[논문리뷰] DiffLO: Semantic-Aware LiDAR Odometry with Diffusion-Based Refinement, CVPR 2025
논문 리뷰 및 실습
최근 Pose Diffusion 논문을 리뷰했던 적이 있는데, 이 논문을 Pose Diffusion을 사용하여 LiDAR Odometry task에 적용해보겠다는 방법을 제안함. 추가적으로 Semantic Distillation을 도입하여 dynamic, repetitive patterns, low textures에 강인함을 더했다고 함.
Overview
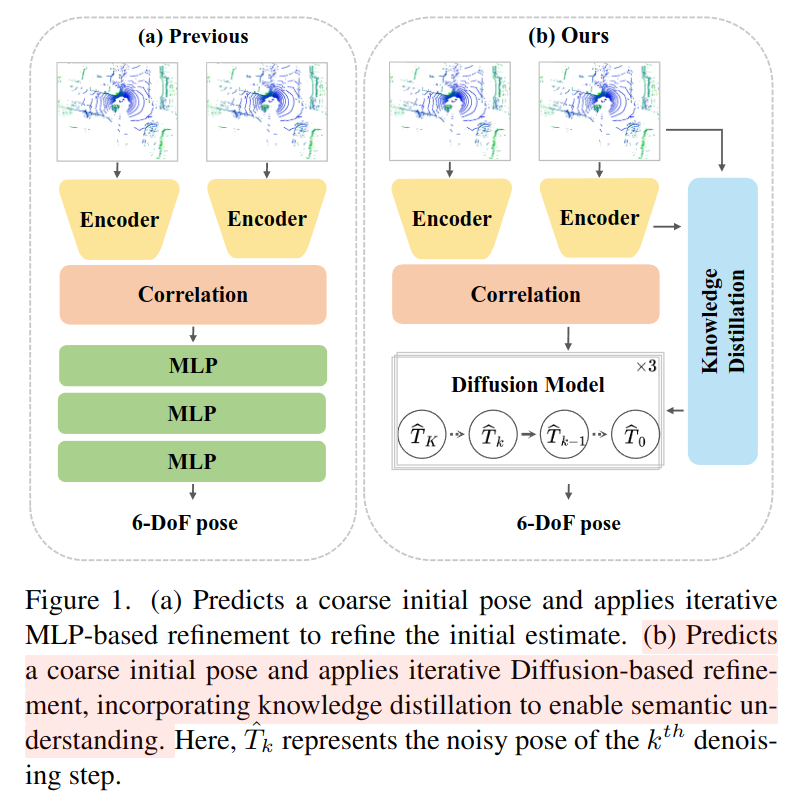
Problem & Solution
기존 딥러닝 기반 odometry task에서는 (1) dynamic objects, occulusion에 취약하며, (2) 학습 환경과 변화나 복잡성에 적응하는 능력이 제한됨을 지적함. 저자들은 (1)을 해결하기 위해 pretrained semantic model의 distillation과, (2) diffusion 모델을 통한 확률적 생성 모델 도입을 통해 다양한 환경에서도 강인하게 개선하고자 함.
본 논문에서 주장하는 contributions는 다음과 같다.
1) Semantic awareness odometry by distillation
2) Novel diffusion-based refinement pipeline, guided by combining semantic embedding, coarse pose embeddings, geometry embedding and cross-frame cost volume을 통한 생성 diversity 제어. (Odometry task에 diffusion을 적용하려는 최초의 시도)
3) 기존 A-LOAM odometry보다 좋은 성능을 보인다고 함.
Details
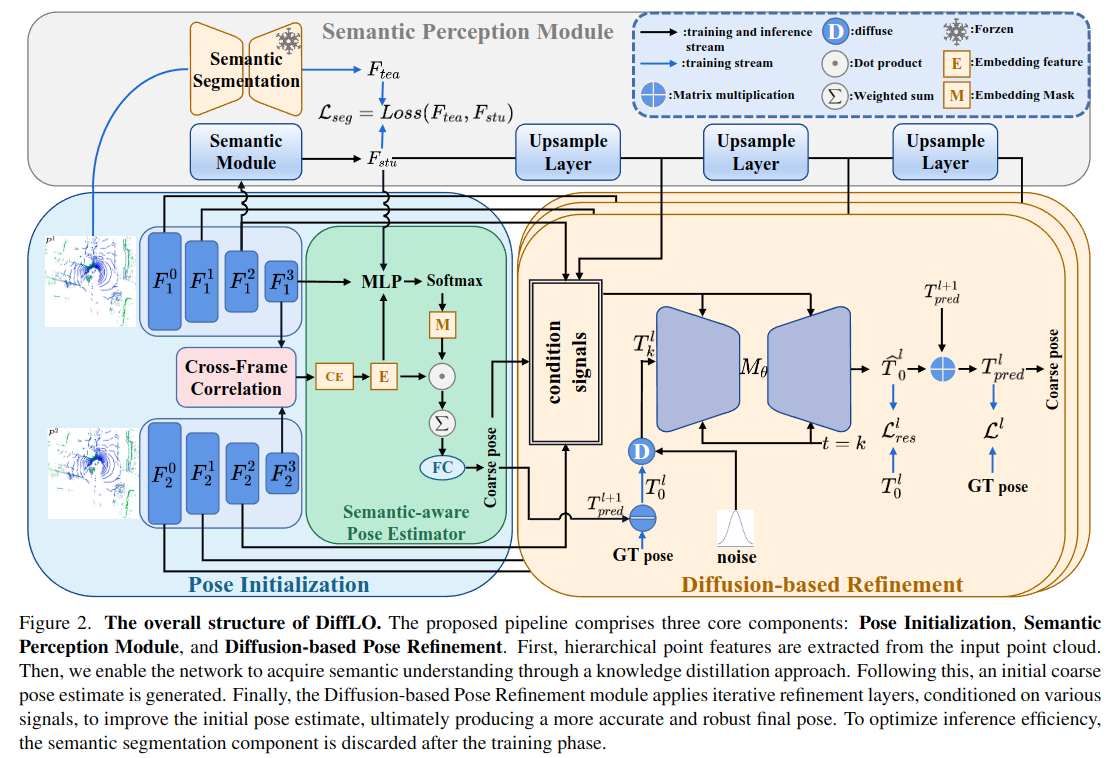
1. Multi-scale feature extraction
PointConv를 기반으로 하여 heirarchical feature extraction을 진행한다고 함. 특정 레이어에서 먼저 furthest point sampling를 통해 sparse point set을 정의하고, 각 subsampled sparse point에 대해 k-nearest neighbor groups을 생성하여 feature extraction을 위한 local region을 정의한다고 함. L-레벨 point feature 피라미드를 생성함.
2. Semantic Perception Module (SPM)
Semantic Perception Module은 다음 세 가지 하위 모듈로 구성.
1. (pretrained) Semantic Segmentation Model: teacher model
- 외부의 사전 학습된 3D semantic segmentation 네트워크 (SphereFormer를 사용)
- 이 모델은 장면의 의미적 구조 정보 (예: 도로, 차량, 건물 등)를 정확하게 포인트 단위로 예측
2. Semantic Module: student model
- segmentation 모델로부터 의미 정보를 전이 학습(knowledge distillation) 받음.

→ 이는 attention-like 연산으로, 중요한 의미 정보에 집중하도록 설계됨.
- 모두 model의 logit (output 직전 값) 기반으로 distillation 진행.

→ 아마 단순히 차이 연산을 통해 loss를 주는 것으로 보임.
| 단계 | 설명 |
|---|---|
| 학습 단계 | - Segmentation 모델로부터 의미 정보를 추출하고, 이를 Odometry 네트워크에 전이 - 이때, 세그멘테이션 모델은 고정(frozen) 상태이며, Semantic Module만 학습 |
| 추론 단계 | - 연산 최적화를 위해 segmentation 모델은 완전히 제거 - 학습된 Semantic Module만을 사용하여 의미 정보를 지속적으로 반영 |
위 모듈을 통해서, 모델은 pose estiamtion을 통해 pose estimation에 이로운 objects에만 집중 가능함.
3. Semantic-Aware Pose Estimator
- Initial pose를 추정하는 핵심 모듈 -> 두 프레임의 포인트 클라우드로부터 상대 포즈 (translation+rotation)을 추정.
- 의미 정보(Semantics), 기하 정보(Geometry), 연관 정보(Cost Volume)를 통합하여 더 정확한 자세 예측
- 추정된 coarse pose는 이후 Diffusion-based Pose Refinement의 입력으로 사용
- Semantic-Aware Pose Estimator는 다음 4가지 정보를 결합하여 coarse pose를 예측
- Feature 결합 및 임베딩 () 생성: 다음과 같이 여러 정보를 결합(concat) 하여 임베딩 벡터
- 임베딩 마스크 () 생성: 마스크는 각 포인트 feature가 자세 예측에 얼마나 중요할지 가중치로 표현 -> semantic feature를 이용하여 가중치 부여!
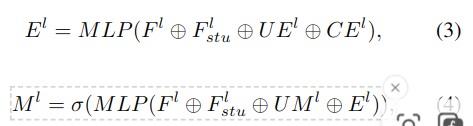
| 구성 요소 | 설명 |
|---|---|
계층 l에서 추출된 point cloud feature | |
| Semantic Module에서 나온 의미 정보 feature | |
| Cross-frame Cost Volume Embedding (feature matching) | |
| , | 상위 레벨에서 업샘플링된 feature/마스크 |
- 최종 자세 (Pose) 예측
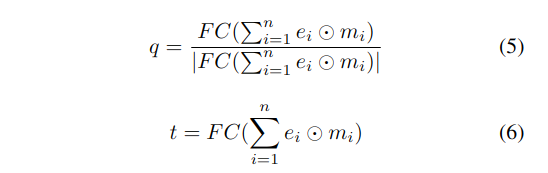
4. Diffusion-based Pose Refinement
coarse pose를 확산 모델의 초기 입력으로 넣고, 조건 신호(geometry, semantic, cost volume 등)을 기반으로 더 정확한 residual pose를 점진적으로 복원하는 방식.
-
학습 동안 diffusion 모델은 손상된 버전의 residual pose로부터 원래의 잔차 자세(GT residual pose)를 복원함으로써, residual pose의 기저 분포(underlying distribution) 를 학습합니다.

-
학습의 각 iteration에서, 임의의 diffusion 단계 를 선택 이후, 사전에 정의된 분산 스케줄에 따라 에 노이즈를 추가하여 noisy residual pose 생성
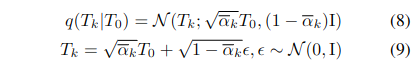
-
추론 단계에서는, denoising 모델이 확산 과정의 역과정을 모사하여 분포 를 근사. 노이즈 ϵ을 예측하는 대신, 신호 그 자체(residual pose)를 직접 예측. 또한, 다양한 조건 정보 C를 이용하여 생성 다양성(generation diversity) 을 통제.
아래의 loss를 기반으로 denoising network를 학습. 학습의 목적은 GT residual pose와 예측된 pose의 translation 및 rotation 차이를 최소화.

- 조건 신호 C의 설계 (Condition Design)
| 구성 요소 | 설명 |
|---|---|
GE | Geometry Feature (PC₁에서 추출) |
CE | Cost Volume Embedding (cross-frame correlation로 생성) |
PE | Pose Embedding: |
F_{stu} | Semantic feature (semantic module에서 나온 것) |
-> 이들을 모두 연결(concatenation)하여 다음과 같이 구성
