1. Introduction
- Talking Head Synthesis의 중요성:
- 사실적인 비디오 아바타를 생성하는 데 필수적인 작업이다.
- 시각적 더빙, 대화형 라이브 스트리밍, 온라인 회의 등 다양한 애플리케이션에서 활용 가능하다.
- 기존 연구 동향:
- 최근 딥러닝 기술을 활용하여 생생한 Talking Head를 one-shot으로 생성하는 데 큰 진전이 있었다.
- 주요 방법론은 크게 두 가지로 나뉜다.
- Audio-driven talking head synthesis: 오디오 신호로부터 정확한 입술 움직임 합성에 중점을 둔다.
- Video-driven face reenactment: 소스 비디오의 모든 얼굴 움직임을 대상 인물에게 충실하게 전이하는 것을 목표로 하며, 이러한 움직임을 개별 제어 없이 하나의 단위로 처리하는 경향이 있다.
- 기존 방법론의 한계 및 본 연구의 필요성:
- 여러 얼굴 모션에 대한 세분화되고 분리된 제어(fine-grained and disentangled control)가 사실적인 Talking Head를 구현하는 핵심이라고 주장한다. 즉, 입술 움직임, 머리 자세, 눈 움직임, 표정을 각각 별도의 제어 신호로 분리하여 제어할 수 있어야 한다.
- 이는 분리 표현 학습(disentangled representation learning)이라는 연구 측면에서도 중요하며, 실제 응용 분야에서도 큰 영향을 미친다. 예를 들어, 이미 합성된 Talking Head의 눈 시선을 변경하고 싶을 때, 다른 모든 모션까지 새로 만들 필요 없이 눈 시선만 바꿀 수 있어야 한다.
- 하지만 이러한 요인들을 분리된 방식으로 제어하는 것은 매우 어렵다.
- 입술 움직임은 본질적으로 감정과 밀접하게 얽혀 있어, 동일한 음성 내용이라도 감정에 따라 입 모양이 다를 수 있다.
- 모든 요인을 분리하기 위한 대규모 주석 데이터가 부족하다.
- 그 결과, 기존 방법들은 특정 요인(예: 눈 시선, 표정)을 수정할 수 없거나, 전체를 한꺼번에 변경하거나, 개별 요인에 대한 정밀한 제어에 어려움을 겪고 있다.
- 본 논문(PD-FGC)의 해결 방안:
- PD-FGC(Progressive Disentangled Fine-Grained Controllable Talking Head)를 제안한다.
- 입술 움직임, 머리 자세, 눈 깜빡임/시선, 감정 표현에 대한 분리된 제어가 가능하다.
- 입술 움직임은 오디오에서, 다른 모션들은 각각 다른 비디오로 개별적으로 구동될 수 있다.
- 각 모션 요인에 대해 분리된 잠재 표현(latent representation)을 학습하고, 이를 입력으로 받아 Talking Head를 합성하는 이미지 생성기(image generator)를 활용한다.
- 야생(in-the-wild) 비디오 데이터만을 사용하여 훈련하는 것이 어렵기 때문에, 각 모션의 고유한 속성을 최대한 활용한다.
- 진보적 분리 표현 학습 전략(progressive disentangled representation learning strategy)을 제안한다.
- 1단계: Appearance 및 Motion 분리: 데이터 증강(data augmentation) 및 자기 구동(self-driving)을 통해 외모 정보는 제외하고 모든 모션 정보를 기록하는 통합 모션 특징(unified motion feature)을 먼저 추출한다.
- 2단계: 세분화된 Motion 분리: 통합 모션 특징에서 입술 움직임, 눈 깜빡임/시선, 머리 자세에 대한 개별 모션 표현을 학습한다. 모션별 대조 학습(motion-specific contrastive learning)과 3D 자세 추정기(3D pose estimator)의 도움을 받는다.
- 3단계: Expression 분리: 감정 표현은 다른 모션과 매우 얽혀 있기 때문에, 특징 레벨 디커플링(feature-level decorrelation)을 통해 다른 모션 요인들과 분리하며, 동시에 자기 재구성(self-reconstruction)을 통해 이미지 생성기를 학습하여 의미론적으로 의미 있는 표현(expression)을 학습한다.
- 주요 기여:
- 정교하게 설계된 진보적 분리 표현 학습 전략을 활용하여 외모, 입술 움직임, 머리 자세, 눈 깜빡임/시선, 감정 표현을 분리하는 새로운 one-shot 세분화 가능 Talking Head 합성 방법을 제안한다.
- 원하는 요인 분리(factor disentanglement)를 달성하기 위해 모션별 대조 학습(motion-specific contrastive learning)과 특징 레벨 디커플링(feature-level decorrelation)을 도입한다.
- 사전 모델의 제한적인 가이드만으로 비정형 비디오 데이터(unstructured video data)에서 훈련되어, 다양한 얼굴 모션에 대해 다른 구동 신호를 통해 정밀하게 제어할 수 있다. 이는 기존 방법으로는 거의 달성하기 어려운 부분이다.
2. Related work
Audio-driven talking head synthesis
-
오디오 기반 토킹 헤드 합성의 목표: 주어진 음성 오디오에 맞춰 입술 움직임이 동기화된 얼굴 이미지를 생성하는 것을 목표로 한다. 초기 연구에서는 주로 입술 영역의 움직임 제어에 초점을 맞추었으며, 다른 얼굴 부분은 변경하지 않고 유지하는 방식이었다.
-
기존 연구의 확장:
- 다양한 얼굴 속성 제어: 최근 연구들은 눈 깜빡임(eye blink)이나 머리 자세(head pose)와 같은 추가적인 얼굴 속성까지 제어할 수 있도록 기능을 확장하고 있다.
- 감정 표현 도입: 더욱 생생한 토킹 헤드 생성을 위해 감정 표현(emotional expression)의 변화를 합성 과정에 도입하려는 시도가 있었다.
-
감정 표현 제어의 어려움:
- 데이터 부족: 감정 표현을 토킹 헤드 합성에 통합하는 것은 표현력이 풍부한 데이터가 부족하여 매우 어려운 과제이다.
- 일반화의 한계: 일부 방법들(EAMM, MEAD)은 수동으로 수집된 감정 토킹 헤드 데이터셋에 의존하지만, 데이터 범위가 제한적이어서 대규모 시나리오에 잘 일반화되지 못한다.
-
선행 연구 GC-AVT의 접근 방식: 최근 연구인 GC-AVT [34]는 'in-the-wild' 데이터(제한되지 않은 실제 환경에서 수집된 데이터)를 활용하여 표현력이 풍부한 토킹 헤드 합성을 시도한다. 이 방법은 입술 움직임과 다른 얼굴 표현을 분리하기 위해 입 영역 데이터 증강(mouth-region data augmentation)을 도입하여 감정 표현에 대한 disentangled control을 달성한다.
-
본 논문(PD-FGC)의 차별점:
- 특징 레벨 비상관화(feature-level decorrelation): GC-AVT와는 다르게 본 논문은 특징 레벨의 비상관화(decorrelation)를 활용하여 입술 움직임과 다른 얼굴 표현이라는 두 요인을 분리한다.
- 다양한 요인 개별 제어: 본 논문의 방법은 입술 움직임(lip motion), 머리 자세(head pose), 눈 응시 및 깜빡임(eye gaze&blink), 그리고 감정 표현(expressions)을 개별적으로 제어할 수 있는 disentangled control을 통해 임의의 토킹 헤드를 합성할 수 있다. 이는 이전 방법들이 모든 요인을 개별적으로 제어하는 데 어려움을 겪었던 한계를 극복하는 핵심적인 기여이다.
Video-driven face reenactment
-
워핑 기반 방법 (Warping-based methods)
- 원리: 소스 프레임(source frame)과 타겟 프레임(target frame) 사이의 워핑 플로우(warping flows)를 예측한다.
- 적용: 예측된 워핑 플로우를 사용하여 타겟 이미지 또는 이미지에서 추출된 특징(features)을 소스 움직임에 맞춰 변형한다.
- 예시 연구: First Order Motion Model for Image Animation, One-shot free-view neural talking-head synthesis for video conferencing 등이 있다.
-
합성 기반 접근법 (Synthesis-based approaches)
- 원리: 입력 이미지에서 중간 표현(intermediate representations)을 학습한 다음, 이 표현들을 생성기(generator)로 직접 보내어 이미지를 합성한다.
- 중간 표현의 종류:
- 랜드마크(landmarks): 얼굴의 특정 지점들을 나타내는 정보이다. 예: LI-Net: Large-Pose Identity-Preserving Face Reenactment Network, LandmarkGAN: Synthesizing faces from landmarks, One-shot identity-preserving portrait reenactment
- 3D 얼굴 모델 파라미터 또는 메쉬(meshes): 3D 얼굴 모델의 형상이나 움직임을 제어하는 파라미터 또는 3D 메시 형태의 데이터이다. 예: UniFaceGAN: A Unified Framework for Temporally Consistent Facial Video Editing, Deep video portraits, PIRenderer: Controllable portrait image generation via semantic neural rendering, Face2Face: Real-Time Face Capture and Reenactment of RGB Videos
- 이미지에서 추출된 잠재 특징(latent features): 딥러닝 모델이 이미지에서 학습한 추상적인 특징 표현이다. 예: Finding directions in GAN’s latent space for neural face reenactment, Neural Head Reenactment with Latent Pose Descriptors, Latent Image Animator: Learning to Animate Images via Latent Space Navigation
- 최근 동향: 일부 최근 방법들은 사전 학습된 2D GAN (Analyzing and Improving the Image Quality of StyleGAN)으로부터 얻은 사전 지식(prior knowledge)을 활용하여 얼굴 이미지를 애니메이션화한다.
-
본 논문의 접근 방식:
- 본 논문에서 제안하는 방법은 합성 기반 접근 방식(synthesis-based approach)에 기반을 둔다.
- 핵심: 설계된 진보적인 비분리 표현 학습(progressive disentangled representation learning) 전략을 통해 여러 얼굴 움직임에 대한 비분리 잠재 표현(disentangled latent representations)을 학습한다.
- 특이점: 다른 비디오 기반 접근 방식과 달리, 립 모션(lip motion)은 오디오 신호(audio signals)를 통해 제어한다는 차이점이 있다.
Disentangled representation learning on the face
얼굴의 Disentangled Representation Learning은 얼굴 이미지나 비디오에서 여러 시각적 요소를 독립적인 잠재 표현으로 분리하여 학습하는 연구 분야이다. 이 연구는 오랫동안 지속되어 왔으며 다양한 접근 방식이 탐구되어 왔다.
-
비지도 표현 학습(Unsupervised representation learning) 방법:
- 초기 연구들 [11, 12, 18, 26, 33, 36, 41, 63]은 InfoGAN [12]과 β-VAE [26]와 같은 비지도 학습(unsupervised learning)에 중점을 두었다.
- 그러나 이 방법들은 인간의 인지(human perception)와 잘 일치하는 의미 있는 잠재 표현을 보장하지 못한다는 한계 [38]가 있었다. 즉, 모델이 스스로 분리한 요소들이 우리가 직관적으로 이해하는 얼굴의 특정 속성(예: 표정, 포즈)과 정확히 대응되지 않을 수 있다는 의미이다.
-
사전 학습된 2D GAN 잠재 공간 편집(Latent space editing of pre-trained 2D GAN) 방법:
- 최근에는 사전 학습된 2D GAN [31]의 잠재 공간을 편집하는 방법 [49–51, 65, 76, 80]이 주목받았다.
- 이 방법들은 특정 분류기(classifier)의 도움을 받아 원하는 얼굴 속성에 대한 분리된 제어를 달성한다.
- 하지만, 이러한 제어 가능성은 주로 선형 분류기(linear classifiers)와 사전 학습된 생성기(generator)의 데이터 분포(data distribution)에 의해 제한되는 경향이 있었다. 복잡하거나 미묘한 제어에는 한계가 있음을 시사한다.
-
강력한 사전 지식(Prior knowledge) 활용 방법:
- 일부 방법 [16, 19, 22, 47, 48, 67]은 3D 얼굴 모델 [45] 또는 표정 모델 [47]과 같은 더 강력한 사전 지식을 활용하여 표현 학습을 안내한다.
- 이들은 구조화된 데이터(structured data)에 대한 특정 훈련 스키마(training schemes)를 개발하여 원하는 요소 분리(factor disentanglement)를 달성한다. 이는 비지도 학습이나 단순 GAN 편집보다 더 정확하고 의미 있는 분리를 가능하게 하는 접근 방식이다.
-
본 논문의 접근 방식:
- 본 논문은 신중하게 설계된 점진적(progressive) 훈련 스키마를 통해 비디오 데이터에서 분리된 표현 학습을 달성한다.
- 또한, 특정 사전 모델 [15]을 도입하여 정확한 요소 제어(accurate factor control)를 돕는다. 이는 이전 방법들이 가진 한계(예: 비지도 학습의 의미 부족, GAN 편집의 제어 제한)를 극복하고 다양한 얼굴 요소를 효과적으로 분리하여 현실적인 Talking Head를 생성하는 데 기여한다.
3. Method
-
연구 목표
- 주어진 임의의 인물 이미지로부터 Talking Head 비디오를 합성하는 것이 목표이다.
- 합성된 비디오에서는 립 모션(lip motion), 고개 움직임(head pose), 눈 응시 및 깜빡임(eye gaze&blink), 감정 표현(emotional expression) 등 각 얼굴 움직임을 프레임별로 개별적으로 제어할 수 있다.
- 립 모션은 오디오 클립에서, 다른 모션들은 각각 다른 비디오로부터 파생되도록 의도한다.
-
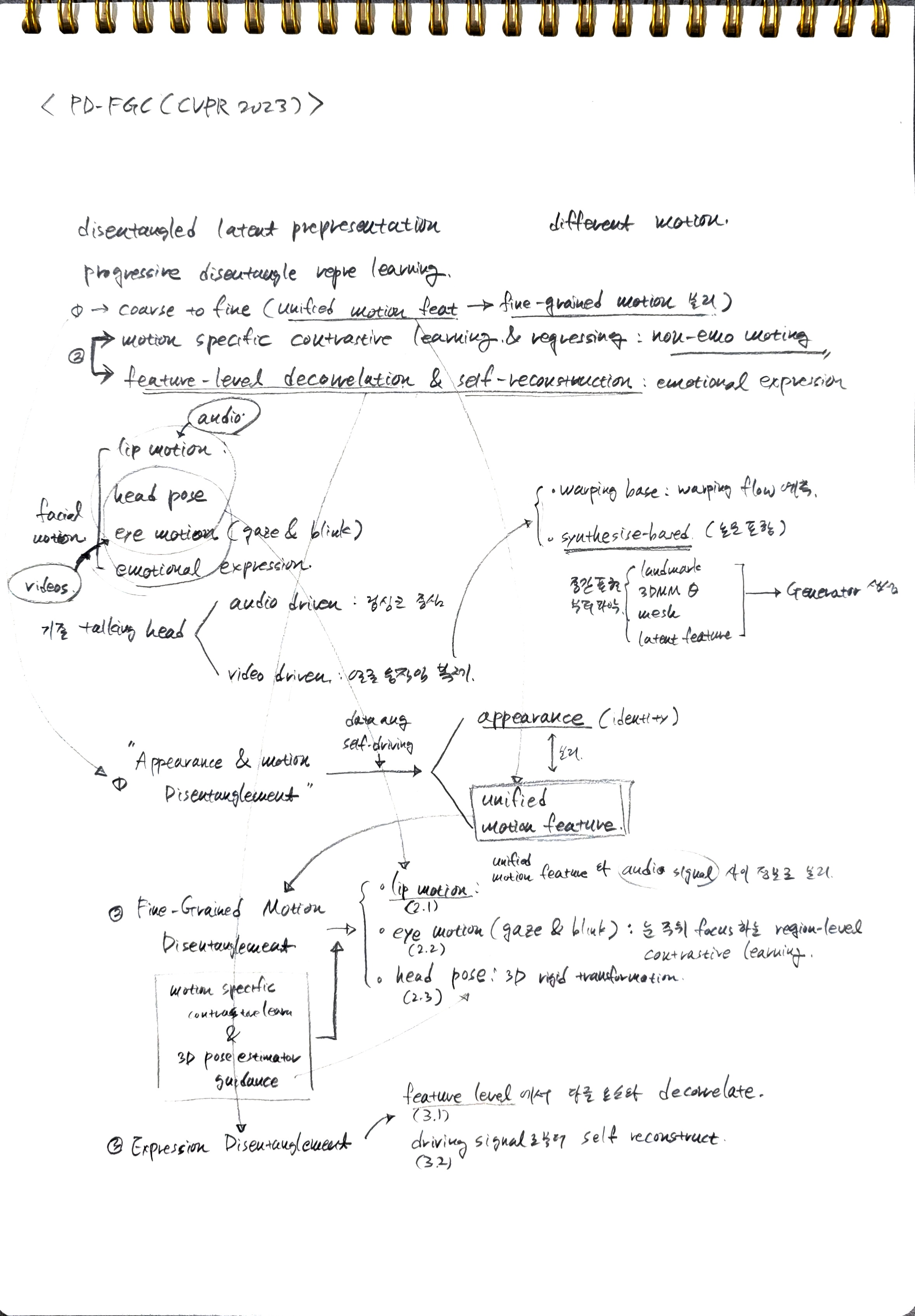
제안하는 방법론: Progressive Disentangled Representation Learning
- 핵심 아이디어: 제어 가능한 모든 얼굴 움직임과 외모(appearance)를 disentangled latent representations (분리된 잠재 표현)을 통해 표현하고, 이 잠재 표현들을 입력으로 받아 Talking Head를 합성하는 image generator를 학습하는 것이다.
- 학습 전략: 잠재 표현들을 "coarse-to-fine"(거칠게에서 세밀하게) 방식으로 학습하는 Progressive Disentangled Representation Learning 기법을 도입한다. 이 전략은 세 단계로 구성된다.
-
1단계: Appearance 및 Motion Disentanglement (Sec. 3.1)
- 목표: 외모(appearance)와 얼굴 움직임(facial motions)을 분리하여 '통합 모션 특징(unified motion representation)'을 얻는 것이다.
- 역할: 이 통합 모션 특징은 외모 정보는 배제하고 모든 모션 정보를 기록하며, 이후 세분화된 모션 분리를 위한 강력한 시작점으로 작용한다.
-
2단계: Fine-Grained Motion Disentanglement (Sec. 3.2)
- 목표: 통합 모션 특징으로부터 립 모션, 눈 응시 및 깜빡임, 고개 움직임 등 세분화된 개별 모션 특징을 분리하는 것이다 (감정 표현은 이 단계에서 제외).
- 방법: 각 모션의 고유한 특성에 기반한 'motion-specific contrastive learning'을 통해 이를 수행한다.
-
3단계: Expression Disentanglement (Sec. 3.3)
- 목표: 감정 표현을 다른 모션들로부터 분리하고, 동시에 세분화된 제어가 가능한 Talking Head 합성을 위한 image generator를 학습하는 것이다.
- 방법: 'feature-level decorrelation'을 통해 감정 표현을 다른 모션과 분리하며, image generator의 'self-reconstruction'을 통해 의미론적으로 정확한 감정 표현을 학습한다.
3.1. Appearance and Motion Disentanglement
이 섹션은 정교하게 제어 가능한 Talking Head를 합성하기 위한 첫 번째 단계인 '외모(Appearance)'와 '움직임(Motion)'을 분리하는 과정에 대해 설명한다.
-
목표:
- 다양한 미세한 움직임 요소를 효과적으로 분리하기 위해, 외모(즉, 신원) 정보는 배제하고 모든 종류의 움직임 정보만을 기록하는 통합된 움직임 표현 (unified motion representation)을 학습하는 것이 주된 목표이다.
- 이 통합된 움직임 특징은 이후 단계에서 더욱 세밀한 움직임 요소들을 분리하는 강력한 출발점 역할을 한다.
-
주요 구성 요소 및 학습 방법:
- 외모 인코더 (): 외모를 나타내는 이미지에서 외모 특징을 추출한다.
- 움직임 인코더 (): 드라이빙(driving) 프레임에서 움직임 특징을 추출한다.
- 생성자 (): 에서 추출한 외모 특징과 에서 추출한 움직임 특징을 결합하여 얼굴 이미지를 합성한다.
- Self-driving 및 Reconstruction: 이 전체 파이프라인은 원본 논문 Neural Head Reenactment with Latent Pose Descriptors의 방법을 따라 학습된다.
- 데이터 증강(Data Augmentation): 움직임 브랜치에 데이터 증강을 적용하여, 움직임 인코더가 외모 변화에는 영향을 받지 않고 오직 움직임 정보 추출에만 집중하도록 강제한다.
- 외모 인코더 ()의 입력 이미지: 하나의 비디오 시퀀스에서 무작위로 추출된 K개의 프레임 집합으로, 사람의 고유한 아이덴티티(얼굴 특징, 조명, 옷 등 포즈와 무관한 정보)를 추출하는 데 사용된다.
- 움직임 인코더()의 입력 이미지: 논문에 따르면, 는 Neural Head Reenactment with Latent Pose Descriptors에 따라 K개의 프레임과 별개로 선택된 하나의 홀드아웃(hold-out) 프레임 K+1이다. 이 프레임은 포즈는 그대로 유지하면서 스케일, 블러, 샤프닝, 대비 등을 이용하여 아이덴티티 관련 정보를 교란한다.
-
움직임 재구성 손실():
- 추출된 움직임 특징의 정확도를 더욱 향상시키기 위해, 원본 논문 Neural Head Reenactment with Latent Pose Descriptors의 학습 손실 위에 움직임 재구성 손실을 추가한다.
- 수식은 다음과 같다.
- 각 항의 의미:
- : 움직임 재구성 손실(Motion Reconstruction Loss)이다. 합성된 이미지의 움직임 특징이 실제 이미지의 움직임 특징과 얼마나 잘 일치하는지 측정한다.
- : 외모 특징과 움직임 특징을 입력으로 받아 생성자 에 의해 합성된(synthesized) 이미지이다.
- : 실제(ground truth) 이미지이다.
- : EMOCA: Emotion driven monocular face capture and animation에서 참조된 3D 얼굴 재구성 네트워크에 의해 추출된 특징이다. 이는 주로 얼굴의 3D 포즈(pose)와 같은 기하학적 움직임 정보를 나타낸다.
- : EMOCA: Emotion driven monocular face capture and animation에서 참조된 감정 네트워크에 의해 추출된 특징이다. 이는 주로 얼굴 표정(emotional expression)과 관련된 움직임 정보를 나타낸다.
- : L2-norm을 나타내며, 두 특징 벡터 간의 유클리드 거리를 계산하여 차이의 크기를 측정한다.
- 역할: 이 손실은 합성된 이미지 의 3D 포즈 및 감정 관련 특징이 실제 이미지 의 해당 특징에 최대한 가깝도록 강제한다. 이를 통해 는 외모는 유지하면서도 드라이빙 프레임의 움직임을 정확하게 재구성하는 법을 학습하게 된다.
3.2. Fine-Grained Motion Disentanglement
이 부분은 통일된 모션 특징(unified motion feature)으로부터 입술 움직임 특징(lip motion feature)을 분리하는 방법에 대해 설명한다.
-
목표: 이전 단계에서 얻은 통일된 모션 특징에서 입술 움직임, 눈 움직임(시선 및 깜빡임), 머리 자세 특징을 더 세부적으로 추출하는 것이 목표이다. 특히 이 단계에서는 감정 표현(expression)을 분리하지 않는데, 이는 감정 표현이 다른 요소들과 강하게 얽혀 있기 때문이며, 이는 최종 단계(3.3절)에서 다루어진다.
-
핵심 아이디어: 각 모션의 고유한 특성을 기반으로 모션별 대비 학습(motion-specific contrastive learning)을 설계하거나, 모션을 잘 설명하는 사전 모델(prior model)의 도움을 받는다.
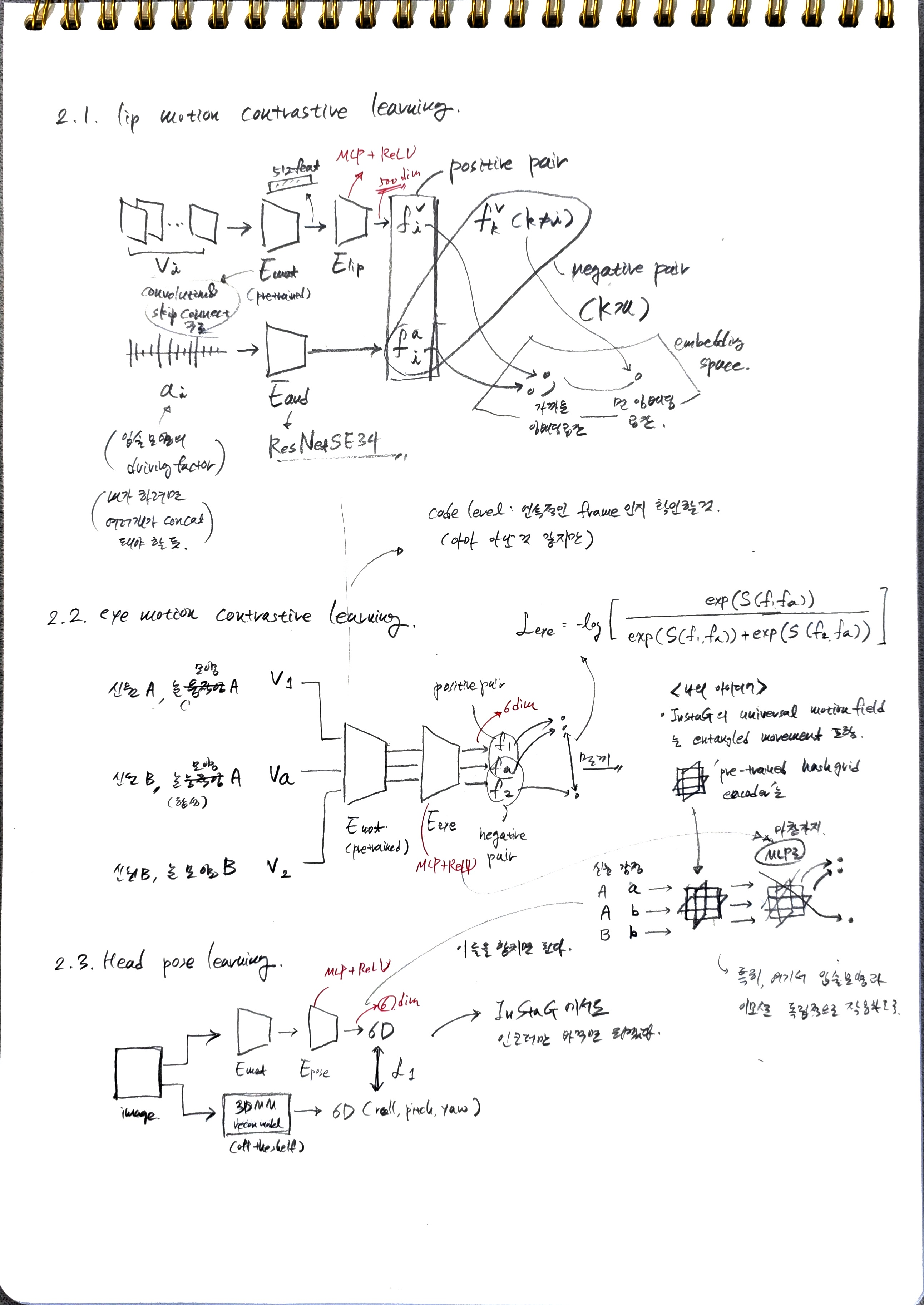
Lip motion contrastive learning:
- 분리 원리: 입술 움직임은 통일된 모션 특징과 해당 음성 오디오 간의 공유 정보를 활용하여 다른 모션과 잘 분리될 수 있다는 점을 이용한다. 이는 이전 연구 [77]에서 입증된 바 있다.
- 인코더 도입:
- 입술 움직임 인코더 와 오디오 인코더 가 도입된다.
- 은 이전 단계에서 미리 학습된(pre-trained) 모션 인코더이다.
- 특징 추출:
- 비디오 프레임 집합 와 해당 오디오 신호 가 주어진다.
- 입술 움직임 특징 는 으로 추출된 통일된 모션 특징에 를 적용하여 얻는다.
- 오디오 특징 는 를 통해 얻는다.
- 대비 쌍 구성:
- 각 샘플링된 오디오 특징 에 대해, 양성 오디오-비디오 쌍 과 개의 음성 오디오-비디오 쌍 를 구성한다.
- 마찬가지로 비디오 특징 에 대해서도 동일한 방식으로 양성 및 음성 쌍을 구성한다.
- 손실 함수 적용: InfoNCE 손실 [43]을 적용하여 양성 쌍 간의 유사도를 최대화하고 음성 쌍 간의 유사도를 최소화한다.
- 수식 설명:
- : 오디오를 비디오로 매핑하는 방향의 손실 함수이다.
- : 비디오를 오디오로 매핑하는 방향의 손실 함수이다.
- : 두 특징 벡터 사이의 코사인 유사도(cosine similarity)를 계산하는 함수이다. 코사인 유사도는 두 벡터의 방향이 얼마나 유사한지를 나타낸다.
- : 번째 오디오 신호로부터 를 통해 추출된 오디오 특징이다.
- : 번째 비디오 프레임으로부터 과 를 통해 추출된 입술 움직임 특징이다.
- : 번째 오디오 특징 와 짝지어진 음성 비디오 특징으로, 번째 프레임이 아닌 다른 프레임에서 추출된 입술 움직임 특징이다. 인 경우이다.
- : 번째 비디오 특징 와 짝지어진 음성 오디오 특징으로, 번째 오디오가 아닌 다른 오디오에서 추출된 오디오 특징이다. 인 경우이다.
- : 음성 샘플의 개수를 나타낸다.
- 두 손실 함수는 분자의
positive pair유사도를 높이고, 분모의positive pair와negative pair유사도 합에서positive pair유사도의 비율을 높이는 방식으로 작동한다. 이는positive pair의 유사도를 최대화하고negative pair의 유사도를 최소화하는 효과를 가져온다.
-
기여 및 활용: 이 손실 함수는 와 에 의해 예측된 입술 움직임 특징이 상응하는 비디오 프레임과 오디오에 대해 서로 가깝도록 보장한다. 오디오 신호는 주로 입술 움직임 정보만 포함하고 있기 때문에, 이 과정은 더 나은 요소 분리(factor disentanglement)에 도움이 된다. 또한, 학습된 오디오 인코더는 오디오 구동 입술 움직임 합성(audio-driven lip motion synthesis)에 활용될 수 있다.
Eye motion contrastive learning
-
핵심 아이디어: 눈 움직임(눈 응시 및 깜빡임)은 얼굴의 다른 부위에 미치는 영향이 적은 국소적인 움직임이라는 점에 기반한다.
-
합성 이미지 생성: 두 개의 원본 드라이빙 프레임 v1과 v2가 주어졌을 때, v1의 눈 영역과 v2의 다른 얼굴 영역을 합성하여 새로운 '앵커 프레임' va를 생성한다.
-
특징 추출: 별도의 눈 움직임 인코더 Eeye를 사용하여 v1, v2, va로부터 각각의 눈 움직임 특징인 를 추출한다.
-
대조 쌍 구성:
- 긍정 쌍(positive pair)은 로 구성된다. v1의 눈과 v2의 나머지 부분을 합성한 va는 v1의 눈 특징을 유지해야 한다는 아이디어에 기반한다.
- 부정 쌍(negative pair)은 로 구성된다. va는 v2의 눈 특징을 가지지 않아야 하므로 이 둘은 부정적으로 연결된다.
-
InfoNCE 손실 함수: 이러한 쌍들을 사용하여 InfoNCE 손실 ()을 적용한다. 이 손실은 긍정 쌍의 유사성은 최대화하고 부정 쌍의 유사성은 최소화하여, Eeye가 오직 눈 영역의 움직임에만 집중하고 다른 얼굴 영역의 변화에는 둔감하도록 학습시킨다.
-
수식 설명:
- 는 코사인 유사도(cosine similarity)를 계산하는 함수이다. 두 특징 벡터가 얼마나 같은 방향을 향하고 있는지를 나타낸다.
- 는 각각 드라이빙 프레임 v1, 앵커 프레임 va, 드라이빙 프레임 v2에서 추출된 눈 움직임 특징이다.
- 는 지수 함수로, 유사도 값을 양수로 만들고 상대적인 크기를 강조한다.
- 는 InfoNCE 손실 함수이다. 이 손실은 과 사이의 유사도를 높이는 동시에 와 사이의 유사도를 낮추는 방식으로 눈 움직임 인코더 Eeye가 학습되도록 유도한다.
-
샘플링된 프레임의 연속성 및 무작위성
- 선택된 텍스트와 보충 자료(Supplementary Material)에 따르면, 명시적으로 프레임이 연속적인지 혹은 무작위로 추출되는지에 대한 정보는 제공되어 있지 않다.
- 하지만 "두 개의 드라이빙 프레임 과 가 주어졌을 때"라는 표현은 특정 시점에서 선택된 임의의 두 프레임일 가능성이 크다.
- 특히, "한 사람의 눈 영역을 다른 사람의 눈 영역으로 대체하여 새로운 이미지를 합성한다면, 이 새로운 이미지에서 추출된 눈 움직임 특징은 눈 영역을 제공한 후자의 사람의 특징과 동일해야 한다"는 아이디어는 과 가 서로 충분히 다른 눈 움직임이나 얼굴 영역을 가진 프레임일 때 disentanglement 효과를 더 명확하게 확인할 수 있다. 따라서 연속된 프레임보다는 무작위 또는 특정 기준으로 선택된 비연속적인 프레임일 가능성이 높다. 보충 자료의 Figure I에서 보여주는 예시에서도, 눈 영역 소스 이미지와 배경 소스 이미지가 시각적으로 다른 순간이나 사람의 눈에서 왔을 가능성을 시사한다.
-
배치 내 Positive/Negative 샘플 생성 및 개수
- 생성 방식: Eye motion contrastive learning은 각 배치(batch) 내에서 positive 및 negative 샘플을 동적으로(on-the-fly) 생성하여 훈련하는 방식이다. 이는 contrastive learning의 일반적인 접근 방식과 일치한다.
- 개수: 선택된 텍스트에는 다음과 같이 명시되어 있다.
- "두 개의 드라이빙 프레임, 즉 과 가 주어졌을 때, 의 눈 영역과 의 다른 영역을 합성하여 앵커 프레임 를 구성한다."
- ", , 에서 눈 움직임 특징을 추출하고, 긍정 쌍 와 부정 쌍 를 구성한다."
- 이는 하나의 앵커 프레임 에 대해 하나의 긍정 쌍과 하나의 부정 쌍이 생성됨을 의미한다.
- 배치 크기: 보충 자료(Appendix A.2)에 따르면, Eye motion disentanglement 단계에서 는 배치 크기 128(batchsize of 128)로 훈련된다. 따라서, 각 배치에서는 128개의 앵커 프레임이 처리되며, 결과적으로 128개의 긍정 쌍과 128개의 부정 쌍이 형성되어 손실 계산에 사용된다고 추론할 수 있다.
-
-
데이터셋 규모와 이터레이션 수
- 데이터셋: VoxCeleb2 [13] 데이터셋의 학습 스플릿(training split)에 있는 모든 가용 동영상을 사용하여 훈련한다. VoxCeleb2는 대규모 화자 인식 데이터셋으로, 수십만 개의 발화(utterances)와 수천 명의 화자를 포함한다.
- 훈련 기간: 보충 자료에 따르면 네트워크는 30 에포크(epochs) 동안 훈련되었으며, 이는 4개의 Tesla V100 GPU에서 2일이 소요되었다고 명시되어 있다.
- 이터레이션 수 추정: 정확한 이터레이션 수는 전체 데이터셋의 크기, 배치 크기, 에포크 수를 알아야 계산할 수 있다.
- VoxCeleb2 학습 데이터셋은 약 100만 개의 발화와 150시간의 비디오를 포함한다.
- 만약 각 비디오 클립에서 하나의 드라이빙 프레임 쌍 (, )이 무작위로 추출된다고 가정하고, 이 데이터셋에 약 100만 개의 프레임이 있다고 가정한다면 (실제로는 비디오이므로 훨씬 많음),
- 1 에포크당 이터레이션 수
- 총 이터레이션 수 = 1 에포크당 이터레이션 수 에포크 수
- 하지만 여기서는 "총 학습 샘플 수"를 명확하게 정의하기 어렵다. "모든 가용 동영상"에서 "드라이빙 프레임 "를 어떻게 샘플링하는지에 대한 세부 정보가 없기 때문이다.
- 그러나 30 에포크 동안 2일의 훈련 시간과 배치 크기 128이라는 정보는 이 학습 과정이 대규모 데이터셋을 효율적으로 활용했음을 시사한다. 학습률 감쇠(decay rate)가 80,000 이터레이션마다 발생한다는 점을 고려하면, 대략적인 총 이터레이션 수를 추정해 볼 수 있다.
- 2일 훈련 기간 동안 80,000 이터레이션마다 학습률이 감쇠된 것을 보면, 30 에포크 동안 상당한 수의 이터레이션이 진행되었을 것이다. (예: 만약 총 이터레이션이 160,000 이라면, 두 번의 학습률 감쇠가 있었을 것이다.)
- 정확한 수치를 알기는 어렵지만, 수십만에서 수백만 이터레이션에 걸쳐 훈련되었을 가능성이 높다.
-
머리 자세 학습 (Head pose learning)
-
핵심 아이디어: 머리 자세(Head pose)는 피치(pitch), 요(yaw), 롤(roll)의 세 가지 오일러 각(Euler angles)과 3D 변환으로 구성된 6차원(6D) 파라미터로 명확하게 정의될 수 있다는 점을 활용한다.
-
회귀 학습: 머리 자세 인코더 Epose는 이러한 6D 파라미터를 직접 회귀(regress)하도록 학습된다.
-
3D Face Prior 모델 활용: 학습 과정에서는 외부의 3D 얼굴 재구성 모델 [15]이 제공하는 ground truth 머리 자세 파라미터()를 가이드로 사용한다.
-
L1 손실 함수: Epose가 예측한 머리 자세 파라미터()와 ground truth 파라미터() 사이의 L1 거리(절대 오차)를 최소화하는 방식으로 학습이 진행된다.
-
수식 설명:
- 는 머리 자세 인코더 Epose에 의해 예측된 머리 자세 파라미터이다.
- 는 외부 3D 얼굴 재구성 모델 [15]로부터 얻은 ground truth(정답) 머리 자세 파라미터이다.
- 는 L1 노름(norm)을 나타낸다. 이는 두 벡터의 각 요소별 차이의 절댓값들을 모두 더한 값이다. 즉, 예측된 머리 자세 파라미터와 실제 머리 자세 파라미터 간의 절대 오차를 최소화하는 것을 목표로 한다.
- 는 Epose를 학습하기 위한 손실 함수이다. 이 손실을 최소화함으로써 Epose는 실제 머리 자세와 일치하는 파라미터를 정확하게 예측하도록 학습된다.
-
3.3. Expression Disentanglement
Progressive Disentangled Representation Learning의 세 번째이자 마지막 단계는 표정(Emotional Expression)을 다른 모션 요인들과 분리하는 것이다.
-
도전 과제
- 다른 모션과의 높은 연관성: 감정적인 표정은 입 움직임과 같은 다른 얼굴 움직임과 매우 밀접하게 얽혀 있다. 예를 들어, 같은 말을 하더라도 감정에 따라 입 모양이 다를 수 있다.
- 정확한 가이드의 부족: 기존의 표정 추정기(expression estimator)는 종종 표정 외의 다른 모션 정보도 함께 포함하고 있어, 순수한 표정 분리 학습에 정확한 가이드를 제공하기 어렵다.
-
해결 전략
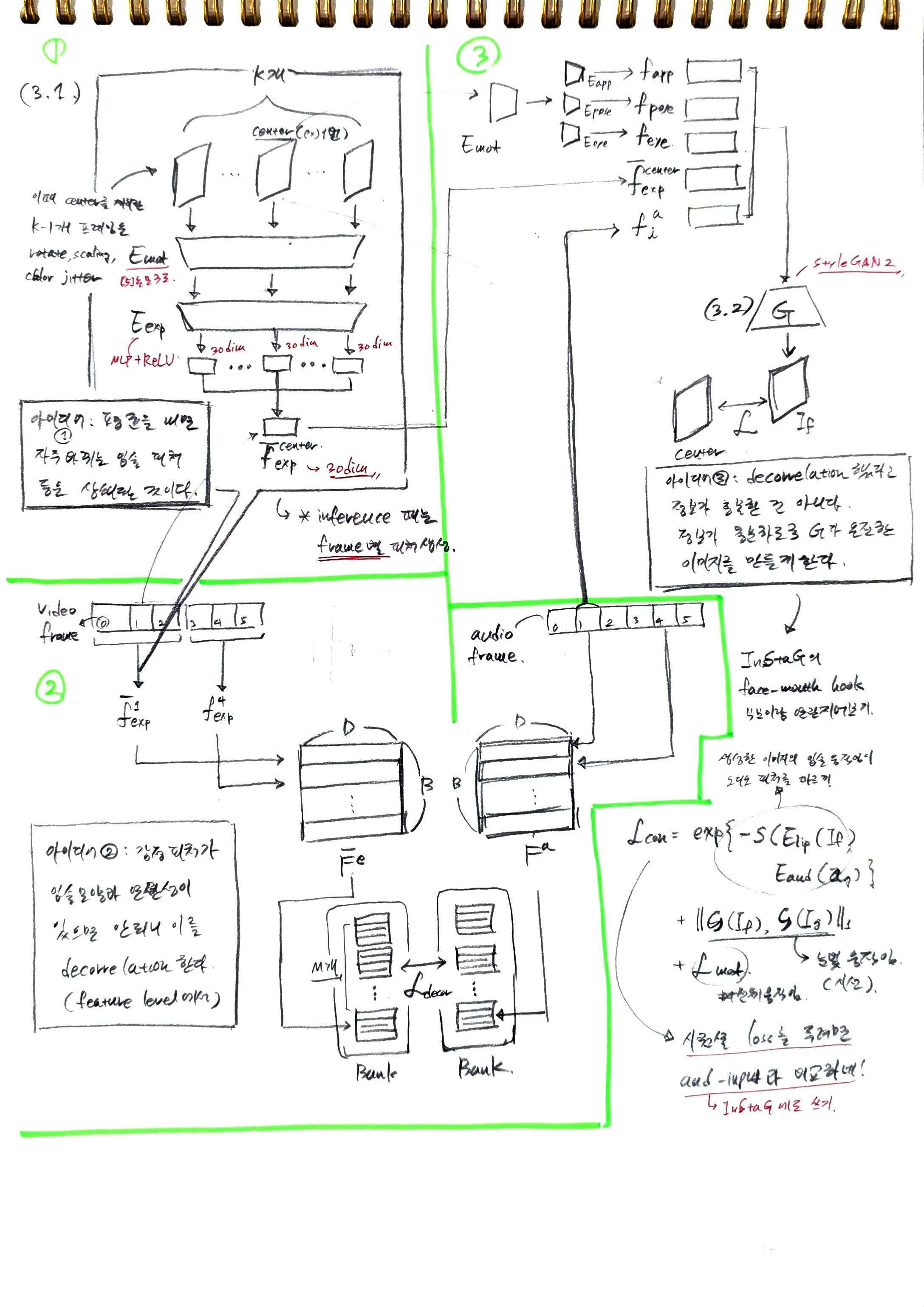
이러한 도전 과제를 해결하기 위해, 이 방법은 "feature-level decorrelation" 전략과 "self-reconstruction"을 통한 보완 학습을 제안한다. 핵심 가설은 추출된 표정 특징이 다른 모션 특징과 독립적이면서도, 이들을 결합했을 때 원본 driving 신호의 모든 얼굴 움직임을 충실하게 재구성할 수 있다면, 그것이 정확한 표정의 잠재 표현이라는 것이다.-
In-window decorrelation (윈도우 내 상관관계 제거)
- 개념: 비디오 시퀀스에서 표정 변화는 다른 움직임(예: 입술 움직임, 시선)보다 빈번하지 않다는 관찰에 기반한다.
- 작동 방식: 특정 프레임을 중심으로 시간 윈도우(크기 )를 설정하고, 이 윈도우 내의 프레임들로부터 추출된 표정 특징들의 평균을 계산한다. 이 평균 특징을 중심 프레임의 표정 특징으로 사용함으로써, 윈도우 내에서 평균화되는 동안 다른 모션 정보는 상쇄되어 표정 특징에서 제거되고, 순수한 표정 특징만 남게 된다. 이 평균 특징은 이후 이미지 생성기 로 전송되어 이미지 합성 및 자가 재구성에 사용된다.
-
Lip-motion decorrelation (입술 움직임 상관관계 제거)
이 부분은 표현 특징(expression feature)과 립 모션 특징(lip motion feature, 오디오 특징으로 간주됨) 간의 독립성을 강화하여, 감정 표현을 다른 얼굴 움직임으로부터 더 잘 분리(disentanglement)하기 위해 도입된 손실 함수에 대해 설명하고 있다. 감정 표현은 입술 움직임과 본질적으로 얽혀 있기 때문에(예: 같은 말을 해도 감정에 따라 입 모양이 다를 수 있음) 이를 분리하는 것은 매우 어려운 과제이다. 이 손실은 이러한 얽힘을 줄이는 데 도움을 준다.손실 함수는 다음과 같다:
-
: 립 모션 디코릴레이션 손실이다. 이 값이 낮을수록 표현 특징과 립 모션 특징 간의 상관관계가 적다는 것을 의미하며, 이는 두 특징이 서로 독립적으로 분리되었음을 나타낸다.
-
: 배치(batch) 크기 를 가진 평균 표현 특징들의 행렬이다. 차원은 이다.
- 여기서 배치 내에서 평균화된 표현 특징(average expression feature)을 사용하는데, 이는 'in-window decorrelation' 전략에서 파생된 것이다. 즉, 일정 시간 윈도우(window) 내의 프레임들에서 추출한 표현 특징들을 평균화하여, 감정 표현을 제외한 다른 움직임 정보(특히 립 모션)를 희석시킨 '클린'한 표현 특징을 얻으려는 목적이다.
-
: 대응하는 오디오 특징들의 행렬이다. 이 역시 차원은 이다. 오디오 신호는 주로 립 모션 정보만을 포함한다고 가정하기 때문에, 립 모션 특징으로 간주된다.
-
: 특징 벡터의 차원이다. 즉, 각 특징( 또는 )이 가지고 있는 값의 개수이다.
-
: 두 행렬 간의 특징 차원(feature dimension) 상관관계를 계산하는 함수이다. 이 함수는 와 의 각 차원(예: 첫 번째 특징 차원끼리, 두 번째 특징 차원끼리 등) 사이의 상관계수를 계산한다.
-
: 는 배치 크기, 는 특징 차원을 의미하며, 이 기호는 배치 내의 모든 특징 차원에 걸쳐 상관관계의 제곱을 합산한다는 것을 나타낸다. 상관관계의 제곱을 사용함으로써 양의 상관관계와 음의 상관관계 모두를 최소화하려는 목표이다.
-
: 상관관계 값에 제곱을 하여, 상관관계의 절댓값을 최소화하도록 강제한다. 즉, 양의 상관관계든 음의 상관관계든 모두 0에 가깝게 만들어서 두 특징이 서로 독립적이 되도록 만든다.
-
슬라이딩 윈도우: 이 윈도우는 비디오 시퀀스를 따라 순차적으로 이동한다. 즉, 다음 중심 프레임을 위해 윈도우가 한 칸씩 이동하며 위 과정을 반복한다.
손실 함수의 작동 방식 및 중요성: -
독립성 강제: 이 손실 함수는 와 사이의 상관관계를 0으로 만들려고 시도한다. 즉, 오디오 신호가 주로 립 모션에 대한 정보를 포함하고 있으므로, 표현 특징이 립 모션 특징과 무관해지도록 학습시킨다. 이는 감정 표현이 입술 움직임에 얽매이지 않고 독립적으로 제어될 수 있도록 돕는다.
-
실용적인 고려사항: 메모리 뱅크: 일반적으로 두 변수 간의 상관관계를 정확하게 계산하기 위해서는 매우 큰 배치 크기가 필요하다. 하지만 딥러닝 모델 훈련 시 메모리 제한으로 인해 큰 배치 크기를 유지하기 어렵다. 이 논문에서는 이 문제를 해결하기 위해 두 개의 메모리 뱅크(memory banks)를 사용한다.
메모리 뱅크는 현재 배치 외에 이전 반복(iteration)에서 얻은 개의 최신 특징들을 저장한다. 이 은 현재 배치 크기보다 훨씬 크다.
따라서 상관관계 계산 시에는 현재 배치 특징과 메모리 뱅크에 저장된 이전 특징들을 함께 사용하여 더 많은 데이터를 기반으로 정확한 상관관계를 추정한다.
* 하지만 네트워크 가중치 업데이트를 위한 그래디언트(gradient)는 현재 배치 특징을 통해서만 역전파(back-propagate)된다. 이는 메모리 사용을 효율적으로 관리하면서도 안정적인 학습을 가능하게 한다.이 "립 모션 디코릴레이션" 전략은 표현과 립 모션이라는 두 가지 중요한 얼굴 움직임 요소가 서로에게 미치는 영향을 최소화하여, 각 요소를 독립적으로 제어할 수 있는 기반을 마련한다.
상관관계 cor를 구하는 건 코사인 유사도 기반인가?
- 제시된 수식 에서 함수가 구체적으로 어떤 상관관계(correlation)를 계산하는지에 대한 명시적인 언급은 없다. 하지만 일반적인 딥러닝 문맥에서 특징 벡터 간의 상관관계를 다룰 때 몇 가지 흔한 방식이 있다.
- 피어슨 상관계수(Pearson Correlation Coefficient) 기반: 두 변수 간의 선형 관계를 측정하는 가장 일반적인 방법이다. 이 논문에서 "feature dimension correlation"을 계산한다고 했으므로, 이는 와 의 각 특징 차원(dimension)별로 피어슨 상관계수를 계산할 가능성이 높다. 예를 들어, 의 첫 번째 차원 벡터와 의 첫 번째 차원 벡터 간의 상관관계를 계산하는 식이다. 이 경우, 는 일반적으로 다음과 같이 정의된다:
여기서 와 는 각 특징 차원의 값들을 모은 벡터가 된다. 이 방법은 두 특징이 얼마나 선형적으로 함께 변화하는지를 측정하며, 상관관계가 0에 가까울수록 독립적이라고 간주한다. - 코사인 유사도(Cosine Similarity) 기반: 코사인 유사도는 두 벡터의 방향이 얼마나 유사한지를 측정하는 방법이다. 값이 1에 가까우면 매우 유사하고, -1에 가까우면 매우 반대 방향이며, 0에 가까우면 직교(독립)한다고 해석할 수 있다. 코사인 유사도는 와 같이 표현될 수 있으며, 이 논문의 다른 부분에서 InfoNCE loss에서 사용되는 가 코사인 유사도라고 명시되어 있다 ( is the cosine similarity).
만약 가 코사인 유사도를 의미한다면, 두 특징 벡터의 방향이 직교하도록(즉, 코사인 유사도가 0이 되도록) 강제함으로써 독립성을 부여하는 것으로 해석할 수 있다. - 결론적으로, 명확하게 언급되어 있지 않지만, "feature dimension correlation"이라는 표현은 피어슨 상관계수와 같은 통계적인 상관관계를 계산할 가능성이 더 높다. 코사인 유사도는 주로 벡터의 유사도를 측정할 때 사용되며, 통계적 상관관계와는 조금 다른 의미를 가진다. 하지만 딥러닝에서는 두 개념이 종종 혼용되거나 유사한 목적으로 사용되기도 한다. 만약 이 논문에서 가 와 동일하게 코사인 유사도를 의미한다면, 이는 두 특징의 방향적 독립성을 강조하는 것이 된다. 일반적으로 상관관계를 0으로 만들려고 할 때는 피어슨 상관계수를 더 많이 사용한다.
는 프레임별 피처를 평균낸 거니까, 에서 D를 구성하는 피처는 모두 동일한 값인가?
- 아니다. 에서 를 구성하는 피처들이 모두 동일한 값이라는 것은 오해이다.
- 는 "a matrix consisting of average expression features within a batch of size "라고 명시되어 있다.
- 이는 각 행이 하나의 샘플(즉, 하나의 배치 아이템)에 대한 평균 표현 특징 벡터를 나타내며, 총 개의 행이 있다는 의미이다.
- 각 평균 표현 특징 벡터는 개의 요소를 가지고 있으며, 이 개의 요소들이 해당 샘플의 표현 특징을 나타낸다. 즉, 각 행이 차원의 벡터이다.
- "프레임별 피처를 평균낸 거니까" 라는 부분은 'in-window decorrelation' 전략을 의미한다.
- 이 전략에서 하나의 중심 구동 프레임(center driving frame)에 대해, 그 주변의 개 프레임(시간 윈도우)에서 각각 표현 특징을 추출한다.
- 그리고 이 개의 특징 벡터들을 평균하여 하나의 평균 표현 특징 벡터를 얻는다. 이 평균 특징 벡터가 바로 의 각 행(batch item)에 해당하는 차원의 벡터가 되는 것이다.
- 예를 들어, 윈도우 크기 이라면 13개의 프레임에서 각각 추출한 30차원(Expression feature dimension)의 특징 벡터를 평균하여 1개의 30차원 평균 표현 특징 벡터를 만든다.
- 따라서 행렬의 각 행은 개의 서로 다른 값으로 구성된 벡터이다. 이 개의 값들은 해당 샘플의 표현 특징을 나타내는 여러 차원들이다. 각 차원이 동일한 값을 가질 필요는 없으며, 보통 서로 다른 값을 가진다.
- 만약 이고 배치 크기 라고 가정한다면, 는 행렬이 된다.
여기서 은 첫 번째 샘플에 대한 평균 표현 특징 벡터이고, 은 이 벡터의 30개 차원을 구성하는 값들이다. 이 값들은 일반적으로 서로 다르다. 두 번째 샘플 도 마찬가지이다.
-
-
첫 번째 아이디어: "더 많은 데이터를 기반으로 정확한 상관관계를 추정한다." (메모리 뱅크 사용)
- 문제점: 상관관계(correlation)를 통계적으로 정확하게 계산하려면 많은 수의 데이터 샘플이 필요하다. 딥러닝 훈련에서는 배치(batch) 단위로 데이터를 처리하는데, GPU 메모리 한계 때문에 이 배치 크기를 무한정 키울 수 없다. 배치 크기가 작으면, 해당 배치 내의 샘플들만으로 계산된 상관관계는 전체 데이터 분포를 제대로 반영하지 못하고 노이즈가 많을 수 있다.
- 해결책: 메모리 뱅크: 이 문제를 해결하기 위해 메모리 뱅크(Memory Bank)를 사용한다.
- 메모리 뱅크는 과거의 여러 배치에서 추출된 특징 벡터들을 저장하는 일종의 '버퍼'이다.
- 예를 들어, 현재 배치 크기가 16이고 메모리 뱅크 크기 이 512라고 가정한다.
- 현재 훈련 단계에서 개의 와 개의 특징을 추출한다.
- 상관관계를 계산할 때는 이 개의 현재 특징뿐만 아니라, 메모리 뱅크에 저장된 이전 개의 와 개의 특징들을 합쳐서 사용한다.
- 이렇게 하면 개의 샘플에 해당하는 특징들을 기반으로 상관관계를 계산하게 된다. 이는 단일 배치(16개)만 사용하는 것보다 훨씬 더 안정적이고 전체 데이터 분포에 가까운 상관관계 추정치를 제공한다.
-
두 번째 아이디어: "네트워크 가중치 업데이트를 위한 그래디언트(gradient)는 현재 배치 특징을 통해서만 역전파(back-propagate)된다."
- 문제점: 메모리 뱅크의 특징들까지 모두 그래디언트 계산에 사용한다면, 사실상 배치 크기가 가 되는 것과 같으므로 여전히 메모리 문제가 발생한다. 또한, 메모리 뱅크의 특징들은 오래된 가중치로 추출된 것이라 현재 가중치에 직접적으로 그래디언트를 역전파하는 것이 비효율적일 수 있다.
- 해결책: 그래디언트 역전파는 오직 현재 배치에서 추출된 특징들만을 통해서 이루어진다.
- 메모리 뱅크의 특징들은 상관관계 값을 "계산"하는 데는 사용되지만, 그 특징들을 추출하는 데 사용된 과거 네트워크의 가중치로는 그래디언트가 흘러가지 않도록 그래디언트 흐름을 차단(detach)한다.
- 즉, 손실 가 계산된 후 역전파가 시작될 때, 메모리 뱅크에서 온 특징 값들은 상수(constant) 취급을 받는다. 이 특징 값들은 네트워크 가중치를 업데이트하는 데 사용되는 그래디언트 계산에 기여하지 않는다.
- 오직 현재 배치에서 새로 추출된 와 에 대해서만 해당 특징을 생성한 인코더(Eexp, Eaud)의 가중치로 그래디언트가 역전파되어 가중치가 업데이트된다.
-
Complementary learning via self-reconstruction (자가 재구성을 통한 보완 학습)
-
개념: 위 두 가지 상관관계 제거 전략이 특징의 독립성을 보장하지만, 추출된 표정 특징 자체의 의미론적 의미는 부족할 수 있다. 이를 위해 이미지 생성기 를 활용하여 표정 특징에 의미론적 의미를 부여한다.
-
작동 방식: 이미지 생성기 는 외모 특징, 다른 모션 특징(입술 움직임, 머리 포즈, 시선/눈 깜빡임)과 함께 표정 특징을 입력받아, driving 프레임을 자가 재구성하도록 학습된다.
-
이 과정에서 표정 인코더 는 다른 모든 모션 특징에 포함되지 않은 (즉, 순수한) 표정 정보를 학습하도록 강제된다.
-
여러 손실 함수가 와 를 학습하는 데 사용된다.
-
VGG Loss (): 합성된 이미지()와 Ground Truth 이미지() 간의 VGG 특징 맵 차이를 측정하여 이미지의 시각적 유사성을 높인다.
- : 미리 학습된 VGG19 [53] 네트워크의 번째 레이어에서 추출된 특징 맵이다.
- : 사용된 VGG 레이어의 총 개수이다.
- : 생성된 이미지이다.
- : Ground Truth 이미지이다.
-
Adversarial Loss 및 Discriminator Feature Matching Loss: [6]에 따라 적용되어 합성된 이미지의 품질을 개선한다.
-
Motion-level consistency loss (): 합성된 이미지가 driving 프레임의 모든 얼굴 움직임을 잘 따르도록 보장한다.
- : 이 값은 motion-level consistency loss를 나타낸다. 이 손실은 합성된 이미지의 움직임이 원본 드라이빙 프레임의 움직임과 일치하는지를 측정한다.
- : 이 항은 입술 움직임 동기화에 관한 손실이다.
- : 두 입력 벡터 간의 코사인 유사도를 계산하는 함수이다. 코사인 유사도는 두 벡터의 방향이 얼마나 유사한지를 측정하며, 부터 까지의 값을 가진다.
- : 미리 학습된 입술 움직임 인코더 가 합성된 이미지 에서 추출한 입술 움직임 특징이다.
- : 오디오 인코더 가 ground truth 오디오 에서 추출한 오디오 특징이다.
- 이 항은 합성된 이미지의 입술 움직임 특징과 ground truth 오디오 특징 사이의 코사인 유사도를 최대화하여, 오디오와 입술 움직임이 잘 동기화되도록 유도한다. 유사도가 높을수록 값은 작아져 손실이 줄어든다.
- : 이 항은 시선 (eye gaze) 일관성에 관한 손실이다.
- : 시선 추정기 (gaze estimator) [1]이다. 이는 입력 이미지에서 시선 방향을 추정한다.
- : 생성된 이미지 (synthesized image)이다.
- : ground truth 이미지이다.
- 이 항은 생성된 이미지 에서 추정된 시선과 ground truth 이미지 에서 추정된 시선 사이의 L1 Norm (절대 오차)을 계산한다. 이 값을 최소화하여 합성된 이미지의 시선이 ground truth와 일치하도록 한다.
- : 이 항은 motion reconstruction loss이다. 이 손실은 논문의 Eq. (1)에 정의되어 있으며, 합성된 이미지의 전반적인 움직임 특징이 ground truth 이미지의 움직임 특징과 유사하도록 강제한다. 이를 통해 합성된 이미지의 다양한 얼굴 움직임 요소들이 드라이빙 프레임의 움직임을 정확하게 반영하도록 한다.
-
-
-
-
-
결론: 이러한 자가 재구성 과정은 특징 수준의 상관관계 제거 전략과 결합되어 표정 특징을 통합 모션 특징으로부터 성공적으로 분리한다. 또한, 이 단계에서 학습된 이미지 생성기 는 분리된 모든 모션 특징과 외모 특징을 입력으로 받아 세밀하게 제어 가능한 Talking Head 합성을 가능하게 한다.
