Introduction to Generative Adversarial Networks (GANs)
- Generative Adversarial Networks
- NIPS 2016 Tutorial:
Generative Adversarial Networks - https://learnopencv.com/introduction-to-generative-adversarial-networks/
- image source
"GAN is the most interesting idea in the last ten years in machine learning" - Yann Lecun -
1. What are GANS?
GAN은 random한 노이즈 벡터를 input으로 받아서 training set의 distribution과 유사한 output을 만들어 내는 신경망입니다.
GAN은 동시에 2가지 모델의 학습을 진행합니다
1. Generator - Capture distribution of training set
2. Discriminatior - 실제 이미지와 generator에서 생성한 이미지들을 판단하는 역할을 합니다.

https://thispersondoesnotexist.com/
실제로 위 사이트에 접속해보면, 사람 얼굴 데이터셋으로 학습한 GAN으로 생성한 사람 얼굴 이미지가 있습니다!
2. Why GANs?
- Training data가 불충분할 시에, GAN을 이용하여 데이터 증강이 가능합니다
- GAN을 통해 저화질의 사진 혹은 비디오를 고화질로 개선이 가능합니다
- Descriptions(text)만 가지고서 이미지들을 생성할 수 있습니다

3. Advantages of GANs over Other Generative Models
요즈음 사용하는 생성 모델은 GAN이 지배하고 있습니다. 왜 그럴까요?
- GAN은 label이 필요없는 unsupervised 방식이므로, 학습하기 위한 라벨링이 따로 필요가 없습니다
- 기존의 생성모델은 흐릿한 이미지들을 생성했지만, GAN을 이용하면 보다 더 sharp한 이미지를 사용할 수 있습니다
- Backpropagation만을 사용하여 GAN 속의 2가지 네트워크를 학습할 수 있습니다
4. Intuition behind GANs
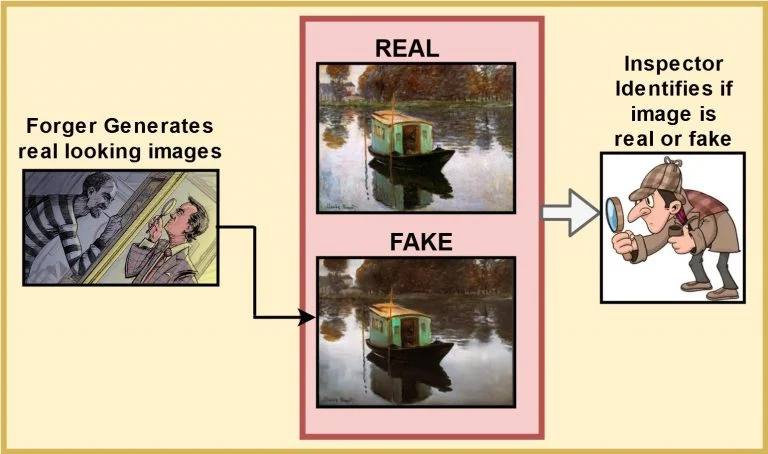 - Generator는 위의 그림과 같이 실제 작품을 모방하려 합니다
- Generator는 위의 그림과 같이 실제 작품을 모방하려 합니다
- Discriminator는 작품이 real인지 fake인지 판단합니다. 또한 Generator가 더욱 더 realistic한 이미지들을 만들도록 feedback을 줍니다

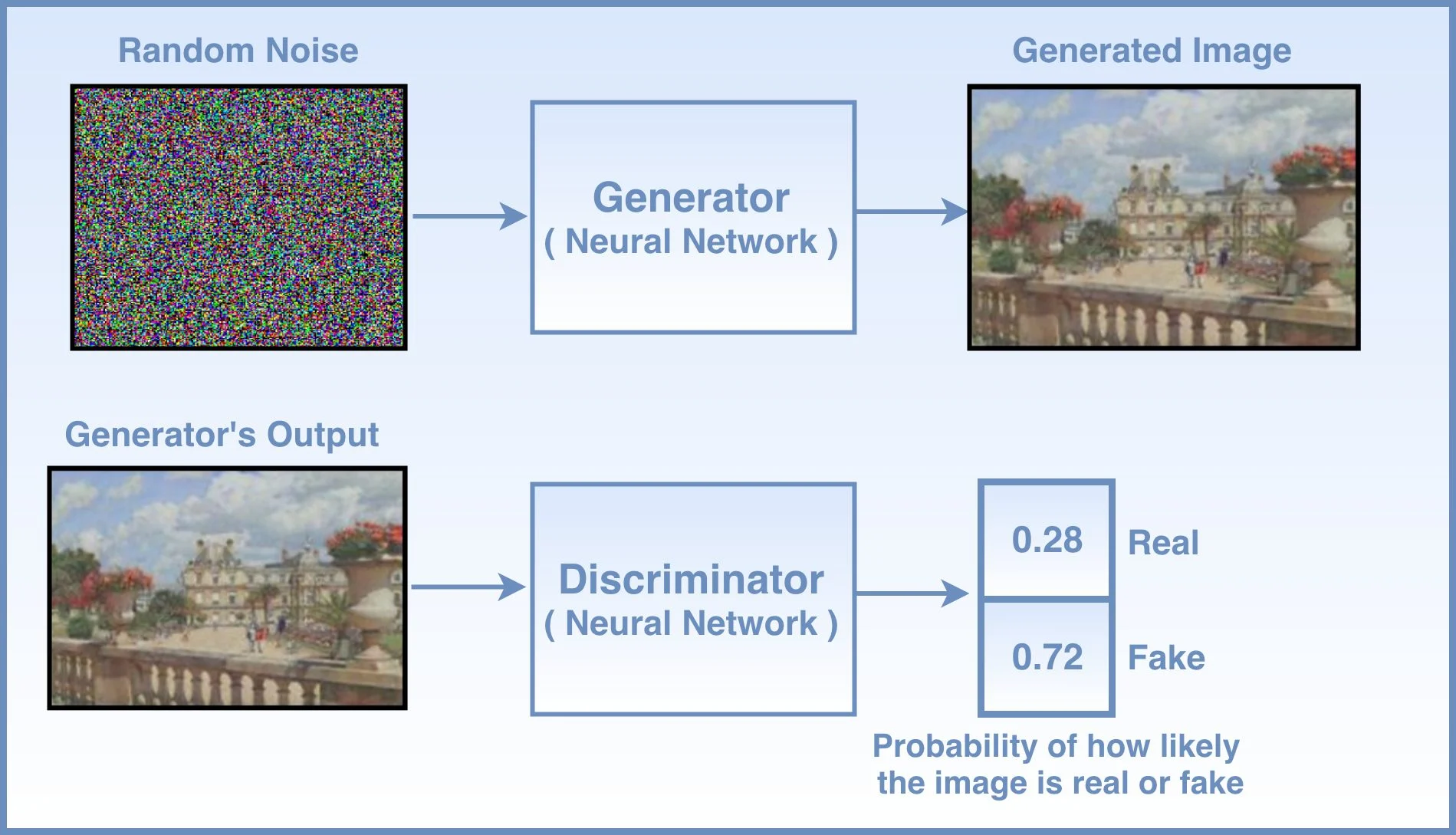
Generator와 Discriminator의 역할을 다시 한 번 정리하자면, - Generator는 data의 distribution을 학습하고, random noise를 input으로 받아서, realistic한 이미지를 만들고자 합니다
- Discriminator는 주어진 sample이 실제 데이터셋인지, Generator에서 생성한 데이터인지 판단하는 역할을 합니다.
5. Components of a GAN
GAN의 아이디어는 생성 모델링 영역에 revolution이 되었습니다. Ian Goodfellow가 2014년 NIPs에서 처음 GAN에 관한 논문을 발표하였는데, 그는 GAN을 "as a new framework for estimating generative models via an adversarial process, in which a generative model G captures the data distribution, while a discriminative model D estimates if the sample came from the training data rather than G"로 소개하였습니다

Generator는 Discriminator를 속이려 하는 것이 목표이며, 반대로 Discriminator는 Generator가 생성한 이미지를 가짜로 판단하고, 실제 이미지를 실제로 판단하고자 하는 것이 목표입니다. 즉 이 둘의 목표가 정반대기에, 적대적(adversarial)이라 부릅니다.
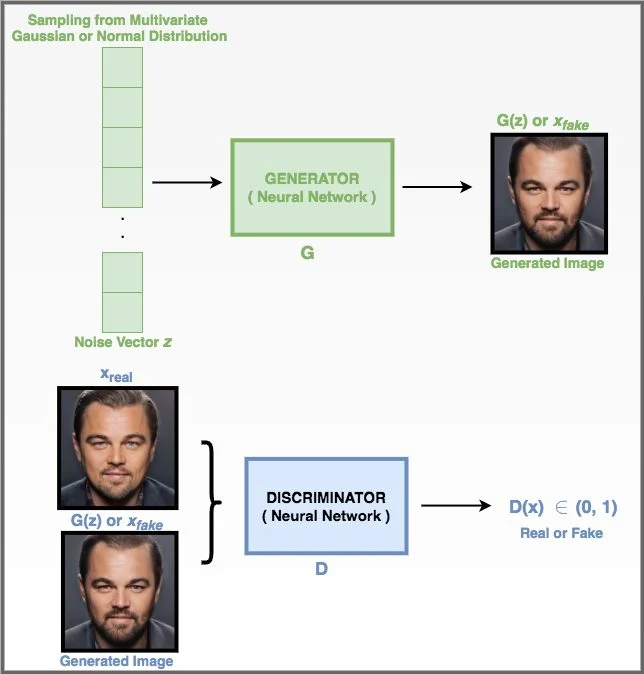
Generator
Generator는 신경망으로서, random set of values를 input으로 받아서, non-linear한 연산을 연속적으로 거쳐서 실제와 닮은 이미지를 생성합니다. 아래와 같이 Generator는 Z라는 mulivariate-gaussian distribution으로 부터 생성된 random vector를 입력으로 받아서, X(fake)라는 fake 이미지를 만들게 됩니다.
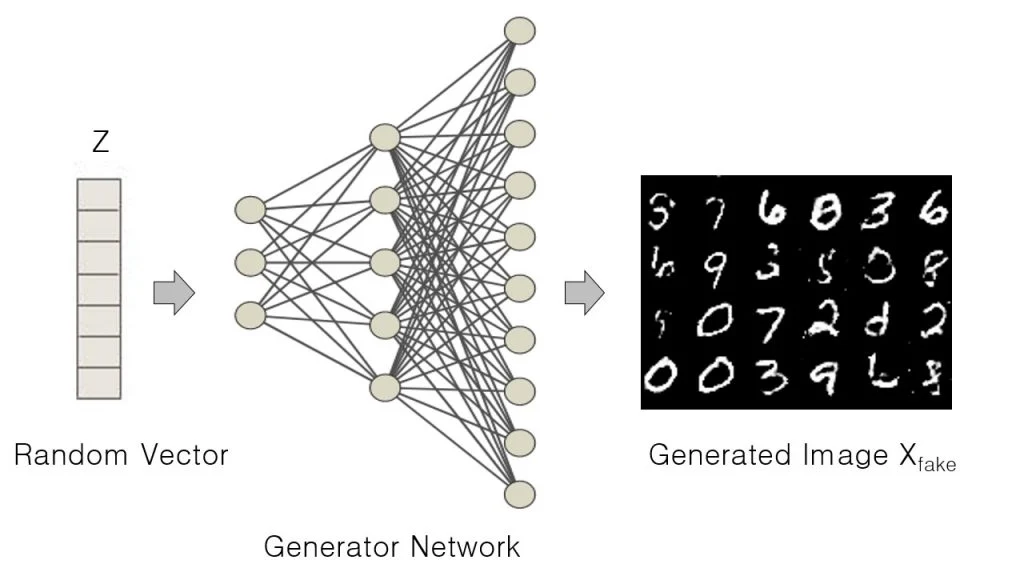
GAN을 통해 unsupervised한 문제를 해결하려 했을때, 우리의 목표는 특정한 클래스에 examples을 만드는 것입니다. 예를 들어서, 만약 우리가 강아지와 고양이 사진으로 GAN을 학습시켰을 때, 우리는 Generator가 2개의 class 모두로부터 이미지를 생성하는 것을 기대할 것입니다.
import torch
z = torch.randn(50)
print(z.mean(), z.var())tensor(-0.0496) tensor(0.8976)GAN의 입력값은 multivariate normal 혹은 gaussian distribution으로 셈플링된 랜덤한 값들을 사용하며, 사이즈는 실제 이미지와 같습니다. GAN의 generator는 latent space(특징 후보 공간)을 이미지에 추상적인 레벨로 투영시킨다는 점에서 VAE와 유사하지만, generator의 latent space는 가우시안 분포만을 배우도록 학습하지 않는다는 점에서 다름니다. 만약 가우시안만 학습하면 조금 더 복잡한 분포를 따를 수 있지만, mode collapse라는 문제점을 겪습니다.
Discriminator
Discriminator는 데이터셋을 특정 클래스로 분류하는 supervised-classification과 유사하지만, classification이 이미지 뿐만 아니라, 비디오, 텍스트, 다른 영역의 데이터를 사용한다는 점이 있습니다. 
GAN에서 Discriminator는 실제와 fake 이미지를 분류하는 binary classification 문제를 해결합니다. fake/real data인지 예측하면서, 많은 파라미터를 학습하며, 학습이 진행될 동안 계속 업데이트가 됩니다. 초창기 GAN은 Dense Layer를 Discriminator에 사용하였는데, 2015년에 Deep Convolutional GAN (DCGAN)이 발표되면서, fully-connected layers보다는 convolutional layer가 잘 된다고 하였습니다.
Training procedure
먼저 첫번째 단계로
- 생성된 X(fake) 이미지들과 실제 이미지 X(real)들은 discriminator에 전달됩니다
- Discriminator는 확률값을 예측하며, 0:fake, 1:real인 label값과 비교되어, Binaary cross entropy 함수를 통과해 loss를 계산합니다
- ss는 Backpropagation을 통해 discriminator만 먼저 학습하게 되며, discriminator의 파라미터들이 업데이트 됩니다
다음 단계로
- Generator가 생성한 X_fake가 다시 discrminator에 전달됩니다
- 마찬가지로 Y_pred값이 계산되며, BCE를 통해 loss가 계산됩니다.
- Generator에서 생성한 이미지들을 discriminator가 실제로 판단하도록 속이기 위해서는 loss값이 generator만 backpropagation을 통해 학습되어 sutiable한 파라미터가 됩니다
Generator가 보다 더 사실적인 이미지들을 생성하기 위해서는, discriminator가 가이드를 해줘야 합니다.(fake images에 대한 loss값이 generator에 backpropagation되어야 합니다) 만약, discriminator가 약하면, 그럴 듯 하지 않은 이미지들도 real이라 판단할 수 있고, Generator가 약하면 discriminator를 속일만한 그럴 듯한 이미지들을 생성하지 못하기 때문에, 2개의 신경망 모두 강하게 학습시킬 필요가 있습니다.
Objective function of GAN
 GAN의 loss함수로는 binary cross entropy를 사용합니다.
GAN의 loss함수로는 binary cross entropy를 사용합니다.
What is BCE?
- 식 맨처음의 (-) 부호는 loss가 음수가 되는 것을 막아줍니다. 신경망의 결과가 0~1사이의 값(확률)이므로, 이 값에 log를 취하면 음수값이 되므로, (-) 부호를 붙혀서 negative-log-likelihood를 사용합니다
- 신경망은 batch단위로 학습을 진행하게 됩니다. N은 1 batch당 데이터 샘플 수이며, 전체 데이터 샘플 수를 N으로 나눠 배치 사이즈를 구하게 됩니다.
- y(i)는 discriminator in GAN이 예측한 값이며, y(i_hat) 은 실제 label값입니다.
- label이 1(real)일때는, 첫번째 항만 유효하지만, label이 0(fake)이면, 두번째 항만 유효하게 됩니다.
이제 GAN에서 BCE가 어떤 의미를 갖는지 살펴보겠습니다.

즉, Discriminator는 실제 데이터를 1로, Generator에서 생성한 데이터를 0으로 분류하려고 하며, Generator는 Discriminator가 자신이 생성한 이미지를 1로 분류하는 것을 목표로 합니다. D와 G는 결국에 two-player의 min-max game을 한다는 것입니다


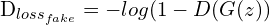

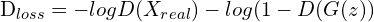
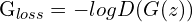
위는 논문에 제시된 loss함수 입니다. E[-logD(x)]는 discriminator가 실제 데이터 x를 1의 확률에 가깝게 분류할수록, loss값은 작아지게 되지만, 반면에 이를 0(fake)에 가깝게 예측하면, loss가 증가하는 것으로 이해할 수 있습니다. 다음 항인 E[-log(1-D(G(z)))]는 Generator가 생성한 이미지인 G(Z)를 D가 판단한 확률이 1(real)로 가까이 갈수록 loss가 증가하지만, 0(real)로 갈수록 loss값이 감소하게 됩니다. 즉, D의 입장에서는 G가 만든 이미지를 가짜(0)로 분류해야, loss가 줄어들게 될 것입니다. 반면에, G의 입장에서 E[-log(1-D(G(z)))]는 D를 속이는 것이 목적이므로, D가 올바르게 분류할 수록 G가 제대로 만들고 있지 못한다는 의미이므로, 반대로 loss를 키워서 G에게 penalty를 부여할 것입니다.
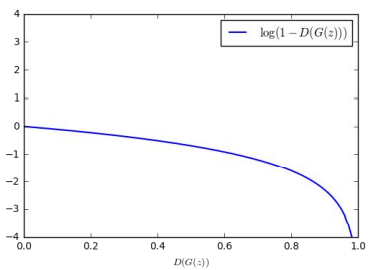
실제 학습시 Generator는 D(G(z))가 1(real) 이 되도록 학습을 진행할 텐데, 그래프를 보면 1로 가까울수록 오히려 loss함수의 graident값이 커져서 학습이 잘 안되는 상황이 발생합니다. 또한 0에서 시작할 것인데, 0근처에서의 gradient값이 매우 작아서도 학습이 잘 안될 것입니다. 이를 해결하고자 다음과 같이 trick을 써서 학습이 잘 되도록 합니다.


즉 위의 그래프를 보면, Generator입장에서 D(G(Z))가 0으로 갈수록 loss가 크고 gradient가 커지지만, 학습의 목표인 D(G(z))가 1로 가까워질수록 loss값도 줄어들면서 gradient값도 줄어들어 안정적으로 학습하는 것을 알 수 있습니다.
GAN의 전체 학습과정에 대한 pseudo-code는 다음과 같습니다

6. Pytorch Implementation
Dataset
Fashion-MNIST dataset을 이용하여 GAN을 실습해 보겠습니다.
Fashion-MNIST
- Database of 60,000 fashion images
- Each image of size 28×28 ( grayscale ) is associated with a label from 10 categories like t-shirt, trouser, sneaker, etc.
Import module
import os
import numpy as np
import math
from PIL import Image
import matplotlib.pyplot as plt
from tqdm.notebook import tqdm
import torch
import torch.nn as nn
import torch.nn.functional as F
import torchvision
from torchvision import datasets
from torchvision import models
from torchvision import transforms
from torch.utils.data import DataLoadertrain_transform = transforms.Compose([
transforms.ToTensor(),
transforms.Normalize(mean=(0.5), std=(0.5))])
train_dataset = datasets.FashionMNIST(root='./data/', train=True, transform=train_transform, download=True)
train_loader = torch.utils.data.DataLoader(dataset=train_dataset, batch_size=128, shuffle=True)C:\Users\wilko\anaconda3\lib\site-packages\torchvision\datasets\mnist.py:498: UserWarning: The given NumPy array is not writeable, and PyTorch does not support non-writeable tensors. This means you can write to the underlying (supposedly non-writeable) NumPy array using the tensor. You may want to copy the array to protect its data or make it writeable before converting it to a tensor. This type of warning will be suppressed for the rest of this program. (Triggered internally at ..\torch\csrc\utils\tensor_numpy.cpp:180.)
return torch.from_numpy(parsed.astype(m[2], copy=False)).view(*s)HyperParameter Setting
class AttrDict(dict):
def __init__(self, *args, **kwargs):
super(AttrDict, self).__init__(*args, **kwargs)
self.__dict__ = selfconfig = AttrDict()
config.data_path = 'data/'
config.save_path = 'save/'
config.dataset = 'FashionMNIST' #FashionMNIST
config.n_epoch = 500
config.log_interval = 100
config.save_interval = 20
config.batch_size = 64
config.learning_rate = 0.0002
# Momentum update for Adam optimizer
config.b1 = 0.5
config.b2 = 0.999
config.img_shape = (1, 32, 32) # FahsionMNIST is grayscale images
config.latent_size = 100 # Random noise's dimension
config.augmentation = transforms.Compose([
transforms.Resize((config.img_shape[1], config.img_shape[2])), # Resize (28, 28) -> (32, 32)
transforms.ToTensor(), # image to Tensor
transforms.Normalize(mean=[0.5], std=[0.5]) # Normalize inputs
])
config.denormalize = lambda x: x*0.5+0.5 # Denormalize outputs for visualization
config.device = torch.device('cuda' if torch.cuda.is_available() else 'cpu') # GPU setting# Creating Folder for dataset
if not os.path.isdir(config.data_path):
os.makedirs(config.data_path)
if not os.path.isdir(os.path.join(config.save_path, config.dataset)):
os.makedirs(os.path.join(config.save_path, config.dataset))# Check GPU opr CPU
config.devicedevice(type='cuda')HyperParameter Setting
train_dataset = datasets.FashionMNIST(
config.data_path,
train = True,
download = True,
transform = config.augmentation
)# DataLoader -> Makes dataset into mini-batches
train_loader = DataLoader(train_dataset, batch_size=config.batch_size, shuffle=True)GAN
- Leaky ReLu : loss가 D에서 G로 back propagation이 일어날 때, vanishing gradient를 완화하기 위해 사용
class Generator(nn.Module):
def __init__(self, config):
super(Generator, self).__init__()
self.model = nn.Sequential(
*self.block(config.latent_size, 128, batchnorm=False),
*self.block(128, 256),
*self.block(256, 512),
*self.block(512, 1024),
nn.Linear(1024, int(np.prod(config.img_shape))),
nn.Tanh()
)
def forward(self, z):
img = self.model(z)
img = img.reshape(img.shape[0], *config.img_shape)
return img
def block(self, input_size, output_size, batchnorm=True):
layers = [nn.Linear(input_size, output_size)]
if batchnorm:
layers.append(nn.BatchNorm1d(output_size))
layers.append(nn.LeakyReLU(0.2, inplace=True))
return layersclass Discriminator(nn.Module):
def __init__(self, config):
super(Discriminator, self).__init__()
self.model = nn.Sequential(
nn.Linear(int(np.prod(config.img_shape)), 512),
nn.LeakyReLU(0.2, inplace=True),
nn.Linear(512, 256),
nn.LeakyReLU(0.2, inplace=True),
nn.Linear(256, 1),
nn.Sigmoid()
)
def forward(self, img):
img = img.reshape(img.shape[0], -1)
validity = self.model(img)
return validity Optimzier and Loss_func
criterion = nn.BCELoss()
generator = Generator(config).to(config.device)
discriminator = Discriminator(config).to(config.device)
optimizer_g = torch.optim.Adam(generator.parameters(), lr=config.learning_rate, betas=(config.b1, config.b2))
optimizer_d = torch.optim.Adam(discriminator.parameters(), lr=config.learning_rate, betas=(config.b1, config.b2))Train Generator and Discriminator
g_loss_list = []
d_loss_list = []
for epoch in tqdm(range(config.n_epoch)):
for i, (real_img, _) in enumerate(train_loader):
real_img = real_img.to(config.device)
"""
adversarial loss에 사용될 ground truth들입니다.
Discriminator에게 있어 실제 이미지는 1, generator가 생성한 fake 이미지는 0을 label로 합니다.
반대로 Generator는 자신이 생성한 fake 이미지의 label이 1이 되게 하여 Discriminator를 fooling 합니다.
"""
# real_img.shape[0] -> batch_size
valid_label = torch.ones((real_img.shape[0], 1), device=config.device, dtype=torch.float32)
fake_label = torch.zeros((real_img.shape[0], 1), device=config.device, dtype=torch.float32)
"""
Gaussian random noise를 Generator에게 입력하여 fake 이미지들을 생성합니다.
"""
z = torch.randn((real_img.shape[0], config.latent_size), device=config.device, dtype=torch.float32)
gen_img = generator(z)
"""
Discriminator가 실제 이미지와 Generator가 생성한 이미지를 잘 구별하는지 loss를 계산합니다.
이 때, Generator는 현재 계산된 loss로 학습되지 않으므로,
detach() 함수를 이용하여 생성 이미지를 computation graph에서 분리한 후 Discriminator의 입력으로 넣어줍니다.
"""
real_loss = criterion(discriminator(real_img), valid_label)
fake_loss = criterion(discriminator(gen_img.detach()), fake_label)
d_loss = (real_loss + fake_loss) * 0.5
"""
Discriminator를 업데이트합니다.
"""
optimizer_d.zero_grad()
d_loss.backward()
optimizer_d.step()
# ====================================================#
# Train Generator #
# ====================================================#
"""
Gaussian random noise를 Generator에게 입력하여 fake 이미지들을 생성합니다.
"""
z = torch.randn((real_img.shape[0], config.latent_size), device=config.device, dtype=torch.float32)
gen_img = generator(z)
"""
Generator가 Discriminator를 속일 수 있는지 loss를 계산합니다.
"""
g_loss = criterion(discriminator(gen_img), valid_label)
"""
Generator를 업데이트합니다.
"""
optimizer_g.zero_grad()
g_loss.backward()
optimizer_g.step()
if (i+1) % config.log_interval == 0:
g_loss_list.append(g_loss.item())
d_loss_list.append(d_loss.item())
print('Epoch [{}/{}] Batch [{}/{}] Discriminator loss: {:.4f} Generator loss: {:.4f}'.format(
epoch+1, config.n_epoch, i+1, len(train_loader), d_loss.item(), g_loss.item()))
if (epoch+1) % config.save_interval == 0:
save_path = os.path.join(config.save_path, config.dataset, 'epoch_[{}].png'.format(epoch+1))
gen_img = config.denormalize(gen_img)
torchvision.utils.save_image(gen_img.data[:25], save_path, nrow=5, normalize=True) 0%| | 0/500 [00:00<?, ?it/s]
Epoch [1/500] Batch [100/938] Discriminator loss: 0.2325 Generator loss: 2.8826
Epoch [1/500] Batch [200/938] Discriminator loss: 0.2301 Generator loss: 2.8940
Epoch [1/500] Batch [300/938] Discriminator loss: 0.2925 Generator loss: 2.6345
Epoch [1/500] Batch [400/938] Discriminator loss: 0.2805 Generator loss: 1.4662
Epoch [1/500] Batch [500/938] Discriminator loss: 0.3207 Generator loss: 1.4996 <br>
...
Epoch [500/500] Batch [400/938] Discriminator loss: 0.3782 Generator loss: 2.5310
Epoch [500/500] Batch [500/938] Discriminator loss: 0.1584 Generator loss: 3.3231
Epoch [500/500] Batch [600/938] Discriminator loss: 0.1210 Generator loss: 3.0685
Epoch [500/500] Batch [700/938] Discriminator loss: 0.2943 Generator loss: 2.4517
Epoch [500/500] Batch [800/938] Discriminator loss: 0.2102 Generator loss: 3.3962
Epoch [500/500] Batch [900/938] Discriminator loss: 0.1978 Generator loss: 4.0172plt.title('GAN training loss on {} data'.format(config.dataset))
plt.plot(g_loss_list, label='generator loss')
plt.plot(d_loss_list, label='discriminator loss')
plt.legend()
plt.show()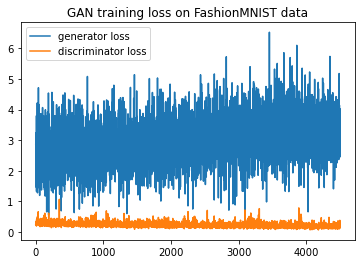
Result

