1. Introduction

2. Related Works
-
2.1 멀티모달 대규모 언어 모델 (Multimodal Large Language Model)
- Image LLM (이미지 LLM):
- 대규모 언어 모델(LLM)이 시각 정보를 이해할 수 있도록 시각 및 언어 양식을 정렬하려는 노력에 대해 다룬다.
- BLIP-2는 Q-Former 개념을 도입하여 정지된(frozen) 이미지 인코더에서 시각 특징을 추출한다.
- MiniGPT-4는 상세한 이미지 설명으로 미세 조정하는 것이 모델의 유용성을 크게 향상시킨다는 것을 입증하였다.
- LLAVA는 다양한 멀티모달 지시 따르기(instruction-following) 데이터를 탐색하여 범용 시각 비서(visual assistant)를 구축하는 것을 목표로 하였다.
- Kosmos-2 및 VisionLLM과 같은 최근 연구는 참조(referring) 및 그라운딩(grounding)을 포함한 이미지 이해의 더 세부적인 측면을 탐구하여 복잡한 이미지 세부 사항을 설명하는 능력을 크게 향상시켰다.
- Video LLM (비디오 LLM):
- Image LLM의 성공에 힘입어 연구자들은 단일 프레임 이미지에서 다중 프레임 비디오로 초점을 확장하였다.
- VideoChat, Video-LLaMA, Video-ChatGPT와 같은 비디오 호환 LLM들이 등장하였다.
- 이 모델들은 일반적으로 두 단계 훈련 전략을 사용한다.
- 첫 번째 단계: 대규모 데이터셋을 사용하여 비디오 특징을 LLM의 특징 공간에 정렬시킨다.
- 두 번째 단계: GPT 또는 사람 주석이 달린 제한된 데이터셋으로 instruction tuning을 수행한다.
- 이러한 모델들은 전반적인 비디오 이해에는 인상적인 능력을 보여주지만, 특정 비디오 세그먼트를 설명하고 시간적 추론을 수행하는 능력은 제한적이다. 이는 주로 첫 번째 훈련 단계에서 사용되는 WebVid [2]와 같은 데이터셋의 특성(단일 이벤트 비디오와 노이즈가 많은 텍스트 주석)과 두 번째 단계에서 고품질의 시간적 주석 데이터가 부족하기 때문이다.
- VTimeLLM은 이 간극을 메우기 위해 이 두 단계 사이에 "경계 인지 단계(boundary perception stage)"를 도입하여 모델이 비디오 내에서 이벤트를 정확하게 찾아내고 여러 다른 이벤트를 정확하게 설명할 수 있도록 한다.
- Image LLM (이미지 LLM):
-
2.2 세밀한 비디오 이해 (Fine-Grained Video Understanding)
- 비디오 내에서 특정 이벤트를 정확하게 찾아내고 이해하는 능력으로, 비디오 분석의 중요한 과제이다. 자연어와 결합될 때 두 가지 주요 작업으로 나뉜다.
- Temporal Video Grounding (시간적 비디오 그라운딩):
- 주어진 텍스트 입력에 대해 해당 비디오 세그먼트를 식별하는 것을 목표로 한다.
- 전통적인 접근 방식은 두 가지 유형으로 분류된다.
- 제안 기반(proposal-based) 방법 [4, 29, 32]: 후보 제안(candidate proposals)을 생성한 후 관련성을 기준으로 순위를 매긴다.
- 제안 비의존(proposal-free) 방법 [9, 30, 33]: 대상 순간의 시작 및 끝 경계를 직접 예측한다.
- Dense Video Captioning (밀집 비디오 캡셔닝):
- 손질되지 않은(untrimmed) 비디오 내의 모든 이벤트에 대한 시간적 위치화와 캡셔닝을 모두 요구하는 더 복잡한 작업이다.
- 초기 방법 [6, 11, 12]은 시간적 위치화 후 이벤트 캡셔닝을 포함하는 두 단계 프로세스를 사용하였다.
- 최근 발전 [25, 28, 36]은 캡셔닝 및 위치화 모듈의 공동 훈련으로 전환하고 있다. 예를 들어, Vid2Seq는 특정 시간 토큰을 통합하여 언어 모델을 강화하여 통합된 출력 시퀀스 내에서 이벤트 경계 및 텍스트 설명을 생성할 수 있도록 한다.
- 이 두 가지 작업 모두 비디오 세그먼트와 의미론적 맥락의 정렬이라는 근본적인 요구 사항을 공유한다. VTimeLLM 모델은 LLM의 강력한 기능과 고유한 훈련 전략을 활용하여 이러한 작업을 통합하고 탁월한 효과를 입증하였다.
3. Method
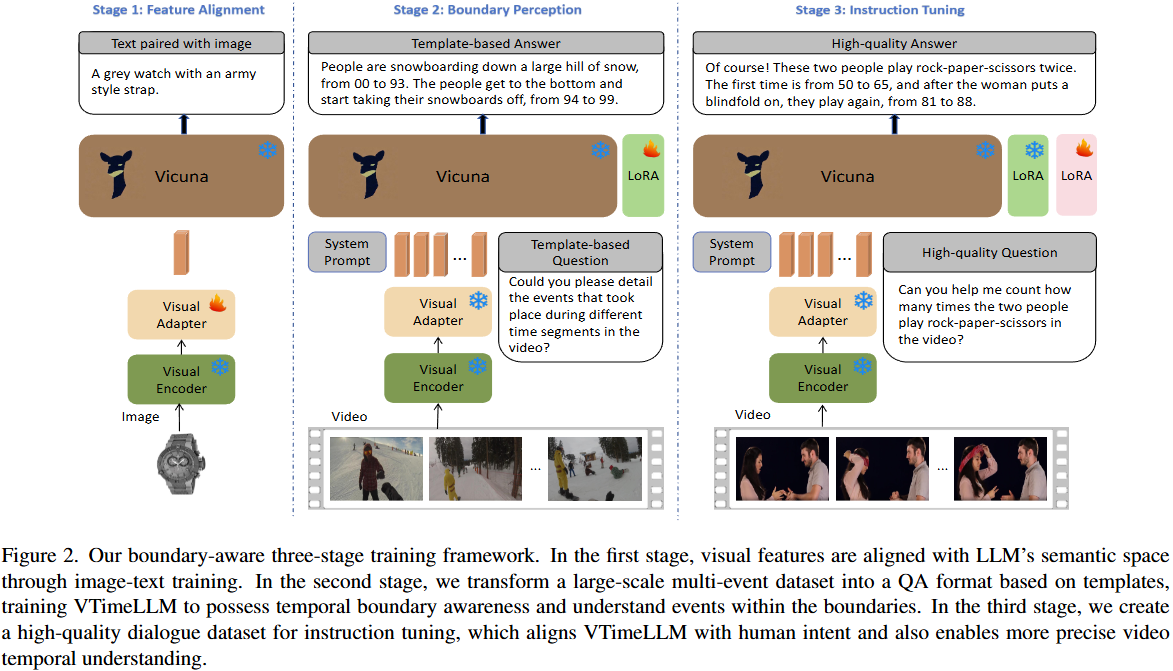
-
Stage 1: Feature Alignment (특징 정렬)
- 목표: LLM(Large Language Model)의 의미 공간과 비디오의 시각적 특징을 정렬하는 데 중점을 둔다. 이를 통해 LLM이 시각 정보를 이해할 수 있게 한다.
- 학습 데이터: 이미지-텍스트 쌍(LLaVA의 LCS-558K 데이터셋)을 사용한다. 이 논문은 시각 특징 정렬에 비디오 데이터셋보다 고품질 이미지 데이터셋이 더 효과적임을 실험으로 보여준다.
- 학습 과정:
- Visual Encoder (CLIP ViT-L/14)는 입력 이미지를 처리하여 특징을 추출한다. 이 인코더는 학습 중에 Frozen(고정)된다.
- 각 이미지 프레임 가 Visual Encoder 를 통해 처리되면 클래스 토큰 특징 와 패치 특징 가 추출된다. 이를 수식으로 표현하면 다음과 같다.
여기서 는 -번째 프레임의 전역 특징을 나타내며, 는 -번째 프레임의 -번째 패치 특징을 나타낸다. 은 샘플링된 프레임의 수이고, 는 ViT의 패치 수를 의미한다. - Visual Adapter 는 Visual Encoder에서 추출된 전역 특징 를 LLM의 임베딩 공간과 동일한 차원 로 투영하는 선형 레이어이다.
이렇게 변환된 는 LLM이 이해할 수 있는 입력 시퀀스 를 구성한다. - 이미지 특징 시퀀스 는
<image>토큰 위치에 삽입되어 텍스트와 함께 LLM에 입력된다.
여기서 는 텍스트 설명의 각 단어 임베딩이다. - 학습 파라미터: Visual Adapter 만 학습된다.
-
Stage 2: Boundary Perception (경계 인식)
- 목표: LLM이 비디오 내의 다양한 이벤트에 대한 시간적 경계를 인식하고 해당 경계 내의 이벤트를 이해하는 능력을 개발하도록 한다.
- 학습 데이터: 대규모 다중 이벤트 비디오-텍스트 데이터셋(InternVid-10M-FLT의 필터링된 서브셋)을 Q&A 형식으로 변환하여 사용한다. 이 데이터셋은 자동화된 방식으로 시간 정보가 대략적으로 주석(roughly annotated)되어 있다.
- 학습 과정:
- 단일 턴(single-turn) 및 다중 턴(multi-turn) Q&A 태스크를 설계한다. 단일 턴 Q&A는 모든 이벤트를 요약하는 Dense Video Captioning과 유사하고, 다중 턴 Q&A는 특정 시간대의 이벤트를 설명하거나(Segment Captioning) 특정 이벤트의 시간 경계를 찾는(Temporal Video Grounding) 방식이다.
<video>토큰을 사용하여 비디오 특징 를 텍스트 임베딩 중간에 삽입하여 LLM에 입력한다.
여기서 과 는<video>토큰 주변의 텍스트 임베딩이다.- 학습 파라미터: Visual Adapter는 Frozen(고정)되고, LLM (Vicuna)에 LoRA [4] 모듈을 적용하여 미세 조정한다. 손실은 Q&A 대화의 답변 토큰에 대해서만 계산된다.
-
Stage 3: Instruction Tuning (명령 튜닝)
- 목표: 모델을 인간의 의도에 맞춰 정렬하고, 비디오의 시간적 이해 및 추론 능력을 더욱 정확하게 만든다. Stage 2의 자동화된 주석의 부정확성과 과적합 문제를 해결하는 것을 목표로 한다.
- 학습 데이터: ActivityNet Captions [12] 및 DiDeMo [1] 데이터셋에서 고품질의 수동 주석(manually annotated) 비디오를 선별하고, LLM의 도움을 받아 Q&A 대화 데이터셋으로 변환한다. 추가적으로 VideoInstruct100K [20] 데이터셋의 Q&A 쌍을 포함한다.
- 학습 과정:
- Stage 2에서 학습된 LoRA 모듈을 원본 LLM 모델에 병합한 후, 새로운 LoRA 모듈을 추가하여 미세 조정한다. 이는 Stage 2에서 얻은 시간 이해 능력을 보존하면서 새로운 학습을 가능하게 한다.
- Visual Adapter는 계속 Frozen(고정)된다.
- 학습 파라미터: 새로 추가된 LoRA 모듈만 학습된다.


4. Experiment
Experiment Setup
1. Temporal Video Grounding (시간적 비디오 접지)
이 작업은 주어진 텍스트 입력(예: "남자가 춤을 추는 부분")에 해당하는 비디오 세그먼트의 정확한 시작 및 종료 시간 경계를 식별하는 것을 목표로 한다.
- 사용된 데이터셋:
- ActivityNet Captions [1]
- Charades-STA [8]
- 평가 지표:
- Intersection over Union (IoU, 교집합-합집합 비율): 모델이 예측한 시간 세그먼트와 실제(Ground Truth) 시간 세그먼트 간의 겹치는 정도를 측정하는 지표이다.
- 수식:
- 각 용어의 의미:
- : 모델이 예측한 시간 세그먼트(Prediction)
- : 실제 시간 세그먼트(Ground Truth)
- : 예측 세그먼트와 실제 세그먼트의 교집합 영역(겹치는 시간 구간)
- : 예측 세그먼트와 실제 세그먼트의 합집합 영역(전체 시간 구간)
- Mean IoU (mIoU, 평균 IoU): 모든 예측된 시간 세그먼트에 대한 IoU 값들의 평균이다.
- Recall@1, IoU (R@m): 모델이 예측한 상위 1개 세그먼트가 실제 세그먼트와 이상의 IoU를 가질 때의 재현율이다. 여기서 은 {0.3, 0.5, 0.7}의 값으로 설정된다. 이 지표는 모델이 얼마나 정확하게 이벤트의 시간적 경계를 찾아내는지를 보여준다.
- Intersection over Union (IoU, 교집합-합집합 비율): 모델이 예측한 시간 세그먼트와 실제(Ground Truth) 시간 세그먼트 간의 겹치는 정도를 측정하는 지표이다.
2. Dense Video Captioning (조밀한 비디오 캡셔닝)
이 작업은 비디오 내에서 발생하는 모든 이벤트의 시간적 위치를 정확히 파악하고, 각 이벤트에 대한 상세한 텍스트 설명을 생성하는 것을 목표로 하는 더욱 복잡한 작업이다.
- 사용된 데이터셋:
- ActivityNet Captions [1]
- 평가 지표: 이 작업은 두 가지 범주의 지표로 평가된다.
- SODA c [7]: Dense Video Captioning 작업에 특별히 고안된 지표로, 비디오의 스토리라인(storyline)을 고려하여 캡션의 품질을 평가한다. 이는 단순한 단어 일치뿐만 아니라 이벤트의 흐름과 논리적 일관성을 중요하게 본다.
- 캡션 품질 측정 지표:
- 모델이 생성한 이벤트와 실제 이벤트 사이에 IoU 임계값 {0.3, 0.5, 0.7, 0.9}를 기준으로 일치하는 쌍을 먼저 계산한다.
- 이 일치하는 쌍을 기반으로 다음 캡션 품질 지표들의 평균값을 보고한다 [28]:
- CIDEr [24]: 주로 이미지 캡션 평가에 사용되는 지표이다. Ground Truth 캡션과 모델이 생성한 캡션 간의 n-gram(연속된 단어의 묶음) 일치도를 측정하여 여러 참조 캡션과 얼마나 잘 일치하는지(합의도)를 반영한다.
- METEOR [3]: 모델 생성 캡션과 Ground Truth 캡션 간의 단어 일치, 어간(stem) 일치, 유의어 일치, 구(phrase) 일치를 종합적으로 고려하여 정밀도와 재현율의 조화 평균을 계산하는 지표이다. 이는 단순한 표면적 일치보다 의미론적 유사성을 더 잘 포착하고자 한다.
Dense Video Captioning 평가 예시
하나의 비디오에 대해 다음과 같은 실제(Ground Truth) 이벤트와 모델 예측(Prediction) 이벤트가 있다고 가정하자.
비디오 길이: 0초 ~ 100초
Ground Truth (실제 이벤트):
- GT Event 1: (0초 ~ 20초) "한 남자가 개와 함께 공원에서 산책하고 있다."
- GT Event 2: (25초 ~ 45초) "개가 공을 쫓아 달려간다."
- GT Event 3: (50초 ~ 70초) "남자가 개에게 간식을 준다."
Model Prediction (모델 예측 이벤트):
- Pred Event A: (5초 ~ 23초) "한 남자가 개와 산책하는 장면이다."
- Pred Event B: (28초 ~ 48초) "개가 공놀이를 하고 있다."
- Pred Event C: (55초 ~ 75초) "남자가 개에게 먹이를 주고 있다."
- Pred Event D: (80초 ~ 90초) "개가 잔디밭에서 쉬고 있다." (GT에는 없는 예측)
1단계: 시간적 로컬라이제이션(Temporal Localization) 평가 (IoU 계산 및 매칭)
각 GT 이벤트와 Pred 이벤트 쌍에 대해 IoU를 계산하고, 특정 IoU 임계값()을 기준으로 매칭되는 쌍을 찾는다. 이 예시에서는 IoU 임계값을 0.5로 설정해 보자.
-
GT Event 1 (0~20초) vs. Pred Event A (5~23초):
- 교집합: (5초 ~ 20초), 길이 = 15초
- 합집합: (0초 ~ 23초), 길이 = 23초
- 이므로, GT Event 1과 Pred Event A는 매칭된다.
-
GT Event 2 (25~45초) vs. Pred Event B (28~48초):
- 교집합: (28초 ~ 45초), 길이 = 17초
- 합집합: (25초 ~ 48초), 길이 = 23초
- 이므로, GT Event 2와 Pred Event B는 매칭된다.
-
GT Event 3 (50~70초) vs. Pred Event C (55~75초):
- 교집합: (55초 ~ 70초), 길이 = 15초
- 합집합: (50초 ~ 75초), 길이 = 25초
- 이므로, GT Event 3과 Pred Event C는 매칭된다.
-
Pred Event D (80~90초): 어떤 GT 이벤트와도 IoU 임계값을 넘는 매칭이 없다. (혹은 IoU가 0이다.)
결과: IoU 임계값 0.5를 기준으로 3개의 매칭된 쌍이 존재한다.
2단계: 캡션 품질(Caption Quality) 평가 (CIDEr, METEOR 계산)
이제 매칭된 각 쌍에 대해서만 캡션의 품질을 평가한다.
-
매칭 쌍 1: (GT Event 1, Pred Event A)
- GT 캡션: "한 남자가 개와 함께 공원에서 산책하고 있다."
- Pred 캡션: "한 남자가 개와 산책하는 장면이다."
- 이 두 캡션에 대한 CIDEr 및 METEOR 점수를 계산한다.
- 예시: ,
-
매칭 쌍 2: (GT Event 2, Pred Event B)
- GT 캡션: "개가 공을 쫓아 달려간다."
- Pred 캡션: "개가 공놀이를 하고 있다."
- 이 두 캡션에 대한 CIDEr 및 METEOR 점수를 계산한다.
- 예시: ,
-
매칭 쌍 3: (GT Event 3, Pred Event C)
- GT 캡션: "남자가 개에게 간식을 준다."
- Pred 캡션: "남자가 개에게 먹이를 주고 있다."
- 이 두 캡션에 대한 CIDEr 및 METEOR 점수를 계산한다.
- 예시: ,
최종 결과:
보고하는 CIDEr 및 METEOR 점수는 이 매칭된 쌍들의 평균이 된다.
- 평균 CIDEr =
- 평균 METEOR =
이 과정은 일반적으로 여러 IoU 임계값( = {0.3, 0.5, 0.7, 0.9})에 대해 반복하여 수행되며, 각 임계값에서의 평균 CIDEr과 METEOR 점수가 최종적으로 보고된다. 이렇게 함으로써 모델이 시간적 경계를 얼마나 엄격하게 지키면서 캡션을 생성하는지에 대한 포괄적인 분석이 가능해진다.
논문에서 "compute matched pairs between the generated events and the ground truth across IoU thresholds of {0.3, 0.5, 0.7, 0.9}, and calculate captioning metrics based on these matched pairs"라고 언급된 부분이 바로 이 과정을 의미한다.
1. CIDEr (Consensus-based Image Description Evaluation) 계산 과정
CIDEr는 주로 이미지 캡션 평가에 사용되었지만, 비디오 캡션에도 확장되어 사용된다. 핵심은 n-gram(연속된 단어 묶음) 일치와 TF-IDF(Term Frequency-Inverse Document Frequency) 가중치를 사용하여 여러 참조 캡션과 얼마나 잘 일치하는지(합의도)를 측정하는 것이다. 여기서는 참조 캡션이 하나뿐인 경우로 설명한다.
단계별 설명:
-
N-gram 추출: 예측 캡션과 참조 캡션에서 n-gram을 추출한다. 일반적으로 1-gram부터 4-gram까지 사용한다.
- Pred 캡션: "개가 공놀이를 하고 있다."
- 1-gram: {개가, 공놀이를, 하고, 있다}
- 2-gram: {개가 공놀이를, 공놀이를 하고, 하고 있다}
- 3-gram: {개가 공놀이를 하고, 공놀이를 하고 있다}
- 4-gram: {개가 공놀이를 하고 있다}
- GT 캡션: "개가 공을 쫓아 달려간다."
- 1-gram: {개가, 공을, 쫓아, 달려간다}
- 2-gram: {개가 공을, 공을 쫓아, 쫓아 달려간다}
- 3-gram: {개가 공을 쫓아, 공을 쫓아 달려간다}
- 4-gram: {개가 공을 쫓아 달려간다}
- Pred 캡션: "개가 공놀이를 하고 있다."
-
N-gram 일치 계산: 각 n-gram 길이()에 대해 예측 캡션에 있는 n-gram 중 참조 캡션과 일치하는 것들의 수를 센다.
- 1-gram:
- 일치: "개가" (1개)
- 불일치 (Pred): "공놀이를", "하고", "있다"
- 불일치 (GT): "공을", "쫓아", "달려간다"
- 2-gram, 3-gram, 4-gram: 일치하는 n-gram이 없다.
- 1-gram:
-
TF-IDF 가중치 부여:
- 각 n-gram에 대해 TF(Term Frequency)와 IDF(Inverse Document Frequency)를 계산하여 가중치를 부여한다.
- TF (단어 빈도): 해당 n-gram이 캡션 내에서 나타나는 빈도이다.
- IDF (역문서 빈도): 해당 n-gram이 전체 코퍼스(여기서는 참조 캡션)에서 얼마나 희귀한지를 나타낸다. 희귀한 n-gram일수록 높은 가중치를 받는다. 이는 단순히 자주 등장하는 단어보다 의미론적으로 중요한 단어에 더 높은 점수를 부여하기 위함이다.
- "개가"와 같이 흔한 단어는 낮은 IDF를 가질 수 있고, "공놀이를 하고 있다"와 같이 특이한 n-gram은 높은 IDF를 가질 수 있다.
-
코사인 유사도 계산:
- TF-IDF 가중치가 적용된 예측 캡션의 n-gram 벡터와 참조 캡션의 n-gram 벡터 간의 코사인 유사도를 계산한다.
- 이 유사도 값은 n-gram 일치를 고려하면서 의미론적 중요도를 반영한다.
-
평균 및 스케일링:
- 각 n-gram 길이()에 대해 계산된 유사도 점수를 평균한다.
- 최종적으로 특정 스케일링 상수(예: 10)를 곱하여 CIDEr 점수를 얻는다.
CIDEr 점수 특징:
- 주로 n-gram의 정확한 일치에 중점을 둔다.
- TF-IDF 가중치를 통해 의미론적으로 더 중요한 n-gram에 높은 점수를 부여한다.
- 다수의 참조 캡션이 있을 경우, 모델의 캡션이 여러 참조 캡션의 "합의"를 얼마나 잘 반영하는지를 측정한다. (이 예시에서는 참조가 하나이므로 단순 비교가 된다.)
2. METEOR (Metric for Evaluation of Translation with Explicit Ordering) 계산 과정
METEOR는 기계 번역 평가에 사용되다가 캡션 평가에도 적용되었다. 이는 단순 n-gram 일치를 넘어, 단어의 어간(stemming), 유의어(synonymy), 그리고 단어 순서(order)까지 고려하여 캡션 품질을 평가한다.
단계별 설명:
-
단어 정렬 (Word Alignment): 예측 캡션과 참조 캡션 간의 단어들을 정렬한다. 이는 다음 규칙에 따라 매칭된다.
- 정확한 일치 (Exact Match): 두 캡션에 동일한 단어가 있으면 매칭.
- Pred: "개가 공놀이를 하고 있다."
- GT: "개가 공을 쫓아 달려간다."
- 일치: "개가"
- 어간 일치 (Stem Match): 단어의 어간이 같으면 매칭 (예: "달려간다" -> "달리다", "달려가는" -> "달리다").
- 이 예시에서는 직접적인 어간 일치는 없다.
- 유의어 일치 (Synonym Match): WordNet과 같은 시소러스를 사용하여 유의어 관계에 있는 단어들을 매칭한다.
- "공놀이"와 "공을 쫓아"는 의미상 유사할 수 있으나, 단어 자체는 유의어로 등록되어 있지 않을 가능성이 높다. "하고 있다"와 "달려간다"도 직접적인 유의어는 아니다.
- "공놀이를"과 "공을"은 부분이 일치하지만, METEOR는 전체 단어 매칭을 우선한다.
- 핵심 단어 일치: 이 예시에서는 "개가"만 정확히 일치한다.
- 정확한 일치 (Exact Match): 두 캡션에 동일한 단어가 있으면 매칭.
-
정밀도 (Precision, P) 및 재현율 (Recall, R) 계산: 정렬된 단어를 기반으로 unigram(1-gram) 정밀도와 재현율을 계산한다.
- 정밀도 (P): (매칭된 단어 수) / (예측 캡션의 전체 단어 수)
- Pred 캡션 단어 수: 4 ("개가", "공놀이를", "하고", "있다")
- 매칭된 단어 수: 1 ("개가")
- 재현율 (R): (매칭된 단어 수) / (참조 캡션의 전체 단어 수)
- GT 캡션 단어 수: 4 ("개가", "공을", "쫓아", "달려간다")
- 매칭된 단어 수: 1 ("개가")
- 정밀도 (P): (매칭된 단어 수) / (예측 캡션의 전체 단어 수)
-
F-평균 (F-mean) 계산: 정밀도와 재현율을 조화 평균하여 F-mean을 계산한다. METEOR는 재현율에 더 높은 가중치를 부여하는 것이 일반적이다 ( 값을 사용하여 ). 보통 를 사용한다.
-
단편화 페널티 (Fragmentation Penalty) 적용:
- 단어의 순서나 구조가 얼마나 잘 유지되었는지를 평가하여 페널티를 부과한다.
- 매칭된 단어들()이 몇 개의 청크(chunk, 연속된 단어 묶음)()로 나뉘는지 계산한다. 청크의 수가 많을수록 페널티가 커진다.
- 이 예시에서는 "개가"만 일치하므로 이다.
- 페널티 요소는 와 같은 형태로 계산된다 (실제 구현은 더 복잡할 수 있음).
- (단, 인 경우 페널티가 항상 는 아니다. 구현체마다 다름.)
- 최종 METEOR 점수 =
- 예시: METEOR = (이는 단순화된 계산이며 실제 점수는 다를 수 있다.)
METEOR 점수 특징:
- 단순한 n-gram 일치를 넘어 어간, 유의어를 통한 의미론적 유사성도 고려한다.
- 정확한 단어 순서에 대한 페널티를 부여하여 문법적, 구조적 일관성을 평가한다.
- 재현율에 더 많은 가중치를 부여하는 경향이 있어, 참조 캡션의 정보를 모델이 얼마나 잘 포함하고 있는지를 중요하게 본다.
결론:
- CIDEr: "개가"라는 단어의 일치는 있지만, "공을 쫓아 달려간다"와 "공놀이를 하고 있다"는 n-gram 일치가 거의 없어 CIDEr 점수는 낮을 것으로 예상된다. "개가"가 흔한 단어라면 IDF 가중치도 낮을 수 있다.
- METEOR: "개가"라는 정확한 단어 일치는 있지만, 나머지 단어들이 어간이나 유의어로도 매칭되지 않고, 문장 구조가 다르기 때문에 F-mean 점수가 낮고, 단편화 페널티까지 적용되어 최종 METEOR 점수도 낮게 나올 것으로 예상된다.
SODA (c) 계산 과정
SODA (c)는 Optimal Matching을 위해 동적 프로그래밍을 사용하며, 이때 비용 함수로 를 활용한다. 여기서 는 와 간의 METEOR 점수를 의미한다. 이후 Optimal Matching 결과를 바탕으로 F-measure를 계산한다.
계산 과정은 다음과 같다.
1. 이벤트 시간 순서 정렬
먼저, Ground Truth(GT) 이벤트와 Prediction(Pred) 이벤트를 시작 시간에 따라 정렬한다.
- Ground Truth (GT) 이벤트:
- : (0초 ~ 20초) "한 남자가 개와 함께 공원에서 산책하고 있다."
- : (25초 ~ 45초) "개가 공을 쫓아 달려간다."
- : (50초 ~ 70초) "남자가 개에게 간식을 준다."
- Model Prediction (Pred) 이벤트:
- : (5초 ~ 23초) "한 남자가 개와 산책하는 장면이다."
- : (28초 ~ 48초) "개가 공놀이를 하고 있다."
- : (55초 ~ 75초) "남자가 개에게 먹이를 주고 있다."
- : (80초 ~ 90초) "개가 잔디밭에서 쉬고 있다."
2. IoU (Intersection over Union) 계산
각 GT 이벤트와 Pred 이벤트 쌍에 대해 IoU를 계산한다. IoU 공식은 다음과 같다:
여기서 는 시작 시간, 는 종료 시간을 나타낸다.
- :
- , , : 시간대가 겹치지 않으므로
- : 시간대가 겹치지 않으므로
- :
- , : 시간대가 겹치지 않으므로
- , : 시간대가 겹치지 않으므로
- :
- : 시간대가 겹치지 않으므로
3. METEOR 점수 계산
각 GT 이벤트와 Pred 이벤트 쌍에 대해 METEOR 점수를 가정한 후, 텍스트 유사도를 바탕으로 적절한 값을 부여한다. (실제로는 METEOR 도구를 사용하여 계산해야 한다.)
- ("한 남자가 개와 함께 공원에서 산책하고 있다." vs "한 남자가 개와 산책하는 장면이다.") (유사도가 매우 높다)
- ("개가 공을 쫓아 달려간다." vs "개가 공놀이를 하고 있다.") (유사도가 높다)
- ("남자가 개에게 간식을 준다." vs "남자가 개에게 먹이를 주고 있다.") (유사도가 높다)
- 나머지 GT-Pred 쌍은 문맥상 관련이 없거나 시간대가 겹치지 않으므로 METEOR 점수를 으로 가정한다.
4. 비용 계산 (SODA (c) Cost)
SODA (c)의 비용 함수는 이다. 일반적으로 DVC 평가에서는 IoU 임계값 를 설정하여 인 경우 매칭에서 제외하지만, SODA (c)의 비용 함수는 IoU가 직접 곱해지므로, 는 동적 프로그래밍의 S[i][j] 업데이트 과정에서 가 0이 되는 조건으로 포함된다. 논문 그림 4의 예시에서는 으로 시작하므로, 여기서는 IoU가 0이 아닌 모든 쌍에 대해 계산한다.
- 그 외의 값은 IoU 또는 METEOR가 0이므로 모두 이다.
5. 동적 프로그래밍을 이용한 최적 매칭
이제 , 인 상황에 대해 동적 프로그래밍 테이블 를 구축한다. 는 개의 Pred 캡션과 개의 GT 캡션 사이의 최적 매칭 점수를 저장한다.
-
초기화:
- (모든 에 대해)
- (모든 에 대해)
-
점화식: ()
여기서 는 -번째 GT 캡션과 -번째 Pred 캡션 간의 비용이다.
DP 테이블 (행 열) 채우기:
| (0) | (1) | (2) | (3) | |
|---|---|---|---|---|
| (0) | 0 | 0 | 0 | 0 |
| (1) | 0 | |||
| (2) | 0 | |||
| (3) | 0 | |||
| (4) | 0 |
각 셀을 채워나가자 (값은 반올림될 수 있다):
최종 이다.
이제 최적 매칭 경로를 역추적한다.
에서 시작하여, 어떤 경로로 이 값에 도달했는지 확인한다.
는 이다. 은 이다. 따라서 이 값을 결정했다.
- 매칭. 다음은 를 추적.
는 ()이 아니고, ()이므로 가 값을 결정했다.
- 매칭. 다음은 를 추적.
는 ()이 아니고, ()이므로 이 값을 결정했다.
- 매칭. 다음은 를 추적.
따라서 Optimal Matching은 , , 이다. (Pred Event D ()는 매칭되지 않았다.)
Optimal Matching에서 METEOR 점수의 합 (SODA (c)의 합)은 다음과 같다.
6. F-measure 계산
Optimal Matching 결과를 바탕으로 Precision, Recall, 그리고 F-measure를 계산한다.
-
Precision():
여기서 는 모델이 생성한 전체 캡션의 수이다.
-
Recall():
여기서 는 참조 캡션의 수이다.
-
F-measure():
따라서 SODA (c) 평가 결과는 약 이다. Pred Event D ()는 GT에 매칭되지 않아 METEOR 점수 합에는 기여하지 못했지만, 전체 예측 캡션 수()에 포함되어 Precision을 낮추는 요인이 되었다. 이는 불필요하거나 중복된 캡션에 대한 페널티를 부여하는 SODA의 목표와 부합한다.
Ablation Study
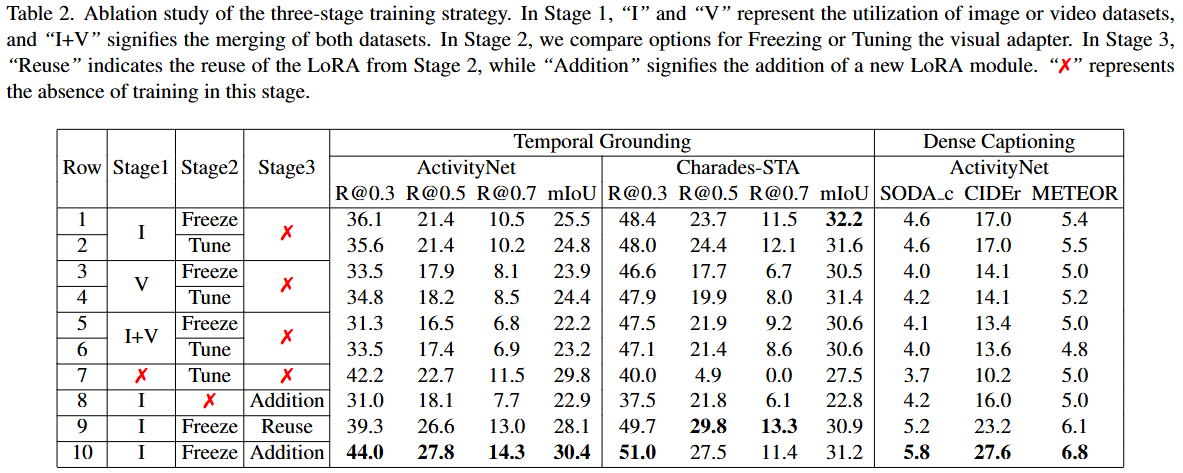
Q1: 좋은 Visual Adapter를 훈련하는 방법은 무엇인가?
이 질문은 Visual Adapter를 효과적으로 훈련하기 위한 데이터 모달리티(이미지 vs 비디오) 선택과 훈련된 Visual Adapter의 파라미터를 후속 단계에서 튜닝할지 고정할지에 대한 질문이다.
- 1단계 훈련을 위한 데이터 모달리티 선택:
- VTimeLLM은 다른 Video LLM과 달리 1단계에서 순수 이미지 모달리티를 활용하며, 이는 모든 평가 지표에서 순수 비디오 모달리티를 사용한 경우보다 우수한 성능을 보인다 (표 2의 Row 1, 2와 Row 3, 4 비교).
- 이러한 효과는 이미지 데이터셋의 더 높은 품질과 정보 손실 감소에 기인한다.
- 또한, 순수 이미지를 사용하는 것이 두 모달리티 데이터셋(이미지+비디오)을 병합한 것보다 더 나은 성능을 보인다 (표 2의 Row 1, 2와 Row 5, 6 비교).
- 이는 단일 프레임 이벤트와 100프레임 시퀀스 이벤트를 설명하는 작업 간의 현저한 차이 때문에 모델 피팅에 개별적인 도전 과제를 제시하기 때문일 수 있다.
- Visual Adapter 파라미터 튜닝 또는 고정 여부:
- 후속 단계에서 이전에 사전 훈련된 Visual Adapter의 파라미터를 튜닝할지 고정할지에 대한 의문이 제기된다.
- 연구 결과, 두 접근 방식 간의 성능 차이는 미미한 것으로 관찰되었다 (Row 1과 Row 2, Row 3과 Row 4, Row 5와 Row 6 비교).
- 따라서 사전 훈련 단계에서 얻은 포괄적인 정보를 유지하기 위해 후반 두 단계에서는 Visual Adapter의 파라미터를 고정하는 것을 선택한다.
Q2: Stage 2의 LoRA를 Stage 3에서 재사용해야 하는가?
이 질문은 Stage 3 훈련 시 Stage 2에서 학습한 LoRA 모듈의 활용 방법에 대한 질문이다.
- Stage 3에서 Stage 2의 LoRA 모듈을 LLM 파라미터와 병합하고 추가적으로 또 다른 LoRA 모듈을 통합하는 것이 더 우수한 결과를 가져온다 (표 2의 Row 9와 Row 10 비교).
- 이러한 접근 방식은 Stage 2에서 습득한 시간 이해(temporal understanding) 능력이 모델 내에 효과적으로 보존되도록 보장한다.
Q3: 세 단계의 훈련 과정이 모두 필수적인가?
-
Stage 1: Feature Alignment 단계의 필요성
- Row 1~6과 Row 7의 비교를 통해 Stage 1 없이 훈련할 경우 temporal grounding 태스크에서 모델 성능에 상당한 차이가 있음을 발견했다.
- ActivityNet 데이터셋에서는 점수가 비정상적으로 높게 나타났지만, 이는 모델이 이벤트를 효과적으로 국지화(localize)하지 못하고 거의 전체 비디오(부터 까지)를 예측하는 경향 때문이었다.
- 만약 Ground Truth(실제 정답) 지속 시간을 비디오 길이에 대한 비율을 라고 하면, 모델 출력과의 IoU(Intersection over Union)는 대략 가 된다. ActivityNet 데이터셋은 긴 샘플이 많으며, 쿼리의 20%가 이므로, 전체 비디오를 예측하는 모델은 실제보다 높은 IoU를 얻게 되어 평가 지표가 과장될 수 있다.
- 반대로 Charades-STA 데이터셋에서는 가 를 넘는 경우가 거의 없어 더 정밀한 국지화가 요구되는데, Stage 1 훈련이 없는 모델은 이를 달성하지 못했다.
- 또한, Dense Captioning 태스크에서도 모델 성능이 불만족스러웠다는 점은 Feature Alignment 단계가 필수적임을 강조한다.
-
Stage 2: Boundary Perception 단계의 필요성
- Row 8과 Row 9, 10의 비교를 통해 Stage 2의 필요성을 입증한다.
- Stage 3의 어노테이션 품질이 더 높음에도 불구하고, 제한된 데이터셋 크기 때문에 Stage 3 훈련만으로는 견고한 시간적 이해(temporal understanding) 능력을 달성하기 어렵다.
- Stage 3 훈련만 거친 모델은 Stage 2에서 예비 훈련을 거친 모델에 비해 다양한 태스크에서 열등한 성능을 보였다.
-
Stage 3: Instruction Tuning 단계의 필요성
- Stage 3 훈련 후 모델은 테이블에 제시된 태스크들에서 포괄적인 개선을 보인다 (Row 1과 Row 10 비교).
- 더 나아가, 모델은 채팅 능력을 되찾아 인간이 제시하는 광범위한 질문에 응답할 수 있게 된다. 이는 이전 단계에서 과적합되거나 일반적인 대화 능력을 상실했던 문제를 해결한다.
