Abstract
이 논문은 이미지의 여러 레벨(머리, 몸, 맥락)에서 얻은 특징들을 활용하여 사람의 감정을 인식하는 CocoER이라는 새로운 방법을 제안한다. 기존 연구들은 시각적 특징 융합 및 추론을 개선하는 데 초점을 맞추었지만, 각 레벨에서 도출된 감정 인식 결과가 서로 다를 때 발생하는 불일치(inconsistency) 문제로 인해 인식 성능이 저하되는 한계가 있었다. CocoER은 이러한 다중 레벨 인식 결과의 충돌 영향을 완화하여 보다 정확한 감정 분석을 수행하는 방법을 제안한다.
1. Introduction
-
감정 인식의 중요성 및 응용 분야:
- 인간-기계 상호작용의 급증과 함께 감정 인식(emotion recognition)이 다시 주목받고 있다.
- 이는 인간의 감정 상태를 인지하여 기계가 반응과 행동을 조절할 수 있도록 하는 데 필수적이다.
-
기존 연구의 한계:
- 기존 연구들은 여러 이미지 레벨(예: 머리, 몸, 맥락)로부터 시각적 특징 융합(visual feature fusion) 및 추론(reasoning)을 개선하는 데 초점을 맞추었다.
- 그러나 각 레벨(머리, 몸, 맥락)의 감정 인식 결과는 종종 서로 달라 불일치(inconsistency)를 유발하며 인식 성능을 저하시키는 문제가 있다.
-
제안 모델: CocoER (Competition and Coordination for Emotion Recognition):
-
CocoER은 다단계 인식에서 발생하는 충돌하는 결과의 영향을 완화하기 위해 제안된 다단계 이미지 특징 정제(multi-level image feature refinement) 방법이다.
-
주요 메커니즘:
- 교차 레벨 어텐션(Cross-level Attention): 계층적으로 잘라낸 머리(head), 몸(body), 맥락(context) 창(window) 간의 시각적 특징 일관성(consistency)을 개선하기 위해 활용된다.
- 어휘 정보 활용 정렬(Vocabulary-informed Alignment): 인식 프레임워크에 통합되어 의사 레이블(pseudo label)을 생성하고, 이를 통해 계층적 시각 특징 정제(hierarchical visual feature refinement)를 안내한다.
- 경쟁 프로세스(Competition Process): 관련 없는 이미지 레벨 예측을 제거하는 역할을 한다.
- 조정 프로세스(Coordination Process): 모든 레벨에 걸쳐 특징(feature)을 강화하는 역할을 한다.
-
2. Related Work
-
Visual Emotion Recognition: 기존 방법은 감정과 일치하지 않는 배경 정보를 제거하였으나, 본 모델은 배경 정보도 사용한다.
-
Multi-modal Emotion Recognition: 기존 방법은 VLM을 사용하여 감정 분석을 하였으나, 언어-시각 도메인 갭 때문에 정확하지 않은 결과를 도출하였다. 본 논문은 감정과 관련 없는 부분은 유동적으로 지워 이런 문제를 해결한다.
3. Methods
3.1. Hierarchical Feature Extraction
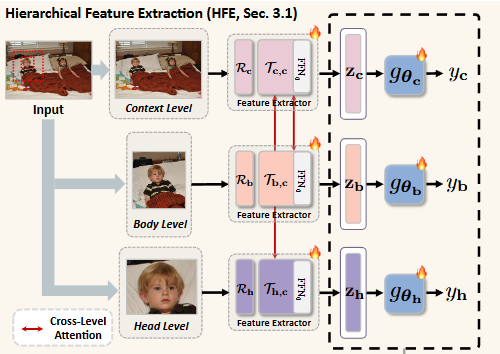
입력 이미지에서 머리(head), 몸통(body), 그리고 배경(context)이라는 세 가지 계층적 영역으로부터 감정 인식에 필요한 시각적 특징을 추출하고 정제하는 과정을 설명한다. 이 모듈은 각 영역의 특징을 독립적으로 처리하면서도 영역 간의 상호작용을 고려하여 일관성 있는 감정 표현을 도출하는 데 중점을 둔다.
-
입력 이미지 분할:
- 주어진 입력 이미지 는 객체 탐지 모델 [4]을 활용하여 머리, 몸통, 배경 영역에 해당하는 바운딩 박스를 얻어 세 개의 윈도우(head, body, context)로 나뉜다.
- 각 윈도우는 동일한 크기 로 조정된다.
-
다단계 특징 추출:
- 조정된 세 개의 윈도우 (여기서 은 context(c), body(b), head(h)를 나타냄)는 각각 학습 가능한 백본(trainable backbone) 에 입력되어 다단계 특징 맵 을 추출한다.
- 특징 맵 의 크기는 이며 개의 채널을 갖는다:
- 각 특징 맵 는 개의 겹치지 않는 패치 로 분할되고 재구성된다.
- 이렇게 얻은 패치들은 선형 프로젝션 을 통해 차원으로 매핑되어 2D 임베딩 시퀀스 을 형성한다. (는 패치 수이다).
-
교차 레벨 어텐션(Cross-Level Attention)을 통한 특징 강화:
- 각 레벨의 임베딩 시퀀스 은 교차 레벨 어텐션 에 전달되어 지역(local) 및 배경(context) 특징 간의 상관관계를 강화한다.
- 예를 들어, 머리-배경 교차 어텐션 는 머리 임베딩 와 배경 임베딩 를 사용하여 다음과 같이 공식화된다:
- 여기서 는 선형 프로젝션이다.
- (Query), (Key), (Value)는 어텐션 메커니즘의 핵심 요소이다.
- 는 어텐션 가중치를 나타내며, 로 나누어 스케일링한다.
- 는 교차 어텐션을 통해 강화된 머리 레벨 표현이다.
- 이 는 원래의 머리 임베딩 와 더해진 후 (Residual Connection), LayerNorm (LN)과 Feed-Forward Network (FFN0)를 거쳐 최종 머리 레벨 표현 가 된다.
- 유사하게 몸통-배경 교차 어텐션 를 통해 몸통 레벨 표현 를 얻는다. 배경 특징 는 자체 어텐션(self-attention) 를 통해 얻는다.
-
다단계 예측:
- 각 레벨의 표현 은 선형 매핑 을 통과한 후 함수 를 거쳐 개의 감정 범주에 해당하는 예측 결과 을 생성한다.
- 선형 매핑 의 파라미터 은 추론 단계에서 업데이트되어 감정 인식 성능 향상을 위해 각 레벨 표현 을 정제하는 데 사용된다.
- 각 레벨의 표현 은 선형 매핑 을 통과한 후 함수 를 거쳐 개의 감정 범주에 해당하는 예측 결과 을 생성한다.
이러한 계층적 특징 추출 과정을 통해 CocoER은 이미지 내의 다양한 시각적 정보(머리, 몸통, 배경)를 통합하고, 각 정보 간의 복잡한 관계를 어텐션 메커니즘으로 포착하여 감정 인식의 정확도를 높인다.
3.2. Vocabulary-Informed Alignment
-
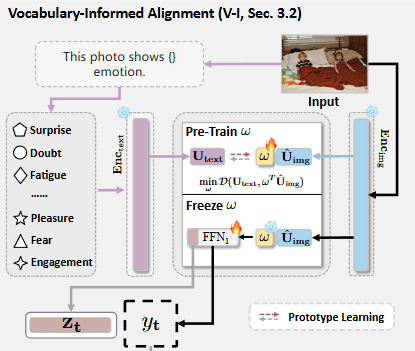
목표: 계층적 특징 추출(Hierarchical Feature Extraction, HFE) 모듈에서 얻은 시각적 특징을 의미론적으로 안내하고 정제하는 것이 목표이다. 즉, 이미지 특징이 감성 범주에 더 잘 부합하도록 돕는 역할을 한다.
-
사전 학습된 모델 활용: CLIP과 같은 사전 학습된 이미지 인코더()와 텍스트 인코더()를 활용하여 의사 레이블(pseudo label)을 얻고 이미지 표현을 보정한다.
-
이미지 인코딩: 입력 이미지 는 CLIP 이미지 인코더를 통해 단일 벡터 특징 로 인코딩된다.
- (8)
- 여기서 는 특징 벡터의 차원이다.
-
텍스트 인코딩: 감성 인식 태스크의 개 감성 클래스("surprise", "fear" 등)는 "이 사진은 {} 감정을 보여준다"와 같은 텍스트 프롬프트(prompt) 로 확장된다. 이 텍스트 프롬프트는 CLIP 텍스트 인코더를 통해 로 인코딩된다.
- (9)
- 는 감성 클래스의 개수이다.
-
-
CLIP 예측의 한계와 개선: CLIP은 다양한 이미지-텍스트 쌍으로 학습되었기 때문에 "surprise"와 "fear"와 같이 미묘한 감성 표현을 정확히 구분하는 데 어려움이 있다. 이를 개선하기 위해 프로토타입 학습(prototype learning)을 적용한다.
-
프로토타입 학습: 이미지 특징 를 텍스트 표현 공간으로 투영하고, 감성 프로토타입에 더 가깝게 만든다. 이를 위해 를 와 동일한 형태인 로 확장한 후, 이 둘 사이의 거리를 최소화하는 방향으로 학습한다.
- (10)
- 는 이미지 표현을 텍스트 표현 공간으로 선형 투영하는 학습 가능한 가중치 행렬이다.
-
감성 정렬된 특징 및 예측: 학습된 를 사용하여 감성 정렬된 이미지 특징 를 (Feed-Forward Network)에 입력하고, 마지막으로 연산을 통해 감성 인식 결과 를 얻는다.
- (11)
- 는 이후 워크스페이스(Workspace) 모듈에서 특징 정제를 위한 의사 레이블(pseudo label)로 사용된다.
-
-
학습 중 파라미터 고정: 사전 학습된 , , 의 파라미터는 CocoER 프레임워크 학습 단계에서 고정(freeze)되며, 만 학습된다.
-
워크스페이스와의 연결: 의 마지막 은닉층 임베딩인 는 계층별 특징 과 동일한 차원 를 가지며, 워크스페이스 모듈에서 경쟁(competition) 및 협력(coordination) 과정을 안내하는 데 활용된다.
3.3. Workspace
-
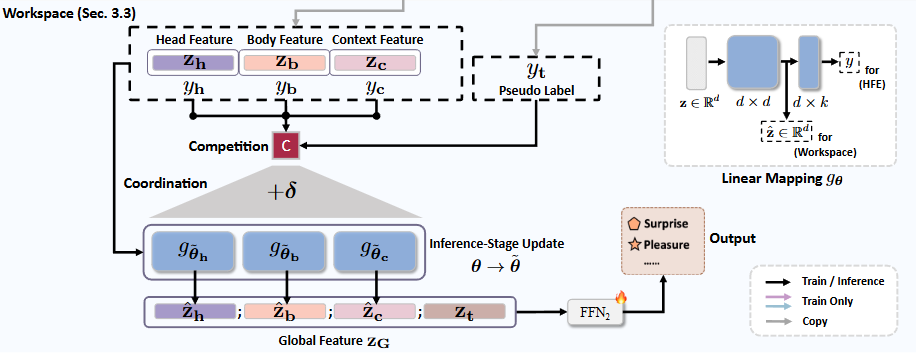
목표: CocoER 프레임워크의 Workspace 모듈은 머리, 몸, 맥락과 같은 여러 이미지 레벨에서 추출된 특징 간의 불일치를 해결하여 감정 인식 성능을 향상시키는 것을 목표로 한다.
-
영감: 이 모듈은 다중 레벨 예측이 최종 인식을 위해 서로 경쟁하고 협력하는 방식을 설명하는 Workspace Theory에서 영감을 얻었다.
-
작동 원리:
- 경쟁 (Competition) 과정: 의사 레이블(pseudo label) 의 안내에 따라 관련 없는 이미지 레벨 예측을 제거한다.
- 협력 (Coordination) 과정: 모든 이미지 레벨에 걸쳐 특징 표현을 강화한다.
3.3.1. 경쟁 (Competition) 과정
-
목표: 다중 레벨 특징 집합 (여기서 는 각각 맥락, 몸, 머리 특징을 의미함)에서 의사 레이블 를 기반으로 일관되지 않은 특징을 점진적으로 제거하여, 최종적으로 하나의 가장 일관된 요소만 남도록 하는 과정이다.
-
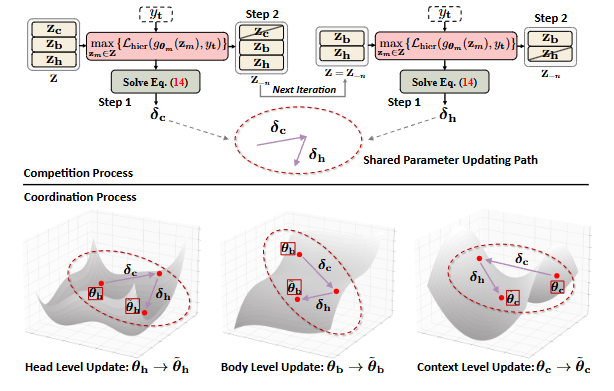
반복적인 수행: 이 과정은 각 반복마다 두 단계를 포함하며, 에 하나의 요소만 남을 때까지 반복된다.
-
1단계: 파라미터 업데이트를 위한 하강 방향 결정:
-
불일치 측정: 각 이미지 레벨의 인식 결과 과 의사 레이블 간의 불일치 정도를 손실 함수 의 값으로 측정한다.
-
가장 불일치하는 레벨 타겟팅: 모든 레벨의 손실 함수 값 중에서 최댓값을 찾는다:
이를 표기 편의상 으로 정의한다.
-
Min-Max 문제로 변환: 각 반복에서 의 기울기를 계산하여 의 파라미터를 업데이트하는 것을 목표로 하며, 이는 다음의 min-max 문제로 변환된다:
-
미분 불가능성 해결: 함수가 미분 불가능하다는 문제를 해결하기 위해, Towards scalable and fast distributionally robust optimization for data-driven deep learning에서 제안된 방법을 차용하여 미분 가능성을 부여하고 정규화(regularization) 항을 추가하여 하강 방향을 안정화한다. 이는 라그랑주 승수 를 사용한 다음의 이차 계획법(Quadratic Programming, QP) 문제로 귀결된다:
여기서 는 손실 에 대한 예측 레이어 의 기울기를 포함하며, 는 에 남아있는 요소의 개수를 나타낸다.
-
공유 파라미터 업데이트 경로 : QP 문제를 풀어 를 구한 후, 는 식 (13)의 근사해 역할을 하며, 이는 세 레벨 모두에 대한 선형 매핑 의 공유 파라미터 업데이트 경로로 사용된다.
-
-
2단계: 불일치하는 요소 제거:
-
는 에서 가장 불일치하는 특징의 인덱스이다.
-
해당 특징 의 을 에서 반복적으로 제거하며, 이를 으로 표기한다 (그림의 위쪽 부분 참조).
-
-
3.3.2. 협력 (Coordination) 과정
-
목표: 경쟁 과정에서 얻은 하강 방향 를 사용하여 다중 레벨 특징 를 교정(rectify)하는 것이다.
-
공유 파라미터 업데이트 경로 누적: 경쟁 과정 동안 얻은 각 하강 방향 등을 누적하여 예측 레이어 에 대한 공유 파라미터 업데이트 경로 를 구성한다. 예를 들어, 맥락 레벨 특징 와 머리 레벨 특징 가 경쟁을 통해 점진적으로 제거되었다면, 가 된다.
-
파라미터 업데이트: 각 이미지 레벨 에 대해, 선형 매핑 의 전체 파라미터 를 연쇄 법칙(chain rule)과 역전파(back-propagation)를 통해 업데이트한다:
-
정제된 특징 획득: 업데이트된 선형 매핑 에 원래의 을 다시 입력하여 마지막 은닉 계층(hidden layer)에서 정제된 특징 을 얻는다:
-
최종 감정 인식 향상: 이러한 추론 단계(inference-stage) 파라미터 업데이트를 통해 다중 레벨 감정 표현을 보정하여, 계층적 특징에서 오는 일관성 없는 감정 인식 결과의 영향을 줄인다.
이 모듈은 Hierarchical context-based emotion recognition with scene graphs나 Disentangled Representation Learning for Multimodal Emotion Recognition 같은 기존의 특징 정제 방법들과는 다르게, 이미지 레벨 분류 결과에 기반하여 동적으로 모든 레벨의 감정 특징을 정제한다는 점이 특징이다. 특히, 이 논문은 GPT-4o API와 같은 대규모 비전-언어 모델(VLM)에서도 다중 레벨 입력의 불일치 문제가 존재하며, 제안하는 프레임워크가 이를 개선할 수 있음을 보여주었다. 이는 VLM이 전체 이미지의 토큰화된 이미지-텍스트 쌍 정렬에 주로 초점을 맞추어, 계층적 이미지 특징의 미묘한 불일치를 간과할 수 있다는 점을 시사한다.
