1. RNN이란?
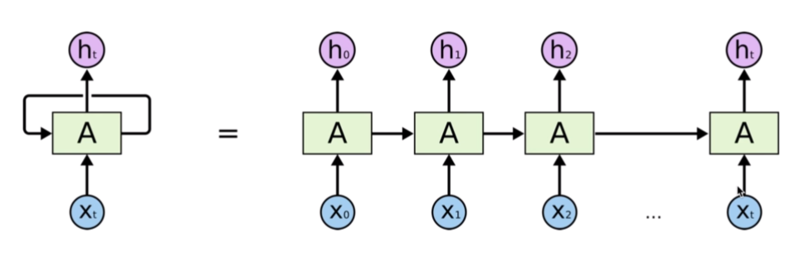
RNN(Recurrent Neural Network, 순환신경망)은 연속성이 있는 데이터를 처리하기 위해서 고안된 신경망이다. RNN은 기존 신경망들과는 달리 은닉층의 노드에서 활성화 함수를 통해 나온 결과값을 출력층 방향으로 보내는 동시에, 은닉층 노드의 다음 계산을 위한 입력으로 보낸다.
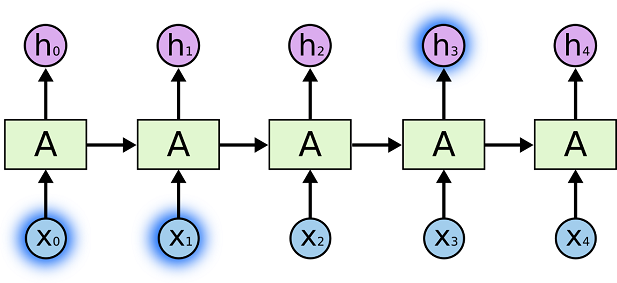
RNN의 기본 구조는 위와 같으며 각 용어의 의미는 다음과 같다.
- : old hidden state vector
- : new hidden state vector
- : input vector at some time step
- : output vector at time step t
- : 입력층에서 은닉층으로 전달되는 가중치
- : 시점의 은닉층에서 시점의 은닉층으로 전달되는 가중치
- : 은닉층에서 출력층으로 전달되는 가중치
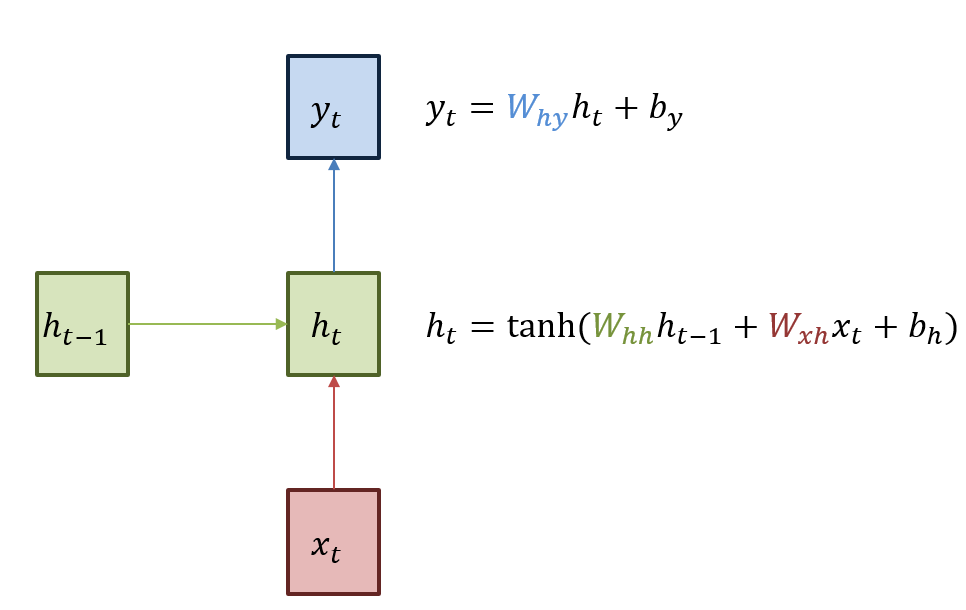
가중치 , , 는 모든 시점에서 동일하다는 것에 주의해야 한다. 즉, 각 time step마다 동일한 가중치를 이용한다. 다만 은닉층이 2개 이상일 경우에는 각 은닉층에서의 가중치는 서로 다르다.
의 크기(차원)을 , 의 크기을 라고 하면 RNN에서의 은닉층 연산은 아래 그림과 같다.

RNN을 통해 풀고자 하는 문제가 무엇인지에 따라 출력층에서 사용되는 활성화 함수의 종류는 달라진다. 예를 들어, 이진 분류의 경우 출력층에서 시그모이드 함수를 사용하며, 다중 분류의 경우 소프트맥스 함수를 사용한다.
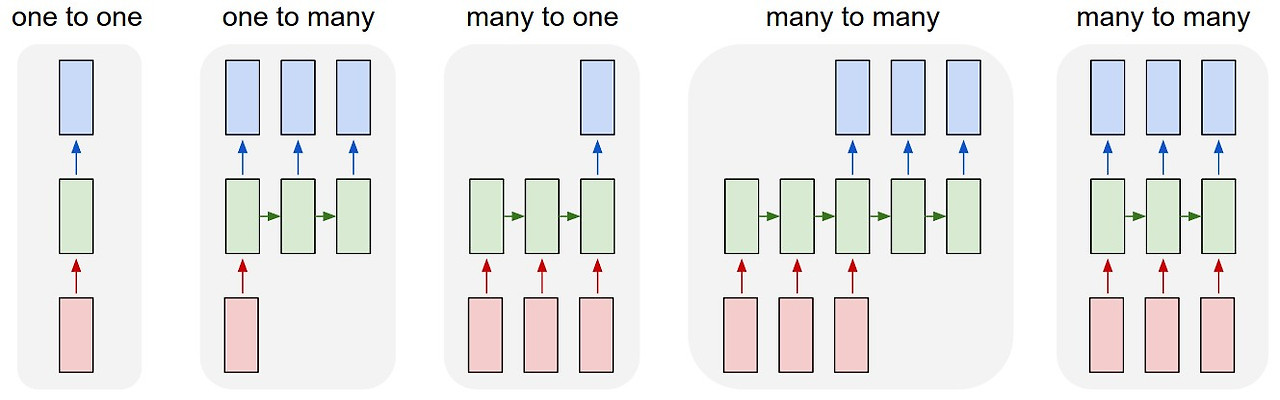
RNN은 입력과 출력에 따라 유형이 다양하다.
- 일대일(one to one) : 순환이 없기 때문에 RNN이라 말하기 어려우며, 일반적인 신경망이 이와 같은 형태다.
- 일대다(one to many) : 입력이 하나이고 출력이 다수인 구조로, 이미지를 입력해서 이미지에 대한 설명을 문장으로 출력하는 이미지 캡션(image caption)이 대표적이다.
- 다대일(many to one) : 입력이 다수이고 출력이 하나인 구조로, 문장을 입력해서 긍정/부정을 출력하는 감정 분석에 사용된다.
- 다대다(many to many) : 입력과 출력 모두 다수인 구조로, 자동 번역이 대표적이다.
- 동기화 다대다(many to many) : 입력과 출력 모두 다수인 구조로, 각 단어의 품사에 대해 태깅하는 pos(part-of-speech)나 프레임 임 단위의 비디오 분류 등이 대표적이다.
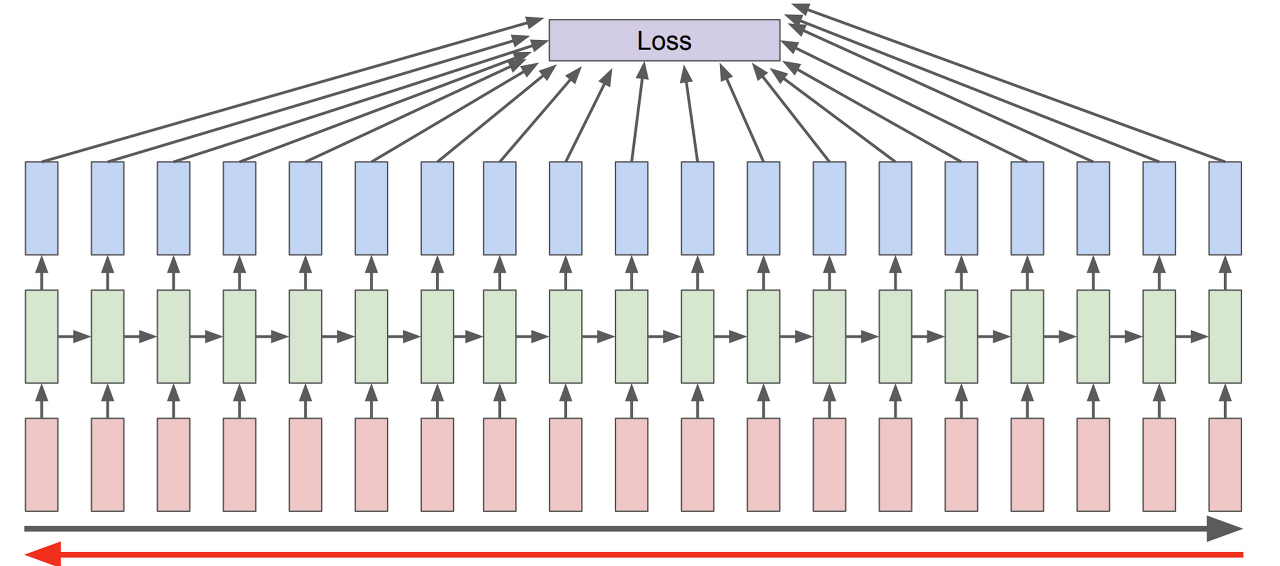
RNN에서 오차는 기존 신경망에서의 feedforward와는 달리 각 time step마다 오차를 측정한다. 즉, 각 단계마다 실제 값과 예측값을 비교하여 오차를 계산한다.
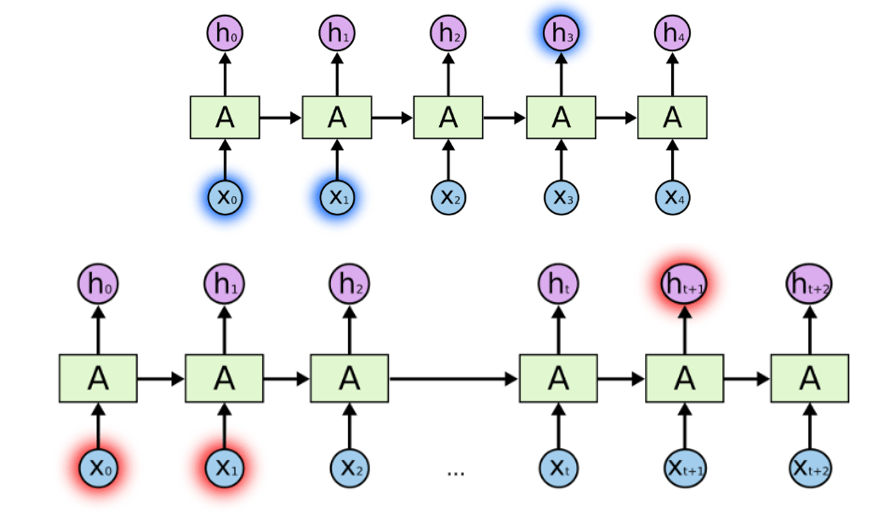
RNN에서 역전파는 BPTT(Backpropagation Through Time)을 이용하여 모든 단계마다 처음부터 끝까지 전달된다. 각 time step에서 구한 오차를 이용하여 , , 및 를 업데이트한다. 이때, 의 계산이 매 time step마다 반복되는데, backpropagation 과정 동안 와 에 대한 gradient가 반복적으로 곱해짐에 따라 Gradient Vanishing/Exploding 문제가 발생하고 이것이 Long-Term-Dependency를 일으킨다.
2.LSTM이란?
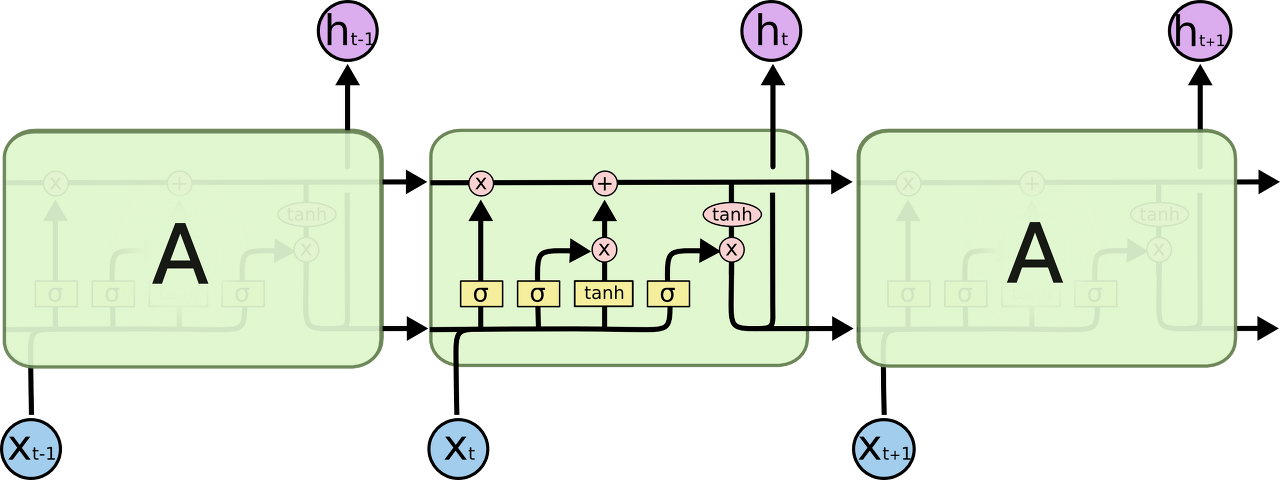
앞서 언급한 Long-Term-Dependency를 해결하기 위해 등장한 모델이 LSTM(Long Short-Term Memory)이다. LSTM은 기존 RNN에서의 hidden state를 의미하는 를 계산하는 방식을 더 복잡하게 만들어 cell state를 의미하는 를 추가하였다.
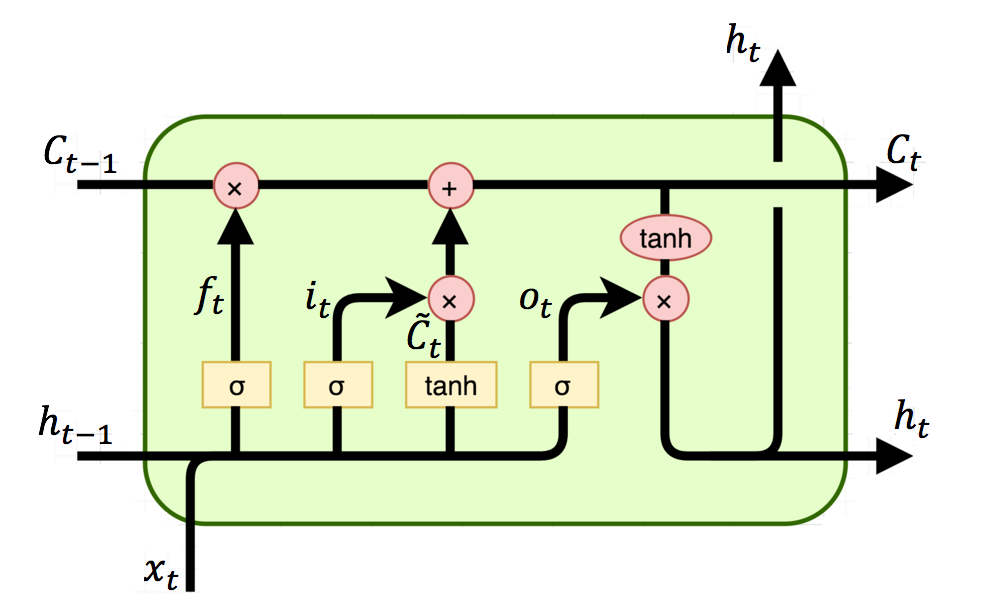
LSTM의 기본 구조는 위와 같으며 각 용어의 의미는 다음과 같다.
- : 망각 게이트, 과거 정보를 삭제하기 위한 게이트
- : 입력 게이트, 현재 정보를 기억하기 위한 게이트
- : 출력 게이트, 과거 정보와 현재 데이터를 사용하여 출력을 결정
- : 게이트 게이트, 현재 정보를 얼마나 기억할지를 결정
각 게이트에 대한 수식은 다음과 같다.
결론적으로 특정 시점 t에서의 cell state를 의미하는 와 hidden state를 의미하는 에 대한 수식은 다음과 같다.
(은 원소별 곱을 의미)
3. GRU란?
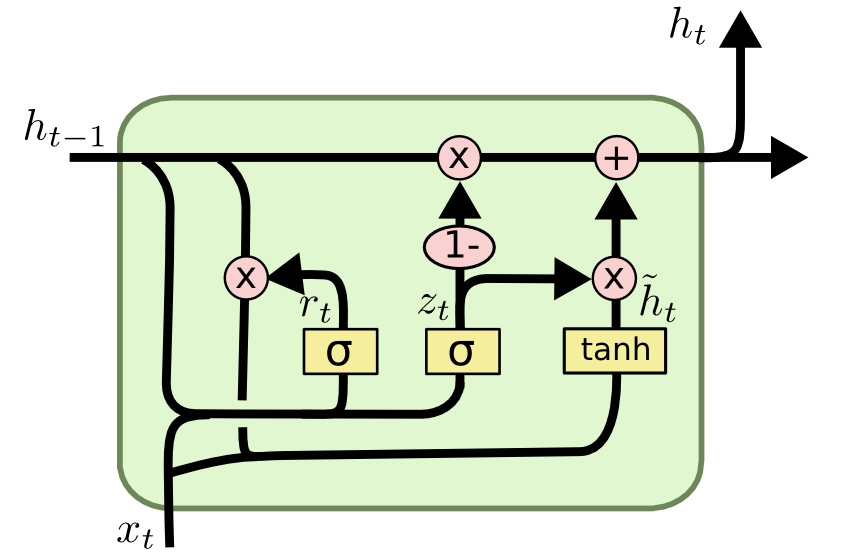
GRU(Gated Recurrent Unit, 게이트 순환 신경망)은 LSTM의 모델 구조를 보다 경량화하여 더 적은 메모리를 사용하며 계산 시간이 더 빠른 모델이다. GRU는 동작 원리는 LSTM과 유사하지만 LSTM에서 사용하는 망각 게이트와 입력 게이트를 하나로 합친 업데이트 게이트()를 사용하며, 오직 만을 사용한다. (GRU에서의 는 LSTM에서의 와 유사한 기능을 한다.)
GRU에서의 각 용어의 의미는 다음과 같다.
- : 리셋 게이트, 과거 정보를 어느 정도 초기화시키는지 결정
- : 업데이트 게이트, 과거와 현재 정보의 최신화 비율을 결정하는 - 역할
- : candidate, 현시점의 정보를 의미
각 용어에 대한 수식은 다음과 같다.(은 원소별 곱을 의미)
결론적으로 GRU에서의 hidden state를 의미하는 는 다음과 같다.