
고명암비(HDR) 장면을 캡처하는 것은 카메라 설계에서 가장 중요한 문제 중 하나입니다. 대부분의 카메라는 서로 다른 노출 수준에서 촬영된 이미지를 결합하는 노출 합성(Exposure Fusion) 방식을 사용하여 명암비를 증가시킵니다. 그러나 이 접근 방식은 보통 3~4 스톱의 제한된 노출 차이에서만 효과적으로 작동합니다. 매우 넓은 명암비가 필요한 장면에서는, 입력 간의 잘못된 정렬, 조명 불일치, 톤 매핑 아티팩트 등으로 인해 성능이 크게 저하됩니다.
이 논문에서는 9 스톱 차이의 입력을 합성할 수 있는 최초의 노출 합성 기술인 ‘UltraFusion’을 제안합니다. 핵심 아이디어는 노출 합성을 가이드 인페인팅(guided inpainting) 문제로 모델링하는 것입니다. 여기서 언더노출 이미지를 가이드로 활용하여, 오버노출된 영역의 하이라이트에 누락된 정보를 보완합니다.
UltraFusion은 언더노출 이미지를 엄격한 제약이 아닌 유연한(soft) 가이드로 사용함으로써, 정렬 오류나 조명 변화에 더 강인한 성능을 보입니다. 또한, 생성 모델의 이미지 프라이어(image prior)를 활용하여 자연스러운 톤 매핑도 가능합니다. 실험 결과, UltraFusion은 최신 HDR 벤치마크에서 HDR-Transformer보다 우수한 성능을 보였습니다.
또한, UltraFusion의 성능을 평가하기 위해 최대 9스톱의 노출 차이를 갖는 실제 환경 기반의 새로운 벤치마크 데이터셋, UltraFusion dataset을 구축하였습니다. 다양한 상황에서 실험한 결과, UltraFusion은 아름답고 고품질의 합성 결과를 생성할 수 있음을 확인했습니다.
최신 기술 발전에도 불구하고, 대부분의 HDR 알고리즘은 동적 범위(dynamic range)를 제한적으로만 증가시킬 수 있습니다. 예를 들어, 상용 카메라에서 처음으로 사용된 HDR 알고리즘인 HDR+ [9]는 약 8배(3 스톱)의 동적 범위 증가만을 안정적으로 지원합니다.
따라서 이 연구에서는 다음과 같은 핵심 질문을 다룹니다:
"9 스톱과 같은 큰 노출 차이를 가진 두 이미지를 합성하여 카메라의 동적 범위를 획기적으로 확장할 수 있을까?"
이 문제는 근본적으로 도전적인데, 그 이유는 다음 세 가지 주요 이슈 때문입니다:
1️⃣ 정렬 문제 (Alignment Issue)
동적인 장면을 처리하려면, 대부분의 HDR 합성 알고리즘은 먼저 입력 프레임 간 정렬을 수행해야 합니다.
그러나 밝기 차이가 큰 경우 정렬이 매우 어렵고, 정렬 실패 시 고스트 아티팩트(ghosting artifacts)가 발생합니다.
→ 이는 논문 Figure 1의 오른쪽 장면의 확대 이미지에서 확인할 수 있습니다.
2️⃣ 노출 수준에 따른 외형 변화
많은 HDR 알고리즘은 언더노출 이미지를 단순히 어두운 버전으로 간주합니다.
하지만 실제로는 노출 수준에 따라 물체의 외형이 달라질 수 있습니다.
→ 예: Figure 1의 왼쪽 장면에서 배(ship)의 모습이 노출에 따라 바뀌며, 부자연스러운 합성 결과로 이어짐.
3️⃣ 톤 매핑(Tone Mapping) 문제
HDR 합성 결과는 종종 HDR 이미지로 생성되며, 이를 일반 LDR(저명암비) 디스플레이에 직접 표시할 수 없습니다.
따라서 톤 매핑 과정을 거쳐야 하는데, 동적 범위가 클수록 이 과정에서 추가적인 시각적 문제가 발생합니다.
→ 자연스러운 대비 및 풍부한 디테일을 유지하기 어렵고, 이는 Figure 1의 기존 HDR 재구성 결과 확대 부분에서 잘 드러납니다.
이러한 이유로, 큰 노출 차이를 효과적으로 다루면서도 자연스럽고 고품질의 결과를 생성하는 것은 매우 도전적인 과제입니다.
이 연구에서는 기존과 전혀 다른 방식의 노출 합성 기법인 UltraFusion을 제안합니다. UltraFusion은 노출 합성을 ‘가이드 인페인팅(guided inpainting)’ 문제로 재정의한 방법입니다.
이 방식에서는 사용자가 두 장의 이미지를 촬영합니다:
하나는 정상 노출된 이미지로, 밝은 물체는 오버노출되어 있습니다.
다른 하나는 언더노출된 이미지로, 가장 밝은 부분만 촬영되어 있는 상태입니다.
UltraFusion은 이 중 정상 노출 이미지를 기준(reference)으로 삼고, 그 하이라이트 영역의 누락된 정보를 인페인팅합니다.
전통적인 인페인팅과 달리, 이 방법은 언더노출 이미지를 가이드로 활용하여 완전히 새로 생성하는 것이 아니라, 실제 촬영된 정보를 기반으로 복원합니다.
✅ 이 접근 방식의 장점 (대규모 노출 차이를 다룰 때):
1️⃣ 직접적인 LDR 생성
기존의 HDR 합성 방식은:
먼저 HDR 이미지를 생성한 후,
이를 일반 디스플레이용으로 톤 매핑하여 LDR로 변환합니다.
→ 이 과정에서 오류 누적이 발생할 수 있습니다.
하지만 UltraFusion은 처음부터 LDR 결과물을 생성하므로
톤 매핑으로 인한 품질 저하나 오류 전파(cascading error)를 방지합니다.
2️⃣ 소프트 가이던스(Soft Guidance)
언더노출 이미지를 엄격한 제약(hard constraint)이 아닌
유연한 가이드(soft guidance)로 사용하기 때문에:
정렬 오류에 강인하고
조명 변화에도 유연합니다.
→ Figure 1의 오른쪽 장면에서는 정렬 오류,
→ 왼쪽 장면에서는 조명 차이를 잘 처리하는 모습을 보여줍니다.
3️⃣ 자연스러운 출력 품질
생성 모델(generative model)의 프라이어(image prior)를 활용하여,
더 자연스러운 톤과 디테일을 가진 결과물을 생성합니다.
→ 인위적이거나 이상한 시각적 아티팩트가 줄어듭니다.
🤖 ControlNet 접근의 한계
단순히 두 입력 이미지를 이용해 ControlNet을 학습시키는 방식도 생각해볼 수 있지만,
어떤 이미지를 기준으로 삼을지 불명확하고,
실제로는 오버노출과 언더노출 이미지를 혼용하면서 결과에 아티팩트가 발생합니다.
또한, 가짜 정보(fake content)가 생성될 가능성도 높습니다.
→ Figure 2의 예시 참고.
🛠️ UltraFusion의 핵심 구성 요소
① Pre-alignment 단계
언더노출 이미지를 오버노출 이미지에 맞춰 정렬(warping)
가려진 영역(occlusion)은 마스킹 처리하여 이후 인페인팅에 방해되지 않게 함
② Guided Inpainting
Stable Diffusion 기반의 생성 모델 활용
인페인팅 시 언더노출 이미지에서 추출한 정보로 가이드
<핵심 모듈>
Decompose-and-Fuse Control Branch: 언더노출 이미지에서 밝기(luminance)를 제거하고 구조와 색상 정보만 분리 추출, 멀티스케일 크로스 어텐션을 통해 오버노출 이미지와 특징 융합
Fidelity Control Branch: 출력 이미지가 현실과 더 충실하게 일치하도록 보조, 구조 및 색상 충실도 보존
🎯 데이터셋 및 실험
기존에는 동적인 장면에서의 노출 합성을 위한 대규모 학습 데이터가 존재하지 않음
따라서 새로운 학습용 데이터 합성 파이프라인도 제안
정적인 고품질 다중 노출 데이터와 비디오 데이터를 활용하여 동적 장면을 모사
📷 벤치마크 테스트
직접 수집한 100쌍의 오버/언더노출 이미지로 이루어진 벤치마크 사용
주야간, 실내외, 움직임이 있는 장면 포함
🔚 결론
UltraFusion은 기존 방법에 비해:
더 큰 노출 차이 (최대 9스톱)
더 복잡한 동적 움직임
을 효과적으로 처리할 수 있으며, 더 높은 품질의 결과물을 생성함을 실험적으로 입증했습니다.
Related work
HDR 영상처리(HDR Imaging)는 일반적으로 융합이 일어나는 도메인(domain)에 따라 두 가지 방식으로 나눌 수 있습니다:
1️⃣ HDR 재구성 (HDR Reconstruction)
이 방식은 카메라 응답 함수(Camera Response Function, CRF)를 역으로 추정하여, 여러 노출의 이미지들을 선형 HDR 도메인에서 병합합니다. 대부분의 경우, 생성된 HDR 이미지는 표준 저명암비(LDR) 디스플레이에서 보기 위해 톤 매핑(tone mapping) 과정을 거쳐야 합니다.
2️⃣ 다중 노출 합성 (MEF: Multi-Exposure Fusion)
더 저비용의 대안으로, MEF는 LDR 도메인에서 직접 여러 이미지를 결합합니다. 이 과정은 CRF 보정이나 복잡한 톤 매핑 과정을 회피할 수 있다는 장점이 있습니다.
🧟♂️ 공통 문제: 고스트 현상 (Ghosting)
HDR 방식에 관계없이, 거의 모든 HDR 처리 방식은 다음 문제에 직면합니다: 카메라 흔들림이나 피사체 움직임으로 인해 고스트 아티팩트가 생김. 이전의 연구들은 이를 해결하기 위해 광학 흐름(optical flow) 또는 어텐션 메커니즘(attention)을 활용해 명시적 혹은 암시적으로 정렬을 시도해 왔습니다. 하지만, 큰 움직임이 있을 경우 상보적 영역(complementary region)에 오클루전(가림 현상)이 발생하고, 그 결과 보기 불쾌한 아티팩트가 생깁니다.
💨 디퓨전 모델의 등장
최근 디퓨전 모델(diffusion models)의 급부상으로 다양한 작업에서 성공적인 적용이 이루어졌습니다:
이미지 생성 (예: ControlNet, [59, 65])
이미지 복원 (예: [21, 23, 31, 47, 63])
이미지 편집 (예: [4, 14, 29, 38])
이미지 인페인팅 (예: [5, 26, 50, 64])
HDR 분야에서도 HDR 디고스팅(deghosting)을 중심으로 몇몇 시도가 있었으나: 대부분은 대규모 학습 데이터를 활용한 디퓨전 프라이어(prior)를 잘 사용하지 못했고, 따라서 일반화 성능이 떨어졌습니다.
또한 일부 연구는 디퓨전 프라이어를 활용하긴 했지만, 단일 이미지 HDR(single image HDR)에 초점을 맞추었고, 다른 노출의 참조 이미지 없이 생성된 결과는 신뢰성이 부족했습니다.
🌟 UltraFusion의 차별점
UltraFusion은 기존 디퓨전 기반 인페인팅 방법과 다르게: 짧은 노출 이미지(short-exposed image)를 가이드(reference)로 활용하여, 오버노출된 이미지의 하이라이트 영역을 보다 정확하고 자연스럽게 복원합니다. 즉, 완전히 무(無)에서 생성하는 방식이 아니라, 실제 촬영된 이미지의 정보를 이용하여 더욱 신뢰할 수 있는 인페인팅을 수행합니다.
🎨 톤 매핑 (Tone Mapping)
톤 매핑은 HDR 이미지를 표준 디스플레이에서 볼 수 있는 LDR 이미지로 변환하는 과정입니다.
하지만 다음과 같은 문제점이 있습니다: 정답(ground truth) 톤 매핑 이미지를 얻는 것이 어렵기 때문에, 지도되지 않은 학습(unsupervised learning) 기반의 딥러닝 기법들이 등장하였습니다.
예: 적대적 학습(Adversarial Learning) [45], 대조 학습(Contrastive Learning) [2]
데이터 부족 문제를 해결하기 위해 Cai 외 [1]는 13개 톤 매핑 알고리즘의 결과 중 가장 우수한 이미지들을 수작업으로 골라 학습 데이터로 사용했습니다. 그러나 기존 톤 매핑 알고리즘은: 강력한 이미지 프라이어 부족, 데이터 제약으로 인해 극단적인 HDR 장면에서 일반화 및 시각적 품질 유지에 한계를 드러냅니다.
🖌️ UltraFusion의 톤 매핑 강점
UltraFusion은 디퓨전 기반의 이미지 프라이어를 통합하여: 극단적인 고명암비 장면에서도 시각적으로 뛰어난 결과를 생성할 수 있습니다. → Fig. 1에서 시각적으로 확인 가능
요약 한 줄 정리: 기존 HDR 기술들이 겪는 정렬 오류, 고스트 현상, 톤 매핑 문제를 해결하기 위해 UltraFusion은 디퓨전 모델 기반의 소프트 인페인팅과 짧은 노출 이미지 가이드를 결합한 혁신적인 접근을 제안합니다.
🔧 3. 방법론 (Methodology)
오버노출 이미지과 언더노출 이미지가 주어졌다고 가정할 때, 기존의 노출 합성(exposure fusion) 알고리즘들은 두 이미지의 주파수 대역(frequency bands)을 직접적으로 결합합니다.
하지만 이러한 방식은: 정렬 오류(misalignment error), 조명 변화(lighting variation)
에 매우 민감하다는 한계가 있습니다.
🖌️ 본 논문에서는 이를 인페인팅(inpainting) 문제로 새롭게 모델링합니다.
📌 구체적으로:오버노출 이미지를 기준 이미지(base image)로 사용하고, 하이라이트 영역의 누락된 정보를 복원(inpaint)합니다.
이때, 인페인팅된 하이라이트가 현실적인 결과가 되도록: 언더노출 이미지의 하이라이트 정보를 가이드(guidance)로 활용합니다.
🧠 네트워크 구성
이러한 아이디어에 기반하여, 우리는 2단계 네트워크 구조를 설계하였습니다 (논문 Fig.3 참고).
🔹 Stage 1: Pre-alignment Stage (정렬 단계)
언더노출 이미지를 오버노출 이미지에 거칠게 정렬(coarse alignment)합니다. 이 정렬된 이미지는 이후 인페인팅 과정에서 소프트 가이던스(soft guidance)로 사용됩니다.
🔹 Stage 2: Guided Inpainting Stage (가이드 인페인팅 단계)
정렬된 언더노출 이미지를 가이드로 활용하여, 오버노출 이미지의 손상된 하이라이트 부분을 복원합니다.
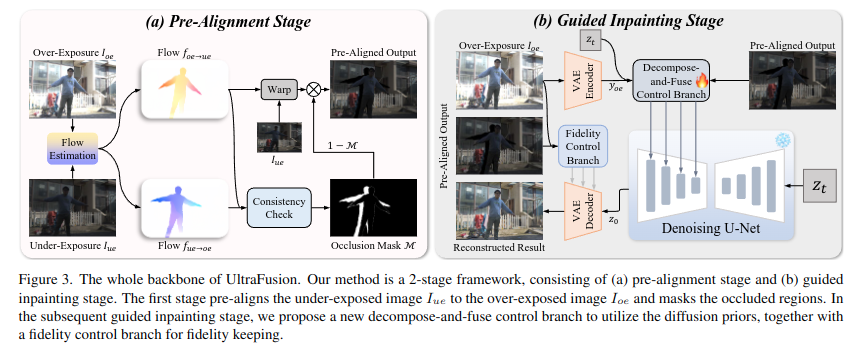
🔹 3.1. 사전 정렬 단계 (Pre-alignment Stage)
대부분의 광학 흐름(optical flow) 기반 정렬 방법은
입력 이미지들이 유사한 밝기(brightness)를 갖고 있다고 가정합니다.
따라서 먼저, 언더노출 이미지의 밝기 분포를 오버노출 이미지와 일치시키기 위해 밝기 매핑 함수(intensity mapping function) [7]를 적용합니다.
🔁 광학 흐름 추정 및 정렬
그 후, 우리는 RAFT [42]라는 사전 학습된(optical flow) 네트워크를 활용하여 다음과 같은 양방향 흐름(bidirectional flow)을 추정합니다: 오버노출 → 언더노출 방향의 흐름, 언더노출 → 오버노출 방향의 흐름
이를 사용해 언더노출 이미지를 오버노출 이미지에 뒤로 워핑(backward warping)하여 정렬합니다.
⚠️ 오클루전 문제와 마스킹
그러나 backward warping 방식은:가려진 영역(occlusion boundary)에서 고스트 현상(ghosting)을 유발하고, 이는 다음 단계 인페인팅에서 아티팩트로 이어질 수 있습니다 [67].
이를 해결하기 위해, 우리는 Forward-Backward Consistency Check [54] 기법을 사용하여
가려진 영역(occluded region) 𝑀을 추정하고, 이를 마스킹(masking) 처리합니다.
✅ 최종적으로 사전 정렬 결과는 다음과 같이 계산됩니다:
결과적으로, 오버노출 이미지에 정렬되고, 가려진 영역은 제거된 언더노출 이미지가 만들어집니다.
📌 이 결과는 논문 Fig. 3(a)에 시각적으로 나타나 있습니다.
🔹 3.2. 가이드 인페인팅 단계 (Guided Inpainting Stage)
우리는 Stable Diffusion 모델 [36]을 기반으로 가이드 인페인팅 모델을 구축했습니다.
이는 디퓨전 모델이 지닌 강력한 생성 프라이어(generative prior)가 인페인팅 중의 모호성(ambiguity)을 해결하는 데 도움이 되기 때문입니다.
기존의 디퓨전 기반 이미지 향상 기법들 [21]과 유사하게, 우리는 다음의 정보를 별도의 제어 브랜치(control branch)를 통해 주입합니다 (논문 Fig. 3(b) 참조):
인페인팅 대상 이미지: 오버노출 이미지 / 하이라이트에 대한 추가 가이드 정보: 언더노출 이미지
현재 디퓨전 단계의 latent 변수 z.
이전 연구 [21]에 따르면 이 latent를 조건으로 포함시키면 이미지 품질이 향상됨, 메인 디퓨전 네트워크는 사전 학습된 U-Net이며, 오버노출 이미지는 먼저 사전 학습된 VAE를 통해 인코딩되어 디퓨전 모듈로 들어가고, 결과는 다시 디코더를 통해 이미지 공간(image space)으로 복원됩니다.
🧠 일반적인 디퓨전 인페인팅과 UltraFusion의 차별점
UltraFusion은 기존 디퓨전 기반 향상 기법과 비교해 두 가지 주요 차이점이 있습니다:
✅ ① Decompose-and-Fuse Control Branch 제안: 단순히 두 이미지를 latent로 넣는 것이 아니라,각 입력 이미지(오버노출/언더노출)와 diffusion latent를 분해해서 제어 신호로 주입.
Fig. 11(b)에서도 설명되듯이, 단순 주입만으로는 디퓨전이 하이라이트 복원을 잘 수행하지 못할 수 있음
✅ ② Fidelity Control Branch 추가 학습
디코딩 시 실제 구조와 색 정보를 더 충실하게 반영할 수 있도록 하는 보조 브랜치
단축 경로(shortcut)를 통해 복원 디코더에 직접 정보 제공
🔧 Decompose-and-Fuse Control Branch 구성 (논문 Fig. 4 참조)
오버노출 이미지: 주요 제어 신호(main control signal)
언더노출 이미지: 소프트 가이드(soft guidance)로 사용
ControlNet [65]을 따르되: 디노이징 U-Net의 인코더와 중간 블록을 복사해서 메인 feature extractor로 사용. 이때 복사된 블록의 파라미터는 훈련 시 업데이트.
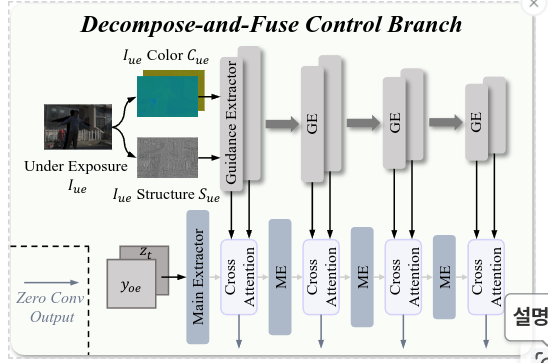
❌ 문제점: 단순 인코딩된는 너무 어두워 무시될 수 있음
VAE 인코더를 통해 얻은 latent를 그대로 사용하면 모델이 무시하거나 노이즈로 판단할 가능성 있음
✅ 해결책: 밝기 변화에 강인한 구조+색 정보 분리
우리는 언더노출 이미지를 다음 두 가지로 분해(decompose)하여 사용합니다: 구조 정보 (Structure), 밝기(luminance) 채널를 정규화하여 사용

🔁 최종 융합 방식: 멀티스케일 Cross Attention
이렇게 추출된 특징은 메인 extractor에 multi-scale cross-attention 방식으로 주입. 각 Cross Attention 모듈의 출력은: 다음 레벨의 메인 extractor로 전달됨. 동시에 U-Net 블록에도 전달되며, 이때는 zero convolution을 통해 적용
📌 정리하면: UltraFusion의 Guided Inpainting은 Stable Diffusion 구조에 기반하면서, 오버노출/언더노출 이미지를 분리된 정보(구조+색상)로 정제하여 조건으로 사용하며, 하이라이트 영역을 보다 현실적이고 충실하게 복원하는 프레임워크입니다.
🎯 Fidelity Control Branch (FCB): 출력의 충실도를 높이기 위한 보조 제어 브랜치
기존의 Decompose-and-Fuse Control Branch만으로는, Stable Diffusion에서 사용하는 VAE(변분 오토인코더)가 이미지 복원 과정에서 텍스처 왜곡(texture distortion)을 일으키는 현상이 종종 관찰됩니다 (논문 Fig. 11(c) 참고).
✅ 목적
: 이러한 문제를 해결하고 출력 이미지의 구조 및 질감을 더욱 사실적으로 유지하기 위해, 우리는 [47]에서 영감을 받아 Fidelity Control Branch (FCB)를 설계하였습니다.
🧱 Fidelity Control Branch의 주요 특징
✔️ 역할
텍스처 왜곡을 완화하기 위해, 추출된 특징(feature)을 VAE 디코더에 직접 주입(inject)합니다.
✔️ 기본 구조
Decompose-and-Fuse Control Branch와 비슷한 아키텍처를 가지지만, 다음 두 가지 핵심 차이점이 있습니다:
1️⃣ 메인 익스트랙터 구조가 다름
FCB의 메인 익스트랙터는 Denoising U-Net이 아니라, VAE Encoder와 동일한 구조를 따릅니다.
목적: VAE 디코더가 복원 시 해당 위치에 정확히 연결되는 단축 경로(shortcut)를 제공하기 위함. 또한, FCB 내부의 소프트 가이던스 추출기도 이에 맞춰 약간 수정됩니다.
2️⃣ 입력 방식
FCB의 메인 익스트랙터는 오버노출 이미지를 직접 입력으로 사용합니다.

✅ 정리하면:
Fidelity Control Branch는 UltraFusion의 복원 품질을 향상시키기 위한 핵심 요소로,
VAE 디코더에 구조적이고 색상에 충실한 특징 정보를 직접 주입함으로써,
텍스처 왜곡을 줄이고 현실에 가까운 고품질 이미지 복원을 가능하게 합니다.
🧪 3.3. 학습 데이터 합성 (Training Data Synthesis)
UltraFusion의 가이드 인페인팅 네트워크를 학습하기 위한 데이터 준비는 매우 도전적인 문제입니다. 모델 학습을 위해서는 이상적으로 다음 조건을 모두 만족하는 대규모 HDR 데이터셋이 필요합니다:
1) 다양한 동적 장면(dynamic scenes)을 포함하고,
2) 최대 9스톱 이상의 노출 차이를 가지고 있으며,
3) 정답에 해당하는 노출 합성 결과(ground truth fusion result)가 존재해야 함
❗ 그러나 현재 존재하는 어떤 데이터셋도 이 세 가지 조건을 모두 만족하지 못합니다.
✅ 해결 방법: 새로운 학습 데이터 합성 파이프라인 제안
UltraFusion은 이 문제를 해결하기 위해 신규 데이터 합성 기법을 설계하였습니다. 논문 Fig. 5에 이 과정이 시각적으로 제시되어 있습니다.
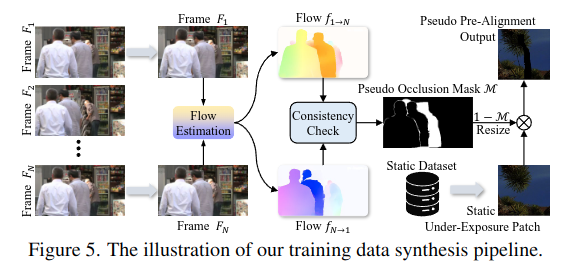
🧩 합성 순서 요약:
① 영상 데이터에서 프레임 샘플링
동적 장면과 모션을 모델링하기 위해, 비디오 데이터셋 [55]로부터 N개의 연속된 프레임을 랜덤하게 샘플링. 이 중 첫 번째 프레임과 마지막 프레임을 선택하여 큰 모션을 만들어냄.
② 광학 흐름 및 오클루전 마스크 생성
선택된 두 프레임 간에 RAFT [42] optical flow를 사용하여 양방향 흐름을 계산. 이후, forward-backward consistency check를 적용하여 → 가려진 영역(occlusion mask)을 의사적으로 생성(pseudo-occlusion mask)
③ 고품질 정적 데이터에서 패치 샘플링
고정된 카메라로 촬영된 정적 고품질 multi-exposure 데이터셋 [1]에서 → 언더노출 이미지 패치를 랜덤으로 샘플링. 이 패치는 정렬된 상태의 ground truth를 이미 포함.
④ 마스킹 및 정렬된 합성 출력 생성
앞서 생성한 pseudo occlusion mask를 샘플링된 패치 크기에 맞게 리사이징. 이 마스크를 적용하여 가려진 영역을 마스킹 처리
결과적으로, 정렬된 언더노출 이미지의 의사 버전(pseudo pre-aligned output)을 생성
🧠 목적 및 효과
이러한 합성 과정을 통해:
실제 동적 장면의 데이터셋이 없어도, 기존의 정적 이미지 쌍(multi-exposure pairs)만으로 → 모션, 오클루전, 정렬 오류에 강한 모델을 학습할 수 있게 됩니다.
✅ 요약
UltraFusion은 정적 multi-exposure 이미지쌍과 비디오 프레임을 조합하여, 의사 동적 장면 학습 데이터를 합성하고, 이로써 실제 동적 장면에 강인한 노출 합성 모델을 학습하는 데 성공했습니다.
Results

| 항목 | UltraFusion의 장점 |
|---|---|
| 정량 성능 | 비참조 품질 지표 4개 모두에서 SOTA |
| 정성 결과 | 하이라이트 복원 및 자연스러운 색 전환 |
| MEF-SSIM | 기존 방법 수준의 정보 보존 |
| Tone Mapping 이슈 없음 | LDR 직접 출력 → 복잡한 후처리 불필요 |

UltraFusion은 기존 MEF나 HDR 기법들과 달리, 정렬 오류, 움직이는 객체, 오클루전 등을 포함한 동적 장면에서도 매우 안정적인 성능을 보이며, 정량적(TMQI) 및 정성적(Fig. 10) 평가에서 모두 최고 결과를 기록했습니다.

| 항목 | UltraFusion 성능 |
|---|---|
| 비참조 지표 | 모든 메트릭에서 SOTA |
| 고난이도 장면 처리 | 매우 밝은 하이라이트(예: 태양)도 자연스럽게 복원 |
| 시각적 비교 | 구조 유지 + 톤 조절 우수 |
| 사용자 평가 | 136명 중 다수 사용자에게 “더 자연스러움”으로 선택됨 |
QnA
-
본 파이프라인이 작동하기 위해서는 optical flow등을 사용하기 위해서는 연속된 시퀀스 내 촬영된 over-exposure하고 under-exposure이미지를 사용해야 하는데, 현실적으로 이런 경우가 있는지?? 단일 이미지 기반 대비 HDR 기법 대비 장점 등을 모르겠음.
-
Training data 생성 시, 비디오 데이터셋에서 pseudo occlusion 마스크를 생성하여 정적인 데이터셋에 masking을 하는 건데, 비디오에서 얻은 occlusion mask는 이미지 내용과 무관하기 때문에 비현실적인 오클루전이 생길 수 있지 않나? 즉, 실제 존재하지 않는 객체에 의해 가려진 것처럼 만들어지는 것이죠. 그냥 Random mask대비 장점?
-
Diffusion에서 보통 classifier-guidance와 같은 constraint를 통해 denoising에 graident를 흘려서 제약은 거는데 UltraFusion은 Geometry constraint 같은 것이 따로 없는 것인지? Training Loss는 단순히 L1 loss를 쓴것 같은데, MEF SSIM과 같은 추가적인 loss는 없는것인지?
문제 1
이 논문에서 제안하는 under-exposure 기반 Soft Guidance가 기존 방식에 비해 갖는 이점이 무엇인지 설명하시오.
: 장노출 이미지에서 빛이 포화되어 정보가 손실된 하이라이트 영역의 텍스처와 구조적 세부 정보(Structure and Texture)를 제공하는 가이드 역할을 합니다. Soft Guidance는 두 이미지 간의 픽셀을 완벽하게 1:1로 매칭시키는 대신, 생성형 모델(Diffusion Model)이 단노출 이미지의 특징을 힌트로 참조하여 자연스럽게 빈 공간을 채우도록 유도하는 방식임.
문제 2
질문: UltraFusion내 단노출 이미지에서 DFCB(Decompose-and-Fuse Control Branch)에서 under exposure 이미지에서 사용하는 정보는 무엇인가? 상기 정보들만 사용하는 이유는?
: 구조(Structure)와 색상(Color). 단노출 이미지를 그대로 가져올 경우, 전체적인 톤 맵핑이 망가지거나 Diffusion 과정에서 혼란을 줄 수 있기 때문에, 휘도를 제외한 순수한 구조와 색상 정보만을 추출하여 구조적인 유사성을 높이면서도 사실적인 색상을 유지하여 빈 공가능 채울 수 있기 때문임.
문제 3
질문: UltraFusion 네트워크에는 생성 품질을 높이기 위한 두 가지 제어 분기(Control Branch)가 존재하는데, 와 FCB(Fidelity Control Branch) 기능에 대해 다음 질문에 답하시오.
DFCB가 단노출 가이드 이미지에서 제거하는 정보는 무엇인가?
해당 정보를 제거하고 만 추출하여 사용하는 기술적인 이유는 무엇인가?
