Abstract
word-sentence-paragraph 프레임워크
기능
- 연속된 형태를 '형태 단어'로 분할
- 해당 단어를 '형태 문장'으로 결합
- 형태를 프롬프트와 결합시켜 멀티모달 문단 생성
훈련 방법
형태 정보를 언어 정보와 연관짓는 codebook을 만들기 위한 훈련 시퀀스
1. shape representation
오브젝트의 형태를 모델이 알 수 있게 표현하는 과정
2. multimodal alignment
형태와 언어를 매치시키는 코드북 생성
3. instruction-based generation
사용자의 프롬프트를 바탕으로 모델을 오브젝트를 생성하는 것
1. Introduction
기존 모델의 한계
대규모 코퍼스로 훈련된 LLM이 등장하면서 이들을 다른 형태의 데이터와 통합하는 연구가 많이 진행되었으나, 프롬프트 기반 3D 모델 생성 쪽은 아직 미흡하다.
그러나 해당 분야는 VR, 게이밍, Network-aided design, 3D 프린팅 등 다양한 분야에 활용될 수 있다.
최근에 비전 언어 모델인 CLIP을 활용해서 언어 기반 모델 생성을 선보인 연구가 있으나, 이 또한 언어 혹은 형태 중 하나의 형태로만 변환시키는 로직을 가지고 있다. 즉, 둘의 상보적인 관계를 이해하는데 한계가 있다. 또한 Instruct-GPT 기반 연구는 분절된 텍스트 인풋은 잘 이해하나, 유저가 생성한 문장을 완벽히 이해하지 못하는 고질적인 문제가 있다.
제안된 방법
1. 3D 형상을 연속된 형상 토큰으로 변환
2. 이를 3D 형상 정보를 언어 모델이 이해하도록 설계된 ector quantized variational autoencoder (VQ-VQE)에 통과시킴.
이 때 vision transformer와 visual-language perceiver를 사용.
3. 해당 토큰은 pre-trained 언어모델에 임베딩 됨.
4. 언어 모델은 이 토큰으로부터 문법과 구문, 특히 모델 텍스처와 관련된 정보를 인지함.
5. 이렇게 하여 서로 다른 두 모델이 소통할 수 있는 코드북이 생성된다.
훈련 시퀀스
1. 3D 데이터셋을 이용하여 모델을 생성하거나, 모델을 설명하는 업무를 전체 모델에 훈련
2. 설명과 렌더링 된 이미지, 형상 데이터로 구성된 멀티모달 데이터셋으로 파인튜닝
Contribution
- 멀티모달 입력을 받아 프롬프트를 수행하는 사전훈련 모델인 ShapeGPT를 제안.
- 명령 프롬프트를 통해 결과를 생성하고 피드백을 학습하는 훈련 체계를 도입.
- img-to-3d, txt-to-3d, 3d-to-text 등의 다양한 업무 가능.
VQ-VAE란?
일반 VAE
- 잠재변수 z를 가우시안 분포로 표현해 연속 공간을 탐색.
- 비슷한 분포의 벡터를 매칭시킴.
VQ-VAE
- 코드북 안의 단일, 혹은 복수의 벡터로 잠재변수 z를 양자화 한다.
모델 구조
- 입력값 를 인코더 에 넣어 얻은 압축 벡터
- 인 에 대해
즉, 와 유클리드 거리에서 가장 가까운 토큰 벡터 를 로 선택 - 를 디코더 에 넣어 얻은 값 를 결과로 사용.
손실함수
- 재구성 손실
- 목적: 인코더, 디코더가 입력 를 잘 복원하도록 학습.
- 계산:
- 인코더 가 를 연속 벡터 로 변환
- 코드북에서 선택된 벡터
- 디코더 가 복원
- MSE(Mean Squared Error) 계산
- 그래디언트:
- 를 생성하는 디코더 파라미터와,
- 직·간접적으로 (→ 코드북) 및 (→ 인코더)
에 모두 전파된다.
- 코드북 업데이트 손실
- 목적: 코드북 벡터 를 인코더 출력 쪽으로 이동시켜, 코드북이 데이터 분포를 제대로 커버하도록 함.
- (stop-gradient): 내부 값의 그래디언트 전파를 차단, 즉 는 상수 취급하여 코드북 쪽만 업데이트.
- 그래디언트: 에만 전파되고, 인코더 파라미터에는 영향을 주지 않는다.
- 커밋 손실
- 목적: 인코더 가 입력 벡터를 양자화된 코드북 벡터 쪽으로 이동하도록 강제함.
- : 커밋 손실의 가중치(보통 0.25~0.4)
- : 코드북 쪽 그래디언트를 차단하여 인코더 만 업데이트
- 그래디언트: 의 수정을 통해 인코더 파라미터만 업데이트
그러나 양자화된 벡터 는 미분이 불가능하므로,
- 순전파: 순수한 사용
- 역전파: 를 대신하여 사용
2. Method
2.1 모델 파이프라인
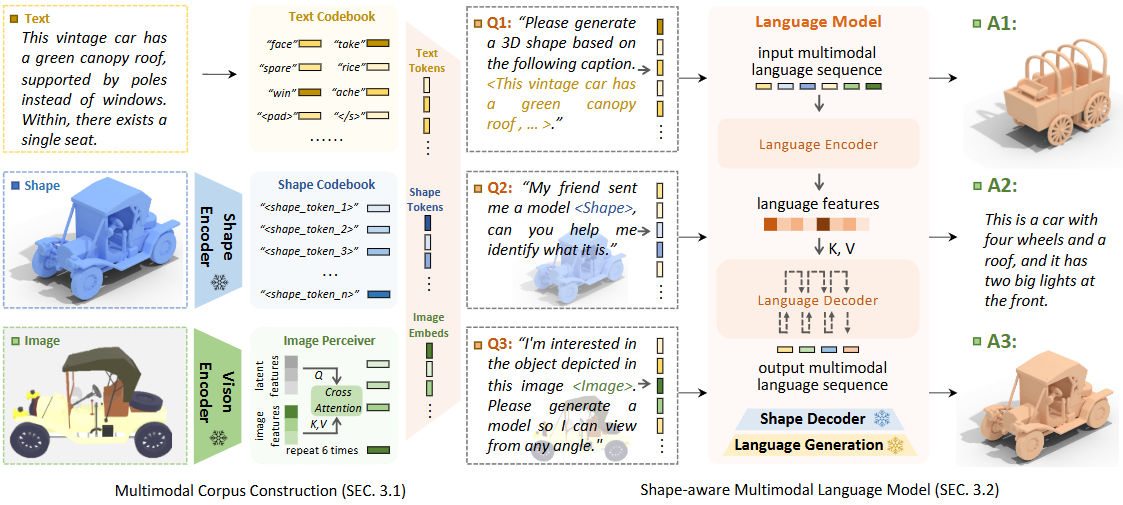

2.2 Multimodal Corpus Construction
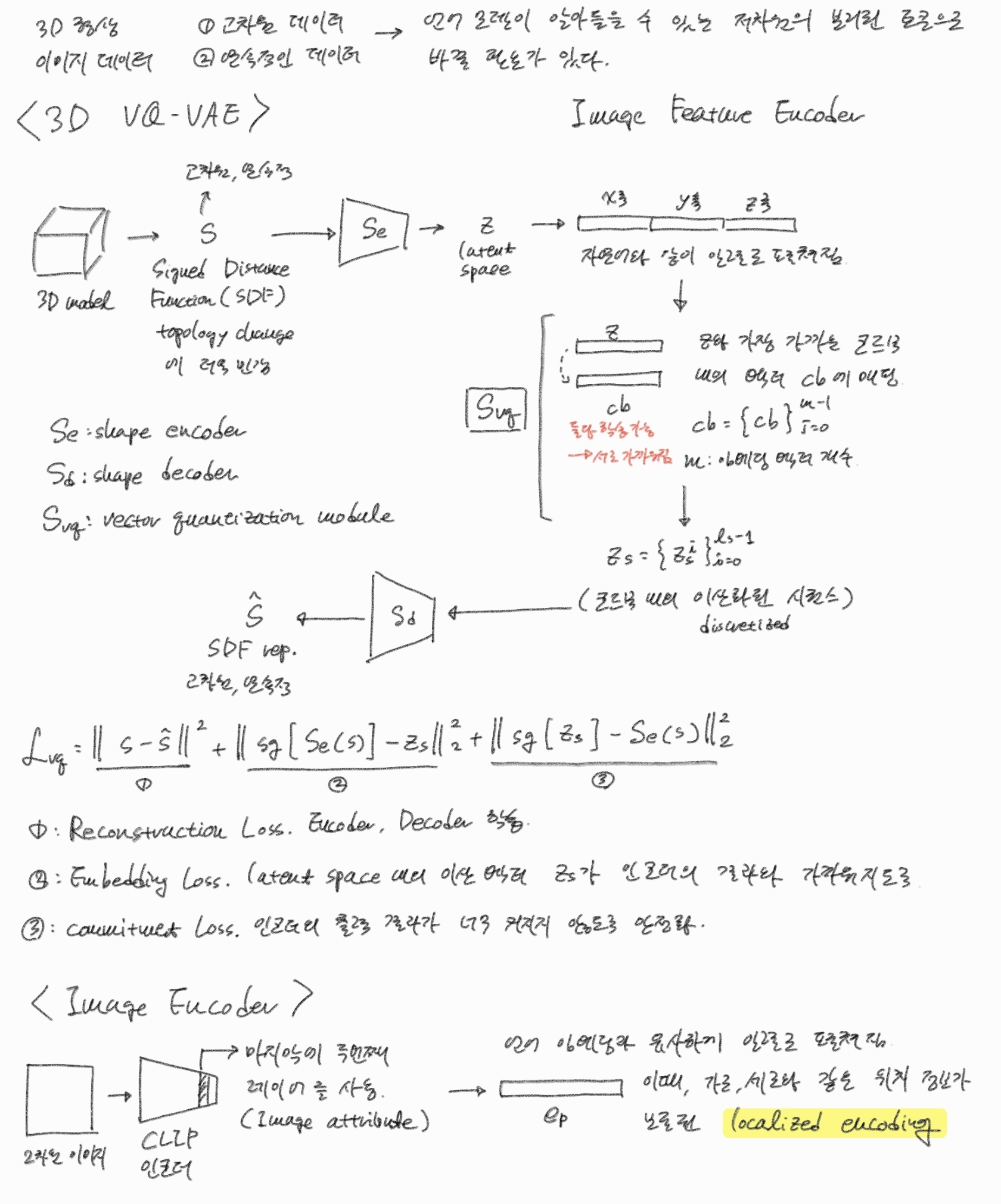
2.3 Shape-aware Multimodal Language Model

2.4 Three-stage training strategy

3. Experiments
3.1 Datasets
| 용어 | 정의 | 특징 |
|---|---|---|
| ShapeNet | 3D CAD 모델 ≈ 51 k개(55개 대분류)로 구성된 대규모 공개 저장소. CAD·로봇·CG 연구의 사실상 표준 벤치마크. (ShapeNet) | ① 다양한 물체(비행기, 의자, …)를 포함해 범주 다양성이 높다. ② 정규화(크기·방향)·WordNet 기반 레이블이 붙어 있어 생성·분류·검색 등 다수의 3D 과제로 쓰인다. |
| Xu split [54] | Xu 등이 제안한 ShapeNet train / test 분할 방식. 약 50 k 모델을 85 % : 15 %로 나눠 후속 연구가 동일 조건에서 비교 가능하도록 만든다. | ShapeGPT도 같은 분할을 채택해 선행 연구와 직접 성능 비교가 가능하도록 함. |
| Text2Shape | ShapeNet ‘chair·table’ 두 클래스에 대해 사람이 작성한 상세 캡션(색상·재질·형태)을 제공하는 최초의 텍스트↔3D 쌍 데이터셋. (Text2Shape: Generating Shapes from Natural Language by ...) | 텍스트-to-Shape 평가에 필수. 자연어만으로 3D 생성 모델이 정밀 형상+재질까지 맞추는지를 측정할 수 있다. |
| MOAT [56] | Mobile cOnvolution & ATtention 하이브리드 비전 백본 (ICLR 2023). 이미지에 태그(단어)를 자동 예측할 때 높은 정확도–효율 균형을 제공. (MOAT: Alternating Mobile Convolution and Attention Brings Strong Vision Models) | 다른 14 개 클래스엔 사람이 쓴 설명이 없으므로, ShapeGPT는 MOAT로 이미지→태그를 생성해 텍스트 주석을 자동 확보한다. |
3.2 Evaluation Metrics
(1) 3D IoU (Intersection over Union)
- 정의 예측 복셀 집합과 정답 복셀 집합이 겹치는 비율.
- 평가: 물체의 전체 외곽 형태가 얼마나 정확히 맞는가.
- 특징
- 0 – 1 범위. 1에 가까울수록 완전 일치.
- 내부 빈 공간·세부 굴곡엔 둔감하므로 “윤곽” 품질을 볼 때 적합.
(2) Chamfer Distance (CD)
-
정의
두 포인트 클라우드가 서로에게 얼마나 가까운지를 양방향으로 평균한 거리.
-
평기: 곡면, 홈, 모서리 등 세밀한 기하차를 파악할 수 있음.
-
특징
- 낮을수록 좋으며 0이면 완전히 일치.
- 거리나 거리² 버전을 모두 사용하므로 논문마다 명시 필요.
(3) F-score @ 1 %
-
절차
-
물체 대각선 길이의 1 %를 반경 로 설정.
-
예측·정답 점 쌍 거리가 이하이면 TP(True Positive)로 간주.
-
계산 후 로 조화 평균.
-
-
평가: 점 단위로 봤을 때 정밀도와 재현율을 동시에 고려한 정합도.
-
특징
- 작은 세부 구조까지 “잘 맞춘” 점이 많은지 확인.
- 임계 반경(1 %)은 ShapeNet·Pix3D 등에서 사실상 표준.
(4) ULIP Score
-
정의
ULIP(Unified Language-Image-Point cloud) 모델 임베딩에서텍스트 캡션에 대한 임베딩 벡터와 3D Shape 임베딩 벡터 간 코사인 유사도.
-
평가: 생성된 Shape가 의미적으로 설명과 얼마나 일치하는지.
-
특징
- 값이 클수록 의미 일치성이 높음.
- 텍스트를 조건으로 하는 다른 도메인의 생성 품질을 다룰 때 핵심 지표.
(5) CLIP Score (Caption Generation)
- 정의
사전 학습된 CLIP 텍스트 인코더에서생성된 캡션 임베딩과 정답에 해당하는 캡션 임베딩에 대한 코사인 유사도. - 무엇을 재나? Shape-to-Text 작업에서 언어적 일치성.
- 특징
- CLIP이 갖는 시각·언어 공통 공간 덕분에 사람이 느끼는 “맞는 설명”과 상관이 높다.
3.3 정량평가
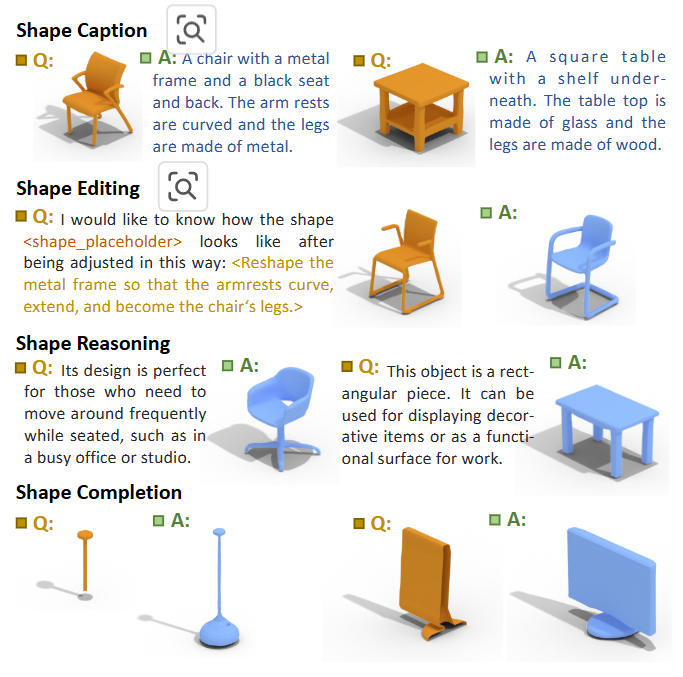
다른 모델과 비교했을 때 더욱 정확한 모습을 생성하였다.
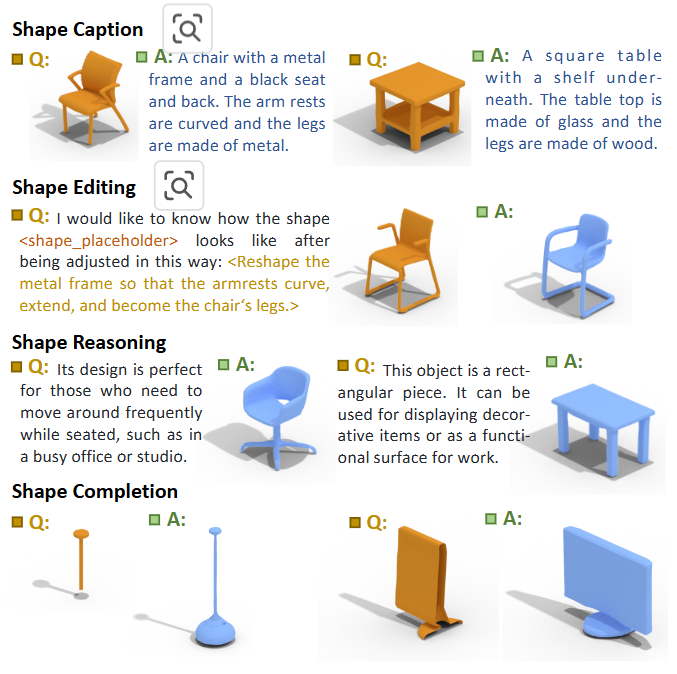
또한 위와 같이 추가적인 태스크로 확장할 수도 있었다.
