RAG와 관련된 공부를 하던 와중에
EnsembleRetriever에서sparse retriever와dense retriever를 결합하여 사용한다는 내용을 봤다.sparse retriever는 키워드를 기반으로 쿼리와 관련 문서를 찾는 데에 효과적이며,dense retriever는 의미적 유사성을 기반으로 관련 문서를 찾는 데에 효과적이다. 여기서sparse retriever의 대표격인BM25Retriever는BM25라는 알고리즘을 사용하여 문서를 검색하는 방식이다.BM25는 주어진 쿼리에 대해 문서와의 연관성을 평가하는 키워드 기반 정보 탐색(Information Retrieval) 알고리즘으로,TF-IDF계열의 검색 알고리즘 중 가장 빈번하게 활용된다. 따라서 이번 기회에BM25와 해당 알고리즘의 근간이 되는TF-IDF에 대해서 정리해보고자 한다.
1. Word Presentation
단어 표현(word representation)은 크게 극소 표현(sparse representation)과 밀집 표현(dense representation)으로 나뉜다.
1-1. sparse representation
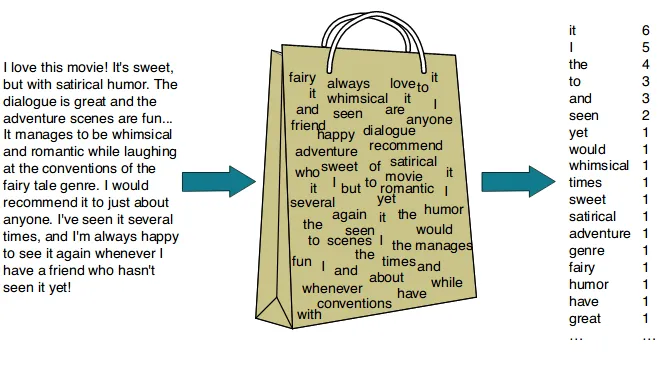
- 해당 단어 그 자체만 보고, 특정 값(ex. 해당 단어가 등장한 빈도 수)에 맵핑하여 단어를 표현하는 방법으로, 순서나 문맥을 고려하지 않기 때문에 해당 단어의 의미를 담을 수 없으며 단어 간의 유사성을 판단하기 어렵다.
One-Hot Encoding,Bag of Words,TF-IDF등의 방식이 여기에 속한다.
1-2. dense represenation
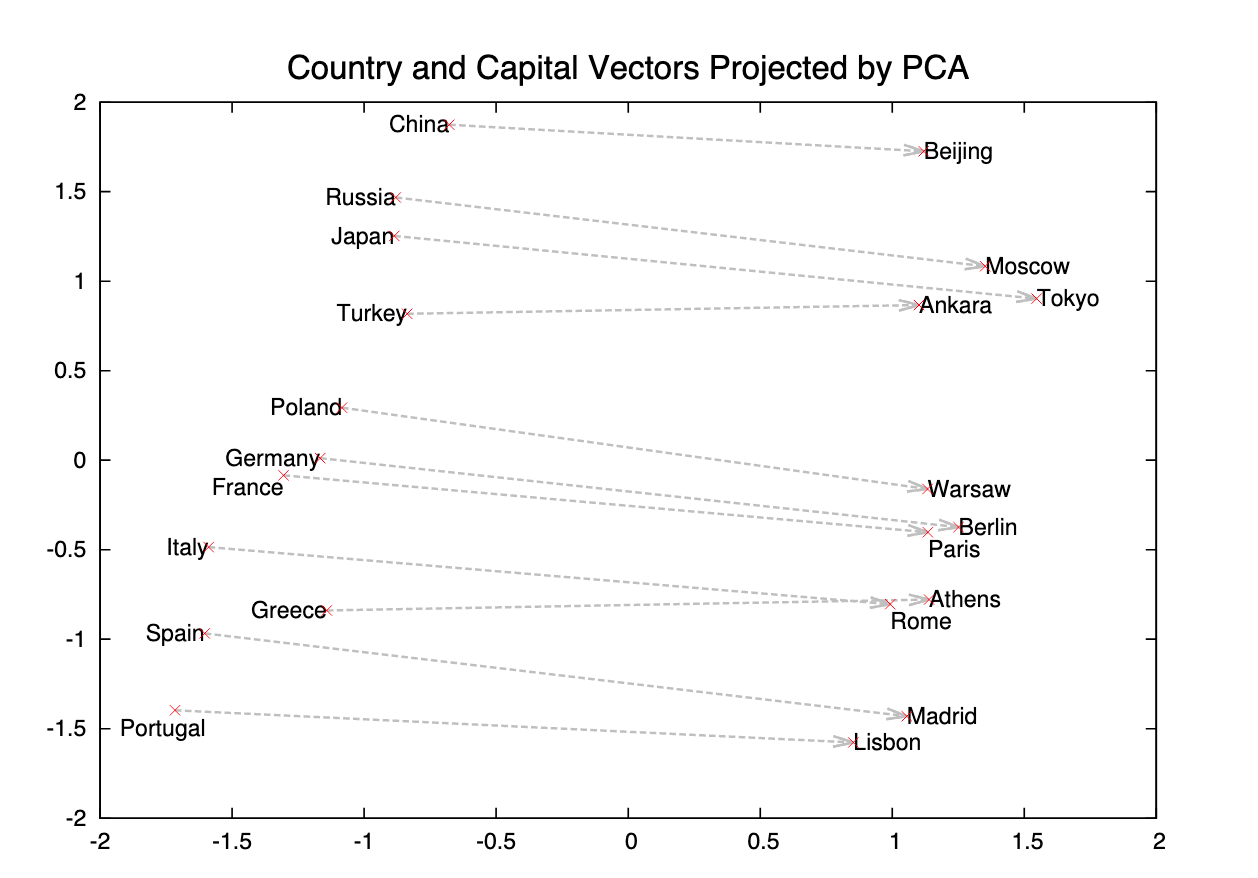
- 특정 단어를 표현하고자 할 때 주변 단어를 참고하여 단어를 표현하는 방법으로, 단어 간의 유사성을 판단할 수 있으며 주변 단어를 참고하기 때문에 단어의 의미를 담을 수 있다.
word2vec뿐만 아니라 유사도 기반의 작업을 진행할 때 사용되는 임베딩 방식은 대부분 밀집 표현을 의미한다고 할 수 있다.
2. TF-IDF
sparse representation에서 가장 기본적으로 사용되는 TF-IDF와 관련하여 이론적 배경과 설명해 필요한 용어를 정리해보자.
2-1. Bag of words
- 단어들의 순서를 전혀 고려하지 않고 단어들의 출현 빈도(frequency)에만 집중하는 text data의 수치화 표현 방법
- 단어의 빈도 수를 기반으로 통계적 언어 모델을 적용하여 나타내는 방식으로 N-gram의 N이 커질수록 각 N-gram의 등장 빈도는 적어질 수밖에 없기 때문에 임베딩 차원이 증가하게 된다.
2-2. Document-Term Matrix(DTM)
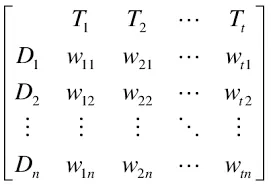
- 문서에서 등장하는 각 단어들의 빈도나 특성을 반영한 행렬이다.
BoW나TF-IDF를 실제로 활용하기 위해 행렬의 형식으로 표현하기 위해서는 DTM 방식을 차용해야 한다.DTM은 여러 문서가 가진 단어들을 하나의 행렬에 표현하는 방식으로 행은 각각의 문서를, 열은 전체 문서에서 등장한 개별 단어를 의미하며 행렬에 존재하는 값은 행에 해당하는 문서에서 열에 해당하는 단어가 등장하는 빈도 수를 나타낸다.
2-3. TF-IDF
-
TF-IDF는 TF와 IDF의 곱을 의미하며 TF와 IDF는 각각 다음과 같다.
-
Term Frequency(TF): 특정 단어가 문서 내에서 얼마나 자주 등장하는지를 나타내며DTM에서의 행렬의 값을 의미한다. -
Inverse Document Frequncy(IDF): 특정 단어가 전체 문서에서 얼마나 자주 등장하는지의 역수를 나타내며 특정 문서에만 등장하는 단어일수록 높은 값을 갖게 된다.
-
-
TF-IDF를 수식적으로 표현하면 다음과 같다.
-
: 특정 문서 에서 등장한 모든 단어의 수 대비 특정 문서 에서 단어 가 등장한 횟수
-
: 특정 단어 가 등장한 문서의 수
-
: 의 역수로 단어가 제공하는 정보의 양을 의미한다. 단어가 모든 문서에서 빈번하게 등장하는 경우는 해당 단어는 흔한 단어라고 볼 수 있으며 정보의 양이 적다고 할 수 있다.
- 를 사용하는 이유는 를 사용하지 않는다면 총 문서의 수 이 커질수록 의 값이 기하급수적으로 커지기 때문이다.
- 분모에 1을 더해주는 이유는 특정 단어 가 문서에 전체 문서에서 등장하지 않는 경우에 분모가 0이 되는 것을 방ㅈ지하기 위해서이다.
-
: 와 의 곱
-
-
'a', 'the', 'of' 등의 관사나 전치사는 는 높으나, 는 낮다고 할 수 있다. 즉 같은 문서 내에서 자주 등장하는 단어이면서 단어가 제공하는 정보의 양이 적다고 할 수 있다.
- 특정 단어 가 거의 모든 문서에 등장하게 되면 는 에 근사하게 되고 는 , 즉 0에 근사하게 된다.
-
사람 이름이나 지명과 같은 고유 명사는 가 작기 때문에 이 상대적으로 다른 단어보다 크다고 할 수 있다.
2-4. TF-IDF example
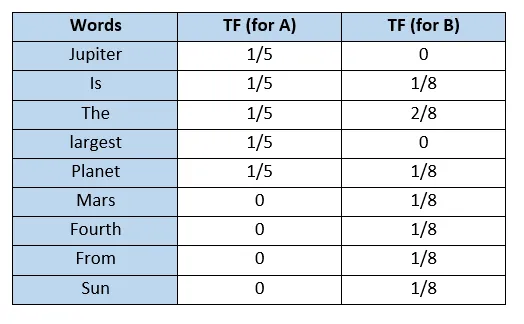
- 아래와 같이 A와 B 두가지 문서가 주어졌을 때, 우선 각 문서에 있는 단어의 수를 세면 각각의 문서는 다음과 같은 단어를 가진다.
- A : "Jupieter", "is", "the", "largest", "planet"
- B : "Mars", "is", "the", "fourth", "planet", "from", "the", "sun"

- 모든 문서에 등장하는 단어들로 사전을 만들고 각 문서에 대해서 를 계산하면 아래와 같다.
-
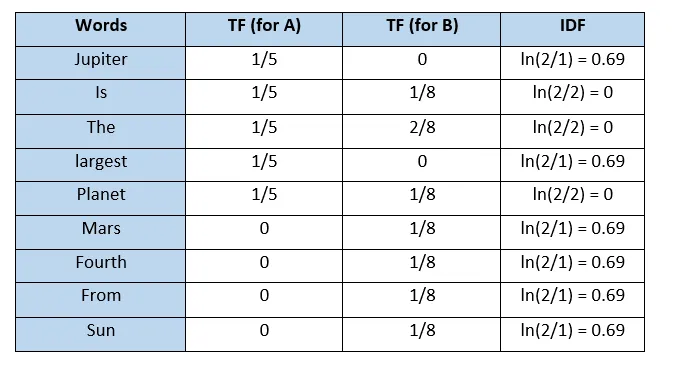
해당 예시에서는 라고 한다면 각 단어의 값은 다음과 같다.(해당 예시에서는 분모에 1을 더해주는 과정을 생략함)
- "is"나 "the"와 같이 모든 문서에서 빈번하게 등장하는 문장에 대해서 IDF가 0에 근사한다는 사실을 여기서 확인할 수 있다.
- 를 구하면 아래와 같으며, 각각의 문서 A와 B는 최종적으로 TFIDF(A)와 TFIDF(B)의 값을 사용하는 벡터로 표현할 수 있다.
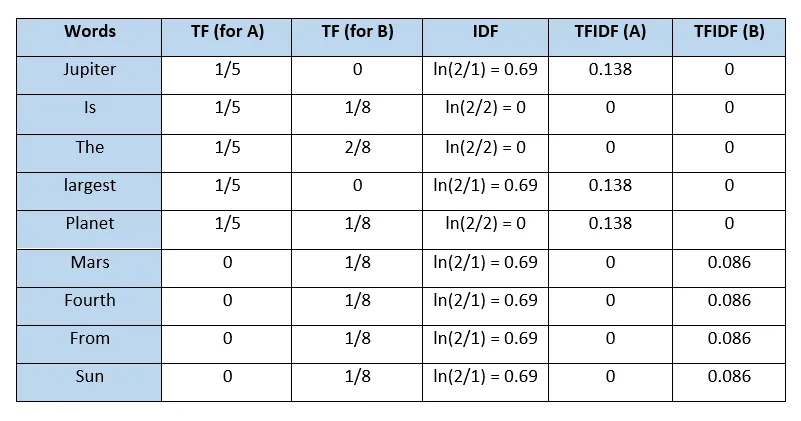
- 정리하면 는 다음과 같은 경우에 높은 값을 가진다.
- 가 높을수록, 즉 특정 문서 에 특정 단어 가 등장하는 횟수가 많을수록 높은 값을 가진다.
- 가 높을수록, 즉 특정 단어 가 등장하는 문서의 수가 적을수록 높은 값을 가진다.
- 결국 가 크다는 것은 특정 문서 가 특정 문서에서만 많이 등장하며 다른 문서에서는 적게 등장하는 경우를 의미한다.
- 비슷한 주제나 유사한 내용을 가진 문서들은 유사한 단어들을 공유하기 때문에 문서의
TF-IDF값을 이용하여 문서를 군집화할 수 있다.
3. BM25
BM25는 TF-IDF를 기반으로, 문서의 길이까지도 고려하여 점수를 매기는 방법으로 현재까지도 검색엔진, 추천시스템 등에서 빈번하게 사용되는 유사도 알고리즘이다. BM25는 대략적으로 아래와 같은 특징을 갖는다고 한다.
- 문서의 길이와 단어의 빈도수를 균형있게 고려하여 길이가 서로 다른 문서 간의 비교를 공정하게 한다.
- TF 값에 한계를 지정함으로써 일정한 범위를 유지하도록 한다.
- 평균적인 문서의 길이보다 더 작은 문서에서 단어가 매칭된 경우 그 문서에 대해 가중치를 부여한다.
- 특정 단어가 문서 내에서 지나치게 많이 등장하는 경우에 페널티를 부여한다.
BM25는 TF-IDF가 기존에 갖고 있던 한계(문서 내에서 특정 단어가 무의미하게 반복된 경우 유사도 점수가 의도치 않게 높게 계산되는 점)를 보완한다.
이제 BM25에 대해서 수식적으로 살펴보자.
3-1. The ranking function
특정 키워드 을 포함하는 쿼리 가 주어졌을 때 문서 에 대한 BM25 점수는 다음과 같이 구한다.
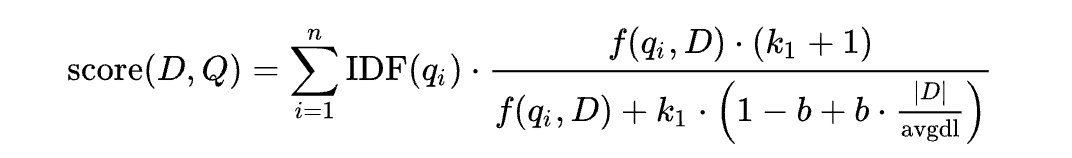
수식에서 각각이 의미하는 바는 다음과 같다.
- : 전체 쿼리 의 번째 토큰을 의미한다. 여기서 토큰은 형태소가 될 수 있으며 간단하게 표현하면 개별 단어라고도 할 수 있다.
- : 가 문서 에서 얼마나 많이 등장하는지를 나타내며 Term Frequency를 의미한다.
- : 문서 의 길이가 전체 문서의 평균 길이에 비해 얼마나 긴지를 나타낸다.
- 문서 가 전체 문서의 평균 길이보다 길 경우에 분모가 커지기 때문에
BM25점수는 낮아지게 된다. 즉 평균 대비 긴 문서에 대해서는 패널티를 부여하기 위한 부분이라고 할 수 있다.
- 문서 가 전체 문서의 평균 길이보다 길 경우에 분모가 커지기 때문에
- : 특정 토큰 의 IDF를 의미하며
BM25에서는 위에서 공부한 IDF와는 달리 다음과 같은 방식으로 IDF를 계산한다.
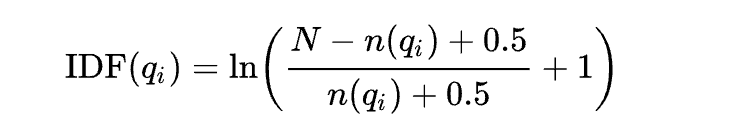
- : 전체 문서의 수
- : 를 포함하고 있는 문서의 수, 즉 Document Frequency를 의미한다.
- : Term Frequency가 전체 점수에 미치는 영향을 보정하는 역할을 한다. 즉 특정 토큰 가 한번 더 등장했을 때 점수에 얼마나 큰 영향을 미치지는지를 결정하는 파라미터이라고 할 수 있. 을 통해서 한 문서 내에서 같은 토큰이 많이 등장하더라도 일정 수준보다 높아지면 유사한 점수에 수렴하게 된다.
- : 문서의 길수록 TF 값이 커지기 때문에 이를 보정하기 위한 값으로 를 어느 정도 값으로 할지 결정하는 파라미터이다. 0의 경우에는 문서 길이에 대한 고려를 하지 않는 것을 의미하며 일반적으로 0.75를 사용한다.
3-2. 왜 BM25가 더 좋을까?
-
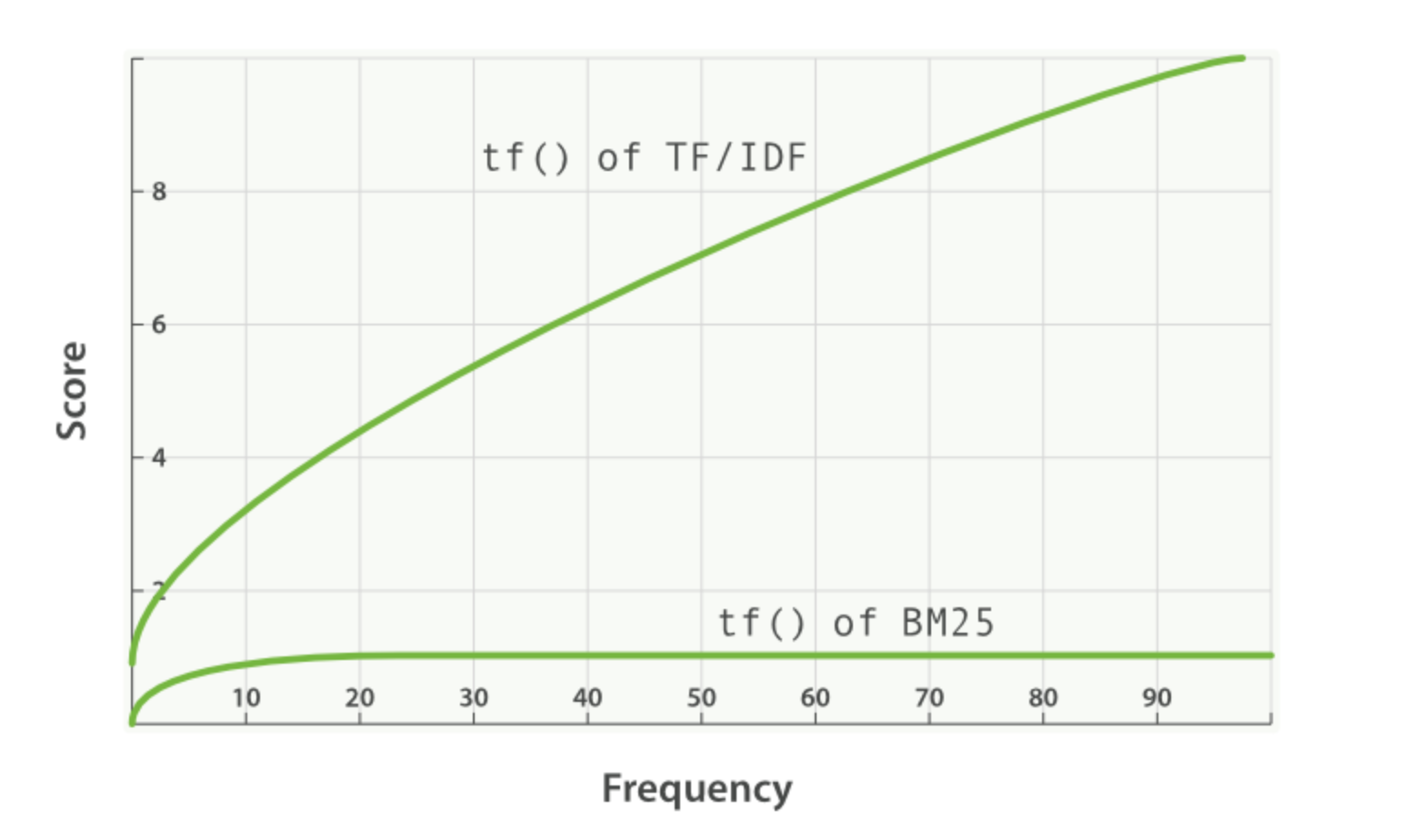
TF에서는 단어 빈도가 높아질수록 검색 점수도 지속적으로 높아지는 반면, BM25에서는 특정 값으로 수렴하여 TF의 영향이 감소한다.
-
BM25에서는 DF가 높아지면 검색 점수가 0으로 급격히 수렴하기 때문에 불용어가 검색 점수에 영향을 미치는 정도가 적어져 상대적으로 IDF의 영향이 커진다.
-
BM25에서는 문서의 평균 길이를 계산에 사용하여 정규화하기 때문에 문서의 길이가 검색 점수에 영향을 덜 미치게 된다.