1. Precision, Recall, F1-score
자연어처리에 있어서 다른 평가 지표에 가장 기본이 되는 것은 다른 task와 마찬가지로 Precision, Recall, F1-score이다. 따라서 해당 평가 지표들이 자연어처리에서 어떤 의미를 가지는지 간단하게 살펴본 이후 Precision, Recall, F1-score를 차용하는 자연어처리에서의 평가 지표들을 살펴보자.
1-1. Concept
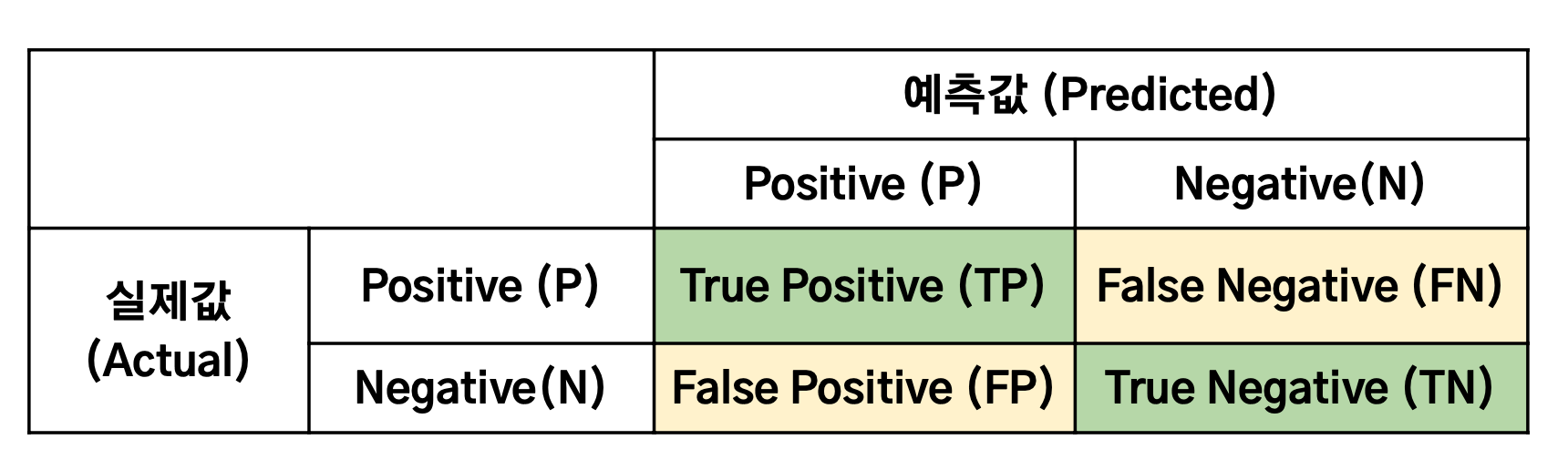
위의 Confusion Matrix를 바탕으로 Precision과 Recall을 계산하면 다음과 같다.
- : 모델이 맞았다고 예측한 것 중 실제로 맞은 비율
- : 실제 맞는 것들 중에 모델이 맞았다고 예측한 비율
일반적으로 Precision과 Recall은 서로 반비례를 갖기 때문에 뒤 지표를 종합적으로 평가하기 위해 F1-score를 사용한다.
1-2. In NLP
그렇다면 자연어처리에 있어
Precision과Recall은 무엇을 의미할까?
자연어처리에 있어서 아래 예시처럼 전체 문장이 아니라 고정된 위치에서 생성된 개별 토큰을 정답 토큰과 비교할 경우, 시퀀스 데이터의 특성상 처음 토큰이 기존 정답과 다르게 생성될 수 있으며 이로 인해 이후에 생성되는 토큰 역시 연쇄적으로 기존 정답과 다르게 생성될 수 있다.
- Reference(정답 문장) : I Love You
- Candidate(예측 문장) : Oh I Love You
따라서 개별 토큰이 아니라 전체 문장에 대해서 예측을 평가하기 위한 방법이 필요하고 이를 위해 기본적으로 Precision과 Recall을 사용할 수 있다. Precision과 Recall을 자연어처리에서 활용할 때는 다음과 같이 나타낼 수 있다.
- : 예측 문장의 단어 중 실제 정답과 일치하는 단어의 비율
- : 정답 문장의 단어 중 예측 문장과 일치하는 단어의 비율
1-3. Example
Reference : Admiral Lee Sun-shin is our nation's hero
Candidate : Admiral Yi Sun-shin is hero
위의 예시는 "이순신 장군은 우리의 영웅입니다"를 영어로 번역하는 작업의 Reference와 Candidate이다. 각각에 대해서 Precision과 Recall을 구해보자.
Precision과 Recall 모두 토큰이 등장한 순서와는 관계없이 일치하는 토큰의 수에 따라 계산되는 것을 확인할 수 있다. 이는 Precision과 Recall을 차용하는 다른 자연어처리 평가 지표의 단점이 되기도 한다.
2. Perplexity(PPL)
Perplexity는 문장의 길이로 정규화된, 문장을 생성할 확률의 역수로서 완성될 때까지의 선택된 토큰들의 누적된 확률을 기반으로 계산한 값이다.Perplexity는 당혹감, 혼란 등 단어가 가진 의미 그대로 모델이 토큰을 생성할 때 얼마나 헷갈렸는지를 나타내는 지표로,Perplexity가 낮을수록 모델이 덜 헷갈린 상태로 확신을 가지고 토큰을 생성했다고 할 수 있다. 즉 낮을수록 언어 모델의 성능이 좋은 것이다.- PPL은 결국 언어 모델이 특정 시점에서 평균적으로 몇 개의 선택지를 가지고 고민하고 있는지를 의미하는 분기계수(branching factor)를 나타낸다. 만약 PPL의 값이 10이라면 해당 언어 모델은 테스트 데이터에 대해 다음 단어를 예측하는 모든 시점마다 평균적으로 10개의 단어를 가지고 어떤 것이 정답인지 고민하고 있다고 할 수 있다.
- PPL은 테스트 데이터 상에서 높은 정확도를 보인다는 의미이지 사람이 직접 느끼기에 좋은 언어 모델이라는 것을 반드시 의미하지는 않는다.
3. BLEU(Bilingual Evaluation Understudy)
- 주로 기계 번역에서 활용되며 목표로 하는 문장(Reference)와 모델이 생성한 문장(Candidate)이 일치하는 정도를
Precision의 관점에서 수치화한 지표로,Perplexity와 달리 값이 클수록 성능이 더 좋음을 의미한다. - 번역 Task에서 Reference 중 몇 단어가 빠져도(즉
Recall이 떨어져도) 문장의 의미가 유사할 수 있지만, 문장에 없는 단어가 오역되어 생성되면(Precision이 떨어지면) 영향이 클 수 있기 때문에Recall이 아닌Precision을 차용했다. BLEU는 크게n-gram에 해당하는 부분과Brevity Penalty에 해당하는 부분으로 나눌 수 있다.- 동의어의 경우에는 의미는 유사하지만 토큰이 정확하게 일치하지 않기 때문에
BLEU는 문맥이나 의미 정보에 대한 평가가 어렵다는 한계를 지닌다.
3-1. N-gram
- 는 -gram을 통해 단어쌍들의 을 계산하는 것이다.
- n-gram(n = 1~4)의 n값에 따라 문장을 나눠서 정답값(ground truth)과 얼마나 겹치는지를 다각도로 평가하여 단어의 순서도 고려한다.
- clipping을 통해 같은 단어가 연속으로 나올 때 과적합 되는 것을 보정한다.
3-2. Brevity Penalty
Brevity Penalty는 Reference가 짧을 경우 제대로 번역이 이루어지지 않아도 높은Precision을 보이는데, 이처럼 문장 길이에 대해서 과적합되는 것을 방지하기 위해 Candidate 문장의 길이가 Reference 문장의 길이보다 짧을 경우 1 이하의 값을 곱하여Precision을 낮게 보정한다.
4. ROUGE
Recall-Oriented Understudy for Gisiting Evaluation의 약자로, 주로 요약이나 기계 번역 등의 생성 성능을 평가하기 위한 지표이며 목표로 하는 문장(Reference)과 모델이 생성한 문장(Candidate)이 일치하는 정도를 수치화한 지표이다.ROUGE에서는Recall의 관점에서 수치화한 지표이지만Precision을 사용하기도 한다. 이는BLEU와 유사하긴 하지만BLEU는Brevity Penalty의 제약이 존재하며 기하평균을 사용한다는 차이가 존재한다.
4-1. ROUGE-N
ROUGE-N은 unigram, bigram, trigram 등 문장 간 중복되는 n-gram을 비교하는 지표이다. 정답 문장을 Gold, 예측 문장을 Pred라고 하고 아래의 예시 문장에 대해서 ROUGE-N을 구해보자.
Gold : the cat was under the bed
Pred : under the bed there was the cat
a. ROUGE-1
Gold : [the], [cat], [was], [under], [the], [bed]
Pred : [under], [the], [bed], [there], [was], [the], [cat]
Gold와 Pred의 겹치는 unigram의 수는 [the], [cat], [was], [under], [the], [bed] 총 6개이다. 따라서 Precision과 Recall을 구하면 다음과 같다.
b. ROUGE-2
Gold : [the cat], [cat was], [was under], [under the], [the bed]
Pred : [under the], [the bed], [bed thre], [there was], [was the], [the cat]
Gold와 Pred의 겹치는 bigram의 수는 [the cat], [the bed], [under the] 총 3개이다. 따라서 Precision과 Recall을 구하면 다음과 같다.
4-2. ROUGE-L
ROUGE-L은 가장 긴 공통 시퀀스(LCS)를 기반으로 한다. LCS란 최대 길이를 가지는 공통 하위 시퀀스를 말하며 ROUGE-N과 같이 단어들의 연속적인 매칭을 요구하지 않으며 문장 내에서 최장 길이로 매칭되는 문자열의 길이를 이요하기 때문에 보다 유연한 성능 비교가 가능하다.
Gold : the cat was under the bed
Pred : under the bed there was the cat
Gold와 Pred 사이의 LCS는 [under the bed]이기 때문에 Precision과 Recall을 구하면 다음과 같다.
5. Tips to read generation metrics
사실 요즘 위에서 살펴본 지표의 고질적인 단점은 LLM 시대에 이르러서는 해당 지표들만으로 과연 성능을 제대로 보여줄 수 있는지에 대한 의문이라고 할 수 있다. 그래서 보다 종합적인 성능 평가를 위해 다양한 평가 지표들이 도입되었으며 여러 지표들을 동시에 사용하는 것이 일반적이다.METEOR 뿐만 아니라 BELURT, BERTScore, G-eval 등도 얼른 공부하도록 하자.