개요
이전 챕터에서 clox는 문자열(ObjString)을 힙에 할당할 수 있게 되었습니다. 하지만 여기서 몇 가지 불편함이 생깁니다.
앞으로 변수를 구현하면, 변수 이름(문자열)으로 값을 저장하고 조회해야 합니다. 만약 변수들을 배열에 순서대로 넣어둔다면, 변수를 찾을 때마다 처음부터 끝까지 하나씩 비교해야 합니다. 변수가 100개면 최악의 경우 100번 비교 — O(n)입니다.
또 다른 문제는 문자열 비교입니다. "hello" == "hello"를 판단하려면 현재는 memcmp로 문자 하나하나를 비교해야 합니다. 문자열이 길수록 느려집니다.
이 두 문제를 한 번에 해결하는 자료구조가 해시 테이블입니다. key를 숫자로 변환해서 배열 인덱스로 직접 접근하면 평균 O(1)에 조회할 수 있고, 이 위에 string interning을 구현하면 문자열 비교도 포인터 비교 한 번으로 끝낼 수 있습니다.
해시 테이블의 기본 원리
해시 테이블의 핵심은 단순합니다. key를 숫자로 변환해서 배열의 인덱스로 사용하는 것입니다.
예를 들어 변수 이름이 a~z 하나뿐인 언어라면, 'c' - 'a' = 2로 바로 배열[2]에 접근할 수 있습니다.
현실에서는 key 공간이 훨씬 크기 때문에, 해시 함수로 얻은 값을 모듈로(%) 연산으로 배열 크기에 맞춥니다.
index = hash(key) % capacity여기서 중요한 개념이 load factor(적재율)입니다.
load factor = 엔트리 수 / 버킷 수load factor가 높으면 충돌이 잦아지고, 낮으면 메모리가 낭비됩니다. clox에서는 0.75를 임계값으로 사용하여, 이를 넘으면 배열을 확장합니다.
충돌 처리
서로 다른 key가 같은 인덱스에 매핑되는 것을 충돌(collision)이라 합니다.
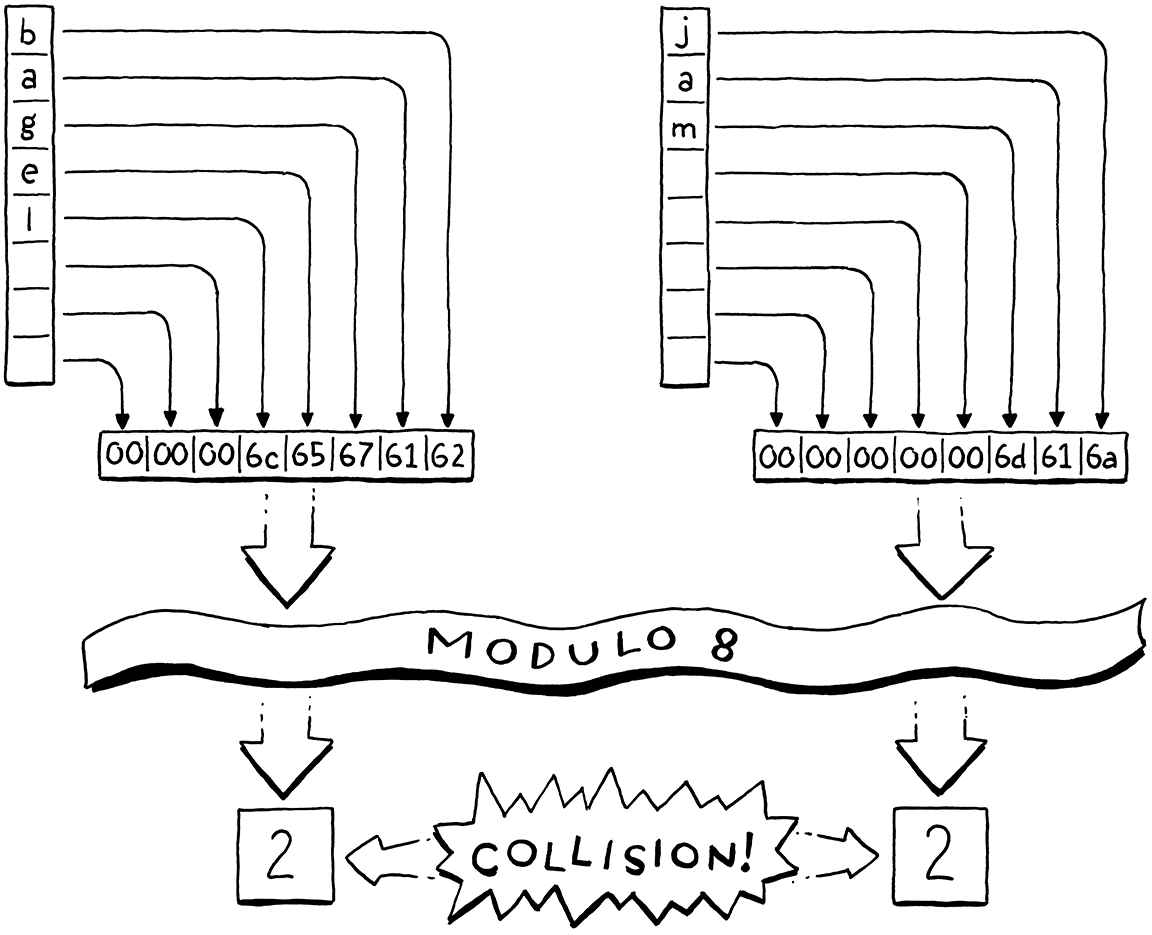
충돌을 처리하는 방식은 크게 두 가지입니다.
Separate Chaining
각 버킷이 연결 리스트를 가지는 방식입니다.
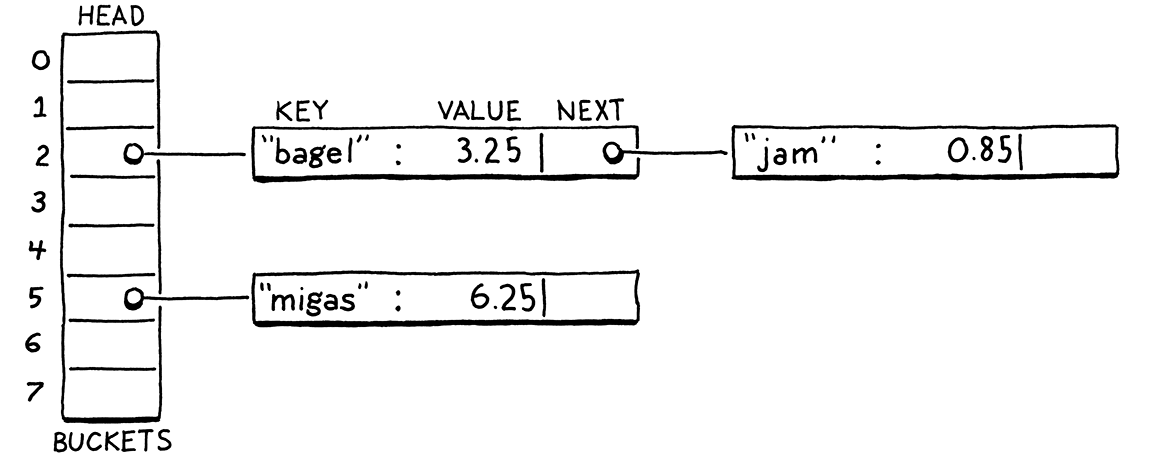
구현이 직관적이지만, 리스트 노드가 메모리에 흩어져서 캐시 효율이 떨어집니다.
Open Addressing
clox가 선택한 방식입니다.
모든 엔트리를 하나의 연속 배열에 저장합니다. 충돌이 나면 배열 안에서 다음 빈 칸을 찾습니다. 그 중 가장 단순한 방식이 linear probing — 다음 칸, 그 다음 칸 순서대로 확인하는 것입니다.
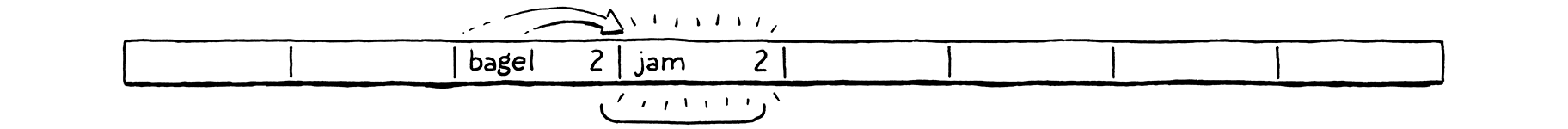
clox가 open addressing을 선택한 이유는 CPU 캐시 효율 때문입니다. 현대 CPU는 메모리를 캐시 라인(보통 64바이트) 단위로 가져옵니다. 연속 배열은 한 번에 여러 엔트리를 캐시에 올릴 수 있지만, 연결 리스트는 노드마다 포인터를 따라가야 하므로 캐시 미스가 잦아집니다.
탐색 원리
밀려난 엔트리를 어떻게 다시 찾는가?
open addressing에서 흥미로운 점은, 엔트리가 원래 위치에서 밀려났다는 정보를 따로 기록하지 않는다는 것입니다.
대신 삽입할 때와 같은 탐색 순서를 반복하면 반드시 찾을 수 있습니다. 해시값에서 시작해서 빈 칸을 만날 때까지 순서대로 확인하면, 있으면 반드시 만나고, 빈 칸을 만나면 "없다"고 판단할 수 있습니다.
"cake"를 찾을 때 (hash("cake") % cap = 2):
[2] "bagel" → 내가 찾는 key가 아님 → 다음
[3] "jam" → 아님 → 다음
[4] "cake" → 찾았다!tombstone — 삭제 후에도 탐색 체인 유지하기
그냥 비우면 왜 안 되는가?

엔트리를 그냥 비우면 탐색 체인이 끊어져서, 뒤에 밀려나 있는 엔트리를 찾을 수 없게 됩니다.
해결책은 tombstone(묘비)입니다. 삭제된 자리를 빈칸으로 만드는 대신, "여기는 삭제되었지만 탐색은 계속해라"라는 특수 표식을 남깁니다.

clox에서는 key = NULL, value = BOOL_VAL(true)로 표현합니다. 빈 칸(value가 NIL)과 tombstone(value가 NIL이 아님)을 구분하는 것이 핵심입니다.
bool tableDelete(Table* table, ObjString* key) {
if (table->count == 0) return false;
Entry* entry = findEntry(table->entries, table->capacity, key);
if (entry->key == NULL) return false;
// tombstone 배치: key를 비우고 value에 표식을 남긴다
entry->key = NULL;
entry->value = BOOL_VAL(true);
return true;
}tombstone은 배열을 리사이징(rehashing)할 때 자연스럽게 정리됩니다. 살아있는 엔트리만 새 배열에 옮기므로 tombstone은 사라집니다. 이런 방식을 지연 삭제라고 합니다.
해시 함수 — FNV-1a
좋은 해시 함수는 세 가지 조건을 만족해야 합니다.
- 결정성: 같은 입력이면 항상 같은 결과
- 균등성: 출력이 배열 전체에 골고루 분산
- 속도: 해시 테이블의 모든 연산이 해시 계산을 거치므로, 느리면 의미가 없음
clox는 FNV-1a 알고리즘을 사용합니다.
static uint32_t hashString(const char* key, int length) {
uint32_t hash = 2166136261u; // FNV offset basis
for (int i = 0; i < length; i++) {
hash ^= (uint8_t)key[i]; // XOR로 현재 바이트 반영
hash *= 16777619; // 곱셈으로 비트를 전체 범위에 확산
}
return hash;
}XOR은 입력 바이트의 비트 패턴을 해시값에 반영하고, 곱셈은 비트를 전체 범위로 퍼뜨려 균등 분산을 만듭니다. 이 두 연산의 조합이 중요합니다. XOR만 쓰면 "ab"와 "ba"의 해시가 같아지고(순서 구분 불가), 곱셈만 쓰면 비슷한 입력이 비슷한 출력을 만들어 분산이 나빠집니다.
문자열은 불변(immutable)이므로, 생성 시점에 해시를 한 번만 계산해서 ObjString 구조체의 hash 필드에 저장해둡니다. 이후 해시 테이블에서 사용할 때마다 재계산할 필요가 없습니다.
String Interning
같은 문자열은 메모리에 하나만 존재하게 합니다.
이번 챕터에서 가장 인상적이었던 부분입니다.
현재 구현에서 "hello"가 코드에 두 번 나오면 ObjString이 두 개 생깁니다. 주소가 다르니까 ==(포인터 비교)로는 같다고 판단할 수 없습니다.
String interning은 VM에 전역 문자열 테이블(vm.strings)을 두고, 새 문자열을 만들 때마다 이미 같은 문자열이 있는지 확인합니다.
ObjString* copyString(const char* chars, int length) {
uint32_t hash = hashString(chars, length);
// 이미 같은 문자열이 있으면 기존 객체를 반환
ObjString* interned = tableFindString(&vm.strings, chars, length, hash);
if (interned != NULL) return interned;
// 없으면 새로 만들고 테이블에 등록
char* heapChars = ALLOCATE(char, length + 1);
memcpy(heapChars, chars, length);
heapChars[length] = '\0';
return allocateString(heapChars, length, hash);
}이렇게 하면 같은 내용의 문자열은 항상 같은 포인터를 가지게 됩니다. 결과적으로 문자열 비교가 memcmp O(n)에서 포인터 비교 O(1)로 바뀝니다.
// interning 전: 문자열 내용을 하나씩 비교
case VAL_OBJ: {
ObjString* aString = AS_STRING(a);
ObjString* bString = AS_STRING(b);
return aString->length == bString->length &&
memcmp(aString->chars, bString->chars, aString->length) == 0;
}// interning 후: 포인터 비교 한 번
case VAL_OBJ: return AS_OBJ(a) == AS_OBJ(b);여기서 tableFindString()이 findEntry()와 다른 점이 있습니다. findEntry()는 포인터 비교(entry->key == key)를 하지만, tableFindString()은 length → hash → memcmp 순서로 문자열 내용을 비교합니다. interning이 완료되기 전에 호출되는 함수이므로, 같은 내용의 문자열이 다른 객체로 존재할 수 있기 때문입니다. 비용이 낮은 비교부터 해서 불일치를 빨리 걸러내는 설계입니다.
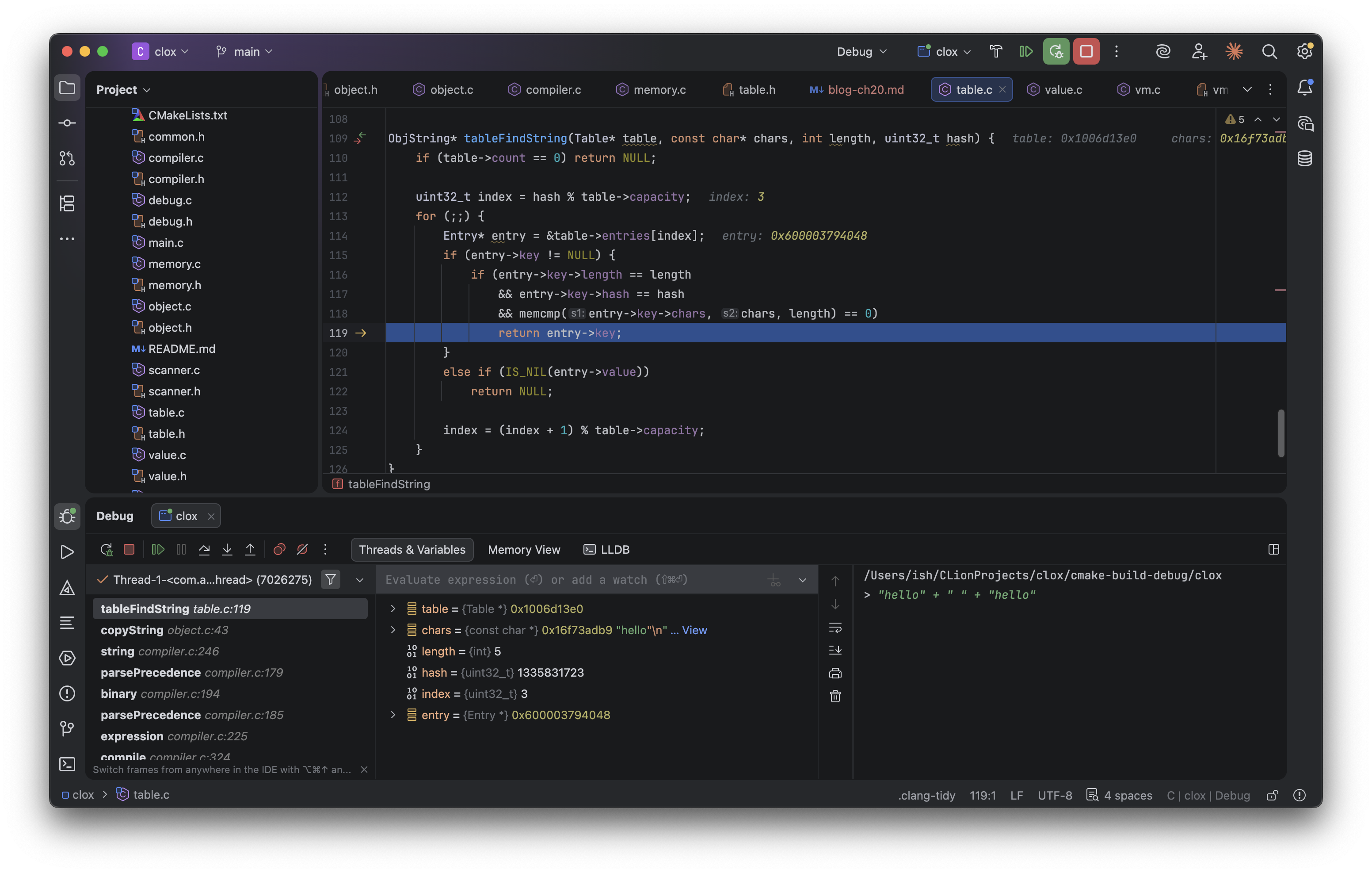
위 이미지는 "hello" + " " + "hello" 를 입력한 상태입니다. 두번째 "hello"를 연산할 때 tableFindString() 함수에서 테이블에 존재하는 "hello"문자열을 찾고 이를 반환하는 부분을 보여줍니다.
마치며
해시 테이블은 자주 등장하는 자료구조 중 하나입니다. 하지만 "O(1)로 찾을 수 있다"는 결론만 알고, 그 안에서 충돌 처리, load factor 관리, 캐시 효율을 위한 설계 선택이 어떻게 이루어지는지는 직접 구현해보지 않으면 알기 어렵습니다.
특히 string interning은 이번 챕터에서 가장 큰 수확이었습니다. 평소 언리얼 엔진의 FName이 왜 빠른지 개념적으로만 이해하고 있었는데, 직접 해시 테이블을 만들고 그 위에 interning을 구현해보니 "같은 문자열 → 같은 포인터 → 비교가 O(1)"이라는 흐름이 구체적으로 와닿았습니다. FName은 모든 이름 문자열을 글로벌 테이블에 interning해서, FName("Weapon") == FName("Weapon")이 문자열 비교가 아닌 정수 비교로 동작합니다. 게임처럼 매 프레임 이름을 비교해야 하는 상황에서 큰 성능 차이를 만드는 기법이라는 것을 직접 구현해보면서 체감할 수 있었습니다.
언리얼의 TMap이 open addressing을 사용하는 이유도, 캐시 효율이라는 맥락에서 이해할 수 있게 되었습니다.
open addressing에서 "밀려난 엔트리를 어떻게 다시 찾는가?"라는 의문이 있었는데, 답은 "기록하지 않는다 — 삽입 때와 같은 순서로 탐색하면 보장된다"였습니다. 이 단순하면서도 우아한 원리가 tombstone이라는 장치와 맞물려 완성되는 과정이 인상적이었습니다.
이미지 출처 및 참고: Crafting Interpreters - Chapter 20: Hash Tables
GitHub: Will-Big/clox
