한다.
-
총 손실 함수:
모델의 총 손실 함수 은 다음과 같이 정의된다:- : 위에서 설명한 잠재 공간 L2 손실이다.
- : 위에서 설명한 픽셀 공간 L2 손실이다.
- : 위에서 설명한 지각 손실이다.
- : 이 세 가지 손실에 적용되는 총 가중치 요소이다. 이 가중치는 로 다시 구성된다.
- : 확산 timestep 에 의존하는 가중치 요소로, Elucidating the Design Space of Diffusion-Based Generative Models에서 정의된 바에 따라, 확산 과정의 특정 단계에서 모델이 특정 노이즈 레벨에 더 집중하도록 돕는 역할을 한다.
- : 이미지의 하단 절반(주로 입술 영역)에 적용되는 특수 가중치이다. 이 가중치를 높게 설정하면 모델이 입술 영역의 디테일과 오디오와의 동기화에 더 집중하도록 유도한다. 이는 사실적인 오디오-구동 얼굴 애니메이션에서 입술 동기화가 매우 중요하기 때문에 도입된 핵심적인 요소이다. 저자들은 실험을 통해 일 때 최적의 균형을 이룬다고 보고하였다.
-
메모리 효율성 전략:
- 저자들은 메모리 소비를 줄이기 위해 전체 시퀀스에 픽셀 손실(L2 및 Lp)을 적용하는 대신, 무작위로 선택된 단일 프레임에만 추가적인 픽셀 손실을 적용하였다. 이는 고품질 결과를 생성하는 데 충분하다고 언급된다. 반면, 표준 diffusion loss는 모든 프레임에 걸쳐 계속 적용된다.
이러한 다중 손실 함수 전략은 KeyFace 모델이 잠재 공간의 효율성을 유지하면서도, 최종 픽셀 결과물의 시각적 디테일, 지각적 유사성, 그리고 얼굴 애니메이션의 핵심인 입술 동기화 품질을 효과적으로 향상시키는 데 기여한다.
연구의 진전과 확장:
KeyFace는 Diffusion Model의 잠재 공간 학습이 고해상도 디테일을 유지하기 어렵다는 일반적인 문제에 대해, 픽셀 공간 손실과 지각 손실을 도입하여 해결하는 접근 방식을 보여준다. 이는 Show-1과 같은 다른 텍스트-투-비디오 생성 모델에서도 유사하게 활용되는 전략이다. 특히 얼굴 애니메이션이라는 특정 도메인에서는 미세한 디테일이 현실감에 미치는 영향이 크기 때문에, 와 같은 특정 영역에 대한 가중치 부여는 더욱 효과적인 해결책으로 작용한다.
3.7. Guidance
Diffusion 모델에서 'Guidance(안내)'는 생성 프로세스를 특정 조건(예: 오디오, 신원, 감정)에 맞춰 조정하여 원하는 특성을 가진 결과물을 얻도록 돕는 메커니즘이다. KeyFace는 두 가지 주요 안내 전략을 활용하여 장기적인 안면 애니메이션의 일관성과 표현력을 향상한다.
-
배경 설명:
- Diffusion 모델의 조건부 생성: Diffusion 모델은 일반적으로 텍스트, 이미지 등 다양한 조건(condition, )을 주어 생성되는 이미지/비디오의 특성을 제어할 수 있다. 예를 들어, "웃는 얼굴"이라는 조건을 주면 모델은 웃는 얼굴을 생성하려고 노력한다.
- Guidance의 필요성: 조건이 주어진 생성 과정에서, 모델이 해당 조건에 얼마나 충실하게 결과물을 생성할지 조절하는 것이 Guidance의 핵심이다. Guidance scale()을 높이면 조건에 더 충실한(그러나 덜 다양할 수 있는) 결과가 나오고, 낮추면 조건으로부터 더 자유로운(그러나 일관성이 떨어질 수 있는) 결과가 나올 수 있다.
- CFG: CFG는 Diffusion 모델의 역확산(reverse diffusion) 과정, 즉 노이즈가 섞인 데이터()로부터 노이즈를 제거하여 깨끗한 데이터( 또는 )를 예측하는 단계에서 적용된다. Diffusion 모델은 일반적으로 특정 노이즈 레벨()에서 노이즈가 섞인 데이터 와 조건 를 받아 노이즈 예측 네트워크 를 학습한다. CFG의 핵심 아이디어는 두 가지 노이즈 예측을 조합하는 것이다:
- Conditional Noise Prediction (): 주어진 조건 에 따라 노이즈를 예측한다. 모델은 가 주어졌을 때 에서 어떤 노이즈를 제거해야 하는지 학습한다.
- Unconditional Noise Prediction (): 조건 를 무시하고(또는 으로 설정하고) 노이즈를 예측한다. 모델은 아무런 가이드 없이 에서 어떤 노이즈를 제거해야 하는지 학습한다.
-
CFG의 수식:
-
CFG의 최종 노이즈 예측 은 이 두 가지 예측의 선형 보간(linear interpolation)으로 정의된다:
-
: CFG가 적용된 최종 노이즈 예측값이다. 이 예측값은 역확산 과정에서 로부터 또는 를 샘플링하는 데 사용된다.
-
: 조건 없이(unconditionally) 예측된 노이즈이다. 이는 일반적으로 모델 학습 시 일정 확률로 조건 를 드롭아웃(dropout)시켜 얻은 예측값을 사용한다. ( 또는 빈 임베딩 등)
-
: 조건 가 주어졌을 때(conditionally) 예측된 노이즈이다.
-
: 가이던스 스케일(guidance scale) 또는 가이던스 가중치(guidance weight)이다.
- 인 실수 값이다.
- 이면, 가 되어 순수하게 조건부 예측만 사용한다.
- 이면, 조건부 예측과 비조건부 예측의 차이 를 증폭시켜 조건 의 영향을 더욱 강하게 반영한다. 이 차이 벡터는 "조건 가 데이터에 어떤 영향을 미쳐야 하는지"를 나타내는 방향으로 해석될 수 있다.
- 직관적으로, 가 높을수록 생성된 결과물은 조건 에 더욱 충실해지지만, 때로는 다양성이 감소하거나 이미지 품질이 저하될 수 있다. 반대로 가 낮으면 다양성은 높아지지만 조건 반영도가 약해질 수 있다.
-
-
Keyframe 생성 단계 (Stage 1): Classifier-Free Guidance (CFG) 활용:
- KeyFace는 오디오 입력과 신원 프레임을 기반으로 핵심적인 표정과 움직임을 포착하는 키프레임을 생성하는 단계에서 Classifier-Free Guidance (CFG)의 변형된 버전을 사용한다.
- 이 CFG는 오디오 제어와 신원 제어라는 두 가지 부분으로 나뉘며, 각각에 대해 독립적인 가이드 스케일을 설정할 수 있다.
- 제안된 Guidance 공식은 다음과 같다:
- 여기서 각 항은 다음을 의미한다:
- : 가이드가 적용된 최종 denoising 출력이다.
- : 모든 조건(오디오, 신원)이 0으로 설정된, 즉 어떤 가이드도 받지 않은 모델의 출력이다. 모델이 기본적으로 생성하는 결과에 해당한다.
- : 신원(identity) 조건만을 부여했을 때 모델의 출력이다. 오디오 조건은 주어지지 않았다.
이 때, 신원 조건은 신원 프레임(identity frame) 을 VAE (Variational Autoencoder) 인코더를 통과하여 잠재 공간(latent space) 표현으로 변환한 뒤, 노이즈가 섞인 입력 시퀀스 에 채널 방향으로 concat 하여 생성한다. - : 신원 조건과 오디오 조건이 모두 부여되었을 때 모델의 출력이다.
- : 신원 조건에 대한 가이드 스케일이다. 이 값이 클수록 생성된 얼굴의 신원이 더 명확하게 유지되도록 강하게 안내한다.
- : 오디오 조건에 대한 가이드 스케일이다. 이 값이 클수록 생성된 얼굴 움직임(특히 입술 동기화)이 오디오에 더 충실하도록 강하게 안내한다.
- 메커니즘: 이 공식은 기본 출력()에 신원 조건에 의한 차이()와 오디오 조건에 의한 차이()를 각 가이드 스케일(, )만큼 더하여 최종 출력을 조정한다. 이를 통해 모델은 특정 오디오에 동기화된, 특정 신원의 얼굴 애니메이션을 생성하도록 유도된다.
- 여기서 각 항은 다음을 의미한다:
-
보간 단계 (Stage 2): Autoguidance 활용:
- CFG는 특정 조건에 대한 모델의 충실도를 높이는 데 효과적이지만, 너무 강하게 적용되면 출력의 다양성을 감소시킬 수 있다는 단점이 있다. 특히 섬세한 감정 표현과 유연한 움직임이 중요한 보간 단계에서는 이러한 다양성 저하가 부자연스러운 결과를 초래할 수 있다.
- 이러한 문제를 해결하기 위해 KeyFace는 보간 단계에서 Autoguidance 방식을 사용한다. Autoguidance의 핵심 아이디어는 자신(메인 diffusion 모델)의 "열화된(reduced)" 버전(또는 "나쁜" 버전)을 사용하여 메인 모델의 샘플링 과정을 가이드하는 것이다. 여기서 "열화된" 버전이란 동일한 아키텍처를 가지지만, 학습 데이터의 양이 적거나, 학습 단계가 적거나, 모델 크기가 작은 등 성능이 의도적으로 제한된 모델을 의미한다.
- KeyFace의 보간 단계는 키프레임 간의 빈 공간을 채워넣어 부드러운 전환과 시간적 일관성, 그리고 자연스러운 미세 움직임을 만들어야 한다. 이 과정에서 과도하게 강한 CFG는 경직된 움직임을 유발할 수 있으며, 높은 다양성과 유연성이 요구된다.
- Autoguidance 공식은 다음과 같다:
- 여기서 각 항은 다음을 의미한다:
- : 가이드가 적용된 최종 denoising 스텝이다.
- : "Reduced model"의 출력이다. 이 모델은 메인 모델과 동일한 아키텍처를 가지지만, 학습 단계가 16배 적게 훈련된 버전을 사용한다. 해당 모델은 현재 로부터 노이즈를 제거하여 얻을 수 있는 '덜 정확하지만' 기본적인 구조와 움직임을 제공한다. 일종의 '기본적인 그림'으로, 합리적인 결과의 출발점이 된다. CFG의 (unconditional output)와 유사하게, 이는 상대적으로 약한 가이드를 제공하여 다양성을 유지하는 데 도움을 준다.
- : 완전히 훈련된 "guiding model"의 출력이다. 메인 모델과 동일한 모델로, 강한 가이드 신호를 제공한다.
- : 완전히 학습된 모델이 덜 학습된 모델보다 무엇을 더 잘 아는지, 어느 방향으로 개선되어야 하는지를 나타내는 정보이다. 이 정보를 추가로 더해줌으로써 더 좋은 방향으로 결과물을 미세하게 조절할 수 있다.
- : Autoguidance 스케일이다. 가이드 모델의 영향력을 조절하는 가중치이다.
- 메커니즘: Autoguidance는 약한 모델()의 출력에 강한 모델()과 약한 모델()의 차이를 만큼 더하여 최종 denoising 스텝을 결정한다. 이를 통해 강한 안내를 받으면서도 다양성이 완전히 희생되지 않도록 조절하여, 보간 단계에서 보다 유연하고 자연스러운 감정 표현과 움직임을 생성할 수 있다. 특히, CFG와 달리 직접적인 조건 에 대한 '강제'보다는, 모델 자신의 '지식' 수준 차이를 이용한 '자기 수정' 방식에 가깝기 때문에, 조건에 대한 과도한 집착 없이도 더 자연스러운 분포를 따르면서 개선된 결과물을 얻을 수 있다.
- 여기서 각 항은 다음을 의미한다:
요약하자면, KeyFace는 키프레임 생성에는 명확한 조건 제어가 필요한 CFG를 사용하고, 키프레임 간의 자연스러운 보간에는 다양성 유지가 중요한 Autoguidance를 사용하여 각 단계의 특성에 맞는 최적의 안내 전략을 적용한다.
3.8 Overall pipeline
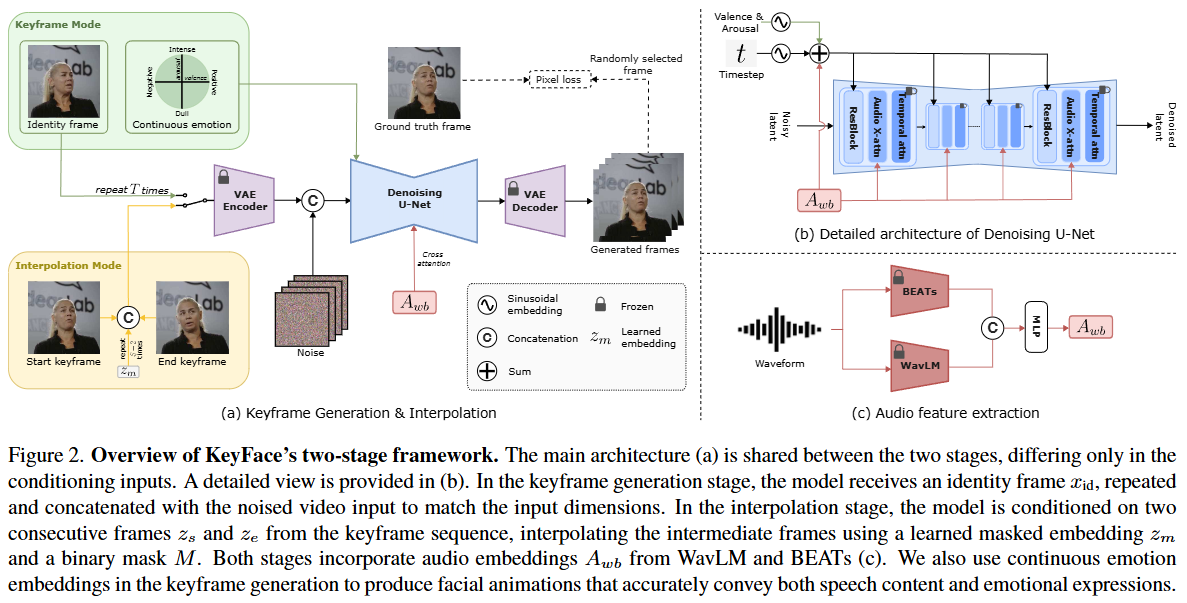
제시된 이미지는 KeyFace 논문의 핵심인 두 단계 확산 기반 프레임워크를 설명하는 Figure 2이다. 이 프레임워크는 오디오 입력으로부터 자연스럽고 일관성 있는 장기 얼굴 애니메이션을 생성하는 것을 목표로 한다.
-
(a) Keyframe Generation & Interpolation:
- 이 부분은 KeyFace의 두 가지 주요 모드인
Keyframe Mode와Interpolation Mode를 보여준다. - VAE Encoder (고정): 입력 이미지를 압축된 잠재 공간(latent space)으로 인코딩한다. 이 인코더는 학습 중에 파라미터가 고정되어 있다.
- Denoising U-Net: 잠재 공간에서 노이즈가 추가된 입력을 받아 다양한 조건 정보(오디오, 감정, 신원/키프레임)를 활용하여 노이즈를 제거하고 깨끗한 잠재 표현을 예측하는 모델이다.
- VAE Decoder (고정): 노이즈가 제거된 잠재 표현을 다시 RGB 이미지 공간으로 디코딩하여 최종 프레임을 생성한다. 이 디코더 역시 학습 중에 파라미터가 고정되어 있다.
Keyframe Mode:- Identity frame: 생성할 인물의 신원(identity) 및 배경 정보를 제공하는 정지 이미지이다. 이는 VAE Encoder를 통과한 후 노이즈 입력과 결합되어
Denoising U-Net의 조건으로 입력된다. 이러한 일련의 과정은 키프레임 시퀀스의 길이 만큼 반복된다. - Continuous emotion: Valence(쾌락-불쾌)와 Arousal(각성-비각성)의 두 가지 차원을 사용하여 시간에 따라 변화하는 감정 상태를 연속적으로 표현한다. 이 감정 정보는 시노소이드 임베딩을 거쳐 확산 타임스텝 임베딩에 추가되어 모델이 감정 표현을 생성하도록 유도한다.
- 이 모드에서는 오디오 입력과 신원 프레임, 연속 감정 정보를 기반으로 낮은 프레임 레이트의 키프레임 시퀀스를 생성한다.
- Identity frame: 생성할 인물의 신원(identity) 및 배경 정보를 제공하는 정지 이미지이다. 이는 VAE Encoder를 통과한 후 노이즈 입력과 결합되어
Interpolation Mode:- Start keyframe, End keyframe:
Keyframe Mode에서 생성된 두 개의 연속적인 키프레임 와 를 조건으로 사용한다. - Learned embedding (): 이 학습된 임베딩은 중간 프레임을 나타낸다. 두 키프레임 사이에
S-2번 반복되어 삽입되며, 이를 통해Denoising U-Net이 키프레임 사이의 간격을 채우도록 학습된다. Interpolation Mode의 목표는 키프레임 사이의 부드러운 전환을 생성하여 전체 비디오의 시간적 일관성을 보장하는 것이다.
- Start keyframe, End keyframe:
- Noise: 잠재 공간에 추가되는 가우시안 노이즈이다. 확산 모델은 이 노이즈를 점진적으로 제거하는 방식으로 작동한다.
- Pixel loss:
Denoising U-Net에 의해 생성된 잠재 표현이 디코딩된 RGB 프레임 와 실제 프레임 사이의 L2 손실과 perceptual loss 를 포함한다. 이는 시각적 품질과 세부적인 얼굴 특징 보존에 기여한다. 메모리 효율성을 위해 무작위로 선택된 단일 프레임에 적용될 수 있다.
- 이 부분은 KeyFace의 두 가지 주요 모드인
-
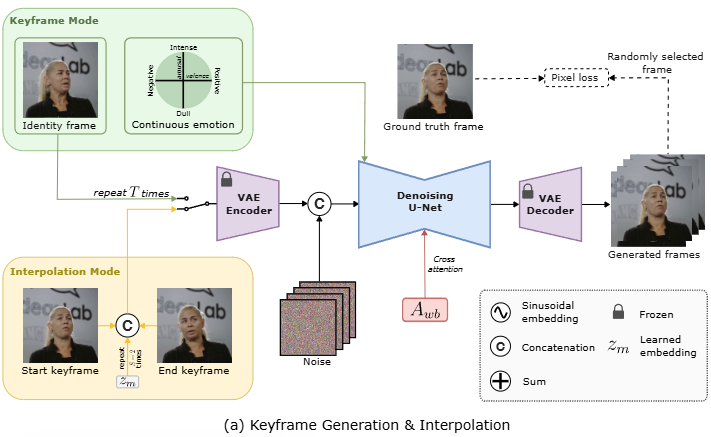
(b) Detailed architecture of Denoising U-Net:
- 이 U-Net은 노이즈 제거 과정의 핵심 구성 요소이다.
- Noisy latent: VAE Encoder에서 전달되는 노이즈가 추가된 잠재 표현이다.
- Timestep (), Valence & Arousal:
- 확산 프로세스의 현재 타임스텝 와 감정 정보인 Valence 및 Arousal은 각각 시노소이드 임베딩(sinusoidal embedding)을 거친다.
- 이 세 가지 임베딩은 서로
Sum되어Denoising U-Net에 조건으로 입력된다. 이는 모델이 현재 확산 단계와 원하는 감정 상태에 따라 노이즈를 제거하도록 안내한다.
- (Audio embeddings): WavLM과 BEATs에서 추출된 결합 오디오 임베딩이다. 이 임베딩은 U-Net 내부의
Audio X-attn (Cross-attention)블록에Key와Value로 제공되어 오디오 내용에 따른 얼굴 움직임을 생성한다. - ResBlock (Residual Block): 심층 신경망 학습을 안정화하고 성능을 향상시키는 데 사용되는 잔차 블록이다.
- Temporal attn (Temporal attention): 비디오 프레임 간의 시간적 관계를 모델링하여 장기적인 시간적 일관성을 확보한다.
- U-Net의 각 단계는
ResBlock,Audio X-attn,Temporal attn으로 구성되어 공간적 특징, 오디오-비주얼 관계, 시간적 일관성을 동시에 처리한다. 최종 출력은Denoised latent이다.
-
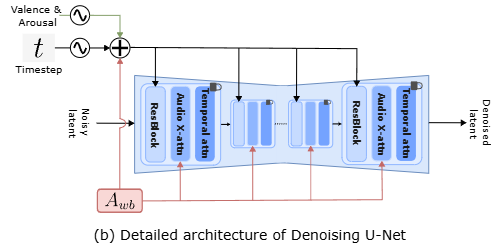
(c) Audio feature extraction:
- 이 부분은 얼굴 애니메이션을 위한 오디오 특징을 추출하는 과정을 설명한다.
- Waveform: 원본 오디오 신호이다.
- BEATs (고정): 비음성 발화(NSVs: Non-Speech Vocalizations)를 포함한 광범위한 음향 신호에서 특징을 추출하도록 사전 학습된 오디오 인코더이다. (본문 3.4절 참조) 이 모델은 학습 중에 파라미터가 고정되어 있다.
- WavLM (고정): 음성에서 언어적 내용을 포착하는 데 탁월한 사전 학습된 오디오 인코더이다. (본문 3.4절 참조) 이 모델도 학습 중에 파라미터가 고정되어 있다.
- Concatenation (C): WavLM과 BEATs에서 추출된 임베딩은 서로
Concatenation되어 결합된 오디오 임베딩을 생성한다. - MLP: Concatenated된 임베딩은 MLP (Multi-Layer Perceptron)를 통과하여
Denoising U-Net에 입력될Awb임베딩을 생성한다. Awb임베딩은Denoising U-Net의Cross-attention레이어와Timestep Embeddings에 추가되어 오디오와 이미지 프레임 간의 정렬을 촉진한다.
요약하자면, KeyFace는 먼저 오디오와 감정을 바탕으로 주요 얼굴 표정 및 움직임을 나타내는 키프레임을 생성한 다음, 보간 모델을 사용하여 이 키프레임들 사이의 간격을 채워 부드러운 전환과 시간적 일관성을 가진 장기 애니메이션을 완성한다. 이 과정에서 Diffusion Model의 U-Net 구조를 활용하고, VAE로 잠재 공간에서 효율적으로 작업을 수행하며, WavLM과 BEATs 오디오 인코더를 통해 음성 및 비음성 오디오를 모두 효과적으로 처리한다.
4. Experiments
4.1. Datasets
- 훈련 데이터셋:
- HDTF [76]: 고품질의 오디오-비주얼 데이터셋으로, 주로 음성 기반의 얼굴 애니메이션 학습에 사용되었다.
- 자체 수집 데이터셋: 160시간의 음성(speech)과 30시간의 비음성 발화(Non-Speech Vocalizations, NSVs)로 구성된 데이터셋이다. NSV는 웃음, 한숨 등 비언어적 소리를 포함하며, KeyFace가 다양한 비음성 발화에 대한 애니메이션을 생성할 수 있도록 학습하는 데 결정적인 역할을 한다.
- CelebV-Text [70] 및 CelebV-HQ [78]: 이 두 데이터셋도 실험적으로 사용되었으나, 저자들은 이 데이터셋들을 훈련에서 제외하는 것이 모델의 품질 향상에 도움이 된다는 것을 발견했다. 이는 KeyFace가 고품질의 실제와 같은 애니메이션을 생성하는 데 있어 데이터 품질이 중요함을 시사한다.
- 테스트 데이터셋:
- HDTF 테스트셋: HDTF 데이터셋의 일부로, 모델의 일반적인 성능 평가에 사용되었다.
- CelebV-Text에서 무작위로 선택된 100개 영상: CelebV-Text의 품질이 훈련에 적합하지 않다고 판단했음에도 불구하고, 테스트셋으로는 일부 사용되어 모델의 일반화 능력을 평가하는 데 기여했다.
- MEAD [60] 테스트셋: 이 데이터셋은 섹션 5.2에서 언급되듯이, KeyFace의 감정 제어 능력(emotion control)을 평가하기 위해 사용되었다. MEAD는 다양한 감정 표현을 포함하는 대규모 오디오-비주얼 데이터셋이다.
4.2. Evaluation metrics
-
이미지 품질 지표 (Image Quality Metrics)
- Aesthetic Quality (AQ) [📄 VBench]: VBench 벤치마크 스위트에서 제공하는 지표로, 생성된 이미지의 미적 품질을 평가한다.
- Fréchet Inception Distance (FID) [📄 GANs Trained by a Two Time-Scale Update Rule Converge to a Local Nash Equilibrium]:
- 생성된 이미지 분포가 실제 이미지 분포와 얼마나 유사한지를 측정하는 지표이다.
- Inception-v3 모델의 특징 공간에서 실제 이미지와 생성된 이미지의 특징 분포 간 Fréchet Distance를 계산한다.
- FID 값이 낮을수록 생성된 이미지가 실제 이미지와 시각적으로 더 유사하고 다양하다는 것을 의미한다.
- 수학적으로는 다음과 같이 정의된다:
- : 실제 이미지 데이터의 특징 분포의 평균 벡터와 공분산 행렬이다.
- : 생성된 이미지 데이터의 특징 분포의 평균 벡터와 공분산 행렬이다.
- : 두 평균 벡터 간의 유클리드 거리의 제곱을 나타낸다.
- : 행렬의 대각합(trace)을 나타낸다.
- : 행렬 곱의 행렬 제곱근이다. 이 항은 두 분포의 공분산 행렬이 얼마나 잘 겹치는지를 나타낸다.
- Learned Perceptual Image Patch Similarity (LPIPS) [74]:
- 두 이미지의 시각적 유사성을 인간의 인지적 판단에 더 가깝게 평가하기 위해 딥러닝 모델(예: AlexNet, VGG)의 특징 공간에서 거리를 측정한다.
- LPIPS 값이 낮을수록 두 이미지가 인간의 눈에 더 유사하게 보인다는 것을 의미한다.
-
일반 비디오 품질 지표 (General Video Quality Metrics)
- Fréchet Video Distance (FVD) [57]:
- 비디오 생성 모델의 품질을 평가하는 데 사용되는 지표로, FID와 유사하게 생성된 비디오 시퀀스의 특징 분포가 실제 비디오 시퀀스의 특징 분포와 얼마나 일치하는지 측정한다.
- S3D(Inflated 3D ConvNet)와 같은 사전 학습된 비디오 특징 추출기를 사용하여 비디오 시퀀스에서 특징을 추출한 후 Fréchet Distance를 계산한다.
- FVD 값이 낮을수록 생성된 비디오가 더 현실적이고 시간적으로 일관적이라는 것을 의미한다.
- Smoothness (from VBench [25]):
- VBench에서 제공하는 비디오의 시간적 부드러움(temporal smoothness)을 측정하는 지표이다.
- 비디오 프레임 간의 움직임이 얼마나 자연스럽고 일관적인지를 평가한다.
- Fréchet Video Distance (FVD) [57]:
-
감정 정확도 (Emotion Accuracy, Emoacc)
- [50]에서 사전 학습된 감정 인식 모델
HSEmotion을 사용하여 생성된 비디오의 감정 상태를 평가하고, 실제 감정 라벨(valence 및 arousal)과의 정확도를 측정한다. - KeyFace는 연속적인 감정 표현(valence 및 arousal)을 사용하므로, 이 지표는 모델이 시간의 흐름에 따라 변화하는 감정을 얼마나 정확하게 표현하는지 보여준다.
- [50]에서 사전 학습된 감정 인식 모델
-
새롭게 도입된 지표 (New Metrics Introduced)
-
LipScore:
- 기존 립싱크 평가 지표인 SyncNet [46]의 알려진 한계를 극복하기 위해 KeyFace가 새로 제안한 지표이다.
- [📄 Auto-AVSR: Audio-Visual Speech Recognition with Automatic Labels]에서 제안된 최신 립리더(lipreader) 모델의 마지막 레이어에서 추출된 임베딩(embedding) 간의 코사인 유사도를 계산한다.
- 이 립리더는 오디오(Audio)와 비디오(Visual) 두 가지 모달리티를 모두 입력으로 받아 음성 인식(Speech Recognition)을 수행하는데, SyncNet보다 6배 더 많은 데이터로 학습되어 인간의 인지적 판단과 더 잘 상관관계가 있다고 주장한다.
- LipScore가 높을수록 오디오와 입술 움직임 간의 동기화가 더 정확하고 자연스럽다는 것을 의미한다.
-
NSV accuracy (NSVacc):
- 모델이 비음성 발화(Non-Speech Vocalizations, NSVs)를 얼마나 정확하게 생성하는지 평가하기 위해 도입된 지표이다.
- 8가지 NSV 유형("Mhm", "Oh", "Ah", 기침, 한숨, 하품, 헛기침, 웃음)과 음성(speech)을 포함하여 총 9개 클래스를 인식하도록 사전 학습된 비디오 분류기(
MViTv2[37] 기반)를 사용한다. - 이 분류기를 통해 생성된 비디오의 NSV 유형을 예측하고, 실제 NSV 유형과의 일치율을 측정하여 모델의 NSV 처리 능력을 평가한다.
-
NSVacc 측정 예시:
-
NSV 분류기 훈련:
- 먼저, 음성 및 다양한 NSV 유형(예: "Mhm", "Oh", "Ah", 기침, 한숨, 하품, 헛기침, 웃음)을 포함하는 비디오 클립 데이터셋으로 별도의 NSV 분류기를 훈련한다.
- 이 분류기는 MViTv2와 같은 비디오 분류 모델을 기반으로 하며, 입력 비디오를 9가지 클래스(8가지 NSV + 1가지 음성) 중 하나로 분류하도록 학습된다.
- 예를 들어, "웃는 사람의 비디오", "기침하는 사람의 비디오", "말하는 사람의 비디오" 등을 입력으로 받아 해당 NSV 또는 음성으로 정확하게 분류하는 능력을 갖추게 된다.
-
KeyFace 모델로 비디오 생성:
- KeyFace 모델은 특정 NSV(예: "웃음") 또는 음성 오디오 입력과 함께 특정 인물(identity) 정보를 받아 페이셜 애니메이션 비디오를 생성한다.
- 예를 들어, "웃음 소리" 오디오를 KeyFace 모델에 입력하면, 모델은 그 오디오에 맞춰 인물이 웃는 표정을 짓는 비디오를 생성한다.
-
생성된 비디오를 NSV 분류기로 평가:
- KeyFace 모델이 생성한 비디오를 앞서 훈련된 NSV 분류기에 입력한다.
- NSV 분류기는 이 생성된 비디오를 분석하여 어떤 NSV 또는 음성 클래스에 속하는지 예측한다.
-
NSV accuracy 계산 예시:
- 시나리오: KeyFace 모델의 NSV 생성 능력을 평가하고 싶다.
- 설정:
- 우리는 KeyFace 모델에 "웃음" 오디오 입력을 100번 주고 100개의 비디오를 생성하게 했다.
- 또한, "기침" 오디오 입력을 100번 주고 100개의 비디오를 생성하게 했다.
- 평가 과정:
- KeyFace가 생성한 100개의 "웃음" 비디오를 NSV 분류기에 넣었을 때, 분류기가 80개의 비디오를 "웃음"으로, 10개를 "Ah"로, 10개를 "Speech"로 분류했다.
- KeyFace가 생성한 100개의 "기침" 비디오를 NSV 분류기에 넣었을 때, 분류기가 70개의 비디오를 "기침"으로, 20개를 "한숨"으로, 10개를 "Mhm"으로 분류했다.
- 결과 분석:
- "웃음" 생성에 대한 정확도는 80/100 = 80%이다.
- "기침" 생성에 대한 정확도는 70/100 = 70%이다.
- 이러한 각 NSV 유형에 대한 정확도를 모두 합산하고 평균을 내어 전체 NSV accuracy를 계산할 수 있다.
-
-
-
사용자 연구 (User Study)
- 정량적 지표 외에, 실제 사용자의 주관적인 평가를 반영하기 위한 사용자 연구도 진행되었다.
- 참가자들에게 모델별로 20개의 5초짜리 비디오 쌍을 제시하고, 시각적 품질, 립싱크 동기화, 움직임의 현실성을 기준으로 더 현실적인 비디오를 선택하도록 요청했다.
- Elo rating 시스템 [10]과 부트스트래핑(bootstrapping)을 적용하여 모델들의 안정적인 순위를 도출했다.
4.3 User study
-
연구의 목적:
- 생성된 비디오의 '시각적 품질(visual quality)', '립 싱크(lip synchronization)', '모션 현실감(motion realism)'과 같은 중요한 요소들을 인간이 어떻게 인지하는지 평가하여 모델의 전반적인 성능을 종합적으로 파악하는 것이다.
- 특히 얼굴 애니메이션은 인간의 시각적 판단에 매우 민감한 영역이므로, 실제 사용자들의 선호도를 파악하는 것이 중요하다.
-
연구 방법론:
- 영감: 이 연구는 대규모 언어 모델(LLM) 평가에서 사용된 💬 Chatbot Arena: An Open Platform for Evaluating LLMs by Human Preference에서 아이디어를 얻었다. 이는 다양한 분야의 평가 방법론을 차용하여 주관적인 평가를 체계화하려는 시도이다.
- 비디오 선정: 각 비교 대상 모델(KeyFace 및 최신 SOTA 모델)당 20개의 비디오를 선정하여 평가에 사용했다.
- 제시 방식: 참가자들에게 동일한 오디오와 동일한 초기 얼굴 이미지(identity frame)를 사용하여 생성된 5초 길이의 비디오 두 개를 한 쌍으로 제시한다. 이는 오디오와 얼굴이라는 동일한 조건 하에 각 모델의 애니메이션 생성 능력만을 비교하기 위함이다.
- 평가 기준: 참가자들은 제시된 두 비디오 중 '시각적 품질', '립 싱크', '모션 현실감'을 종합적으로 고려하여 더 현실적인 비디오를 선택하도록 지시받는다.
- 참가자 및 평가 규모: 총 51명의 참가자가 이 연구에 참여했으며, 각 참가자는 평균적으로 20쌍의 비디오를 비교 평가했다. 이는 통계적 유의미성을 확보하기 위한 충분한 규모의 데이터를 수집했음을 의미한다.
-
결과 분석:
- Elo rating system: 참가자들의 비디오 선호도를 기반으로 모델의 상대적 순위를 매기기 위해 💬 The Rating of Chessplayers, Past and Present에서 유래한 'Elo rating system'을 사용한다. Elo 시스템은 체스 플레이어의 실력을 평가하는 데 사용되는 방식으로, 두 플레이어 간의 대결 결과에 따라 각 플레이어의 점수를 업데이트하여 상대적 강도를 측정한다. 이 연구에서는 각 모델을 '플레이어'로 간주하고, 사용자 선택 결과를 '대결 결과'로 활용하여 모델별 Elo 점수를 산출한다.
- 부트스트래핑(Bootstrapping): Elo 점수의 안정성과 신뢰성을 높이기 위해 '부트스트래핑' 기법을 적용한다. 부트스트래핑은 원본 데이터셋에서 무작위로 여러 개의 부분집합(재표집 데이터셋)을 생성하여 각 부분집합에서 통계량을 추정하고, 이 추정치들의 분포를 통해 원본 데이터의 통계량에 대한 불확실성을 평가하는 재표집 방법이다. 이를 통해 특정 평가 쌍이나 참가자의 편향이 전체 순위에 미치는 영향을 줄이고, 더욱 견고한 모델 순위를 얻을 수 있다.
5. Results
5.1. Quantitative analysis
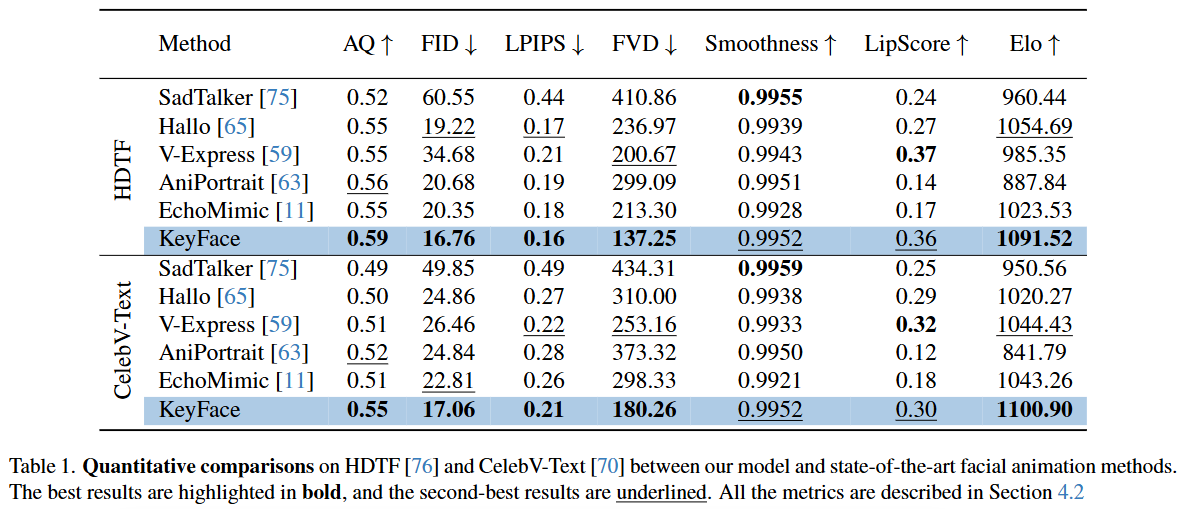
-
AQ (Aesthetic Quality) ↑: 생성된 비디오의 미학적 품질을 나타내는 지표이다. 높을수록 시각적으로 더 매력적이고 자연스럽게 인식된다.
-
FID (Fréchet Inception Distance) ↓: 생성된 이미지 분포와 실제 이미지 분포 간의 유사성을 측정한다. 값이 낮을수록 생성된 이미지가 실제 이미지와 더 유사하다는 것을 의미하며, 일반적으로 이미지 품질을 평가하는 데 널리 사용된다.
-
LPIPS (Learned Perceptual Image Patch Similarity) ↓: 두 이미지 간의 지각적 유사성을 측정하는 지표이다. 사람이 인지하는 방식과 유사하게 이미지의 차이를 평가하며, 값이 낮을수록 두 이미지가 사람의 눈에 더 비슷하게 보인다는 것을 나타낸다.
-
FVD (Fréchet Video Distance) ↓: FID의 비디오 버전으로, 생성된 비디오와 실제 비디오 간의 분포 유사성을 측정한다. 비디오의 시간적 일관성과 품질을 동시에 평가하며, 값이 낮을수록 비디오의 현실감이 높다는 것을 의미한다.
-
Smoothness ↑: 비디오의 움직임이 얼마나 부드러운지를 나타내는 지표이다. 값이 높을수록 움직임이 끊김 없이 자연스럽다.
-
LipScore ↑: 음성-입술 동기화(lip-sync)의 정확도를 측정하는 새로운 지표로, 최첨단 립리더(lipreader) 모델 [41]에서 추출된 임베딩 간의 코사인 유사성을 기반으로 한다. 값이 높을수록 오디오와 입술 움직임이 더 정확하게 일치한다.
-
Elo ↑: 사용자 연구(user study)를 통해 얻은 모델의 사용자 선호도를 Elo 레이팅 시스템 [16]으로 나타낸 값이다. 값이 높을수록 사용자들이 해당 모델이 생성한 비디오를 더 선호한다는 것을 의미한다.
-
HDTF 데이터셋:
- KeyFace는 AQ (0.59), FID (16.76), LPIPS (0.16), FVD (137.25), Elo (1091.52) 모든 지표에서 가장 높은 또는 가장 낮은(↓ 지표) 값을 기록하며 최신 방법들 중 최고 성능을 달성했다.
- Smoothness (0.9952)와 LipScore (0.36)에서는 각각 SadTalker [75]와 V-Express [59] 다음으로 두 번째로 좋은 성능을 보였다. 이는 KeyFace가 전반적인 비디오 품질과 시간적 일관성 측면에서 다른 모델들을 능가하며, 립싱크 정확도와 움직임 부드러움 또한 매우 높은 수준임을 의미한다.
-
CelebV-Text 데이터셋:
- 마찬가지로 KeyFace는 AQ (0.55), FID (17.06), FVD (180.26), Elo (1100.90) 지표에서 최고 성능을 달성했다.
- LPIPS (0.21)에서는 V-Express [59]와 비슷한 수준으로 두 번째로 좋았고, Smoothness (0.9952)에서는 SadTalker [75] 다음으로 좋았다. LipScore (0.30)에서는 V-Express [59] 다음으로 두 번째로 좋은 성능을 보였다.
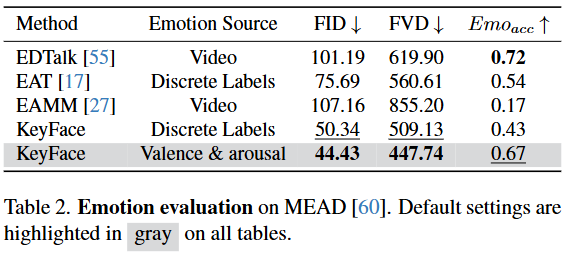
이 표는 다양한 오디오 기반 얼굴 애니메이션 모델들이 감정을 얼마나 정확하고 사실적으로 표현하는지 평가한 결과를 제시한다. 특히 KeyFace 모델이 연속적인 감정 표현 방식(Valence & Arousal)을 사용했을 때의 뛰어난 성능을 강조하고 있다.
-
Method (모델): 평가 대상이 되는 얼굴 애니메이션 생성 모델들을 나타낸다.
- EDTalk [55], EAT [17], EAMM [27]: 기존의 감정 기반 얼굴 애니메이션 모델들이다.
- KeyFace: 본 논문에서 제안하는 모델이다. 이산적인 감정 레이블(
Discrete Labels)을 사용했을 때와 연속적인 감정 표현(Valence & Arousal)을 사용했을 때의 두 가지 설정으로 평가되었다.
-
Emotion Source (감정 소스): 각 모델이 감정 표현을 위해 어떤 종류의 감정 정보를 입력으로 사용했는지 명시한다.
- Video: 입력 비디오에서 직접 감정 관련 특징을 추출하여 사용한다.
- Discrete Labels: '기쁨', '슬픔', '화남' 등과 같이 명확하게 구분되는 이산적인 감정 범주를 레이블 형태로 사용한다.
- Valence & Arousal (쾌감 & 각성): 감정을 '불쾌-쾌감(Valence)'과 '차분-흥분(Arousal)'이라는 두 가지 연속적인 차원으로 표현하는 방식이다. 이는 이산적인 레이블보다 훨씬 더 미묘하고 복합적이며 유동적인 감정 상태를 정밀하게 포착할 수 있다.
-
FID ↓ (Fréchet Inception Distance): 생성된 이미지의 품질과 다양성을 평가하는 지표이다. 실제 이미지 분포와 생성된 이미지 분포 간의 통계적 거리를 측정하며, 값이 낮을수록 생성된 이미지가 실제 이미지와 더 유사하고 다양성이 풍부함을 의미한다.
-
FVD ↓ (Fréchet Video Distance): 생성된 비디오의 품질과 시간적 일관성을 평가하는 지표이다. 실제 비디오 분포와 생성된 비디오 분포 간의 통계적 거리를 측정하며, 값이 낮을수록 생성된 비디오가 실제 비디오와 더 유사하고 움직임이 시간적으로 자연스럽게 연결됨을 의미한다.
-
Emoacc ↑ (Emotion Accuracy): 생성된 비디오가 표현하는 감정의 정확도를 측정하는 지표이다. 이는 사전 훈련된 감정 인식 모델이 생성된 비디오의 감정을 얼마나 잘 식별하는지 나타내며, 값이 높을수록 생성된 애니메이션이 의도된 감정을 더 정확하게 전달함을 의미한다.
결과 분석:
- KeyFace의 우수성: KeyFace (Valence & Arousal) 모델은 FID 44.43, FVD 447.74로 모든 모델 중 가장 낮은 값을 기록했다. 이는 KeyFace가 다른 어떤 모델보다도 시각적으로 사실적이고, 시간적으로 일관되며, 자연스러운 비디오를 생성하는 능력이 탁월함을 보여준다.
- 연속적인 감정 표현의 효과: KeyFace 모델 내에서도
Discrete Labels를 사용했을 때(FID 50.34, FVD 509.13, Emoacc 0.43)보다Valence & Arousal을 사용했을 때(FID 44.43, FVD 447.74, Emoacc 0.67) 모든 지표에서 크게 향상된 성능을 보인다. 특히 FID와 FVD가 크게 낮아지고 Emoacc도 0.43에서 0.67로 대폭 상승한 점은 연속적인 감정 표현 방식이 모델의 전반적인 생성 품질과 감정 표현의 미묘함을 포착하는 데 훨씬 효과적임을 강력히 시사한다. - 감정 정확도 측면: Emoacc에서는 EDTalk가 0.72로 가장 높지만, KeyFace (Valence & Arousal)도 0.67로 매우 경쟁력 있는 수준이다. 특히 논문 섹션 5.2에서 언급된 바와 같이, KeyFace는 MEAD 데이터셋의 ground-truth 레이블이 아닌 pseudo-label로 훈련되었음에도 불구하고 이러한 높은 정확도를 달성했다는 점은 주목할 만하다. 이는 KeyFace가 감정 표현의 학습 효율성이 높음을 의미한다.
- 다른 SOTA 모델들과의 비교: EDTalk, EAT, EAMM과 같은 기존의 최첨단(SOTA) 모델들은
Video또는Discrete Labels를 감정 소스로 사용했으나, KeyFace는 이들 모델 대비 훨씬 낮은 FID와 FVD를 달성하여 이미지/비디오 품질에서 압도적인 우위를 보인다.
