이커머스 프로젝트 회고를 쓴 지 또 사흘밖에 안 된 것 같은데 벌써 2주가 지났다. 이번에도 같은 식으로 회고해보려 한다.
✅ 프로젝트 및 사용된 기술 소개
프론트엔드 2명과 백엔드 2명이 모여 진행된 프로젝트다. 기간은 2주였고 타깃 사이트는 채용 공고 사이트로, 기업은 채용 공고를 올리고, 지원자들은 이력서를 관리하고 해당 이력서를 가지고 지원할 수 있는 서비스를 제공하는 플랫폼이다. 시간상의 문제로 기업 쪽의 기능은 구현할 수 없었지만 지원자의 가입 및 이력서 관리, 지원까지의 기능들은 목표한 만큼 구현할 수 있었다.
-완성본-
채용 사이트 말고 다른 아이템을 찾아 기획을 수정하려고 했는데, 이커머스와는 달리 아이템이 바뀌면 기획 자체가 바뀌어서 포기하고 리쿠르팅 서비스를 그대로 진행했다.
Python을 기반으로 Django web fremework가 사용되었고 DB는 MySQL을 사용하였다. django ORM을 점점 더 많이 알게 되었는데, ORM이 어디까지 할 수 있는지 알게 되는 게 정말 재미있었다. 하드코딩할 때마다 검색해본 바로 SQL문 자체는 MySQL이 Oracle과 얼마나 어떻게 다른지 알아볼 수는 없었지만, 오히려 그래서 DB를 수정할 일이 생길 때 마음 편하게 update문을 작성하는 재미도 있었다.
✅ 역할
팀이 이전보다 작으니 회의 자체는 먼저 말을 꺼내는 등 진행을 조금 했지만 PM을 맡는 등 어떤 책임을 가지고 한다기보다 각자 맡은 일을 진행하면서 상의하는 것이 훨씬 수월했다. 팀원이 6명인 것과 4명인 것을 둘 다 경험해볼 수 있었던 것은 참 좋았던 것 같다.
✅ 내가 구현한 기능
이 이미지를 다시 보지 않을 수 없다. Agile! MVP! Scrum! Daily Meeting!
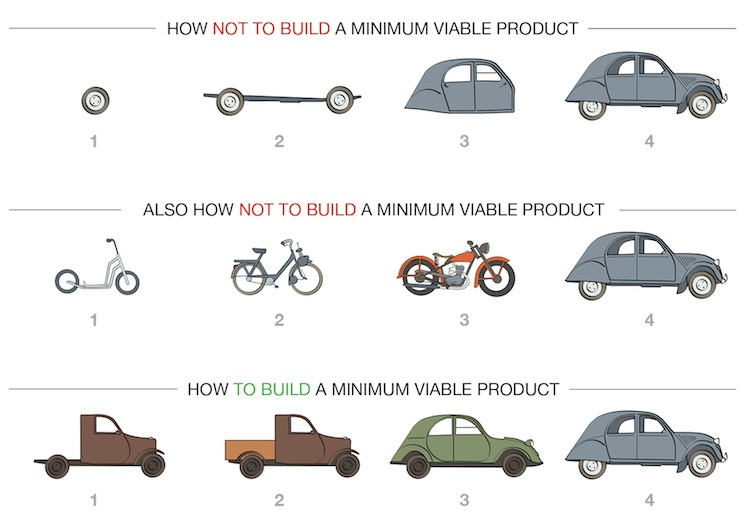
지난 프로젝트 회고록을 작성한 것을 한번씩 다시 읽어보면서, 이번에도 일단 굴러가게 만드는 것에 집중했다. 필요한 기능들은 전부 잊고, 일단 냅다 뿌리는 거다.
내가 구현한 부분안 카카오 소셜 로그인과 채용 공고 상세, 채용 공고 리스트다.
- 제일 기본적인 기능 구현
공고 리스트와 공고 상세는 동시에 진행하게 되었는데, 프론트 팀원들이 어떤 페이지에 어떤 데이터가 필요한지 미리 많은 논의를 거쳐 깔끔하게 정리해 주었기에 굉장히 편안하게 진행할 수 있었다. 리스트에는 이미지 중 .first()를 사용해 가장 먼저 나오는 이미지들을 썸네일에 사용할 수 있도록 했고, 상세에서는 이미지 여러 장을 함께 리턴했다.
카카오톡 소셜 로그인은 프론트에서 레이아웃을 만드는 동안에 진행할 수 없어서 그냥 처음부터 끝까지 백엔드에서 요청하고 받는 것으로 작성한 후 수정했다. 주고받는 데이터가 조금 달라진 것 외에는 특별히 달라진 부분 없이 완성했다. 다음에는 조금 더 섬세하고 상세한 api를 다양한 기능을 사용해 구현해보고 싶다.
- 리스트 관련 추가 데이터들과 ORM 최적화
리스트에 필요한 데이터들 중에는 공고를 올린 회사의 이름과 위치에 대한 것이 필요했는데, 여기서 조금 고민이 있었다.
- 위치
위치를 단순히 string으로 "경기 성남", "미국 캘리포니아" 등으로 작성한 터라 위치 필터링을 넣기가 좋지 않았다. 고민하다가 프론트에서는 각 회사의 맨 앞 2글자를 가지고 위치 필터링을 보내주기로 했다. 이것을 받아 lookup_field를 사용해 전달받은 값으로 시작하는 데이터를 꺼내오도록 했다.
q = Q()
if location:
q &= Q(company__location__startswith=location)- 태그
각 채용 공고는 다양한 태그를 가지는 바 다대다 테이블로 묶여 있는데, tag를 가지는 공고만 꺼내도록 했다. 마찬가지로 lookup_field를 사용했고 채용 공고를 참조하고 있는 tagnotification 테이블에서 값을 꺼내올 수 있었다.
q = Q()
if tag_id:
q &= Q(tagnotification__tag_id=tag_id)마무리된 후에 select_related와 prefetch_related를 사용했는데, 사용해보니 오히려 prefetch_related가 있을 때 더 느린 것을 알게 되었다.
몇번 수정하며 실험해본 후에 select_related만 남는 것으로 확정되었다.
queryset = JobPosition.objects.select_related("company").filter(q).order_by(sort)- 페이징 기능 구현
이전 프로젝트에서는 페이징에 관한 모든 데이터를 전달받아서 사용했는데, 이번에는 프론트에서 진행하도록 하고 offset과 limit만 받고 또 해당하는필터링을 적용한 후의 채용 공고 갯수를 함께 리턴했다. 데이터를 따로 요청해 전체 count와 [offset:limit] 슬라이싱을 받을까 했는데, 대신 전체 쿼리셋을 요청해 담은 후 count를 계산하고 그 후에 슬라이싱해 리턴하는 것으로 결정했다. 조금 여유가 있었다면 django paginator를 사용했을 텐데 아쉽다. 리팩토링할 때 꼭 수정할 것이다.
- 공고 하나에 대한 사용자의 정보
상품은 한 사용자가 여러번 구매할 수 있지만, 채용 공고는 다르다. 채용 공고에서 이력서를 선택해 지원할 수도 있고, 지원한 공고에 다시 지원할 수는 없기에 로그인한 사용자가 공고의 상세 정보를 확인한다면 지원 여부에 대해서도 데이터가 있어야 한다.
처음에는 공고의 상세 정보와 사용자의 정보를 동시에 돌려주는 api를 작성했는데, 페이지 단위로 생각하는 것 같아서 사용자 정보를 따로 돌려주도록 수정했다.
이 부분을 작성하면서 삼항연산자도 사용했는데, 파이썬의 삼항연산자는 내가 알던 형태가 아니라 꽤 놀랐었다.
✅ KPT 회고
이번 프로젝트 역시 KPT 회고 방식을 사용할 것이다. 전반적으로 이전 프로젝트와 비교를 많이 하게 되었다.
Keep
- 팀원이 적은 만큼 일정이 더 빡빡했으므로 프로젝트는 정말 애자일하게 진행되었다. mock data를 만들 시간도 아까웠다면 이해가 빠를까? 후다닥 데이터 작업을 마친 후 빠르게 데이터를 붙여 보면서 진행했는데, 매주 목표한 sprint를 전부 마무리할 수 있었던데다 처음 기획하고 구상할 때에는 생각하지 못했던 변수들이 튀어나와도 그것들을 핸들링할 수 있는 여유가 있었다.
Problem
- 이번에는 팀원들이 다 1차 프로젝트때 아쉬웠던 것들을 많이 생각하고 의식하면서 신경쓴 덕에 상당히 많은 문제들을 해결할 수 있었다. 나도 작성했던 회고록을 다시 읽어보면서 계속 되새길 수 있었고 비슷한 문제들이 다시 생기는 일이 거의 없을 수 있었다.
- 다만 sprint가 여유로웠던 것이 반대로 더 열심히, 더 치열하게 할 수 있었던 것들을 놓친 결과가 아닐까 하는 아쉬움이 있었다.
- 또 다른 팀원이 맡은 아마존 S3를 아직 잘 모른다는 것이 아쉽다. 개인적인 프로젝트에서(아마... gs25?) 추가로 진행해서 나 스스로 S3를 활용한 서비스를 만들고 AWS와 Docker로 배포도 해 보고 싶다.
Try
- 라이브 코드 리뷰를 진행하면서 다시 느낀 것인데, 코드를 모듈화하는 것을 더 많이 배우고 신경써야겠다고 생각했다. 나름대로 이렇게 하면 모듈화하는 거라고 생각했는데 그것보다 더 촘촘히 나누고 재사용하기 쉽도록, 다른 개발자가 봐도 쉽게 읽을 수 있도록 작성하는 훈련이 꼭 필요하구나 싶었다.
