아이펠 6일차가 시작되었다. 사실 진짜 어제 시작한것 같은데 벌써 일주일이나 지나버린게 굉장히 시간이 빠르구나 싶다.
원래같았으면 종강하고 1월 초까지는 놀다가 이제 슬슬 책을 폈을텐데, 아이펠 덕분에 조금 일찍 공부를 시작할 수 있었던 것 같다.
사실 저번주는 기록을 꼼꼼하게 안하고, 건너뛴 것도 많은것 같은데 이번주는 꼼꼼히 기록해봐야지,,!
또 중간중간에 쉬는시간, 노드 빨리 끝나면 남는시간이 꽤 되는데 이 시간을 잘 이용해야겠다.
오늘은 데이터 전처리 LMS + 파이썬 풀잎스쿨은 class가 진행범위였다!
LMS : 데이터 전처리
사실 데이터 전처리 (numpy, pandas)는 이번학기에도 수업을 들어서 조금 안다고 생각했는데, 복습을 안하니까 진짜 다 까먹는것 같다.. 열심히 기록해야지
* 결측치
print('컬럼별 결측치 개수')
len(trade) - trade.count()컬럼별 결측치는 이렇게 데이터프레임(trade)의 전체 갯수와 count를 빼주어 구할 수 있다.
이렇게 결측치를 구한후, 모든 행이 다 결측치인 열이 있다면,
trade = trade.drop('결측치 컬럼', axis =1)
이렇게 drop을 통해 컬럼을 한번에 삭제할 수 있다.
결측치가 있는 행은 isnull() 과 any(axis =1)로 파악할 수 있는데, 먼저 isnull()d은 데이터마다 결측치가 있으면 True로, 없으면 False를 반환한다.
any(axis =1 )은 행마다 True가 하나라도 있으면 True,아니면 False를 반환한다.
isnull, any를 함께 쓰게 되면 결측치가 있는 '행'만을 True로 확인할 수 있고, 이 True값을 데이터 프레임에 넣으면 어떤 값이 비어있는지 정확히 확인할 수 있다.
trade[trade.isnull().any(axis=1)]그렇다면 이 결측치는 어떻게 처리를 할까? 먼저, 여러 컬럼이 모두 결측치를 가지고 있다면 그 데이터 자체를 삭제하는 방법이 있다.
바로 dropna()를 활용하는 방법이다. 이전의 drop()은 그냥 특정 행 or 열을 삭제했다면, dropna()는 결측치가 있을때, 결측치가 있는 행 또는 열을 삭제해주는 메소드이다.
subset을 이용해 특정 컬럼들을 선택한 후, how옵션을 지정해주면 된다. any면 subset의 특정 칼럼들 중 하나라도 결측치가 있으면 삭제하는 것이고, all이면 모두 결측치가 있으면 삭제하는 것이다. inplace옵션을 사용하면 데이터프레임에 바로 적용 가능하다.
trade.dropna(how='all', subset=[결측치 있는 컬럼들], inplace=True)만약, 여러 열이 아니라 한 두 열만 빈 값이 있다면 어떻게 할까? 이 컬럼들이 수치형 데이터를 가질 경우, 데이터를 보완할 방법은 4가지가 있다.
- 특정 값 지정
- 평균, 중앙값으로 대체
- 다른 데이터를 이용한 예측값으로 대체
- 시계열 특성을 가진 데이터의 경우, 앞뒤 데이터를 통해 결측체 대체(전후 데이터의 평균 등)
* 중복된 데이터 확인
trade.duplicated()duplicated()는 중복된 데이터 여부를 불리안으로 반환해준다.
만약, True값이 있다면, 데이터프레임에 넣어 확인해볼 수 있다.
trade[trade.duplicated()]근데, '중복'이라면 총 2개가 나와야하는데, 이 경우엔 하나의 행밖에 출력되지 않는다. 여기서 출력된 행 이전에 이미 원본? 데이터가 있다는 것이다. 아래 코드로 확인할 수 있다.
trade[(trade['중복행']=='값')&(trade['중복행']=='값')]중복데이터는 어차피 모든 행이 중복이므로 중복된 데이터의 정보를 이용하여 조건 검색을 한다고 생각하자.
이번엔, 중복된 데이터를 삭제해보자
trade.drop_duplicates(inplace=True)drop_duplicates를 이용하여 삭제할 수 있다. inplace옵션을 이용하여 바로 데이터에 적용시킬 수 있다.
drop_duplicate의 keep옵션을 이용하면, 인덱스가 빠른 행을 남기는 것이 아니라, 인덱스가 나중인 행을 남기도록 지정할 수도 있다.
trade.drop_duplicates(keep='last', inplace=True)* 이상치(Outlier)
-
이상치란 값의 범위를 벗어나서 극단적으로 크거나 작은 값을 의미한다.
-
이상치가 있는 경우 다른 데이터들에 영향을 많이 미칠수 있다. 예를들어 minmax 스케일링을 하면 이상치를 제외한 데이터들이 한쪽에 몰려있는 현상이 나타난다.
그렇다면 이 아웃라이어를 어떻게 판단할까?
- z-score
첫번째 방법으로는 z-score(표준화)를 계산하는 방법이 있다.
z-score는 데이터값에서 평균을 빼고, 표준편차로 나눠주어 계산할 수 있다.
모든 데이터의 z-score을 계산하고, 일정 기준을 넘어서는 값을 아웃라이어로 지정하면 된다.
결측치를 판단한 다음에는 어떻게 할까?
1. 이상치를 삭제하거나 이상치끼리 따로 분석
2. 이상치는 다른 값으로 대체
3. 예측 모델을 만들어 예측값을 활용
4. binning을 통해 수치형을 범주형으로
이상치를 판단하는 함수를 만들어보자.
def outlier(df, col, z):
return df[abs(df[col] - np.mean(df[col]))/np.std(df[col])>z].index-
abs(df[col] - np.mean(df[col])) : 데이터에서 평균을 빼준 것에 절대값 씌우기
-
abs(df[col] - np.mean(df[col]))/np.std(df[col]) : 위에 한 작업에 표준편차로 나누기
-
df[abs(df[col] - np.mean(df[col]))/np.std(df[col])>z].index: 값이 z보다 큰 데이터의 인덱스를 추출
trade.loc[outlier(trade, '무역수지', 1.5)]trade데이터의 무역수지 컬럼에 z=1.5로 지정한다고 하면 위의 코드처럼 작성할 수 있다.
이제 non_outlier함수를 만들어 이상치가 아닌 값들만 확인해보자
def not_outlier(df, col, z):
return df[abs(df[col] - np.mean(df[col]))/np.std(df[col]) <= z].index- IQR
z-core은 2가지의 단점이 있다.
1) Robust하지 못하다 - 왜나하면 평균과 표준편차 자체가 이상치의 존재에 크게 영향을 받음
2) 작은 데이터셋의 경우 z-score의 방법으로 이상치를 알아내기 어렵다. 특히 item이 12개 이하인 데이터셋에서는 불가능
따라서 우리는 z-score의 대안으로 사분위 범위수(IQR)를 이용할 수 있다.
IQR=Q_3−Q_1
즉, IQR은 제 3사분위수에서 제 1사분위 값을 뺀 값으로 데이터의 중간 50%의 범위!
Q_1 -1.5IQR보다 왼쪽에 있거나, Q_3 +1.5IQR 보다 오른쪽에 있는 경우 이상치 판단
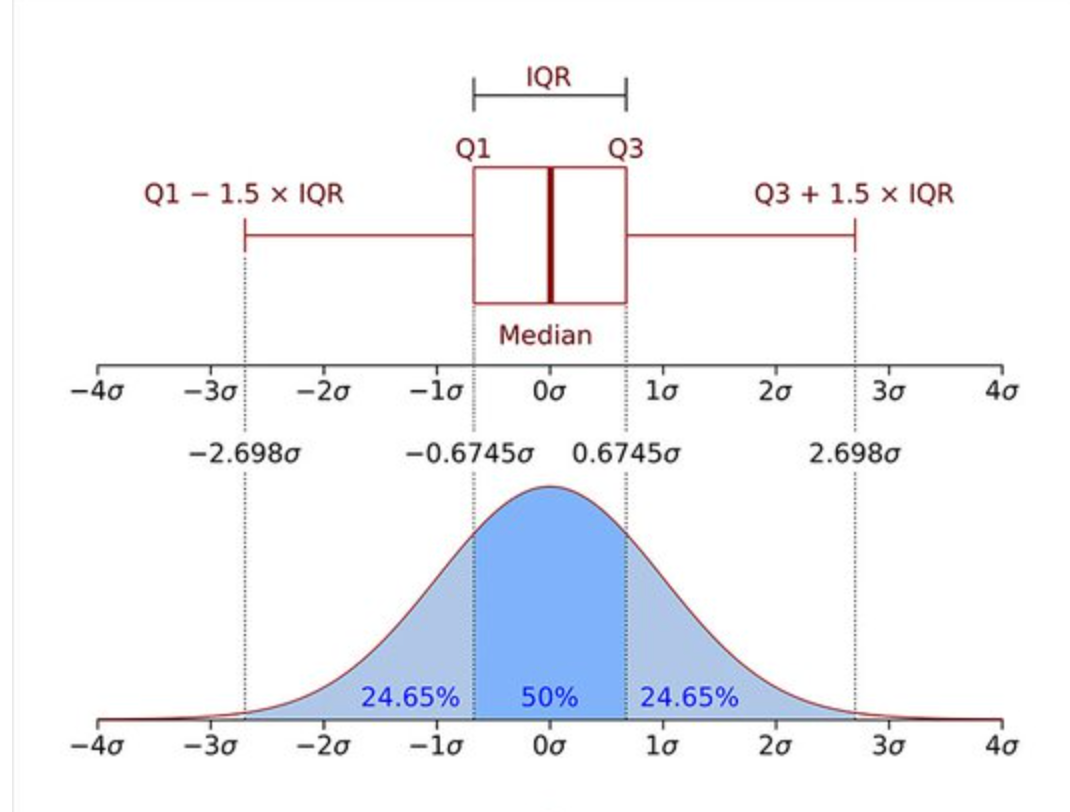
코드를 이용하여 구현해보자.
Q3, Q1 = np.percentile(data, [75 ,25])
IQR = Q3 - Q1
IQR
data[(Q1-1.5*IQR > data)|(Q3+1.5*IQR < data)]* 정규화(Normalization)
데이터 컬럼마다 스케일 차이가 크게 나면 모델에 영향을 줄 수 있기 때문에 정규화를 해줘야 한다. 데이터를 정규화하는 방법에는 Standardization과 Min-Max Scaling이 있다.
-
Standardization : 데이터의 평균은 0, 분산은 1로!
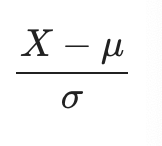
-
Min-Max Scaling 데이터의 최솟값은 0, 최댓값은 1로!
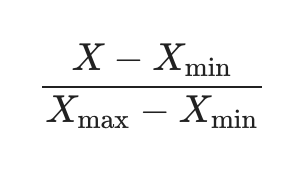
정규화를 할때에는 train set 과 test set을 같은 기준으로 해야함!
사이킷런의 StandardScaler, MinMaxScaler를 사용하면 매우 간편하게 할 수 있음
* 원-핫 인코딩(One-Hot Encoding)
- 원-핫 인코딩이란 카테고리별 이진 특성을 만들어 해당하는 특성만 1, 나머지는 0으로 만드는 방법
- 범주형 데이터를 다루기 위해서는 원-핫 인코딩이 필요함
- pandas에서 get_dummies 함수를 통해 손쉽게 원-핫 인코딩 가능
일단 get_dummies를 통해 원핫 인코딩 데이터프레임을 만들어준다.
# get_dummies를 통해 국가명 원-핫 인코딩
country = pd.get_dummies(trade['국가명'])
country.head()그 후, concat함수로 만든 데이터 프레임을 기존 데이터 프레임에 합쳐준다.
trade = pd.concat([trade, country], axis=1)
trade.head()마지막으로 원핫인코딩으로 변경하기 전의 컬럼을 삭제한다.
trade.drop(['국가명'], axis=1, inplace=True)
trade.head()구간화(Binning)
- 구간화는 연속적인 데이터를 구간을 나눠 분석할때 사용
- pandas의 cut과 qcut을 이용함
bins = [0, 2000, 4000, 6000, 8000, 10000] #먼저 구간을 나눠줌
ctg = pd.cut(data, bins=bins) #cut함수에 데이터와 구간을 입력하면 구간별로 데이터를 나눠줌
ctg위처럼 내가 직접 구간을 지정해줘도 되고, 구간의 개수를 지정해 줄 수도 있다.
ctg = pd.cut(data, bins=6)
ctg이렇게 bins 옵션에 정수를 입력하면 데이터의 최솟값에서 최댓값을 균등하게 bins 개수만큼 나눠준다.
qcut은 구간을 일정하게 나누는 것이 아니라 데이터의 분포를 비슷한 크기의 그룹으로 나눠줍니다.
ctg = pd.qcut(salary, q=5)
ctg위 코드는 데이터를 5개의 구간으로 나누는데, 각 구간의 크기가 일정한것이 아니라, 구간별 데이터의 개수를 일정하게 나누어준다!
이렇게 데이터 전처리에 관해 알아보았다. 내가 제일 못한다고 생각하는 부분이 데이터 전처리인데, 오늘 노드를 통해 한번 정리할 수 있었던것 같다.
아직 넘파이랑 판다스의 쓰임을 완전히 알지는 못하는것 같아서, 데이터를 다루기 전에, 데이터 전처리 연습을 진짜 충분히 해봐야겠다!
