지난 기록에서는 가상 머신(VM)의 기본 구조를 만들고, 직접 작성한 바이트코드를 실행하는 단계까지 진행했습니다. 하지만 진정한 인터프리터라면 사용자가 작성한 소스 코드를 직접 해독할 수 있는 능력이 필수적입니다.
이번 개발 기록에서는 스캐너(Scanner)를 구현한 과정을 공유하고자 합니다. 스캐너는 소스 코드라는 텍스트를 인터프리터가 이해할 수 있는 최소 단위인 토큰(Token)으로 분해하는, 언어 처리의 가장 기본적인 단계입니다.
스캐너의 역할
인터프리터가 "var a = 10;"과 같은 코드를 만났을 때, 이것을 단순한 텍스트가 아닌 var 키워드, a라는 이름, = 연산자, 10이라는 숫자, 그리고 ; 기호의 조합으로 인식하게 만드는 것이 바로 스캐너의 역할입니다.
이 스캐닝 단계를 거치면, 위 코드는 아래와 같은 토큰들의 흐름(Stream)으로 변환됩니다.
TOKEN_VAR TOKEN_IDENTIFIER TOKEN_EQUAL TOKEN_NUMBER TOKEN_SEMICOLON
이렇게 생성된 토큰 스트림은 인터프리터의 다음 단계인 파서(Parser)로 전달되어, 코드의 문법적 구조를 분석하는 데 사용됩니다.
Clox 스캐너 구현 과정
본격적으로 scanner.c와 scanner.h 파일에 스캐너를 구현한 과정을 단계별로 설명하겠습니다.
1. 토큰(Token)의 정의
가장 먼저 scanner.h 파일에 Lox 언어에 필요한 모든 종류의 토큰을 enum으로 정의했습니다. 한 글자로 된 괄호나 연산자부터, != 나 == 처럼 두 글자로 이루어진 토큰, 그리고 숫자, 문자열, 식별자 및 모든 키워드가 여기에 포함됩니다.
// scanner.h
typedef enum
{
// Single-character tokens.
TOKEN_LEFT_PAREN, TOKEN_RIGHT_PAREN,
// ...
// Keywords.
TOKEN_AND, TOKEN_CLASS, TOKEN_ELSE, TOKEN_FALSE,
// ...
TOKEN_ERROR, TOKEN_EOF
} TokenType;다음으로, 각 토큰이 담게 될 정보를 Token 구조체로 설계했습니다. 토큰의 종류(type)는 물론, 오류 메시지 출력이나 디버깅을 위해 소스 코드 내 위치를 알려주는 줄 번호(line) 정보도 필요합니다.
여기서 중요한 설계 결정은 토큰의 실제 텍스트, 즉 렉심(lexeme)을 처리하는 방식이었습니다. 렉심을 위해 매번 새로운 메모리를 할당하여 문자열을 복사하는 대신, 원본 소스 코드 문자열의 시작 위치를 가리키는 포인터(start)와 그 길이(length)만을 저장하기로 했습니다. C언어 환경에서는 이 방식이 불필요한 메모리 할당과 해제를 줄여주므로 훨씬 효율적이며 관리 또한 용이합니다.
// scanner.h
typedef struct
{
TokenType type;
const char* start;
int length;
int line;
} Token;2. 키워드와 식별자의 구분
스캐너 구현에서 가장 흥미로운 부분 중 하나는 키워드(var, if, for 등)와 일반 식별자(사용자가 정의한 변수 이름 등)를 구분하는 로직이었습니다. 예를 들어 'for'는 키워드이지만, 'forest'는 식별자로 처리되어야 합니다.
만약 단어가 'f'로 시작했다면, 두 번째 글자가 'a'인지('false'), 'o'인지('for'), 'u'인지('fun')를 다시 switch 문으로 확인하는 방식으로 탐색을 이어갑니다.
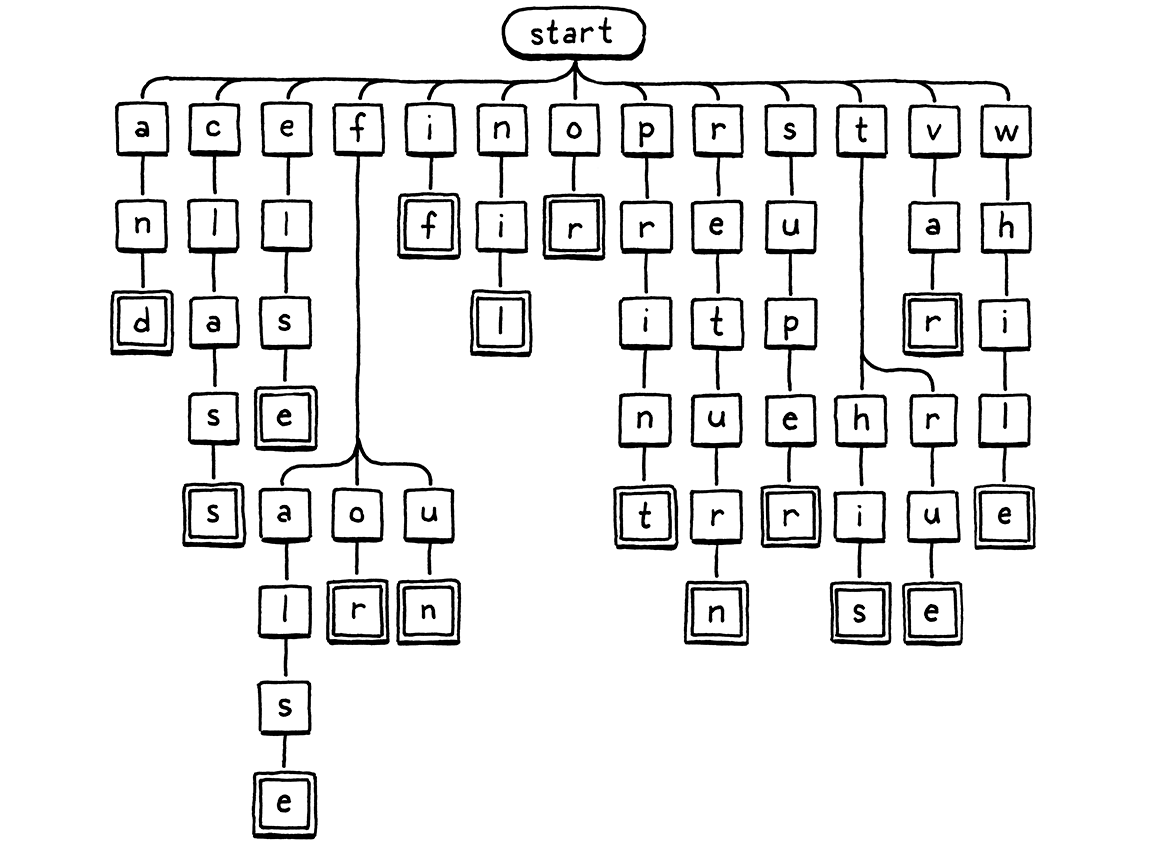
이미지 출처: Crafting Interpreters
이를 해결하기 위해 identifierType 함수 내에서 위 이미지와 같은 Trie(트라이) 자료구조와 유사한 아이디어를 적용했습니다.
static TokenType identifierType()
{
switch (scanner.start[0])
{
case 'a': return checkKeyword(1, 2, "nd", TOKEN_AND);
// ...
case 'f':
if (scanner.current - scanner.start > 1)
{
switch (scanner.start[1])
{
case 'a': return checkKeyword(2, 3, "lse", TOKEN_FALSE);
case 'o': return checkKeyword(2, 1, "r", TOKEN_FOR);
case 'u': return checkKeyword(2, 1, "n", TOKEN_FUN);
}
}
break;
// ...
case 'w': return checkKeyword(1, 4, "hile", TOKEN_WHILE);
}
return TOKEN_IDENTIFIER;
}3. scanToken() 함수
스캐너의 모든 동작은 scanner.c 파일에 정의된 scanToken() 함수를 중심으로 이루어집니다. 이 함수는 호출될 때마다 소스 코드에서 다음 토큰 하나를 정확히 인식하여 반환하는 역할을 수행합니다.
내부적으로는 다음과 같은 여러 도우미 함수들을 활용하여 코드를 한 글자씩 탐색합니다.
-
isAtEnd(): 소스 코드의 마지막에 도달했는지 검사합니다. -
advance(): 현재 문자를 반환하고 다음 문자로 포인터를 이동시킵니다.scanner.current++실행 후scanner.current[-1]을 반환하는 포인터 연산을 활용합니다. -
peek()&peekNext(): 포인터를 이동시키지 않고 현재 또는 바로 다음 문자를 확인합니다. -
match(char): 현재 문자가 특정 문자와 일치하는지 확인하고, 일치할 경우에만 포인터를 이동시킵니다. 이 함수 덕분에!=,==와 같이 한 글자 또는 두 글자로 구성될 수 있는 토큰들을 간결하게 처리할 수 있습니다.
scanToken 함수의 전체적인 로직은 advance()로 문자 하나를 읽어온 뒤 switch 문으로 분기하여, 해당 문자에 맞는 토큰을 생성(makeToken)하는 구조로 되어 있습니다.
// scanner.c
Token scanToken()
{
scanner.start = scanner.current;
if (isAtEnd()) return makeToken(TOKEN_EOF);
char c = advance();
if (isAlpha(c)) return identifier();
if (isDigit(c)) return number();
switch (c)
{
case '(': return makeToken(TOKEN_LEFT_PAREN);
// ...
case '!':
return makeToken(match('=') ? TOKEN_BANG_EQUAL : TOKEN_BANG);
// ...
case '"': return string();
}
return errorToken("Unexpected character.");
}먼저 identifier() 함수는 알파벳이나 밑줄(_)로 시작하는 단어를 발견하면, 알파벳이나 숫자가 끝날 때까지 모든 문자를 읽어들입니다.
그 후 identifierType() 함수가 호출되어, 스캔된 단어의 첫 글자를 기준으로 switch 문을 통해 분기합니다.
만약 단어가 'f'로 시작했다면, 두 번째 글자가 'a'인지('false'), 'o'인지('for'), 'u'인지('fun')를 다시 switch 문으로 확인하는 방식으로 탐색을 이어갑니다.
마지막으로 checkKeyword() 함수에서 단어의 전체 길이와 나머지 문자열의 내용이 정확히 일치하는지를 memcmp 함수를 통해 최종적으로 검사합니다. 이 모든 조건이 충족되면 해당 키워드 토큰 타입을 반환하고, 그렇지 않으면 일반 TOKEN_IDENTIFIER로 최종 판정합니다.
이러한 접근 방식은 수많은 문자열 비교 함수(strcmp)를 호출하는 것보다 훨씬 효율적으로 키워드를 판별할 수 있게 해줍니다.
마치며
이번 구현을 통해 clox 인터프리터는 소스 코드를 읽고 의미 있는 단위로 이해하는 첫 번째 단계를 완성했습니다. 인터프리터(컴파일러)가 키워드를 인식하는 방식으로 간단하지만 효율적인 방법인 Trie 자료구조를 활용하여 만들며 스캐너가 동작하는 원리를 파악하였습니다.
이제 스캐너가 잘게 나눈 토큰들이 준비되었습니다. 다음 단계는 이 토큰들을 조합하여 코드의 문법적인 구조를 파악하는 파서(Parser)를 구현하는 것입니다.
참고자료: Crafting Interpreters - Scanning on Demand
Github: Will-Big/clox
