모든 코드는 아래 링크에서 다운받을 수 있습니다.
https://github.com/Foxhead-Studio/NeRF-Code-Analysis/tree/main
[3] NeRF Network
1. Positional Encoding
아래 코드는 NeRF 논문의 Positional Encoding 기법을 파이썬 클래스(Embedder)로 구현한 예시입니다.
목표는 3차원 벡터(예: 위치 또는 방향 )에 대해, 다음과 같은 형태의 트리그 함수(사인/코사인) 묶음을 만들어 고차원 벡터로 확장하는 것입니다.
위 식에서:
- 의 차원이 3 (x,y,z)라면, 각 주파수(frequency)마다 각각 3차원씩 6차원이 추가됩니다.
- 개의 주파수가 있으면 총 차원을 얻게 되고, “원본 포함 여부”(
include_input)에 따라 추가 3차원이 붙어서 최종 63차원(예: 일 때) 정도가 됩니다.
아래는 코드 상세 해설입니다.
1) Embedder 클래스
__init__: 인스턴스 생성에 필요한 kwargs를 받아 초기화(입력 차원, 옥타브 수, 주기 함수의 종류 등)
create_embedding_fn: 입력 데이터를 태울 지수 함수와 삼각 함수 리스트를 인스턴스 변수로 생성하여 저장
embed: 실제로 입력 데이터를 받고, 임베딩 함수의 리스트로 구성된 인스턴스 변수에 태워 실제 임베딩 결과값을 반환
왜 굳이 create_embedding_fn와 embed를 구분하여 코드를 설계하였는가?
1. 초기화 단계 vs. 실행 단계를 명확히 분리
create_embedding_fn는 “어떤 주파수 대역을 쓸 것인지?”, “사인·코사인 등 어떤 함수를 쓸 것인지?”를 결정하고, 그에 맞는 람다 함수들을 한 번 생성해 둡니다.- 이후 실제 데이터를 넣을 때(
.embed()호출 시), 이미 만들어진 함수를 재사용하여 빠르게 인코딩을 수행할 수 있습니다.
- 반복 호출 효율
- 만약 매번 입력이 들어올 때마다(예: 매 배치마다) “사인·코사인 함수를 생성·세팅” 한다면 오버헤드가 큽니다.
- 반면 초기 한 번(
create_embedding_fn)만 람다들을 생성해두고,.embed(...)에서는 “이미 만들어진 함수 리스트”를 순회하기만 하면 되므로 코드 재사용과 효율이 좋아집니다.
import torch
# torch.autograd.set_detect_anomaly(True)
import torch.nn as nn
import torch.nn.functional as F
import numpy as np
# Positional encoding (section 5.1)
class Embedder:
def __init__(self, **kwargs):
self.kwargs = kwargs # “몇 차원의 입력을 받을지?”, “몇 개의 주파수를 사용할지?”, “어떤 함수를 쓸지?(sin, cos 등)” 등의 정보가 담긴 아규먼트를 받는다.
self.create_embedding_fn() # 바로 create_embedding_fn()을 호출하여 실제 인코딩 함수를 만든다.
def create_embedding_fn(self):
embed_fns = [] # 임베딩 할 함수들을 담는 리스트
d = self.kwargs['input_dims'] # 입력 차원. view dir과 카메라 위치 좌표 모두 3차원이다.
out_dim = 0 # 최종 Positional Encoding의 출력 차원을 추적하기 위한 변수로, 초기 값은 0으로 세팅.
if self.kwargs['include_input']: # 단순히 인풋 값을 아웃풋에 추가할 것인지.
embed_fns.append(lambda x : x) # 인코딩 벡터에 인풋값인 X, Y, Z 좌표를 추가해준다. (즉, 60차원이 아닌 63차원으로 return)
out_dim += d # out_dim에 3 더하여 추적 업데이트.
# L과 L-1을 정해준다. (하단의 embed_kwargs 참조)
max_freq = self.kwargs['max_freq_log2'] # 최대 주파수 max_freq = Octave-1 = L-1
N_freqs = self.kwargs['num_freqs'] # 주파수 개수 N_freqs = Octave = L
if self.kwargs['log_sampling']: # 로그 샘플링
freq_bands = 2.**torch.linspace(0., max_freq, steps=N_freqs)
# 0부터 max_freq(=L-1)까지 N_freqs개를 2의 제곱에 모두 태우는 것.
else: # 리니어 샘플링
freq_bands = torch.linspace(2.**0, 2.**max_freq, step=N_freqs)
# 0부터 max_freq(L-1)까지 N_freqs개를 단순히 리니어 샘플링 한다.
# 실제 코드는 있으나 사용하진 않음.
# 예: max_freq_log2=9, num_freqs=10 → freq_bands = [1, 2, 4, 8, ..., 512(=2^9)]
# 이제 sin, cos에 태워준다.
for freq in freq_bands:
for p_fn in self.kwargs['periodic_fns']: # 어떤 함수에 태울 것인가? (논문에선 cos, sin 사용)
embed_fns.append(lambda x, p_fn=p_fn, freq=freq : p_fn(x * freq)) # 수식에는 π까지 붙이는데 여기선 그냥 sin(2^n * x), cos(2^n * x)
# cf) lambda (input : output)
out_dim += d
# 이후 클래스의 다른 함수에서 접근할 수 있도록 self 변수에 대입
self.embed_fns = embed_fns # 포지션 인코딩에 사용할 람다 함수 리스트 (x, sin, cos, ... , sin, cos)
self.out_dim = out_dim # 포지션 인코딩 된 값의 차원
# embed_fns에 input 데이터를 넣어 임베딩 된 결과를 도출한 뒤, torch.cat으로 묶어서 반환해주는 함수
def embed(self, inputs):
return torch.cat([fn(inputs) for fn in self.embed_fns], -1)
# 여러 개의 람다 함수를 순회하며, 입력벡터 inputs에 대해 각각 사인·코사인을 계산.
# 마지막 차원(-1)으로 연결(torch.cat), 즉 shape가 (N, out_dim) 형태가 됨.
# 예:
# 입력이 shape (N,3)
# 주파수 대역이 L=10, include_input=True라면,
# 최종 출력은 (N, 63).2) get_embedder
이 함수는 위에서 선언한 임베더 클래스의 내부 함수들을 실행시켜 결과를 받아내는 역할을 한다.
이렇게 선언된 클래스에서 인스턴스를 생성하고, 내부 함수를 수행하는 함수를 헬퍼 함수라고도 부른다.
헬퍼 함수는 외부 코드에서 직접 인스턴스를 만들고 일일이 인자들을 세팅하는 과정을 하나의 명령어로 컨트롤할 수 있기 때문에 다양한 변인을 바꿔줘야 하는 실험 세팅에 편리함을 준다.
input:
- mulitres: 옥타브 수
- i: 포지셔널 인코딩 사용 여부
output:
- embed: 포지셔널 임베딩을 진행할 함수
- embedder_obj.out_dim: 포지셔널 임베딩 된 벡터의 차원
# 위에서 정의한 임베더 클래스에서 객체를 생성한 후, view_o와 view_d를 구분하여 임베딩 해주는 함수.
# view_o와 view_d의 옥타브 (L = multires)의 값이 각각 다르다.
def get_embedder(multires, i = 0): # multires는 옥타브 수
# 만약 i=-1, 즉 “positional encoding을 쓰지 않겠다”는 상황이면, 항등 함수(nn.Identity())와 출력차원 3을 반환.
if i == -1:
return nn.Identity(), 3 # 그냥 같은 값 return.
# -1이 아닌 경우
# 임베더 인스턴스를 생성하기 전에, 이것이 생성자(__init__)에서 받는 kwargs를 생성해준다.
embed_kwargs = {
'include_input' : True, # 원래 input 값을 output에 넣을 것이냐? (60 -> 63)
'input_dims' : 3, # input_dim은 view_o와 view_d 모두 3차원으로 동일.
'max_freq_log2' : multires-1, # L - 1
'num_freqs' : multires, # = L (옥타브 수). 이 값은
'log_sampling' : True, # 지수함수에 태울 것인가
'periodic_fns' : [torch.sin, torch.cos], # 어떤 주기함수에 태울 것인가
}
embedder_obj = Embedder(**embed_kwargs) # 객체 생성 후 위에서 정의한 kwargs로 초기화
embed = lambda x, eo=embedder_obj : eo.embed(x) # 임베딩 된 결과값
# embed는 positional encoding 된 값, embedder_obj.out_dim는 예를 들어 63이 나올 것
return embed, embedder_obj.out_dim# 카메라 좌표 (X, Y, Z)를 옥타브 10에 태워 임베딩 하는 예제(torch.rand)
embed, out_dim = get_embedder(10,0) # 옥타브 10
# embed: 임베딩 함수
# outdim: 임베딩 차원수
print(embed)
print(out_dim)
input = torch.rand(3)
# embed 함수로 인스턴스 생성부터 결과값
output = embed(input) # 처음 3개는 같고, 그 다음 60개는 sin, cos을 태운 것.
print(input)
print(output)# 카메라 좌표 (X, Y, Z)를 옥타브 10에 태워 임베딩 하는 예제(torch.zeros)
embed, out_dim = get_embedder(10,0) # 옥타브 10
print(embed)
print(out_dim)
input = torch.zeros(3)
output = embed(input)
print(input)
print(output)# view_dirs를 옥타브 4에 태워 임베딩 하는 예제
embed, out_dim = get_embedder(4, 0) # 뷰 디렉션의 옥타브는 4
print(embed)
print(out_dim)
output = embed(input)
print(input)
print(output)2. NeRF 네트워크 구현
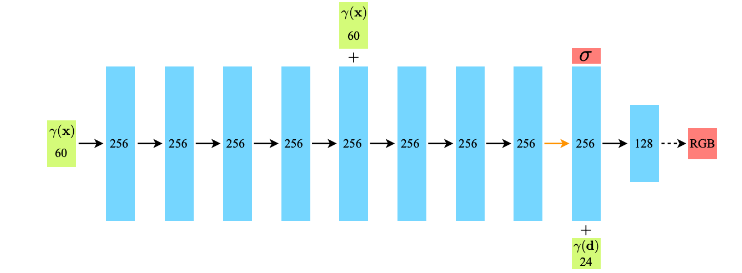
입력 데이터:
- x.shape = (B, 63 + 27)
- 각 샘플 포인트의 rays_o 임베딩 벡터와 rays_d 임베딩 벡터가 두 번째 차원에서 concat
- 여기서 B는 모든 샘플 포인트 수 (N_rays * N_samples) 를 배치 단위
출력 데이터:
- return.shape = (B, 4)
- 각 샘플 포인트의 RGB 값과 불투명도 값
네트워크 임베딩 시퀀스:
- rays_o의 임베딩 벡터만 첫 번째 레이어에 임베딩 됨
- 5번째 레이어에서 해당 벡터를 skip connect 하여 정보 희석 방지
- 마지막 레이어에서 해당 픽셀의 투명도를 산출
- rays_d의 임베딩 벡터와 rays_o의 임베딩 벡터를 concat 한 벡터가 마지막 레이어에 임베딩 됨
- 이 정보에 대한 아웃풋으로 RGB값을 산출
# Model
class NeRF(nn.Module):
def __init__(self, D=8, W=256, input_ch=3, input_ch_views=3, output_ch=4, skips=[4], use_viewdirs=False): # output_ch=4인 이유는 rgb와 alpha의 4개이므로.
super(NeRF, self).__init__()
# 생성자로 받은 인자를 클래스 내부 변수로 저장
self.D = D # 네트워크의 총 레이어
self.W = W # 은닉 레이어 너비(채널 수)
self.input_ch = input_ch # 뷰 위치 차원
self.input_ch_views = input_ch_views # 뷰 디렉션 차원
self.skips = skips # 스킵 커넥션 레이어
self.use_viewdirs = use_viewdirs # 뷰 디렉션 사용 여부 (사용)
# 위치 좌표의 입력을 처리하는 레이어
self.pts_linears = nn.ModuleList([nn.Linear(input_ch, W)] +
[nn.Linear(W, W) if i not in self.skips else nn.Linear(W+input_ch, W) for i in range(D-1)])
# 스킵 레이어가 아니라면 단순히 W -> W 레이어
# 스킵 레이어라면 W + input_ch -> W 레이어
# 스킵 커넥션의 성능: 깊은 레이어에서도 초기 입력 좌표의 고주파 정보를 계속 사용할 수 있게 됩니다.
# 시점 방향 입력을 처리하는 레이어
self.views_linears = nn.ModuleList([nn.Linear(input_ch_views + W, W//2)])
# W + input_ch_view -> W 레이어
if use_viewdirs: # view_dirs를 사용한다면
self.feature_linear = nn.Linear(W, W) # W -> W 레이어
self.alpha_linear = nn.Linear(W, 1) # 하나의 스칼라 값인 알파값을 뽑기 위한 1채널
self.rgb_linear = nn.Linear(W//2,3) # rgb output을 뽑기 위한 3채널
else: # view_dirs를 사용하지 않는다면
# 단일 레이어 (W -> 4)로 RGB값과 알파 값을 같이 추출
self.output_linear = nn.Linear(W, output_ch) # rgb 알파까지 해서 4채널
def forward(self, x): # x.shape = (B, 63 + 27), 이 때, B는 전체 포인트 N_rays * N_samples를 chunk 단위로 나눈 것이다.
# input x에는 좌표에 대한 인코딩 값인 self.input_ch와 view dir에 대한 인코딩 값인 self.input_ch_views이 concat 되어있다.
# 따라서 우선 이걸 torch.split를 dim = -1 (마지막 dim)에서 나눠준다.
input_pts, input_views = torch.split(x, [self.input_ch, self.input_ch_views], dim=-1) # (B, 63), (B, 27)
# input_pts: 인코딩된 광선 원점
# 이를 for문을 돌면서 변형될 h에 대입하는 이유는, skip connection layer에서 input_pts를 concat 해주기 위함이다.
h = input_pts
# 인덱스 4 레이어에서 h를 한 번 더 concat 하니까 인덱스를 알기 위해 enum 사용
for i, l in enumerate(self.pts_linears):
h = self.pts_linears[i](h) # i번째 레이어에 h를 넣고
h = F.relu(h) # relu 태워주기
if i in self.skips: # 인덱스가 self.skips에 포함된다면
h = torch.cat([input_pts, h], -1) # (B, 63+256)
# 현재 h: 위치 좌표에 대한 W 차원의 output
# view dirs의 사용 여부(논문에선 사용)
if self.use_viewdirs:
alpha = self.alpha_linear(h) # for loop를 다 돌고 나온 h에 self.alpha_linear를 통과시켜 투명도인 alpha를 생성
# h를 다시 feature layer에 통과시켜 변형
feature = self.feature_linear(h) # for loop를 다 돌고 나온 h에 self.feature_linear를 통과시켜 feature를 생성
h = torch.cat([feature, input_views], -1) # feature_linear를 input_views와 concat
# 위치와 방향 두 가지 정보를 조합해서 rgb 컬러 값을 낸다.
# 보는 방향이 달라졌을 때, 빛의 반사 등에 의해 같은 지점의 색상도 다르게 보일 수 있으니 방향 정보를 concat 하는 것
# views_linears를 거쳐 최종 rgb값 산출
for i, l in enumerate(self.views_linears):
h = self.views_linears[i](h)
h = F.relu(h)
# 마지막 rgb 레이어 (256 to 128)
rgb = self.rgb_linear(h)
outputs = torch.cat([rgb, alpha], -1)
else:
outputs = self.output_linear(h) # view dir를 사용하지 않을 경우 단일 레이어에서 rgb, alpha 모두 얻음.
return outputs# 인풋 값 생성
input_pts = torch.rand(1,3) # 배치 1, input은 x, y, z로 3
input_dir = torch.rand(1,3) # 배치 1, dir도 3
print(input_pts)
print(input_dir)
# 임베딩 하기
embed_func_pts, out_dim_pts = get_embedder(10) # 좌표 옥타브는 10
embed_func_dir, out_dim_dir = get_embedder(4) # 방향 옥타브는 4
# 임베딩한 결과값
emb_input_pts = embed_func_pts(input_pts)
emb_input_dir = embed_func_dir(input_dir)
print(emb_input_pts.shape)
print(emb_input_dir.shape)
# 모델 생성
model = NeRF(input_ch=out_dim_pts, input_ch_views=out_dim_dir, use_viewdirs=True)
x = torch.cat([emb_input_pts, emb_input_dir], dim=-1)
print(x.shape)
out = model(x)
print(out.shape) # out은 rgb와 알파 값이 concat 되어 나온다. (B, 4)batchify()
GPU 연산 과부하를 막기 위해 모든 샘플들을 잘라서 NeRF 네트워크에 넣은 뒤, 연산 결과를 concat 하여 return
- input data: (N_rays * N_samples, 63 + 27)
- output data: (N_rays * N_samples, 4)
# 함수를 return 하는 함수
# chunk: flattend 된 N_rays * N_samples이 매우 큰 경우 (512*512*64) 이 배치가 연산이 안 될 수 있다.
# 따라서 모델이 처리할 수 있는 max 사이즈를 chunk 단위로 끊어서 연산한다.
def batchify(fn, chunk): # fn은 분할하여 연산할 함수. 여기선 NeRF 모델.
"""Constructs a version of 'fn' that applies to smaller batches.
"""
if chunk is None: # chunk: 한 번에 처리할 수 있는 최대 샘플 수(배치 크기).
return fn # fn: 실제 모델(NeRF MLP) 등, 텐서를 입력받아 출력 텐서를 반환하는 함수.
# 만약 chunk가 None이면, 그냥 fn을 그대로 반환(즉, 분할 없음).
# 그렇지 않다면, 내부에 ret(inputs)라는 새 함수를 정의 → 이 함수가 실제로 “batchify”를 수행.
def ret(inputs): # (N_rays * N_samples, 63 + 27)
# inputs.shape[0]은 모든 샘플을 일렬로 펼친 개수 (N_rays × N_samples)
# range(0, inputs.shape[0], chunk)로 0번 축(첫 번째 차원)을 chunk 단위씩 나눈다.
# 예: chunk=4096이면, inputs[0:4096], inputs[4096:8192], 등으로 슬라이스.
# 각 조각을 fn(...)에 넣어 계산 → 결과 리스트를 torch.cat(..., dim=0)으로 연결.
# 최종적으로 모든 조각이 합쳐진 결과를 반환.
return torch.cat([fn(inputs[i:i+chunk]) for i in range(0, inputs.shape[0], chunk)], 0) # 0부터 N_rays * N_samples까지 chunk 단위로 잘라 nerf에 통과시킨 뒤, 이들을 전부 concat하여 return
# 즉, (N_rays×N_samples, D) 형태로 flatten된 대규모 입력을,
# (chunk, D) 단위로 여러 번 나눠서 모델에 넣고,
# 그 출력을 이어붙이는 역할을 함.
return ret # (N_rays * N_samples, 4)run_network()
전체 데이터를 받아 배치 단위로 나눈 뒤 모델 네트워크를 통과시켜 최종 결과값을 반환하는 함수
입력 데이터:
- inputs: 모든 광선상의 샘플 포인트 위치 좌표 (H*W, N, 3) = (N_rays, N_samples, 3)
- viewdirs: 광선의 방향벡터 (N_rays, 3)
- fn: NeRF 네트워크 (Coarse or Fine Network)
- embed_fn: inputs를 포지셔널 임베딩 해줄 함수
- embeddirs_fn: view_dirs를 포지셔널 임베딩 해줄 함수
- netchunk: 한 번에 처리할 chunk 크기(디폴트 1024*64), 즉 1024개의 광선 상의 64개의 샘플 포인트를 연산.
출력 데이터:
- outputs: 모든 광선상의 샘플 포인트의 RGB값과 불투명도 (H*W, N, 4) = (N_rays, N_samples, 4)
ays_d와 viewdirs의 차이
rays_d
- get_rays() 혹은 get_rays_np() 함수에서 H, W, K(카메라 내부 행렬), c2w(카메라 외부 행렬)을 받아 계산
- 시점이 카메라의 초점 &(0, 0, 0)&이고 종점 &인 노멀 플레인 상에 있는 픽셀별 방향벡터를 c2w 행렬을 통해 월드 좌표계로 회전한 것
- 광선 위에 분포하는 샘플 포인트의 좌표를 구할 때 사용
- 아래의 render_rays() 함수에 구현 되어있음
viewdirs
- 위에서 계산한 rays_d의 크기를 1로 정규화한 방향벡터
- 이 변수는 포지셔널 임베딩을 거쳐 NeRF 네트워크에 들어갈 입력 데이터로 사용 됨
- 아래의 run_network() 함수에 구현 되어있음
# 모델을 실행하는 code
# inputs, viewdirs, fn, embed_fn, embeddirs_fn를 받아 포지션 임베딩부터 모델 통과까지를 일괄 처리 해주는 함수
def run_network(inputs, viewdirs, fn, embed_fn, embeddirs_fn, netchunk=1024*64):
# inputs: 모든 광선상의 샘플 좌표 (H*W, N, 3) = (N_rays, N_samples, 3)
# viewdirs: 광선의 방향벡터 (N_rays, 3)
# fn: NeRF 네트워크 (예: Coarse/Fine MLP)
# embed_fn, embeddirs_fn: 샘플 포인트의 위치 좌표와 방향벡터를 포지셔널 인코딩 할 함수들
# netchunk: 한 번에 처리할 chunk 크기(디폴트 1024*64), 즉 1024개의 광선 상의 64개의 샘플 포인트를 연산할 것이다.
inputs_flat = torch.reshape(inputs, [-1, inputs.shape[-1]]) # (H*W, N, 3)을 (H*W*N, 3) = (N_rays*N_samples, 3) = (모든 샘플 개수, 3)
embedded = embed_fn(inputs_flat) # 포지션 인코딩 (H*W*N, 63) = (N_rays*N_samples, 63)
if viewdirs is not None:
# viewdirs (N_rays, 3)
# 하나의 광선 상에 존재하는 모든 샘플 포인트의 방향 벡터는 동일하므로 (N_rays, N_samples, 3)으로 차원을 확장한 뒤, 동일한 방향 벡터를 채워넣어 줘야 한다.
# viewdirs[:, None]: [N_rays, 1, 3] (차원 확장)
# viewdirs[:, None].expand(inputs.shape): [N_rays, N_samples, 3] (expand 명령어로 동일한 방향 벡터를 확장된 차원에 채워넣음)
input_dirs = viewdirs[:, None].expand(inputs.shape) # input_dirs = (N_rays, N_samples, 3)
# inputs_flat과 동일한 차원으로 맞춰주기 위해 모든 샘플 포인트를 일렬로 펼침
input_dirs_flat = torch.reshape(input_dirs, [-1, input_dirs.shape[-1]]) # (N_rays * N_samples, 3)
embedded_dirs = embeddirs_fn(input_dirs_flat) # 포지션 인코딩 (H*W*N, 27) = (N_rays*N_samples, 27)
embedded = torch.cat([embedded, embedded_dirs], -1) # concat 진행. 최종 (H×W×N, 63 + 27)
outputs_flat = batchify(fn, netchunk)(embedded) # run network
# (H×W×N, 63 + 27)를 (1024*64, 63 + 27)의 청크 단위로 나누어 NeRF 네트워크에 통과시킨 후, 이를 다시 0번 차원으로 concat 하여 (H×W×N, 4) 차원의 결과값 반환
# list(inputs.shape[:-1]): 마지막 채널 전까지, 즉 [N_rays, N_samples]의 모양으로 다시 펼치고, 마지막 4차원인 [outputs_flat.shape[-1]의 모양으로 reshape
outputs = torch.reshape(outputs_flat, list(inputs.shape[:-1]) + [outputs_flat.shape[-1]]) # [N_rays, N_samples, output_ch=4]
return outputs1) chunk는 한 광선의 전체 샘플 수(N)의 배수여야 하는가?
결론부터 말하면, 반드시 배수일 필요는 없습니다.
각 광선(ray)에 대해 샘플링한 점들이 chunk 경계에서 “중간에 잘려” 들어가도, 모델(MLP) 입장에서는 아무 문제가 없습니다.
왜 괜찮을까?
- NeRF 신경망(MLP)은 완전히 점별(point-wise) 독립적인 함수입니다.
- (x,y,z) 한 점이 입력으로 들어오면, (density, color) 하나를 출력할 뿐, “ray의 다른 점들”과 시간을 공유하거나 RNN처럼 상태를 공유하지 않습니다.
- Chunk는 단지 “(N_rays × N_samples)이 너무 커서 한 번에 GPU에 못 태우는 경우”에, 0번 축으로 슬라이스해 여러 번 나눠서 연산할 뿐입니다.
- 즉, 된 1D 인덱스 순서대로 잘라서 MLP에 넣고, 결과를 이어 붙이면, 최종 순서가 동일하게 복원되므로 문제가 없습니다.
- NeRF 후처리(볼륨 렌더링 등)에서는 “각 레이의 , color”를 다시 같은 인덱스 순으로
reshape해서 쓰기 때문에, 한 레이의 5개 점이 chunk 경계를 사이에 두고 분산되어 처리되어도 괜찮습니다.
예를 들어, 하나의 광선에서 5개의 점()을 샘플링 했다고 가정했을 때,
이 한꺼번에 들어가든,
로 두 번 나눠 들어가든, 결과적으로는 모델이 “입력-출력 대응”만 하면 되므로 학습 혼동은 없습니다.
2) 실제 torch.reshape()함수가 어떻게 동작하는가?
- 가정:
H=4, W=6, 총 24픽셀인 화면에서, 각 픽셀마다3차원 좌표 (x,y,z)로 이루어진 샘플 포인트를N=5개씩 뽑는다고 가정하자. - 그럼
inputs.shape = (24, 5, 3)이다. - 또한
inputs[i, j]= i번째 픽셀의 j번째 샘플 포인트로shape = (3,)이다.
(1) flatten될 때, 원소의 순서
inputs_flat = torch.reshape(inputs, [-1, inputs.shape[-1]])
# shape: (24*5, 3) = (120, 3)PyTorch에서는 row-major 방식(“C 스타일”)으로 텐서를 일렬로 펼칩니다. 즉,
- 0번 픽셀 (
i=0)에 대해 j=0..4 (총 5개 샘플)이 순서대로 - 1번 픽셀 (
i=1)에 대해 j=0..4 - 2번 픽셀 (
i=2)에 대해 j=0..4
… - 23번 픽셀 (
i=23)에 대해 j=0..4
이 순서로 0번 축이 이어진 뒤, 마지막 축(3)은 그대로 (x,y,z)로 모양을 유지.
구체 예시
inputs
inputs[0,1,:] = (x00,y00,z00)
inputs[0,1,:] = (x01,y01,z01)
…
inputs[0,4,:] = (x04,y04,z04)
inputs_flat
inputs_flat[0] = (x00,y00,z00)
inputs_flat[1] = (x01,y01,z01)
inputs_flat[2] = (x02,y02,z02)
inputs_flat[3] = (x03,y03,z03)
inputs_flat[4] = (x04,y04,z04)
inputs_flat[5] = (x10,y10,z10)
inputs_flat[6] = (x11,y11,z11)
inputs_flat[7] = (x12,y12,z12)
inputs_flat[8] = (x13,y13,z13)
inputs_flat[9] = (x14,y14,z14)
…
이런 식으로 i 픽셀마다 5샘플씩 차례대로 나열되어, 총 (120, 3)이 됩니다.
(2) Chunk가 샘플 포인트의 배수가 아닌 경우는?
-
예:
batchify(fn, chunk=3)라면,inputs_flat.shape = (120,3)을- 1번째:
inputs_flat[0:3] - 2번째:
inputs_flat[3:6] - 3번째:
inputs_flat[6:9]
… - 40번째:
inputs_flat[117:120]
- 1번째:
-
이렇게 40번 나누어 모델에 통과시키고, 각각의
inputs_flat.shape=(3, 3)을 0번 차원으로 이어 붙이면 최종ret.shape=(120, 3)이 생성. -
이때
0번 픽셀의 5개 샘플중 첫 3개는 첫 chunk, 나머지 2개는 두 번째 chunk에 들어가 처리됩니다. -
그러나 네트워크는 포인트별 독립 계산이므로 전혀 문제 없음.
3) 텐서의 차원 추가
아래 코드는 뷰 방향(input_dirs)을 “inputs_flat”에 맞춰 반복해서 붙여주는 전형적인 방식입니다.
다시 말해, 한 광선(ray)에 대해 그 광선 전체가 동일한 방향을 갖고 있으므로, 각 샘플 지점마다 동일한 값을 주어 확장하는 것입니다.
# viewdirs.shape: (N_rays, 3)
# viewdirs.shape: (N_rays, 1, 3)
input_dirs = viewdirs[:, None].expand(inputs.shape) # (N_rays, N_samples, 3)
input_dirs_flat = torch.reshape(input_dirs, [-1, input_dirs.shape[-1]]) # (N_rays*N_samples, 3)(1) 전제: H=4, W=6 → 개의 광선, 각 광선마다 N_samples=5
-
viewdirs.shape = (24,3):- 광선이 24개이고, 각 광선의 3차원 방향벡터를 저장.
- 예를 들어,
viewdirs[0]=(x0,y0,z0)
viewdirs[1]=(x1,y1,z1)
…
viewdirs[23]=(x23,y23,z23)
-
inputs.shape = (24,5,3):- 24개 광선 각각에 대해, 샘플 포인트가 5개씩 존재.
- 예:
inputs[i, j]= 번째 광선의 번째 샘플 좌표.
-
그러나 번째 광선에 있는 모든 샘플의 방향은 동일하므로, viewdirs의 방향 벡터를 N_samples 만큼 확장해줘야 한다.
(2) viewdirs[:, None] → shape (24, 1, 3)
- 원본: viewdirs.shape = (24, 3)
[:, None](또는.unsqueeze(1)):
두 번째 축에 길이 1을 추가해, shape(24, 1, 3)로 바뀜.
시각적으로, 이제 각 행이 “(1,3)짜리 소그룹”이 됩니다.
이를 3차원 텐서로 보면, 첫 번째 축(=24)은 “각 광선 index”, 두 번째 축(=1)은 “길이가 1인 차원”, 마지막 축(=3)은 xyz 벡터.
(3) .expand(inputs.shape) → Shape (24, 5, 3)
inputs.shape는 (24,5,3).
따라서 viewdirs[:, None].expand(inputs.shape)는 (24,1,3)의 두 번째 축(=1)을 5차원으로 브로드캐스트(복제)하여 (24,5,3)를 만듭니다.
어떤 값이 들어갈까?
- 번째 광선의 방향벡터가, 그 광선의 모든 5개의 샘플에 걸쳐 동일하게 반복됩니다.
- 예를 들어,
i=0광선이면, shape(1,3)-> shape(5,3)로 5번 복제 - 전체로는
(24,5,3)텐서가 되며, 각 [i, s, :] =
- 표로 표현하면, 예컨데 (24,5,3)을 2D로 써보면 아래처럼,
각 광선 index i가 행, 각 샘플 s가 열, (x,y,z)는 벡터로
| 광선 | 샘플 0 | 샘플 1 | 샘플 2 | 샘플 3 | 샘플 4 |
|---|---|---|---|---|---|
| 0 | |||||
| 1 | |||||
| 2 | |||||
| ... | |||||
| 23 |
즉, 한 광선 에 대한 단일 방향이 “해당 광선의 5개 샘플 지점마다 동일”하게 복제되어, 최종 (24,5,3) 형태로 담깁니다.
create_nerf()
사용할 네트워크가 coarse인지 fine인지, 모델 train인지 test인지, 파인튜닝을 할지 등 모든 경우의 수를 인자로 아울러 네트워크를 실행할 수 있도록 만든 함수
입력 데이터
- 실험에 대한 모든 정보를 담은 args 객체
출력 데이터
- render_kwargs_train: 모델 학습을 위해 필요한 세팅값 (노이즈/perturb 사용).
- render_kwargs_test: 모델 테스트를 위해 필요한 세팅값 (노이즈/perturb 사용 안 함).
- start: 학습 스텝. 파인 튜닝시 이어서 학습.
- grad_vars: 학습할 모델 파라미터 목록.
- optimizer: Adam 최적화 인스턴스.
# 학습에 들어갈 모든 것을 생성하는 wrap up 함수
def create_nerf(args):
"""Instantiate NeRF's MLP model.
"""
# --------------------------------------------------
# (1) 샘플 포인트 좌표를 포지셔널 임베딩 할 함수 생성
# --------------------------------------------------
embed_fn, input_ch = get_embedder(args.multires, args.i_embed) # args.multires: 옥타브 args.i_embed: 임베딩 여부(당연히 사용) ex: 10, 0
# embed_fn: 임베딩 함수
# iput_ch: 임베딩 후 차원(63)
# --------------------------------------------------
# (2) 광선의 방향을 포지셔널 임베딩 할 함수 생성
# --------------------------------------------------
# 변수 초기화
input_ch_views = 0 # 임베딩 후 차원 개수를 담을 변수 (0 -> 27)
embeddirs_fn = None # 임베딩 함수를 담을 변수
if args.use_viewdirs:
embeddirs_fn, input_ch_views = get_embedder(args.multires_views, args.i_embed)
# --------------------------------------------------
# (3) coarse 모델 생성
# --------------------------------------------------
# view_dirs를 사용하지 않을 경우 output_ch = 5의 결과를 반환.
# 그러나 실험에서 view_dirs를 사용하므로, output_ch = 4 (RGB + density)
output_ch = 5 if args.N_importance > 0 else 4
skips = [4] # 스킵 커넥션 레이어 지정
# coarse 모델 객체 생성
model = NeRF(D=args.netdepth, W=args.netwidth,
input_ch=input_ch, output_ch=output_ch, skips=skips,
input_ch_views=input_ch_views, use_viewdirs=args.use_viewdirs).to(device)
# 모델 파라미터를 학습할 파라미터 리스트에 저장
grad_vars = list(model.parameters())
# --------------------------------------------------
# (4) fine 모델 생성
# --------------------------------------------------
# coase 모델의 weight가 높은 곳에서는 중요도가 높기 때문에 더 많은 점을 샘플링
# 이 때, wights = transmitance * occupancy
model_fine = None
if args.N_importance > 0:
# 사실 모델의 네트워크 구조는 동일하다.
# 단지 인풋 데이터인 샘플 포인트의 좌표가 더 정확하고 촘촘해졌을 뿐.
model_fine = NeRF(D=args.netdepth_fine, W=args.netwidth_fine,
input_ch=input_ch, output_ch=output_ch, skips=skips,
input_ch_views=input_ch_views, use_viewdirs=args.use_viewdirs).to(device)
grad_vars += list(model_fine.parameters()) # 모델 파라미터 append
# --------------------------------------------------
# (5) 네트워크를 실행하는 함수 설계
# --------------------------------------------------
network_query_fn = lambda inputs, viewdirs, network_fn : run_network(inputs, viewdirs, network_fn,
embed_fn=embed_fn,
embeddirs_fn=embeddirs_fn,
netchunk=args.netchunk)
# lamnda 함수를 사용한 wrap up 함수 해석하기
# 매개변수: inputs, viewdirs, network_fn
# 나머지 매개변수는 고정된 값으로 전달하여 run_network 함수 실행
# network_query_fn(inputs, viewdirs, network_fn)을 실행하면, 나머지 인수는 고정 값으로 전달되어 run_network를 실행한 후, 결과값을 return.
# 이는 fine, coarse network를 실행할 때, embed_fn, embeddirs_fn, netchunk는 변함이 없기 때문이다.
# Create optimizer
# grad_vars: 모델 파라미터 리스트
optimizer = torch.optim.Adam(params=grad_vars, lr=args.lrate, betas=(0.9, 0.999))
start = 0 # 훈련 스텝
basedir = args.basedir
expname = args.expname
##########################
# Load checkpoints
if args.ft_path is not None and args.ft_path!='None':
ckpts = [args.ft_path]
else:
ckpts = [os.path.join(basedir, expname, f) for f in sorted(os.listdir(os.path.join(basedir, expname))) if 'tar' in f]
print('Found ckpts', ckpts)
if len(ckpts) > 0 and not args.no_reload:
ckpt_path = ckpts[-1]
print('Reloading from', ckpt_path)
ckpt = torch.load(ckpt_path)
start = ckpt['global_step'] # 파인튜닝이라면 이전 스텝에서 이어서 학습 진행.
optimizer.load_state_dict(ckpt['optimizer_state_dict'])
# Load model
model.load_state_dict(ckpt['network_fn_state_dict']) # coarse model
if model_fine is not None:
model_fine.load_state_dict(ckpt['network_fine_state_dict']) # fine model
##########################
# 모델 학습을 위해 필요한 정보들을 딕셔너리 형태로 저장하여 사용한다.
render_kwargs_train = {
'network_query_fn' : network_query_fn, # 네트워크를 실행하는 함수
'perturb' : args.perturb, # fine network에 들어갈 샘플 포인트에 진동을 줄지 여부
'N_importance' : args.N_importance, # fine 모델이 샘플할 개수(128)
'network_fine' : model_fine, # fine 모델
'N_samples' : args.N_samples, # coarse 모델이 샘플할 개수(64)
'network_fn' : model, # coarse 모델
'use_viewdirs' : args.use_viewdirs, # 광선의 방향벡터를 이용할 것인가? True
'white_bkgd' : args.white_bkgd, # 블렌더 데이터의 배경을 흰색으로 할 것인가?
'raw_noise_std' : args.raw_noise_std, # 노이즈를 섞어서 오버피팅 막기
}
# NDC only good for LLFF-style forward facing data
if args.dataset_type != 'llff' or args.no_ndc:
print('Not ndc!')
render_kwargs_train['ndc'] = False
render_kwargs_train['lindisp'] = args.lindisp
# 모델 테스트를 위해 필요한 정보들을 딕셔너리 형태로 저장하여 사용한다.
render_kwargs_test = {k : render_kwargs_train[k] for k in render_kwargs_train} # 동일한 내용을 복사
# 그러나 테스트시에는 perturb, raw_noise_std를 사용하지 않도록 수정
render_kwargs_test['perturb'] = False
render_kwargs_test['raw_noise_std'] = 0.
return render_kwargs_train, render_kwargs_test, start, grad_vars, optimizer # start는 훈련 스텝
# render_kwargs_train: 모델 학습을 위해 필요한 세팅값 (노이즈/perturb 사용).
# render_kwargs_test: 모델 테스트를 위해 필요한 세팅값 (노이즈/perturb 사용 안 함).
# start: 학습 스텝. 파인 튜닝시 이어서 학습.
# grad_vars: 학습할 모델 파라미터 목록.
# optimizer: Adam 최적화 인스턴스.