NoSQL
개요
최근 데이터베이스를 사용함에 있어 데이터량이 늘어나 캐쉬 서버가 있었으면 좋겠다는 생각을하고 redis에 대해 공부하다 NoSql에 정리의 필요성이 있어 한번 찾아보았다
정의
관계형 데이터 모델을 지양 하며 대량의 분산된 데이터를 저장하고 조회하는 데 특화되었으며 스키마 없이 사용 가능하거나 느슨한 스키마를 제공하는 저장소를 말한다.
종류마다 쓰기/읽기 성능 특화, 2 차 인덱스 지원, 오토 샤딩 지원 같은 고유한 특징을 가진다. 대량의 데이터를 빠르게 처리하기 위해 메모리에 임시 저장하고 응답하는 등의 방법을 사용한다. 동적인 스케일 아웃을 지원하기도 하며, 가용성을 위하여 데이터 복제 등의 방법으로 관계형 데이터베이스가 제공하지 못하는 성능과 특징을 제공한다.
CAP 이론
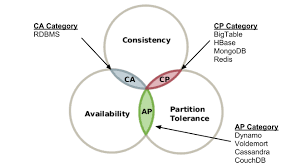
-
CAP 정리에 의하면 시스템은 일관성(Consistency), 가용성(Availablity), 분단 허용성(Partition torlerance) 세 가지 속성중에서, 두 가지만 가질 수 있다는 것이다.
-
위의 그림에서 볼 수 있듯이, Consistency, Availablity를 합치면, CA 또는 Consistency와 Partition tolerance를 조합하면 AP가 된다.
-
이 모든 속성을 다 포함한 시스템은 절대로 존재할 수 없다는 것이 CAP 정리이다.
관계형 데이터베이스는 CA 시스템이다. 일관성(C)와 가용성(A)를 보장하되, 분단 허용성(P)는 보장하지 않는다
대부분의 NoSQL 데이터베이스는 CA가 아닌 CP나 AP 시스템이다. 대용량의 분산 시스템을 구축하는데에는 CP보다도 AP가 알맞다. C가 들어가서 강력한 일관성 즉, ACID 트랜잭션을 지원한다고 가정하면 예를 들어 하나의 쓰기 작업을 수행한다고 가정할 때 2대가 정상 응답할 때까지 LOCK이 걸리겠지만 100대라면 너무 긴 시간동안 LOCK이 걸리게 된다.
1. 일관성(Consistency)
일관성은 동시성 또는 동일성이라고도 하며 다중 클라이언트에서 같은 시간에 조회하는 데이터는 항상 동일한 데이터임을 보증하는 것을 의미한다. 이것은 관계형 데이터베이스가 지원하는 가장 기본적인 기능이지만 일관성을 지원하지 않는 NoSQL 을 사용한다면 데이터의 일관성이 느슨하게 처리되어 동일한 데이터가 나타나지 않을 수 있다. 느슨하게 처리된다는 것은 데이터의 변경을 시간의 흐름에 따라 여러 노드에 전파하는 것을 말한다. 이러한 방법을 최종적으로 일관성이 유지된다고 하여 최종 일관성 또는 궁극적 일관성을 지원한다고 한다.
각 NoSQL 들은 분산 노드 간의 데이터 동기화를 위해서 두 가지 방법을 사용한다.
첫번째로 데이터의 저장 결과를 클라이언트로 응답하기 전에 모든 노드에 데이터를 저장하는 동기식 방법이 있다. 그만큼 느린 응답시간을 보이지만 데이터의 정합성을 보장한다.
두번째로 메모리나 임시 파일에 기록하고 클라이언트에 먼저 응답한 다음, 특정 이벤트 또는 프로세스를 사용하여 노드로 데이터를 동기화하는 비동기식 방법이 있다. 빠른 응답시간을 보인다는 장점이 있지만, 쓰기 노드에 장애가 발생하였을 경우 데이터가 손실될 수 있다.
2. 가용성(Availability)
가용성이란 모든 클라이언트의 읽기와 쓰기 요청에 대하여 항상 응답이 가능해야 함을 보증하는 것이며 내고장성이라고도 한다. 내고장성을 가진 NoSQL 은 클러스터 내에서 몇 개의 노드가 망가지더라도 정상적인 서비스가 가능하다.
몇몇 NoSQL 은 가용성을 보장하기 위해 데이터 복제(Replication)을 사용한다. 동일한 데이터를 다중 노드에 중복 저장하여 그 중 몇 대의 노드가 고장나도 데이터가 유실되지 않도록 하는 방법이다. 데이터 중복 저장 방법에는 동일한 데이터를 가진 저장소를 하나 더 생성하는 Master-Slave 복제 방법과 데이터 단위로 중복 저장하는 Peer-to-Peer 복제 방법이 있다.
3. 네트워크 분할 허용성(Partition tolerance)
분할 허용성이란 지역적으로 분할된 네트워크 환경에서 동작하는 시스템에서 두 지역 간의 네트워크가 단절되거나 네트워크 데이터의 유실이 일어나더라도 각 지역 내의 시스템은 정상적으로 동작해야 함을 의미한다.
저장 방식에 따른 NoSQL 분류
Key-Value Model, Document Model, Column Model, Graph Model로 분류할 수 있다.
1. Key-Value Model
가장 기본적인 형태의 NoSQL 이며 키 하나로 데이터 하나를 저장하고 조회할 수 있는 단일 키-값 구조를 갖는다. 단순한 저장구조로 인하여 복잡한 조회 연산을 지원하지 않는다. 또한 고속 읽기와 쓰기에 최적화된 경우가 많다. 사용자의 프로필 정보, 웹 서버 클러스터를 위한 세션 정보, 장바구니 정보, URL 단축 정보 저장 등에 사용한다. 하나의 서비스 요청에 다수의 데이터 조회 및 수정 연산이 발생하면 트랜잭션 처리가 불가능하여 데이터 정합성을 보장할 수 없다.
ex) Redis
2. Document Model
키-값 모델을 개념적으로 확장한 구조로 하나의 키에 하나의 구조화된 문서를 저장하고 조회한다. 논리적인 데이터 저장과 조회 방법이 관계형 데이터베이스와 유사하다. 키는 문서에 대한 ID 로 표현된다. 또한 저장된 문서를 컬렉션으로 관리하며 문서 저장과 동시에 문서 ID 에 대한 인덱스를 생성한다. 문서 ID 에 대한 인덱스를 사용하여 O(1) 시간 안에 문서를 조회할 수 있다.
대부분의 문서 모델 NoSQL 은 B 트리 인덱스를 사용하여 2 차 인덱스를 생성한다. B 트리는 크기가 커지면 커질수록 새로운 데이터를 입력하거나 삭제할 때 성능이 떨어지게 된다. 그렇기 때문에 읽기와 쓰기의 비율이 7:3 정도일 때 가장 좋은 성능을 보인다. 중앙 집중식 로그 저장, 타임라인 저장, 통계 정보 저장 등에 사용된다.
ex) MongoDB
3. Column Model
하나의 키에 여러 개의 컬럼 이름과 컬럼 값의 쌍으로 이루어진 데이터를 저장하고 조회한다. 모든 컬럼은 항상 타임 스탬프 값과 함께 저장된다.
구글의 빅테이블이 대표적인 예로 차후 컬럼형 NoSQL 은 빅테이블의 영향을 받았다. 이러한 이유로 Row key, Column Key, Column Family 같은 빅테이블 개념이 공통적으로 사용된다. 저장의 기본 단위는 컬럼으로 컬럼은 컬럼 이름과 컬럼 값, 타임스탬프로 구성된다. 이러한 컬럼들의 집합이 로우(Row)이며, 로우키(Row key)는 각 로우를 유일하게 식별하는 값이다. 이러한 로우들의 집합은 키 스페이스(Key Space)가 된다.
대부분의 컬럼 모델 NoSQL 은 쓰기와 읽기 중에 쓰기에 더 특화되어 있다. 데이터를 먼저 커밋로그와 메모리에 저장한 후 응답하기 때문에 빠른 응답속도를 제공한다. 그렇기 때문에 읽기 연산 대비 쓰기 연산이 많은 서비스나 빠른 시간 안에 대량의 데이터를 입력하고 조회하는 서비스를 구현할 때 가장 좋은 성능을 보인다. 채팅 내용 저장, 실시간 분석을 위한 데이터 저장소 등의 서비스 구현에 적합하다.
관계형 DB vs NoSql
관계형 DB
특징
-
트랜잭션(전부 아니면 무): 전체 트랜잭션이 하나의 단위로 기록. 실패 시 전체 롤백
-
정규화: DB설계 시 중복을 최소화해서 구조화하는 프로세스
장점
-
데이터의 성능이 일반적으로 좋아 정렬, 탐색, 분류가 빠름
-
신뢰성이 높아 데이터의 무결성을 보장
-
정규화에 따른 갱신 비용을 최소화
단점
-
기존에 작성된 스키마를 수정하기 어려움
-
데이터베이스의 부하를 분석하기 어려움
-
빅데이터를 처리하는데 매우 비효율적임.
비관계형 DB
NoSQL이라고도 부르며, Not Only SQL(SQL 뿐만이 아닌. 이라는 뜻)의 줄임말이라고 합니다.
이 말은 곧 SQL뿐만 아니라 다른 여러 장점을 가지고 있다는 소리입니다.
기존의 관계형 데이터베이스의 한계를 뛰어넘기 위해 만들어진 새로운 형태의 데이터베이스라서,
관계형 데이터베이스보다 더 융통성 있는 데이터 모델을 사용하며, 데이터의 저장 및 검색에 특화된 메커니즘을
제공합니다. NoSQL은 분산 환경에서의 데이터 처리를 더욱 빠르게 하기 위해 개발되었습니다.
대표적으로 MongoDB, CouchDB 등이 있습니다.
특징
-
거대한 Map으로서 key-value 형식을 지원함.
-
관계형 db와 달리 PK,FK JOIN등 관계를 정의하지 않음.
-
스키마에 대한 정의가 없다.
장점
-
대용량 데이터 처리를 하는데 효율적임.
-
읽기 작업보다 쓰기 작업이 더 빠르고 관계형 데이터베이스에 비해 쓰기와 읽기 성능이 빠름.
-
데이터 모델링이 유연함.
-
뛰어난 확장성으로 검색에 유리함.
-
최적화된 키 값 저장 기법을 사용하여 응답속도나 처리효율 등에서 성능이 뛰어남.
-
복잡한 데이터 구조를 표현할 수 있음.
단점
- 쿼리 처리시 데이터를 파싱 후 연산을 해야해서 큰 크기의 document를 다룰 때는 성능이 저하됨.
