Chapter objectives
- 프로세스의 구성요소들을 살피고, OS에서 어떻게 관리되는지 설명한다
- OS에서 프로세스가 어떻게 만들어지고 없어지며, syscall에 의해 어떻게 프로그램을 개발하는지 설명한다
- 공유 메모리를 사용한 IPC(프로세스들간의 통신)에 관하여 설명한다
- 파이프와 POSIX 공유 메모리를 통해 프로세스 간 통신하는 프로그램 설계
3.1 Process 개념
3.1.1 The process
프로세스란 실행중인 프로그램을 일컫는다. 프로세스의 상태는 program counter와 processor-registor의 내용들로 나타낼 수 있다. 메모리에서 프로세스의 틀은 아래와 같다.
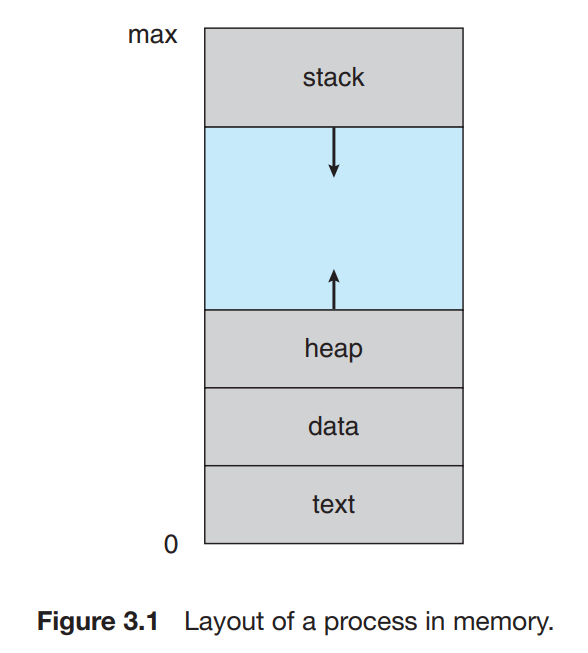
- Text section : 실행되는 코드가 저장된다
- Data section : global variables이 저장된다
- Heap section : 프로그램이 실행되면서 dynamically allocated 되는 메모리 공간이다.
- Stack section : 주로 function(function parameters, return address, local variables)와 같은 임시 데이터 저장소이다.
프로그램이 작동하는 동안, 코드와 전역 변수들은 고정되므로, Text, Data section의 크기는 고정되어 있다. 반면에, stack,heap section은 프로그램 동작중에 크기가 변화할 수 있다. stack과 heap은 서로 마주보는 방향으로 크기가 증가하는데, OS는 서로 overlap하지 않도록 보장해야 한다.
프로그램 자체가 프로세스는 아니다. 프로그램은 수동적인 객체이지만, 프로세스는 능동적인 객체이다. 프로그램은 실행될 파일이 메모리에 업로드 될 때, 프로세스가 된다. 더블 클릭이나 command line 입력을 통해 메모리에 파일이 로드가 된다. 또한 같은 프로그램에 관련한 여러개의 프로세스가 존재할 수 있으며, 그들은 서로 다르다! 프로세스는 또한 다른 코드를 위한 실행환경도 될 수 있다.
3.1.2 Process state
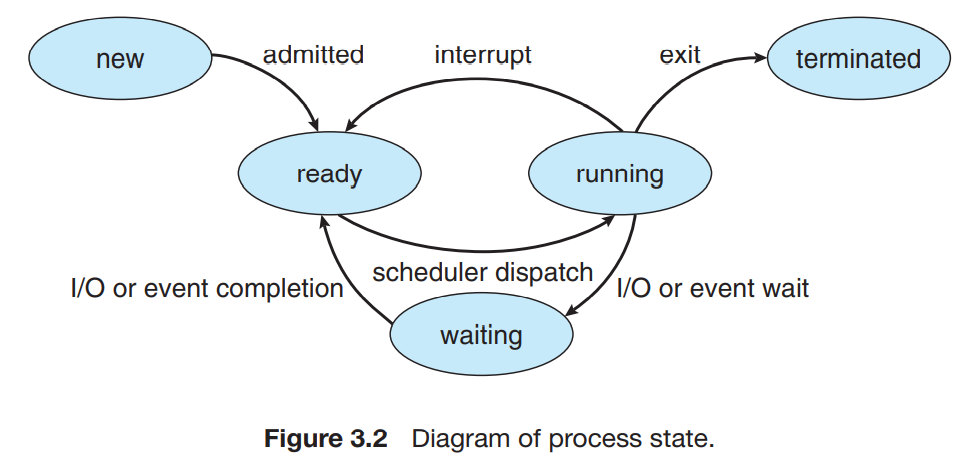
프로세스가 실행되면 상태 역시 바뀐다. 프로세스 상태란, 프로세스의 최근까지의 활동을 말하는 것이다. 프로세스의 상태들은 다음과 같다.
| 상태 | 내용 |
|---|---|
| New | 프로세스가 새로 생성된 상태 |
| Running | 명령어가 돌아가는 상태 |
| Waiting | 프로세스가 event를 기다리는 상태(ex.I/O devices) |
| Ready | 프로세스가 프로세서에게 할당되기를 기다리는 상태 |
3.1.3 Process Control Block (PCB)
각 프로세스들은 OS에서 process control block (PCB)의 형태로 관리된다.
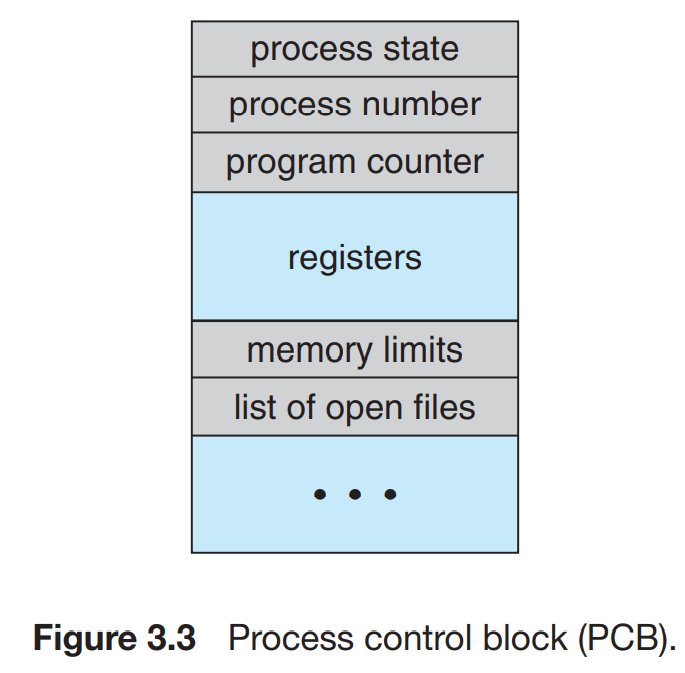
- Process state : new, ready, running, waiting, halted 등의 상태가 있다
- Program counter : 다음에 실행되어야 할 프로세스의 주소를 가리킨다.
- CPU registers : 다시 run 상태로 reschedule 될때, 계속 실행되기 위해 레지스터의 상태 정보도 저장되어야 한다
- CPU-scheduling information : 프로세스 우선순위, 스케쥴링 큐 포인터 등의 정보를 포함한다
- Memory-management information : 기준 레지스터, 한계 레지스터, 페이지 테이블, 세그먼트 테일블 값과 같은 정보. 운영체제 메모리 구조에 따라 다르다.
- Accounting information : CPU의 실시간 사용량, 시간 제한, 프로세스 갯수 등을 담고 있는 정보다
- I/O status information : 프로세스에 할당된 I/O 장치들의 정보들을 포함하고 있다.
PCB는 프로세스를 시작하거나 재시작하기 위한 데이터를 저장하는 기능을 하고 있다
3.1.4 Threads
지금까지 위에서 설명한 내용들은 단일 thread를 가진 process를 가정하여 설명한 것이다. 프로세스에 스레드가 1개이면, 한번에 한개의 task 밖에 할 수 없다. 대부분의 현대 OS들은 확장된 process 개념을 가지고 있어서, 프로세스 하나에 여러 스레드를 가지게 하여, 1개의 task 이상의 일들을 할 수 있게 한다. 특히 이것은 멀티 스레드들이 병렬적으로 돌아갈 수 있는 multicore system에 매우 유리하다. 예를 들어 멀티스레드 워드 프로세스는, 1개의 스레드를 user input을 받는데 사용하며, 다른 스레드는 오타 검증을 하는데 할당할 수 있다.
3.2 Process Scheduling
멀티프로그래밍의 목적은 process를 항상 실행시키게 하여, CPU 사용을 극대화 하는 것이다.
Time sharing의 목적은 단일 CPU 코어에서 프로세스를 계속 전환하여, 사용자가 프로그램이 실행되는 동안 interact하는 것이다. 이러한 목적들을 달성하기 위하여, process scheduler는 여러 프로세스들 중에서 단일 코어에서 실행할 가능한 프로세스를 선택한다. 1개의 CPU core는 1개의 프로세서를 실행할 수 있다.
단일 CPU core에서, 1개의 프로세스 이상 돌아갈 일은 없지만, 멀티 코어 시스템에서는 여러개의 프로세스가 실행될 수 있다. 코어 수보다 프로세스의 수가 많으면, 여분의 프로세스들은 코어가 빌 때까지 기다리고, reschedule된다. 현재 메모리에 있는 프로세스의 갯수를 degree of multiprogramming라 한다.
3.2.1 Scheduling Queues
프로세서가 시스템에 등록되면, ready queue에 올라가고, CPU core에 실행될 때까지 기다린다. 이 큐는 링크드 리스트로 구현되어 있다. 헤더는 첫 PCB를 가리키며, 각 PCB마다 다음 실행될 PCB를 가리킨다.
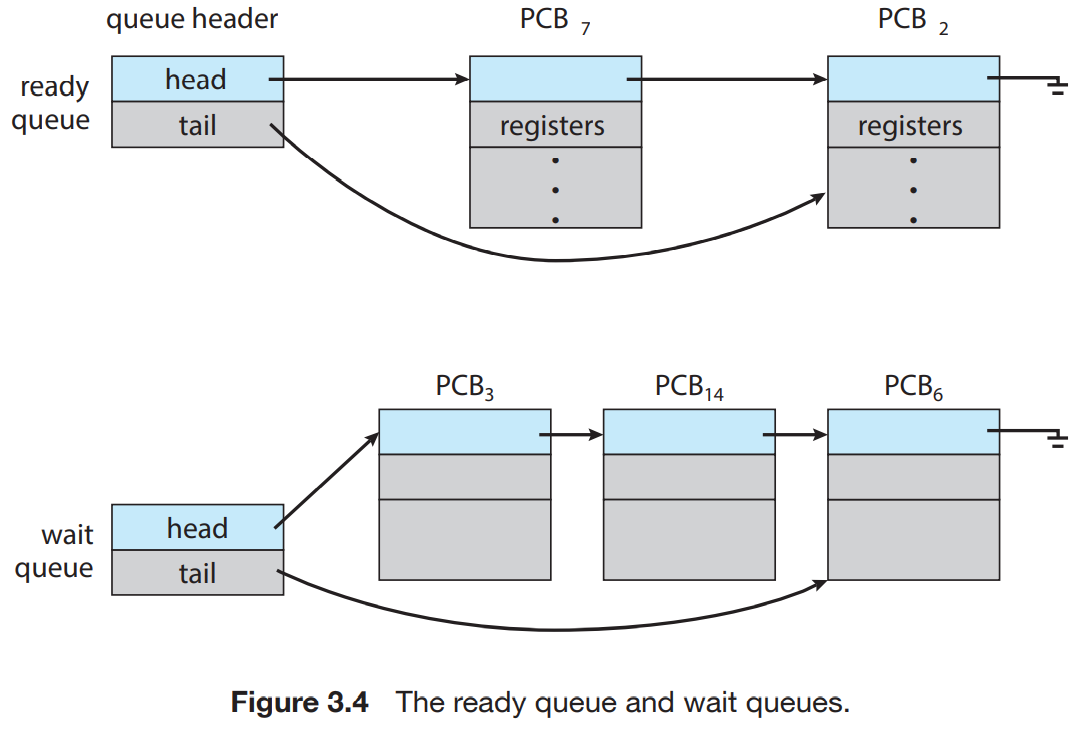
프로세스가 CPU에 할당되면, 어느 정도 실행되다가, interrupted 등에 의해 결국에는 제거된다. wait queue라는 곳에는 입출력 장치 연산같은 프로세서처럼 event를 기다리는 프로세스들이 저장된다.
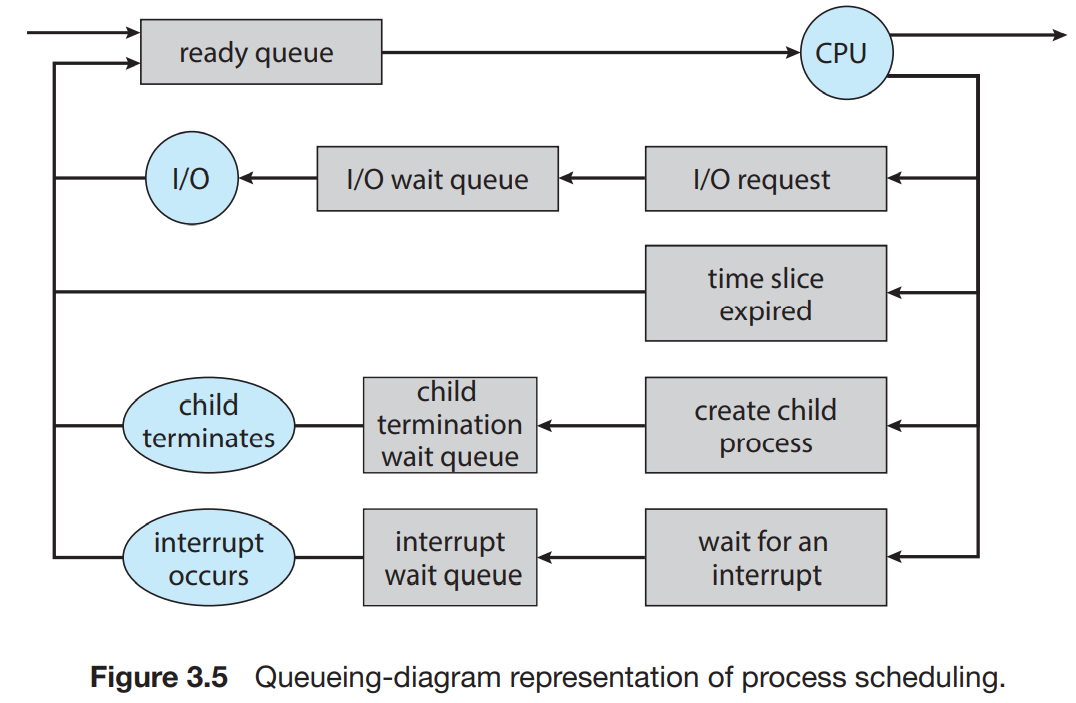
system에서는 또한 다른 queue들이 존재한다.
Ready Queue
: ready state상태의 프로세스들이 모여있는 queue로서, 메인메모리 상에서 CPU에 의해 실행되기를 기다리고 있다.
I/O Device queue
: 특정한 I/O 연산들을 기다리는 프로세스들이 모여있는 queue이다.(waiting for I/O device)
프로세스 스케쥴링의 가장 대표적인 방식은 위와 같은 queueing diagram이다. ready queue와 wait queue들로 구성된다. 새로운 프로세스는 ready queue에 들어가게 되며, 실행을 위해 선택되거나 Dispatch(지명)까지 wait한다. 즉, ready queue로부터 가능한 프로세서를 선택하여 dispatch하는 것을 프로세스 스케쥴링이다.
프로세스가 CPU에 할당되면 다음과 같은 이벤트들이 일어날 수 있다.
- 프로세스는 입출력 오청을 받아 I/O wait 큐에 존재할 수 있다
- 프로세스는 새로운 child 프로세스를 만드록, wait queue에 놓여서 child 프로세스의 종료를 기다린다
- 프로세스는 인터럽트나 할당 시간 초과로 인해 강제로 코어로부터 제거되어 ready queue에 놓여있을 수 있다.
3.2.2 CPU Scheduling
CPU Scheduler의 역할은 레디 큐에 있는 프로세스들을 선택하여 CPU 코어에 할당해주는 것이다. CPU 스케쥴러는 새로운 프로세스를 자주 선택해야 한다. 프로세스들은 CPU 코어에게 긴 작동시간을 요구하지만, 스케쥴러는 정해진 시간이 끝나면 강제로 프로세스를 내려버리고 다른 프로세서를 코어에 올린다. 따라서 CPU 스케쥴러는 100밀리세컨드 당 최소 한 번 실행되어야 하며, 보통 이것보다 더 자주 실행된다.
몇몇 운영체제들은 swapping이라는 스케쥴링 방식을 사용하는데, 프로세스를 아예 메모리에서 제거하여 degree of multiprogramming을 줄이는 방법이다. 이후 프로세스는 최근 상태가 저장된 채로 메모리에 다시 로드된다. swapping은 메모리의 과부하가 걸려 비워야 할때만 필요하다.
프로세스 스케쥴러는 다음과 같이 2종류가 있다
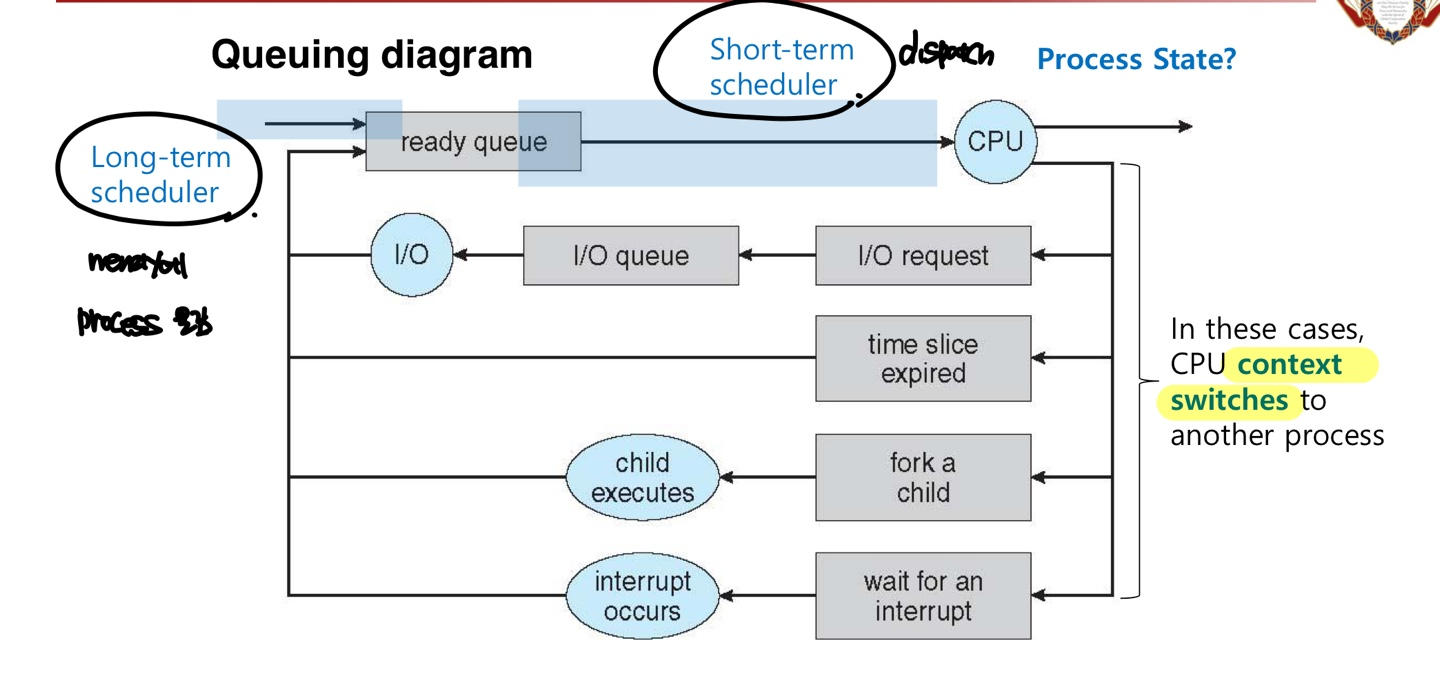
Long-term scheduler(=job scheduler) -> Giving to Memory
: 어떤 job이나 process를 ready큐에 넣어야 할 지 결정한다. 즉, degree-of-multiprogramming(메모리에 존재하는 프로세스 갯수)를 조정한다. 프로세스는 I/O bound process(연산보다는 I/O에 시간을 많이 할당하여, short CPU burst)와 CPU bound process(연산에 많은 시간을 할당하여, long CPU burst)로 구분되며, Long-term-scheduler는 process mix를 적절히 하여 시간을 조정한다. infrequently하게 발생하여 속도가 느리다.
Short-term scheduler(=CPU scheduler) -> Giving to CPU
:레디큐에 있는 프로세스들 중에서 어떤 프로세스를 다음에 CPU에 할당할 지 선택한다. 매우 자주 일어나서, 속도가 빠르다.
3.2.3 Context switching
인터럽트가 발생한 경우처럼, 시스템에서 CPU에서 실행되는 프로세스의 현재 상태(context)를 저장하여, context를 복구해 다시 재개하는데 사용하는 경우가 있다. PCB에 context가 포함된다. 이것은 CPU register의 값과 프로세스 상태를 포함한다. 보통 우리들은 커널/사용자 모드에서 CPU 코어의 현재 상태를 저장하고, 후에 다시 상태를 복구하여 연산들을 재개한다.
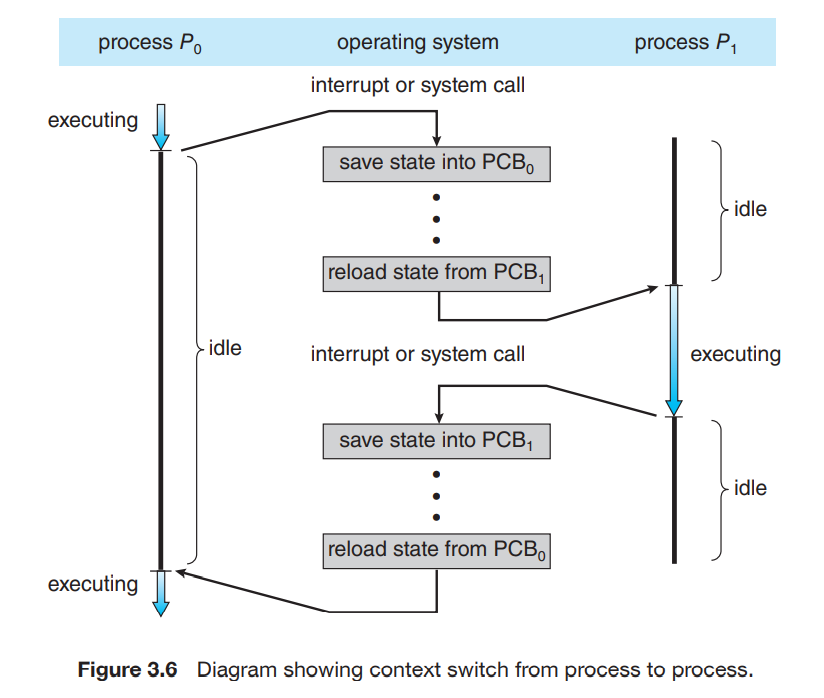
CPU 코어에서 프로세스를 전환하는 것은 프로세스의 현재 상태의 저장과 다른 프로세스의 상태 복구를 필요로 한다. 이러한 과정을 context switch라 하며, 위의 그림에 잘 설명되어 있다. Context switch가 일어나면 커널은 옛 프로세스의 상태를 PCB에 저장하며, 새로운 프로세스의 context를 불러온다. Context switching 동안 의미있는 작업을 하지 못하므로, 이 시간은 오버헤드이다. Context switch 시간은 또한 hardware support의 지원을 많이 받는다고 한다.
3.3 Operations on processes
프로세서들은 동시에 실행될 수 있기 때문에, dynamic하게 생성 및 삭제될 수 있어야 한다.
3.3.1 Process creation
프로세스는 자신의 프로세스를 복제하여 다른 프로세스를 생성한다. parent, child process가 존재. 이러한 방식을 따르면 프로세스들의 관계를 tree로 표현 가능하다.
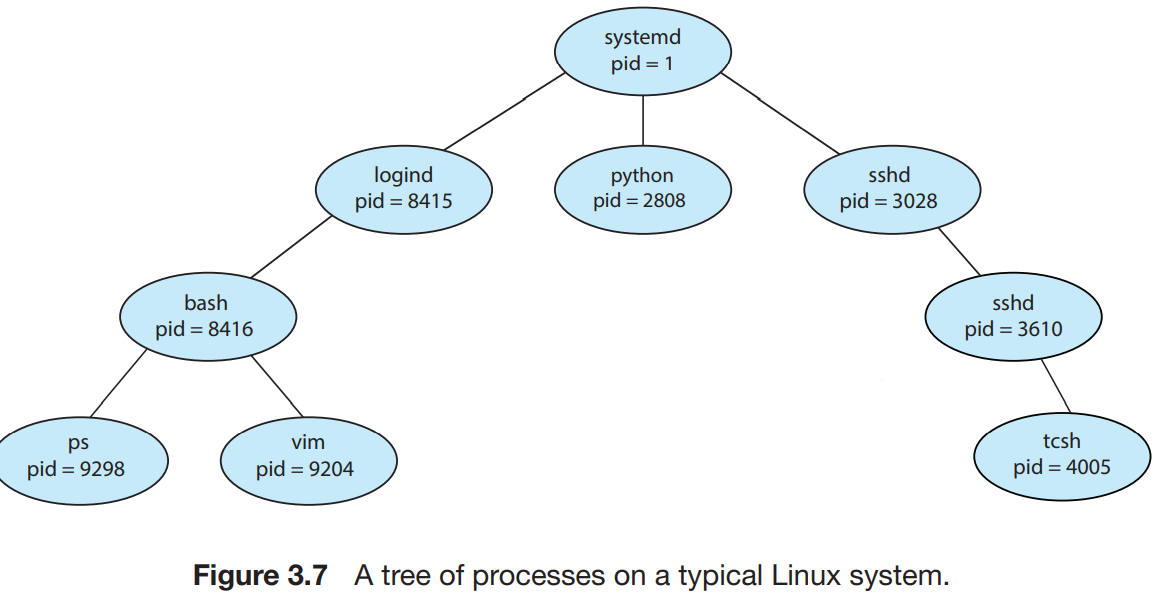
대부분의 운영체제들은 pid(process identifie, 정수)를 사용하여 프로세스를 identify한다. pid는 각 프로세스마다 고유 정수값을 가져서, 커널 내 특성들의 index로 사용될 수도 있다.
부모 프로세스로부터 자식 프로세스가 만들어질때, 자식 프로세스는 리소스가 필요할 것이다. 이는 OS로부터 바로 얻을수도 있으며, 부모 프로세스에서 제한적으로 가져올 수 있다.
자식 프로세스가 생길때, 부모 프로세스는 아래 2가지 중 하나로 행동한다.
- 1. 자식 프로세스와 동시에 작동한다
- 2. 자식 프로세스가 종료될 때까지 기다린다
새로운 프로세스에 대한 주소 공간의 가능한 경우는 다음과 같다
- 1. 자식 프로세스는 부모 프로세스의 복제품여서, 같은 프로그램, 데이터를 사용한다
- 2. 자식은 로딩될 새로운 프로그램이 있다
UNIX system에서의 예
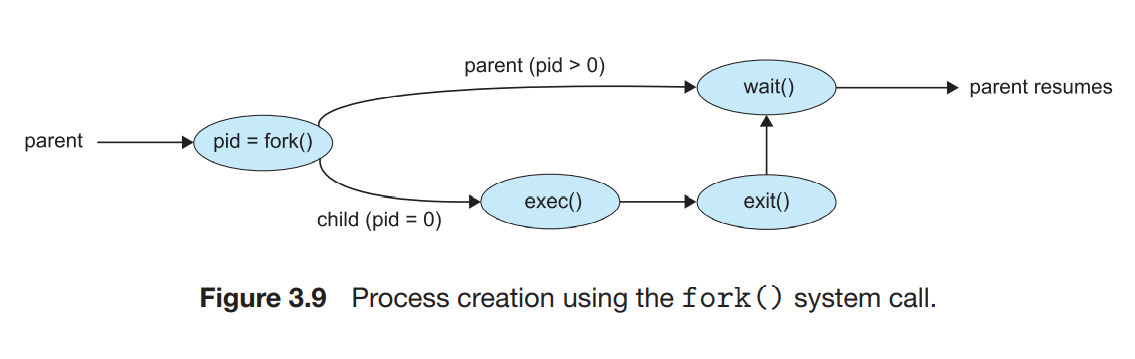
: 각 프로세스는 pid에 의해 identify된다. 새로운 프로세스는fork()라는 syscall에 의해 생성된다. 새로운 프로세스의 주소 공간은 원래 프로세스를 복사한 것이며, 이러한 원리를 통해 부모-자식 프로세스간의 소통이 용이하다. fork()에 의해 생성된 부모-자식 프로세스간의 유일한 차이점으로는, return code가 다르다는 것이다. 자식은 0를 return, 부모는 자식의 pid값이 반환된다.
fork() call이후에,exec() syscall에 의해 부모 자식 중 하나는 프로세스 메모리 공간을 새 프로그램으로 교체한다. 이러한 방식을 통해 서로 분리되면서도 소통할 수 있게 된다.

3.3.2 Process termination
프로세는 실행을 완료하면 OS에게 exit() syscall을 통해 삭제를 요청한다. 프로세스들의 resources들은 다시 OS에게 반납된다. 부모 프로세스는 다음과 같은 경우들에 대해서 자식 프로세스들을 종료(kill, SIGkill)시킨다.
- 자녀 프로세스가 할당된 자원 이상을 쓰는 경우
- 자녀 프로세스의 task가 더이상 필요하지 않는 경우
- 부모가 제거될 시, OS에서 자녀가 살아있는 것을 원하지 않는 경우 -> 몇몇의 OS에서 부모 프로세스가 제거되면, 자녀 프로세스도 반드시 제거되어야 한다. 이를 cascading termination이라 한다.
3.4 Interprocess communication
프로세스가 독립적이라는 것은, 다른 프로세스들과 data를 공유하지 않는다는 것이다. 반면에 프로세스가 협력적이라는 것은, 하나의 프로세스가 다른 프로세스들에 영향을 주거나 받을 수 있다는 것이다. 즉, 프로세스간 데이터를 주고 받을 수 있다.
프로세스 협력을 하는 이유는 다음과 같다
1. Information sharing
2. Computation speedup
3. Modularity
Cooperating process란, interprocess communication(IPC)를 요구한다. 즉, 프로세스간 데이터를 서로 주고 받을 수 있어야 한다. IPC에는 두가지의 기본적인 방법이 있는데, 1)shared memory 2)message passing 방식이 있다. shared memory 방식에서는, 프로세스간 공유할 메모리 공간이 만들어진다. 프로세스들은 이 공간에 데이터를 읽고 쓰는 것이다. 반면에 message passing방식에서는, message교환을 통해 정보를 주고 받는다.
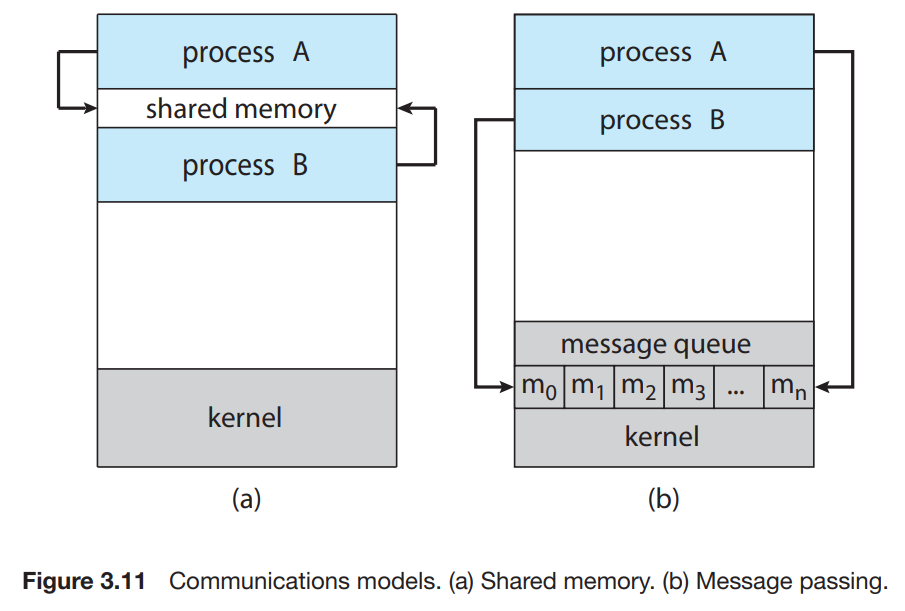
위의 두가지 방식은 많은 OS에서 흔히 사용되며, Message passing 방법은 프로세스 충돌이 없으므로 적은 양의 데이터를 교환할 때 효율적이다. 또한 shared memory보다 구현하기 쉽다. 반면에 shared memory 방식은 빠른데, message passing은 syscall에 의해 실행되어, kernel의 개입이 있어 시간이 더 많이 사용될 것이기 때문이다. shared memory방식에서는 공유 공간을 만들때만 syscall이 발생한다.
3.5 IPC in Shared-Memory systems
앞서 언급했듯이, shared memory방식서는 공유 저장공간을 통해 communication이 일어난다. 그동안 OS는 프로세스간의 침범을 막는 역할을 했는데, shared-memory에서는 프로세스들간 동의를 통해서 이러한 OS의 제약을 없앤다. 대신, 프로세스들이 몇가지 책임을 지게 된다. 데이터와 저장 위치는 프로세스들이 결정하며(OS는 통제못함), 서로 같은 메모리 위치를 동시에 쓰는 일이 없도록 프로세스들이 책임져야한다. 이러한 공유된 저장공간을 통해 데이터를 읽고 쓸 수 있다. 이 방법의 단점으로는 대표적으로 synchronization(동기화)가 있다.
3.6 IPC in Message-Passing systems
이 방법은 communication과 synchronization을 메시지를 주고 받는 것을 통해 하는 방식이다. 특히 distributed system에서 유용한데, 네트워크에 의해 연결된 다른 컴퓨터들 간의 프로세스 통신시 유용하다. 메시지 전달체는 send(message), receive(message) 연산(syscall에 의해)을 가지고 있다.
3.6.2 Synchronization(동기화)
communication은 주로 send(), receive()연산을 통해 이뤄진다. send(), receive() 구현 방법은 여러가지가 있다. Message passing은 blocking(종료시까지 기다림)/nonblocking, 다시 말해서 synchronous, asynchronous한 방법이 있다.
- Blocking send : Sending process는 메시지가 수신될 때까지 송신이 불가하다
- NonBlocking send : sending process에서 메시지 송신을 하면 바로 다시 송신
- Blocking receive : 메시지 수신이 가능할 때까지 수신이 불가
- Nonblocking receive : 유효/null 메시지 모두 수신
