서론
프로젝트 진행중 cross join문제가있어 해결하던중 join의 동작방식이나 자주 사용하지 않았던 join방식에 대해서도 정확히 알필요가 있다고 느껴 여기대 대해 얘기해보려 한다.
본론
join?
-
SQL 명령문에 의해서 여러 테이블에 저장된 데이터를 한번에 조회할 수 있게 하는 DBMS의 기능
-
두 집합 간의 곱으로 데이터를 연결하는 가장 대표적인 데이터 연결법
JOIN 알고리즘(3가지)
-
Nested Loop JOIN - 중첩반복
-
Sort Merge JOIN - 정렬병합
-
Hash JOIN - 해시매치
JOIN의 종류 -> 논리적 JOIN
JOIN의 방식 -> 물리적 JOIN
로우가 많아 질수록 쿼리의 코스트(Cost)는 높아진다. 당현히 처리할 데이터가 많기 때문이다.
이렇게 모두 비례적으로 성능의 떨어지지만 떨어지는 정도에는 차이가 있다.
우선 Loop가 가장 기본적인 방법이며, 양이 적을 때에는 성능이 좋지만 데이터가 많아질 수록 비용도 급격히 증가한다.
Merge 방식은 데이터가 적을 경우에는 Loop 보다는 못하지만, 양이 많아 질 수록 더 뛰어난 성능을 보인다. (여러 조건들이 있음)
Hash 방식은 데이터가 얼마 없을 경우에는 그 오버헤드(Overhead)로 인하여 성능이 좋지 않지만, 데이터가 많을수록 Loop 보다는 낮고 Merge 보다는 못하게 비용이 증가한다.
물리적 JOIN
1. Nested Loops JOIN (중첩 반복 조인)
Nested Loop Join의 방식은 두개의 테이블의 행을 각각 모두 확인하여 조인하는 방법으로 표현하자면 중첩된 for문이다.
nner와 outer loop이 있듯이 조인에는 dirving과 driven 테이블이 있습니다. 실행계획에서 먼저 실행되는 테이블이 driving 테이블이고 나중에 실행되는 것이 driven 테이블입니다. 중첩된 for 문이라고 표현한 이유는 각각 테이블을 모두 읽고 확인하는 것이아니라 각 행별로 확인하기 때문에 행이 적은 테이블을 driving 테이블로 선정하는 것이 빠른결과를 얻을 수 있는 방법입니다. 또한 조인 컬럼에 인덱스가 있어야 테이블 전체를 탐색하지 않고 필요한 행에대해서만 탐색하여 효율적입니다.
-
바깥 테이블의 처리 범위를 하나씩 엑세스하면서 그 추출된 값으로 안쪽 테이블을 JOIN하는 방식
1) 순차적으로 처리된다.
2) 바깥 테이블과 일치하는 값을 안쪽 테이블에서 찾아야 하므로 안쪽 테이블의 해당 열에 인덱스가 필요
3) 메모리 사용량은 가장 적다
4) 랜덤 엑세스 위주의 조인 방식(대량 데이터 처리시 매우 치명적인 한계)
5) 마지막으로 다른 조인방식과 비교할 때 인덱스 구성 전략이 특히 중요함
성능을 높이기 위한 방법
가) 후행테이블의 크기가 작을수록
나) 요소들의 비교가 빠르게 이루어 지도록 인덱스가 미리 설정되어 있어야 한다.
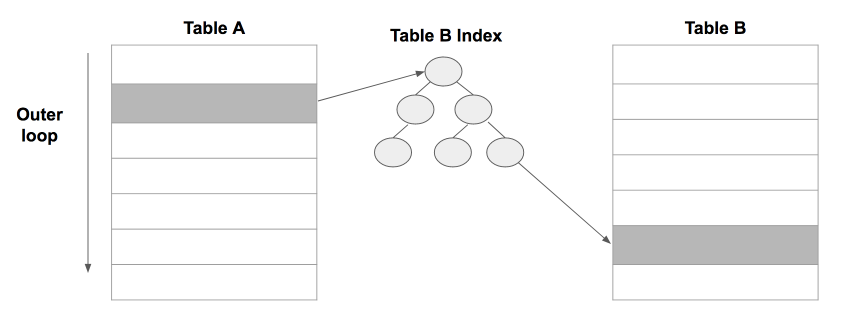
- 선행테이블(Driving Table) : 찾는 주체가 되는 테이블
- 후행테이블(Driven Table) : 비교 대상이 되는 테이블
즉, Row가 적은 Driving Table + Inner Table의 조인키에는 인덱스
양쪽 테이블의 처리 범위를 각자 액세스하여 정렬한 결과를 차례로 스캔하며, 연결고리 조건으로 Merge하는 방식을 말합니다.
-
이 방식은 경우에 따라 Loop Join 보다 훨씬 빨라지는 경우도 많이 있으며, 랜덤 액세스가 줄어들어 시스템 부하를 감소 시킵니다.
-
하지만 일반적으로 Loop Join보다는 사용빈도가 적습니다.
2. Sort Merge (정렬병합 조인)
-
양쪽 테이블의 처리 범위를 각자 액세스하여 정렬한 결과를 차례로 스캔하며, 연결고리 조건으로 Merge하는 방식을 말합니다.
-
이 방식은 경우에 따라 Loop Join 보다 훨씬 빨라지는 경우도 많이 있으며, 랜덤 액세스가 줄어들어 시스템 부하를 감소 시킵니다.
-
하지만 일반적으로 Loop Join보다는 사용빈도가 적습니다.
동시적 처리
각 키에 의해 정렬된 양쪽 행들을 순차적으로 병합하여 조인을 수행합니다.
인덱스가 필요
양 테이블의 모두 조인키에 의해 정렬되어있어야 합니다.
전체 범위 처리
선행 테이블, 후행 테이블 크기는 성능과 관련이 없습니다.
그러나 선행 테이블에 중복행이 존재하지 않을때 메모리 사용량이 적으며 권장하고 있습니다.
부분 범위처리를 할 수가 없으며 항상 전체 범위를 처리합니다.
스캔방식
주로 스캔방식으로 처리합니다.
자신의 처리범위를 줄이기 위해 인덱스를 사용하는 경우만 랜덤 액세스이며 나머지작업은 스캔방식입니다.
조인의 방향과는 무관
테이블 스캔 수는 한번
장점
-
처리량이 많을 때 성능상 이점이 있다.
-
중첩반복(Nested Loops)은 연결고리의 상태가 굉장히 중요하다. 한쪽 연결고리에 이상이 발생하면 중첩반복은 심히 고려해야한다. 이때 연결고리에 영향을 받지않는 Sort Merge를 쓰면 좋다.
단점
-
정렬에 따른 부담 (메모리 사용 증가)
-
정렬은 tempdb를 사용한다. 정렬양이 극도로 많아 tempdb의 임계치를 넘었을때 순간 전체 데이터베이스에 페이지잠금이 발생하는등 DB성능에 심각한 영향을 줄 수 있다.
-
물론 가공없이 Clustered Index를 그대로 사용하게 되면 정렬은 안해도 되니 이때만큼은 정렬의 부담에서 해방된다.
3. hash (정렬병합 조인)
-
조인할 테이블에 대해서 해시 버킷을 생성하고 (이를 빌드입력이라한다) 해시 버킷의 순서대로 결과가 출력된다.
따라서 테이블의 인덱스는 사용되지 않으며, 인덱스가 없거나 임의성 쿼리에 탁월한 성능을 발휘한다. -
적은 행에 대해 인덱스가 있는 테이블에 대해서는 중첩루프조인이 사용될 가능성이 높다.
-
하지만 용량이 커지고 행수가 많아지면 중첩 루프 조인은 행수 만큼의 테이블 스캔이 발생하므로 매우 느린 방법이다. 이때 해시 조인이 발생한다.
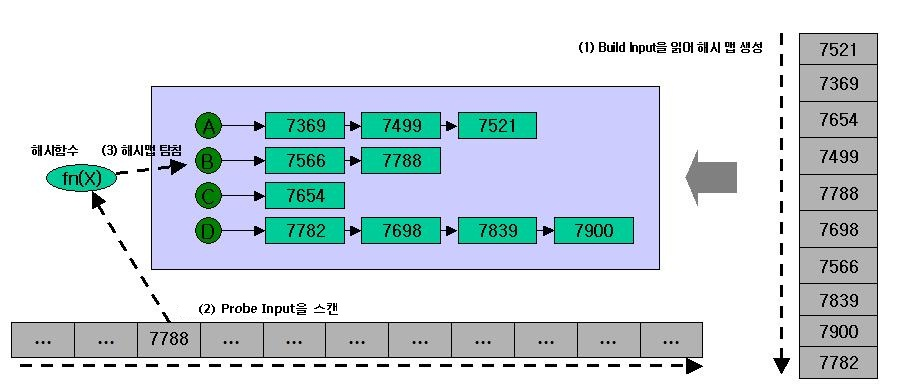
연결고리
각 테이블의 연결고리의 인덱스는 사용하지 않는다!
대신 테이블에 대한 해시 버킷을 생성하며 그것을 통해 조인을 한다. 물론 조인이 되면 삭제된다. 그래서 반복적으로 명령을 수행할경우 매번 새로 생성합니다.
조인 결과
조인의 결과는 정렬하지 않는 상태로 출력된다. 그래서 특정 컬럼으로 정렬을 하고 싶다면 ORDER BY 절을 이용해야 합니다.
랜덤 액세스
랜덤 액세스가 있으나 중첩조인과는 달리 빠른 랜덤 액세스입니다.
메모리 사용
해시 버킷을 만들기 때문에 많은 메모리를 사용합니다.
논리적 JOIN
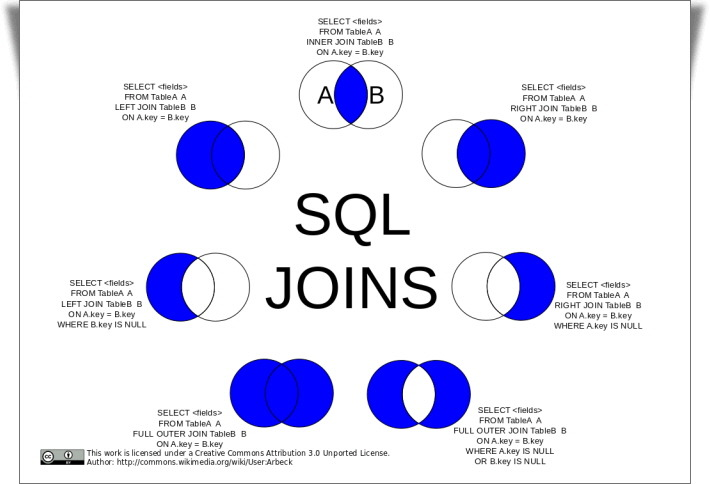
JOIN (INNER JOIN)
일반적으로 "조인"이라 함은 INNER JOIN을 지칭하는데, 별도로 아우터 조인과 구분할 때 "이너 조인(INNER JOIN)"이라 한다. MySQL에서 조인은 네스티드-루프 방식만 지원하며(최근 hash join을 지원) 네스티드-루프란 일반적으로 프로그램을 작성할 때 두 개의 FOR나 WHILE과 같은 반복 루프 문장을 실행하는 형태로 조인이 처리되는 것을 의미한다.
FOR ( record1 IN TABLE1 ) { // 외부 루프 (OUTER)
FOR ( record2 IN TABLE2 ) { // 내부 루프 (INNER)
IF ( record1.join_column == record2.join_column ) {
join_record_found(record1.*, record2.*);
} ELSE {
join_record_notfound();
}
}
}중첩된 반복 루프에서 최종적으로 선택될 레코드가 안쪽 반복 루프 (INNER 테이블)에 의해 결정되는 경우를 INNER JOIN이라고 한다. 즉, 두 개의 반복 루프를 실행하면서 TABLE2(INNER 테이블)에 "IF(record1.join_column == record2.join_column)" 조건을 만족하는 레코드만 조인의 결과로 가져옴.
OUTER JOIN
INNER JOIN에서 살펴본 의사 코드를 조금만 수정해서 살펴보겠습니다.
FOR ( record1 IN TABLE1 ) { // 외부 루프 (OUTER)
FOR ( record2 IN TABLE2 ) { // 내부 루프 (INNER)
IF ( record1.join_column == record2.join_column ) {
join_record_found(record1.*, record2.*);
} ELSE {
join_record_found(record1.*, NULL);
}
}
}위 코드에서 TABLE2에 일치하는 레코드가 있으면 INNER 조인과 같은 결과를 만들어내지만, TABLE2(INNER 테이블)에 조건을 만족하는 레코드가 없는 경우에는 TABLE2의 칼럼을 모두 NULL로 채워서 가져옵니다. 즉, INNER JOIN에서는 일치하는 레코드를 찾지 못했을 때는 TABLE1의 결과를 모두 버리지만 OUTER JOIN에서는 TABLE1의 결과를 버리지 않고 그대로 결과에 포함합니다.
INNER 테이블이 조인의 결과에 전혀 영향을 미치지 않고, OUTER 테이블의 내용에 따라 조인의 결과가 결정되는 것이 OUTER JOIN의 특징입니다.
물론 OUTER 테이블과 INNER 테이블의 관계(대표적으로 1:M 관계일 때)에 의해 최종 결과 레코드 건수가 늘어날 수는 있지만, OUTER 테이블의 레코드가 INNER 테이블에 일치하는 레코드가 없다고 해서 버려지지는 않습니다.
참고: https://enterone.tistory.com/234 [Lifelong Study]
