
딥러닝 프레임워크
- 딥러닝 프레임워크의 기본
- tensor 생성하고 다루기
- 연산 정의
- 최적화(미분)
- 데이터 다루기
환경 세팅
!pip install tensorflow==2.7.0
!pip install torch==1.10.0 torchvision==0.11.1 torchtext==0.11.0 torchaudio==0.10.0Tensor 다루기
1. Constant
import tensorflow as tf
import numpy as npTensor
- Deeplearning framework는 기본적으로 Tensor를 다루는 도구다.
- Tensor를 다룰 때 가장 중요한 것
→ SHAPE 확인!!!
(해보면 알겠지만, 제일 에러 많이 나는 이유, 제일 헷갈리는 것, 개발할 때 우리가 이론을 알아야 하는 이유, 함수들의 설정값을 확인해야하는 이유)
Tensor 생성
- 우리가 생성하는 것은 tf.Tensor 데이터!
- 항상 체크 해야 할 것 !
- shape
- dtype (데이터 타입이 같아야 연산이 가능합니다.)
- Constant (상수)
tf.constant()- list -> Tensor
- tuple -> Tensor
- Array -> Tensor
li_ten = tf.constant([1, 2, 3])
li_ten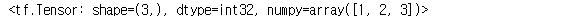
li_ten_f = tf.constant([1., 2., 3.])
li_ten_f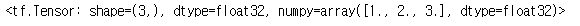
tu_ten = tf.constant(((1, 2, 3), (1, 2, 3)), name="sample")
tu_ten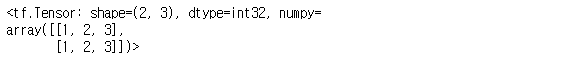
arr = np.array([1., 2., 3.]) #, dtype='float64')
arr_ten = tf.constant(arr)
arr_ten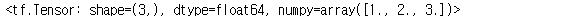
Numpy array 추출
arr_ten.numpy(), type(arr_ten.numpy())
li_ten.numpy(), type(li_ten.numpy())
shape, dtype 항상 체크!!
li_ten.shape, tu_ten.shape
arr_ten.dtype, li_ten.dtype
데이터 type 컨트롤하는 방법
tf.cast
# 미리 지정해주거나
tensor = tf.constant([1, 2, 3], dtype=tf.float32)
tensor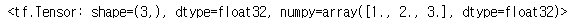
# tf.cast를 사용. 다만, 많은 경우 미리 데이터 타입을 정리해둘 수 있다.
tf.cast(tensor, dtype=tf.int16)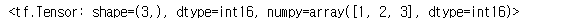
특정 값의 Tensor 생성
tf.onestf.zerostf.range
tf.ones(1)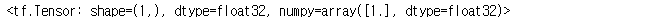
tf.zeros((2, 5), dtype = 'int32')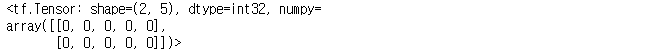
tf.range(10)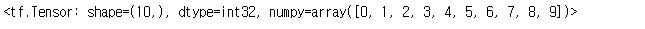
tf.range(1, 11)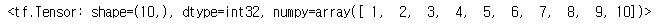
Random Value(난수)
- 무작위 값을 생성할 때 필요.
- Noise를 재현 한다거나, test를 한다거나 할 때 많이 사용됨
- 데이터 타입은 상수형태로 반환됨
tf.random에 구현 되어 있음.
tf.random.normal- Gaussian Normal Distribution
tf.random.uniform- Uniform Distribution
shape = (3, 3) # shape은 튜플 형태로tf.random.normal(shape)
tf.random.normal(shape, mean = 100, stddev = 10)
- tf.random.uniform
- TensorFlow에서 Uniform Distribution
tf.random.uniform(shape)
- Random seed 관리 하기!!!
- Random value로 보통 가중치를 초기화
- 이외에도 학습과정에서 Random value가 많이 사용됨.
- 이를 관리 안해주면, 자신이 했던 작업이 동일하게 복구 또는 재현이 안됨!!!
tf.random.set_seed({seed_number})
-> 항상 Random seed를 고정해두고 개발 한다!!!
(주의 할 점은 해당 개발물에 사용되는 난수가 모두 TensorFlow에서 생성된것이 아닐 수 있다는 것)
seed = 7777tf.random.set_seed(seed)
a = tf.random.uniform([1])
b = tf.random.uniform([1])
print(a, b, sep="\n")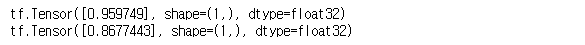
a = tf.random.uniform([1])
b = tf.random.uniform([1])
print(a, b, sep="\n")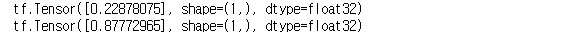
tf.random.set_seed(seed)
a = tf.random.uniform([1])
b = tf.random.uniform([1])
print(a, b, sep="\n")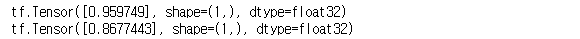
2. Variable
Variable (변수)
- 미지수, 가중치를 정의할 때 사용
- 직접 사용할 일이 많지는 않음
- 변수 정의는 변수 생성 + 초기화
tensor = tf.constant([[1.0, 2.0], [3.0, 4.0]])
arr = np.array([[1, 2], [3, 4]])
li = [[1, 2], [3, 4]]
te_var = tf.Variable(tensor)
arr_var = tf.Variable(arr)
li_var = tf.Variable(li)
print(te_var)
print(arr_var)
print(li_var)
- Constant와 같이 기본 속성값이 들어있음
print("Shape: ", te_var.shape)
print("DType: ", te_var.dtype)
print("As NumPy: ", te_var.numpy)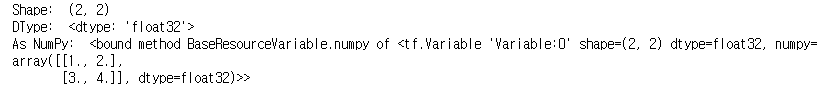
변수는 기존 텐서의 메모리를 재사용하여 텐서를 재할당 할 수 있다.
a = tf.Variable([2.0, 3.0])
print("First : ", a, "\n")
a.assign([1, 2]) # 초기값은 float 기준으로 생성되었기 때문에 [1, 2]로 해도 float
print("Second : ", a, "\n")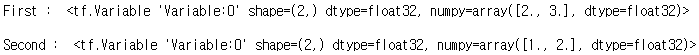
3. Tensor 연산
아래의 기본 연산은 특수 메서드를 이용하여 연산자 오버로딩이 되어 있으므로 그냥 연산자 기호를 사용하는게 가능!
tf.add: 덧셈tf.subtract: 뺄셈tf.multiply: 곱셈tf.divide: 나눗셈tf.pow: n-제곱tf.negative: 음수 부호
여러 가지 연산
tf.abs: 절대값tf.sign: 부호tf.round: 반올림tf.ceil: 올림tf.floor: 내림tf.square: 제곱tf.sqrt: 제곱근tf.maximum: 두 텐서의 각 원소에서 최댓값만 반환.tf.minimum: 두 텐서의 각 원소에서 최솟값만 반환.tf.cumsum: 누적합tf.cumprod: 누적곱
axis 이해하기
rank_2 = tf.random.normal((3, 3))
rank_2
rank_2[0]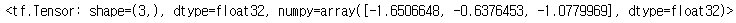
rank_2[0, 0]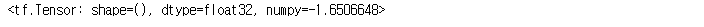
rank_3 = tf.random.normal((3, 3, 3))
rank_3
rank_3[0, 1, 2]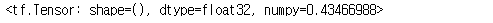
rank_4 = tf.random.normal((3, 3, 3, 3))
rank_4
rank_4[1, 2, 1, 2]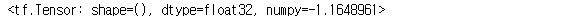
차원 축소 연산
tf.reduce_mean: 설정한 축의 평균을 구한다.tf.reduce_max: 설정한 축의 최댓값을 구한다.tf.reduce_min: 설정한 축의 최솟값을 구한다.tf.reduce_prod: 설정한 축의 요소를 모두 곱한 값을 구한다.tf.reduce_sum: 설정한 축의 요소를 모두 더한 값을 구한다.
tf.reduce_sum(a, axis=0) # shape은 스칼라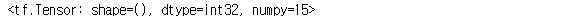
tf.reduce_sum(a, axis=0, keepdims=True) # shape은 벡터형태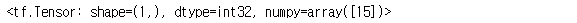
b = tf.random.normal([2, 7])
b
tf.reduce_mean(b, axis = 0) # 값 7개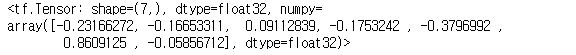
tf.reduce_mean(b, axis = 1) # 값 2개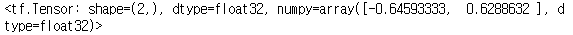
행렬과 관련된 연산
tf.matmul: 내적tf.linalg.inv: 역행렬
a = tf.constant([[2, 0], [0, 1]], dtype=tf.float32)
b = tf.constant([[1, 1], [1, 1]], dtype=tf.float32)
tf.matmul(a, b)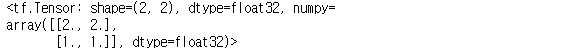
a = tf.constant([[2, 0], [0, 1]], dtype=tf.float32)
tf.linalg.inv(a)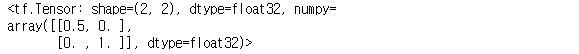
크기 및 차원을 바꾸는 명령
축을 잘 이해하고 사용면 좋음
tf.reshape: 벡터 행렬의 크기 변환tf.transpose: 전치 연산tf.expand_dims: 지정한 축으로 차원을 추가tf.squeeze: 벡터로 차원을 축소
a = tf.range(6, dtype=tf.int32) # [0, 1, 2, 3, 4, 5]
print("a :", a, "\n")
print('-' * 20)
a_2d = tf.reshape(a, (2, 3)) # 1차원 벡터는 2x3 크기의 2차원 행렬로 변환
print("a_2d :", a_2d, "\n")
print('-' * 20)
a_2d_t = tf.transpose(a_2d) # 2x3 크기의 2차원 행렬을 3x2 크기의 2차원 행렬로 변환
print("a_2d_t:", a_2d_t, "\n")
print('-' * 20)
a_3d = tf.expand_dims(a_2d, 0) # 2x3 크기의 2차원 행렬을 1x2x3 크기의 3차원 행렬로 변환
print("a_3d :", a_3d, "\n")
print('-' * 20)
a_4d = tf.expand_dims(a_3d, 3) # 1x2x3 크기의 3차원 행렬을 1x2x3x1 크기의 4차원 행렬로 변환
print("a_4d :", a_4d, "\n")
print('-' * 20)
a_1d = tf.squeeze(a_4d)
print("a_1d :", a_1d, "\n") # 1x2x3x1 크기의 4차원 행렬을 1차원 벡터로 변환
텐서를 나누거나 두 개 이상의 텐서를 합치는 명령
tf.slice: 특정 부분을 추출tf.split: 분할tf.concat: 합치기tf.tile: 복제-붙이기tf.stack: 합성tf.unstack: 분리
a = tf.reshape(tf.range(12), (3, 4))
a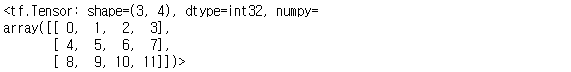
tf.slice(a, [0, 1], [2, 3]) # (0, 1)위치에서 (2개, 3개)만큼 뽑아낸다.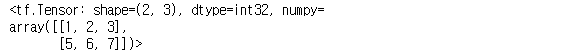
a1, a2 = tf.split(a, num_or_size_splits=2, axis=1) # 가로축(axis=1)을 따라 2개로 분할
print(a1)
print()
print(a2)
tf.concat([a1, a2], 1) # 가로축(axis=1)을 따라 a1, a2를 합치기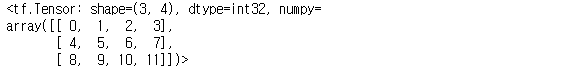
tf.concat([a1, a2], 0) # 세로축(axis=0)을 따라 a1, a2를 합치기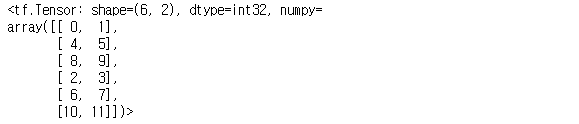
tf.tile(a1, [1, 3]) # 가로축(axis=1)을 따라 3개로 복사-붙이기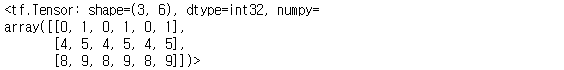
a3 = tf.stack([a1, a2]) # 3x2 행렬 a1, a2를 추가적인 차원으로 붙여서 2x3x2 고차원 텐서 생성
a3
tf.unstack(a3, axis=1) # 2x3x2 고차원 텐서를 0차원으로 풀어서 3개의 2x2 행렬 생성

Date Scientist & Data Analyst
제로베이스들을 데이터 취업 스쿨 예정인데 괜찮을까요? ㅠㅠ