[논문리뷰] UNSUPERVISED REPRESENTATION LEARNING WITH DEEP CONVOLUTIONAL GENERATIVE ADVERSARIAL NETWORKS(DCGAN), ICLR, 2016
논문 리뷰 및 실습
Abstract
본 논문발표 당시에는, CNN이 unsupervised learning에서는 아직 큰 성공을 이루지 못했습니다. 저자들은 DCGANs이라는 CNN기반의 GANs 네트워크를 제시하며, unsupervised learning에서도 강력히 사용될 수 있다고 합니다. Object의 part에서 scene으로 표현 방법들의 계층을 generator와 discriminator 모두 학습하며, 학습된 특징을 특정 tasks에 사용할 수 있다고 합니다.
Introduction
Ian Goodfellow가 발표한 GAN은 image representation의 좋은 방법이었습니다. 하지만 GANs모델들은 학습하기 불안정했고, 때때로 이상한 결과를 만드는 generator가 발생합니다. 또한 당시에는 GAN이 무엇을 배우는지 이해하고 시각화하려는 연구가 거의 없었다고 합니다.
본 논문은 다음과 같은 contributions을 한다고 합니다.
- 안정적인 training이 가능한 Deep Convolutional GANs(DCGAN)을 제안합니다
- 이미지 분류를 위한 학습된 discriminator을 사용하여, 다른 unsupervised 알고리즘들보다 경쟁적인 성능을 보여줍니다.
- GAN의 filter를 시각화하여, filter가 어떤 특정 objects를 그리는지 보여줍니다
- Generator의 입력 벡터의 산술 연산적인 특징을 보여주며, 쉽고 다양한 segmentic 단위의 조작이 가능한 것을 보여줍니다.
Related Works
- Representation Learning from Unlabelled Data
: 이미지 픽셀들로부터 좋은 feature representations을 위한 다양한 방법들을 소개하고 있습니다.
- Generating Natural Images
: 이미지 생성 모델은 크게 parametric, non-parametric으로 구분할 수 있습니다. non-parametric 모델의 경우 기존 이미지들의 database로부터 matching하는 방식을 이용하며, parametric 모델은 다양한 방법들이 연구되었으며, 대표적으로 GANs, Laplacian pyramid가 있습니다.
- Visualizing the Internals of CNNs
: Neural networks의 가장 큰 비판으로는 black-box method, 즉 네트워크가 어떤 일을 하는지 사람이 이해하기 어렵다는 점입니다. CNNs의 관점에서, Zeiler는 deconvolution과 filtering을 사용할 때, 신경망에서 각 convolution-filter의 목적을 찾을 수 있다는 사실을 보여줬습니다.
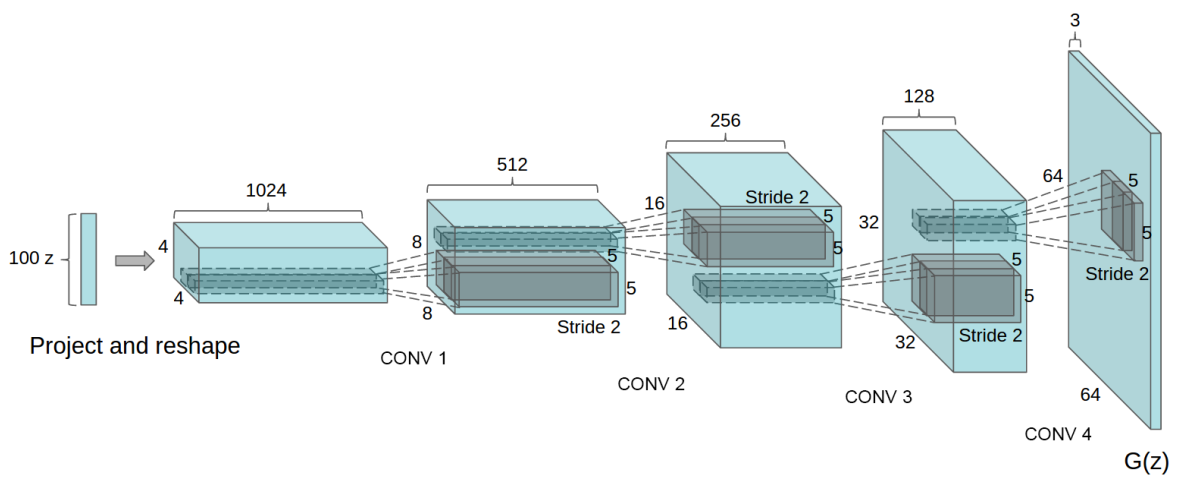
Approach and Model Architecture
CNN을 사용하여 GANs을 scale-up하려는 시도들은 성공적이지 못했다고 합니다.
LAPGAN의 저자들은 생성된 저해상도 이미지들로부터 반복적으로 upscale하는 방식을 사용하는 방법을 제안하였으며, reliable하게 모델링 될 수 있다고 합니다. 본 논문 저자들도 supervised 방식에서 널리 사용되는 CNN 아키텍쳐를 사용하였을 때 많은 어려움을 겪었다고 합니다. 많은 모델을 탐사한 후에, 저자들은 다양한 데이터셋, 고해상도 training, deeper generative 모델들에 대해서 안정적인 훈련이 가능한 아키텍쳐들을 identify하였다고 합니다.
본 논문에서 제안하는 CNN 아키텍쳐의 변화된 부분은 아래 3가지입니다.
1) 먼저 pooling layer가 없고, 대신에 strided convolution을 사용하여 신경망이 spatital downsampling을 학습하도록 합니다. 이러한 방법을 generator, discriminator에 적용하여, 스스로 spatial upsampling을 학습하도록 하였습니다.
2) convolutional features 위에 Fully connected hidden layers를 두지 않는 방식입니다.
3) Generator와 Discriminator 모두 batch normalization을 사용하는 것입니다. 이것은 깊은 모델의 gradient flow를 도와주며, GANs에서 흔히 관측되는 모든 샘플들이 하나의 point를 생성하는 것을 방지해줍니다. 하지만 모든 layer에 batchnorm을 사용하는 것은 불안정성을 도래할 수 있다 하므로, generator의 output layer와 discriminator의 input에는 사용하지 않는다고 합니다.

Details of Adversarial Training
논문에서는 DCGAN을 3가지 데이터셋을 가지고 훈련시켰다고 합니다. 훈련 시 Adam optimizer를 사용했다고 합니다.
LSUN dataset
위의 그림처럼 더 높은 품질의 이미지가 생성된 것을 확인할 수 있습니다
다음은 5 epoch만 학습시켰을 때, 즉 under-fitting이 되었을 때의 결과입니다.


Emprical Validation of DCGANs Capabilities
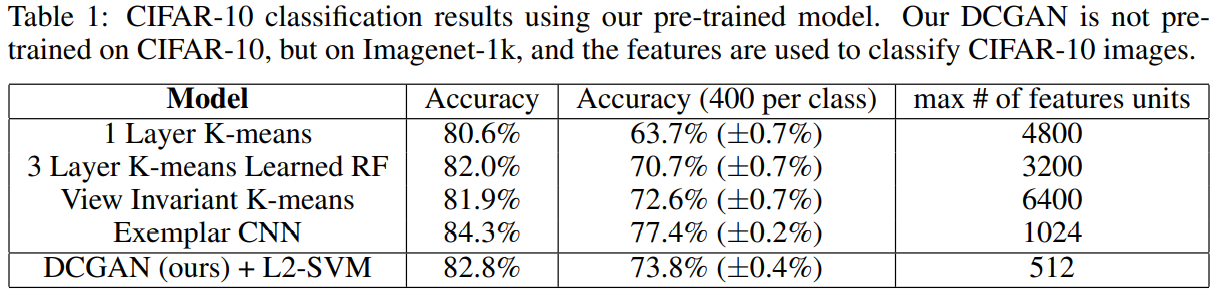
본 논문에서는 DCGAN을 feature extractor, 즉 supervised learning에서 image-classifiation에서도 좋은 성능을 보여준다는 것을 보여줍니다. ImageNet을 통해 학습시킨 DCGAN을 CIFAR10(훈련해본 적이 없는 데이터셋)을 분류하였을 때, K-means 알고리즘보다 훨씬 성능이 좋은 것을 아래와 같이 표에서 확인할 수 있다고 합니다.
Investigating and Visualizing the Internals of the networks
저자들은 먼저 latent space(잠재적 공간) 접근에 대한 실험을 진행해 보았습니다. latent space에서의 접근이 이미지 생성에 있어서 semantic change을 줄 수 있는지 실험해보았고, 모델이 relevant하고 interesting한 representations을 학습한다는 것을 추론할 수 있었다고 합니다.
 위의 그림처럼 Z의 random points들을 interpolinate(선형보간)한 결과 위와 같이 그럴듯한 침실 사진들을 만들어 내는 것을 보여줍니다.
위의 그림처럼 Z의 random points들을 interpolinate(선형보간)한 결과 위와 같이 그럴듯한 침실 사진들을 만들어 내는 것을 보여줍니다.
또한 본 논문은 Face dataset을 가지고 latent vectors의 결과들에 대한 산술 연산적인 특징을 설명하고 있습니다. 아래 그림처럼 smiling woman을 도출하는 z벡터들과 neutral woman에 해당하느 z벡터들을 뺀 후에, neutral man에 해당하는 z백터를 더해준 것을 DCGAN의 입력으로 주면 놀랍게도 smiling man에 해당하는 결과가 도출된다고 합니다.


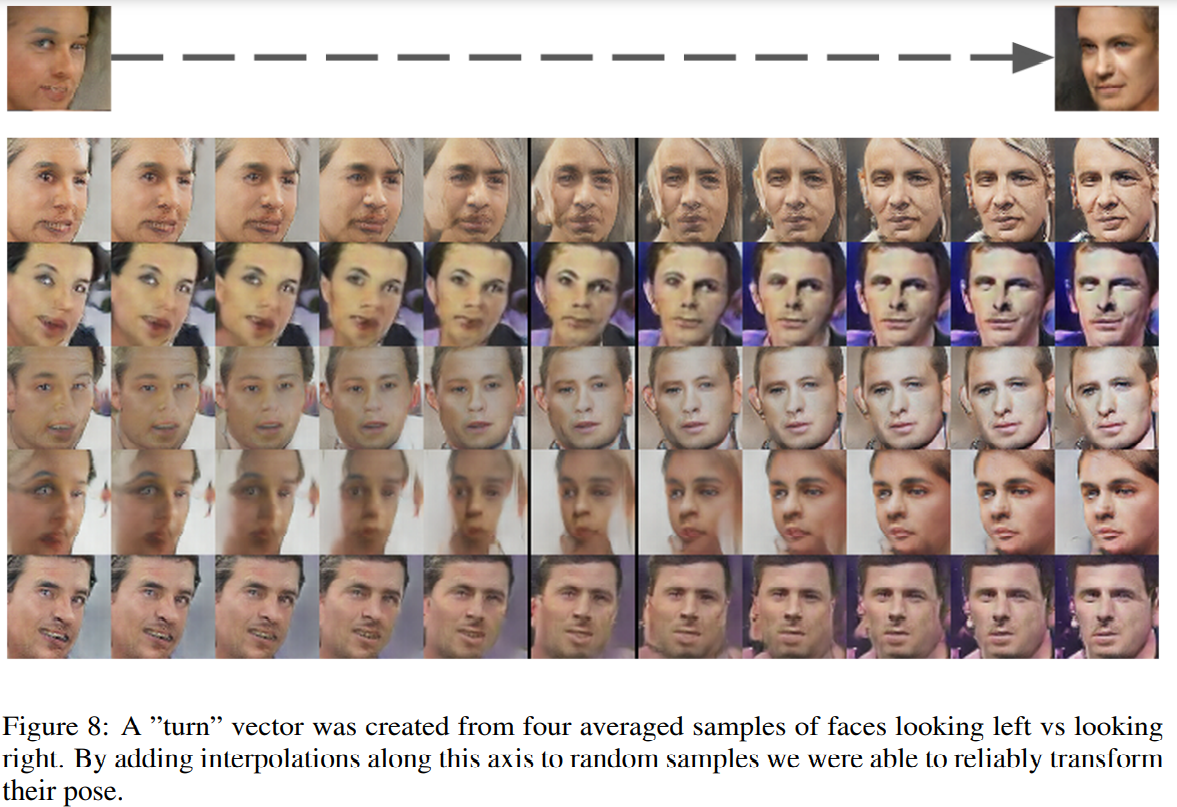
또한 Interpolination을 사용하여 결과의 pose를 바꿀 수도 있다고 합니다
Conclusion
본 논문은 안정적인 아키텍쳐 구조의 DCGAN을 제안하면서, Image representations과 generative modeling을 adversarial networks가 좋다는 사실을 보여주었습니다. 하지만 train을 길게하면 subset of filters들이 붕괴되고 하나의 단일 모드로 붕괴된다는 불안정성이 있다고 합니다. 따라서 이에 대한 추가 연구와 latent space에 대한 추가 연구의 필요성을 제시합니다.
