데이터베이스
1.인덱스란
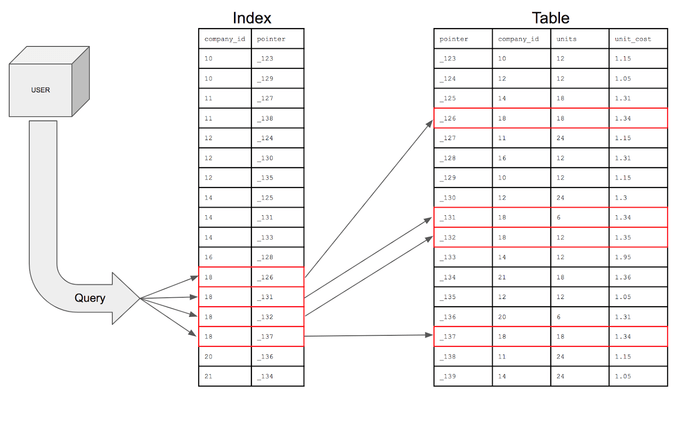
인덱스(index)란? 인덱스란 추가적인 쓰기 작업과 저장 공간을 활용하여 데이터베이스 테이블의 검색 속도를 향상시키기 위한 자료구조이다. 만약 우리가 책에서 원하는 내용을 찾는다고 하면, 책의 모든 페이지를 찾아 보는것은 오랜 시간이 걸린다. 그렇기 때문에 책의 저
2.인덱스 사용법

CREATE INDEX 인덱스명 ON 테이블명(컬럼1, 컬럼2, 컬럼3.......)SELECT \* FROM USER_INDEXES WHERE TABLE_NAME = 'CUSTOMERS';DROP INDEX 인덱스 명인덱스를 리빌드하는 이유인덱스 파일은 생성 후 in
3.Join의 동작
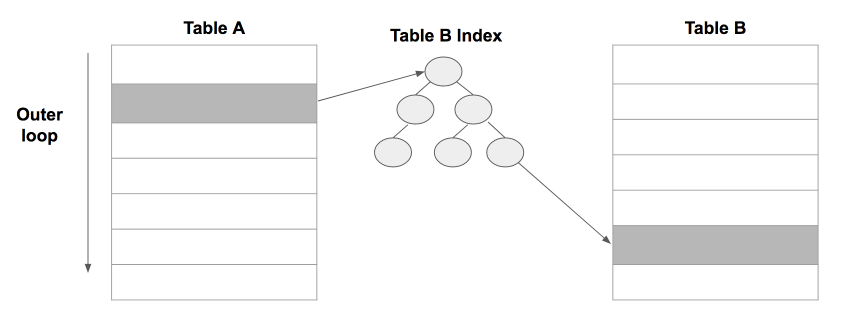
서론 프로젝트 진행중 cross join문제가있어 해결하던중 join의 동작방식이나 자주 사용하지 않았던 join방식에 대해서도 정확히 알필요가 있다고 느껴 여기대 대해 얘기해보려 한다. 본론 join? SQL 명령문에 의해서 여러 테이블에 저장된 데이터를 한번
4.No Sql
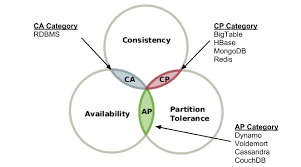
최근 데이터베이스를 사용함에 있어 데이터량이 늘어나 캐쉬 서버가 있었으면 좋겠다는 생각을하고 redis에 대해 공부하다 NoSql에 정리의 필요성이 있어 한번 찾아보았다관계형 데이터 모델을 지양 하며 대량의 분산된 데이터를 저장하고 조회하는 데 특화되었으며 스키마 없이
5.Redis
레디스 (Remote Dictionary Server)는 메모리 기반의 key-value 구조의 데이터 관리 시스템이다.모든 데이터를 메모리에 저장하고 조회하기때문에 빠른 Read, Write 속도를 보장하는 NoSql이다.속도가 빠른 이유 ?메모리 접근이 디스크 접근