Introduction

SemGauss-SLAM은 3D 가우시안 표현 기법을 활용하여 정밀한 3D 의미론적 매핑(Semantic Mapping)과 견고한 카메라 추적(Tracking), 그리고 고품질 렌더링을 동시에 수행하는 밀집 의미론적 SLAM 시스템이다. 논문의 서론에서 강조하는 주요 내용은 다음과 같다.
-
Dense Semantic SLAM의 정의와 중요성:
Dense Semantic SLAM은 환경에 대한 의미론적 이해(객체 분류 등)를 지도 재구성에 통합하면서 동시에 카메라의 자세를 추정하는 기술이다. 이는 로봇 시스템과 자율 주행의 필수적인 과제이다. -
기존 기술의 한계:
- 전통적인 방식은 미관측 영역을 예측하지 못하는 한계가 있다.
- 최근 등장한 Neural Radiance Fields(NeRF) 기반 방법들은 이를 해결했지만, 픽셀 단위의 레이캐스팅(Raycasting) 방식 때문에 렌더링 속도가 느려 실시간 최적화에 부적합하고, 새로운 시점에서의 의미론적 표현 품질이 낮다.
-
3D Gaussian Splatting(3DGS)의 도입:
3D Gaussian Splatting에서 제안된 스플래팅(Splatting) 기법을 통해 고품질의 실시간 렌더링을 가능하게 한다. Splatam과 같은 최신 연구들이 이를 SLAM에 적용했으나, 대부분 시각적 매핑에만 집중하고 의미론적 정보 활용은 부족한 상태이다. -
SemGauss-SLAM의 핵심 기여:
- Semantic Feature Embedding: 각 3D 가우시안에 의미론적 특징 임베딩을 통합하여 공간 레이아웃 내에서 의미 정보를 효과적으로 인코딩한다.
- Feature-level Loss: 단순한 레이블 비교가 아닌 특징 수준의 손실 함수를 도입하여 가우시안 최적화에 고차원적인 가이드를 제공한다.
- Semantic-informed Bundle Adjustment(BA): 다중 프레임 간의 의미론적 연관성을 활용하여 카메라 자세와 가우시안 표현을 공동으로 최적화한다. 이를 통해 추적 시 발생하는 누적 오차(Drift)를 줄이고 매핑 정확도를 높인다.
Method
A. 3D Gaussian Semantic Mapping and Tracking
1. 의미론적 가우시안 표현 (Semantic Gaussian Representation)
장면을 구성하는 개별 가우시안의 형태와 투명도를 정의하는 기본 수식이다.
-
수식:
-
: 3D 공간상의 특정 지점 에서 가우시안이 갖는 영향력 값이다.
-
: 해당 가우시안의 불투명도(Opacity)이다. 0과 1 사이의 값을 가지며, 값이 클수록 뒤에 있는 가우시안을 더 많이 가린다.
-
: 가우시안의 중심 위치를 나타내는 3D 좌표 벡터이다.
-
: 가우시안의 반지름이다. 본 논문에서는 모든 방향으로 퍼짐 정도가 같은 등방성(Isotropy) 가우시안을 사용하므로 하나의 스칼라 값으로 표현된다.
-
: 중심점 로부터 지점 까지의 거리의 제곱이다. 중심에서 멀어질수록 지수 함수()에 의해 영향력이 급격히 감소한다.
-
2. 3D 가우시안의 2D 투영 (Projection to 2D)
3D 공간에 존재하는 가우시안을 카메라 화면, 즉 2D 픽셀 평면으로 옮기기 위한 좌표 변환 수식이다. 이 과정은 기존 핀홀 카메라 모델의 투영 방정식을 바탕으로 이루어진다.
- 수식:
이에 대한 유도 과정이 궁금하다면, 해당 포스팅의 링크를 걸어둔다.
- link: https://velog.io/@whitecl1031/%ED%95%80%ED%99%80-%EC%B9%B4%EB%A9%94%EB%9D%BC-%EB%AA%A8%EB%8D%B8
위의 핀홀 카메라 투영 방정식에서 세계 좌표계의 점 를 가우시안의 중심 로 치환하고, 양변을 깊이 값으로 나누어 정리하면 아래의 가우시안 2D 투영 식을 얻을 수 있다.
- : 2D 픽셀 평면에 투영된 가우시안의 중심 좌표를 의미한다. 이는 핀홀 카메라 모델에서 최종적으로 구하고자 했던 픽셀 좌표 , 즉 벡터에 해당하는 값이다.
- : 초점 거리와 주점 정보를 포함하는 카메라 내부 파라미터 행렬이다. 기존 핀홀 모델 식의 행렬과 완전히 동일한 역할을 수행하며, 3D 공간의 좌표를 픽셀 단위로 변환해 준다.
- : 번째 프레임에서의 카메라 자세를 나타내는 외부 파라미터 행렬이다. 핀홀 카메라 모델의 행렬과 마찬가지로 회전 변환과 병진 변환을 수행하여, 세계 좌표계에 존재하는 3D 점을 카메라 좌표계 기준으로 변환하는 역할을 한다.
- : 카메라 중심으로부터 3D 가우시안의 중심까지 떨어진 깊이 거리를 뜻한다. 이는 카메라 좌표계로 변환된 위치 의 축 성분과 같으며, 핀홀 모델 식에서 픽셀 평면으로 스케일을 맞추기 위해 나누어주던 거리 값 와 완벽하게 대응된다.
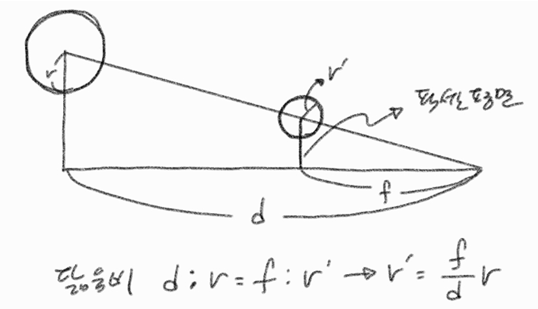
- : 픽셀 평면에 투영된 2D 가우시안의 반지름이다. 3D 공간에서의 반지름 을 깊이 로 나누고 초점 거리 를 곱함으로써, 거리가 멀어질수록 물체가 작게 보이는 원근법의 특성을 투영 결과에 물리적으로 반영한다.
3. 의미론적 특징 및 속성 렌더링 (Differential Rendering)
여러 가우시안이 겹쳐 보일 때, 최종 픽셀의 값을 결정하는 알파 블렌딩(Alpha-blending) 과정이다.
여러 가우시안이 겹쳐 보일 때, 최종 픽셀의 값을 결정하는 알파 블렌딩 과정이다.
- 수식:
-
: 픽셀 에서 렌더링을 마친 최종 16채널 의미론적 특징 벡터이다.
-
: 번째 가우시안이 가진 고유한 의미론적 특징 임베딩 값이다.
-
: 픽셀 위치에서 투영된 번째 2D 가우시안의 불투명도 영향력 값이다.
-
: 빛의 투과율을 나타낸다. 번째 가우시안보다 카메라에 더 가깝게 위치한 가우시안들에 의해 가려지고 남은 빛의 비율을 의미하며, 앞에 있는 가우시안들의 불투명도가 높을수록 이 값은 작아진다.
-
간단한 예시:
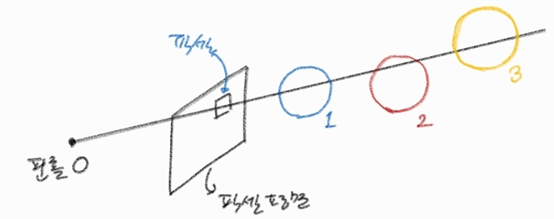
픽셀 에서 쏜 레이가 카메라와 가장 가까운 순서대로 가우시안 1, 가우시안 2, 가우시안 3을 차례대로 관통한다고 가정한다. 이때 시그마 기호 는 각 가우시안이 최종 픽셀 값에 기여하는 정도를 모두 누적해서 더한다는 뜻이고, 파이 기호 는 해당 가우시안 앞쪽에 있는 가우시안들이 빛을 투과시키는 비율을 계속 곱해나간다는 의미이다. 이 시나리오에 맞춰 총 3개의 가우시안 집합에 대해 수식을 풀어서 쓰면 아래와 같이 세 항의 합으로 나타낼 수 있다.
- 첫 번째 항 : 카메라와 가장 가까운 첫 번째 가우시안이 픽셀에 미치는 영향이다. 자신의 앞을 가리는 다른 물체가 전혀 없으므로, 자신의 고유한 특징 값 에 자신의 불투명도 영향력인 를 온전히 곱해서 더해준다.
- 두 번째 항 : 두 번째 가우시안이 미치는 영향이다. 자신의 특징 값 와 불투명도 를 곱한 기본 값에, 앞에 있는 첫 번째 가우시안이 가리고 남은 빛의 비율인 를 추가로 곱해주어야 비로소 최종 픽셀에 도달하는 실제 기여도를 구할 수 있다.
- 세 번째 항 : 가장 뒤에 있는 세 번째 가우시안은 앞선 두 가우시안을 모두 통과하고 남은 빛만 픽셀에 도달하게 된다. 따라서 자신의 고유 값 에 첫 번째 가우시안의 투과율 과 두 번째 가우시안의 투과율 를 연속으로 곱해주어 최종 반영 비율을 계산한다.
-
이 수식 구조는 색상 와 깊이 를 렌더링할 때도 동일하게 적용할 수 있으며, 각각 자리에 색상 와 깊이 를 대입하여 계산을 수행한다.
-
각 가우시안의 피처 주입 방법
-
초기화 단계:
-
새로운 가우시안을 생성할 때(Mapping process), 입력된 RGB-D 프레임의 각 픽셀 정보를 이용한다.
-
깊이(Depth) 정보를 통해 픽셀의 3D 좌표를 계산하여 가우시안의 중심 위치()를 정한다.
-
이때, 해당 픽셀 위치에서 DINOv2가 추출한 2D 의미론적 특징을 가져와 해당 3D 가우시안의 속성인 16채널 특징 임베딩()의 초기값으로 할당한다. 이를 통해 가우시안이 처음 생성될 때부터 의미론적 정보를 내포하게 된다.
-
-
렌더링 및 최적화 단계:
- 주입된 피처는 가우시안 스플래팅 과정을 통해 다시 2D 평면으로 렌더링될 수 있다. 픽셀 에서의 렌더링된 피처 를 위 수식으로 계산한다.
-
피처 수준의 손실 (Feature-level Loss):
-
렌더링된 피처()와 실제 이미지에서 추출된 피처() 사이의 차이를 줄이도록 가우시안의 임베딩()을 계속 최적화한다.
-
결과적으로 3D 공간의 각 가우시안은 주변 맥락과 일관된 고유한 의미론적 특징을 학습하게 된다.
-
-
4. 가시성 실루엣 렌더링 (Visibility Silhouette)
추적(Tracking) 시 신뢰할 수 있는 영역을 구분하기 위해 픽셀별 가시성 정도를 계산한다.
- 수식:
- : 픽셀 에서의 누적 가시성(Silhouette) 값이다.
- 수식의 형태는 속성 렌더링과 같으나, 가우시안 고유의 속성값( 등)을 곱하지 않고 가중치들의 합만을 구한다.
- 이 값이 1에 가까울수록 해당 픽셀 영역이 3D 가우시안들에 의해 충분히 채워져 있음을 의미하며, 본 논문에서는 이 값이 0.99 이상인 픽셀들만을 추적 최적화에 사용한다.
5. 추적 과정 (Tracking Process)
카메라의 움직임을 실시간으로 쫓는 과정으로, 이전 프레임들의 정보를 바탕으로 현재 위치를 예측하고 정밀하게 보정한다.
-
등속도 모델(Constant Velocity Model)을 통한 초기 예측: 카메라가 직전 두 프레임 사이에서 움직였던 속도와 방향이 현재 프레임에서도 그대로 유지된다고 가정하는 방식이다.
- 직전 프레임의 포즈를 , 그 이전 프레임의 포즈를 라고 할 때, 두 프레임 사이의 상대적인 변화량(속도)은 로 계산된다.
- 현재 프레임의 예상 초기 포즈 는 직전 포즈에 이 변화량을 한 번 더 적용한 가 된다.
- 이 예측치는 최적화 알고리즘이 전혀 모르는 상태에서 시작하는 것보다 훨씬 정답에 가까운 시작점을 제공하여, 계산 속도를 높이고 잘못된 위치로 수렴하는 것을 방지한다.
-
반복적 정밀화(Iterative Refinement): 위에서 구한 초기 포즈를 시작점으로 삼아, 현재의 3D 가우시안 지도를 투영한 영상과 실제 입력된 영상 사이의 차이를 최소화하는 방향으로 카메라 포즈를 조금씩 수정하여 최종 위치를 확정한다.
6. 매핑 과정 (Mapping Process)
새로운 환경 정보를 3D 가우시안 지도로 업데이트하는 과정으로, 입력 데이터의 특성을 활용해 기하학적 구조를 형성한다.
-
RGB-D 데이터를 활용한 역투영(Inverse Projection): 시스템은 RGB 영상뿐만 아니라 깊이(depth) 정보를 동시에 제공하는 RGB-D 카메라를 입력으로 사용한다.
- 첫 번째 프레임이 입력되면, 각 픽셀 에는 해당 지점의 색상 정보와 함께 카메라 센서가 측정한 정확한 거리 값(depth)인 가 포함되어 있다.
- 카메라 내부 파라미터(intrinsic matrix) 와 카메라 외부 파라미터(extrinsic matrix) 를 알고 있으므로, 각 픽셀의 좌표와 깊이 값을 결합하여 3D 공간상의 좌표 를 수학적으로 계산할 수 있다.
- 이 3D 좌표들을 중심으로 초기 3D 가우시안들을 배치함으로써, 단 한 장의 프레임만으로도 실제 물리적 크기와 거리가 반영된 초기 지도를 생성할 수 있다.
-
점진적 확장 및 가우시안 추가: 이후 프레임들에서는 현재 포즈에서 렌더링한 실루엣 지도 를 확인한다. 새로운 프레임의 픽셀 중 기존 지도와 겹치는 부분이 50% 미만인 영역이 발견되면, 해당 영역의 RGB-D 데이터를 다시 3D로 역투영하여 새로운 가우시안들을 지도에 추가한다.
B. Loss Functions
1. 의미론적 최적화를 위한 손실 함수
의미론적 정보를 정확하게 학습하기 위해 두 가지 형태의 손실을 결합하여 사용한다.
-
특징 수준 손실 (Feature-level Loss, ):
- : 렌더링된 이미지 내의 모든 픽셀 집합이다.
- : DINOv2 기반의 특징 추출기에서 생성된 실제 이미지의 특징 값이다.
- : 3D 가우시안 표현으로부터 렌더링된 픽셀 의 특징 임베딩 값이다.
- 단순한 분류 레이블뿐만 아니라 고차원의 중간 특징을 직접 비교함으로써 더 정교하고 견고한 의미론적 이해를 가능하게 한다.
- 학습 대상: 각 3D 가우시안이 보유한 16채널의 의미론적 특징 임베딩 를 학습시킨다.
-
의미론적 손실 (Semantic Loss, ):
- 렌더링 과정: 3D 가우시안들이 2D 화면으로 투영(Splatting)되면, 각 픽셀 위치에 여러 가우시안의 의미론적 특징 임베딩()이 혼합되어 쌓인다.
- 분류(Classification): 이렇게 혼합되어 렌더링된 픽셀 의 특징 를 분류기(Classifier)에 통과시켜 해당 픽셀이 어떤 클래스(예: 의자, 벽, 바닥)에 속하는지 예측한다.
- 손실 계산: 해당 픽셀의 예측된 클래스 분포와 실제 정답 레이블을 비교하여 Cross-entropy 손실을 구한다.
- 학습 대상: 각 3D 가우시안이 보유한 16채널의 의미론적 특징 임베딩 를 학습시킨다.
2. 기하학적 및 시각적 최적화를 위한 손실 함수
장면의 외형과 구조를 정확히 재구성하기 위해 RGB 이미지와 깊이 정보를 활용한다.
- RGB 손실 () 및 깊이 손실 ():
- 두 손실 모두 손실을 기반으로 하며, 입력된 RGB-D 프레임과 가우시안 스플래팅으로 렌더링된 결과물을 비교한다.
- 매핑 과정에서는 3D Gaussian Splatting의 방식을 따라 RGB 손실에 구조적 유사도를 측정하는 SSIM 항을 추가하여 시각적 품질을 높인다.
- 학습 대상: 는 3D 가우시안의 색상 속성 와 불투명도 를, 는 중심 위치 와 반지름 을 학습시킨다.
3. 매핑과 트래킹의 전략적 분리
논문은 시스템의 효율성과 정확성을 위해 매핑과 트래킹 단계에서 사용하는 손실 함수의 구성을 다르게 설정한다.
-
매핑 손실 ():
- 네 가지 손실(특징, 의미, RGB, 깊이)을 가중치()와 함께 합산하여 사용한다.
- 지도를 구성하는 3D 가우시안의 모든 속성(위치, 색상, 불투명도, 의미론적 임베딩 등)을 최적으로 업데이트하는 것이 목적이다.
-
트래킹 손실 ():
- 카메라 자세(Pose)를 추정할 때는 계산 시간을 단축하고 정확도를 높이기 위해 RGB와 깊이 손실만 사용한다.
- 특히 는 가우시안 지도가 충분히 학습된 영역(렌더링된 실루엣 값 )의 픽셀들만 선별하여 자세 추정의 신뢰도를 확보한다.
C. Semantic-informed Bundle Adjustment
-
Bundle Adjustment (BA)
- 개념 정의: 번들 조정은 사진 측량학 및 컴퓨터 비전에서 여러 시점에서 찍은 이미지들을 사용하여 3D 좌표(지도)와 카메라의 자세(위치 및 방향)를 동시에 최적화하는 과정이다.
- 번들(Bundle)의 의미: 각 카메라 중심에서 3D 공간상의 점으로 뻗어나가는 광선(Light Rays)의 묶음을 의미한다.
- 조정(Adjustment)의 의미: 이 광선들이 3D 공간상의 한 점에 완벽하게 모이도록 카메라의 자세 정보와 3D 점들의 위치 정보를 미세하게 수정한다는 뜻이다.
- 목적: 카메라 추적 중에 발생하는 누적 오차를 제거하여 전체적인 지도의 일관성을 유지하고 추적의 정확도를 높이는 것이 핵심이다.
-
기존 방식의 한계 극복
- 기존의 NeRF 기반 SLAM 시스템은 주로 마지막 입력 프레임 하나만을 사용하여 카메라 자세와 장면 표현을 최적화한다.
- 이러한 단일 프레임 제약 방식은 전역적인 제약 조건이 없기 때문에 추적 과정에서 누적 오차(Drift)가 발생하기 쉽다.
- 또한, 의미론적 수준에서 장면을 업데이트할 때 전역적으로 일관성이 떨어지는 문제가 발생한다.
-
공동 최적화(Joint Optimization)의 도입
- 이를 해결하기 위해 다중 뷰 제약 조건(Multi-view Constraints)과 의미론적 연관성을 활용하여 3D 가우시안 표현과 카메라 자세를 동시에 최적화하는 번들 조정을 수행한다.
- 3D 가우시안의 빠른 렌더링 능력을 활용하여 여러 프레임 간의 일관성을 실시간으로 계산한다.
-
의미론적 일관성 손실 ()
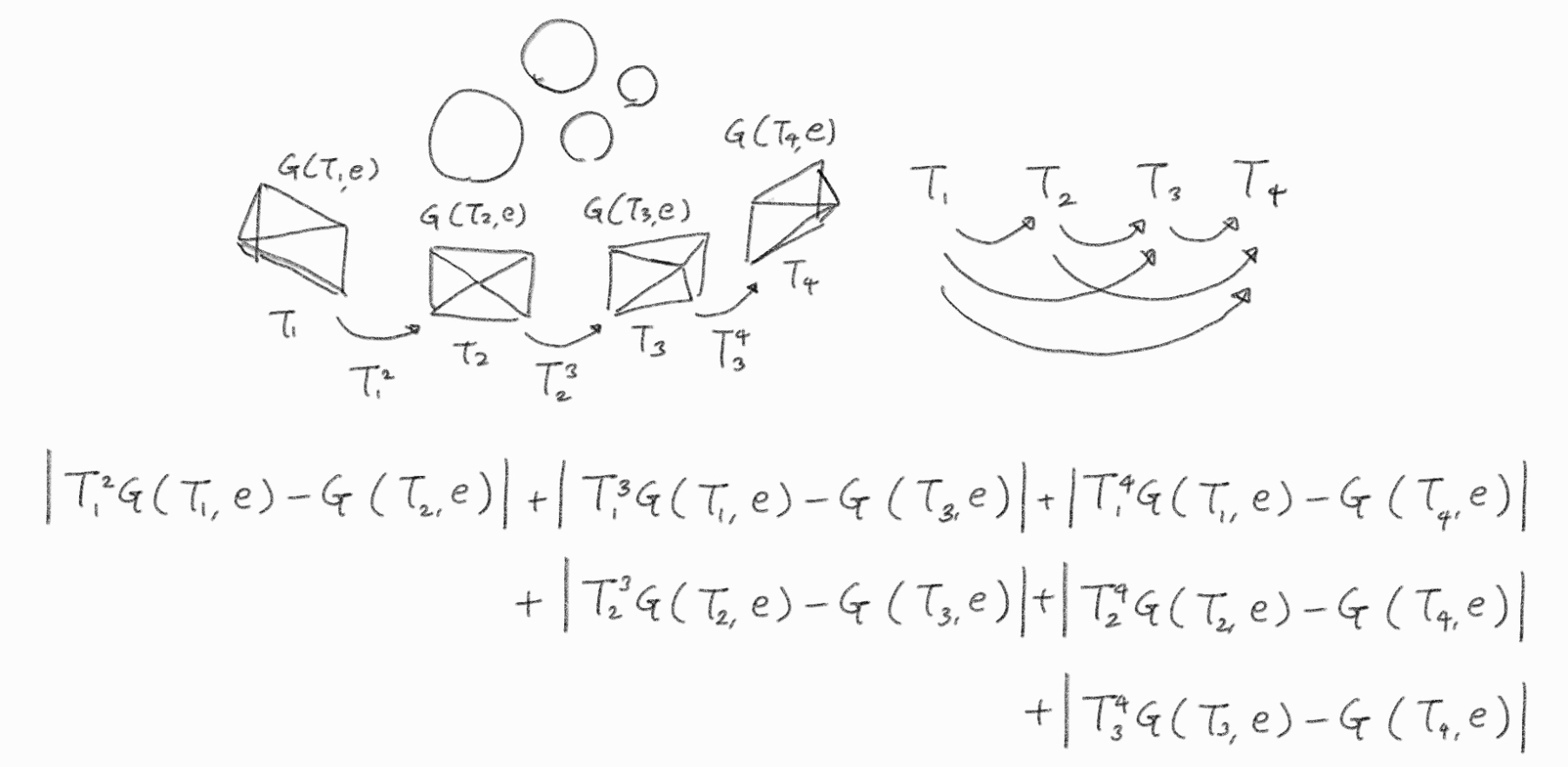
-
: 프레임 에서 프레임 로의 상대적인 카메라 자세 변환이다.
-
: 3D 공간에 흩뿌려진 가우시안들이 가진 16채널의 의미론적 특징 임베딩()을 카메라 자세 시점에서 평면에 투영(Splatting)하여 만든 2D 이미지 맵(Feature Map)이다. 일반적인 RGB 이미지가 3채널(R, G, B)인 것처럼, 이 결과물은 각 픽셀마다 16개의 숫자로 이루어진 벡터가 담겨 있는 특수한 이미지 형태라고 이해하면 된다.
-
프레임 에서 렌더링된 의미론적 특징을 추정된 자세 변환을 통해 프레임 로 워핑(Warping)한 값과, 프레임 에서 직접 렌더링된 값 사이의 차이를 최소화하여 다중 뷰 간의 의미론적 일관성을 강제한다.
-
프레임의 범위: 논문에서 사용된 은 현재 최적화 대상이 되는 공시야(Co-visible) 프레임들의 집합 크기를 의미한다.
-
조합의 수: 수식 은 선택된 개의 프레임 중에서 서로 겹치는 영역이 있는 모든 가능한 쌍(Pair)을 의미한다.
-
구체적 개수: 일반적으로 SLAM 시스템에서는 실시간성을 위해 수천 개의 전체 프레임이 아닌, 최근 프레임이나 주요 프레임(Keyframe)들 중 5~10개 내외의 적은 수()를 윈도우 방식으로 선택하여 번들 조정을 수행한다.
-
로 워핑(Warping)한다는 것의 의미와 시각적 결과
-
프레임 의 특정 픽셀 를 해당 위치의 깊이 값()을 이용해 3D 공간의 점으로 복원한다.
-
이 3D 점에 상대적 자세 변환 행렬 를 곱하여 프레임 의 카메라 좌표계로 옮긴다.
-
프레임 의 카메라 내부 파라미터를 이용해 다시 2D 픽셀 좌표 로 투영한다.
-
-
의 최적화 요소
- 카메라 자세 (): 여러 프레임 사이의 의미론적 연관성을 바탕으로 카메라의 위치와 방향을 정밀하게 조정한다.
- 가우시안의 기하학적 구조 (): 의미론적 경계가 다중 뷰에서 일치하도록 가우시안의 중심 위치(), 반경(), 불투명도()를 최적화한다.
- 의미론적 특징 임베딩 (): 각 3D 가우시안이 가진 16채널의 Semantic Feature Embedding을 최적화한다. 이를 통해 여러 시점에서 렌더링된 의미론적 정보가 일관되도록 만든다.
-
-
기하 및 외관 일관성 손실 ()
-
와 는 각각 렌더링된 RGB 색상과 깊이 정보이다.
-
의미론적 정보뿐만 아니라 색상과 깊이 정보 역시 여러 시점에서 일관되도록 보장하여 기하학적 구조를 정밀하게 다듬는다.
-
의 최적화 요소:
- 카메라 자세 (): 인접한 프레임 간의 광학적(Photometric) 일관성을 확보하기 위해 카메라의 포즈를 미세 조정한다.
- 가우시안의 기하학적 구조 (): 렌더링된 이미지의 텍스처와 색상 배치가 실제 관측값과 일치하도록 가우시안의 형태와 배치를 정밀화한다.
- 색상 속성 (): 각 가우시안의 RGB 색상 정보를 최적화하여 여러 각도에서 보았을 때 시각적인 외관이 일치하도록 만든다.
-
최적화 요소:
- 카메라 자세 (): 서로 다른 시점에서 측정한 깊이 지도가 3D 공간상에서 일관되게 정렬되도록 카메라의 자세를 최적화하여 누적 오차를 줄인다.
- 가우시안의 기하학적 구조 (): 이 손실 함수는 장면의 3D 구조를 잡는 데 가장 핵심적인 역할을 한다. 렌더링된 깊이 값이 실제 센서 데이터와 일치하도록 가우시안의 중심 위치()와 크기(), 불투명도()를 강력하게 구속하며 최적화한다.
-
-
전체 손실 함수 ()
- : 각 손실 항목의 비중을 결정하는 가중치 계수이다.
- 이 통합된 손실 함수를 통해 의미론, 기하학, 외관 정보의 상관관계를 종합적으로 고려함으로써 낮은 추적 오차와 일관된 의미론적 매핑을 달성한다.
D. Entire Framework
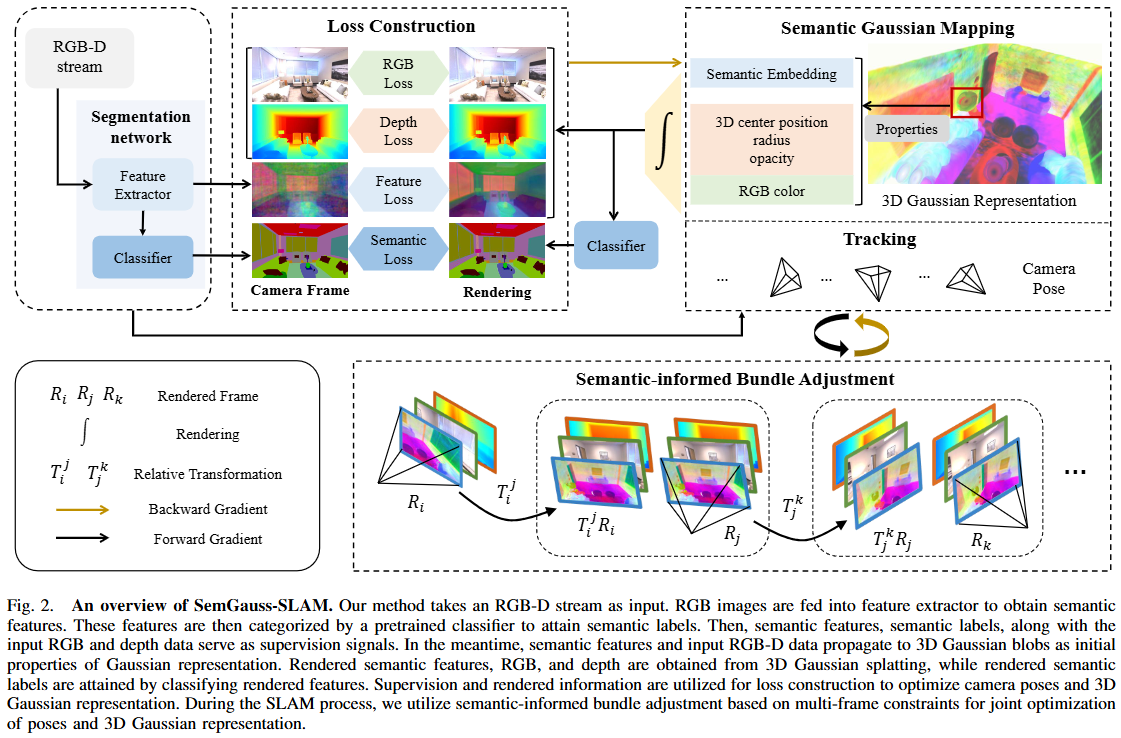
1. 입력 및 의미론적 특징 추출 (Segmentation Network)
- 시스템은 RGB-D stream을 입력으로 받는다.
- 입력된 RGB 이미지는 Feature Extractor인 DINOv2를 거쳐 고차원의 의미론적 특징을 추출하며, 이후 Classifier를 통해 각 픽셀에 대한 의미론적 레이블(라벨)을 할당한다.
- 이 정보들은 가우시안 표현을 초기화하거나 손실 함수를 계산하는 감독 신호로 사용된다.
2. 3D 가우시안 의미론적 표현 (Semantic Gaussian Representation)
- 본 논문은 3DGS의 각 가우시안에 Semantic Embedding을 추가하였다.
- 각 가우시안은 위치(), 반지름(), 불투명도(), RGB 색상()뿐만 아니라 16채널의 의미론적 특징 벡터()를 속성으로 가진다.
- 이를 통해 기하학적 형태와 시각적 외형뿐만 아니라 장면의 의미론적 구조를 3D 공간상에 조밀하게 모델링할 수 있다.
3. 손실 함수 구성 (Loss Construction)
- RGB 및 Depth Loss: 렌더링된 이미지와 입력 이미지 사이의 색상 및 깊이 차이를 최소화하여 기하학적 정확도를 높인다.
- Feature Loss (): 렌더링된 특징 맵과 DINOv2에서 추출된 특징 사이의 차이를 계산한다. 이는 단순한 클래스 분류를 넘어 고차원적인 문맥 정보를 학습하도록 돕는다.
- Semantic Loss (): 분류기를 통해 얻은 의미론적 레이블과 렌더링 결과 사이의 교차 엔트로피 손실을 계산한다.
4. 추적 및 매핑 (Tracking & Mapping)
- Tracking: 3D 가우시안 맵을 고정시킨 상태에서 현재 프레임의 카메라 포즈(위치 및 방향)를 최적화한다.
- Mapping: 새로운 가우시안을 추가하거나 기존 가우시안의 속성을 업데이트하여 지도를 확장한다. 이 과정은 SplaTAM과 같은 기존 3DGS 기반 SLAM의 방식을 의미론적 영역까지 확장한 형태이다.
5. 의미론적 정보를 활용한 번들 조정 (Semantic-informed Bundle Adjustment)
- 그림 하단은 본 논문의 핵심 기여 중 하나인 Bundle Adjustment (BA) 과정을 보여준다.
- 단일 프레임만 사용하는 대신, 여러 공동 가시 프레임(Co-visible frames, ) 사이의 상대적 변환()을 활용한다.
- 렌더링된 의미론적 특징을 다른 프레임으로 워핑(Warping)하여 시각적, 기하학적 일관성뿐만 아니라 의미론적 일관성까지 동시에 최적화한다. 이는 추적 시 발생하는 누적 오차(Drift)를 획기적으로 줄이는 역할을 한다.
Experiments
-
사용 데이터셋 (Datasets)
- Replica: 8개의 장면으로 구성된 정교한 시뮬레이션 데이터셋으로, 정확한 의미론적 정답(Ground Truth)이 포함되어 있어 시스템의 이상적인 성능을 측정하기 좋다.
- ScanNet: 5개의 장면을 포함하는 실제 환경 데이터셋으로, 노이즈가 있는 실제 센서 데이터에서의 견고함을 평가하는 데 사용된다.
-
평가 지표 (Metrics)
- 재구성 정확도: 실제 깊이 값과 예측 값의 차이를 cm 단위로 측정하는 Depth L1 지표를 사용한다.
- 추적 정확도: 카메라의 궤적 오차를 측정하는 ATE RMSE (cm)를 활용한다.
- 렌더링 품질: 이미지의 유사도를 측정하는 PSNR, SSIM과 인간의 시각적 인지 유사도를 반영하는 LPIPS를 사용한다.
- 의미론적 분할: 클래스별 교집합 대비 합집합 비율의 평균인 mIoU (%)를 통해 의미론적 매핑 능력을 평가한다.
-
비교 대상 (Baselines)
- NICE-SLAM, Co-SLAM, ESLAM, Point-SLAM과 같은 기존 NeRF 기반 SLAM 시스템과 비교한다.
- 최신 3D 가우시안 기반 SLAM인 SplaTAM 및 의미론적 SLAM인 SNI-SLAM, SGS-SLAM 등과 성능을 대조한다.
-
구현 세부 사항 (Implementation Details)
- 하드웨어: NVIDIA RTX 4090 GPU 환경에서 실험을 진행한다.
- 매핑 주기: 매 8프레임마다 매핑 과정을 수행하여 연산 효율을 높인다.
-
실험 결과
-
Replica 데이터셋에서 기존 방법들보다 모든 지표(Depth L1, RMSE, PSNR, SSIM, LPIPS)에서 우수한 성능을 기록했다.
-
실제 환경 데이터셋인 ScanNet에서도 타 시스템 대비 낮은 RMSE를 기록하며 위치 추정(Tracking)의 강건함을 입증했다.

-
이전에 보지 못한 시점에서 의미론적 레이블을 생성하는 능력(Novel View Semantic Synthesis)이 매우 뛰어나다.
-
이는 3D 가우시안에 특징 임베딩(Feature Embedding)을 통합하여 장면의 공간적 의미론적 분포를 연속적으로 모델링했기 때문이다.
-
입력 뷰에 대한 의미론적 분할 성능에서 최신 기법들을 모두 능가했다.

-
-
시각화 결과, 다른 방법들이 놓치기 쉬운 바닥이나 가구의 측면 등 빈도가 낮은 관측 영역에서도 구멍이 생기지 않고 완벽한 기하학적 재구성을 보여주었다.
-
멀티 뷰 일관성을 보장하는 BA 덕분에 서로 다른 시점에서 관측된 정보들이 기하학적으로 일관되게 정렬되어 정밀한 렌더링 품질을 유지한다.
