
다음 논문은 privacy-attack의 개념을 최초로 제시한 논문이다. 위 논문에서는, sparse한 colored points clouds를 입력으로 받아서 2D Image를 합성할 수 있다는 것을 보여주었다.
- 입력으로는 특정 시점으로 projection된 point의 depth, color, SIFT descriptor가 들어가고, 출력으로는 그 시점에서의 color image가 나온다
1. Introduction
- SfM을 통해 reconstructed된 model은 sparse한 3D point cloud를 가지고 있으며, descriptor, color, point visibility, camera pose등의 부가적인 정보를 가지고 있다고 가정.
Contribution
1. unknown한 keypoint orientation, scale, 3D point visibilities에 대해서 2D 이미지 합성이 가능한 것을 보여줌
2. 3가지 Neural networks을 사용
- 1st: visibility estimation
- 2nd: image reconstruction
- 3rd: Adversarial framework를 기반의 이미지 quality 개선
3. Point의 Descpritor, color, camera poses, visibility의 역할을 분석하고, descriptors만으로도 충분히 이미지 복원이 가능하다는 것을 보여줌
4. Privacy-Preserving의 필요성을 제시함
- 앞서 언급된 3가지 network들은 NYU2와 MegaDepth 데이터셋을 이용하여 SfM reconstructions으로 복원된 700개 이상의 실내/실외 데이터셋을 사용하여 진행
- 모든 훈련데이터셋은 COLMAP을 이용하여 생성
2. Related Work
Inverting features
- SIFT나 HOG features에 의해 encoding된 것이 무엇인지 파악하여 이미지를 복원하는 방법들이 연구됨
- 하지만 기존의 방법들은 dense features를 기반으로 함
- 본 논문서는 말 그대로 저장된 SfM point clouds와 SIFT descriptors를 이용하여 이미지를 복원하려 함
- Projected된 3D points는 single image의 SIFT 특징점과 차이점들이 있음.
1) SfM의 point cloud가 sparse한 영향으로, 2D point distribution이 매우 sparse하며 불규칙적 일수도 있다
2) SfM은 3D points의 descriptor만 가지기 때문에, SIFT keypoint의 크기나 방향이 상실
3) 각 3D point당 1개의 descriptor를 가지고 image source를 모르기 때문에 perspective에서 왜곡이나 photometric inconsistency가 발생
Image-to-Image Translation
- U-Net, adversarial loss, percpetual loss등을 이용하여 이미지 변환이 가능.
Upsampling
- Input&Output의 도메인이 같을 때, 딥러닝은 up-sampling이나 superresolution에 유용함
- 하지만, 기존의 upsampling 방법들은 이미지가 uniform하게 sparse할 때를 가정.
- 본 논문에서는 non-uniform sparsity를 가정
Novel view synthesis and image-based rendering
- Deep neural networks를 사용하면 photorealism을 증대시켜 이미지 합성이 가능
CNN-based privacy attacks and defense
- Speciale et al.은 privacy preserving image-based localization problem을 소개하고, 이를 해결하기 위해 line clouds를 이용한 새로운 camera pose estimation 방법을 제안
3. Method
본 논문이 제안하는 pipeline의 Input으로는 SfM 3D point cloud를 특정한 시점으로 project한 points와 3D points의 부가적 정보(SIFT descriptor, color 등)이 project되는 픽셀에 같이 저장되어 있다. 만약 여러 점들이 같은 픽셀도 투영된다면, 카메라와 가장 가까운 점에 특성과 depth를 저장.
Visibility Estimation
- SfM 3D point clouds이 sparse하고 기저의 geometry가 잘 감춰져 있기 때문에, 쉽게 어떤 카메라로부터 3차원 점이 보이는지 파악하기 쉽지 않음
- 이로 인해 view에서는 보이지 않는 3D points가 2D pixels에 있을 수 있음. 따라서 이러한 점들의 제거는 필수적
- 따라서 data-driven의 neural network(VISIBNet)를 사용해서 point visibility를 복원하고자 함
Coarse Image Reconstruction and Refinement
- Feature map으로부터 이미지 합성을 위해서는 coarser한 합성(COARSENET)과 refinement(REFINENET)을 거침
- COARSENET은 feature map을 condition으로 feature map과 같은 높이, 너비의 RGB이미지를 합성, REFINENET은 final color image를 출력.
3.1 Visibility Estimation

- CoarseNet 자체를 이용해 visibility를 reason할 수 있지만, 부정확함
- 특히 Implicit visible한 점들을 이용하면 c처럼 부정확하게 복원
- 따라서 Explicit visibility estimation을 이용함
VisibSparse
- detph channel을 input으로 하며, kxk kernel에 min filter를 적용하면 filtered depth map을 얻을 수 있음
- filtered depth값의 5%보다 크지 않으면 visible로 간주. 그렇지 않으면 point는 occulued로 간주
VisibDense
- SfM 3D point cloud에 카메라 poses와 measurements이 저장되어 있으면, dense한 scene reconstruction이 가능
- z-buffering을 이용하여 3D point visibility를 계산하고 이를 COLMAP에 구현되어 있는대로 Dense하게 복원
VisibNet
- SfM 카메라 poses나 image measurements이 불가능하면, VISIBDENSE는 사용 불가능하다
- 따라서 본 논문에서는 regression-based 접근법을 사용하여 input feature maps의 visibility를 판단하게 된다. VISIBNET이라는 네트워크를 도입하여 "visible" 혹은 "Occluded"로 판단.
- Ground truth는 앞서 언급된 VisibDense 방법을 이용하여 얻음
- COARSENET전 VisibNet을 적용하면 복원된 이미지들의 quality가 높아짐
3.2 Architecture
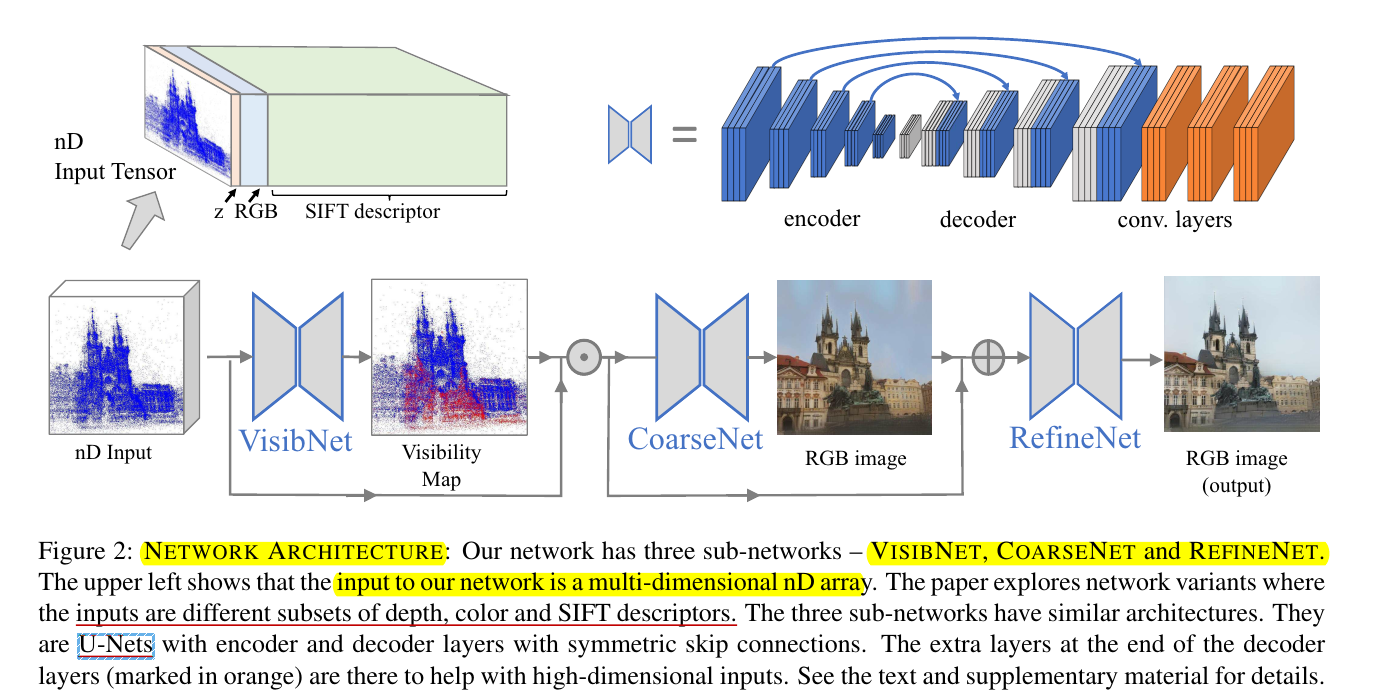
- Network의 input으로는 HxWxn dimension의 feature map이 들어간다. 이때 n-dimensional features로는 point의 해당 2D location에서의 depth, color, SIFT-features의 combination이 된다.
- sub-networks은 U-Nets의 비슷한 아키텍쳐를 가짐
- 기존의 U-nets과는 달리, decoder 뒷부분에 추가적인 layer가 있는데, 이로 인해 skip connection을 통한 low-level features(SIFT descriptors)의 propagation에 도움이 되고, highly sparse&irregular한 artifacts를 감쇠시킨다고 함.
3.3 Optimization
- VISIBNET, COARSENET, REFINENET 모두 batch normalization이 적용되었다(마지막 layer는 제외)
VISIBNET
- feature map의 points이 visible/occulued한지 판단
- VISIBDENSE를 이용한 ground-truth visibility mask를 생성
- Input feature map을 , target source images를 이라 하면, VISIBNET의 목적함수는 다음과 같다

- V:VISIBNET, : Ground-truth visibility map
COARSENET
- L1 pixel loss와 L2 perceptual loss(by pretrained VGG16)의 결합
- COARSENET이 훈련되는 동안 VISIBNET은 fixed
- COARSENET의 목적함수는 다음과 같다

- : COARSNET
- : pretrained network(VGG16)의 각 relu lyaer
REFINENET
- L1 pixel loss와 L2 perceptual loss(COARSENET과 동일), adversarial loss의 결합
- REFINENET training시, COARSENET과 VISIBNET은 fixed
- Conditional discriminator를 추가: 실제 SfM에 사용되는 이미지들과 REFINENET에서 합성된 이미지들간의 real/fake 구분

- : REFINENET, : Discriminator
4. Experimental Results
point clouds에 대한 missing information, visibility estimation의 효율성, input scene samples의 sparse, irregular distribution에 대해서 survey
-
Dataset: MegaDepth, NYU dataset을 이용. 이들 데이터셋은 scene의 내용, 이미지 해상도가 다르고, distiribution이 많이 다른 SfM points를 생성하게 됨
-
Preprocessing: SfM implementation으로는 COLMAP을 사용. 각 데이터셋을 training, validation, testing set으로 분할. color range가 [0,1]인 MAE(mean absolute error)을 metric으로 이용. average structured similarity(SSIM)도 같이 이용. MAE는 낮을수록, SSIM은 높을수록 좋은 결과
Inverting single Image SIFT Features
- unknown한 keypoint들의 scale, orienatation, multiple unknown 이미지 sources에 대해서 inverting features를 측정

- 위의 테이블을 보면, sparsity가 커져도 MAE나 SSIM의 성능 지표가 크게 악화되지 않음
- 마지막 row를 보면, SIFT descriptor를 다른 image source에서 가져왔을 때에도, 결과가 크게 악화되지 않음을 보여줌

- 또한 위의 결과를 보면 keypoint features의 scale과 orientation을 달리 했을 때에도 robust하다는 것을 보여줌
4.1 Visibility Estimation
제안된 VISIBNET 모델의 성능을 측정하고 이것을 VISIBSPARSE, VISIBDENSE와 비교.
-
VISIBNET은 scene type, sparsity정도, input attributes(depth, color, descriptors)의 선택에 덜 민감

-
다음 표를 보면, VISIBNET에 의해 occuluded되었다고 판명난 points이 제거되었을때가 COARSENET에게 vsibility를 판명시키는 burden을 주었을때와 비교해 improvement가 일어났음을 보여줌
-
수치적으로 큰 개선이 일어난 것 처럼 보이지는 않지만, 아래 그림을 보면 visual한 artifacts이 제거된 것을 알 수 있음

4.2 Relative Significance of Point Attributes
SfM points의 attributes의 중요성을 파악하는 part. SfM points를 저장할때 어떤 attributes를 제거해도 되는지 알 수 있음.
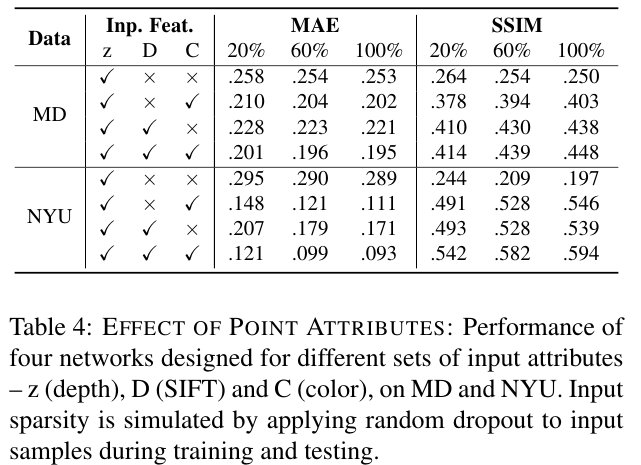
- Sparsity에 invariant하며, input feature map이 단지 depth일 뿐이라도 모든 fine details을 capturing할 수 있는 것을 보여줌.
- color나 SIFT descriptors가 더 들어가면 visual quality가 더 좋아짐

4.3 Significance of RefineNet

- Input feature가 depth와 descriptor일때와 모든 것을 이용할 때를 비교해봄. COARSENET은 color정보가 없으면 해메는 것이 관찰됨. 하지만 RefineNet을 통해 그럴듯한 색상이 생성되는 것을 확인 가능
5. Conclusion
- sparse SfM point clouds로부터 이미지를 합성하는 방법을 제시
- privacy & security risk를 제시함
- Scene structure를 숨기면서도 privacy preserving camera pose estiamtion을 하는 것이 주된 목표
