[논문 리뷰] Matching 2D Images in 3D: Metric Relative Pose from Metric Correspondences (MICKEY), CVPR 2024
논문 리뷰 및 실습
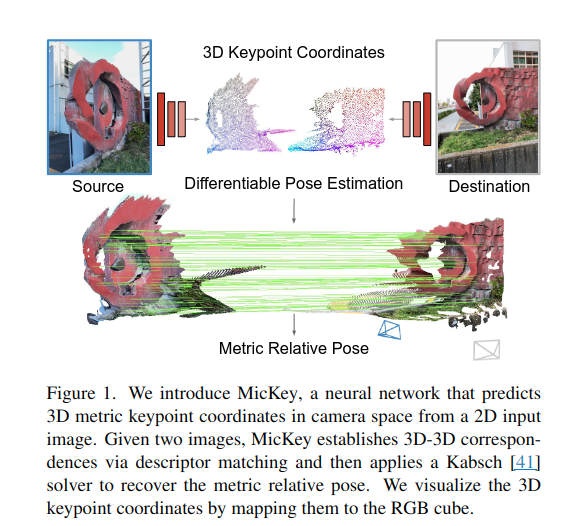
Overview
Mickey: Keypoint matching pipeline인데, 기존과는 다르게 3D keypoint의 metric correspondences를 바로 예측한다고 함. 따라서 외부 depth sensor없이 바로 metric한 relative pose estimation이 가능함. 학습 시 심지어 3D Model 혹은 이미지 중복 정보도 필요하지 않으며, 오로지 image pair와 해당 relative pose만 필요하다고 함.
Problem
보통 Map-free Relocalization setting에 사용되는 방법들은 2가지 문제점이 있음
- Feature detector와 Depth Estimation 모듈을 결합하여 3D로 추정하려 하나, 각각이 독립됭 있음. 예를 들어 feature detector는 코너나 엣지 부분에서 검출하나 이러한 부분은 depth estiamtion 모델이 어려워하는 부분.
- Best metric depth estimator를 학습하기 위해서는 좋은 groud truth depth가 필요하지만, 획득하기 쉽지 않음.
Solution from the paper
- 1) 특징점 위치 회귀 후 descriptor matching: 3차원 공간에서 3차원 특징점을 예측 후, 3D-3D correspondences를 학습
- 2) weak supervision: 미분 가능한 pose optimization을 통해 pose 이외에는 추가적인 정보를 요구하지 않음
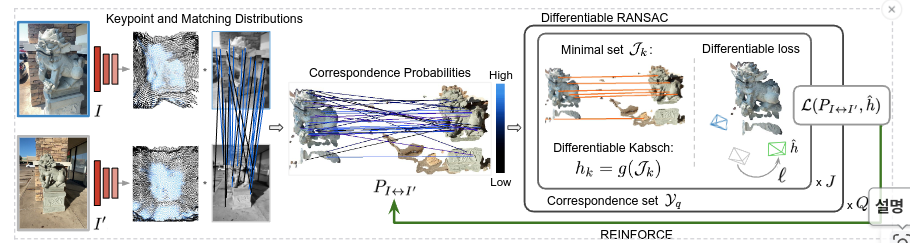
모델 input: Image pair
모델 output: Metirc relative pose, keypoint scores, mathcing 확률, pose confidence (soft-inlier counting)
Probabilistic Correspondence Selection
- Sampling keypoint correspondence 확률 = (keypoint selection 확률) x (descriptor matching 확률)
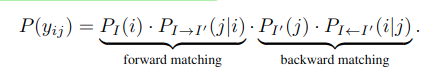
< descriptor mathing 확률 >
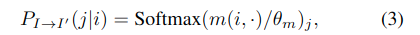
- m은 모든 디스크립터 쌍의 유사도를 저장한 유사도 행렬, theta는 oftmax 온도(hyperparameter)로, 확률 분포의 sharpness를 조정.
< keypoint selection 확률 > ->
네트워크는 각 키포인트의 confidence (신뢰도) 값을 예측 -> 이 신뢰도 값들에 대해 Spatial Softmax (공간 Softmax) 연산을 수행하여 확률로 변환
Differentiable RANSAC
-> Pose error를 keypoints와 descriptors 모두에 backpropagate 하는 것이 목적.
-
Soft Inlier Counting: 일반적인 RANSAC은 Inlier Count를 기준으로 후보를 선택하지만, 이는 미분 불가능함. MicKey에서는 Sigmoid 함수를 활용한 부드러운 인라이어 카운팅을 사용하여 해결.
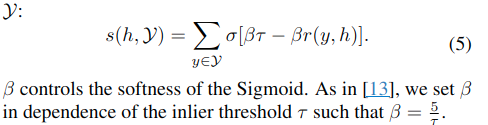
-
Differentiable Refinement: pose 후보 ℎ를 더 정밀하게 개선. 인라이어 집합 𝐼를 재선택하고, 다시 Kabsch Solver를 적용. 마지막 iteration에만 backpropagating을 적용하여 미분 가능하도록 유지
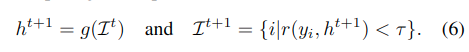
Learning objectives
- Virtual Correspondece Reprojection Error: h(hypotheis)와 (gt inverse)의 곱이 I가 될수록 에러가 작아짐.

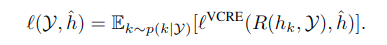
최종 Loss는 다음과 같이 표현한다고 함. 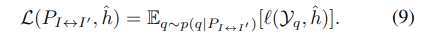
- Gradient 계산 (REINFORCE 기반)
Gradient를 계산할 때는 policy gradient (REINFORCE) 방식으로 다음처럼 구함. 식 (10)은 식 (9)를 weight(w)로 미분한 표현.
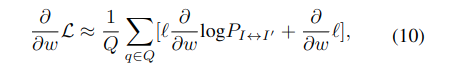 첫 번째 항: 대응점 확률을 조정하기 위한 gradient (키포인트 쌍 매칭을 향상), 두 번째 항: 키포인트 좌표 자체를 직접 최적화하는 gradient (정확한 3D 좌표 예측을 위해 학습). b는 baseline으로, variance를 줄이기 위해 평균 loss를 빼줌.
첫 번째 항: 대응점 확률을 조정하기 위한 gradient (키포인트 쌍 매칭을 향상), 두 번째 항: 키포인트 좌표 자체를 직접 최적화하는 gradient (정확한 3D 좌표 예측을 위해 학습). b는 baseline으로, variance를 줄이기 위해 평균 loss를 빼줌.


Why REINFORCE 방식이 필요?
: 대응점 확률 기반 샘플링이 반드시 필요 -> 샘플링은 미분 불가능 (discrete sampling) -> Policy Gradient만이 이런 상황에서 gradient 제공 가능
- 행동: 대응점 샘플링
- 보상: VCRE Loss (낮을수록 좋음): → REINFORCE를 통해 대응점 확률 분포 를 최적화 가능.
Curriculum learning
처음에는 쉬운 예제부터 학습하고, 훈련이 진행될수록 점점 더 어려운 예제들을 포함시켜 네트워크를 안정적으로 학습을 진행.
✅ MicKey의 Curriculum Learning 과정:
1. 훈련 배치(Batch)에서 여러 이미지 쌍들을 준비합니다.
2. 각 이미지 쌍에 대해 VCRE loss를 계산합니다.
3. loss가 낮은(쉬운) 이미지 쌍들만 선택해서 학습합니다.
4. 학습이 진행될수록 선택하는 이미지 쌍의 수를 점차 늘립니다.
✅추가 안전장치: Null Hypothesis (무효 가설)
가끔은 RANSAC 후보군 전체가 모두 실패하는 경우도 존재. 이 경우를 대비해 Null Hypothesis를 추가:
- 고정된 손실값(최대 허용 VCRE)과 점수를 갖는 가상의 후보.
- 모든 후보가 잘못된 경우에는 이 Null Hypothesis가 선택되도록 하여, 학습이 잘못된 gradient로 흐르는 것을 막습니다.
-> 코드를 보면서 이해하는게 더 좋을 것 같음.
Mickey 구조
Shared Encoder와 multi-head 구조를 사용. 인코더로는 DinoV2를 사용.
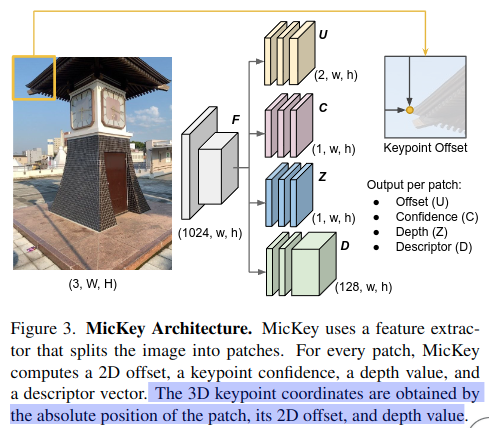
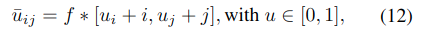
- f는 인코더의 다운샘플링 비율 (MicKey에서는 f=14)
- 는 격자 상의 위치
- u∈[0,1]은 네트워크가 예측한 상대 오프셋
-> MicKey는 조밀한 격자(coarse grid) 상의 오프셋을 예측하여 효율성을 유지하면서도 서브픽셀 정확도(sub-pixel accuracy)의 대응점 추정이 가능.
Results

- Score map은 이미지 내에서 관심 물체(object of interest)가 있는 영역을 강조하며,단순히 모서리(corners)나 에지(edges)에만 반응하지 않음.
- Detector head와 depth head는 훈련 과정에서 함께 조정되므로, detector는 정확한 깊이 추정이 가능한 위치를 활용하도록 학습됨.

- MicKey는 다른 기법들과 달리 단순히 벽(wall)의 저수준 패턴에만 집중하는 것이 아니라 객체의 형태(shape)에 대한 고차원적인(high-level) 추론을 하는 모습을 보이는 점이 인상적.
Few remarkable points
- Curriculum learning 기법은 다른 학습에도 사용 가능할 것으로 기대되어 기억해둘 만 함.
- Joint하게 keypoint detection과 descriptor matching 확률의 곱으로 표현하고, probablistic하게 하여 RANSAC을 적용.
- Policy-gradient 기법: 샘플링(sampling)은 본질적으로 이산적(discrete)인 과정이며, 대응점을 확률적으로 "뽑는" 과정은 불연속적이어서 gradient를 흘릴 수 없음. 즉 에서 대응점 샘플링: Gradient를 직접 전파가 불가능하므로 기존의 backpropagation으로는 학습이 불가함. 따라서 강화학습 기반 방법을 사용하여 정책(probability distribution)을 따르는 행동(샘플링)을 했을 때 결과(보상)에 따라 확률을 조정하는" gradient를 제공하는 기법이 매우 인상적.
< 왜 Mickey가 minimal overlap에 robust할까? >
1) 2D 이미지 패턴에만 의존하지 않음 → 3D 공간 기반 학습: 존의 대부분 매칭 기법은 이미지의 겹치는 부분에서 모서리, 엣지, 질감 패턴 같은 저수준 시각 정보로 대응점 찾음. 반면 MicKey는 아예 3D 카메라 좌표계 상의 metric keypoint를 직접 학습. 따라서 이미지가 많이 겹치지 않아도, 카메라 좌표계 상에서 비슷한 공간 위치의 키포인트를 찾을 수 있
2) 유연한 확률적 학습 + Curriculum Learning → 비정형 상황 학습 가능. MicKey는 훈련 시 minimal overlap 이미지 쌍도 적극적으로 학습. 치지 않는 이미지도 점진적으로 학습하면서 "겹침이 적더라도 맞는 상대 자세를 추정"하는 방법을 배움. 기존 방법들은 overlap이 전제조건이라 학습이 힘듬.
3) Feature의 역할 자체가 다름 → 고수준 공간 reasoning: 기존 기법들은 벽이나 바닥처럼 반복적이고 무의미한 패턴에 쉽게 의존. MicKey는 훈련 과정에서 "이 점이 자세 추정에 얼마나 도움이 되는가?"를 직접 학습. 그래서 단순한 벽 패턴 대신 실제 3D 물체 구조를 고려해 대응점을 설정하는 경향이 강함.
4) 3D Pose Loss 기반 학습 → Pose Recovery 자체 최적화: Keypoint와 Descriptor 모두 "정확한 상대 자세 추정"을 기준으로 학습됨. 따라서 "겹치는 영역을 잘 매칭"이 아니라 "정확한 pose를 잘 추정할 수 있는 keypoint"를 찾도록 직접 최적화. Minimal Overlap에서도 자세가 맞으면 Loss가 작으니, MicKey는 이런 상황을 효과적으로 해결하는 방향으로 학습됨.
