데이터베이스 쿼리 성능을 튜닝하는데 가장 먼저 해야할 일, 바로 실행 계획 분석이다.
당연히 INDEX SCAN 할거라 생각했던 쿼리도, 막상 실행 계획을 보면 FULL SCAN인 경우가 많다.
실제로 실행 계획을 제대로 확인하지 않아 서버 장애가 발생한 사례가 있다.
커밋 전 실행 계획을 제대로 확인해 사고를 미연에 방지하자.
아키텍쳐
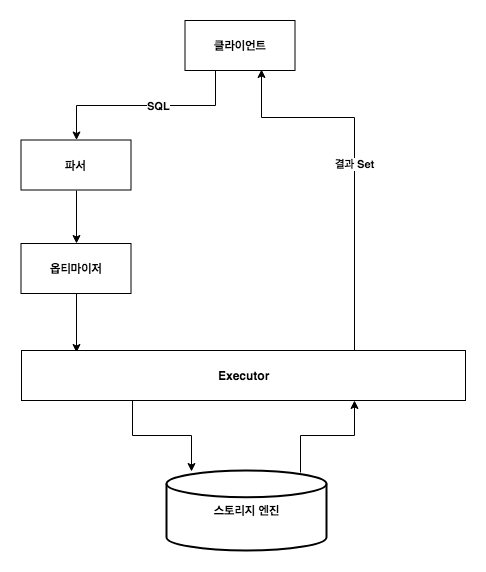
- 옵티마이저는 비용에 기반해, 쿼리를 실행할 비용이 가장 적은 것으로 실행 계획을 세운다.
- 비용은 실행 전까지 정확하게 예상할 수 없으며, 어디까지나 추정치임을 명심해야 한다.
- (버전 5.7 이하에서는 파서 전에 쿼리 캐시가 존재한다)
EXPLAIN
실행 계획을 알고 싶을 때 사용하는 기본 명령어다.
사용법
EXPLAIN [EXTENDED] SELECT ... FROM ... WHERE ...
항목 별 의미
| 구분 | 설명 |
|---|---|
| id | select 아이디로 SELECT를 구분하는 번호 |
| table | 참조하는 테이블 |
| select_type | select에 대한 타입 |
| type | 조인 혹은 조회 타입 |
| possible_keys | 데이터를 조회할 때 DB에서 사용할 수 있는 인덱스 리스트 |
| key | 실제로 사용할 인덱스 |
| key_len | 실제로 사용할 인덱스의 길이 |
| ref | Key 안의 인덱스와 비교하는 컬럼(상수) |
| rows | 쿼리 실행 시 조사하는 행 수립 |
| extra | 추가 정보 |
id
SELECT의 번호다.
서브 쿼리나 UNION이 없다면 SELECT는 하나밖에 없기 때문에 모든 행에 대해 1이란 값이 부여된다.
table
어떤 테이블에 대한 접근을 표시하고 있는지 표시한다.
alias 명이 있는 경우 해당 명으로 표시된다.
select_type
| 구분 | 설명 |
|---|---|
| SIMPLE | 단순 SELECT (Union 이나 Sub Query 가 없는 SELECT 문) |
| PRIMARY | Sub Query를 사용할 경우 Sub Query의 외부에 있는 쿼리(첫번째 쿼리), UNION 을 사용할 경우 UNION의 첫 번째 SELECT 쿼리 |
| UNION | UNION 쿼리에서 Primary를 제외한 나머지 SELECT |
| DEPENDENT_UNION | UNION 과 동일하나, 외부쿼리에 의존적임 (값을 공급 받음) |
| UNION_RESULT | UNION 쿼리의 결과물 |
| SUBQUERY | Sub Query 또는 Sub Query를 구성하는 여러 쿼리 중 첫 번째 SELECT문 |
| DEPENDENT_SUBQUERY | Sub Query 와 동일하나, 외곽쿼리에 의존적임 (값을 공급 받음) |
| DERIVED | SELECT로 추출된 테이블 (FROM 절 에서의 서브쿼리 또는 Inline View) |
| UNCACHEABLE SUBQUERY | Sub Query와 동일하지만 공급되는 모든 값에 대해 Sub Query를 재처리. 외부쿼리에서 공급되는 값이 동이라더라도 Cache된 결과를 사용할 수 없음 |
| UNCACHEABLE UNION | UNION 과 동일하지만 공급되는 모든 값에 대하여 UNION 쿼리를 재처리 |
type
쿼리 성능 판별 시 가장 주되게 보는 항목이다.
| 구분 | 설명 |
|---|---|
| system | 테이블에 단 한개의 데이터만 있는 경우 |
| const | SELECT에서 Primary Key 혹은 Unique Key를 살수로 조회하는 경우로 많아야 한 건의 데이터만 있음 |
| eq_ref | 조인을 할 때 Primary Key |
| ref | 조인을 할 때 Primary Key 혹은 Unique Key가 아닌 Key로 매칭하는 경우 |
| ref_or_null | ref 와 같지만 null 이 추가되어 검색되는 경우 |
| index_merge | 두 개의 인덱스가 병합되어 검색이 이루어지는 경우 |
| unique_subquery | 다음과 같이 IN 절 안의 서브쿼리에서 Primary Key가 오는 특수한 경우 SELECT * FROM tab01 WHERE col01 IN (SELECT Primary Key FROM tab01); |
| index_subquery | unique_subquery와 비슷하나 Primary Key가 아닌 인덱스인 경우 SELECT * FROM tab01 WHERE col01 IN (SELECT key01 FROM tab02); |
| range | 특정 범위 내에서 인덱스를 사용하여 원하는 데이터를 추출하는 경우로, 데이터가 방대하지 않다면 단순 SELECT 에서는 나쁘지 않음 |
| index | 인덱스를 처음부터 끝까지 찾아서 검색하는 경우로, 일반적으로 인덱스 풀스캔이라고 함 |
| all | 테이블을 처음부터 끝까지 검색하는 경우로, 일반적으로 테이블 풀스캔이라고 함 |
possible_keys
- 이용 가능성 있는 인덱스 목록
key
possible_keys 목록 중 옵티마이저가 선택한 인덱스
key_len
key 의 길이
ref
키 컬럼에 나와 있는 인덱스에서 값을 찾기 위해 선행 테이블의 어떤 컬럼이 사용되었는 지를 나타낸다.
rows
원하는 행을 가져오기 위해 얼마나 많은 행을 읽을지 예측치
extra
| 구분 | 설명 |
|---|---|
| using index | 커버링 인덱스라고 하며 인덱스 자료 구조를 이용해서 데이터를 추출 |
| using where | where 조건으로 데이터를 추출. type이 ALL 혹은 Indx 타입과 함께 표현되면 성능이 좋지 않다는 의미 |
| using filesort | 데이터 정렬이 필요한 경우로 메모리 혹은 디스크상에서의 정렬을 모두 포함. 결과 데이터가 많은 경우 성능에 직접적인 영향을 줌 |
| using temporary | 쿼리 처리 시 내부적으로 temporary table이 사용되는 경우를 의미함 |
성능 판별법 (일반적)
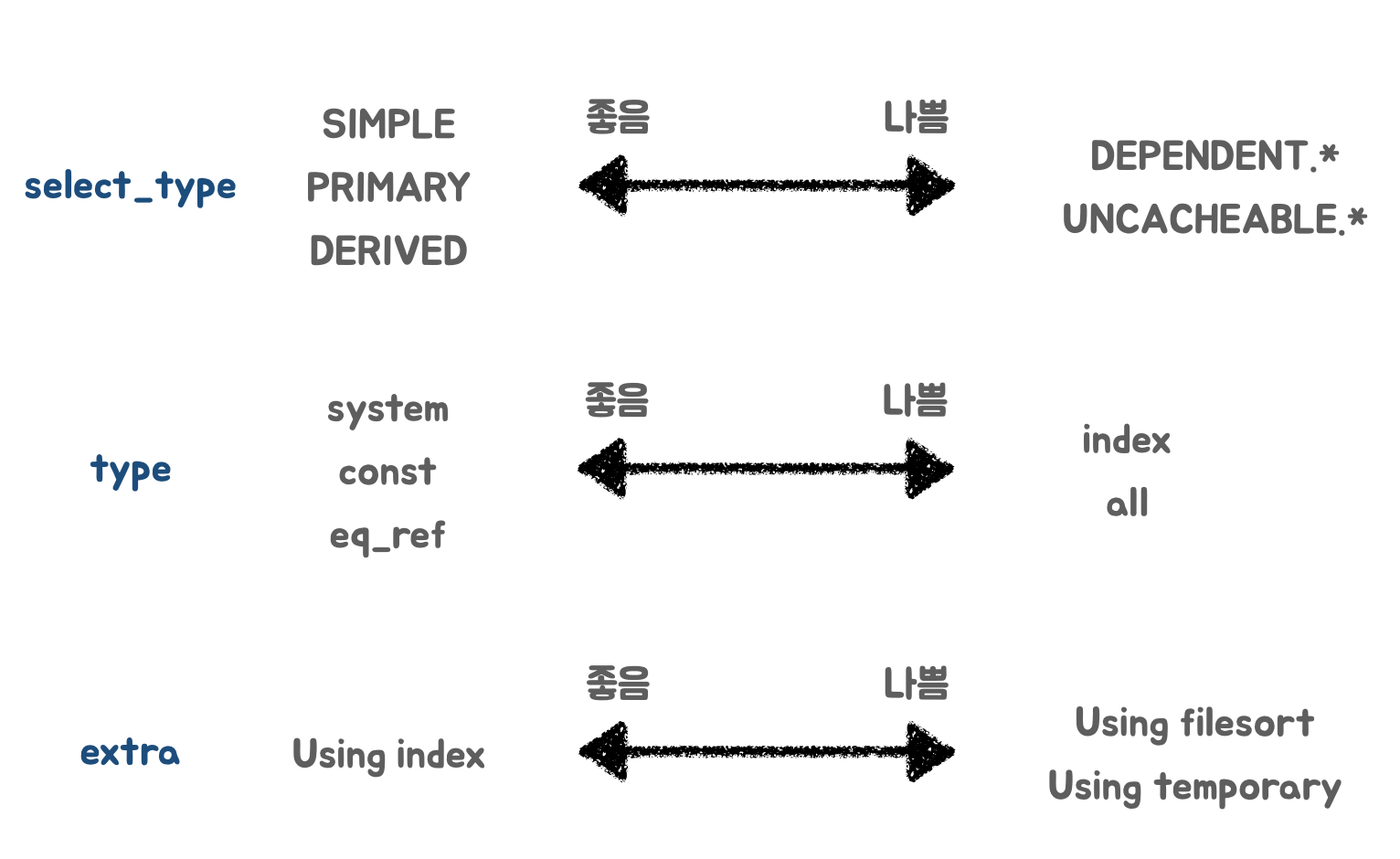
select_type
dependent.type은 조회시마다, 외부 테이블에 접근하게 되므로 악영향.uncacheable.또한 캐시할 수 없으므로 악영향 (ex. rand 함수 사용 등)
type
- 인덱스 레인지 풀 스캔, 혹은 테이블 풀 스캔을 줄일 수 있는 방향으로 개선 필요
extra
- filesort나 group by를 위한 temp 테이블 생성보다 인덱스를 활용하여 sorting/group by를 수행할 수 있다면 성능 개선 가능
Reference
https://nomadlee.com/mysql-explain-sql/
https://cheese10yun.github.io/mysql-explian/#null

툴 만들기 좋아하는 삽질 전문(...) 주니어 백엔드 개발자입니다.