[논문리뷰] 3DMatch: Learning Local Geometric Descriptors from RGB-D Reconstructions, 2017, CVPR
논문 리뷰 및 실습

Local geometric feature들을 매칭하는 것은 noise, low-resolution, 3D 스캔 데이터의 불완전성으로 인해 어려운 task입니다. 본 논문에서는 기존의 geometric한 특성들의 histogram을 기반으로한 SOTA를 뛰어넘는, data-driven 기반의 local volumeric patch descriptor를 학습하는 3DMatch방법을 소개하고 있습니다. 이 방법의 이접으로는 새로운 scenes에 대해서도 local geometry가 잘 매칭되어 reconstruction이 용이하고, 다른 tasks에서도 잘 generalize된다는 점이 있다고 합니다.
1. Introduction
3D geometry matching은 pose estimation, 3D reconstruction, camera localization 등에 많이 사용되곤 합니다. 하지만 저해상도, 노이즈, 부분적인 3차원 데이터셋의 특성으로 인해 geometric 특성을 매칭하는 것은 힘든 일입니다. 기존의 low-level한 hand-craft geometric descriptor가 많이 사용되고 있지만, 실제 3차원 스캔데이터들에 대해 불안정하며 일정하지 않은 성능을 보이며, 새로운 데이터셋에 적용하기 힘들다는 단점이 있습니다. 따라서 이러한 descriptor들은 outlier들을 제거하고 global correspondences를 잘 만들어야하는 노력이 필요하게 됩니다.
이러한 어려움을 해결하고자, 본 논문에서는 data driven의 local geometric descriptor를 학습하는 방법을 neural network 방법을 제안하였습니다. 기본적인 아이디어는 partial한 3D scanning 데이터에 대해서, 3D match라는 3차원 컨벌루션을 이용하여, interest point주변의 local volumeric region을 입력으로 하여 feature descriptor를 계산하게 됩니다. 만약 2개의 descriptor간의 거리가 작을수록 매칭되는 확률이 높아지는 것을 의미합니다.
하지만 data driven 방식의 단점으로는 많은 양의 학습데이터를 요구한다는 점인데, 본 논문에서는 기존의 RGB-D scene reconstruction 데이터셋을 이용하여 학습을 진행하였다고 합니다. 이 데이터들은 표면의 점들과 aligned frame들 간의 labeled correspondences를 나타낼 수 있다고 합니다. 또한 각자 센서 노이즈, 다양한 geometric한 structures, 다시점의 camera 뷰가 있어서, 3D Match가 보다 robust하고 잘 generailze 할 수 있었다고 합니다. 본 논문에서는 62개의 RGB-D scene reconsturction을 사용하였고, RANSAC과 결합 시, 다른 알고리즘들보다 우수한 성능을 보였다고 합니다. 또한 3D Match 방법은 6차원 object pose estimation등에서도 align하는데 사용할 수 있다고 합니다.
2. Related Work
1) Hand-crafted 3D Local Descriptors
: 앞에서 언급된 것처럼, 기존의 hand-craft descriptor들은 노이즈, 저해상도, 부분적인 3차원 데이터로 인해서 성능이 떨어진다는 점이 있습니다. 또한 specific한 applications이나 3D data types에 초점이 맞춰저 있으므로, generalize가 잘 안된다는 문제점도 존재합니다.
2) Learned 2D Local Descriptors
: 2D Image patch들에 대해서 학습시키는 선행 연구들도 많이 있습니다. 특히 multi-view stereo 데이터셋들에 대해서 학습을 진행시켜왔습니다. 하지만 이를 그대로 3차원에 적용하기에는 적합하지 않습니다. 더욱 최신의 연구는 RGB-D reconstuction을 이용하여 2D desriptor를 학습하지만, 본 방법은 3D geometric descriptor를 학습합니다.
3) Learned 3D Global Descriptors
3차원 shape을 학습하는 연구가 활발히 발전하고 있습니다. 3D ShapeNet은 3D shape를 modeling하기 위한 3차원 딥러닝을 제시하였고, 그외의 많은 연구들이 3차원 데이터에서 deep feature를 계산합니다. 연구들의 초점은 global level의 feature들을 추출하는 것을 목적으로 합니다. 반면에 본 논문의 방법은 local level의 특징들을 학습하는 것에 초점을 두고, various pattern이나 viewpoints의 변화가 있는 data를 처리할 때 robustness를 제공합니다.
4) Learned 3D Local Descriptors
Guo et al.은 2D ConvNet descriptor를 이용하여 mesh labeling의 local geometric 특징들은 매칭하는 방법을 제시하였습니다. 다음 방법은 완전한 3D model에서만 유효하며, ConvNet의 입력으로 spatial 연관성이 없는 패치드를 입력으로 하는 반면에, 3D Match방법은 spatial하게 일관된 데이터를 사용합니다.
5) Self-Supervised Deep Learning
SSL 기법을 이용하여, 훈련데이터와 correspondence 라벨을 RGB-D reconstuction에서 추출하였고, 이는 automatic하여 수동적인 labeling이 필요없다는 장점이 있다고 합니다.
3) Learning from Reconstruction
본 논문의 목적으로는 point 주변의 local volumetric region를 descriptor vector로 바꿔주는 함수 ψ를 찾는 것입니다. 두 descriptor간의 l2 거리가 더 작을수록 correspondence의 확률이 높아집니다. ψ는 high quality의 RGB-D reconstruction에서 배울 수 있다고 합니다. Reconsturction을 통해 학습하는 방버븨 장점으로는 크게 3가지가 있다고 합니다.
먼저 RGB-D reconstruction dataset은 여러 시점에서 얻은 무수한 points들이 존재하여, training correspondence를 많이 제공할 수 있다는 점입니다. 한개의 점을 여러 관찰을 통해보면, local한 3D patches은 센서 노이즈, 시점 다양성, occulusion pattern에 의해 다르게 보일 수 있습니다. 이러한 점들은 훈련시에 수많고 다양한 correspondence 훈련 집합을 보여줄 수 있다고 합니다.
다음으로는 이러한 challenging한 registration에서 얻은 powerful한 descriptor는 기존의 domain adatation이 힘들어 보였던 분야에서도 사용이 가능할 수 있다는 점입니다.
마지막으로는 다양한 dataset에서 훈련하게 됨으로써, 실제 3차원 모델에 대해서도 robust하게 local match가 된다는 장점이 있습니다.
3-1) Generating Training Correspondences
3D patch들과 대응되는 correspondence ground truth를 얻기 위해서, 임의로 점들을 선택한 뒤에, 점들 주변의 local 3D patches를 추출하였다고 합니다.
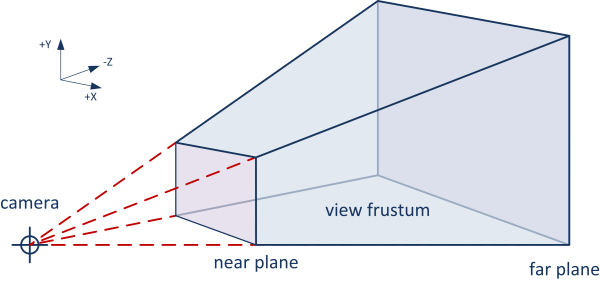
Interest point의 correspondence를 찾기 위해서, 모든 RGB-D 프레임들 속 3차원 점을 매핑하여서, 점이 위의 그림과 같이 같은 camera view frustum속에 있으며, 가려지지 않게 하였다고 합니다. 카메라의 위치들은 최소 1m 이상 떨어지도록 설정되었으며, observation 쌍에 있는 v시점은 충분히 wide-baselined 되도록 되어있습니다.
Interest point 주변 2개의 local patches들을 2개의 RGB-D 프레임들 속에서 각각 뽑아내어 matching pair로 사용한다고 합니다. Non-matching point를 얻기 위해서는 2개의 interest points 주변의 random하게 depth frames에서 선택된 2개의 3D patches를 사용합니다.
4) Learning a Local Geometric Descriptor
3D ConvNet을 사용하여 3D patch에서 512 dimensional feature 표현으로 변환하고 이를 descriptor로 사용한다고 합니다. descriptors간 coorespoding matches에서는 l2거리를 최소화하는 방향으로, non-corresponding한 점들의 descriptor는 l2거리를 최대화하는 방향으로 최적화합니다.
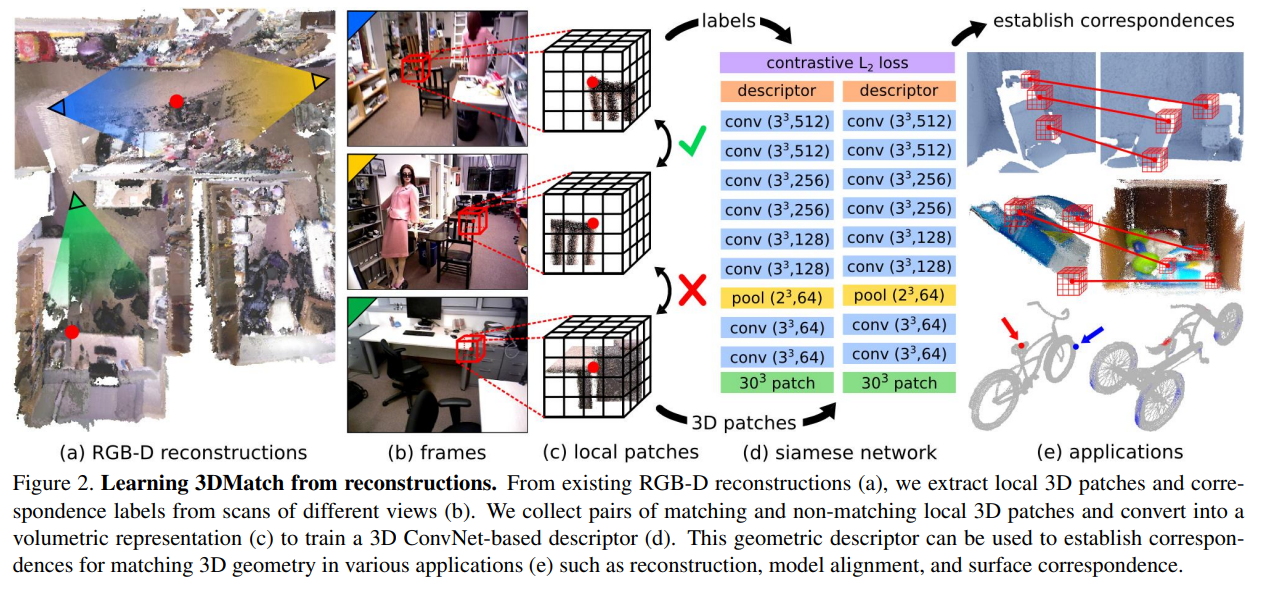
4-1) 3D Data Representation
각각의 interest 점에서, 먼저 3D volumetric 표현을 추출하는 과정을 거칩니다. 각각의 3D region은 원래의 표현(mesh, point-cloud, depth map)에서 volumetirc하게 표현됩니다.(30x30x30 voxel grid of Truncated Distance Function) 2D pixel image patches와 동일하게, 우리는 TDF voxels을 local 3D patches로 사용합니다. (voxel 1개의 크기가 0.01 세제곱 미터-> voxel grid는 0.3 세제곱미터 부피) Voxel grid는 카메라 view에 align 되어 있습니다. 각 voxel의 TDF값은 voxel의 중심과 가까운 3차원 surface간의 거리를 의미합니다. 이 TDF값은 truncate, normalize 되어 0(표면과 far)에서 1(표면 위에 존재) 사이로 표현되었다고 합니다.
4-2) Network Architecture
3DMatch는 표본적인 3D ConvNet으로, AlexNet에 의해 영감을 받았다구 합니다. Interest point 주변의 30x30x30 TDF voxel grid를 입력으로 하여, 8개의 conv layer를 거친 이후에, 1개의 pooling layer를 통과하여 512차원의 feature representation을 얻게 됩니다.
4-3) Network Training
Training의 목표는 같은 point에 대응되는 local descriptors을 같게, 그 외에는 다르게 하는 것입니다. ConvNet은 2개의 streams로 학습되며, 각각의 stream은 독립적으로 descriptor를 생성합니다. 2 streams은 모두 같은 아키텍쳐와 weights을 공유하며, l2 distance를 이용합니다. 훈련 중에는 match와 non-match pair 비율을 1:1 비율로 사용한다 합니다.
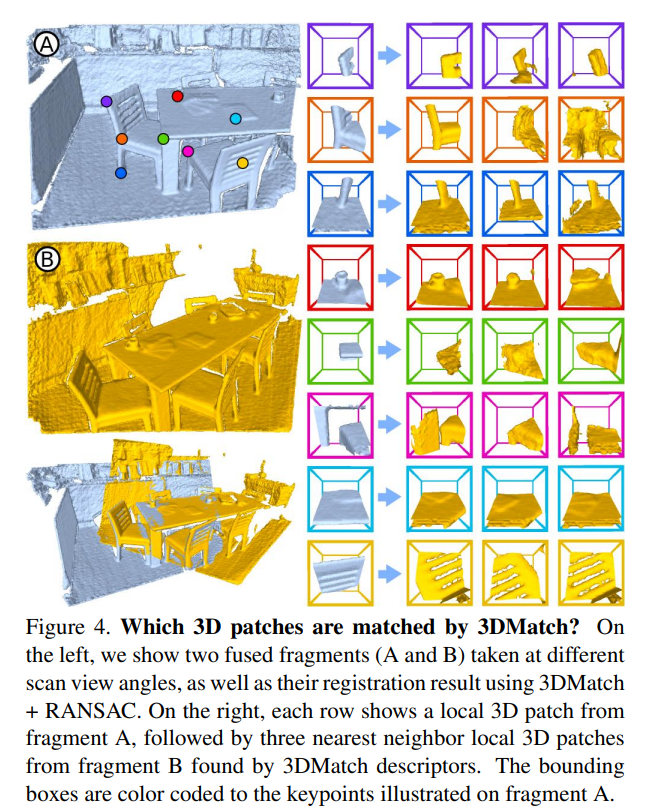
위의 그림은 ConvNet을 이용하여 local 3D patches을 local context와 geometric structure를 기반으로 하여 cluster하는 것을 보여준다고 합니다.
5. Evaluation
5.1 Keypoint Matching
Matching과 Non-matching local 3D patches of keypoint를 구별하는 능력을 먼저 측정한다고 합니다. 평가 지표로는 false-positive rate(error)를 사용하며 낮을수록 좋다고 합니다.

위의 결과와 같이 3DMatch의 성능이 뛰어나다고 합니다.
또한 2D depth patches를 사용하는 대신에 3D volume을 사용하는 것이 실제 세계의 scale과 가려진 지역을 표현하는데 유리하고, 이것은 2D patch에서는 바로 encoding할 수 없는 부분이라 설명하고 있습니다.
5.2 Geometric Registration
Geometric registration은 3DMAtch에 RANSAC을 섞은 것을 사용하였고, n개의 keypoints를 각각의 point cloud로부터 얻어내여 2n개의 keypoint descriptor를 계산하고, 유클리디안 거리가 가장 가까운 descriptor들을 찾고, RANSAC을 이용하여 3차원위치의 transformation 을 구하는 과정으로 진행된다 합니다.
5.2.1 Matching Local Geometry in Scenes
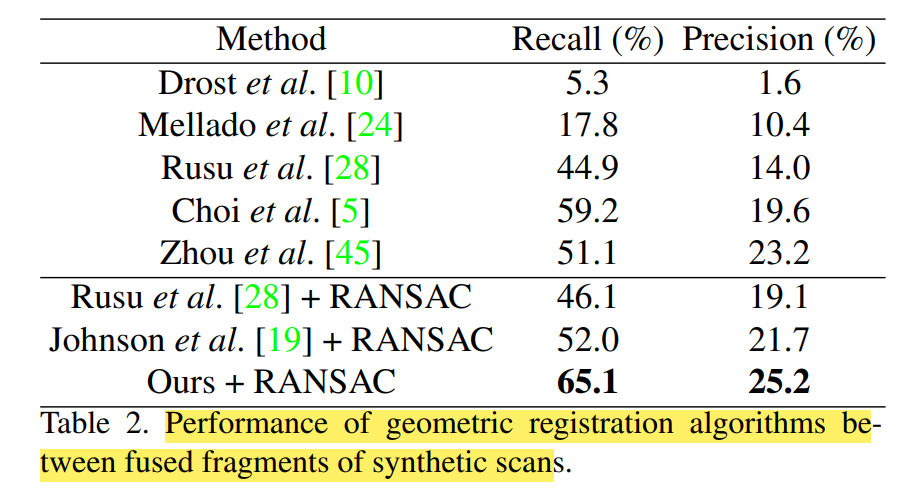
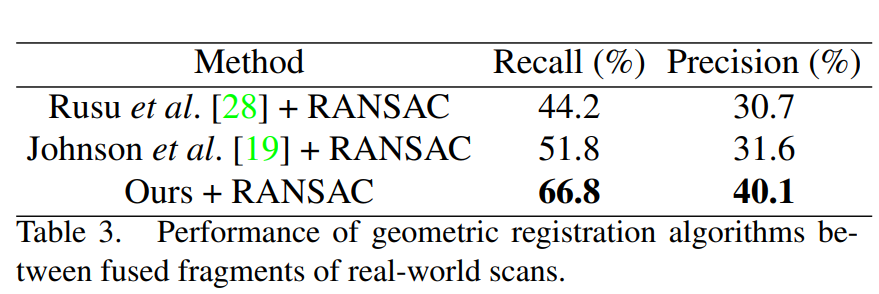
2가지 측면에 초점을 두어, recall and precision을 metric으로 사용하였다고 합니다. 먼저 얼마나 loop closure을 잘 감지하는지와 얼마나 rigidi transfromation matrix를 잘 찾는에 초점을 두었다고 합니다.
5.2.2 Integrate 3DMatch in Reconstruction Pipeline
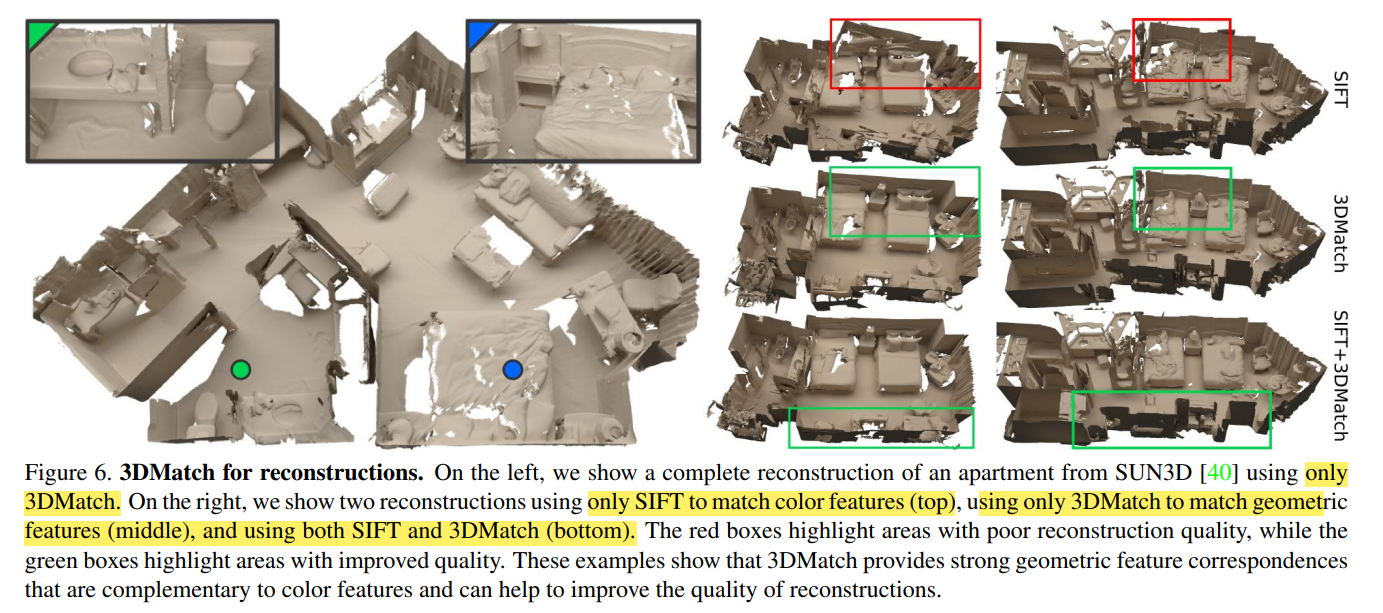
RGB-D에서 Color 정보와 Depth정보의 상호 보완적인 면을 이용하여 matching이 보다 잘 될수 있도록 할 수 있다고 합니다. 예를 들어 sparse한 RGB 특징들은 correspondences를 제공할 수 있으며 이는 geometric 정보가 부족시에 많은 도움이 됩니다. 반면에 geometric signal들도 drastic viewpoint나 조명 변화시 RGB fail에 도움이 됩니다. SIFT(color)와 3DMatch(geometry)를 동시에 사용한 경우 아래처럼 보다 잘 align되는 것을 확인할 수 있습니다.
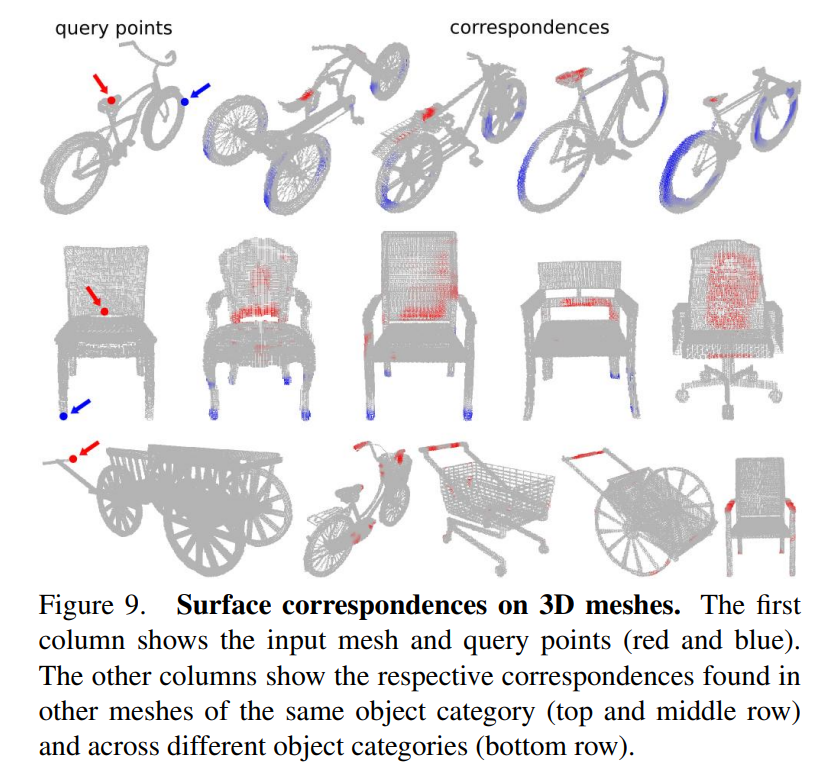
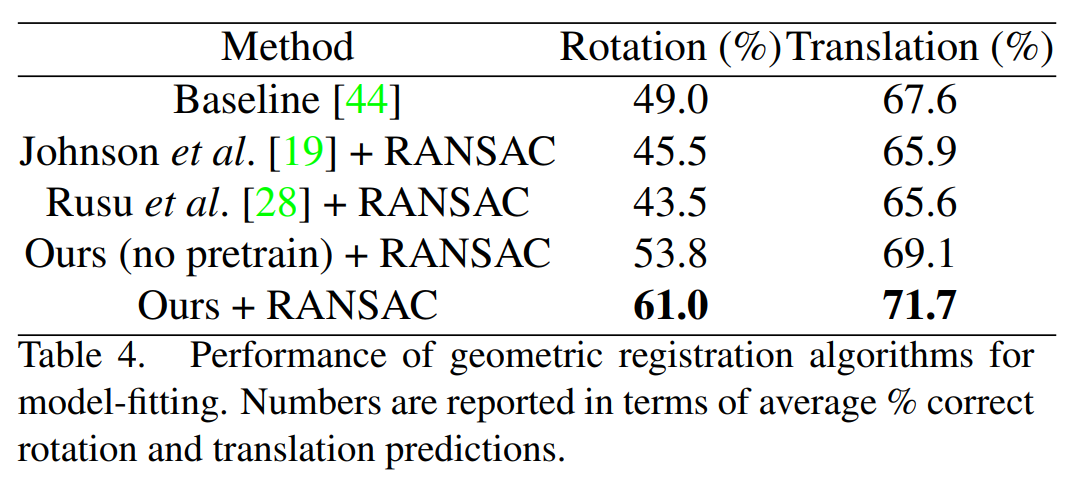
5.3 Can 3D Match generalize to new domains?
논문서는 6D object pose estimation by model alignment에 3DMatch가 사용되는 점을 언급하고 있습니다. 또한 3D meshes에서 surface correspondence를 찾는데에도 3DMatch가 잘 일반화되어 사용가능하다고 하고 있습니다.