[논문리뷰] Density-invariant Features for Distant Point Cloud Registration, ICCV 2023
논문 리뷰 및 실습
Overview
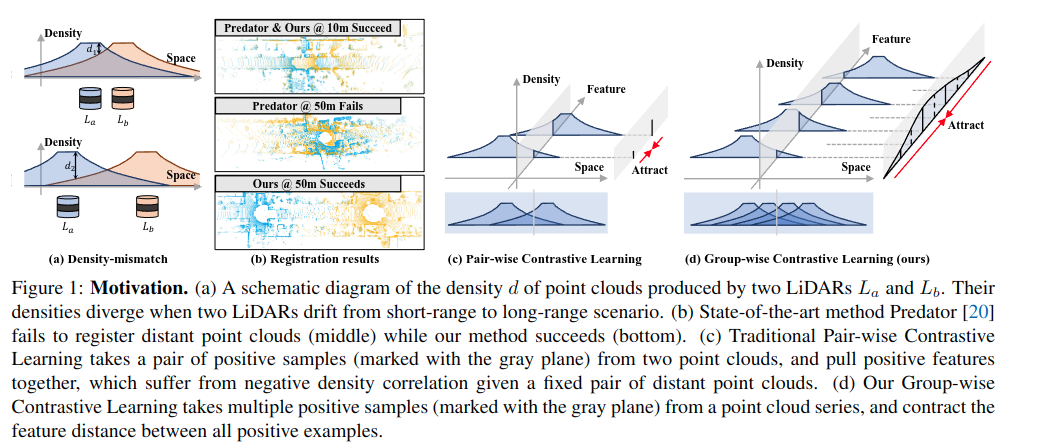
Distant한 LiDAR point cloud registration 문제를 해결하기 위해, Group-wise Contrastive Learning (GCL) 기법을 제안. 기존 방법은 point cloud density 차이로 성능이 저하되었으나, GCL은 positive smapel들을 그룹으로 구성하여 density-invariant feature)를 학습하도록 함.
기존 방법과 뭐가 다르냐? : 기존 PCL (위 그림 (c)) 기반의 constrastive 방식은 positive sample이 한 쌍의 point이지만, GCL (위 그림 (d))은 positive group에 포함된 모든 점에 대해 group-wise학습을 진행. ("같은 위치를 본 여러 점을 다 같이 묶어서 학습")
Problem
- Distant Point Cloud Registration의 어려움: 거리가 멀어질 수록 극도로 낮은 overlap -> 같은 영역에 대해서도 심각한 밀도 불일치가 발생 가능함. 기존 방법들은 이러한 밀도 차이로 인해 성능이 감소
- 기존 Contrastive Learning 기반 정합법의 한계: 기존 방법들은 두점간 pairwise constrastive learning (PCL) 기반으로 두 point cloud내 같은 위치의 점 쌍을 골라서 feature를 가깝게 학습 진행. 하지만 distant point cloud에서는 밀도 차이로 인해 feature가 다름 -> 학습이 불안정
Solution from paper
-
Group-wise Constrastive Learning: 한 쌍이 아닌, 여러 점을 묶어서 학습하는 방법을 제안. 자율주행 데이터에서는 sequential하여 같은 공간 위치의 점들을 모두 모아 positve group 생성이 용이함.
-
Group-wise Loss
1) Positive Variance Loss: 그룹 내 features의 분산을 최소화 -> 모든 밀도에서 유사한 feature 추출 유도.
2) Finest Loss: 그룹 평균 feature가 가장 좋은 feature (가장 높은 밀도에서 얻은 feature)에 가깝도록 학습 진행. 따라서 고밀도 point cloud를 기준으로 feautre를 정렬 진행.
3) Hardest Negative Loss: 다른 그룹과 feature가 겹치지 않로록 최악의 negative와 feature 차이를 벌리기.
4) Positive Group 내 다양한 밀도의 점들이 들어가므로, i.i.d. 근사를 통한 효과적인 feature 학습이 가능.
| 문제 | 해결법 | 핵심 아이디어 |
|---|---|---|
| 멀리 떨어진 점군 정합 어려움 (Low Overlap, Density Mismatch) | Group-wise Contrastive Learning (GCL) | 여러 점군에서 같은 위치의 점들을 Positive Group으로 묶어 학습 |
| 기존 Pair-wise 방법의 i.i.d. 가정 깨짐 (학습 실패) | Group-wise Loss 설계 (Positive Variance Loss, Finest Loss) | 그룹 내 feature 분산 최소화 + 고밀도 feature에 정렬 |
| Feature가 밀도 변화에 민감 | Group-wise 학습으로 다양한 밀도에서 동일한 feature 유도 | 동일 위치의 feature를 강제 수렴시킴 |
Training & Inference 파이프라인
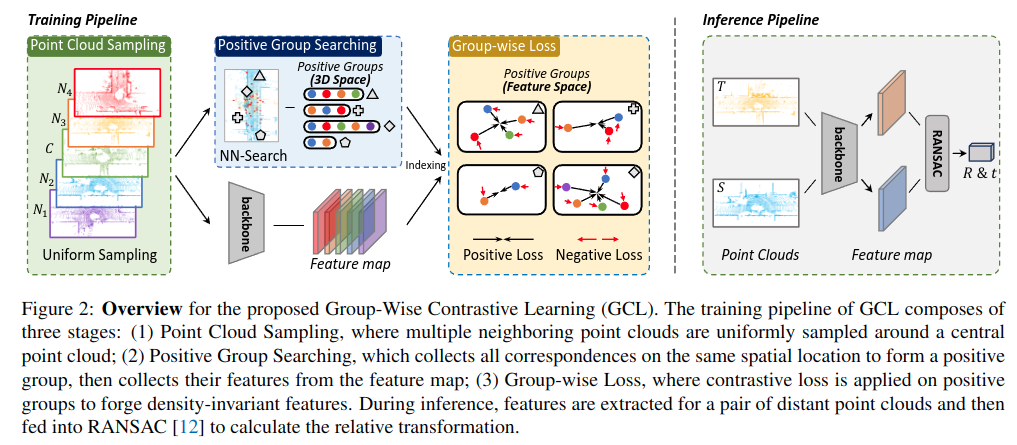
학습 단계
1) Point Cloud Sampling (포인트 클라우드 샘플링): Central point cloud (C)를 중심으로 주변에서 neighbor point cloud를 균등하게 선택
2) Positive Grout searching: 동일한 공간 위치에 대응하는 점들을 찾기 위해 Nearest Neighbor Search를 수행. Central과 주변 point cloud에서 같은 공간 위치에 대한 점들을 Postivie Group으로 묶음. (여기서 찾은 점들은 서로 다른 시점/밀도에서 얻은 동일 공간의 점)
3) Group-wise Loss: Positive Group 내의 모든 점들의 feature를 모아 group-wise Loss를 적용. 이 Loss를 통해 밀도 불변 feature를 학습 가능.
- Positive Variance Loss: 그룹 내 feature 분산 최소화
- Finest Loss: 그룹 평균 feature가 가장 좋은(highest density) feature에 가깝게 유도
- Hardest Negative Loss: 다른 그룹과의 구분을 유지
추론 단계
1) 학습된 feature extractor를 통해 각 점의 feature 추출
2) 추출된 feature들로부터 RANSAC 기반 매칭 수행 -> Rotation 및 Translation 추출
Detailed content
1. 멀리 떨어진 포인트 클라우드 정합에서 기존 Pair-wise Contrastive Learning (PCL) 방식이 실패하는 이유 분석
1) i.i.d. Positive Features 필요성: 학습을 잘 하기 위해서는 Positive Feature(같은 공간 위치의 점들)는 반드시 i.i.d. (독립적이고 동일한 분포)이어야 함. 그래야 모든 밀도/각도 상황에서도 feature가 같은 위치로 수렴 가능. 하지만 기존 PCL은 항상 두 점군만 보고 positive sample을 찾음 → Sampling Bias 발생. 특히 멀리 떨어진 점군에서는 겹치는 영역이 매우 작고, 주로 도로선(Roadside Line) 점들만 대응점으로 선택되는 것을 발견 -> i.i.d 가정이 깨짐
2) Feature Drift 현상: Point cloud의 밀도가 낮아지면 feature 품질이 나빠지고, feature Drift(feature가 변하는 정도)가 커짐. 특히 PCL 방식은 밀도가 낮아질수록 feature가 불안정해지고, 거리와 Feature Drift가 강한 상관관계를 가짐 → 멀리 떨어진 점군에서는 성능 급락.
| 문제점 | 상세 설명 |
|---|---|
| Sampling Bias | 멀리 떨어진 점군은 도로선 중심으로만 점들이 몰림 |
| i.i.d. 위배 | Positive Samples가 강하게 상관 → 학습 실패 |
| Feature Drift 심각 | 밀도 낮을수록 feature 불안정 → 정합 성능 급락 |
| 정합 실패 원인 명확 | 기존 PCL은 근본적으로 멀리 떨어진 점군에 부적합 |
2. Positive Group Searching process
1️⃣ 중앙 포인트 클라우드 선택
중앙 프레임(Central Frame, C)을 기준으로 주변에 균등하게 배치된 여러 점군들(Nk)을 선택. 논문에서는 [-60m, +60m] 영역을 ϕ 개로 나눈 후, 각 cluster마다 uniform하게 1개씩 점군을 선택.
2️⃣ Nearest Neighbor Search (최근접 이웃 탐색)
중앙 프레임 C의 모든 점에 대해 주변 점군들(Nk)에서 가장 가까운 점을 찾음.
동일한 공간 위치를 서로 다른 시점과 밀도로 관찰한 점들을 모음.
3️⃣ Positive Group 형성
이렇게 찾은 점들을 묶어 Positive Group 생성-> 하나의 그룹에는 중앙 프레임 점 + 주변 점군의 대응점들 포함. 한 그룹에는 2개 이상의 점이 포함되며, 이는 고밀도와 저밀도 점들이 혼합된 형태.
4️⃣ 특징
Positive Group들은 충분한 크기로 feature 분포를 근사할 수 있음. i.i.d. 조건에 더 가까워짐 → 밀도 차이 문제 해결 가능. 만약 특정 점이 대응점을 찾지 못하면 해당 점은 학습에서 제외.
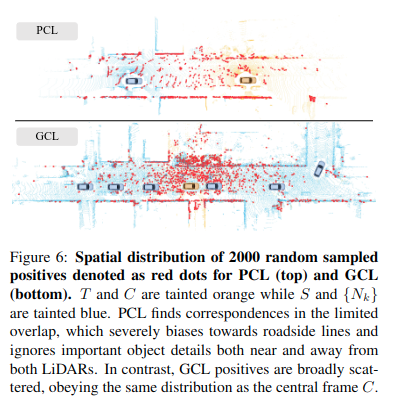 위의 그림을 보았을때, GCL 방식은 기존 PCL보다 훨씬 고르게 점군을 활용. (도로선 편향 제거 → 다양한 구조물까지 학습 가능)
위의 그림을 보았을때, GCL 방식은 기존 PCL보다 훨씬 고르게 점군을 활용. (도로선 편향 제거 → 다양한 구조물까지 학습 가능)
3. Group-wise Loss
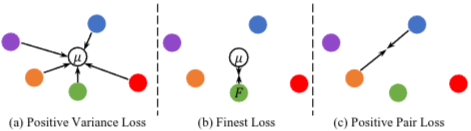
1️⃣ Positive Variance Loss (L_PV)
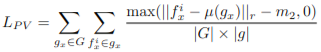 ✨ 목적: Positive Group 내 feature 분산을 최소화
✨ 목적: Positive Group 내 feature 분산을 최소화
→ 그룹 내 점들의 feature들이 서로 가깝게 모이게 함.
✨ 원리:그룹 평균 feature(μ)를 기준으로, 각 점 feature와 평균 feature 간의 차이를 줄이는 방식.
✨ 효과: Positive Group 내 모든 feature들이 안정적이고 일관된 방향으로 수렴 → 강인한 feature 생성.
2️⃣ Finest Loss (L_F)
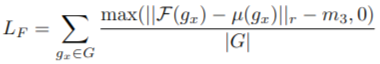
✨ 목적: 그룹 평균 feature가 가장 좋은 feature(밀도가 가장 높은 점의 feature)와 가깝도록 함.
✨ 원리: Positive Group에서 가장 높은 밀도의 점을 Finest Feature로 지정 → 기준점으로 삼음. 그룹 평균 feature가 이 Finest Feature와 비슷해지도록 학습.
✨ 효과: 고밀도 점의 feature가 기준이 되어, 저밀도 점도 안정적으로 feature를 따라가게 됨 → 밀도 불변성 강화.
3️⃣ Hardest Negative Loss (L_HN)
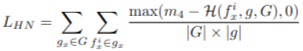
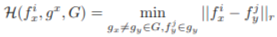
✨ 목적: 서로 다른 Positive Group 간의 feature 혼동 방지 (Negative Sample 구분).
✨ 원리: 그룹 내 각 점의 feature와 가장 가까운 다른 그룹의 점 feature(Negative Sample) 사이의 거리를 벌리는 Loss.
✨ 효과: Positive Group끼리는 가까워지지만, 다른 Group과는 확실히 구분되는 feature 생성 → 정합 성능 향상.
Results
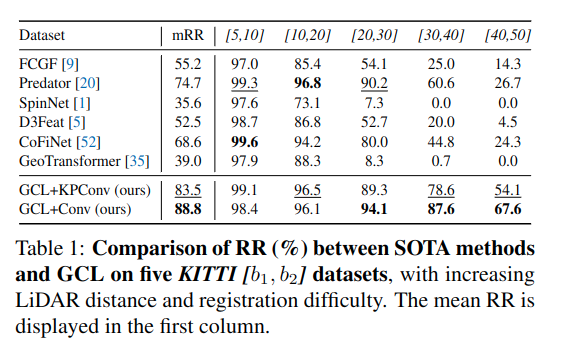
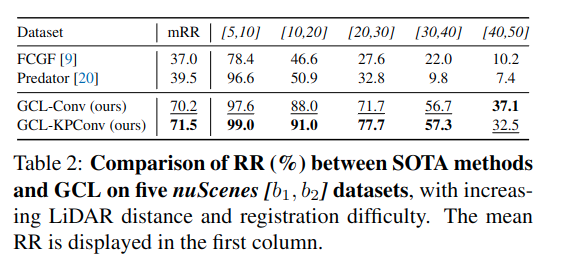
KITTI 및 nuScenes 데이터셋에서 기존 SOTA 대비 먼 거리 정합 시 최대 +40.9% (KITTI) 및 +26.9% (nuScenes) 성능 향상되었다고 함.
< Qualitative results >

< Quantiative results >
Remarkable points
- 이 논문에서 제시하는 density-invariant feature는 Localization 등에 요긴하게 써먹을 수 있을 것 같다.
- Sequential한 LiDAR 스캔 내 동일한 영역에서의 점들을 여러 scan에서 가져와서 사용하는 방식은 내 연구에도 적용해 볼 만 하다.
