Abstract
한계와 해결방안
-
이 논문은 기존의 3D 재구성 방법들이 충분한 3D inductive bias가 없으면 고품질 3D 메쉬를 효율적으로 생성하기 어렵고, 학습 비용도 높다는 문제를 지적합니다. MeshFormer는 이러한 한계를 극복하기 위해 다음과 같은 핵심 아이디어를 적용했습니다.
-
Triplane 대신 3D 희소(voxel) 특징 저장:
- 한계: 3D 공간을 2D 평면으로 분할하여 표현하는 triplane 방법은 공간 정보를 보존하기 어려움.
- 제안: 3D 공간을 복셀 피처로 표현하는 Explicit 3D-native structure 덕분에 공간 정보를 명시적으로 보존합니다.
-
트랜스포머와 3D 컨볼루션 결합:
-
한계: 기존의 블랙박스 형식의 트랜스포머 모델과 단순 Rendering Loss로는 3D native structure와 projective bias(3D 점과 2D 점 사이의 관계를 파악하는 선험지식)를 보존하기 어려움.
-
제안: 3D 컨볼루션으로 지역 정보를 처리하고 트랜스포머로 전역 특징을 학습하는 하이브리드 네트워크를 설계했습니다.
- 이 방법은 3D 복셀 피처를 더욱 명확하게 표현합니다.
- 3D 복셀과 2D 이미지 픽셀 사이의 대응점을 더욱 명확하게 인지합니다.
-
-
입력 및 출력에 법선맵 활용:
-
한계: 기하학적 디테일을 훈련하기 어려움.
-
제안: 네트워크가 sparse-view RGB 이미지뿐 아니라 이와 대응하는 multi-view normal maps를 입력받고 생성하도록 하여 기하학적 학습을 돕습니다. 이 법선지도는 센서나 광도 측정 뿐만 아니라 2D diffusion 모델로 예측할 수 있어서, 기하학적인 디테일 훈련에 큰 도움을 줍니다.
-
-
Signed Distance Function(SDF) 감독과 표면 렌더링 결합 훈련:
-
한계: 기존의 모델은 NeRF 기반의 볼륨 렌더링 기술을 사용해 시간이 오래 걸리고 복잡한 다단계 훈련이 필요했습니다.
-
제안:
- 메쉬 기반 표현법을 사용하며, 싱글 스테이지 학습을 진행.
- 고해상도 SDF 볼륨을 사용하여 SDF 필드를 학습하도록 네트워크에 요구합니다. 이 SDF 손실은 기본 3D 형상에 대한 명시적인 지도(explicit guidance)를 제공하여 학습 속도를 높입니다.
- 렌더링 로스를 통해 생성된 메쉬에 미분 가능한 서페이스 렌더링 방식을 추가적으로 도입하여 고품질의 메쉬를 생성.
-
-
단어 정리
-
3D inductive bias (3D 선험 정보)
-
머신러닝 모델이 3D 문제를 학습할 때, 3D 공간의 특징, 규칙, 구조와 관련된 선험적인 지식을 말합니다. 예를 들어, 공간상에서 물체 표면은 연속적이거나 주변 위치와 관계가 있다는 점 등이 이에 해당합니다.
-
이런 bias가 있으면 적은 데이터라도 더 잘 학습하고 효율적인 모델을 만들 수 있습니다. 반대로 이런 bias가 없으면 모델이 3D 공간 정보를 잘 활용하지 못해 데이터가 많아야 하거나 학습이 어렵습니다.
-
-
3D native structure (3D 본질 구조)
- 3차원 공간에서 직접적으로 다루는 데이터 구조를 의미합니다. 대표적으로 3D voxel입니다.
- 즉, 3D 데이터를 3차원 좌표 체계(가로, 세로, 높이)를 가진 격자나 점들의 집합으로 명시적으로 표현하는 방식입니다.
- 이를 통해 공간적 위치 정보를 자연스럽게 모델링할 수 있습니다.
- MeshFormer 논문에서는 이런 3D voxel 공간을 활용합니다.
-
triplane representation (트리플레인 표현)
- 3D 공간을 3개의 서로 직교하는 2D 평면으로 분해하여 표현하는 방법입니다.
- 즉, 3D 정보를 2D 평면 3개로 나누어서 저장하고 처리합니다. (XY, YZ, ZX 평면)
- 이 방법은 2D CNN이나 트랜스포머로 쉽게 처리할 수 있지만, 공간 구조가 명시적이지 않고 3D에서의 정확한 상호작용을 다루기 어렵다는 단점이 있습니다.
- 논문에서 MeshFormer는 기존의 이런 방식을 대신해 3D voxel을 씁니다.
-
projective bias (투영 편향)
- 3D 공간의 한 점이 여러 2D 카메라 시점에서 어떻게 보이는지에 대한 모델의 선험 지식.
- 즉, 3D 지점이 2D 이미지의 어느 위치에 대응하는지를 알고 활용하는 편향입니다.
- 이런 편향이 있으면 3D-2D 데이터 간에 정확한 연결 고리를 만들어 3D 재구성 성능이 좋아집니다.
- MeshFormer는 투영 편향을 이용해 3D voxel과 multi-view 이미지 픽셀 간의 상호작용을 정교하게 처리합니다.
SDF (Signed Distance Function)
-
SDF
- 공간 내 한 점이 표면(surface)과 얼마나 떨어져 있는지를 나타내는 함수입니다.
- 구체적으로, 어떤 점 에 대해, 그 점에서 가장 가까운 표면까지의 거리를 계산합니다.
- 그리고 이 거리에 부호(signed)를 붙여, 점이 표면 안쪽에 있으면 음수, 밖에 있으면 양수, 표면 위에 있으면 0으로 표현합니다.
-
수식 표현
- 여기서 는 점 와 표면 사이의 최소 거리입니다.
-
SDF의 특징과 장점
- 3D 형태를 암시적으로 표현할 수 있습니다. 즉, 정교한 메쉬 없이도 부드러운 형태와 경계를 표현할 수 있어, 변형이나 합성 작업이 쉽습니다.
- 표면까지의 거리를 알기 때문에, 메쉬 추출 시 쉽게 고품질 메쉬를 얻을 수 있습니다.
- 변형, 충돌 검사, 렌더링 등 다양한 3D 작업에서 유용하게 쓰입니다.
-
MeshFormer에서의 역할
- MeshFormer는 네트워크가 SDF를 학습하도록 하여, 3D 물체의 정확한 기하학적 형태를 명시적으로 습득하도록 합니다.
- SDF 감독은 네트워크가 기하학적 오류나 잡음을 줄이고, 안정적이며 고품질의 메쉬 표면을 빠르게 학습하게 도와줍니다.
- SDF 값이 0인 등고선을 기준으로 메쉬를 추출하기 때문에, 메쉬 추출 과정도 간단하고 명확해집니다.
1. Introduction
기존 연구의 한계
-
Open-world 3D object (오픈 월드 3D 객체)
-
개념: 특정 카테고리나 제한된 데이터셋에 포함된 객체에 국한되지 않고, 현실 세계의 다양하고 임의의 객체를 3D로 생성하거나 재구성하는 것을 목표로 합니다.
-
연구 접근법:
-
3D 애셋 생성 과정을 전문가뿐만 아니라 일반 사용자에게도 개방(democratize)하기 위해 입력 요구사항을 줄이는 방향으로 발전하고 있습니다.
-
다양한 객체를 다루기 위해 외부 소스(예: 2D diffusion 모델)에서 얻은 방대한 사전 지식(extensive priors)을 활용하려는 시도가 이루어집니다.
-
-
한계점:
-
매우 다양한 형태와 특징을 가진 객체를 모두 처리하기 위해서는 방대한 양의 학습 데이터나 효과적인 사전 지식 활용 방법이 필수적입니다.
-
3D 데이터만으로 학습된 모델은 보지 못한 객체 카테고리에 대해 일반화(generalize) 성능이 제한적일 수 있습니다.
-
-
-
Per-shape optimization (형상별 최적화)
-
개념: 3D 모델을 생성할 때, 입력된 이미지나 텍스트로부터 각각의 개별 객체(shape)에 대해 독립적으로 최적화(optimization) 과정을 거쳐 해당 객체의 3D 표현을 만듭니다.
-
연구 접근법: 주로 사전 학습된 2D diffusion 모델의 guidance이나 Score Distillation Sampling (SDS) loss를 활용하여 Neural Radiance Field 등의 모델을 반복적으로 개선하는 방식을 사용합니다.
-
한계점:
-
객체 하나를 생성하기 위해 반복적인 최적화가 필요하므로 긴 실행 시간(long runtime)이 소요됩니다.
-
서로 다른 뷰(view)에서 생성된 결과 간에 3D 불일치(3D inconsistency) 문제가 발생하기 쉽습니다.
-
-
-
Score Distillation Sampling (SDS) losses
-
개념: 사전 학습된 2D diffusion 모델이 이미지에 추가된 노이즈를 제거하는 방향("점수" 또는 "score") 정보를 활용하여, 이 "점수" 방향으로 3D 표현을 업데이트하도록 유도하는 손실 함수입니다. 이를 통해 2D diffusion 모델이 학습한 이미지 생성 능력과 지식을 3D 생성 과정에 "증류(distillation)"할 수 있습니다.
-
연구 접근법: 2D diffusion 모델을 3D 생성의 강력한 사전 지식(prior) 또는 지침(guidance)으로 사용하여 NeRF 등을 최적화하는 데 사용됩니다.
-
한계점:
-
본문에서는 SDS loss 자체의 내재적인 한계보다는, 이를 활용한 per-shape optimization 방식에서 발생하는 문제점들을 언급합니다. 즉, 긴 실행 시간과 3D 불일치 문제의 원인 중 하나로 간접적으로 지적됩니다.
-
(다른 연구들과 비교할 때) 고품질의 미세한 형상이나 텍스처를 얻는 데 어려움이 있을 수 있습니다.
-
-
-
Large Reconstruction Model (LRM)
-
개념: 희소한 입력 뷰(sparse-view)에서 3D 객체를 재구성하기 위해 대규모 변환 모델(large-scale transformer)과 triplane 표현 방식을 결합한 모델 계열입니다.
-
연구 접근법: 입력 이미지를 받아 feed-forward 방식으로 3D 표현(주로 triplane 형태의 NeRF)을 직접 예측하며, 주로 렌더링 손실(rendering loss)을 사용하여 모델을 학습시킵니다.
-
한계점:
-
학습을 위해 매우 많은 컴퓨팅 자원(over a hundred GPUs)이 필요하여 비용이 많이 듭니다(expensive training costs).
-
볼륨 렌더링(volume rendering) 방식에 의존하기 때문에 여기에서 고품질 메시(high-quality meshes)를 추출하는 데 어려움이 있습니다.
-
결과 품질을 개선하기 위해 복잡한 다단계 "NeRF-to-mesh" 학습 전략이 필요할 수 있으나, 여전히 개선의 여지가 남아 있습니다.
-
-
2. Related Work
기존의 연구
-
3D 데이터만 사용하여 3D 생성 모델 학습
-
이 방식은 모델을 학습시킬 때 오로지 3D 형상이나 장면 데이터(예: 3D 메쉬, 포인트 클라우드, 복셀, NeRF 표현 등)만 사용합니다.
-
모델은 이 3D 데이터셋에 존재하는 3D 구조, 형상, 텍스처의 분포를 학습하여 새로운 3D 객체를 생성하는 방법을 배웁니다.
-
입력으로는 텍스트 설명이나 단일 이미지 등이 주어질 수 있으며, 모델은 이를 바탕으로 학습된 3D 지식을 활용하여 해당하는 3D 결과물을 직접 생성합니다.
-
한계점:
- 이 방식은 학습된 데이터 분포 내에서는 빠르게 3D 객체를 생성할 수 있습니다.
- 하지만 현실 세계의 다양하고 방대한 객체를 모두 포괄하는 대규모 고품질 3D 데이터셋을 구축하기가 2D 이미지 데이터셋보다 훨씬 어렵습니다.
- 데이터가 부족하기 때문에, 학습 데이터에 없는 새로운 카테고리의 객체에 대해서는 일반화 성능이 떨어지는 경향이 있습니다 (오픈 월드 기능의 한계).
- 또한, 네트워크 자체에서 고품질 텍스처를 직접 예측하기 어렵다는 한계도 언급됩니다.
-
-
2D 모델 가이드를 사용하는 SDS(Score Distillation Sampling) 손실 기반 형상별 최적화(per-shape optimization)
-
이 방식은 텍스트-3D 생성 분야에서 많이 사용되는 최적화 기반 기법입니다.
-
사전에 대규모 텍스트-이미지 쌍으로 학습된 강력한 2D Diffusion 모델의 능력을 활용하여 3D 표현(예: NeRF또는 Gaussian Splatting)을 점진적으로 개선해 나갑니다.
-
작동 방식:
- 초기 3D 표현(예: 구 형태의 NeRF)에서 시작합니다.
- 이 3D 표현을 여러 시점에서 이미지로 렌더링합니다.
- 렌더링된 이미지를 2D Diffusion 모델에 입력하고, 주어진 텍스트 설명과 얼마나 잘 일치하는지에 대한 "점수(Score)" 정보를 얻습니다. 이 점수는 이미지를 텍스트에 더 가깝게 만들기 위해 어떤 방향으로 수정해야 하는지를 알려주는 역할을 합니다.
- 이 점수 정보를 바탕으로 SDS 손실을 계산하고, 이 손실을 렌더링 과정을 역전파하여 3D 표현의 파라미터(형상, 색상 등)를 업데이트합니다.
- 이 과정을 텍스트 설명이 만족될 때까지 각각의 3D 객체(형상)마다 반복적으로 최적화합니다.
-
한계점:
-
SDS는 2D Diffusion 모델의 강력한 생성 능력을 3D로 옮겨와 인상적인 결과물을 만들 수 있게 했습니다.
-
하지만 핵심적으로 "각 형상별 최적화(per-shape optimization)" 과정을 거치기 때문에, 하나의 3D 객체를 생성하는 데 상당한 시간(수십 분 ~ 수 시간)이 소요됩니다.
-
또한, 2D Diffusion 모델이 3D 구조에 대한 명시적인 이해가 부족하여 여러 시점에서 일관되지 않은 이미지를 생성할 수 있으며, 이는 최종 3D 결과물에 3D 불일치 문제(예: 객체의 양쪽에 얼굴이 나타나는 Janus 문제)를 야기할 수 있습니다.
-
-
-
2D diffusion 모델을 사용하여 스파스(sparse)한 다중 뷰 이미지 예측 후 피드포워드 네트워크를 통해 3D로 변환
-
기준선(Baseline)은 여러 장의 이미지를 촬영한 카메라들의 위치 사이의 거리를 의미합니다.
-
작은 기준선(Small Baseline): 카메라들이 서로 가까운 위치에서 이미지를 촬영한 경우입니다. 인접한 이미지들 간의 시점 변화가 크지 않아, 이미지 상의 동일한 지점(feature)을 찾는 것(correspondence matching)이 비교적 쉽습니다. 전통적인 Multi-View Stereo (MVS)나 작은 움직임에 특화된 NeRF 기반 복원 기법들이 이러한 설정에서 잘 작동합니다.
-
큰 기준선(Large Baseline): 카메라들이 서로 멀리 떨어져 있는 위치에서 이미지를 촬영한 경우입니다 (예: 객체를 전면, 측면, 후면 등 몇 개의 시점에서만 촬영한 경우).
-
한계점:
-
MeshFormer와 같은 "Sparse-View 복원 모델"은 적은 수의 이미지(예: 6장)를 입력으로 받기 때문에 필연적으로 이미지들 사이의 기준선이 커집니다.
-
기준선이 크면 시점 변화가 매우 커서 이미지 상에서 동일한 3D 지점을 찾기가 매우 어렵습니다. 어떤 부분이 한 이미지에서는 보이지만 다른 이미지에서는 가려지거나(occlusion) 아예 다른 각도에서 촬영되어 Feature Matching이 실패하기 쉽습니다.
-
작은 기준선 설정을 가정하고 설계된 기존의 일반화 가능한 NeRF 또는 MVS 기반 방법들은 이러한 큰 기준선 설정에서는 정확한 3D 구조를 복원하는 데 어려움을 겪습니다. MeshFormer는 이러한 한계를 극복하고 Sparse-View, 즉 큰 기준선 입력에서도 잘 작동하도록 설계되었습니다.
-
-
3. Method
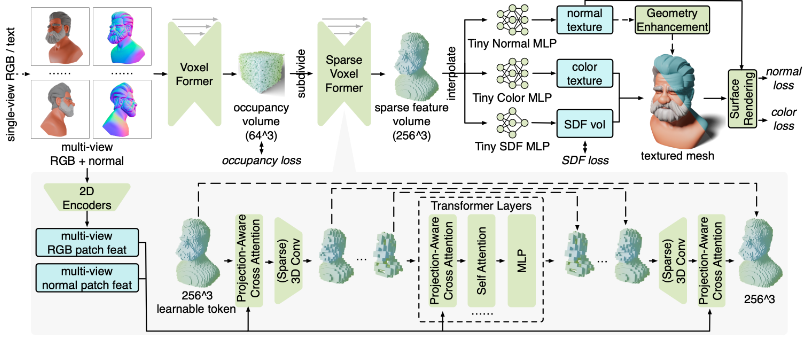
-
Input
-
MeshFormer는 여러 시점에서 촬영된 sparse RGB 이미지와 Normal 맵 이미지를 입력으로 받습니다.
-
노멀 맵은 3D 모델 표면의 각 지점에서 어느 방향이 바깥쪽을 향하는지를 나타내는 정보입니다.
-
이 논문에서는 기존의 2D 확산 모델을 사용하여 이러한 노멀 맵을 추정하여 입력으로 활용할 수 있음을 언급합니다. 이는 3D 재구성에 중요한 기하학적 단서를 제공합니다.
-
-
3D Representation & Model Architecture
-
Triplane과 같은 2D 기반의 표현 대신, 3D 구조를 명시적으로 보존하는 3D Feature Volume (희소 복셀 sparse voxels)을 사용합니다.
-
모델은 VoxelFormer와 Sparse VoxelFormer라는 하위 모듈을 포함하며, 이들은 Transformer와 3D Convolution을 결합한 새로운 아키텍처를 공유합니다. 이 구조는 명시적인 3D 구조와 투영 편향(projective bias)을 활용하여 더 효율적이고 효과적인 학습을 가능하게 합니다.
-
-
Training Strategy
-
MeshFormer는 복잡한 다단계 학습 과정 없이 unified single stage로 학습됩니다.
-
학습은 Mesh Surface Rendering과 512³ SDF(Signed Distance Function) Supervision을 결합하여 이루어집니다.
-
SDF는 3D 공간 상의 한 지점이 물체 표면으로부터 얼마나 떨어져 있는지를 나타내는 함수로, SDF Supervision은 모델이 정확한 3D 형상을 학습하도록 명시적인 기하학적 지침을 제공합니다.
-
Surface Rendering은 3D 메시를 2D 이미지로 투영하여 실제 이미지와 비교하는 방식입니다.
-
-
이러한 결합을 통해 모델은 초기 형상 정보 없이도 고품질 메시를 직접 생성하도록 학습됩니다.
-
-
Geometry Enhancement
-
MeshFormer는 3D 컬러 텍스처 외에 추가적으로 normal texture를 학습합니다.
-
학습된 normal texture는 후처리 과정을 통해 생성된 메시의 형상 디테일을 더욱 날카롭고 미세하게 다듬는 데 사용될 수 있습니다 (Geometry Enhancement).
-
3.1 3D Representation and Model Architecture
Triplane vs. 3D Voxels
-
Triplane Representation:
-
3D 공간의 정보를 여러 장의 2D 평면(주로 XZ, XY, YZ 평면)으로 분해하여 특징을 저장합니다.
-
트랜스포머 모델이 처리하기에는 비교적 간단한 구조입니다.
-
단점:
-
명시적인 3D 공간 구조 부족: Triplane은 3차원 필드를 2차원 평면으로 분해하기 때문에, 명시적인 3D 공간 구조를 직접적으로 나타내기 어렵습니다.
-
3D 위치와 2D 픽셀 간 정밀한 상호작용의 어려움: 각 3차원 공간의 특정 위치와 이를 다양한 시점에서 투영한 2차원 이미지의 해당 픽셀 간의 정밀한 상호작용을 구현하기 어렵습니다.
-
비효율적인 Attention 메커니즘: 기존 Triplane 기반 방식에서는 모든 Triplane 패치 토큰 간에 self-attention을 적용하고, Triplane 토큰과 모든 다중 시점 이미지 토큰 간에 cross-attention을 적용하는 경우가 많습니다. 이러한 'all-to-all' attention은 다음과 같은 문제를 야기합니다.
- 높은 비용: 계산 비용이 매우 높습니다.
- 학습의 복잡성: 학습 과정을 번거롭고 어렵게 만듭니다.
-
패치 경계에서의 Artifact 발생 가능성: Triplane 표현 방식은 패치 경계에서 눈에 띄는 artifact(왜곡이나 부자연스러운 결과물)를 자주 발생시킬 수 있습니다.
-
복잡한 구조에 대한 표현력 제한: 복잡한 3D 구조를 표현하는 데 있어 표현력이 제한될 수 있습니다.
-
-
-
3D Voxel Representation:
- 3D 공간을 작은 정육면체 격자(voxel)로 나누어 각 격자에 특징을 저장하는 방식입니다.
- 장점:
- 3D 공간 구조를 명시적으로 보존합니다.
- MeshFormer는 이 방식을 채택하여 명시적인 3D 구조를 활용하고 멀티뷰 이미지의 투영 정보(projective bias)를 결합함으로써 더 빠르고 효과적인 학습이 가능하다고 주장합니다.
Combining Transformer with 3D Convolution
-
3D 특징 볼륨의 시작: 모델은 '학습 가능한 토큰(learnable token)'으로 구성된 3D 특징 볼륨으로 시작합니다. 이는 3D 공간에 정보를 채우기 위한 초기 상태와 같습니다.
-
2D 이미지 정보 통합: 각 3D 복셀의 좌표와 카메라의 투영 행렬(projection matrix)을 사용하여, 해당 3D 복셀이 각 2D 입력 이미지의 어디에 투영되는지 계산합니다. 그리고 projection-aware cross-attention 레이어를 통해 이러한 여러 장의 2D 이미지로부터 해당 복셀 위치에 해당하는 2D feature을 모아 3D 특징에 통합합니다. 이를 통해 3D 복셀이 해당 시점에서 보이는 2D 이미지 정보를 반영하게 됩니다.
-
압축 단계: projection-aware cross-attention와 3D 컨볼루션을 반복적으로 적용하여 3D 특징 볼륨의 해상도를 낮추면서 정보를 압축합니다. 3D 컨볼루션은 복셀 사이를 3D 커널을 움직이며 특징을 추출하며, cross-attention은 2D 이미지 정보를 통합하는 역할을 합니다. 이는 3D Unet 구조와 보틀넥에 트랜스포머가 임베딩 된 구조입니다.
-
트랜스포머를 활용한 전역적 학습: 압축된 낮은 해상도의 3D 특징 볼륨에서는 각 3D 복셀 특징이 '잠재 토큰(latent token)'으로 간주됩니다. 이 토큰들은 위치 인코딩(position encoded)된 후, 깊은 트랜스포머 모델의 입력으로 사용됩니다. 트랜스포머는 압축된 전역적인 3D 정보들 간의 관계를 학습하여 모델의 표현력(expressiveness)을 강화합니다.
-
고해상도 복원: 마지막으로, 컨볼루션 기반의 역방향 UNet 브랜치에 스킵 연결(skip connection)을 사용하여 압축된 저해상도 특징 볼륨을 초기 해상도의 고해상도 3D 특징 볼륨으로 디코딩합니다. 이 과정에서 스킵 연결은 인코딩 단계의 특징 정보를 디코딩 단계로 전달하여 세부 정보를 복원하는 데 도움을 줍니다.
Projection-Aware Cross Attention
-
기존 방식: 기존의 멀티 뷰 스테레오(MVS) 방식은 여러 뷰의 2D 특징을 합칠 때 평균 풀링(mean pooling)이나 최대 풀링(max pooling) 같은 간단한 방법을 사용했습니다. 하지만 이러한 방법은 물체의 가려짐(occlusion)이나 시야각(visibility) 문제를 제대로 처리하지 못하여 3D 재구성 품질에 한계가 있었습니다.
-
MeshFormer의 접근 방식: MeshFormer는 이러한 문제를 해결하기 위해 각 3D 복셀이 여러 뷰에서 투영된 2D 정보 중 어떤 정보가 자신에게 가장 관련 있는지 '인지'하고 '선택적'으로 통합할 수 있도록 Projection-Aware Cross Attention 메커니즘을 도입했습니다.
-
작동 방식:
-
입력으로 들어온 다중 뷰 RGB 및 Normal 이미지는 먼저 학습 가능한 DINOv2와 같은 2D 특징 추출기를 통과하여 2D 특징을 생성합니다.
-
재구성하려는 3D 공간의 각 복셀 을 개의 입력 뷰 각각에 투영합니다.
-
각 투영된 위치에서 해당하는 RGB 특징 , Normal 특징 , 실제 픽셀의 RGB 값 , Normal 값 을 보간(interpolate)하여 가져옵니다.
-
가져온 이 네가지 요소를 concatenate하여 개의 투영된 2D 특징 을 만듭니다.
-
Projection-Aware Cross Attention 모듈에서 3D 복셀 특징 을 쿼리(Query, Q)로 사용합니다.
-
키(Key, K)와 값(Value, V)으로는 개의 투영된 2D 특징 과 원래의 3D 복셀 특 자체를 모두 사용합니다.
-
쿼리 는 키 및 와 상호작용하여 각 투영된 2D 특징 또는 자기 자신 에게 얼마나 집중할지 결정하고, 이를 바탕으로 값 및 을 가중 평균하여 새로운 3D 복셀 특징을 계산합니다.
-
-
공식 설명:
선택하신 공식은 이 Projection-Aware Cross Attention 과정을 나타냅니다.-
: 현재 처리 중인 3D 복셀의 특징 벡터를 나타냅니다. 화살표()는 이 복셀 특징이 CrossAttention 연산을 통해 업데이트됨을 의미합니다.
-
: Cross Attention 메커니즘을 나타내는 함수입니다. 이 함수는 Query, Key, Value 세 가지 입력을 받아 새로운 특징 벡터를 출력합니다.
-
: 쿼리(Query)입니다. 현재 3D 복셀의 특징()이 쿼리로 사용됩니다. 이 쿼리는 어떤 정보를 찾고 있는지 또는 어떤 정보에 주의를 기울여야 하는지를 나타냅니다.
-
: 키(Key) 집합입니다. 총 개의 키로 구성됩니다.
- : 번째 뷰에서 해당 3D 복셀 위치에 투영된 2D 픽셀의 특징 벡터()들입니다. 개의 뷰가 있으므로 개의 2D 특징 벡터가 있습니다. 이 특징 벡터는 RGB 특징(), Normal 특징(), RGB 값(), Normal 값()을 연결(concatenation)하여 생성됩니다.
- : 원래의 3D 복셀 특징() 자신도 키 집합에 포함됩니다. 이는 복셀 특징이 자신의 원래 상태와 투영된 2D 정보를 모두 고려하여 업데이트를 결정함을 의미합니다.
-
: 값(Value) 집합입니다. 키 집합과 동일하게 개의 투영된 2D 특징()과 원래의 3D 복셀 특징()으로 구성됩니다. Cross Attention은 쿼리와 키 간의 유사도(attention score)를 계산하고, 이 점수를 바탕으로 값들을 가중 평균하여 최종 결과를 만듭니다.
-
-
이점:
-
각 3D 복셀이 자신의 투영된 2D 픽셀 정보와 정밀하게 상호작용할 수 있게 합니다.
-
단순 풀링 방식과 달리, 가려짐 등으로 인해 특정 뷰의 정보가 부정확할 경우 해당 뷰의 가중치를 낮추는 등 2D 특징을 적응적으로 통합할 수 있습니다.
-
이러한 적응적 통합 능력은 모델이 3D 구조와 투영 편향(projective bias)을 더 효과적으로 학습하도록 도와 재구성 품질을 향상시킵니다.
-
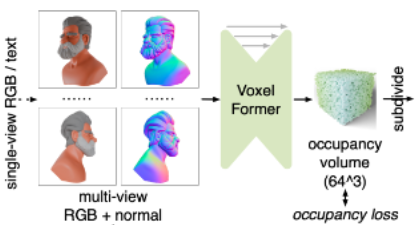
Coarse-to-Fine Feature Generation
MeshFormer는 3D 형상의 미세한 디테일을 포착하는 고해상도 3D 특징 볼륨(feature volume)을 생성하기 위해 coarse-to-fine 전략을 사용합니다. 이는 컴퓨팅 비용을 효율적으로 관리하면서 상세한 정보를 얻기 위한 방법입니다. 과정은 다음과 같습니다.
-
저해상도 초기 예측 (Coarse Volume):
-
먼저 VoxelFormer 모듈을 사용하여 저해상도(예: 64³)의 대략적인 3D 점유 볼륨(occupancy volume)을 예측합니다.
-
VoxelFormer는 전체 3D 공간에 대해 작동하는 3D Convolution을 사용합니다.
-
이 점유 볼륨에서 각 voxel은 표면에 가까운지 여부를 나타내는 이진 값(binary value)을 저장합니다. 해당 값은 제안된 Occupancy Loss를 통해 모델이 학습한다.
-
-
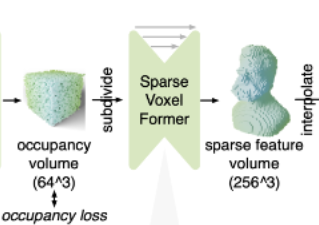
고해상도 희소 복셀 생성 (Sparse Voxels):
- 예측된 점유된 voxel들(즉, 표면에 가깝다고 판단된 영역)만 더 높은 해상도(예: 256³)의 희소 복셀(sparse voxels)로 세분화됩니다. 이는 모든 voxel을 처리하는 대신 필요한 영역에만 집중하여 효율성을 높입니다.
-
희소 복셀 특징 예측 (Sparse Feature Volume):
- 두 번째 모듈인 SparseVoxelFormer를 사용하여 이러한 고해상도 희소 복셀에 대한 특징을 예측합니다.
- SparseVoxelFormer는 희소한 데이터에 최적화된 3D Sparse Convolution [63]을 사용합니다.
-
3D Sparse Convolution:
-
3D Sparse Convolution은 3D 데이터, 특히 복셀 그리드처럼 대부분의 공간이 비어있는 '희소(sparse)'한 데이터에 최적화된 Convolution 연산입니다.
-
일반적인 3D Convolution은 입력 복셀 볼륨의 모든 위치에 대해 계산을 수행합니다. 만약 볼륨의 대부분이 비어있다면, 이 빈 공간에 대한 계산은 불필요한 낭비가 됩니다.
-
반면, 3D Sparse Convolution은 실제로 데이터(정보)가 존재하는 복셀(active voxel)과 그 주변 복셀에 대해서만 계산을 수행합니다. 빈 공간에 대한 계산은 건너뜁니다.
-
이를 통해 희소 복셀 데이터를 처리할 때 계산량과 메모리 사용량을 대폭 줄일 수 있습니다.
-
참고문헌 [63]은 이러한 3D Sparse Convolution을 GPU에서 효율적으로 구현하기 위한 라이브러리 또는 프레임워크(Torchsparse++)를 가리킵니다.
-
-
3D 포인트 특징 보간 및 활용:
-
Trilinear Interpolation (삼선형 보간): 이것은 3D 공간에서 희소 복셀의 중심들의 값을 사용하여, 그 격자점들 사이에 있는 임의의 위치에서의 값을 추정하는 방법입니다. 1D에서의 선형 보간, 2D에서의 이선형 보간을 3D로 확장한 것입니다. 특정 3D 포인트 주변의 8개 복셀 값을 가중 평균하여 해당 포인트의 특징 값을 계산합니다.
-
왜 필요한가:
-
SparseVoxelFormer은 특징을 희소 복셀 상에 저장합니다.
-
하지만 MeshFormer는 SDF 필드, 색상 텍스처, 노멀 텍스처와 같은 '연속적인 필드(continuous field)'를 학습해야 합니다. 또한, 메시 추출이나 렌더링을 위해서는 복셀 중심만이 아닌, 표면 근처의 임의의 3D 포인트에서 이러한 필드 값(또는 이를 계산하기 위한 특징 값)이 필요합니다.
-
예를 들어, 메시 추출 알고리즘(Dual Marching Cubes)은 복셀 경계나 그 사이에서 SDF 값이 0이 되는 지점을 찾습니다. 렌더링을 할 때도 특정 3D 점을 카메라에 투영하여 색상이나 노멀을 얻습니다. 이러한 점들이 SparseVoxelFormer의 출력 복셀 중심과 정확히 일치하지 않을 수 있습니다.
-
-
3.2 Unified Single-Stage Training: Surface Rendering with SDF Supervision
-
안정적인 학습 과정: NeRF나 3D Gaussian Splatting은 학습 과정이 비교적 쉽고 안정적이라는 장점이 있습니다.
-
SDF supervision이 필요한 이유: 그럼에도 불구하고 이러한 모델에서 고품질의 3D 메시를 추출하는 것은 쉽지 않습니다.
- 예를 들어, 학습된 NeRF의 밀도 필드에 Marching Cubes 알고리즘을 직접 적용하면 많은 아티팩트(불필요하거나 잘못된 기하학적 요소)가 발생합니다. 이는 NeRF의 밀도 표현이 표면 경계를 명확하게 나타내지 못하고 부드럽게 표현하는 경향이 있기 때문입니다.
- 최근 NeuManifold, MeshLRM, InstantMesh와 같은 방법들은 미분 가능한 표면 렌더링을 사용하여 복잡한 다단계 "NeRF-to-mesh" 학습 과정을 설계했지만, 생성된 메시의 품질은 여전히 개선의 여지가 있습니다.
- 반면에 초기화 과정 없이 오로지 미분 가능한 surface rendering loss만을 사용하여 메시를 직접 학습하는 것은 매우 불안정하며 왜곡된 기하학적 형태를 초래합니다. 이는 표면 렌더링 손실이 지역 최솟값에 쉽게 빠지고 초기 메시 형태에 매우 민감하기 때문입니다.
-
SDF(Signed Distance Function) supervision 활용:
- MeshFormer는 고해상도 512³의 실제 SDF 볼륨을 GT로 학습합니다.
- SDF 손실은 기본 3D 형상에 대한 명시적인 지침을 제공하여 학습 속도를 높입니다.
- 이는 메시 표현과 미분 가능한 표면 렌더링을 초기부터 사용할 수 있게 하여, 기존 방식에서 좋은 형상 초기화 없이 학습 시 발생했던 불안정성을 해결합니다. SDF 손실이 기본 형상에 대한 강력한 정규화 역할을 하기 때문입니다.
-
통합된 단일 단계 학습:
- 표면 렌더링과 명시적인 3D SDF supervision를 결합하여 MeshFormer를 통합된 단일 단계로 학습합니다.
- 3D 스파스 피처 볼륨에서 보간된 3D 피처를 입력으로 받아 SDF 필드, 3D 색상 텍스처, 3D 노멀 텍스처를 학습하기 위해 세 개의 작은 MLP를 사용합니다.
- 학습된 SDF 볼륨에서 Dual Marching Cubes를 사용하여 메시를 추출하고, NVDiffRast를 사용하여 미분 가능한 표면 렌더링을 수행합니다.
- 멀티뷰 RGB 및 노멀 이미지를 렌더링하고 MSE 및 perceptual 손실 항으로 구성된 렌더링 손실을 계산합니다.
- 주목할 점은 메시 형상에서 노멀 맵을 도출하는 대신, 학습된 노멀 텍스처를 활용한다는 것입니다.
-
총 학습 손실 함수:
-
MeshFormer의 총 학습 손실은 다음과 같이 표현됩니다.
-
각 항의 의미는 다음과 같습니다.
-
: 총 학습 손실입니다.
-
: 렌더링된 색상 이미지와 실제 색상 이미지 간의 평균 제곱 오차(MSE) 손실입니다.
-
: 렌더링된 색상 이미지와 실제 색상 이미지 간의 LPIPS(Learned Perceptual Image Patch Similarity) 손실입니다. 이는 이미지의 지각적 유사성을 측정합니다.
-
: 렌더링된 노멀 이미지와 실제 노멀 이미지 간의 MSE 손실입니다.
-
: 렌더링된 노멀 이미지와 실제 노멀 이미지 간의 LPIPS 손실입니다.
-
: 예측된 점유(occupancy) 볼륨과 실제 점유 볼륨 간의 MSE 손실입니다.
-
: 예측된 SDF 볼륨과 실제 SDF 볼륨 간의 MSE 손실입니다.
-
() : 각 손실 항의 가중치입니다. 이 가중치들은 각 손실 항이 총 손실에 기여하는 정도를 조절합니다.
-
-
-
Dual Marching Cubes: SDF 볼륨으로부터 메시를 추출하는 알고리즘
-
개념: Marching Cubes는 3차원 볼륨 데이터(예: CT 스캔, 학습된 SDF 필드)에서 특정 임계값(예: SDF의 0 값)을 갖는 표면(등가면, isosurface)을 추출하는 고전적인 알고리즘입니다. Dual Marching Cubes는 이 알고리즘의 변형으로, 특히 SDF와 같은 부호 있는 거리 함수에서 더 견고하고 날카로운 형상을 잘 보존하는 메시를 생성하는 데 사용됩니다.
-
작동 방식:
- MeshFormer는 학습을 통해 3차원 공간에 대한 SDF 볼륨을 생성합니다. 이 볼륨의 각 복셀(voxel)에는 해당 위치에서 가장 가까운 표면까지의 부호 있는 거리 값이 저장됩니다. 표면 내부에서는 음수, 외부에서는 양수, 표면 위에서는 0의 값을 가집니다.
- Dual Marching Cubes 알고리즘은 이 SDF 볼륨을 순회하며, SDF 값이 0인 표면이 지나는 위치를 식별합니다.
- 표면이 지나는 각 복셀의 중심 또는 면에 메시의 정점(vertex)을 생성합니다. 이것이 "Dual"이라고 불리는 이유로, 기존 Marching Cubes가 복셀의 경계에 정점을 생성하는 것과 대조됩니다.
- 인접한 복셀들 간의 관계를 기반으로 이러한 정점들을 연결하여 삼각형 또는 사각형 폴리곤으로 구성된 3D 메시를 생성합니다.
-
MeshFormer에서의 역할: MeshFormer는 학습을 통해 SDF 볼륨을 출력하고, Dual Marching Cubes를 사용하여 이 SDF 볼륨의 0-레벨 셋(zero-level set), 즉 객체의 표면을 3D 메시 형태로 변환합니다. 이렇게 추출된 메시가 다음 단계인 렌더링의 기반이 됩니다.
-
-
NVDiffRast: 미분 가능한 표면 렌더링 방식
-
개념: 렌더링은 3D 메시를 2D 이미지로 투영하는 과정입니다. NVDiffRast는 NVIDIA에서 개발한 라이브러리로, 이 렌더링 과정을 "미분 가능(differentiable)"하게 만듭니다. 즉, 렌더링된 2D 이미지 픽셀 값의 변화에 대해 3D 모델의 속성(정점 위치, 텍스처 색상 등)이 얼마나 영향을 미치는지 수학적으로 미분할 수 있습니다.
-
작동 방식:
- Dual Marching Cubes로 추출된 3D 메시와 학습된 3D 색상과 노멀 텍스처를 입력으로 받습니다.
- 주어진 camera pose에서 메시를 2D 이미지 평면에 투영하고(rasterization), 각 픽셀이 어떤 삼각형에 해당하는지, 그리고 해당 픽셀의 색상 및 노멀 값이 어떻게 결정되는지를 계산합니다.
- NVDiffRast의 핵심은 이 모든 과정에서 미분 계산이 가능하도록 설계되었다는 점입니다. 특히 불연속적인 과정(예: 한 픽셀이 갑자기 다른 삼각형에 속하게 되는 경우)을 처리하는 기술을 포함하여, 렌더링 결과의 각픽셀 값에 대한 손실 함수(loss function)의 기울기(gradient)가 3D 메시 및 텍스처의 속성까지 역전파(backpropagate)될 수 있도록 합니다.
-
MeshFormer에서의 역할: MeshFormer는 학습 과정에서 예측된 메시와 텍스처를 NVDiffRast를 통해 렌더링하여 2D 색상 및 노멀 이미지를 얻습니다. 이 렌더링된 이미지를 실제 이미지와 비교하여 렌더링 손실(, , , )을 계산합니다. NVDiffRast 덕분에 이 손실의 기울기가 렌더링 파이프라인을 거슬러 올라가 3D 모델의 학습 가능한 파라미터(MLP를 포함하여 SDF 볼륨, 텍스처를 생성하는 네트워크)를 업데이트하는 데 사용될 수 있습니다.
-
3.3 Fine-Grained Geometric Details: Normal Guidance and Geometry Enhancemen
-
Sparse-view RGB 이미지 기반 reconstruction의 한계: 몇 장 안 되는(Sparse-view) RGB 이미지만으로는 3D 객체의 미세한 기하학적 세부 정보를 포착하기 어렵고, 텍스처가 모호해지는 문제가 발생합니다.
-
기존 대규모 모델의 한계: RGB 이미지에서 기하학적 세부 정보를 학습하려는 기존의 많은 대규모 모델들(Instant3D, MeshLRM, InstantMesh 등)은 상당한 컴퓨팅 자원을 필요로 합니다. 또한, 이러한 모델들은 주로 3D 데이터를 사용하여 학습하지만, 방대한 양의 기하학적 특징을 학습하기에는 현재 3D 데이터셋의 규모가 충분하다는 보장이 없습니다.
-
Normal Map의 중요성: 이와 달리 Normal Map은 법선 벡터를 명시적으로 나타내므로 기하학적 정보를 직접적으로 담고 있습니다. 이는 3D 재구성에 있어 매우 중요한 지침이 될 수 있습니다.
-
2D 확산 모델 활용의 이점: 다행히 최근에는 Normal Map을 추정하는 Open-world 모델들이 크게 발전했습니다. 수십억 장의 자연 이미지로 학습된 2D 확산 모델(Zero123++ 등)은 방대한 사전 지식(Prior)을 내재하고 있어 Normal Map을 예측하도록 미세 조정될 수 있습니다(GeoWizard, Wonder3D 등에서 보여주듯). 2D 데이터와 3D 데이터 규모의 현저한 차이를 고려할 때, Geometric Guidance를 생성하는 데는 3D 데이터로 직접 학습하기보다 방대한 2D 데이터를 활용하는 것이 더 효과적일 수 있습니다.
Input Normal Guidance
-
Normal Map 생성: 이 논문에서는 Sparse-view RGB 이미지 외에도 Multi-view Normal map을 입력으로 사용합니다. 이 Normal map은 최근의 Open-world Normal estimation 모델, 특히 Zero123++ v1.2를 사용하여 생성될 수 있습니다.
-
Zero123++와 ControlNet 사용: Zero123++는 입력 이미지로부터 Multi-view 이미지를 생성합니다. 이 논문에서는 Zero123++ 위에 추가적인 ControlNet을 학습시켜, Zero123++가 예측한 Multi-view RGB 이미지를 조건으로 해당 Multi-view Normal map을 생성합니다.
-
좌표계 변환 및 처리: 생성된 Normal map은 카메라 좌표계로 표현됩니다. MeshFormer는 이를 통합된 World coordinate frame으로 변환한 후, Multi-view RGB 이미지와 유사하게 처리합니다.
-
Projection-Aware Cross-Attention 적용: MeshFormer는 이 Normal map 정보를 Multi-view RGB 이미지 정보와 함께 Projection-aware cross-attention을 통해 3D Reconstruction 과정에 통합하여 Geometry 학습을 안내합니다.
Geometry Enhancement
- 기존 방식의 어려움: 전통적으로 학습된 메쉬에서 노멀 맵(normal map)을 추출하고 이를 노멀 손실(normal loss) 계산에 사용하여 지오메트리(geometry) 학습을 유도했습니다. 하지만 이 방식은 메쉬 학습을 불안정하게 만드는 경향이 있습니다.
- MeshFormer의 새로운 접근 방식:
- MeshFormer는 색상 텍스처(color texture)와 유사하게 별도의 MLP(Multi-Layer Perceptron)를 사용하여 3D 노멀 텍스처를 학습합니다.
- 메쉬에서 노멀 맵을 직접 도출하는 대신, MLP에서 쿼리된(query) 노멀 맵에 대해 노멀 손실을 계산합니다.
- 이 방식은 노멀 텍스처 학습을 기본적인 지오메트리 학습과 분리(decouple)합니다.
- 날카로운 3D 노멀 맵을 학습하는 것이 날카로운 메쉬 지오메트리를 직접 학습하는 것보다 쉽기 때문에 훈련이 더욱 안정적입니다.
- 학습된 노멀 텍스처의 활용:
- 학습된 3D 노멀 텍스처는 색상 텍스처와 함께 메쉬와 함께 내보내져 다양한 그래픽 렌더링 파이프라인에서 사용될 수 있습니다.
- 3D 프린팅과 같이 정밀한 3D 지오메트리가 필요한 경우, 학습된 노멀 텍스처는 기존 알고리즘을 사용하여 메쉬 지오메트리를 더욱 세밀하게 개선하는 데 활용될 수 있습니다.
- 추론 단계에서의 지오메트리 개선:
- 추론(inference) 단계에서 SDF 볼륨으로부터 3D 메쉬를 추출한 후, 포스트 프로세싱(post-processing) 알고리즘(44)이 사용됩니다.
- 이 알고리즘은 메쉬 정점(vertex)의 3D 위치와 MLP에서 추정된 정점 노멀을 입력으로 받아 메쉬 정점을 예측된 노멀에 맞춰 조정합니다.
- 이 과정은 몇 초 만에 이루어지며, 지오메트리 품질을 더욱 향상시키고 Figure 5에서 보여주듯이 세밀하고 날카로운 지오메트리 디테일을 생성합니다.
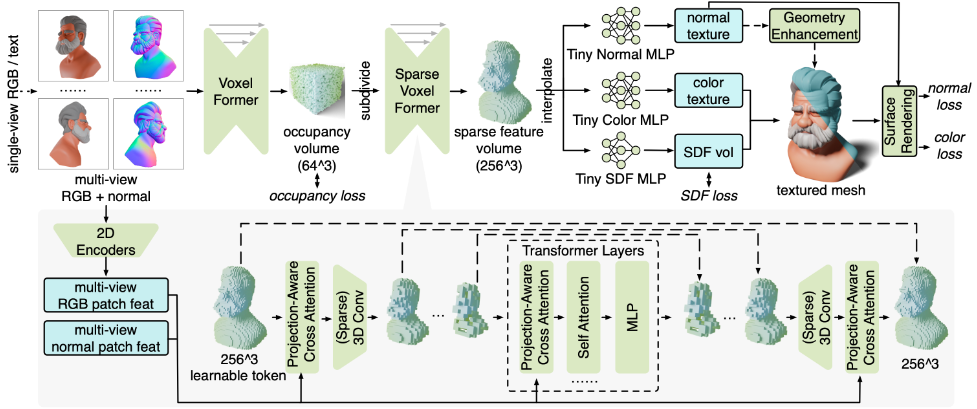
Model Pipeline
-
입력 (Input):
- 모델은 스파스 뷰(sparse-view, 적은 수의 시점에서 찍은 이미지)의 RGB 이미지와 법선 맵(normal map)을 입력으로 받습니다.
- 이 입력은 실제 RGB 이미지 또는 텍스트 프롬프트에서 2D 확산 모델(diffusion models)을 통해 생성될 수 있습니다.
- 2D 인코더를 사용하여 입력 멀티 뷰 RGB 및 법선 이미지에서 패치 특징(patch features)을 추출합니다.
-
3D 특징 표현 및 아키텍처 (3D Feature Representation and Architecture):
-
MeshFormer는 Triplane 방식 대신 3D 스파스 복셀(sparse voxels)에 특징을 저장합니다.
-
이 모델은 VoxelFormer와 SparseVoxelFormer라는 두 개의 주요 모듈로 구성됩니다.
-
VoxelFormer: 초기 단계에서 사용되며, 3D 컨볼루션(3D Convolution)을 사용하여 의 낮은 해상도인 점유 볼륨(occupancy volume)을 예측합니다. 이 볼륨은 객체 표면에 가까운 복셀을 식별합니다.
-
Subdivide: VoxelFormer에서 예측된 점유된 복셀은 의 더 높은 해상도 스파스 복셀로 세분화됩니다.
-
SparseVoxelFormer: 세분화된 스파스 복셀을 처리하며, 3D 스파스 컨볼루션(3D Sparse Convolution)을 사용하여 특징을 예측합니다.
-
모델 아키텍처 (회색 영역):
-
가장 낮은 해상도에서 각 3D 복셀은 학습 가능한 토큰(learnable token)으로 시작합니다.
-
Projection-Aware Cross Attention: 각 3D 복셀이 프로젝션 행렬을 사용하여 멀티 뷰 이미지의 해당 2D 로컬 특징을 집계합니다. 이를 통해 3D 위치와 2D 픽셀 간의 정확한 대응 관계를 활용합니다.
-
(Sparse) 3D Conv: 3D 컨볼루션(스파스 컨볼루션 포함)을 사용하여 특징을 처리합니다.
-
Transformer Layers: 낮은 해상도의 압축된 특징 볼륨에서는 모든 3D 복셀 특징 시퀀스에 트랜스포머 레이어를 적용하여 모델의 표현력을 높입니다. 여기 포함된 Projection-Aware Cross Attention은 각 3D 복셀이 프로젝션 행렬을 사용하여 멀티 뷰 이미지의 해당 2D 로컬 특징을 집계합니다. 이를 통해 3D 위치와 2D 픽셀 간의 정확한 대응 관계를 활용합니다.
-
컨볼루션 기반의 역방향 상단 브랜치와 스킵 커넥션(skip connection)을 사용하여 초기 고해상도 3D 특징 볼륨을 디코딩합니다.
-
-
-
출력 및 지도 학습 (Outputs and Supervision):
-
고해상도 스파스 특징 볼륨에서 근접한 표면의 3D 점에 대한 특징을 삼선형 보간(trilinearly interpolate)합니다. SparseVoxelFormer에서 생성된 스파스 특징 볼륨은 이러한 점들의 특징을 보간하는 데 사용됩니다.
-
이 3D 점은 SDF 학습을 위해 샘플링되는 점들을 의미합니다. 이 점들은 미리 정해진 고정된 점들이 아니라 학습 중 동적으로 샘플링됩니다.
-
논문에서는 해상도의 Ground Truth SDF 볼륨으로 SDF 필드를 지도 학습한다고 언급하고 있습니다. 학습 시에는 이 그리드 상의 점들이나 그 주변에서 점들을 샘플링하여 SDF 값을 예측하고 GT 값과 비교하게 됩니다.
-
이 보간된 특징은 세 개의 작은 MLP(Multi-Layer Perceptron)에 입력됩니다.
-
Tiny SDF MLP: SDF 볼륨을 학습합니다. 이는 high-resolution의 GT SDF 볼륨에 대한 SDF 손실()로 지도 학습됩니다.
-
Tiny Color MLP: 3D 색상 텍스처를 학습합니다.
-
Tiny Normal MLP: 3D 법선 텍스처를 학습합니다.
-
-
-
통합 단일 단계 학습 (Unified Single-Stage Training):
-
MeshFormer는 복잡한 다단계 학습 과정 없이 통합된 단일 단계로 학습됩니다.
-
고해상도의 SDF 볼륨을 생성하고, 이 값이 0이 되는 지점들을 객체의 표면(isosurface)로 간주합니다. 이 지점들에 Dual Marching Cubes 알고리즘을 적용하여 메시를 생성합니다.
-
NVDiffRast와 같은 미분 가능한 표면 렌더링(differentiable surface rendering)을 추출된 메시에 적용하여 RGB 이미지 및 법선 이미지를 렌더링합니다.
-
렌더링된 이미지와 GT 이미지 간의 손실(색상 손실 , 및 법선 손실 , )을 계산합니다.
-
모델은 점유 손실()과 SDF 손실()을 포함한 렌더링 손실들의 조합으로 학습됩니다.
-
-
기하학적 개선 (Geometry Enhancement):
-
Geometry enhancement는 MeshFormer 파이프라인의 후처리 단계입니다.
-
모델은 SDF 필드를 학습하여 메시를 추출하는 것 외에도, 별도의 Tiny Normal MLP를 통해 3D 법선 텍스처(normal texture)를 함께 학습합니다.
-
메시가 SDF 볼륨에서 추출된 후, 이 단계에서는 학습된 3D 법선 텍스처 정보를 활용하여 메시의 기하학적 디테일을 더욱 날카롭게 만듭니다.
-
구체적으로, 논문에서는 Efficiently combining positions and normals for precise 3d geometry와 같은 전통적인 후처리 알고리즘을 사용하여 메시 정점(vertex)의 위치를 조정하여 학습된 법선 텍스처와 더 잘 정렬되도록 한다고 설명합니다.
-
이 과정을 통해 SDF 기반의 메시 추출만으로는 얻기 어려운 미세하고 날카로운 기하학적 디테일을 추가할 수 있습니다.
-
-
normal loss, color loss
-
normal loss와 color loss는 3D 공간 자체에서 직접 계산되는 것이 아니라, 학습된 텍스처링된 메시(textured mesh)를 여러 시점(multi-view)에서 2D 이미지로 렌더링한 후, 이 렌더링된 2D 이미지와 지면 진실(ground truth) 멀티 뷰 2D 이미지(RGB 및 법선 맵)를 비교하여 계산됩니다.
-
도표에서
Surface Rendering모듈이textured mesh를 입력받아normal loss와color loss를 출력하는 것으로 표현되어 있습니다. 이는 메시를 렌더링하여 얻은 2D 법선 맵 및 색상 이미지와 지면 진실 2D 법선 맵 및 색상 이미지를 비교하여 손실을 계산함을 의미합니다. -
이러한 렌더링 기반 손실은 모델이 다양한 시점에서 보았을 때 실제처럼 보이는 3D 객체를 생성하도록 유도하는 역할을 합니다.
-
Experiments
Text to 3D Application
-
Text-to-3D의 기본 아이디어: 텍스트 설명만으로 원하는 3D 모델을 생성하는 작업입니다. 기존에는 이미지 기반으로 3D를 생성하거나 복잡한 최적화 과정을 거치는 경우가 많았습니다.
-
MeshFormer의 Text-to-3D 적용 과정:
- 사용자는 원하는 3D 객체를 텍스트로 설명합니다 (예: "파란색 고양이").
- 텍스트 설명은 먼저 Stable Diffusion과 같은 2D diffusion 모델로 전달됩니다. 논문에서는 Wonder3D 등에서 제안된 방법을 참고하여 이 2D diffusion 모델을 fine-tune하여 Zero123++처럼 텍스트에 맞는 다양한 시점(multi-view)의 RGB 이미지를 생성하도록 합니다.
- 이렇게 생성된 multi-view RGB 이미지와 함께, Zero123++를 사용하여 해당 이미지들에 대한 노멀 맵(normal map, 표면의 방향을 나타내는 이미지)을 예측합니다.
- 마지막으로, 생성된 multi-view RGB 이미지와 노멀 맵 세트를 MeshFormer의 입력으로 사용합니다.
- MeshFormer는 이러한 입력 정보를 바탕으로 고품질의 3D 텍스처 메시(textured mesh)를 재구성합니다.
-
결과의 특징: 이러한 통합 방식을 통해 복잡한 multi-stage training이나 per-shape optimization 없이도 몇 초 만에 고품질의 3D 메시를 생성할 수 있습니다.
