Chapter objectives
- 스레드의 구성 성분을 파악하고, 프로세스와의 차이점을 살핀다
- 멀티스레드 포르세스들의 장단점을 살펴본다
- 스레딩을 실행하는 방법들에 대해 설명한다
- 윈도우와 리눅스에서 스레드가 어떻게 시스템에서 돌아가는지 살펴본다
- 멀티스레드 시스템 설계
이전 3장에서는 단일 스레드 프로세스를 기반으로 설명하였다. 최근 운영체제들은, 멀티스레드 프로세스들을 기반으로 한다. 다중 CPUs를 가진 최근의 컴퓨터들의 OS를 파악하기 위해, 스레드는 필수적인 지식이다.
4.1 Overview
스레드(Thread)란 CPU 연산의 가장 작은 단위이다. 스레드는 Thread ID, program counter(PC), reigster set, stack으로 구성된다.같은 프로세스 안에있는 스레드들은 코드 섹션, 데이터 섹션, OS resources을 같이 공유한다. 프로세스가 멀티 스레드를 갖게되면, 한번에 1개 이상의 task를 수행할 수 있게 된다. 아래 그림은 단일 스레드 프로세스와 멀티 스레드 프로세스를 비교한 것이다.

4.1.1 Motivation
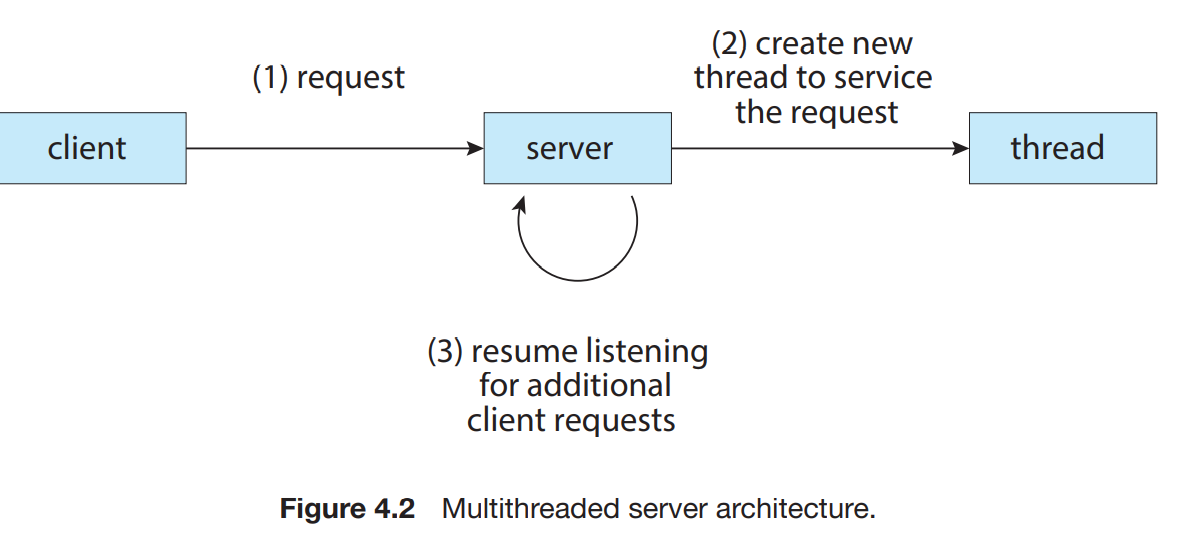
최근 현대 컴퓨터와 모바일 기기는 멀티 스레드 기반이다. 예를 들어 워드 프로세스의 경우, display용 스레드, 키 입력용 스레드, 문법 확인 스레드 등, 여러가지 작업을 동시에 할 수 있다. 아래 그림처럼 웹서버 같은 경우에도 멀티 스레드 방법의 개념을 적용하여, 여러 스레드를 통해 여러 request를 처리할 수도 있다고 한다.
4.1.2 Benefits
- Responsiveness : 프로세스 일부 스레드가 block되거나 긴 연산이 수행될 때도, 나머지 스레드들을 통해 계속 실행할 수 있으므로, user에 대한 반응성을 높여준다. 사용자 인터페이스에 많이 사용
- Resource sharing : 프로세스간에는 shared memory, message passing을 통해서 resource 공유가 가능하다. 이건 프로그래머가 구현해 주어야 할 필요가 있다. 반면에 같은 프로세스의 스레드들은 메모리와 자원을 default로 공유한다.
- Economy : 프로세스 생성에 있어 메모리와 자원의 할당은 cost가 크다. 반면에 스레드는 같은 프로세스 안에서 자원을 공유하므로, context-switch 스레드를 만드는 것이 더욱 경제적이다. Context switch역시 스레드 간이 프로세스 간보다 빠르다.
- Scalability : 멀티프로세서 구조에서, 스레드들은 여러 프로세싱 코어에 병렬적으로 돌아갈 수 있다는 장점이 있다. 반면, 단일 스레드 프로세스는 한번에 하나밖에 못돌림.
4.2 Multicore Programming
다중 CPU 시스템화 되면서, 멀티스레드 프로그래밍은 효율적인 멀티 코어들의 사용과 동시성을 개선해준다. 예를 들어 4개의 스레드가 있을때, 단일 코어서는 아래처럼 동시에 여러 스레드를 실행하지 못하고, Conccurency는 스레드를 교차시켜 실행하는 것을 말한다. 반면에, 멀티코어 시스템서는, Concurrency(동시성)은 몇개의 스레드들을 병렬적으로 실행할 수 있다는 뜻이다.
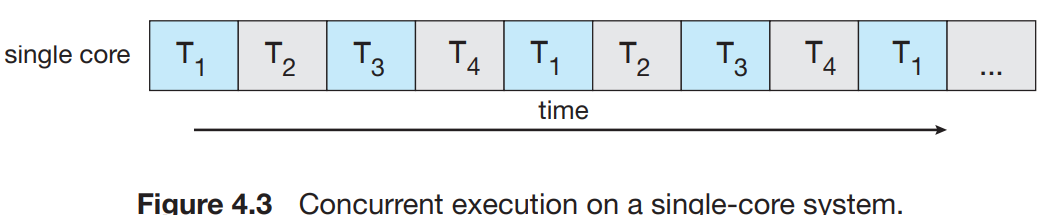
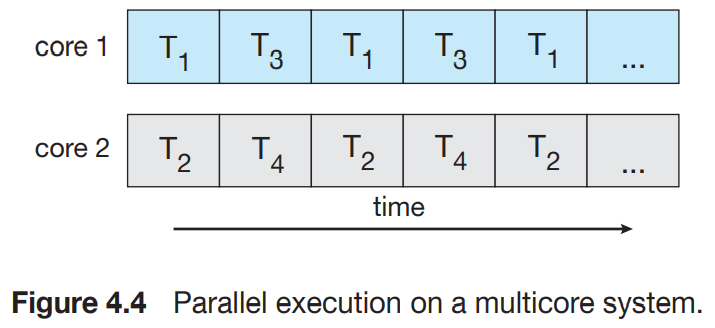
Concurrency(동시성)와 Parallelism(병렬성)은 서로 다른 개념이다. Concurrent system은 모든 tasks를 진행하게 만드는 것이며 단일 코어로도 가능하다. parallel system은 하나 이상의 task를 동시에 실행하는 것으로, 멀티 코어가 필요하다. 따라서 병렬성없이 동시성을 가지는 것은 가능하다. 기존 단일코어 시스템서, CPU스케쥴러는 process교환을 매우 빠르게 하여, 마치 parallelism같은 환상을 느끼게 한 것이다. 각 프로세스들은 진척이 되었을 거지만, 병렬적으로 수행되었다고는 할 수 없다!
4.2.1 Programming Challenges
OS 설계자들은 멀티 프로세싱 코어를 사용한 병렬 실행을 기반으로 한 스케쥴링 알고리즘을 만들어야한다. App 설계자들은, 멀티스레드 기반으로 프로그램을 작성해야 한다. 프로그램을 할 때 다음과 같은 어려움이 있다고 한다.
1. Identifying task : 어플리케이션이 seperate, concurrent한 task들로 나뉠 수 있게 확인해야 한다.
2. Balance : 식별된 tasks들이 병렬적처리를 통해 같은 값에 같은 일을 수행해야 한다. 전체 프로세스에 기여가 적은 것들은 병렬적으로 돌리면 cost가 안맞을수 있다는 것
3. Data spliting : 데이터들로 tasks처럼 쪼개져서 다른 코어들로 가야함
4. Data dependency : 자료들간의 의존성을 확인하여, 동기화 문제와 같이 생길 이슈들을 확인
5. Testing and debugging : 다중 코어서 작동하면, 많은 경우의 수가 발생한다. 단일 스레드보다 검증하기 어려워짐
4.2.2 Types of Parealellism
병렬화의 종류는 크게 2가의 타입이 있다. Data parallelism, Task parallelism이 있다.
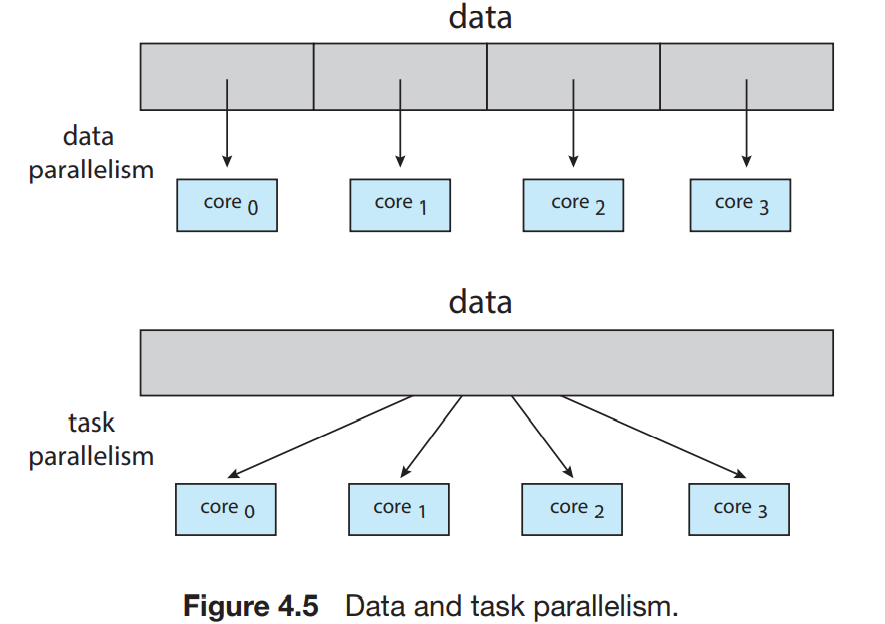
- Data parallelism : 같은 데이터의 부분 집합들을 멀티 코어들에 분배하는 것에 초점을 두어서, 각 코어마다 같은 연산을 수행한다.
- Task parallelism : 데이터뿐만 아니라 스레드들도 멀티 코어에 분배하는 것을 포함한다. 각 스레드는 고유 연산이 있고, 각기 다른 스레드들은 같은 데이터를 연산할 수도 있고, 다른 데이터를 연산할 수도 있다.
4.3 Multithreading models
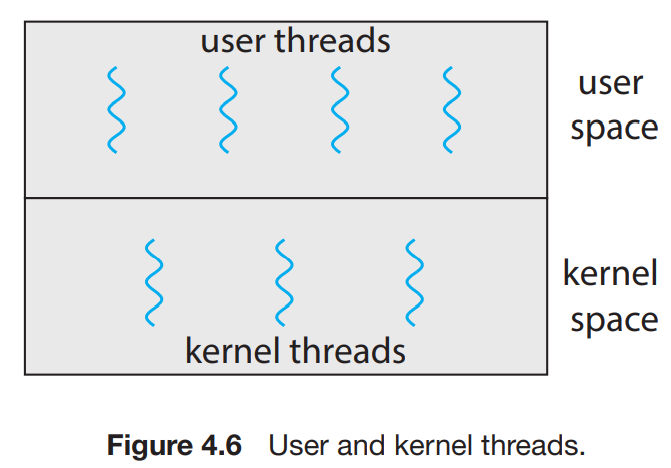
스레드는 user threads(사용자 스레드)나 kernel threads(커널 스레드)로 제공된다. 많은 user threads들이 1개의 kernel thread에 연결되어 있다. kernel 스레들 1개당 연결된 user thread를 수행. 엄밀히 말하자면, OS의 입장에서 user thread는 thread가 아니라고...
- User thread : 커널의 도움 없이(syscall필요 x) 커널의 윗부분(User library)을 지원한다. 비교적 빠르고 효율적이나, 스레드 1개에 block이 생기면 모든 스레드가 block된다. OS는 커널 스레드 기준으로 할당을 받기 때문에, 병렬적으로 안돌아 갈수도 있다.
- kernel thread : OS에 직접적으로 지원 관리된다. syscall에 생성/관리가 이뤄진다. 각각의 스레드는 TCB를 필요로 한다. 여러 스레드를 멀티 코어에 돌릴 수 있다.
아래와 같이 user, kernel 스레드 간의 관계가 존재한다. 이 섹션서는 가장 흔한 3가지 관계를 살펴볼 것.
4.3.1 Many-to-One Model
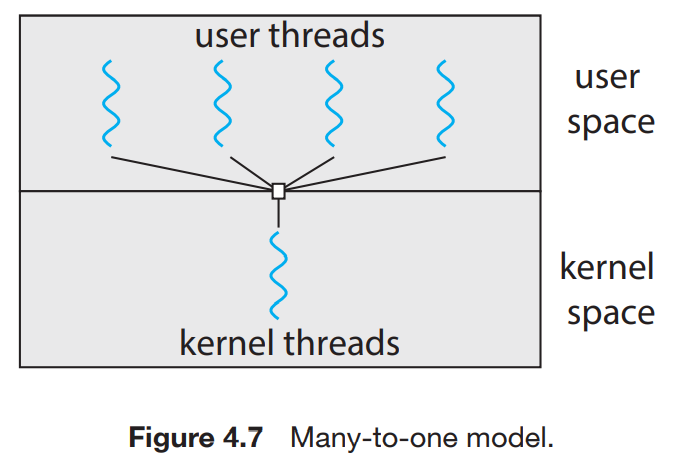
사용자 스레드들이 하나의 커널 스레드와 연결되어 있는 구조다. user space에서 스레드 관리가 일어나서 효율적이다. 하지만 만약 스레드 하나가 block(ex. I/O syscall -> wait)되면 프로세세스 전체가 block이 된다는 단점이 생긴다. 사용자 스레드 1개만 커널에 접근이 가능하므로, 다중 스레드들이 멀티코어 시스템서 병렬적으로 작동하기는 불가능하다. 다중 프로세서를 사용하지 못하므로, 요즘은 잘 사용하지 않는다.
4.3.2 One-to-One Model
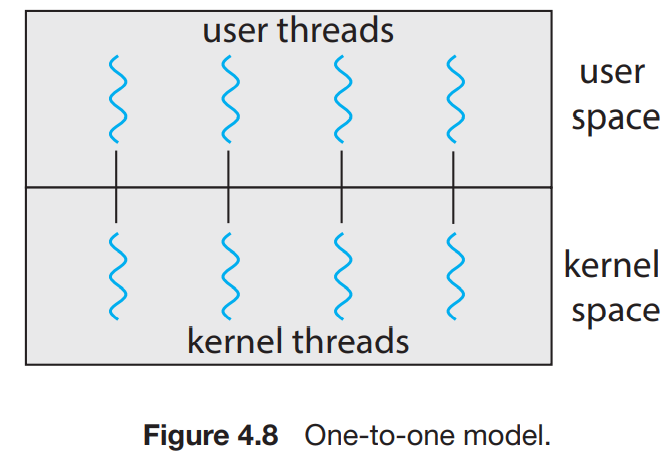
일대일 모델은 사용자 스레드별로 1개의 커널 스레드를 mapping한 구조다. 하나의 스레드가 block되어도 다른 스레드가 실행가능하여 concurrency가 many-to-one보다 높다. 또한 다중 프로세서에게 다중 스레드를 병렬적으로 실행이 가능하다. 이 방법의 유일한 단점으론, 사용자 스레드를 만들기 위해서는 대응되는 커널 스레드도 만들어야 하는데, 커널 스레드수가 많아질수록 시스셈의 성능이 떨어질수도 있다. 리눅스와 윈도우가 이 모델 사용.
4.3.3 Many-to-Many Model
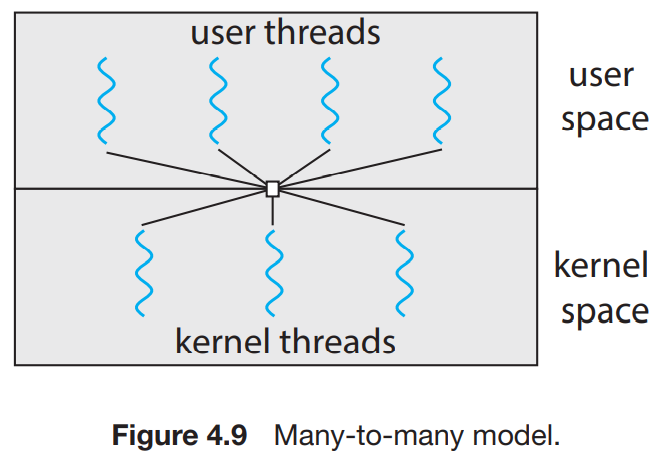
많은 사용자 스레드들은 그보다 적은 커널 스레드와 mapping하는 구조다. 커널 스레드의 갯수는 어플리케이션이나 기기에 따라 다르다. Many-to-One 구조서는, 커널이 한개의 thread밖에 schedule하지 못하므로 병렬화가 불가능하다. One-to-one에서는, concurrency가 증가하지만, 커널 스레드의 갯수를 관리해야한다. Many-to-Many구조서는 위의 2가지 방법들의 단점을 겪지 않아도 된다. 개발자들은 필요한 만큼 사용자 스레드를 만들어도 되며, 대응되는 커널 스레드들을 멀티 프로세서에서 병렬적으로 실행할 수 있다. 그리고 만약에 스레드가 block되면, 커널은 다른 스레드를 schedule하여 실행한다.

위와 같이 하이브리드로 연결되는 구조도 있다. Many-to-Many 구조는 효율적으로 보이지만, 구현하기 어렵다. 최근 멀티프로세서 시스템의 등장으로, 커널 스레드의 갯수를 제한하는 것이 더이상 중요해지지 않았다. 그래서 최근 OS들은 보통 one-to-one을 많이 사용.
4.4 Thread Libraries
스레드 라이브러리는 프로그래머들에게 스레드 생성/관리를 위한 API를 제공한다. 스레드 라이브러리를 구현하는 방법은 크게 2가지가 있다
- 모든 라이브러리를 user space안에 만들어서, 커널의 지원이 필요없게 하는 방법이 있다. 모든 코드와 데이터 구조들은 user space안에 존재해야 한다. 함수가 호출된다는 것은 user space안의 local함수를 부르는 것이지, syscall이 아니다.
- 직접적으로 OS를 통해 커널의 지원을 받게하는 방법도 있다. 모든 코드와 데이터구조는 커널 공간에 있으며, 보통 함수를 호출한다는 것은 syscall을 호출하는 것이다.
요즘 사용되는 스레드라이브러리는 크게 POSIX pthreads, Windows, Java가 있다.
4.4.1 Pthread
Pthread란 POSIX 표준(IEEE 1003.1c)에 해당하는 스레드 생성과 동기화에 관한 API 정의이다. 명세이지, 구현이 아니다. 보통 UNIX 계열의 OS에서 많이 사용된다.
Multithreaded C program using the Pthreads API
#include <pthread.h> #include <stdio.h> #include <stdlib.h> int sum; /* this data is shared by the thread(s) */ void *runner(void *param); /* threads call this function */ int main(int argc, char *argv[]) { pthread t tid; /* the thread identifier */ pthread attr t attr; /* set of thread attributes */ /* set the default attributes of the thread */ pthread attr init(&attr); /* create the thread */ pthread create(&tid, &attr, runner, argv[1]); /* wait for the thread to exit */ pthread join(tid,NULL); printf("sum = %d∖n",sum); } /* The thread will execute in this function */ void *runner(void *param) { int i, upper = atoi(param); sum = 0; for (i = 1; i <= upper; i++) sum += i; pthread exit(0); }
위의 코드를 통해 Pthread 라이브러리를 이용하여 스레드 생성 및 관리하는 것을 살펴보겠다.
- sum : 전역변수로서, 스레드들 간에 공유되는 데이터이다
- void *runner : 스레드가 실행할 함수이다.
main() 함수가 생성되면서 단일 스레드가 생성된다. 후에 runner함수가 시작될 때, 2번째 스레드가 생성되어 control을 갖는다. 두 스레드 모두 sum이라는 전역변수를 공유한다. 먼저 프로그램을 수행하기 위해서는 pthread.h 헤더파일을 포함해야 한다. pthread_t tid는 우리가 만들 스레드의 identfier이다. pthread_attr_t attr은 각각의 스레드별 특성들을 대표하는 것이다. 위에서는 pthread attr init(&attr)을 통해 default한 특성들을 set해준다. pthread_create함수를 통해 분리된 스레드가 생성이 된다. 이때 input으로, 스레디 id, 스레드 특성, 새로운 스레드가 실행될 함수의 이름(위의 코드는 runner), 마지막으로 integer parameter(argv[1])을 전달해준다.
위의 결과 프로그램은 2개의 스레드를 갖게 된다. main()을 통해 생성된 Initial(부모) 스레드와 runner()함수에서 sum연산을 수행하는 summation(child) 스레드가 있다. 위 프로그램은 create/join 전략을 따라서, summation 스레드를 먼저 생성한 이후에, 부모 스레드는 pthread_join()함수에 의해 summation 스레드가 없어질 때까지 기다릴 것이다. summation thread는 pthread_exit() 함수에 의해서 제거된다. summation thread가 반환되면, 부모 스레드는 공유한 data sum의 값을 반환할 것이다.
위의 예시는 스레드를 하나만 생성하였지만, 여러 스레드를 생성하는 것은 흔한 일이 되었다. pthread_join함수를 통해서 여러 스레드를 기다리는 방법은, 아래와 같이 간단히 구현할 수 있다.
Pthread code for joining ten threads.
#define NUM THREADS 10 /* an array of threads to be joined upon */ pthread t workers[NUM THREADS]; for (int i = 0; i < NUM THREADS; i++) pthread join(workers[i], NULL);
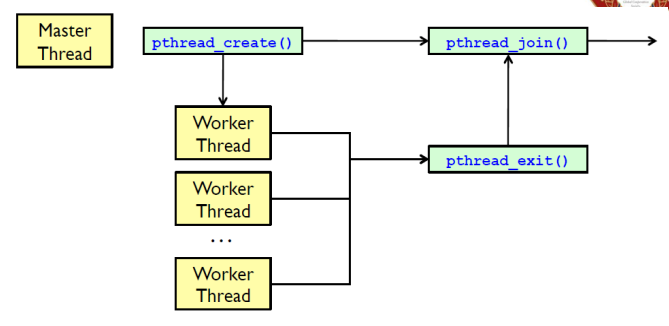
또한 pthread_join을 통해 동기화(synchronization)을 수행할 수 있다!
Summary
- 스레드는 cpu 사용의 기본 단위이며, 같은 프로세스 내의 스레드들은 resources(code, data등)을 공유한다
- 멀티 스레드의 장점으로는, responsiveness, resource sharing, economy, scalability가 있다
- Concurrency는 다중 스레드들이 진행되는 것을 의미하며(단일코어서도 가능), Parllelism은 다중 스레드들이 동시에 진행되는 것을 의미한다(다중코어가 필요). 보통 단일 코어서는 Concurrency는 가능하나, parellism은 불가하다
- 멀티 스레드 프로그래밍은 힘든 점이 있다
- Data parellelism은 데이터의 부분 집합들을 여러 코어에 분산하여 (동일)연산하는 것이며, Task parellelism은 데이터뿐만 아니라 task까지 분산할 수 있다. 각 task는 고유 연산이 있다.
- 사용자 어플리케이션은 사용자 스레드를 만들며, 이것은 CPU에서 실행되기 위해서 반드시 kernel 스레드와 mapping되어야 한다. many-to-one모델은 여러 사용자 스레드를 하나의 커널 스레드와 매핑. one-to-one, many-to-many 모델등이 존재한다.
- 스레드 라이브러리는 스레드 생성/관리를 위한 API를 제공한다. 흔히 3가지(pthread, window, Java)가 존재한다.
