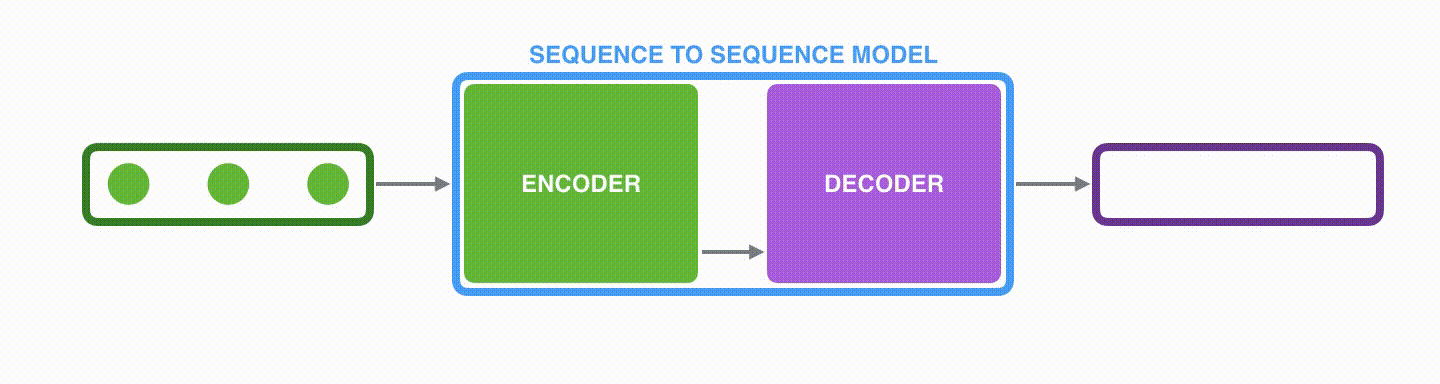
1.Seq2Seq란?

Seq2Seq(sequence to sequence)란 입력 시퀀스(input sequence)에 대해서 출력 시퀀스(output sequence)를 만들기 위한 모델로서, 주로 기계 번역(Machine Translation)이나 챗봇(Chatbot)뿐만 아니라 내용 요약(Text Summariztion) 등에 사용되는 모델이다. 위 그림처럼 입력 시퀀스와 출력 시퀀스의 길이는 다를 수 있다.

Seq2Seq 모델은 크게 Encoder와 Decoder로 구성되어 있다. Encoder와 Decoder의 아키텍쳐 내부는 RNN 아키텍쳐이다. 기계 번역의 경우, Encoder는 입력 문장의 모든 단어들을 순차적으로 입력받는다. 이때, 사용되는 모든 단어들은 임베딩 벡터로 변환된 후 입력으로 사용된다. 마지막에는 정보들을 압축하여 하나의 벡터로 만드는데 이를 context vector라고 한다. 위와 같은 모델에서는 Encoder의 마지막 hidden state vector가 context vector의 역할을 한다. 압축된 context vector는 Decoder로 전달되고 Decoder는 context vector를 이용하여 번역된 단어를 하나씩 순차적으로 출력한다.
2. Attention in Seq2Seq Learning

context vector만으로는 Encoder에서 처리하는 정보를 담기에는 부족하다. 이러한 문제를 해결하기 위해 등장한 것이 Attention의 개념이다. Attention은 모델이 입력 시퀀스에서 연관된 특정 부분에 집중하도록 도와준다. 즉, Decoder에서 출력 단어를 예측하는 매 time step마다 예측해야 할 단어와 연관이 있는 입력 단어 부분을 더 중점적으로 보는 것이다.

기존 Seq2Seq와 Attention 메커니즘에는 크게 2가지 차이점이 존재한다.
- Encoder가 마지막 hidden state vector뿐만 아니라 모든 hidden state vector를 Decoder에 전달한다.

- Decoder의 각 time step에서 가장 관련이 있는 입력 시퀀스에 집중하기 위해서 추가적인 단계를 거친다.
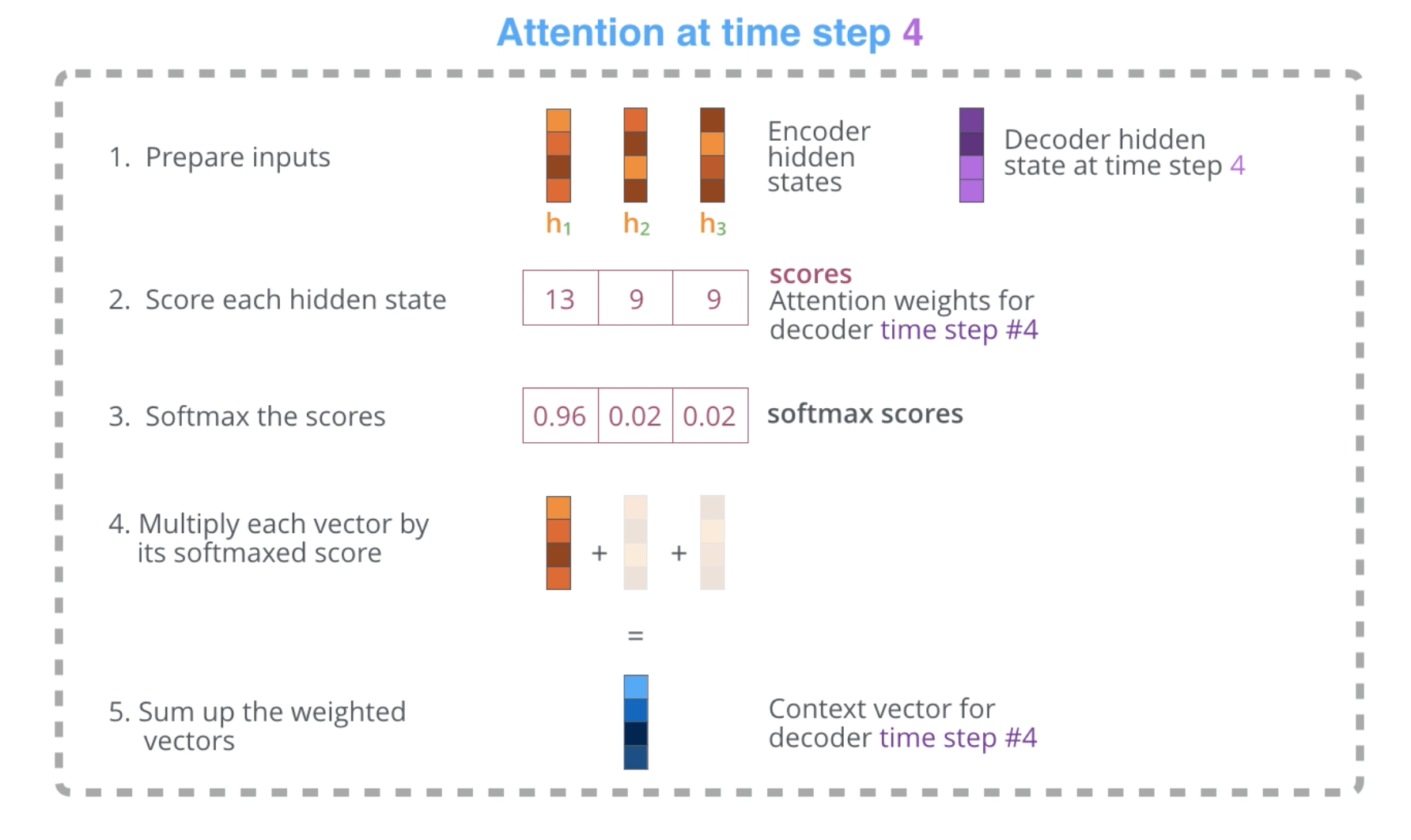
- Encoder에서 모든 hidden state vector를 전달받는다. 각각의 hidden state vector는 입력 시퀀스에서의 특정 단어와 가장 관련성이 높다고 할 수 있다.
- 각 hidden state vector에 대해 점수를 계산한다.
- 점수에 대한 소프트맥스 결과값을 각 hidden state vector에 곱한 후, hidden state vector들의 가중평균을 구한다.
점수를 계산하는 과정은 매 time step마다 수행되며, 이렇게 구해진 가중평균 벡터가 Decoder의 해당 time step에서의 context vector가 된다.
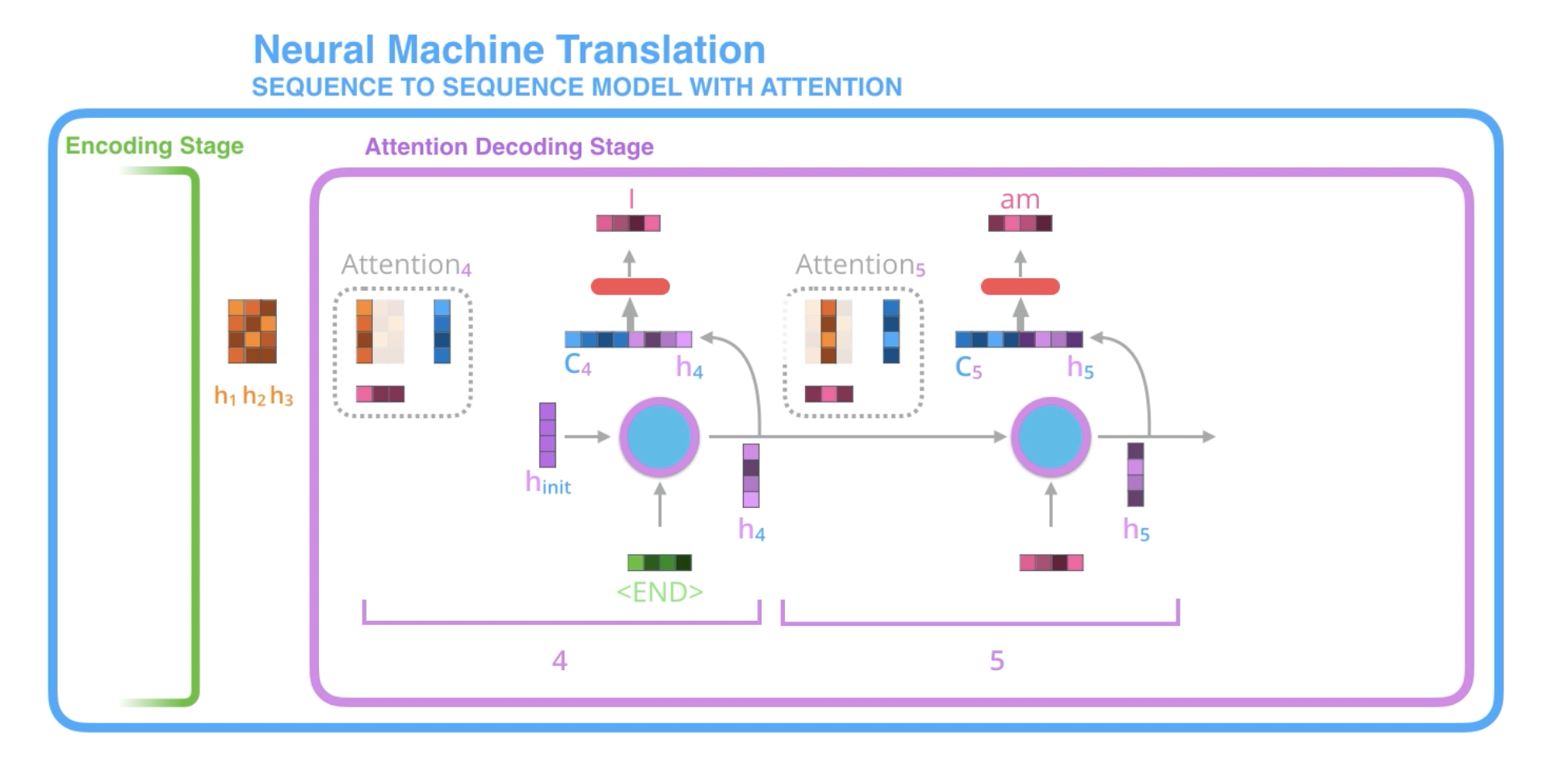
- 해당 time step의 hidden state vector()와 context vector()를 concatenate한다.
- feedforward neural network에 해당 벡터를 입력하면 출력 시퀀스에 해당하는 단어 벡터가 출력된다.
- 이때 출력된 단어 벡터는 다음 time step의 입력으로 사용되며,
<END>에 해당하는 벡터가 출력될 때까지 이러한 과정을 반복한다.