[논문 리뷰] StarGAN : Unified Generative Adversarial Networks for Multi-Domain Image-to-Image Translation
논문 리뷰 및 실습
- paper : StarGAN: Unified Generative Adversarial Networks for Multi-Domain Image-to-Image Translation
My Summary
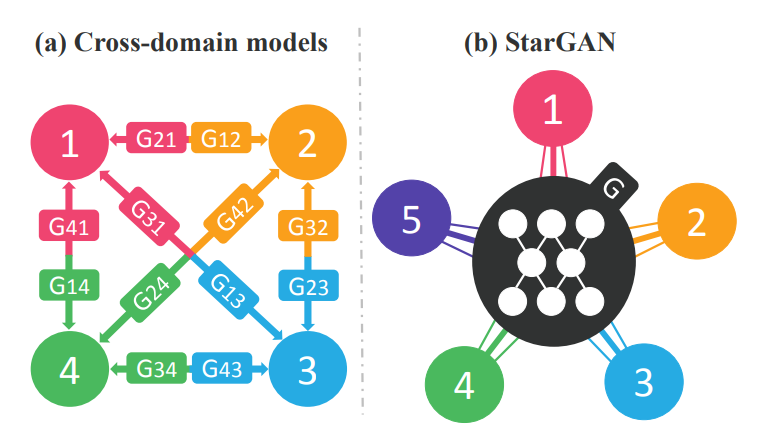
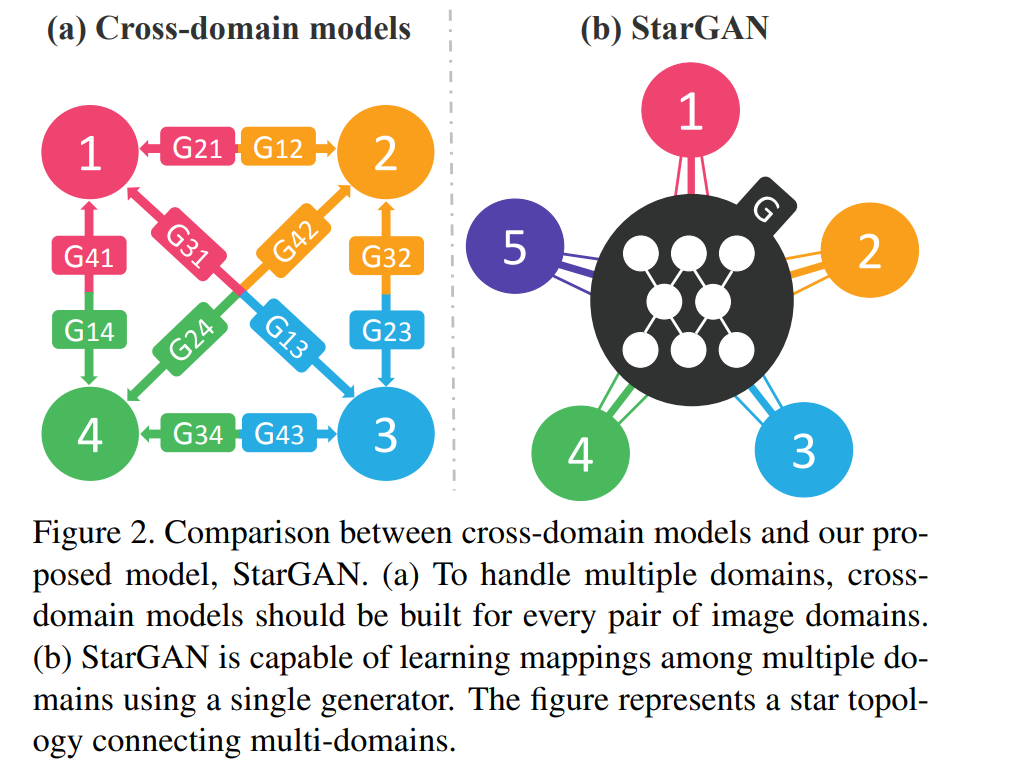
기존의 cycleGAN과 같은 Image-to-Image translation 모델의 단점으로는 fixed된 domain간의 translation이 가능하므로 최대 2개의 domain간 가능하다는 점입니다. 여러 domain에 대해서는 위의 그림처럼 여러개의 Generator가 필요하게 되는데, StarGAN은 하나의 생성모델을 이용하여 multi domain translation이 가능하게 만들었다는 것입니다. 이것이 StarGAN의 가장 큰 의의라고 생각합니다.
Abstract
최근에 많은 Image-to-Image translation model(ex. CycleGAN)들이 성공을 거두고 있지만, 2개 이상의 도메인에 대해서 scalability와 robustness에 한계를 가진다고 합니다. 이는 각각의 이미지 도메인 쌍에 대해서 다른 모델들이 만들어 져야하기 때문입니다. 본 논문은 이러한 한계를 넘고자, StarGAN이라는 single model기반의 다중 도메인 translation이 가능한 모델을 소개합니다. 단일화된 StarGAN모델의 아키텍쳐는 동시에 여러 도메인의 데이터셋들을 동시에 학습이 가능하게 한다고 합니다. 이것은 flexibility을 제공하여 StarGAN의 우수성을 보여준다고 합니다.
Introduction
Image-to-Image translation의 역할은 주어진 이미지를 다른 특성으로 변환하는 것이라고 합니다. GANs을 이용한 접근 방법들이 많이 연구가 되었고, 모델은 주어진 다른2개의 도메인 훈련 데이터를 이용해, 하나의 도메인에서 다른 도메인으로의 변환을 학습하게 됩니다. 여기서 domain이란, 같은 특성을 공유하는 이미지들을 말합니다.(ex 머리색, 성별 등..)
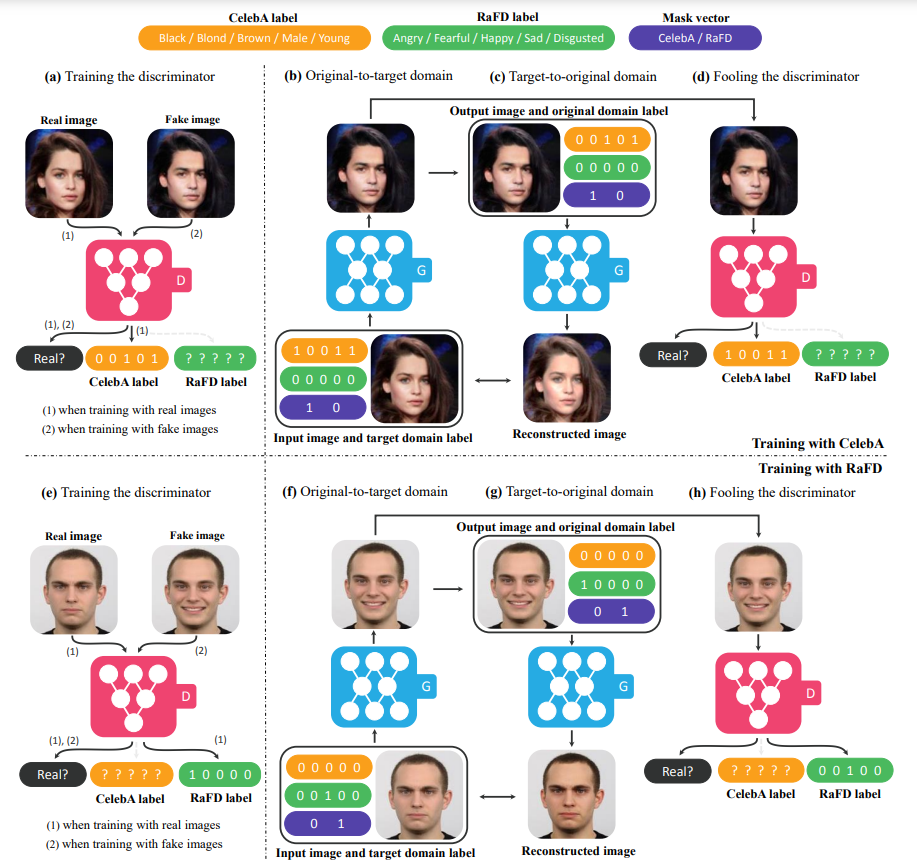
이미지 데이터셋들은 수많은 labeled된 특성들을 가지고 있습니다. CelebA의 경우에는 40개의 특성에 대한 label이, RaFD는 얼굴 표정에 대한 8개의 label을 가지고 있습니다. 이러한 여러개의 특성에 대한 multi-domain translation이 가능합니다. 아래의 그림은 RaFD에서의 표정 특징을 배운 generator가 CelebA 데이터셋에 대해서 domain translation을 진행하는 것입니다. 
현존하는 모델들의 문제로써는 k개의 domain mapping을 학습하기 위해서는 k(k-1)개의 generator가 훈련되어야 한다는 점입니다. StarGAN은 이와 달리 하나의 generator를 사용하여 multiple domains간의 mapping을 배우게 합니다. 그러기 위해서 StarGAN의 inputs은 이미지와 domain information로 하여서 flexible하게 translation이 일어나게 합니다. 저자들은 one-hot vector를 이용하여 domain information을 표현하였다고 합니다. 훈련 과정 시, domain label을 random하게 생성하여 줌으로써 유연하게 domain간의 translate이 가능하도록 모델을 학습하게 됩니다. Testing 과정동안, 도메인 라벨을 통해 원하는 도메인 변환을 가능토록 하게 됩니다.
또한 제안된 방법은 모델이 unknown label에 대해서는 무시할 수 있는 것이 보장되며, 데이터셋마다 특정한 라벨만 학습할 수 있게 됩니다. 저자들은 이를 이용하여 RaFD에서 배운 표정 변환을 CelebA에서 구현할 수 있었다고 합니다.
Contribution
- StarGAN이라는, 하나의 generator, discriminator를 사용하는 multi domains간의 mapping을 만드는 모델을 제안합니다
- 여러 데이터셋 간의 Multi-domain image translation은 mask vector를 이용하여서 모든 라벨을 control할 수 있다고 합니다
- StarGAN을 이용하여 다른 기저 모델보다의 우수성을 보여주었다고 합니다.
Related Works
본 논문의 관련 연구로는 Generative Adversarial Networks, Conditional GANs, Image-to-Image translation을 소개하고 있습니다. 특히 CycleGAN이나 DiscoGAN도 언급하고 있는데, single model이 fixed된 translation mapping만 가능하다는 점을 한계로 들고 있습니다.
Star Generative Adversarial Networks
Multi-Domain Image-to-Image Translation
저자들은 단일 모델을 이용하여 multiple domains간의 mapping을 학습하는 것을 목표로 하고 있습니다. 즉, 입력 이미지 x와 조건 c를 가지고 출력 이미지 y를 생성하는 mapping G(x,c)->y를 학습하는 것입니다. 본 논문에서는 target domain label c(condition)을 random하게 생성하여 줌으로써 flexible하게 학습되도록 합니다. 또한 보조 classifier를 넣어서 하나의 discriminator가 여러 도메인을 control 할 수 있게 하였습니다. 즉, Discriminator는 real/fake에 대한 확률값과 domain classify 결과에 대한 확률값을 생산합니다. 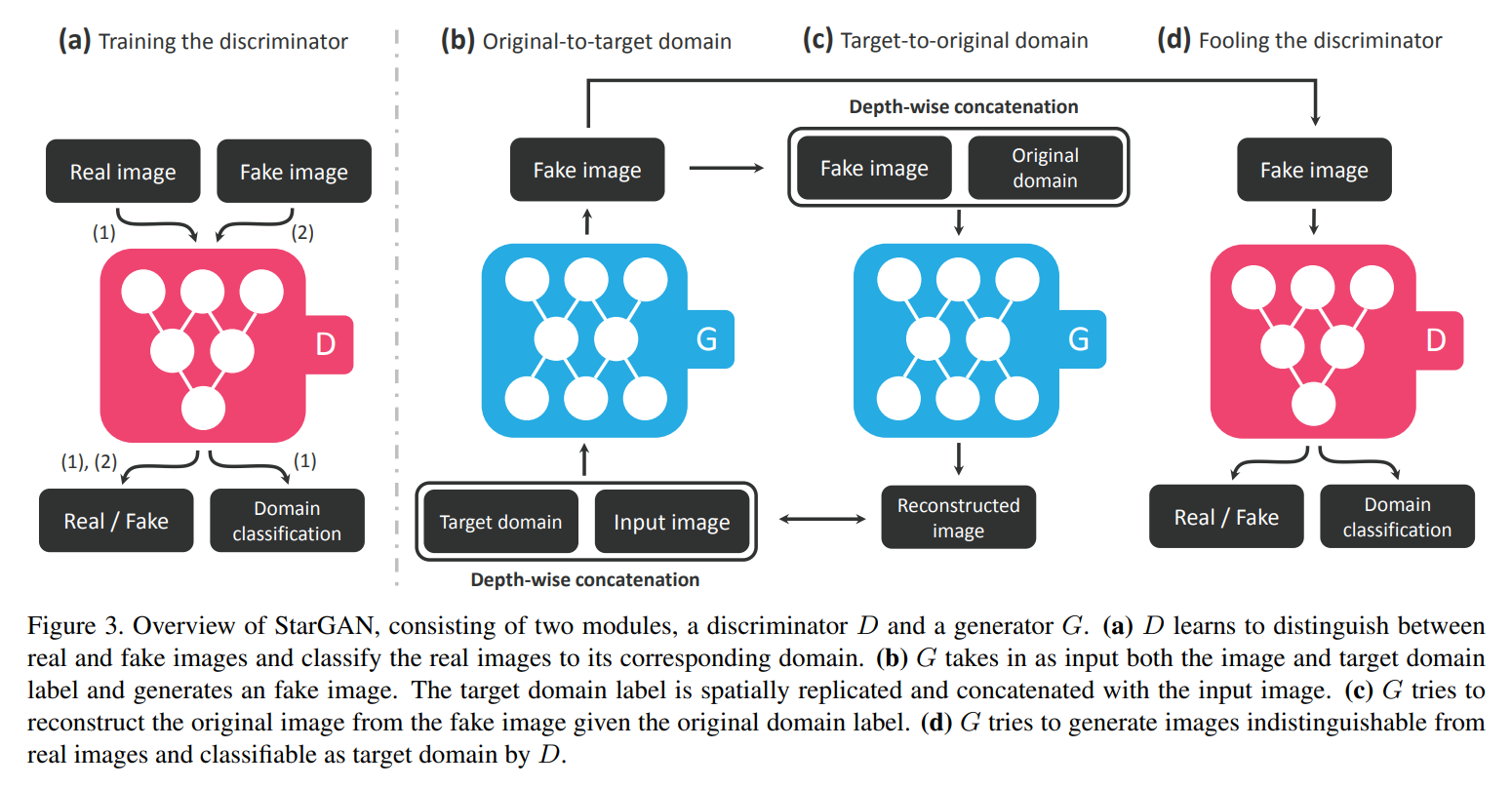
-
Adversarial Loss
Generator가 실제 이미지와 비슷한 이미지들을 만들게 하기 위해서, Adversarial loss를 사용하게 됩니다.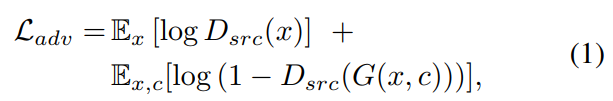
-
Domain Classification Loss
Discriminator에 auxilary classifier를 추가하고 condition에 대한 domain classification loss를 주어서 D와 G를 최적화에 사용합니다. 필자는 loss를 크게 D를 최적화하기 위한 real images에 대한 domain classification loss와 G를 최적화하기 위한 fake images에 대한 domain classification loss로 분류합니다. 즉 전자는 식2와 같이 후자는 식3으로 표현할 수 있다고 합니다.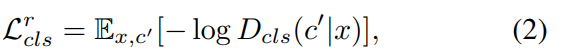
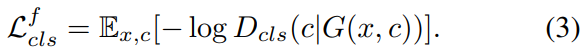
식 2의 loss함수를 최소화 함으로써, D는 실제 이미지 x를 해당되는 original domain c'로 분류하는 것을 학습하게 됩니다. 식 3의 loss함수를 최소화함으로써, G는 target domain c로 분류하도록 이미지를 생성하게 됩니다.
- Reconstruction Loss
Cycle-GAN과 마찬가지로 StarGAN도 cycle loss를 도입하여서, 변환된 이미지가 input images의 내용이 잘 유지될 수 있도록 합니다. 또한 L1 norm을 reconstruction loss로 사용하였다고 합니다.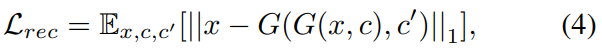
Full Objective
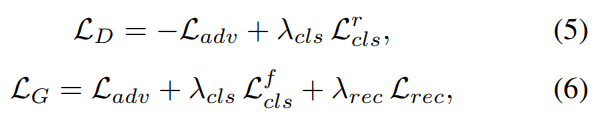 D와 G의 Loss함수 최종식은 위와 같다고 합니다.
D와 G의 Loss함수 최종식은 위와 같다고 합니다.
Training with Multiple Datasets
본 논문에서는, multiple dataset을 학습할 때, label information이 각각의 데이터셋에 대해 부분적으로만 알려지는 문제가 있다고 합니다. CelebA와 RaFD를 살펴보면, 전자는 머리색, 성별 등의 label을 담고 있지만 얼굴 표정에 대한 label은 존재하지 않습니다. 이것은 하나의 모델로 이미지 reconstruction시, 모든 라벨에 대한 정보가 필요하기 때문에 문제가 된다고 합니다
본 논문은 위의 문제에 대한 해결책으로 Mask Vector를 제시합니다. 이를 통해 StarGAN은 명시되지 않은 label을 무시하고, 데이터셋마다 주어진 라벨에 집중이 가능토록 합니다. Mask vector는 one-hot vector로 n개의 dataset에 대해 통일된 라벨벡터를 아래와 같이 제시합니다. 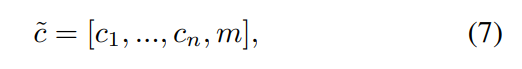 라벨에 대한 정보는 binary하게 표현가능하며, 알려지지 않은 라베들에 대해서는 모두 0으로 값을 주었다고 합니다.
라벨에 대한 정보는 binary하게 표현가능하며, 알려지지 않은 라베들에 대해서는 모두 0으로 값을 주었다고 합니다.
Implementation
Adversarial loss의 학습안정화를 위해서 필자는 아래와 같이 WGAN의 목적함수로 대체하여 사용하였다고 합니다. 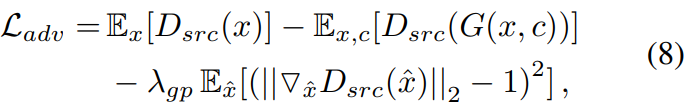 또한 Instance Normalization을 사용하였고, PatchGAN 방법을 discriminator에 사용하였다고 합니다.
또한 Instance Normalization을 사용하였고, PatchGAN 방법을 discriminator에 사용하였다고 합니다.
Results
본 논문은 CelebA와 RaFD 데이터셋에 대해 StarGAN을 실험하였다고 합니다.


또한 평가지표로는 먼저 AMT perceptual evaluation을 사용하였다고 하고 결과는 아래와 같이 다른 모델보다 좋다고 합니다. 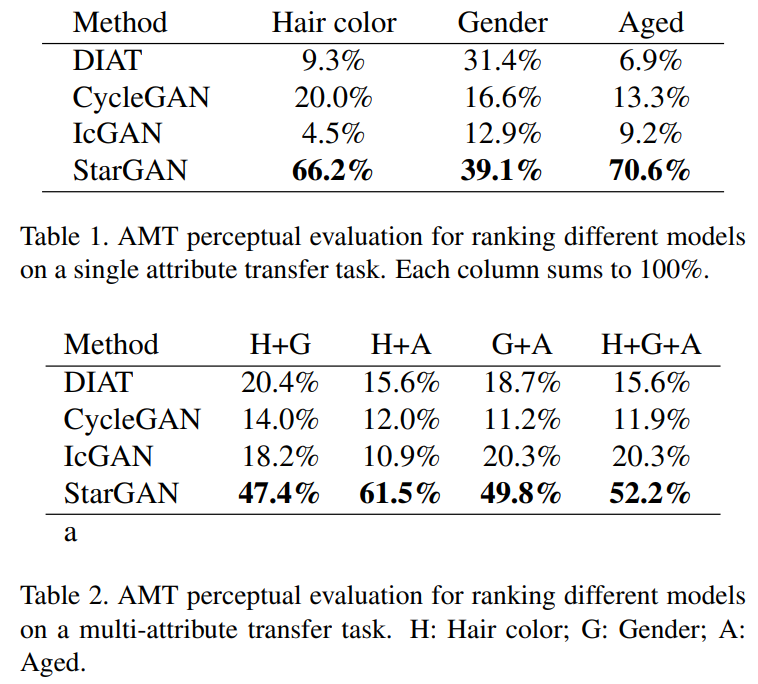 또한 ResNet18 아키텍쳐 기반의 facial expression classifier를 학습시켜 모델들이 생성한 이미지들을 분류해 보았을 때, StarGAN의 성능이 좋았다는 것을 제시하고 있습니다. Multi-domain translation에 필요한 parameter수도 StarGAN이 적다고 합니다.
또한 ResNet18 아키텍쳐 기반의 facial expression classifier를 학습시켜 모델들이 생성한 이미지들을 분류해 보았을 때, StarGAN의 성능이 좋았다는 것을 제시하고 있습니다. Multi-domain translation에 필요한 parameter수도 StarGAN이 적다고 합니다. 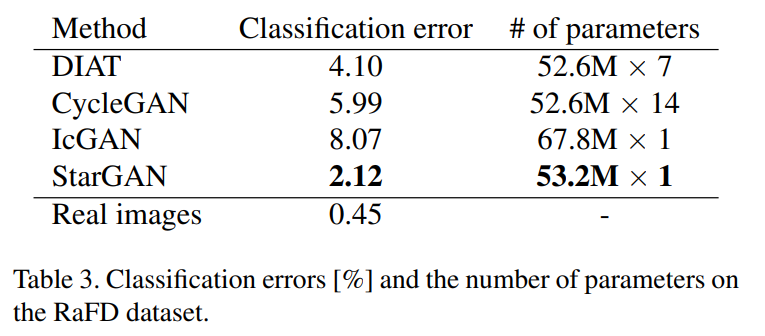 RaFD 데이터셋으로만 학습시킨 StarGAN-SNG와 CelebA까지 같이 학습시킨 StarGAN-JNT의 결과도 제시하고 있는데, joint training의 결과가 더 좋았다고 합니다.
RaFD 데이터셋으로만 학습시킨 StarGAN-SNG와 CelebA까지 같이 학습시킨 StarGAN-JNT의 결과도 제시하고 있는데, joint training의 결과가 더 좋았다고 합니다. 
Reference
- FastCampus, The Red, 주재걸교수님-GAN 강의 中
