[논문리뷰] Universal adversarial perturbations for CNN classifiers in EEG-based BCIs, IOP(Journal of neural engineering), 2021
논문 리뷰 및 실습
- 「 Universal adversarial perturbations for CNN classifiers in EEG-based BCIs」 ,
IOP - Journal of Neural Engineering, 2021 - Zihan Liu, Lubin Meng, Xiao Zhang, Weili Fang and Dongrui Wu
Abstract
최근 EEG 기반의 BCI interfaces(BCIs)에서 CNN classifier들이 많이 사용되고 있습니다. 그러나 이러한 CNN model들은 universal adversarial perturbations(UAP)에 매우 취약한 것이 발견되었습니다. UAP는 small, example-independent(샘플과 무관) 하면서도, CNN의 성능을 매우 약화시킵니다. 이 논문서는 Total Loss Minimization(TLM)이라는 방법을 이용하여, EEG-based BCI의 UAPs를 생성하는 방법을 소개한다고 합니다. 이 방법을 검증하기 위한 실험을 진행하였고, 3개의 유명한 CNN classifier에 대해 target, non-target attack을 진행하였다고 합니다. 이 논문이 또한 EEG-BCIs 분야에 대한 UAP를 처음으로 연구한 논문이라 주장하고 있습니다. UAP는 만들기 쉽고, real-time attack이 가능하며, BCIs의 보안 영역에 큰 Issue가 될 것이라고 말하고 있습니다
1. Introduction
BCIs는 사람의 뇌파를 이용하여 직접 computer와 interact하는 분야입니다. EEG(Electroencephalography)는 이 분야에서 가장 많이 사용되는 Input signal입니다. EEG-based BCIs에는 다양한 패러다임이 존재합니다. P330 evoked potentials, motor imagery(MI, 움직임을 상상), SSVEP(steady-state visual evoked potential, 시각적인 자극) 등이 있습니다.
Deep learning은 이러한 EEG 신호 decoding에 있어서, manual하게 feature processing 하는 과정을 제거한다는 장점이 있습니다. 많은 EEG-based CNN classifier들이 제시되었는데, 이 논문에서는, Lawhern et al이 제시한 EEGNet과, Schirrmeister이 제시한 deep CNN model(DeepCNN), shallow CNN model(ShallowCNN)에 주목하고 있습니다. 이 논문에서는 raw signal을 사용하여 classification을 하는 것에 focus하고 있으며, 다른 input form에도 확장 적용할 수 있다고 합니다.
Adversarial attack은 이미 이미지 분류, 음성 인식 등에서 많은 성공 사례가 있었으며, non-target과 target attacks으로 분류할 수 있다고 합니다.
Non-target attack은 adversairal example에 대한 model의 output이 특정 class로 분류되지 않고, wrong class로 분류하는 것을 목표로 한다고 할 수 있습니다. 대표적으로 DeepFool과 UAP가 있습니다.
반면에, Target-attack은 model의 output이 target하는 특정한 class로 분류되어, 오분류를 일으키는 것을 목표로 합니다. 대표적으로 iterative least-likely class method, adversarial transformation networks, projectd gradient descent(PGD)가 있다고 합니다.
또한, target, non-target에 모두 적용될 수 있는 방법도 있다고 합니다. FGSM, C&W method, L-BFGS, basic-iteratvie method 등이 있습니다.
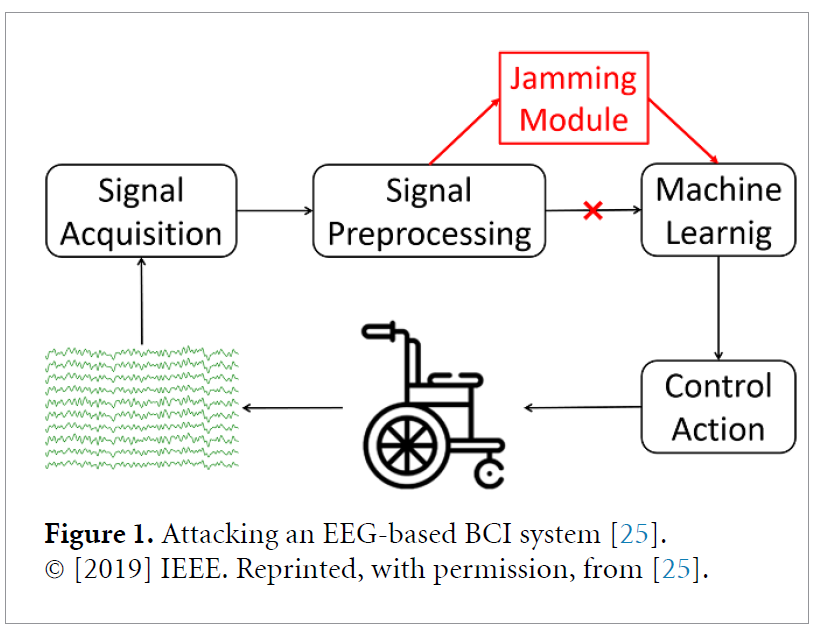
EEG-BCI system은 위의 그림과 같이 4가지 단계로 구성되어 있습니다.
- Signal Acquisition
- Signal preprocessing
- Machine learning
- Control action
Zhang et al은 처음으로 EEG-based BCI의 취약성을 탐구하였다는데요, 위의 그림처럼 singal preprocessing과 machine learning사이 단계에서, jamming module을 삽입하여 perturbation을 주었다고 합니다. EEGNet, DeepCNN, ShallowCNN 3가지 모델을 사용하였고, white-box, gray-box, black-box attack을 하여서, 보안 이슈에 관한 제기를 하였다고 합니다.
하지만 위의 논문에서의 방법은 다음과 같은 limitations이 있었다고 이 논문은 말하고 있습니다.
- Each input EEG trial마다 adversarial perturbation을 계산해주어야 한다는 점
- Adversarial perturbation을 계산하기 위해서는 complete EEG trial이 collect되어야 하는데, 이 시간동안 EEG 신호는 지나가서, 후에 계산된 perturbation을 더할 수 없다는 문제
이 논문서는 offline으로 real-time으로 perturbations을 더하는 것이 가능한, UAPs for BCIs 제시한다고 합니다. 아래와 같은 장점이 있다고 합니다
- UAP는 한 번만 계산하면 되며, 어떠한 EEG trial에도 적용이 가능하다고 합니다.
- EEG trial이 시작되자 마자, UAP가 더해질 수 있다고 합니다.
UAP는 최신 연구분야라 하는데요, Moosavi-Dezfooli et al은 UAPs의 존재를 밝혔으며, DeepFool이라는 complex optimization 문제를 해결하는, UAP 생성 방법을 제시하였습니다. Mopuri et al에서 제안된 UAPs crafting에서의 일반화, data free한 방법을 이 논문에서 사용하였다고 합니다. 위의 방법은 모두 Non-target attack이라 합니다. Target attack은 훨씬 더 여렵다고 하는데요, perturbation이 universal하며 동시에 특정 class를 targeting해야 하기 때문이라 합니다. 저자들이 조사한 바로는, Hirano et al에서 제시된, FGSM과 UAP 방법을 통합한 simple iterative method가 유일한 target attack이라 합니다.
이 논문은 아래와 같이 3개의 contributions을 한다고 합니다
- First study on UAPs for EEG-based BCIs
- EEG-trials를 위한 generating UAPs 하는 TLM approach 제시. 기존 DeepFool 방식보다 better하며 smaller perturbations을 사용한다
- 제시한 TLM방식은 non-target, target attack 모두 가능하다는 점
2. Universal adversarial perturbations
이 섹션에서는 먼저 EEG trials에 대한 UAP crafting하는 iteratvie algorithms을 소개하고, 후에 TLM approach 방법에 대해 소개하고 있습니다. Attack을 먼저 2가지 타입으로 분류하고 있습니다.
- Target attacks : adversarial examples이 특정 class로 오분류되어야 합니다.
- Non-target attacks : adversarial examples이 어떤 class로 오분류되든지 상관없습니다.
2.1 - Problem setup
BCI system을 attack하기 위해서는, adversarial perturbations이 benign EEG signals에 real-time으로 더해져야 합니다.
X(i) ∈ R(C×T) 라 하겠습니다
- X(i): i번째(i=1,...,n) raw EEG trial
- C: number of EEG channels
- T: number of time domain samples
이후 x(i)의 모든 column을 single column으로 concatenate하여 x ∈ R(C·T×1)로 만듭니다. k(x(i))을 target CNN 모델로부터 얻은 label이라 하고, v ∈ R(CT×1) 을 UAP라 하면은, ˜xi = xi +v은 UAP를 더한 adversarial EEG가 될 것입니다. v 는 아래와 같은 식을 만족해야 합니다.
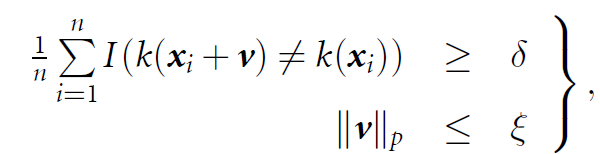
- ∥ · ∥p: Lp norm
- I(·) : 1이면 true, 0이면 false를 나타내는 indicator function
- δ ∈(0, 1]: Desired attack success rate
- ξ : v 의 크기를 제약. UAP가 small하다는 것을 ensure해준다.
2.2 - DeepFool-based UAP
DeepFool은 single input example에 대한 adversarial perturbations을 만드는 방법입니다.
Binary classification 문제를 예를 들어 설명하고 있습니다. labels이 {−1, 1}, x를 input example, f를 affine transormation function f(x) = wTx+b 라 가정합니다. Predicted label인 k(x) = signf(x)을 통해 얻을 수 있으며, minimal adversarial perturbation r∗ 은 점 x를 decision hyperplane F = {x∗ : wTx∗ +b = 0}로 이동시켜야 합니다. r∗은 아래와 같습니다.
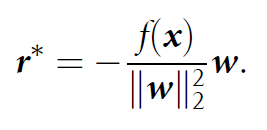
CNN classifiers은 nonlinear하므로, iterative procedure에서 (iteration t 기준) 통한 선형 근사화(f(xt) ≈ f(xt)+∇f(xt)Trt)를 통해, minimal-perturbation을 아래와 같이 구하게 됩니다.
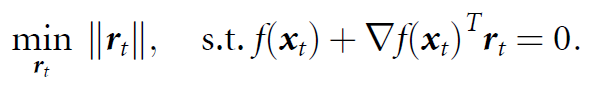
Iteration t에서 perturbation r(t)위의 공식을 이용하여 계산한 이후, ** x(t+1) = x(t) +r(t)**과정을 통해 x(t)를 update하게 됩니다. 위 과정은 아래의 algorithm1에 자세히 구현되어 있습니다. Algorithm1은 one vs all을 통하여 multi-class classification에도 확장 적용될 수 있다고 합니다. 또한 perturbation의 크기가 FGSM에 비해 DeepFool방식이 작다고 합니다.

Moosavi-Dezfooli et al에서 UAP방식이 image classification에 대해 처음으로 제시되었습니다. 여기서는 dataset X = {x(i)}(i=1 ~ n)에 대해 iterative한 방법을 적용하여서 UAP를 구합니다. 각 iteration마다, current perturbed point x(i) +v에서 minimum perturbation△vi를 구하기 위해 DeepFool을 사용하며, △vi는 v에 통합됩니다. 만약 perturbation v가 classifier를 속이지 못하면, minimum extra perturbation인 △v는 아래와 같이 구할 수 있으며, 속일 수 있도록 만들어 줍니다.
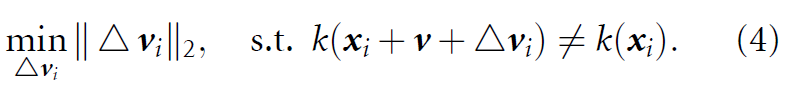
제약 조건 ∥v∥p ≤ ξ을 만족하기 위해서, updated universal perturbation v는 원점을 중심으로한 반지름이 ξ인 ball에 아래와 같이 project됩니다.
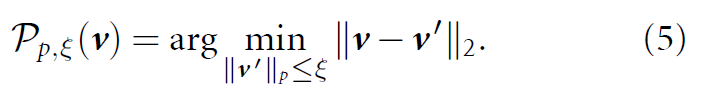
이 후, UAP는 각 iteration마다 v = Pp,ξ(v+△vi)로 update됩니다. Attack succes rate threshold를 넘기거나 dataset 끝까지 반복되면 멈추게 됩니다.
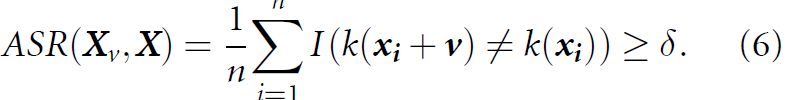

2.3 Our proposed TLM-based UAP
DeepFool방식과는 달리, TLM은 directly하게 UAP objective function을 batch gradient descent로 optimize 한다고 합니다. White-box attack에서는 model의 parameter를 알 수 있고, UAP를 objective function을 minimize하도록 만드는 변수라고 생각할 수 있다고 합니다. optimization problem을 아래와 같이 해결 가능하다고 합니다.
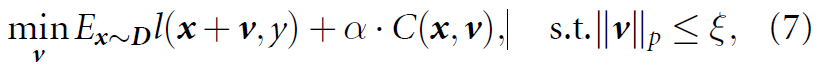
- l(x+v, y) : loss function / evaluates the effect of the UAP on target model
- C(x, v) : constraint on the perturbation v
- α : regularization coefficient
이 방법은 optimizers, loss functions, constraints를 attacker가 정할 수 있으므로 flexible하다고 합니다.
Non-target attacks에서는, loss function을 다음과 같이 정의할 수 있다고 합니다. l(x, y) = log(py(x))(y : true label of x). 이 loss function은 UAP가 모델이 true label y에 대한 confidence를 minimize하도록 합니다. TLM은 perturbation 최적화를 training data D에 대한 모델의 expected loss를 maximize하는 방식을 사용한다고 합니다.
Target attack에서는, loss function이 UAP가 target label에 대한 모델의 confidence를 maximize 하도록 만듭니다. loss function은 l(x, yt) = −log(pyt (x))로 정의할 수 있습니다. 위에서 정의한 l(x, y)와 l(x, yt) 모두 negative cross-entropy에 필수적이라고 합니다.
Constraint function, C(X,v)는 다양한 options을 가질 수 있다고 합니다. 간단하게, L1 or L2 regularization을 사용할 수도 있고, 정교하게 input이 adversarial example인지 판단하는 metric function을 사용할 수도 있다고 합니다. 이 논문에서는 L1,L2 regularization에 대해서만 다루었으며, 다른 metric function에 대해서는 추후 연구에서 다룰 것이라 하네요.
∥v∥p ≤ ξ 제약조건을 만족시키기 위해서는, 앞서 설명드린대로 원점을 중심으로 반지름이 ξ인 ball에, 각 optimization iteration 이후, project 한다고 하였습니다. 혹은 UAP v 의 크기를 [−ξ, ξ]로 고정시킬수 있는 방법도 있다고 합니다. 이 논문에서는 simplicity를 위해 후자의 방법을 택하였다고 합니다.
Adversarial examples들의 모델 간의 transferability를 이용하면, 위에서 설명했던 white-box attack을 gray-box attack senario에도 적용가능하다고 합니다. 대신에 attacker는 training set에만 접근 가능할 것입니다. sub-model에 UAP generating하는 것을 훈련한 이후, target model 공격에 사용될 수도 있을 것이라 합니다.

3. Experimental settings
3.1. The three BCI datasets
-
P300 evoked potentials (P300): 8 subjects. 각 subjects는 laptop을 바라보고 있으며, P300 response를 측정하고자 6개의 images들을 random하게 flash한다. Goal은 이미지가 target인지 non-target인지 classify하는 것이며, 32-channel EEG data가 256HZ로 downsampled 되었으며, bandpass filtered to [1,40]Hz, 각 이미지 등장부터 [0,1]s동안 측정되었습니다. 이 후, resulting value를 [-5,5]로 고정하기 위해 x−mean(x) / 10으로 normalize를 진행하였다고 합니다. Each subject당 3300 trials.
-
Feedback error-related negativity(ERN): Kaggle challenge에 있는 것을 사용하였으며, 26 subjects, 2 classes(bad/good feedback), 16 subjects for training, 10 subjects for testing으로 구분되어 있었지만, 이 논문서는 26 subjects를 모두 사용. 56-channel-EEG data, downsampled to 200Hz, bandpass filtered to [1,40]Hz, 각 stimulus 이후 [0,1.3]s동안 측정, z-normalized. Each subject당 340 trials.
-
Motor imagery (MI): 데이터 소스는 2A in BCI Competition IV로 부터 가지고 왔다고 합니다. 9 subjects, 4 classes(left/right hand, tongue, both beet). 22-channel-EEG data, downsampled to 128 Hz, bandpass filtered to [4, 40]Hz, 움직임 상상 후 [0, 2]s동안 측정, moving-average-window를 사용하여 standardize. 각 subject당 576 trials(각 class당 144 trials).
3.2. The three CNN models
-
EEGNet: Lawhern et al. EEG-based BCIs을 위한 compact한 CNN 모델입니다. 2개의 convolutional block들과 하나의 classification block을 가지고 있습니다. 모델의 paremeter를 줄이기 위해서, depthwise convolution연산을 수행합니다
-
DeepCNN: Schirrmeister et al. 4개의 convolutional block들과 하나의 softmax layer로 구성되어 있으며, EEGNet보다 깊은 모델입니다. 첫번째 convolutional block은 EEG inputs을 다루기 위해 design 되었으며, 나머지 3개는 standard한 convolutional block입니다.
-
ShallowCNN: Schirrmeister et al. band power featuers를 decode하는 것에 초점이 되어 있습니다. DeepCNN과 비교했을 때, ShallowCNN은 큰 kernel을 temporal convolution에 사용하며, spatial filter, mean pooling layer, log연산의 활성화함수가 뒤를 따릅니다.
3.3. The two experimental settings
-
Within-subject experiments: 실험에서는 five-fold cross validation이 적용되었습니다. 각 subject당, train:vallidation:test의 비율을 3:1:1로 주면서, overlapping이 안생기도록 하였다고 합니다.
-
Cross-subject experiments: leave-one-subject-out cross-validation이 사용되었습니다. N명이 있다고 하면, Nth subject는 test로 두고, 나머지 N-1 subjects에 대해서, mix후에 75% training, 25% validation으로 분리하였다고 합니다.
class imbalance를 조정하기 위해서, training set의 class 비율의 역수로 class별 weights을 주었으며, Adam optimizer, corss-entropy loss function을 사용했다고 합니다. 또한 overfitting을 막기 위해서 Early stopping을 사용했다고 하네요.
TLM방식의 UAP는 constraints가 없이 train되었으며, δ를 1.0으로 설정하고, early stopping (patience =10)으로 주었다고 합니다. 또한 위의 (7)번 식에서, true label y를 알 수 없으므로, predicted 값으로 대체하였다고 합니다.
3.4 The two performance measures
performance 지표로 2가지 개념을 제시하고 있습니다.
- RCA(Raw classification accuracy): (number of correctly classified samples) / (total samples)
- BCA(Balanced classification accuracy): 각 class별 RCAs의 평균. class imbalance가 있는 경우 RCA만 사용하는 것은 잘못된 결과를 초래할 수 있으므로, BCA를 사용한다고 합니다.
4. Non-target attack results
이 섹션에서는 3가지 BCI dataset에 대한 Non-target attack 결과를 소개하고 있습니다.
4.1. Baseline performances
4.1.1. Clean baseline
clean한 dataset에 대하여 각 데이터셋에 대해 3가지 모델을 활용하여, 2가지 방식으로 RCA, BCA를 측정하였다고 합니다. within-subject experiments의 값이 대응되는 cross-subject experiments 보다 값이 높다고 하는데, 개인마다의 차이점이 EEG trials의 inconsistency를 만들었기 때문이라 합니다
4.1.2. Noisy baseline
Original EEG data에 Gaussian random noise ξ(max(−1, min(1,N(0, 1))))를 추가하였다고 합니다. ξ크기의 제약은 마치 UAP에서 ∥v∥p ≤ ξ와 동일하다고 합니다. 아래의 결과 표를 보면, Random noise에 대해서는 UAP만큼 모델의 성능저하가 일어나지 않은 것을 확인할 수 있습니다. 이를 통해 3가지 모델은 random-noise에 robust하다고 말할 수 있다 합니다. 따라서 정교하게 design된 perturbation의 필요성을 제시합니다.
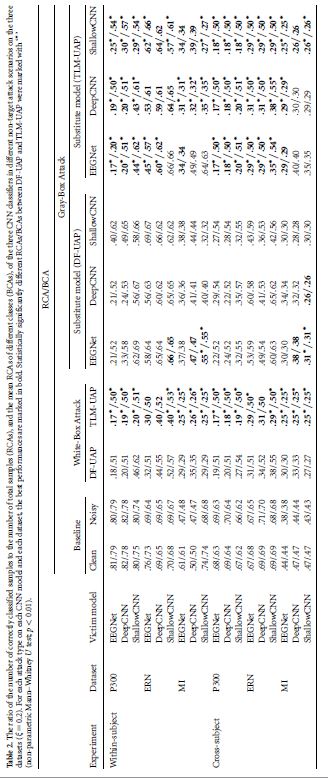
4.2. White-box non-target attack performances
White-box attack에서는 모델의 모든 정보와 training data에 대해서 알 수 있습니다. DeepFool-UAP와 TLM-UAP 모두 위의 표를 보면, RCA와 BCA모두 확연히 감소하였습니다. 또한 TLM방식이 DF방식보다 잘 되는 것을 확인할 수 있는데, 이는 TLM방식이 entire dataset에 대해 direct하게 optimize하는 반면, DF방식은 각각의 sample을 고려하므로, local minimum에 빠진다는 문제가 발생하기 때문이라 설명합니다.
DF-UAP, TLM-UAP이후, P300, ERN은 RCA가 0.5가 안되지만 BCA가 0.5정도 나오는 것을 보아, best한 attack performace를 위해 test EEG trials를 minority class로 분류한다고 합니다. EEGNet에 TLM-UAP를 적용한 결과를 보면, majority class로 분류되던 trials들이 minority class로 분류되는 것을 확인할 수 있습니다.
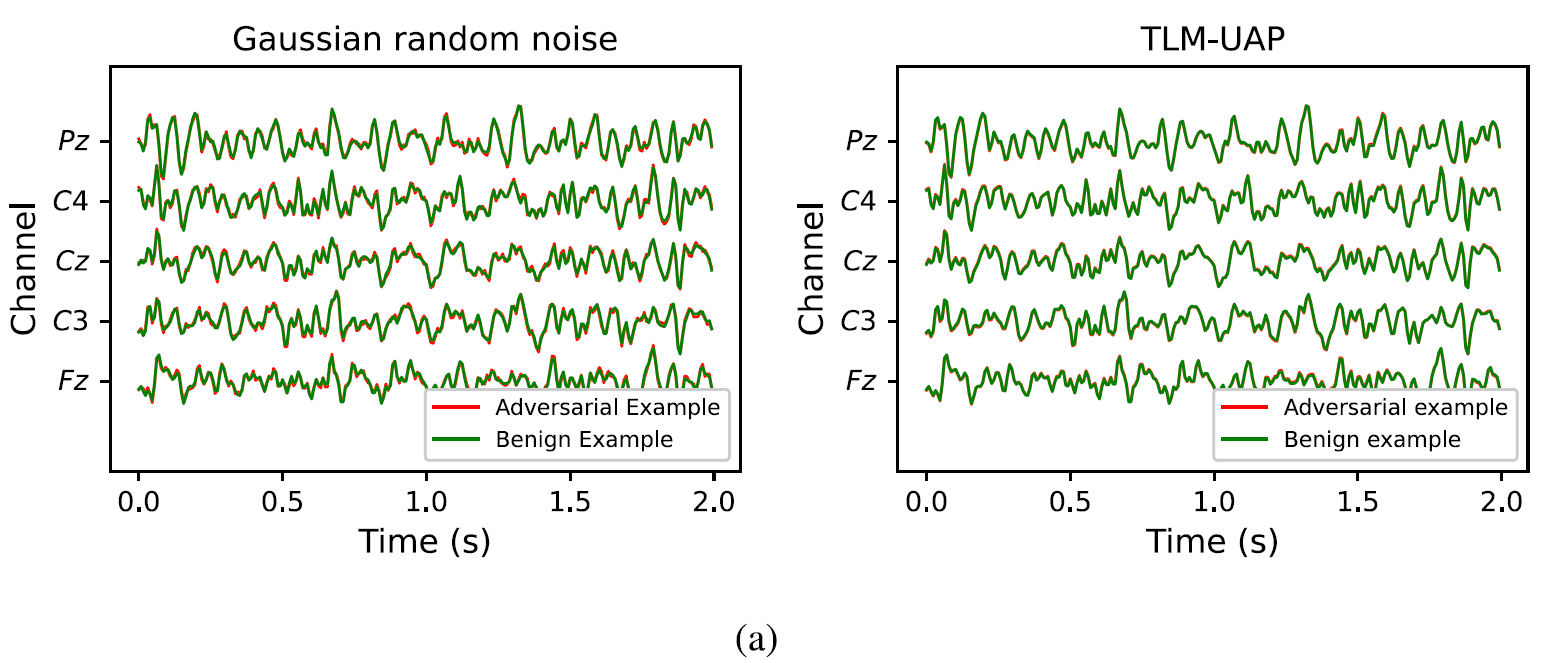
위의 그림을 살펴보면 Gaussian random noise보다 TLM-UAP의 distortion이 작다는 것을 알확인 가능합니다. 이 이유는 TLM에서 optimization과정에서 크기에 constarint가 있었기 때문이라 합니다.
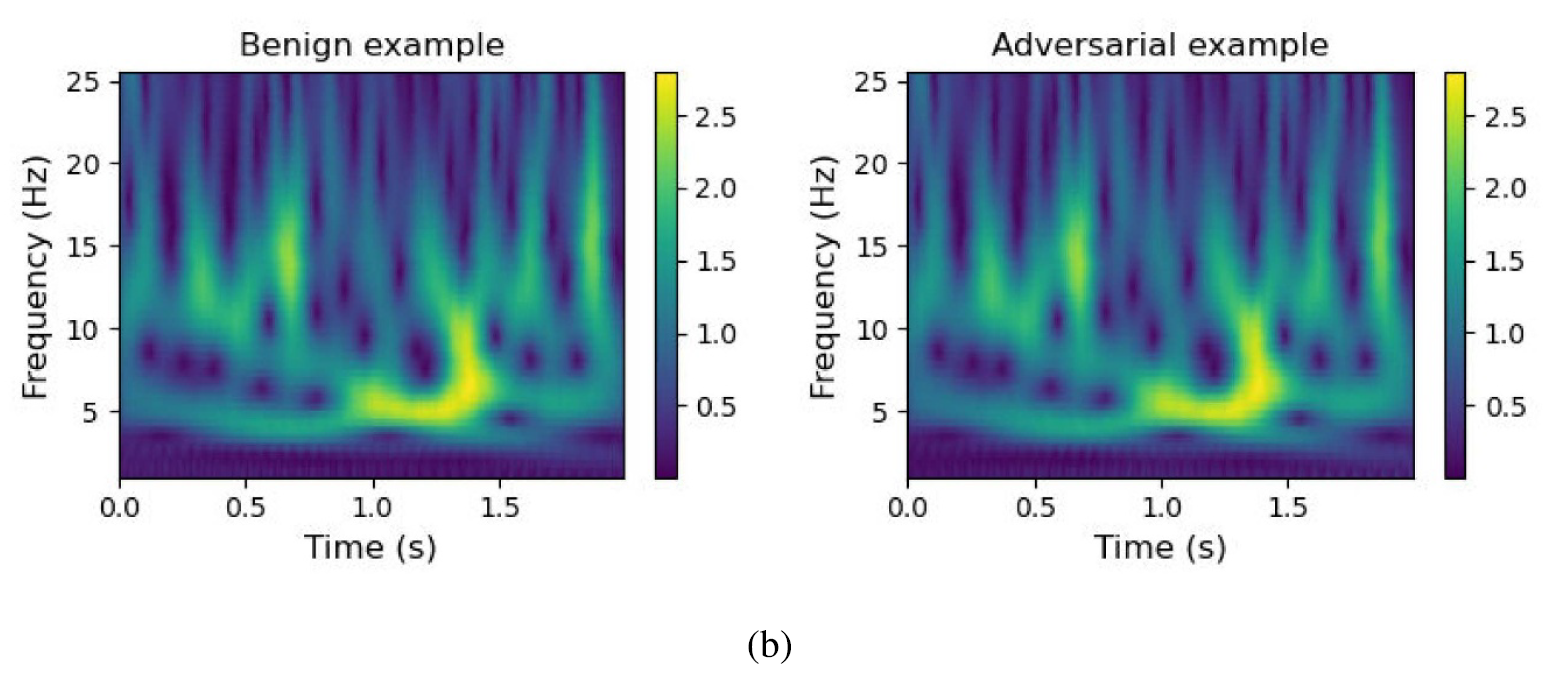
위 그림은 TLM-UAP를 적용하기 전후의 spectrogram인데요, TLM-UAP의가 time-domain과 frequency-domain에서 모두 작아, 구분하기 힘든 것을 확인할 수 있습니다
4.3. Generalization of TLM-UAP on traditional classification models
CNN모델 기반으로 생성된 TLM-UAP를 traditional models에 적용한 결과를 소개하고 있습니다.
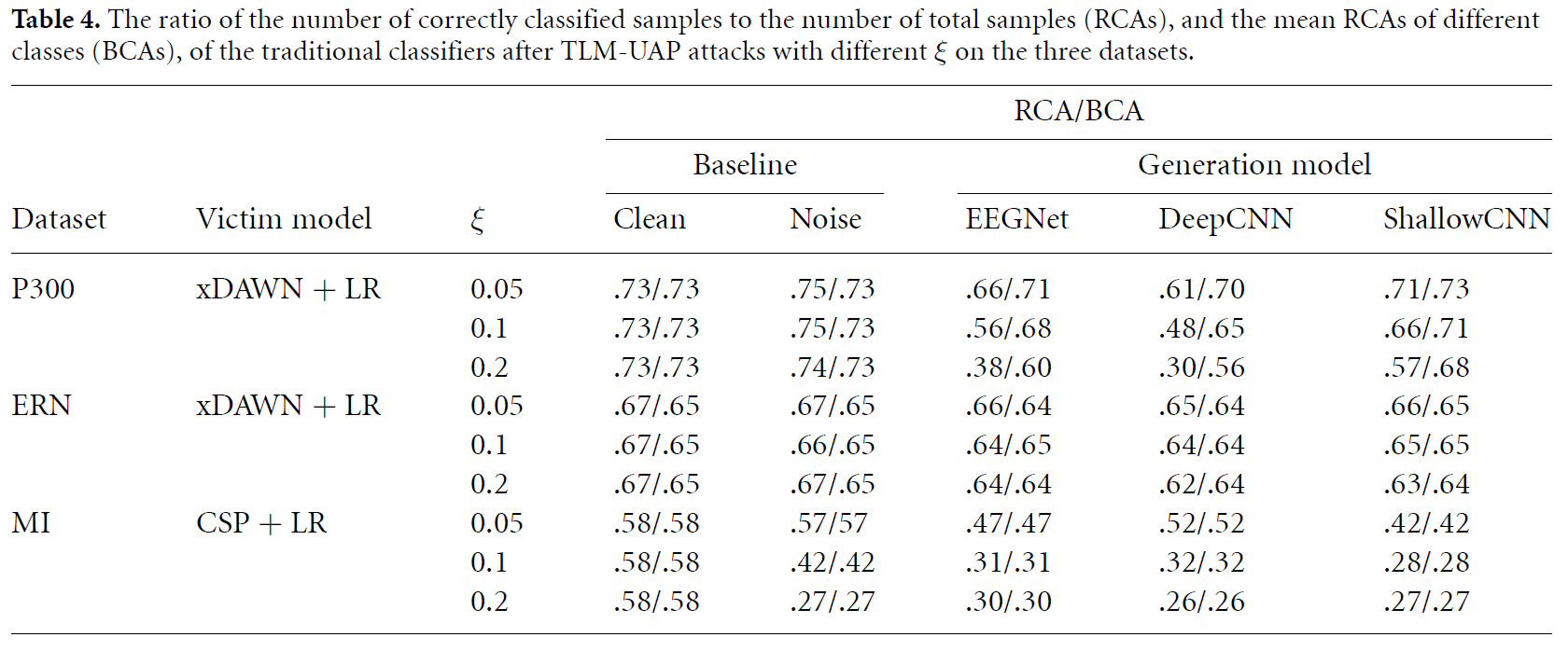
위의 결과를 살펴보았을 때, traditional models에도 잘 적용되는 것을 살펴볼 수 있었으며, TLM-UAP의 크기(입실론)에 영향을 많이 받는 것을 확인할 수 있습니다.
4.4. Transferability of UAP in gray-box attacks
Adversarial examples은 모델을 뛰어넘어 적용될 수 있습니다. 이 섹션에서는 DF-UAP와 TLM-UAP의 transferability에 관해서 설명하고 있습니다.
Gray-box attack scenario의 예시를 들었는데요, attacker는 대체 모델을 이용하여 같은 training data에 대해 UAP를 만들고, target model에 attack을 할 수 있을 것이라 합니다. 이에 대한 결과는 위의 table2에서 확인할 수 있다고 합니다.
4.5. Characteristics of UAP
4.5.1. Signal-to-perturbation ratio (SPR)
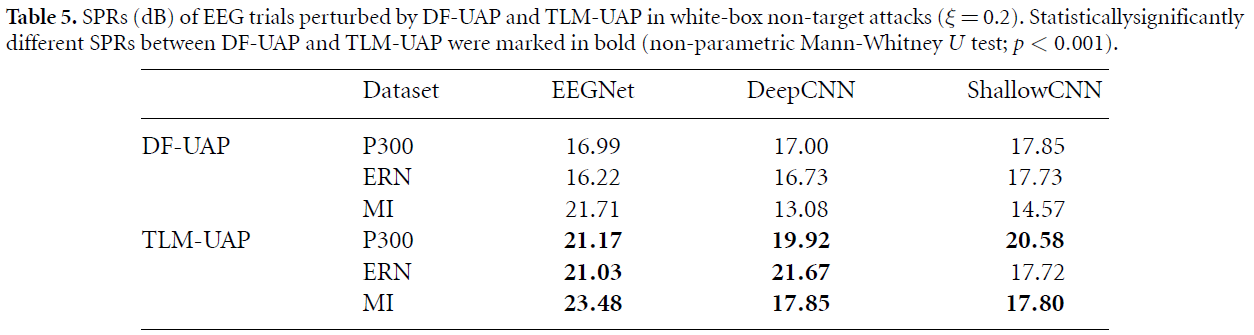
위의 table은 cross-subjects에 대해 clean signals / perturbation의 값을 나타낸 것입니다. TLM-UAP가 DF-UAP보다 높은 값을 가졌는데요, 이유로는 위에서도 언급했듯이, TLM에 constraints가 많기 때문이라 합니다.
4.5.2. Spectrogram
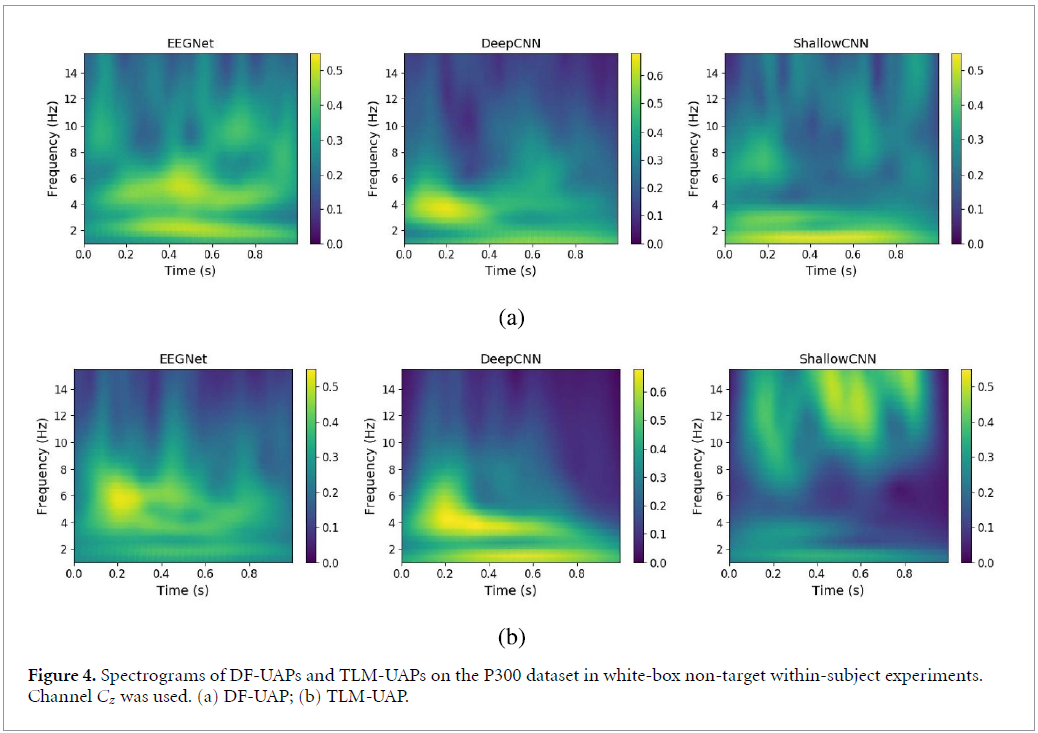
위의 그림은 white-box attack에서 DF-UAP와 TLM-UAP방식을 이용하여 spectogram을 만든 것입니다. 둘은 비슷한 spectogram pattern을 가지고 있습니다. EEGNet, DeepCNN의 경우 energy가 low-frequency영역에 몰려있고, ShallowCNN의 경우 흩어진 것을 확인할 수 있었습니다. 이러한 결과는 table2에서 EEGNet으로부터 생성된 TLM-UAP가 ShallowCNN보다 DeepCNN에 더 효과적인 것을 뒷받침 해준다고 합니다.
4.5.3. Hidden-layer feature map
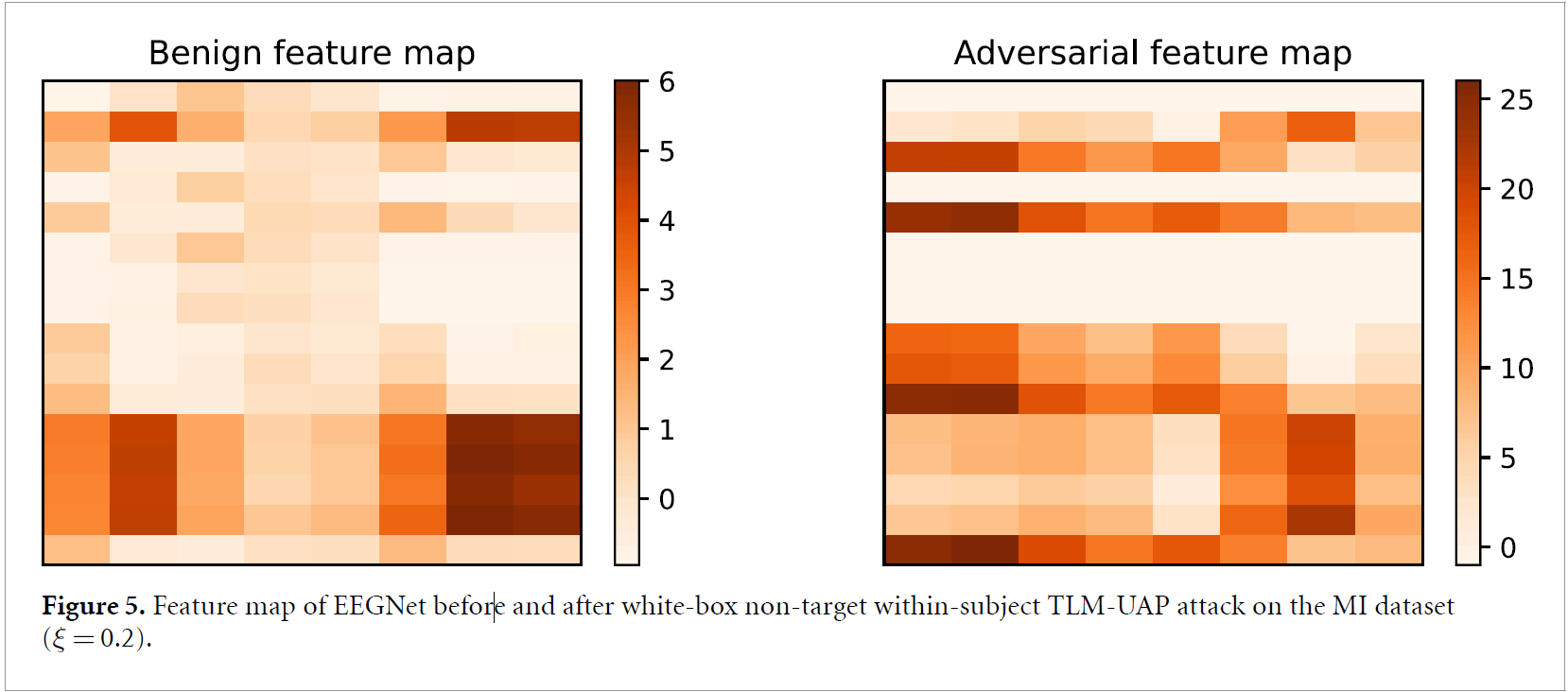
Figure 5는 EEGNet의 마지막 convolutional layer의 feature map을 TLM-UAP 적용 전후로 형상화 한 것입니다. Small perturbation이 EEGNet에서 complex한 nonlinear transformation을 통해 증폭된 것을 확인할 수 있었습니다. 이로 인해 hidden layer의 feature map이 매우 달라졌음을 알 수 있습니다.
4.6. Hyper-parameter sensitivity
4.6.1. The magnitude of TLM-UAP
ξ은 TLM-UAP의 크기를 constrain하는 요소로서, 매우 중요한 요소임을 알 수 있습니다. 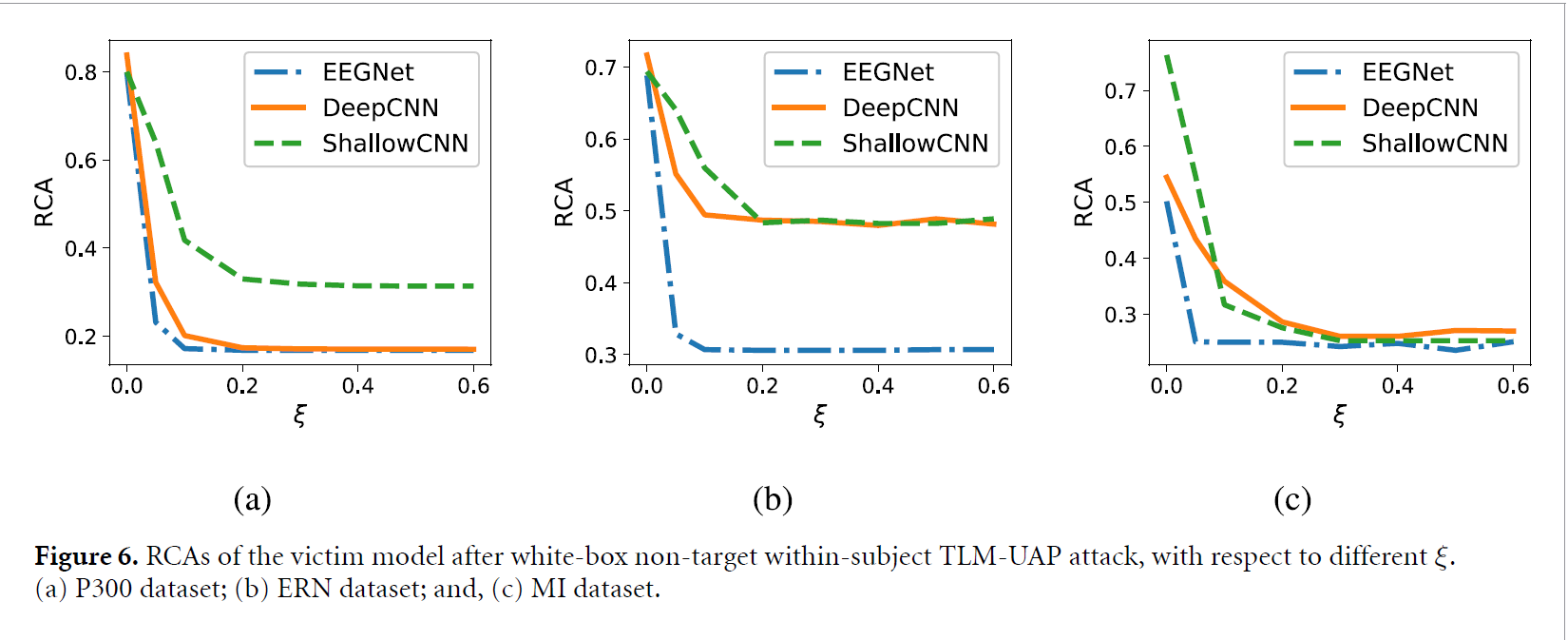
Figure 6는 ξ에 따른 attack performace를 보여주는데, ξ이 커질수록 RCA가 급격하게 감소하였습니다. 또한 TLM-UAP는 ξ=0.2이하에도 잘 적용되므로, small한 UAP도 powerful한 attack이 될 수 있다고 제시합니다.
4.6.2. Training set size
위의 표는 MI dataset에 대해, white-box attack에서 training size를 달리했을 때의 결과입니다.
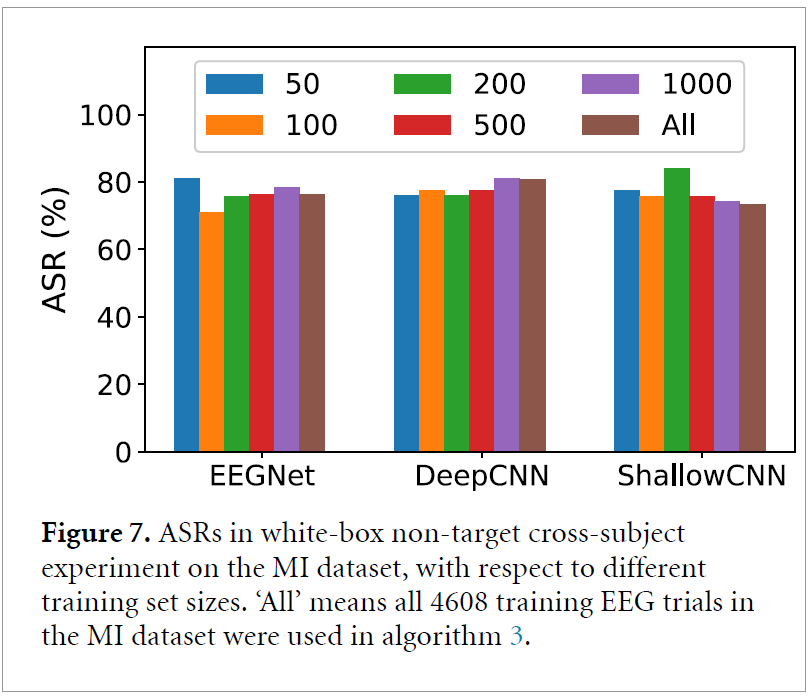
large training set이 없어도 effective하게 TLM-UAP를 얻을 수 있다고 합니다.
4.6.3. Constraint
아래의 표는 constraint C의 변화에 따른 결과를 보여주고 있습니다. No constraint, L1 regularization (α = 10/10/5 for EEGNet/DeepCNN/ShallowCNN), and L2 regularization (α=100)
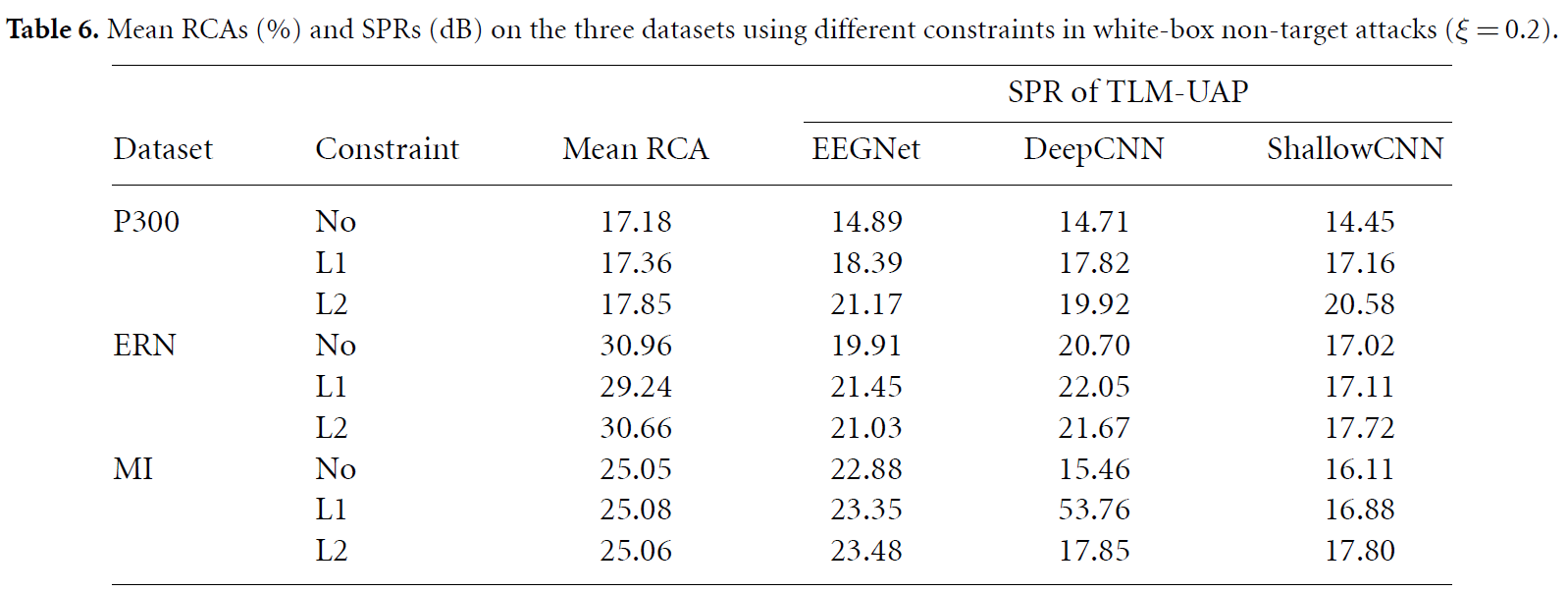
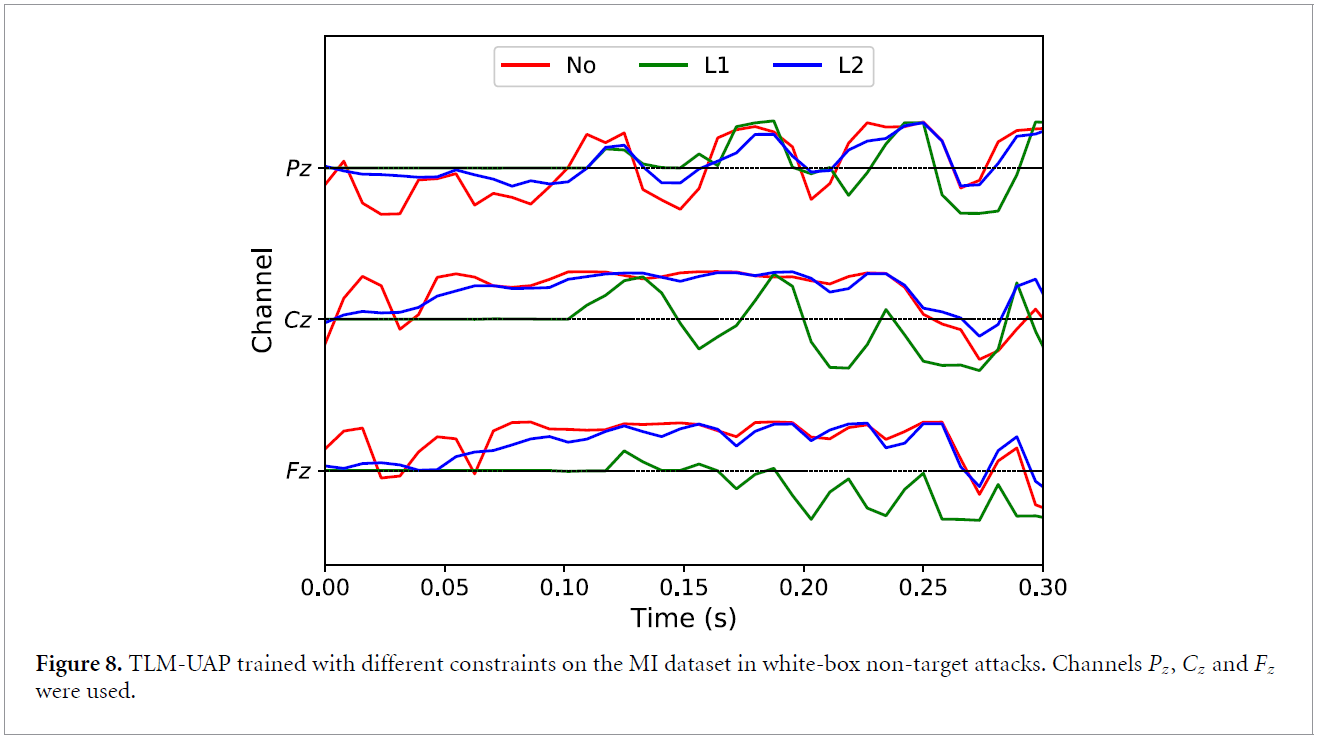
위의 그래프는 다른 Constraints이 waveform을 얼마나 바꾸는지 나타낸다고 합니다. L1은 sparsity(값이 0인 구간)이 많아졌고, L2는 perturbation의 크기를 줄이는 역할을 합니다. 다른 constraint function을 쓰거나, 특정 EEG Channel에 제약을 가하는 것, metric function을 바꾸는 것의 경우는 후속 연구로 남긴다고 합니다.
4.7. Influence of the Batch size
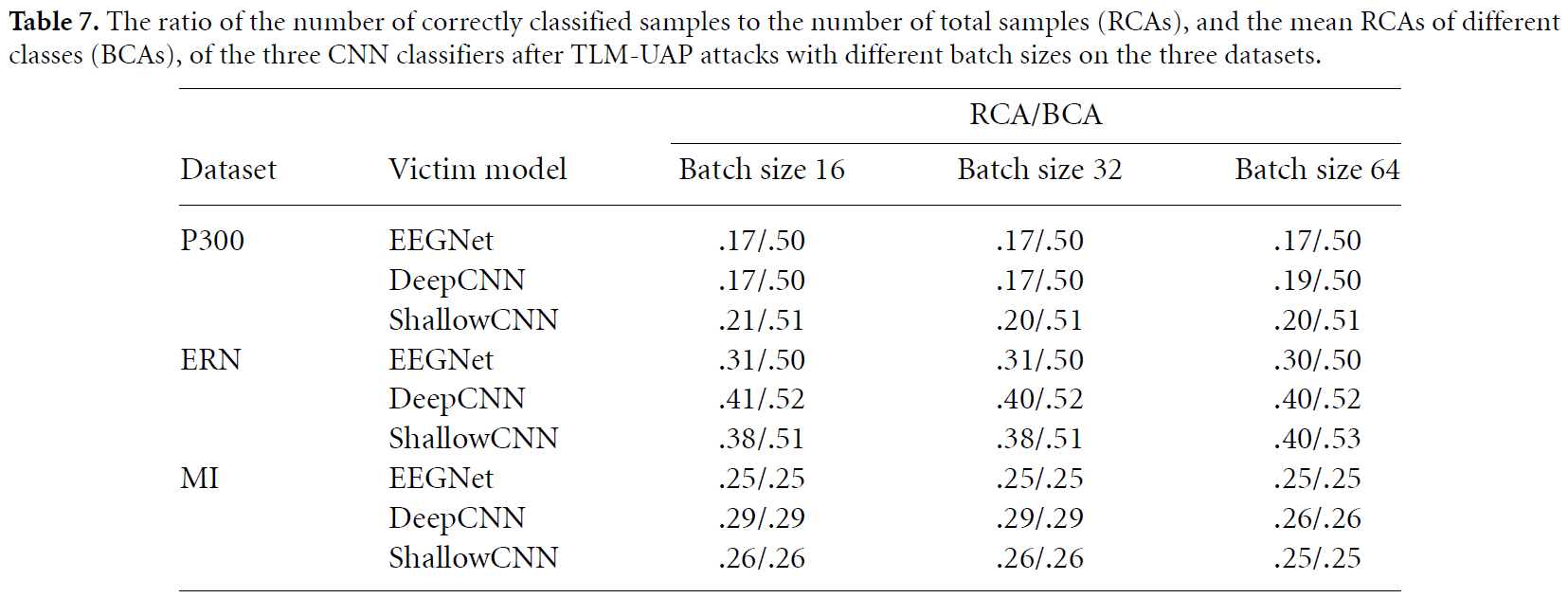
5. Target attack results
Target attack에 대한 TLM 방법은 loss function l을 바꿔주기만 하면 된다고 합니다.
cross-subjects experiments에서 white-box target attacks 후, target rate( target class로 분류된 sample수 / total samples)를 측정한 결과는 아래 table8에 기록되어 있습니다.
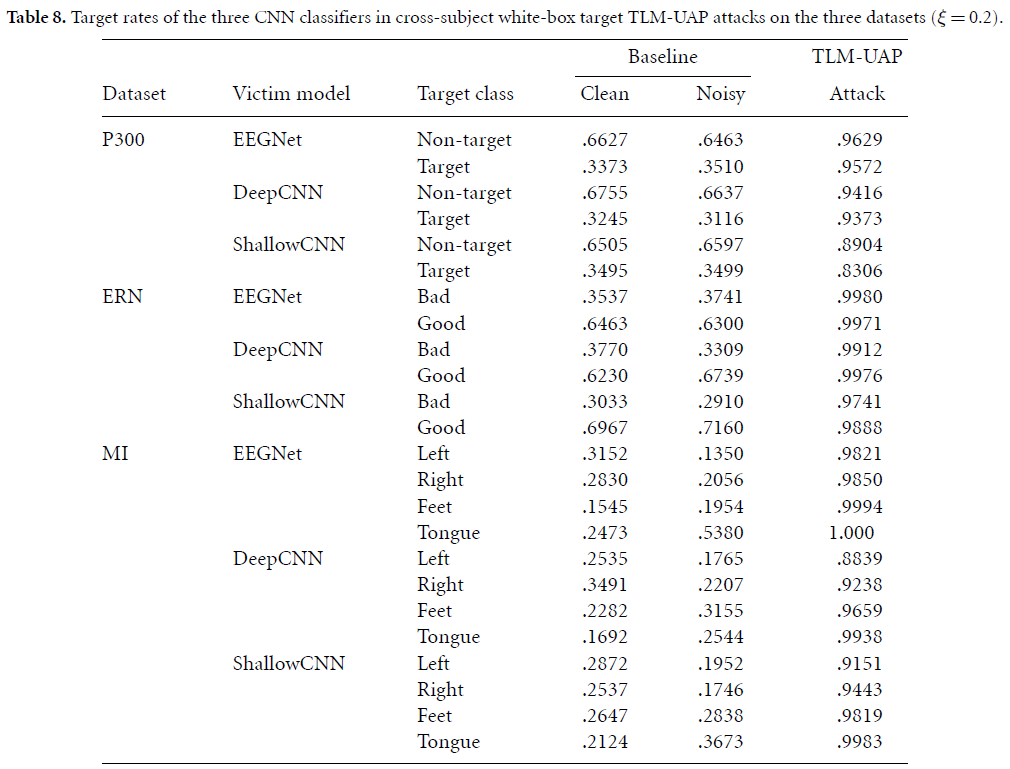
TLM-UAPs는 white-box target attack에서 90% 후반의 높은 target rates를 보이고 있는데, 이는 BCI systems을 attacker가 원하는대로 공격할 수 있다는 매우 위험한 보안 이슈를 보여준다고 합니다.
TLM-UAP의 implementation을 간단히 하기 위해, 이 논문서는 적은 채널수와 sample수를 가지고 있고, 어떤 EEG trial에 더해질 수 있는 Mini TLM-UAPs을 소개하고 있습니다. Mini TLM-UAPs는 attacker에게 정확한 EEG 채널수나, EEG trial의 시작점, 길이를 요구하지 않으므로, 훨씬 더 flexible하다고 합니다.
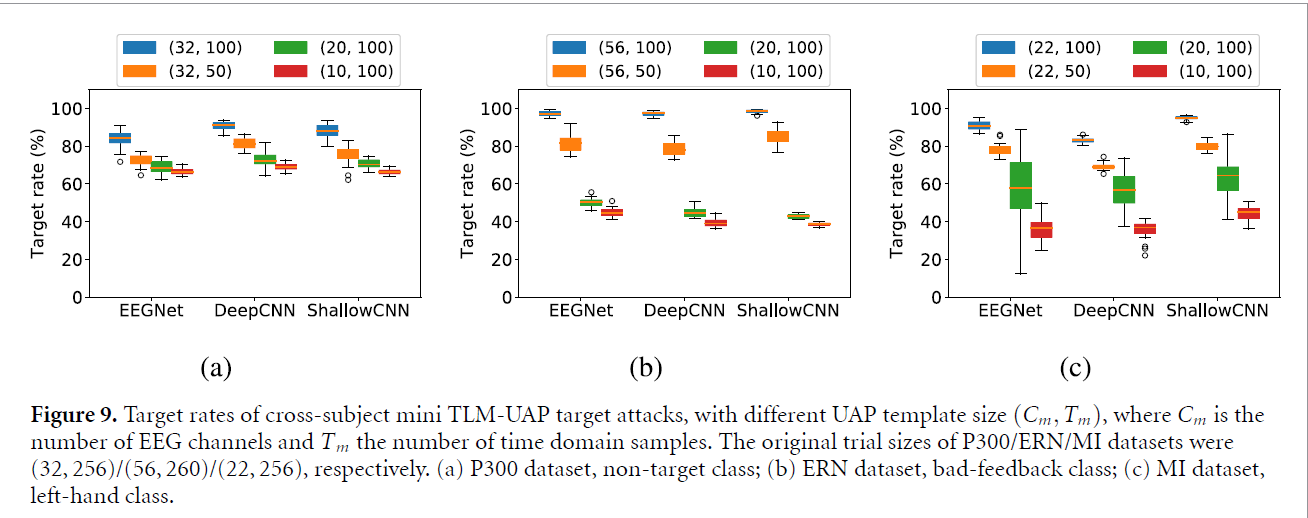
위의 결과는 30개의 다른 EEG trials에서 Channel수와 Template length를 변화시킬때의 결과입니다. Mini TLM-UAPs가 잘 작동되는 것과, C와 T가 줄어들 때, effectivenss가 같이 줄어드는 것을 보여줍니다. 이러한 결과는 mini TLM-UAPs가 attack performance와 implemenation difficulty 사이의 타협에서 최선이라는 것을 보여준다고 합니다.
6. Conclusions and future research
최근 많은 CNN classifier이 EEG-based BCIs에 제안되었습니다. 그러나 UAPs에 매우 취약하다는 사실도 있습니다. 이 논문서는 TLM approach를 제안하여, EEG-based BCIs에 UAP를 generating하는 법을 제안하였습니다. 실험들을 통해 이 방법이 유효하다는 것을 보였으며, target/Non-target에 모두 적용 가능하며, 모델간의 transferability도 보여주었 다고 합니다. 이 논문은 EEG-based UAP에 관한 첫 논문이라고 하며, 이것을 계기로 BCI에서의 security issue를 제시했다고 말하고 있습니다.
후속연구로는 TLM-UAP의 transferability를 강화하는 방법과 EEG-based의 machine learning models들을 어떻게 공격할 것인가에 대한 점이라고 합니다. 더욱 중요한 것으로는, 이러한 UAP를 defense하는 방법에 관하여서도 연구를 진행한다고 합니다.
논문에 대한 리뷰는 위와 같습니다. 사실 이 논문은 제 첫 연구 주제인 'EEG adversarial attack'을 가장 잘 다루는 논문이라 생각합니다. 사실 adversarial attack을 비전 분야에서 다뤄보고 있지만, 제가 아는바로는 EEG-BCI 영역에서는 많은 선행 연구가 없는 것으로 알고 있습니다. 저도 얼른 연구가 진행되어서 논문을 publish했으면 좋겠습니다!
긴 글 읽어주셔서 감사합니다^^
