1. Introduction

2. Related Works

3. Method
3.1. Enocoder

3.2. Latent Space
VAE(Variational Autoencoder)에서 잠재 공간(Latent space)은 입력 데이터의 핵심 정보를 압축하여 저장하는 저차원 연속 공간이다. 이 공간의 각 점은 원본 데이터의 특징을 나타내는 잠재 벡터(latent vector)이다. VAE의 인코더는 입력 데이터를 잠재 공간의 평균 ()과 분산()으로 변환하고, 디코더는 이 잠재 공간에서 샘플링된 벡터를 받아 원본 데이터를 재구성한다.
이 문단에서 제시된 수식 (1)은 VAE의 핵심 구성 요소인 재매개변수화 트릭(reparameterization trick)을 설명한다. 이는 잠재 공간에서 미분 가능한 샘플링을 가능하게 하는 기법이다.
- : 인코더로부터 얻은 와 를 사용하여 잠재 공간에서 샘플링된 최종 잠재 벡터이다. 이 벡터는 디코더의 입력으로 전달되어 원본 3DGS(3D Gaussian Splatting) 데이터를 재구성하는 데 사용된다.
- : 인코더의 출력 중 하나로, 잠재 공간에서 입력 데이터의 평균(mean)을 나타내는 벡터이다. 이는 입력 3DGS 장면이 잠재 공간의 어느 "중심"에 위치하는지를 결정한다.
- : 인코더의 또 다른 출력으로, 잠재 공간에서 입력 데이터의 분산(variance)의 로그 값을 나타내는 벡터이다. 분산은 입력 3DGS 장면의 불확실성 또는 잠재 공간 내에서 얼마나 넓게 분포될 수 있는지를 나타낸다. 로그 값을 사용하는 것은 학습의 안정성을 높이는 데 도움이 된다.
- : 이 항은 잠재 공간의 표준 편차 와 같다.
- 는 분산 의 자연 로그이다.
- 는 로 변환된다.
- 는 자연 로그의 역함수이므로, 최종적으로 가 된다.
- 즉, 이 항은 각 잠재 변수의 표준 편차를 의미한다.
- : 표준 정규 분포 에서 샘플링된 무작위 노이즈 벡터이다. 여기서 는 평균이 0이고 공분산 행렬이 항등 행렬(identity matrix)인 다변량 정규 분포를 나타낸다. 은 예측된 평균과 분산을 기반으로 잠재 벡터 를 무작위로 샘플링하는 데 필요한 "무작위성"을 제공한다.
재매개변수화 트릭의 목적과 이점:
VAE는 잠재 공간에서 확률적으로 를 샘플링하는데, 이 샘플링 과정은 미분 불가능하다는 문제가 있다. 재매개변수화 트릭은 이 무작위성()을 와 로부터 분리하여, 인코더의 파라미터가 와 를 통해 기울기(gradient)를 받을 수 있도록 한다. 이로 인해 VAE 전체 네트워크를 효과적으로 학습시킬 수 있다. 이 논문에서는 이 트릭을 통해 3DGS와 같은 복잡하고 비정형적인 3D 장면 데이터의 잠재 표현을 학습하는 데 필수적인 역할을 한다.



3.3. Decoder

- 잠재 샘플 입력: 디코더는 VAE의 재매개변수화 트릭을 통해 인코더에서 샘플링된 잠재 샘플 를 입력으로 받는다. 이 는 입력 3D Gaussians의 압축된 표현이다.
- 3DGS 파라미터 재구성: 디코더의 주된 목적은 이 잠재 샘플 로부터 원래의 3D Gaussian Splatting (3DGS) 파라미터인 을 복구하는 것이다.
- 아키텍처 구성:
- 입력 는 먼저 선형 레이어(linear layer)를 통과한다.
- 이후 16개의 self-attention 블록을 거쳐 정보를 처리한다.
- 마지막 부분은 여러 개의 선형 레이어와 비선형 활성화 함수로 구성되어 있으며, 이는 잠재 공간을 3D 연속체(3D continuum)로 매핑하는 역할을 한다.
- 계산 효율성: Can3Tok 디코더의 마지막에 위치한 다층 퍼셉트론(multi-layer perceptron)은 학습 가능한 파라미터 수가 제한적이다. 또한, 입력과 출력이 모두 경계가 있는(bounded) 공간 내에 존재하기 때문에, 잠재 공간에서 3D 공간으로의 매핑이 가능하며 계산 비용이 적게 든다.
3.4. Loss Function


3.5. 3DGS Processing
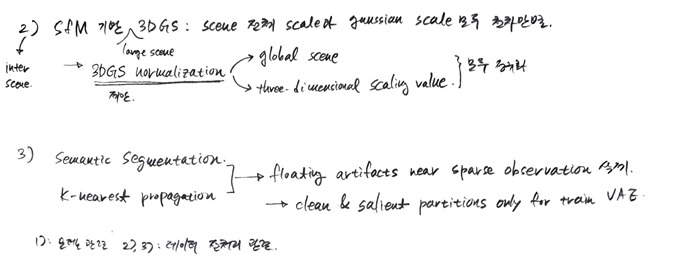
3DGS Processing은 VAE 모델을 대규모 3DGS 장면 데이터에 적용할 때 발생하는 스케일 불일치 문제를 해결하기 위한 데이터 전처리 과정이다. 이 처리는 모델의 학습 효율성과 일반화 능력을 향상시키는 데 필수적이다.
-
문제점: 스케일 불일치 (Scale Inconsistency)
- VAE 모델을 확장하여 다양한 3DGS 장면 표현을 처리할 때, 각 장면의 글로벌 스케일과 개별 3D Gaussian 프리미티브의 스케일링 값이 일관적이지 않은 문제가 발생한다.
- 이는 COLMAP과 같은 Structure-from-Motion (SfM) 기법이 카메라 포즈 추정 및 3D 포인트 삼각 측량을 수행할 때 절대적인 측정값을 제공하지 않기 때문이다.
- 이러한 스케일 불일치 때문에 Can3Tok을 포함한 기존의 어떤 VAE 모델도 많은 수의 3DGS 장면 데이터에 대해 효과적으로 일반화되지 못하였다.
-
해결책 1: Normalization
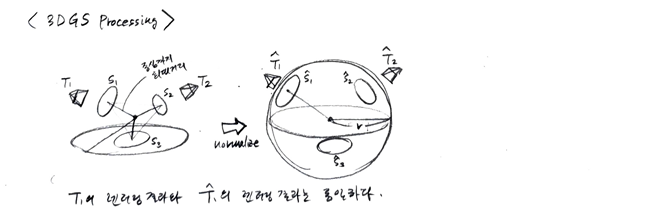
- 목표: 글로벌 장면 스케일과 각 3D Gaussian 프리미티브의 3차원 스케일링 값을 통일하여, VAE 모델이 대규모 데이터에서 더 잘 수렴하고 일반화될 수 있도록 하는 것이다.
- 영감: 2D 이미지 처리에서 모든 이미지의 크기와 RGB 채널이 일관된 범위로 정규화되는 방식이 모델 수렴과 일반화를 가속화하는 데 효과적임이 입증된 것에서 착안되었다.
- 방법:
- 각 3DGS 장면의 중심 를 월드 공간의 원점으로 평균 이동(mean-shift)한다.
- 모든 3DGS를 반지름 을 가진 구(sphere) 내에 포함되도록 스케일을 조정하고, 각 3D Gaussian 프리미티브의 스케일링 팩터 도 이에 맞춰 로 재조정한다.
- 이 과정에서 카메라의 중심 위치 또한 동일한 변환을 적용하여 로 변환한다.
- 관련 수식은 다음과 같다.
- 3DGS의 다른 속성(예: RGB 컬러)은 원래의 물리적 의미를 유지하므로 정규화하지 않는다.
- 이점: 정규화된 3DGS를 사용하여 렌더링된 이미지에서 깊이 추정 모델을 통해 장면의 실제 스케일을 복구할 수 있는 이점도 있다.
-
Normalization 예시
가정:- 가우시안의 개수
- 각 가우시안의 중심 위치 :
- 각 가우시안의 스케일링 값 (균일 스케일로 단순화):
- 정규화 목표 반지름 (일반적으로 유닛 스피어에 맞춘다.)
- 안전 계수
단계 1: 평균 이동 (translate) 벡터 계산
-
수식:
-
계산:
- 모든 가우시안 중심의 합을 구한다:
- 평균을 구한다:
- 평균 이동 벡터
translate를 계산한다:
- 모든 가우시안 중심의 합을 구한다:
-
설명: 씬의 모든 가우시안 중심들의 평균 위치를 계산하여, 이 평균 위치가 원점 으로 오도록 씬 전체를 이동시키기 위한 벡터이다.
단계 2: 스케일 (scale) 팩터 계산
-
수식:
-
계산:
- 각 가우시안 중심에
translate벡터를 적용하여 이동된 위치 를 구한다: - 각 이동된 위치 의 원점으로부터의 거리 제곱 을 계산한다:
- 이 거리 제곱들 중 최대값을 찾는다:
scale팩터를 계산한다:
- 각 가우시안 중심에
-
설명:
translate를 적용한 후, 씬 내의 가우시안 중 원점으로부터 가장 멀리 떨어진 가우시안이 반지름 인 구의 경계에 놓이도록 전체 씬의 크기를 조절하는 팩터이다. 안전 계수 을 곱함으로써, 가장 바깥쪽 가우시안이 구의 경계에 아슬아슬하게 걸치는 것이 아니라 구 안에 충분히 포함되도록 한다.
단계 3: 정규화된 3D Gaussian 중심 계산
-
수식:
-
계산: (단계 2에서 계산된 값을 활용)
-
설명: 각 가우시안의 중심이 씬의 평균 이동과 전체 씬 스케일 조절을 거쳐 정규화된 최종 위치를 갖게 된다. 이렇게 되면 모든 가우시안은 원점을 중심으로 하는 반지름 의 구 안에 안정적으로 위치한다.
단계 4: 정규화된 3D Gaussian 스케일 계산
-
수식:
-
계산: (각 스케일 벡터의 모든 성분에
scale팩터를 곱한다.) -
설명: 각 가우시안의 개별적인 스케일링 값도 씬 전체의 스케일 변화에 비례하여 조정된다. 이는 개별 가우시안의 상대적인 크기 비율은 유지하면서, 전체 씬의 정규화된 스케일에 맞춰 그 절대적인 크기를 조절하는 효과가 있다.
-
해결책 2: 의미 인식 필터링 (Semantic-aware Filtering)
- 목표: 일반적인 장면의 3DGS 재구성 결과에 포함될 수 있는 노이즈(예: 플로터, floater) 아티팩트를 제거하여, 학습 데이터의 품질을 높이고 VAE 모델의 고주파 디테일 학습 능력을 향상시키는 것이다.
- 배경: 3DGS 재구성 시 시점 관측 부족으로 인해 노이즈가 발생하며, 이는 VAE 모델의 잠재 표현 학습을 저해하여 재구성된 3DGS의 고주파 디테일이 손실되는 원인이 된다.
- 방법:
- LangSam [28]과 같은 텍스트 기반 분할 모델을 사용하여 각 장면 비디오의 중간 프레임에서 "가장 눈에 띄는 영역(the most salient region)"을 텍스트 프롬프트로 추출한다.
- 분할 마스크 내의 하나의 Gaussian을 시작으로, 3D 공간에서 K-NN (K-Nearest Neighbor) 알고리즘을 사용하여 미리 설정된 개수 에 도달할 때까지 Gaussian들을 점진적으로 포함시킨다.
- 이점: 이 필터링을 통해 의미적으로 가장 중요한 내용만을 보존하고 노이즈가 많고 덜 중요한 Gaussian들을 제거하여 재구성 품질을 향상시킨다.
4. Experiments
4.1. Implementation Details
-
데이터셋 (Dataset)
- DL3DV-10K 데이터셋의 모든 비디오를 사용하여 3DGS를 생성했다.
- 데이터셋은 6:1 비율로 훈련 세트와 테스트 세트로 분할했다.
- 3DGS 초기화는 COLMAP을 통해 얻은 카메라 위치와 SfM(Structure-from-Motion) 포인트를 사용했다.
- 각 장면 표현에 사용되는 가우시안의 수 은 100K로 제한했다. 이는 가우시안 밀집화(densification) 및 가지치기(pruning) 과정을 통해 이루어졌다.
-
데이터 증강 (Data Augmentation)
- 훈련 데이터의 다양성을 높이기 위해 입력 3DGS 표현에 무작위 SO(3) 회전(random SO(3) rotations)을 적용했다. 이는 2D 이미지의 무작위 회전과 유사한 데이터 증강 기법이다.
-
아키텍처 (Architecture)
- 인코더 (Encoder):
- 1개의 선형 레이어(linear layer), 1개의 교차-어텐션 블록(cross-attention block), 8개의 자체-어텐션 블록(self-attention blocks)으로 구성된다.
- 병목(bottleneck) 지점에서 잠재 공간의 평균 와 로그-분산 으로 매핑하는 2개의 선형 레이어가 뒤따른다.
- 디코더 (Decoder):
- 1개의 선형 레이어, 16개의 자체-어텐션 블록, 그리고 마지막으로 3개의 선형 레이어로 구성된다.
- 어텐션 블록:
- 자체-어텐션(self-attention) 및 교차-어텐션(cross-attention) 블록은 멀티-헤드(multi-head) 방식이며, 각 12개의 헤드(head)와 64차원(dimension)을 갖는다.
- 효율성을 위해 Flash-Attention [11]을 사용하여 구현했다.
- 정규화: 각 선형 레이어와 어텐션 블록 뒤에 레이어 정규화(Layer Normalization)를 적용했다.
- 학습 가능한 정규 쿼리 (Learnable Canonical Query): 크기는 이다.
- 잠재 공간 (): 평균 , 로그-분산 , 그리고 샘플링된 는 크기를 가지며, 이는 Stable Diffusion [54]의 잠재 공간 크기와 동일하다.
- 푸리에 위치 인코딩 (Fourier positional encoding): 3D 가우시안 중심 의 출력 크기는 이며, 이는 을 의미한다.
- 입력 볼륨 해상도 (): 으로 설정된다.
- 손실 하이퍼파라미터 (Loss Hyperparameter): 으로 설정된다.
- 가우시안 수: 의미론적 필터링 후 각 장면은 개의 가우시안을 포함한다.
- 인코더 (Encoder):
-
훈련 환경 및 속도:
- 모델은 8개의 A100 GPU로 5일 동안 훈련되었다.
- 입력 3D 장면을 인코딩하고 디코딩하는 단일 포워드 패스(forward pass)는 약 0.06초가 소요되어, 확산 모듈(diffusion module)과 결합하여 피드포워드 생성(feedforward generation)에 적합하다.
4.2. Baselines and Metrics
-
Baselines
- 다른 연구와 비교하기 위해 사용된 기존 3D 기반 VAE 모델을 의미한다. 본 논문에서는 Can3Tok의 우수성을 입증하기 위해 다음 모델들과 비교하였다.
- L3DG: 3DGS의 객체 수준 인코딩 및 디코딩을 위한 최신 방법이다. 이 모델은 Minkowski Engine 및 spconv를 활용한 컨볼루션 기반 아키텍처로 구현되었다.
- PointNet VAE: PointNet 기반의 autoencoder이다. 모델의 용량을 늘리기 위해 더 많은 네트워크 레이어를 사용하여 구현되었다.
- PointTransformer: 널리 사용되는 트랜스포머 기반 아키텍처이다.
- 이 모든 비교 모델들은 Can3Tok과 동일한 DL3DV-10K 데이터셋의 훈련 및 테스트 세트에서 동일한 데이터 처리 방식으로 훈련 및 테스트되어, 훈련되지 않은 새로운 3DGS 입력에 얼마나 정확하게 일반화되는지 평가되었다.
- 다른 연구와 비교하기 위해 사용된 기존 3D 기반 VAE 모델을 의미한다. 본 논문에서는 Can3Tok의 우수성을 입증하기 위해 다음 모델들과 비교하였다.
-
Metrics
- 모델의 성능을 정량적으로 측정하기 위한 기준이다. 본 논문에서는 두 가지 주요 지표를 사용하여 모델의 재구성 품질과 일반화 능력을 평가하였다.
- L2 error: 재구성된 3DGS와 원본 3DGS 간의 평균 L2 거리이다. 이는 모든 3DGS 특징 채널에 걸쳐 계산되며, 값이 낮을수록 재구성 품질이 우수하다는 것을 의미한다.
- Failure rate: 모델이 입력 3D Gaussians를 완전히 재구성하지 못한 경우의 비율이다. 본 논문에서는 재구성 L2 오류가 1000.0을 초과하여 시각적으로 식별할 수 없는 경우를 '실패'로 정의하였다. 이 값이 낮을수록 모델의 일반화 능력이 뛰어나다는 것을 의미한다.
- 모델의 성능을 정량적으로 측정하기 위한 기준이다. 본 논문에서는 두 가지 주요 지표를 사용하여 모델의 재구성 품질과 일반화 능력을 평가하였다.
-
Can3Tok의 성능: 다른 비교 방법들 PointNet, L3DG, PointTransformer는 학습 과정에서 수백 개의 장면 입력에 대해서도 수렴에 실패하거나, 수렴하더라도 미약한 시각적 품질을 보였다. 특히 이 방법들은 미지의 3D 장면에 대한 일반화 능력이 전혀 없어 100%의 실패율을 기록하였다. 반면, Can3Tok은 낮은 L2 오류와 2.5%의 실패율을 보이며, 대규모 3D 장면 데이터에 대한 재구성 및 일반화 능력에서 우수함을 입증하였다. 이는 Can3Tok이 3DGS의 비정형적이고 스케일 불일치 문제가 있는 데이터를 효과적으로 처리할 수 있음을 나타낸다.
4.3. Latent-Space Analysis
-
공간 인코딩 (Spatial Encoding)
- 이 논문은 t-SNE 시각화를 통해 입력과 잠재 임베딩 간의 공간적 관계를 탐색한다.
- 같은 3DGS 장면에 대해 다양한 SO(3) 회전을 적용한 후, 해당 장면들의 잠재 임베딩을 시각화한다.
- Can3Tok은 명시적인 제약 없이도 입력과 잠재 임베딩 간의 공간적 상관관계를 자동으로 발견한다. t-SNE 시각화(Fig. 7)에서 X, Y, Z축을 중심으로 회전된 동일 장면의 잠재 임베딩이 닫힌 루프(closed loops) 패턴을 형성하는 것을 보여준다.
- 이는 Can3Tok이 3DGS 데이터의 3차원 공간적 특성을 잠재 공간에 효과적으로 인코딩하고 있음을 의미한다. 반면, 다른 기준 모델들은 동일 장면의 다른 3D 방향과 다른 장면들을 잠재 공간에서 서로 혼합하여, 디코더가 올바른 3DGS 표현으로 복원하는 데 실패하는 모습을 보인다.
-
의미 인코딩 (Semantic Encoding)
- Can3Tok의 잠재 표현이 3D Gaussians를 단순히 기억하는 것을 넘어, 입력의 의미론적 정보(semantic information)를 추상화하는 능력을 강조한다.
- 다양한 장면의 3DGS 재구성에서 의미 기반 필터링과 유사하게 무작위로 샘플링된 3DGS를 사용하여 잠재 공간의 t-SNE를 시각화한다(Fig. 8).
- 그 결과, 동일한 장면에서 추출된 잠재 임베딩(예: 같은 야외 의자와 책상이 있는 장면에서 다른 필터링 또는 크롭핑)은 서로 가깝게 위치하며, 다른 장면에서 온 잠재 임베딩과는 멀리 떨어져 있음을 보여준다.
- 이는 Can3Tok이 장면의 핵심적인 의미 내용을 효과적으로 파악하고 잠재 공간에 표현한다는 증거이다. Fig. 7에서도 동일 장면의 다른 SO(3) 회전이 잠재 공간에서 서로 가깝게 위치하는 것은 의미적으로 유사하기 때문이라고 설명한다.
4.4. Ablation Study
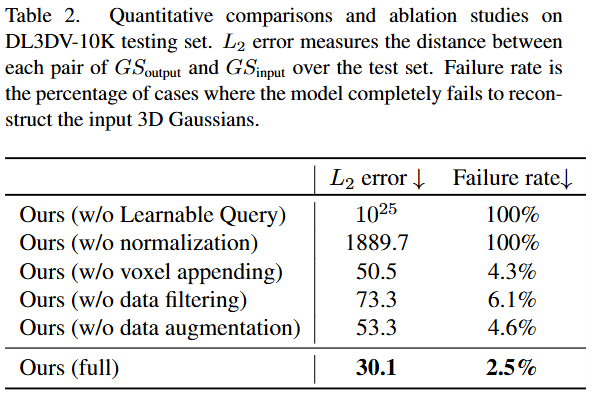
- Ours (w/o Learnable Query): Learnable Canonical Query를 사용하지 않고 cross-attention 블록을 일반 self-attention으로 대체했을 때의 결과이다. L2 error는 로 매우 크고, 실패율은 100%이다. 이는 Learnable Query와 cross-attention 메커니즘이 계산 효율성을 높이고 비정형적인 3DGS 데이터를 구조화된 잠재 공간으로 인코딩하는 데 필수적임을 강력히 시사한다.
- Ours (w/o normalization): 3DGS 데이터에 대한 정규화(normalization) 프로세스를 적용하지 않았을 때의 결과이다. L2 error가 1889.7, 실패율이 100%로 나타났다. 이는 다양한 3D 장면 간의 스케일 불일치(scale inconsistency) 문제를 해결하기 위한 데이터 정규화가 대규모 데이터 훈련과 새로운 장면에 대한 모델의 일반화 능력에 매우 중요하다는 것을 보여준다.
- Ours (w/o voxel appending): 3DGS의 위치와 가장 가까운 복셀(voxel) 중심 좌표를 추가하여 위치 인코딩하는 단계를 제거했을 때의 결과이다. L2 error는 50.5, 실패율은 4.3%이다. 이 모듈의 제거는 다른 주요 모듈 제거만큼 성능에 치명적이지는 않지만, 정밀한 로컬 디테일을 보존하고 재구성 품질을 향상하는 데 기여함을 알 수 있다.
- Ours (w/o data filtering): 노이즈가 많거나 불완전한 3DGS 재구성 결과에서 의미론적 필터링(semantic-aware filtering)을 통해 깨끗하고 의미 있는 영역만 추출하는 과정을 생략했을 때의 결과이다. L2 error는 73.3, 실패율은 6.1%로 증가한다. 이는 훈련 데이터에서 노이즈(floater)를 제거하는 것이 모델이 잠재 공간에서 고주파 디테일을 더 잘 학습하고 재구성 품질을 높이는 데 중요함을 나타낸다.
- Ours (w/o data augmentation): 훈련 중에 임의 SO(3) 회전과 같은 데이터 증강(data augmentation)을 적용하지 않았을 때의 결과이다. L2 error는 53.3, 실패율은 4.6%이다. 데이터 증강은 모델의 견고성(robustness)과 다양한 방향의 장면에 대한 일반화 능력을 향상하는 데 도움이 된다.
- Ours (full): Can3Tok 모델의 모든 제안된 구성 요소를 온전히 적용했을 때의 최종 성능이다. L2 error는 30.1, 실패율은 2.5%로, 모든 절제된(ablated) 버전 중 가장 우수한 성능을 보여준다. 이는 제안된 모든 모듈이 Can3Tok의 탁월한 성능에 기여함을 입증한다.
4.5. Application
-
Text-to-3DGS Generation
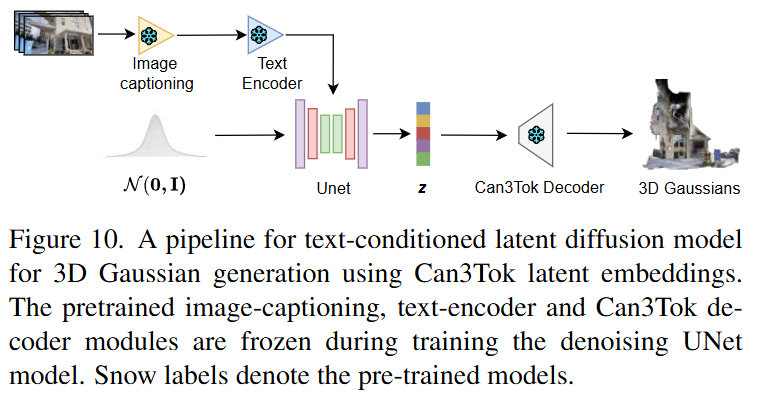
- 훈련 데이터 준비 (Training Data Preparation): 논문에서는 DL3DV-10K 데이터셋에 텍스트 레이블이 없기 때문에, 각 장면 비디오의 중간 프레임에 대해 사전 학습된 BLIP 모델을 사용하여 이미지 캡셔닝을 수행한다. 이 과정을 통해 각 장면에 대한 간결하고 의미 있는 텍스트 프롬프트가 생성된다. (이 단계는 그림에 직접적으로 나타나 있지 않지만, Text Encoder 입력으로 활용됨을 문맥상 알 수 있다.)
- 텍스트 인코더 (Text Encoder): 이미지 캡셔닝을 통해 얻은 텍스트 프롬프트는 텍스트 인코더에 입력된다. 이 인코더는 텍스트 프롬프트를 조건부 정보로 활용할 수 있는 잠재 벡터로 변환한다. 이 텍스트 인코더는 사전 학습된 모델이며, UNet 훈련 중에는 가중치가 고정되어 있다.
- 노이즈 벡터 샘플링 (): UNet은 정규 분포 로부터 무작위 노이즈 벡터를 샘플링하여 3D Gaussian 잠재 임베딩 생성을 시작한다. 여기서 는 평균이 0이고 공분산 행렬이 항등 행렬인 정규 분포를 의미한다. 즉, 각 차원이 독립적인 표준 정규 분포를 따르는 무작위 벡터이다.
- UNet (확산 모델): 샘플링된 노이즈 벡터와 텍스트 인코더의 출력(조건부 텍스트 임베딩)은 UNet 모델에 입력된다. 이 UNet은 확산 과정(denoising diffusion process)을 통해 텍스트 조건에 따라 노이즈를 점진적으로 제거하고, 최종적으로 의미 있는 3D Gaussian 잠재 임베딩 를 생성한다. UNet은 노이즈 제거 단계를 거치면서 잠재 공간 에 접근하도록 훈련된다.
- 잠재 임베딩 (): UNet의 출력은 3D 장면의 의미론적 및 공간적 정보를 효과적으로 포착하는 저차원 잠재 임베딩 이다. 이 는 Can3Tok VAE 인코더가 압축한 원래 3D Gaussians의 잠재 표현과 동일한 구조를 가진다.
- Can3Tok 디코더 (Can3Tok Decoder): UNet에서 생성된 잠재 임베딩 는 사전 학습되고 고정된 Can3Tok 디코더에 입력된다. 이 디코더는 잠재 임베딩 를 원래의 3D Gaussian 파라미터 (위치 , 회전 , 불투명도 , 스케일링 , 색상 , 뷰 의존적 색상 )로 재구성한다.
- 3D Gaussians (3D 가우시안): Can3Tok 디코더의 최종 출력은 텍스트 프롬프트에 해당하는 3D Gaussian Splatting(3DGS) 표현이다. 이는 3D 장면을 구성하는 수많은 Gaussian 프리미티브들의 집합으로, 실시간 렌더링이 가능한 고품질의 3D 장면을 생성한다.
-
Image-to-3DGS Generation
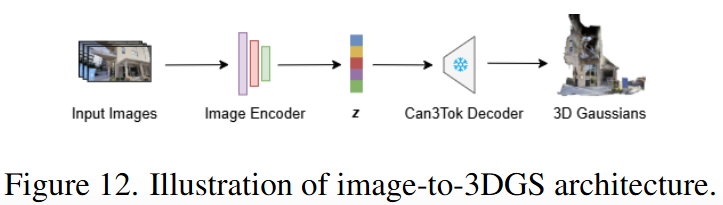
- Input Images: 파이프라인의 시작점은 2D 이미지이다. 이 이미지는 생성하고자 하는 3D 장면의 시각적 정보를 포함한다. 이 예시에서는 건물과 주변 환경을 담은 여러 장의 이미지가 입력으로 사용된다.
- Image Encoder:
- 이 컴포넌트는 입력된 2D 이미지를 처리하여 저차원 잠재 공간 임베딩으로 변환하는 역할을 한다.
- 논문은 이를 위해 Pythae와 같은 기존의 이미지 회귀(image regression) 모듈을 사용한다고 언급하고 있다.
- 이 인코더는 학습 과정에서 2D 이미지를 3DGS 잠재 공간 와 일치하도록 매핑하는 방법을 학습한다.
- 잠재 임베딩 (): Image Encoder의 출력은 잠재 공간 임베딩 이다. 이 는 2D 이미지에 담긴 3D 장면의 핵심적인 정보를 압축적으로 표현한다.
- 이 잠재 임베딩은 Can3Tok의 인코더가 3DGS를 인코딩하여 생성하는 잠재 공간과 동일한 구조를 가진다.
- 훈련 목적은 예측된 잠재 임베딩 와 Can3Tok 인코더를 통해 얻어진 "Ground-Truth 3D Gaussian latents" 사이의 L2 오류를 최소화하는 것이다. 이는 다음 수식으로 표현된다.
- 여기서 는 Image Encoder가 예측한 잠재 임베딩이며, 는 원본 3DGS 데이터를 Can3Tok 인코더에 입력하여 얻은 실제 3D Gaussian 잠재 임베딩이다. 이 손실 함수는 Image Encoder가 2D 이미지를 3DGS의 의미 있는 잠재 표현으로 정확하게 매핑하도록 학습시킨다.
- Can3Tok Decoder:
- Can3Tok 디코더는 학습된 잠재 임베딩 를 입력으로 받아, 이를 원래의 3D Gaussian Splatting (3DGS) 파라미터(위치, 스케일, 회전, 색상, 불투명도 등)로 재구성한다.
- 이 디코더는 Can3Tok 모델의 일부로, 잠재 공간의 정보를 실제 3D 장면 표현으로 변환하는 핵심적인 역할을 한다.
- 3D Gaussians: 파이프라인의 최종 출력은 재구성된 3D Gaussians 세트이다. 이는 입력된 2D 이미지에 해당하는 완전한 3D 장면을 실시간 렌더링 가능한 형태로 표현한다.
