
항상 뭔가 뜬구름 잡는 것처럼 들렸던 개념이다.
확실히 짚고 넘어가보자
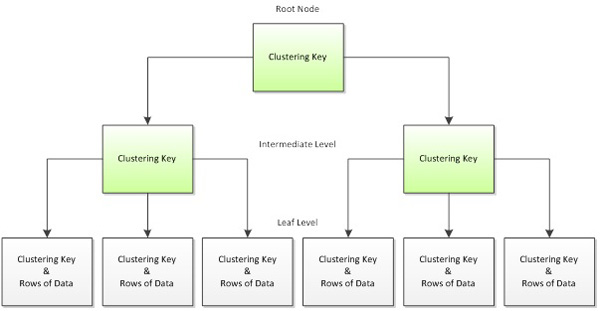
Clustered Index
- 클러스터링 인덱스 키를 기준으로 정렬된 상태를 유지한다.
mysql기준, Primary key에 기본으로 적용되는 인덱스다.- 테이블 마다 한 개만 적용 가능하다.
- leaf node에는 항상 실제 데이터 페이지가 들어있다.
장점
- 범위 검색에 특화되어 있다.
- 캐시 hit를 최대화하고 page 전환을 최소화한다.
- leaf node에서 원하는 데이터로 바로 이동하므로, 데이터에 보다 빠른 접근이 가능하다.
단점
- 항상 정렬해야 하므로 insert, update, delete 속도가 느리다.
- 비연속적인 데이터를 요청할 때는 효과를 보기 힘들다.
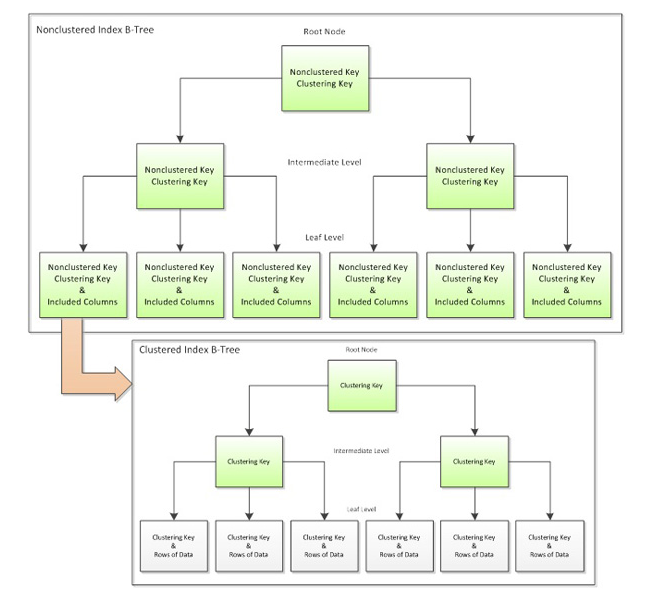
Non-Clustered Index
- 인덱스로 물리적 데이터 위치를 정렬하지 않는다.
- 인덱스 목록을 분리 저장하기 때문에, 추가적인 저장 공간이 필요하다.
- leaf node에는 heap/clustered 인덱스 row에 대한 포인터를 담고 있다.
장점
- clustered에 비해 쓰기 성능 오버헤드가 적다.
- 테이블 당 두개 이상 만들 수 있다.
단점
- 물리적으로 데이터를 정렬하지 않아 읽기 속도가 느리다.
- 클러스터링 키 값이 업데이트 될 때마다, 해당 키의 포인터를 가지고 있는 non-clustered index 또한 함께 업데이트 되어야 한다.
참고

툴 만들기 좋아하는 삽질 전문(...) 주니어 백엔드 개발자입니다.