PoseScript는 2024년 IEEE/CVF 컴퓨터 비전 및 패턴 인식 회의(CVPR 2024)에 게재된 연구로, 자연어와 3D 인간 자세 데이터를 연결하는 대규모 주석 데이터셋을 제안하며, 다양한 자연어 표현을 기반으로 3D 자세를 이해하고 생성할 수 있도록 학습된 모델을 소개한다. 이 연구는 언어와 자세 간의 깊은 상호작용을 모델링할 수 있는 프레임워크를 제공하며, 기존의 단순한 자세 인식 및 추론을 넘어, 자연어를 통한 복합적인 인간 행동 이해에 기여하고 있다.
- 게재 학회: CVPR 2024
- arXiv 링크: https://arxiv.org/abs/2311.18836
- 프로젝트 페이지: https://yfeng95.github.io/ChatPose
1. Introduction
1.1 PoseScript dataset 구축
-
PoseScript Dataset: AMASS의 6000개 이상의 3D human pose를 인간의 주석과 짝지음.
-
이를 바탕으로 몇 분 안에 수천개의 캡션을 달 수 있는 주석 파이프라인을 소개.
-
데이터 생성 파이프라인
- posebits 데이터셋을 더 세부적인 범주로 나누어 저수준 정보 (posecode)를 얻음.
- BABEL 데이터셋의 텍스트 레이블과 posecode의 조합에서 나오는 고수준 개념을 기반으로 구축.
- 언어적 원칙을 사용하여 posecode를 선택하고 집계하는 규칙 정의 후 이를 문장으로 변환하여 텍스트 설명을 생성
- 이렇게 자동화 하여 100,000개의 포즈를 준비.
1.2 아래 태스크를 수행하는 모델 구축
-
Text to Pose Retrieval: 텍스트 쿼리와 가장 유사한 3D 포즈를 데이터베이스에서 검색.
-
Text-conditioned Pose Generation: 텍스트 정보를 바탕으로 3D 포즈 생성.
-
Pose Description Generation: 3D 포즈에 대한 텍스트 묘사.
2. 관련 연구
-
Text for humans in images
- 기존의 연구들도 텍스트 정보를 통해 SMPL 파라미터를 생성하는 시도가 있었다. 그러나 MS Coco의 불충분한 캡션만을 사용하였다.
- 다른 연구는 물체와의 상호작용에 대해 다루었으나, 우리는 개인의 포즈에만 집중한다.
-
Text for human motion
- 몇몇 연구들이 동적인 자세에 대해 연구한 반면, 우리는 정적인 자세에 대해 연구한다.
-
Pose Semantic representation
- 인간의 포즈를 세밀하게 묘사하기 위해 각종 파라미터를 도입한 poselets, posebits, deepfashion 등의 방법이 도입되었다.
- 저자들은 posecode라는 개념을 통해 좀 더 명확한 3D 포즈를 생성할 수 있도록 한다.
-
기존 연구와의 차별성
- 동적인 자세 연구보다 정적인 하나의 포즈에 집중
- 하나의 포즈가 아닌 다양한 포즈에 적용 가능
- 단순한 명사 태그가 아닌 자세한 자세 설명을 제공
3. PoseScript dataset
- 정적인 3D 인체 포즈와 세분화된 의미론적 주석으로 구성.
- PoseScript-H: 사람이 직접 작성한 주석
- PoseScript-A: 위 데이터를 바탕으로 자동 생성된 캡션
3.1 Pose Selection
AMASS 시퀀스
-
100,000개 샘플링
-
T-자세를 제거하기 위해 처음과 마지막의 25 프레임은 샘플링 안 함
-
중복된 자세를 피하기 위해 25 프레임에 하나씩 선별
-
변화를 극대화 하기 위해 farthest-point sampling을 사용
- 포즈 정규화: 뉴트럴 모델을 기준으로 각 관절의 위치를 정규화
- 초기 포즈 선택: 모든 포즈 중 하나를 임의로 선택하여 첫 번째 원소로 할당
- 가장 먼 포즈 추가: MPJE(mean per-joint error)의 값이 가장 높은 포즈를 찾아 추가
- 이 과정을 100,000개가 될 때까지 반복
3.2 Dataset collection
3.2.1 Annotation interface

-
Amazon Mechanical Turk2라는 크라우드 소스 주석 플랫폼을 사용하여 추출한 이미지에 대한 캡션을 작성
-
1단계: 방향과 신체 부위간의 인터렉션, 일반적인 포즈 및 비유를 사용하여 설명 작성.
-
2단계: 해당 포즈를 비슷한 회색의 다른 포즈를과 함께 보여준 뒤, 이들간의 차별성을 부여할 수 있도록 좀 더 자세하게 설명 작성.
3.2.2 Pose dicriminator
- 푸른색 포즈와 대비되는 회색 포즈를 선택하는 알고리즘
- 포즈 임베딩 거리가 가까워 유사한 포즈를 띄어야 함.
- 또한 15개 정도만의 다른 포즈 카테고리를 가지고 있어 유사한 모습을 띄어야 함.
3.2.3 Annotators
- 영어권 국가 거주자들이 1000개에 가까운 주석을 수동으로 제작.
- 철자 오류와 문법 오류가 없는 사람들을 추가로 41명 뽑아 다시 검토.
3.2.4 Automatic captioning pipeline
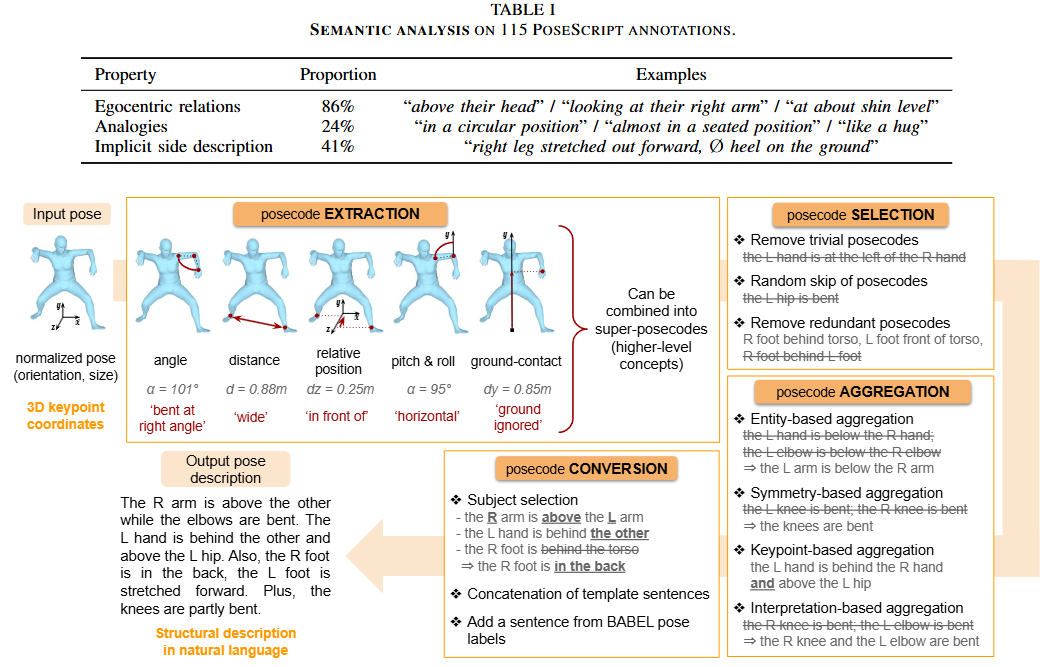
-
캡셔닝을 자동화 하기 위해 popsecode의 추출, 선택 및 집계를 기반으로 진행.
-
입력 정보: 3D keypoint 좌표(shape 계수는 디폴트로 두고, 글로벌 오리엔테이션은 y축으로 정규화 된 SMPL-H 모델에서 추출)
3.2.5 Posecode extraction
이는 관절들 사이의 관계를 아래 5가지로 나누어 기록한다.
-
Angle posecode: 관절이 얼마나 구부러지는지를 아래 6개 중 하나로 선택.
- 'straight'
- ‘slightly bent’
- ‘partially bent’
- ‘bent at right angle’
- ‘almost completely bent’
- ‘completely bent’
-
Distance posecode: 두 키포인트 사이의 L2-distance를 아래 중 선택. (예: 두 손)
- 'close'
- ‘shoulder width apart’
- ‘spread’
-
Posecodes on relative position: X, Y, Z 축을 따라 두 키포인트 사이의 좌표값 차이를 계산
-
X축의 경우: 'at the right of', 'x-ignored', 'at the left of'
-
y축의 경우: 'below', 'y-ignored', 'above'
-
z축의 경우: 'behind', 'z-ignored', 'in front of'
-
이러한 지표는 관절의 교차 등을 파악할 때 쓰인다. 예를 들어 양 손의 X 좌표값을 비교했을 때, 왼손이 'at the right of'라면 이는 두 손이 교차되어있음을 나타낸다.
-
'ignored' 태그는 설명하기 어려운 모호한 구성에 태그된다.
-
-
Pitch & roll posecodes: 두 키포인트로 정의된 신체 부위(예를 들어, 왼쪽 허벅지는 왼쪽 무릎 키포인트와 엉덩이 키포인트 두 개로 정의됨)이 수직인지, 수평인지 평가한다.
- 'vertical': y-hyperplace에 거의 직교
- 'horizontal': y-hyperplace에 거의 수평
- 'pitch-roll-ignored': 애매한 경우
-
Ground-contact posecodes: 중간 컴퓨팅 과정에서만 사용되며, 해당 키포인트가 땅과 맞닿아 있는지 의미한다.
- 'on the ground': 가장 아래에 있는 키포인트의 수직 거리가 가깝다면.
- 'ground-ignored': 그렇지 않다면.
레이블링의 문제점 및 해결방안
- 관절이 얼마나 구부러졌는지에 대한 임계값을 기반으로 어노테이션 진행.
- 예를 들어 팔이 20도보다 적게 구부러져있다면 'slightly bent' 태깅.
- 그러나 포즈들이 워낙 다양하므로 경계를 모호히 만들기 위해 노이즈를 더한 각도로 태깅.
- 즉, 실제로는 15도 기울어져있으나, 노이즈 값을 더한 25도를 기준으로 ‘partially bent’ 태깅
상위 개념의 포즈 코드 도입
- 하나의 조인트에 대한 정보를 담고 있는 포즈 코드로는 의미론적인 포즈를 표현하기 어려움.
- 다리 관절에 'on the ground'와 'completely bent' 두 가지 정보를 포함하여 'kneeling'이라는 의미론적인 상위 포즈 코드를 생성하여 이진수로 추가 표현함.
3.2.6 Posecode selection
- 사소한 설명 삭제 (왼손은 오른손보다 왼쪽에 있다.)
- 전체 포즈에 대한 통계를 기반으로, 사소하진 않지만, 결정적으로 중요하지도 않은 정보는 스킵.
- 정말 중요하고 차별적이지 않은 코드는 스킵하지 못하도록 함.
- 비슷한 포즈 코드를 두 쌍, 혹은 세 쌍으로 짝지은 다음, 불필요한 포즈 코드는 삭제.
3.2.7 Posecode aggregation
포즈의 의미적인 정보를 공유하는 포즈 코드들을 병합하는 과정.
네 가지 병합 규칙이 적용됨.
- Entity-based aggregation
손이나 발보다 더 큰 개체인 팔이나 다리의 키포인트를 설명하면서 유사한 포즈 코드를 병합.
- 왼손이 오른손보다 아래에 있다.
- 왼쪽 팔꿈치가 오른손보다 아래에 있다.
- 병합: 왼팔이 오른 손보다 아래에 있다.
- Symmetry-based aggregation
같은 신체 부위에 속하고 좌, 우 측면만 다른 경우 이들을 통합.
- 왼쪽 팔꿈치가 굽혀있다.
- 오른쪽 팔꿈치가 굽혀있다.
- 병합: 양 팔꿈치가 굽혀있다.
- Keypoint-based aggregation
하나의 신체 부위에 대한 병렬적인 정보를 하나로 통합. 이 때 it, they 등의 지시대명사가 사용됨.
- 왼쪽 팔꿈치가 오른쪽 팔꿈치보다 위에 있다.
- 왼쪽 팔꿈치가 오른쪽 어깨와 가깝다.
- 왼쪽 팔꿈치가 굽어있다.
- 병합: 왼쪽 팔꿈치는 오른쪽 팔꿈치보다 굽어있고, 오른쪽 어깨와 가깝다. 또한 이것은 굽어있다.'
- Interpretation-based aggregation
다른 신체 부위지만 동일한 포즈를 하고 있는 것을 하나로 통합.
- 왼쪽 무릎이 굽혀있다.
- 오른쪽 팔꿈치가 굽혀있다.
- 병합: 왼쪽 무릎과 오른쪽 팔꿈치가 굽혀있다.
병합 옵션은 우선순위 없이 무작위로 여러 개가 적용될 수 있다.
3.2.8 Posecode conversion into sentences
1. 대칭적인 부위
- 팔, 다리 등의 대칭 부위는 왼쪽이나 오늘쪽 중 하나가 먼저 무작위로 선택 됨.
- 나머지 한쪽 팔은 '다른 쪽 팔' 등의 지칭대명사를 통해 표현됨.
2. 비대칭적인 부위
- 주요 키포인트와 보조 키포인트를 추출. ('왼손이 머리 위로 올라감'이란 문장에서 '머리'가 주요 키포인트가 되고, '왼손'은 보조 키포인트가 됨)
- 문장의 흐름을 위해 주요 키포인트가 생략되기도 힘. (왼손이 위로 올라감.)
3. 개별 posecode에 대한 설명 생성
- 이전 단계에서 추출된 각 posecode 데이터에 대해 해당 posecode 범주에 맞는 미리 정의된 여러 문장 템플릿 중 하나를 무작위로 선택.
- 예를 들어, "왼손이 머리 위에 있다"는 정보를 담은 posecode가 있다면, "The {body_part} is {position}"과 같은 템플릿이 선택되어 "The left hand is raised above the head"라는 개별 설명 조각이 만들어짐.
- 다른 예로, "사람이 서 있다"는 posecode는 "The person is {action}" 템플릿과 결합하여 "The person is standing"이 될 수 있음.
4. 개별 설명을 문장으로 조합
- 이렇게 생성된 여러 개의 개별 설명 조각들을 모아 무작위 순서로 배열.
- 조각들 사이에 미리 정의된 연결어구(transitions)를 무작위로 사용하여 자연스러운 문장을 만듦.
- 예를 들어, 앞서 만든 "The left hand is raised above the head"와 "The person is standing" 설명 조각을 "," 연결어구를 사용하여 "The left hand is raised above the head, the person is standing"처럼 연결할 수 있습니다. 또는 다른 연결어구를 사용하여 "The left hand is raised above the head. Also, the person is standing"처럼 연결할 수도 있음.
5. 고수준 개념의 문장 추가
BABEL 데이터셋에서 추출한 데이터라면, 이에 대한 고수준의 개념 캡션이 존재하므로, 이 문장을 최종 설명으로 추가. "the person is in a yoga pose"
- PoseScript-H: 6,283개의 직접 어노테이션을 생성
- PoseScript-A: 자동화 파이프라인을 통해 100,000개의 포즈에 대한 3개의 캡션을 10분 이내에 생성.
- train : valid : test = 7 : 1 : 2
4. Text-to-Pose Retrieval
텍스트 쿼리를 바탕으로 비슷한 포즈를 검색해 순위화하는 태스크.
텍스트 정보와 3D 포즈 정보를 공유 잠재 공간으로 매핑하는 과정이 필요.
4.1 Encoders
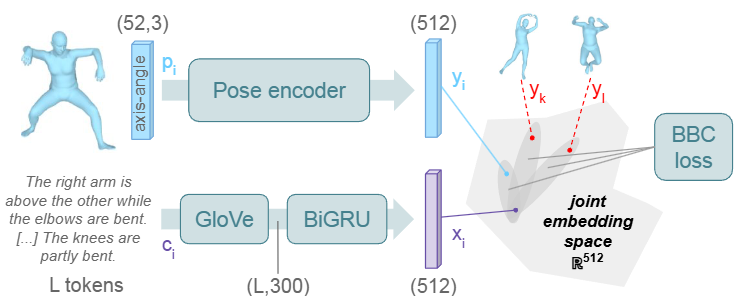
-
: 캡션
-
: 포즈
SMPL-H body joints의 회전으로 구성된 (52, 3) 크기의 행렬. -
: 텍스트 인코더
-
: 포즈 인코더
-
: 캡션에 대한 텍스트 인코더 아웃풋
가 토큰화된 다음 GloVe word embeddings 상의 bi-GRU 또는 frozen pretrained DistilBERT word embeddings 상의 transformer를 사용하여 임베딩 됨. -
: 포즈에 대한 포즈 디코더 아웃풋
가 일렬로 펼쳐진 뒤 VPoser encoder로 선택된 포즈 인코더에 입력. 이후 ReLU와 최종 MLP를 통해 이를 텍스트 인코딩과 같은 차원의 벡터로 프로젝션.
4.2 Problem formulation
- : 캡션과 포즈 쌍의 집합.
- : 유사성 함수로, 의 결과를 통해 와 의 유사성이 차등을 둘 수 있도록 학습.
4.3 오차 함수
B개의 훈련 쌍 의 배치가 주어지면, Batch-Based Classification (BBC) loss를 사용
- : 학습 가능한 민감도 파라미터. 민감도 파라미터가 크면 정답과 오답 사이의 경계가 명확해짐.
이 값을 학습 가능하게 두면 모델이 최적점을 찾아 수렴. - : 코사인 유사도 함수
- : 각 코사인 유사도에 대한 소프트맥스
- : 크로스 앤트로피 손실
4.4 평가 지표
-
recall@K (R@K): 주어진 쿼리 텍스트에 대해 모델이 검색한 결과 중 상위 K개 안에 정답 포즈가 포함될 확률을 의미. 논문에서는 K = 1, 5, 10 일 때를 실험. -
K=5일 때
recall@5의 예시:- 텍스트 쿼리: "오른팔을 들고 있는 사람"
- PoseScript 모델은 수만 개의 3D 포즈 데이터베이스를 검색하여 이 텍스트와 가장 관련이 높다고 판단되는 포즈들을 순서대로 나열.
recall@5는 전체 검색 쿼리들 중에서, 각 텍스트에 해당하는 실제 정답 3D 포즈가 모델이 검색하여 보여준 상위 5개의 결과 안에 포함된 쿼리의 비율을 계산- 예를 들어, 총 100개의 텍스트 쿼리로 검색을 수행했는데, 이 중 70개의 쿼리에서 정답 포즈가 상위 5위 안에 있었다면,
recall@5는 70% (0.7).
-
mean recall (mRecall):recall@K값을 여러 K 값(논문에서는 K=1, 5, 10)에 대해 계산한 후,Text-to-Pose Retrieval과pose-to-text retrieval양방향의 결과를 모두 평균하여 최종 성능 지표로 나타낸 값.
정리
recall@K: 검색 시스템이 얼마나 정확하게 정답을 찾아서 사용자에게 보여주는지를 나타내는 지표.mean recall: 다양한 K값과 양방향 검색 성능을 종합적으로 보여주는 평가 지표.
4.5 실험 결과
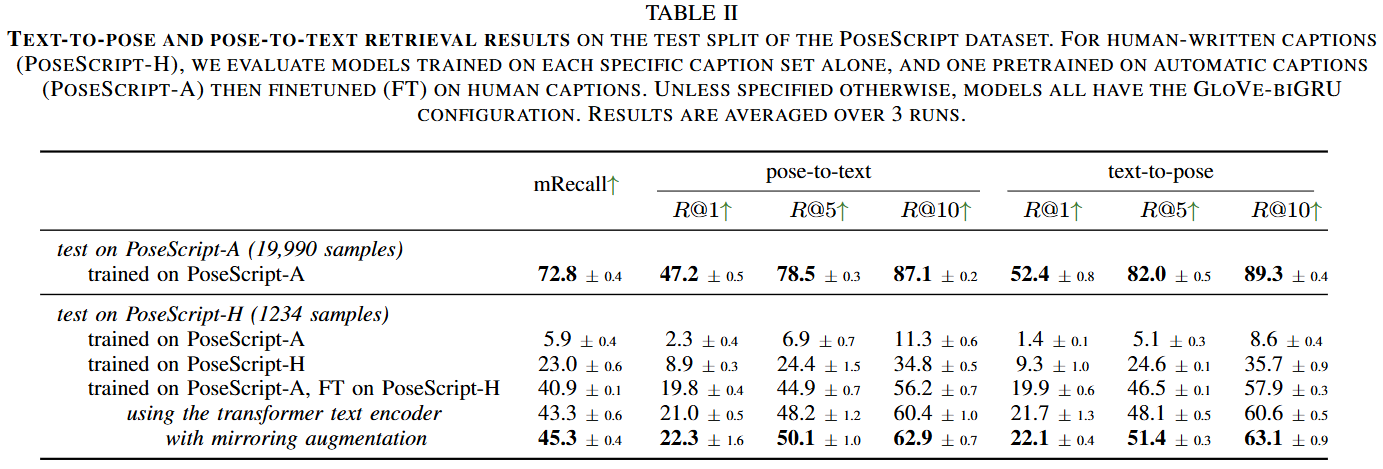
- 실험 결과 R@1은 50%에 가깝고 R@10은 80%가 넘었음.
- 그러나 인간이 직접 쓴 스크립트에서는 결과가 낮게 나왔다. 이는 파이프라인이 생성한 데이터가 인간의 풍부한 어휘를 포함하지 못했기 때문이다.
- 따라서 파이프라인으로 모델을 훈련하고, 인간 어노테이션으로 파인튜닝 하자 더 높은 성과가 나왔다.
5. TEXT-CONDITIONED POSE GENERATION
5.1 훈련
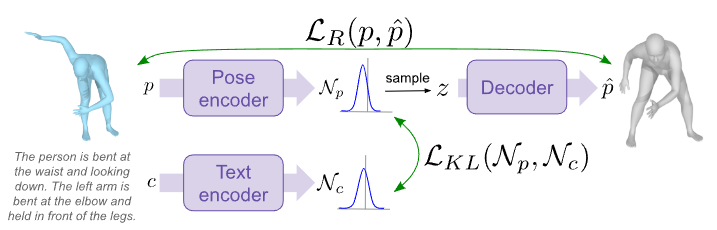
-
: 캡션
-
: 정답 포즈
-
: 생성된 포즈
-
자세 인코더:
를 받아 잠재 공간상의 확률 분포인 '사후 분포' 를 생성.
는 정규분포 의 평균 와 분산 을 계산.
모델 학습시 에서 에 대한 정보가 압축된 잠재 변수 를 샘플링. -
디코더:
잠재 변수 를 받아서 원래 자세 를 복원하려고 시도.
그 결과로 재구성된 자세 를 출력 -
텍스트 인코더:
를 받아 잠재 공간상의 확률 분포인 '사전 분포' 를 생성.
5.2 오차함수
5.2.1 Reconstruction term:
입력 자세 와 디코더가 생성한 재구성된 자세 가 얼마나 비슷한지를 측정
-
Reconstruction Loss의 구성:
- 각 관절의 회전 행렬(rotation matrices)에 대한 손실
- 각 관절의 위치(position of the joints)에 대한 손실
- 몸체 표면을 구성하는 정점(vertex)의 위치에 대한 손실
-
각 요소의 평가 방법:
-
회전 행렬: 회전 행렬 간의 복원 손실은 예측값과 실제값 간의 제곱 오차(squared error)를 최소화하는 L2 손실에 해당.
-
관절 및 정점 위치: 관절과 정점 위치 간의 복원 손실은 예측값과 실제값 간의 절대 오차(absolute error)를 최소화하는 L1 손실에 해당.
-
-
관절의 회전 행렬을 6D 표현으로 변환하는 이유:
- 모델은 각 관절의 회전을 연속적인 6D 표현 (continuous 6D representation) 으로 출력.
- 6D 표현은 오일러 각(Euler angles)이나 쿼터니언(quaternions)과 같은 다른 회전 표현보다 연속적이며, 이는 신경망이 학습하기에 더 적합하기 때문.
- 하지만 손실 함수는 6D 표현이 아닌 회전 행렬을 사용하여 정의. 이는 모델이 출력한 6D 표현이 손실을 계산하기 전에 회전 행렬로 다시 변환됨을 의미.
5.2.2 Regularization term:
자세 인코더가 만든 사후 분포 와 텍스트 인코더가 만든 사전 분포 간의 차이를 측정
- 이 항은 포즈 인코더에서 나온 잠재 변수의 사후 분포 와 텍스트 인코더에서 나온 사전 분포 간의 쿨백-라이블러 발산(Kullback-Leibler divergence) 값이다.
쿨백-라이블러 발산은 두 확률 분포 간의 차이를 측정하며, 이 값을 최소화함으로써 모델은 주어진 텍스트 설명 c에 해당하는 포즈 p의 잠재 공간 분포 가 텍스트만으로 정의된 잠재 공간 분포 와 유사해지도록 학습된다.
이는 텍스트와 포즈 임베딩이 공유된 잠재 공간에서 잘 정렬되도록 돕는 역할을 한다.
5.2.3 부가적인 정규화 항:
논문에서는 라는 부가적인 정규화 항도 함께 실험한다.
- 여기서 는 평균이 0이고 공분산이 단위 행렬인 표준 가우시안 분포를 나타낸다.
- 항: 이 항은 사후 분포 가 표준 가우시안 분포에 가까워지도록 유도한다.
이는 VAE에서 흔히 사용되는 정규화 기법으로, 잠재 공간이 잘 구조화되고 인코더가 붕괴되는 것을 방지하는 역할을 한다. - 항: 이 항은 텍스트에 의해 조건화된 사전 분포 또한 표준 가우시안 분포에 가까워지도록 유도한다.
이는 또 다른 형태의 정규화 역할을 하며, 표준 가우시안 분포에서 샘플링하여 텍스트 조건 없이 일반적인 포즈를 생성할 수 있게 해주는 편리함을 제공한다.
5.3 평가 지표
-
FID (Fréchet Inception Distance): 실제 테스트 포즈와 테스트 캡션에서 생성된 포즈의 특징 분포를 비교하여 샘플의 품질을 평가하는 지표입니다. 여기서 특징은 검색 모델(Section IV 참고)을 사용하여 추출됩니다. 점수가 낮을수록 생성된 샘플이 실제 샘플과 유사하여 품질이 좋다고 판단할 수 있습니다.
-
mRecall R/G (mean-recall Real/Generated): 실제 포즈로 학습된 검색 모델을 사용하여 생성된 포즈를 평가할 때의 평균 재현율(mean recall)입니다. 생성된 포즈가 실제 포즈의 특징 분포를 얼마나 잘 반영하는지를 나타내며, 점수가 높을수록 생성된 샘플이 실제와 유사하다고 볼 수 있습니다.
-
mRecall G/R (mean-recall Generated/Real): 생성된 포즈로 학습된 검색 모델을 사용하여 실제 포즈를 평가할 때의 평균 재현율입니다. 이 지표는 생성된 샘플의 품질뿐만 아니라 생성 모델이 실제 데이터의 다양성을 얼마나 잘 포착하는지 평가하는 데 사용됩니다. 점수가 높을수록 생성 모델이 실제 데이터의 다양성을 잘 표현한다고 볼 수 있습니다.
-
ELBO (Evidence Lower Bound): 생성 모델의 학습 목표와 관련된 지표로, 관절, 정점 또는 회전 행렬에 대해 계산됩니다. VAE 기반 모델의 성능을 나타내는 지표 중 하나입니다. 이 값이 높을수록 모델이 데이터를 잘 모델링한다고 볼 수 있습니다.
5.4 실험 결과
-
자동 생성 캡션 데이터셋(PoseScript-A)으로 사전 학습하는 것이 사람이 작성한 캡션 데이터셋(PoseScript-H)으로만 학습하는 것에 비해 성능 향상에 크게 기여하는 것으로 나타남.
-
사람이 작성한 캡션(PoseScript-H)으로 평가했을 때, 사전 학습 없이 학습한 모델의 mRecall은 5.2%인 반면, 자동 생성 캡션으로 사전 학습한 후 파인튜닝한 모델의 mRecall은 19.5%로 크게 개선됨.
-
텍스트 인코더를 Transformer 기반으로 변경하고 미러링 증강 기법을 적용했을 때 mRecall 성능이 37.5%까지 향상되었으며, FID 지표 또한 사전 학습을 통해 0.29에서 0.04로 크게 개선됨.
-
미러링 증강 (mirroring augmentation) 기법은 데이터 양을 늘리고 모델의 일반화 성능을 향상시키기 위한 데이터 증강 방법 중 하나. 텍스트에서 왼쪽/오른쪽 방향을 바꾸고, 해당 포즈도 좌우 반전시키는 방식으로 미러링 증강을 적용. 예를 들어, "오른팔을 올렸다"는 텍스트는 "왼팔을 올렸다"로 바꾸고, 그에 맞는 포즈 이미지도 좌우를 반전시키는 것.
- 이를 통해 모델은 좌우 방향에 관계없이 포즈 특징과 텍스트 설명을 연관시키는 능력을 학습하게 되며, 데이터 부족 문제를 완화하고 모델의 강건성을 높일 수 있음. 이 논문의 실험 결과에서 미러링 증강이 검색 및 생성 작업에서 성능을 약간 향상시키는 데 도움이 되었음을 보여줌.
6. APPLICATION TO POSE DESCRIPTION GENERATION
6.1 학습 과정
-
주어진 3D 포즈에 대한 자연어 설명을 생성하는 것이므로, 이를 위해 모델은 자동 회귀(auto-regressive) 방식으로 학습됨. 자동 회귀 모델은 이전까지 생성된 단어 시퀀스와 주어진 포즈 정보를 바탕으로 다음 단어를 예측하도록 학습.
-
입력: 모델은 캡션의 토큰 시퀀스()와 해당 포즈를 입력으로 받습니다. 여기서 은 캡션의 총 단어(토큰) 수입니다.
-
토큰 임베딩 및 위치 인코딩: 캡션의 각 토큰은 임베딩 벡터로 변환되며 포지셔널 인코딩 정보가 더해집니다.
-
트랜스포머 모델: 임베딩된 토큰 시퀀스는 트랜스포머 모델에 입력됩니다.
-
마스크드 크로스 어텐션: 트랜스포머 내부의 크로스 어텐션(cross-attention) 메커니즘을 통해 입력 포즈 정보가 캡션 정보와 결합됩니다. 이는 모델이 포즈를 참고하여 설명을 생성하도록 돕습니다. 이 때, 마스킹 정보는 모델이 현재 토큰 을 처리할 때 미래의 토큰들 부터 까지를 보지 못하도록 차단합니다. 이는 모델이 마치 사람이 문장을 쓰듯 순차적으로 다음 단어를 예측하는 방식을 모방합니다.
-
출력: 모델은 어휘 집합 전체에 대한 확률 분포 을 출력합니다. 여기서 은 이전 토큰 이 주어졌을 때 다음 토큰에 대한 확률 을 나타냅니다.
-
손실 함수: 모델은 교차 엔트로피 손실을 사용하여 학습됩니다. 이는 예측된 다음 토큰 확률 분포()와 실제 다음 토큰 시퀀스(, 목표 시퀀스) 간의 오차를 최소화하는 방식입니다. 즉, 을 최대화하여 모델이 이전 단어들로부터 다음 단어를 정확하게 예측하도록 학습합니다.
6.2 추론 과정
-
학습된 모델은 주어진 포즈에 대한 새로운 설명을 생성하는 데 사용됩니다.
-
입력: 문장의 시작을 알리는 BOS(Beginning-Of-Sequence) 토큰과 입력 포즈를 모델에 제공합니다.
-
자동 회귀 디코딩: 설명은 단어 하나씩 순차적으로 생성됩니다.
-
탐욕적 방식(Greedy Fashion): 각 단계 에서 모델이 출력하는 어휘 집합에 대한 확률 분포 중 확률이 가장 높은 토큰을 다음 단어로 선택합니다.
-
선택된 토큰은 이전에 생성된 토큰 시퀀스에 추가됩니다.
-
새롭게 확장된 토큰 시퀀스는 다음 단어()를 예측하기 위한 입력으로 다시 사용됩니다.
-
이 과정은 문장의 끝을 알리는 특별 토큰인 EOS(End-Of-Sequence) 토큰이 생성될 때까지 반복됩니다.
6.3 예시
예를 들어, "The person is standing"이라는 설명을 생성한다고 가정해 봅시다.
-
학습 시:
- 모델은 포즈와 캡션 "BOS The person is standing EOS"을 입력으로 받습니다.
- 인과적 마스크 때문에, 모델은 "The"를 예측할 때는 포즈와 "BOS"만 볼 수 있습니다.
- "person"을 예측할 때는 포즈와 "BOS The"를 볼 수 있습니다.
- "is"를 예측할 때는 포즈와 "BOS The person"을 볼 수 있습니다.
- "standing"을 예측할 때는 포즈와 "BOS The person is"를 볼 수 있습니다.
- "EOS"를 예측할 때는 포즈와 "BOS The person is standing"을 볼 수 있습니다.
- 이전 단어들이 주어졌을 때 실제 다음 단어를 예측하는 확률을 높이는 방향으로 학습됩니다.
-
추론 시:
- 모델은 입력 포즈와 BOS 토큰을 받습니다.
- 모델은 BOS 토큰과 포즈를 바탕으로 다음 단어("The")에 대한 확률 분포를 계산하고 가장 확률이 높은 단어인 "The"를 선택합니다.
- 이제 모델은 포즈와 "BOS The"를 바탕으로 다음 단어("person")를 예측하고 선택합니다.
- 이 과정을 반복하며 "is", "standing", "EOS"를 차례로 생성합니다.
- EOS 토큰이 생성되면 설명 생성이 완료됩니다.
이 모델은 이러한 학습과 추론 과정을 통해 3D 포즈와 해당 포즈를 묘사하는 자연어 설명 사이의 복잡한 관계를 학습하게 됩니다.
6.4 평가 지표
-
자연어 처리 지표 (NLP Metrics)
-
목적: 생성된 텍스트가 사람이 작성한 '참조 텍스트(reference text)'와 얼마나 유사하고 자연스러운지를 측정하는 지표입니다. 주로 기계 번역이나 텍스트 생성 모델의 평가에 사용됩니다.
-
측정 방법: 생성된 텍스트와 참조 텍스트 간의 단어 또는 구문 일치도를 기반으로 점수를 계산합니다. 논문에서 사용된 지표는 다음과 같습니다.
- BLEU-4: 생성된 텍스트와 참조 텍스트 간의 1-gram부터 4-gram까지의 일치도를 측정하며, 짧은 길이의 텍스트에 페널티를 부여합니다. 텍스트의 정확성과 유창성을 평가하는 데 사용됩니다.
- Rouge-L: 생성된 텍스트와 참조 텍스트 간의 최장 공통 부분 수열(Longest Common Subsequence, LCS) 길이를 기반으로 합니다. 단어 순서는 고려하지만, 단어의 일치 여부가 중요합니다. 텍스트의 내용 포괄성을 평가하는 데 사용됩니다.
- METEOR: 단순 n-gram 일치 외에 어간(stemming), 동의어(synonymy) 등을 고려한 단어 일치와 단어 순서(fragmentation)를 함께 평가하여 사람이 판단한 품질과 더 높은 상관관계를 보이는 것으로 알려져 있습니다.
-
이 논문에서의 의미: NLP 지표는 생성된 포즈 설명이 문법적으로 올바르고, 표현이 자연스러우며, 사람이 작성한 설명과 표면적으로 얼마나 유사한지를 평가하는 데 사용됩니다. 하지만 이 지표들만으로는 텍스트가 해당 포즈의 구체적인 특징을 정확하게 묘사하는지, 즉 의미론적 정확성은 완전히 파악하기 어렵습니다.
-
-
검색 지표 (Retrieval Metric)
-
목적: 생성된 텍스트 설명이 원래의 포즈를 얼마나 잘 식별하고 검색할 수 있는지를 측정하는 지표입니다. 텍스트-포즈 간의 의미론적 정합성을 평가합니다.
-
측정 방법: 논문에서는 R-precision (recall@K) 지표를 사용했습니다.
- Recall@K: 특정 '쿼리 포즈(query pose)'에 대해 모델이 생성한 텍스트 설명을 가지고 데이터베이스에서 포즈를 검색했을 때, 원래 쿼리 포즈가 검색 결과 상위 K개 안에 포함될 확률을 측정합니다. 이 논문에서는 생성된 텍스트 설명을 쿼리로 사용하여, 해당 텍스트와 관련된 포즈들을 검색합니다. 이때, 검색 대상은 원래 쿼리 포즈와 무작위로 샘플링된 다른 포즈 31개를 포함한 총 32개의 포즈 집합입니다. K=1, 2, 3에 대해 Recall@K를 측정하고, 이들을 평균하여 R-precision으로 사용합니다. (텍스트에서 "top-k R-precision"이라고 언급된 부분입니다.)
-
이 논문에서의 의미: 이 지표는 생성된 텍스트 설명이 포즈의 특징을 얼마나 정확하게 담고 있어서, 그 텍스트만으로도 해당 포즈를 다른 많은 포즈들로부터 구별하고 찾아낼 수 있는지를 평가합니다. 즉, 생성된 설명의 '유용성(usefulness)'과 '의미론적 정확성(semantic accuracy)'을 간접적으로 측정하는 지표입니다.
-
-
재구성 지표 (Reconstruction Metrics)
-
목적: 생성된 텍스트 설명에 포즈의 3차원 기하학적 정보가 얼마나 정확하게 인코딩되어 있는지를 측정하는 지표입니다.
-
측정 방법: 원본 포즈를 모델에 입력하여 텍스트 설명을 생성하고, 이 생성된 텍스트 설명을 다시 포즈 생성 모델(논문의 섹션 V 모델)에 입력하여 3D 포즈를 재구성합니다. 그리고 이 재구성된 포즈가 원본 포즈와 얼마나 일치하는지를 3차원 공간에서 직접 비교하여 오류를 측정합니다.
- MPJE (Mean Per-Joint Error): 포즈를 구성하는 각 관절(joint)들의 3차원 위치 평균 오류를 측정합니다.
- MPVE (Mean Per-Vertex Error): 포즈의 3D 메시(mesh)를 구성하는 각 정점(vertex)들의 3차원 위치 평균 오류를 측정합니다.
- Geodesic distance on the joint rotations: 각 관절의 3차원 회전(rotation) 간의 지름길 거리(geodesic distance) 평균 오류를 측정합니다. 포즈의 형태를 더 잘 나타내는 지표입니다.
-
이 논문에서의 의미: 재구성 지표는 생성된 텍스트 설명이 단순히 자연스러운 문장으로 구성되어 있는지 넘어, 포즈의 세밀한 3차원 형태 및 관절 회전과 같은 기하학적 정보를 얼마나 정확하게 표현하고 있는지를 정량적으로 평가합니다. 오류 값이 낮을수록 생성된 텍스트가 원본 포즈의 3차원 정보를 잘 보존하고 있다고 볼 수 있습니다.
-
6.5 실험 결과
-
자동 생성된 캡션(PoseScript-A)으로 사전 학습(pretraining)한 모델이 그렇지 않은 모델에 비해 훨씬 우수한 설명 생성 능력을 보여주었습니다.
-
포즈 미러링(mirroring augmentation) 역시 성능 향상에 도움이 되었습니다.
-
R-precision 및 재구성 지표는 학습된 모델에 의존하기 때문에 데이터에 대한 편향된 이해가 있을 수 있으며, 이로 인해 생성된 텍스트가 원본 텍스트보다 더 나은 결과를 보이는 것처럼 나타날 수도 있다고 언급하고 있습니다.
-
모델은 egocentric relations(신체 부위 간의 상대적 위치) 및 high-level concepts(예: handstand와 같은 복잡한 개념)를 포함하는 의미 있는 설명을 생성할 수 있습니다.
7. 결론
-
본 논문은 3D 인체 포즈와 자연어 텍스트로 이루어진 설명이 매핑된 최초의 데이터셋인 PoseScript를 구축하였다.
-
텍스트 to 포즈 검색, 텍스트 기반 포즈 생성, 포즈에 대한 캡션 생성 이 세가지 태스크를 수행하는 멀티 모달 모델을 개발하였다.
