
❗️ 실제 서비스의 데이터베이스를 다루며 생긴 이슈였으므로,
기능과 쿼리 속 테이블 명, 컬럼 명 등은 임의의 이름으로 대체하겠다.
🙄 문제 상황
리스폰스 속도가 3초가 넘는 쿼리가 있었다.
해당 기능을 학생 관리 시스템으로 치환해보자면 아래와 같다.
기능
- 목적
- 전체 과목 조회
- 선택 과목의 경우, 사용자가 현재 수강하고 있지 않은 과목만 조회
DB
스펙: MySQL 5.7
STUDENT: 학생 테이블COURSE: 과목 테이블COURSE_REGISTER: 과목 수강 신청/취소 기록 로그성 테이블 (*선택 과목일 경우, row가 존재하지 않을 시 미수강으로 간주)- *주의: 과목을 신청했다 취소할 시 새로운 row가 추가됨. 신청 상태의 row를 업데이트하지 않음
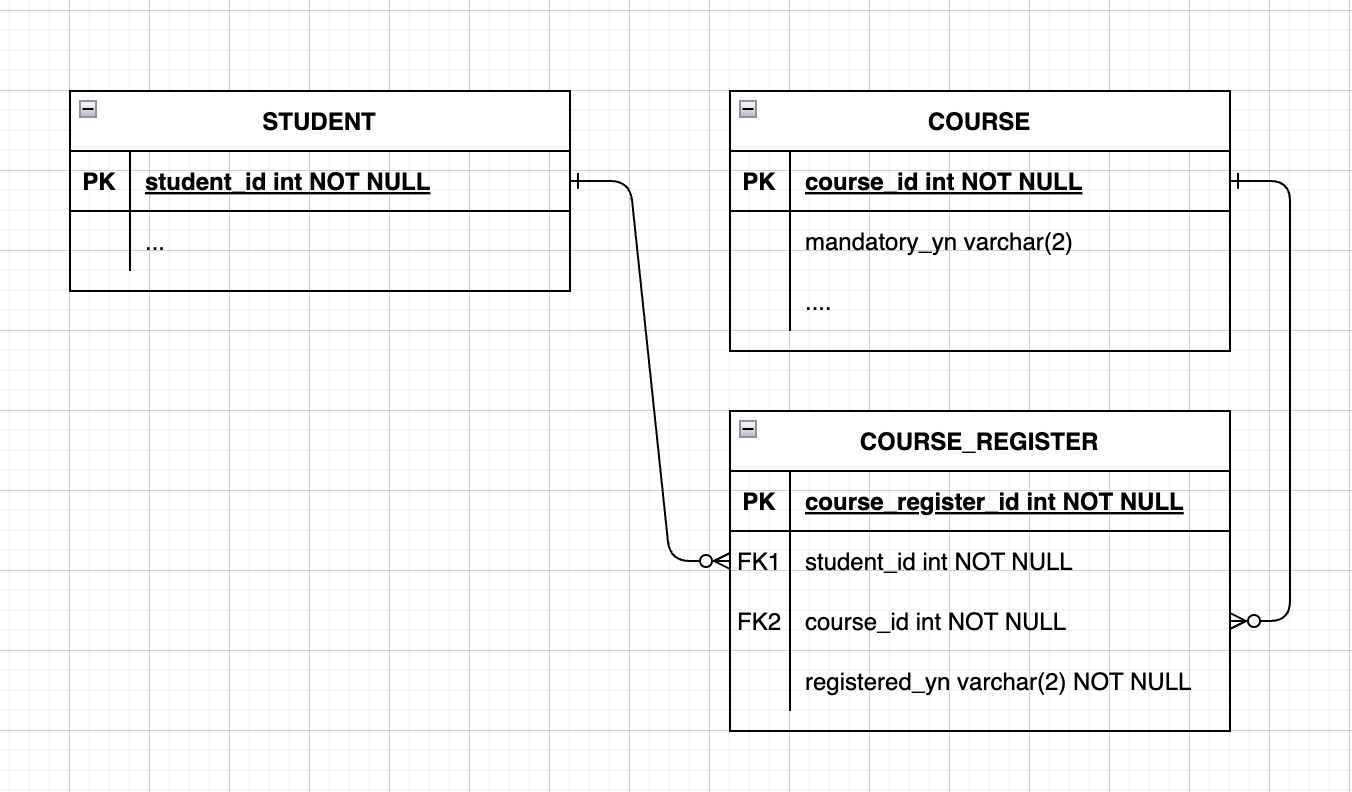
❗️ 쿼리에 언급되지 않을 필드는 그림에 포함하지 않았다.
😓 문제 쿼리
SELECT DISTINCT *
FROM COURSE C
LEFT JOIN COURSE_REGISTER CR
ON C.COURSE_ID = CR.COURSE_ID
WHERE IF(C.MANDATORY_YN = 'N',
C.COURSE_ID NOT IN (
SELECT DISTINCT COURSE_ID // 선택 과목 row가 없는 경우
FROM COURSE_REGISTER
WHERE STUDENT_ID = ?
)
OR (
CR.STUDENT_ID = ? // 가장 최근에 insert 된 row면서 수강 취소 기록인 경우
AND CR.REGISTERED_YN = 'N'
AND CR.COURSE_REGISTER_ID IN (
SELECT MAX(COURSE_REGISTER_ID)
FROM COURSE_REGISTER
GROUP BY (COURSE_ID, STUDENT_ID))
),
true);도무지 왜 이렇게 짰는지 이해가 가지 않는다면 정상이다.
부끄럽게도 이걸 짰던건 다름 아닌 필자 본인이다.
기능 확장 전 상태의 쿼리 형태를 최대한 보존하려다 보니 기괴한(?) 형태를 띄게 되었다.
(늦게라도 고칠 수 있어서 정말 다행이다......)
어쨌든 요구한 동작은 정확히 해내긴 한다.
하지만 성능이 약 3초 대로 매우 처참하니.. 뜯어고칠 날을 벼르고 있었다.
😘 1차 튜닝
보이는 개선할 지점은 크게 세가지였다.
- 수강 기록 테이블에 불필요한 액세스가 너무 많다. (이전 쿼리에서 FROM 절로 언급된 것만 세번이다.)
- 기껏 join 해놓고 거의 활용하지 않았다.
- 실행 계획을 살펴본 결과, 매 행마다 서브쿼리를 재호출 하고 있었다. 그 서브쿼리에 IN 절로 선형탐색까지 하니 최악이다...
쿼리
SELECT DISTINCT *
FROM COURSE C
LEFT JOIN COURSE_REGISTER CR
ON C.COURSE_ID = CR.COURSE_ID AND CR.STUDENT_ID = ?
WHERE IF(C.MANDATORY_YN = 'N'
, CR.COURSE_REGISTER_ID IS NULL
OR (
CR.COURSE_REGISTER_ID = (
SELECT MAX(COURSE_REGISTER_ID)
FROM COURSE_REGISTER
WHERE COURSE_ID = C.COURSE_ID
AND STUDENT_ID = CR.STUDENT_ID)
AND CR.REGISTERED_YN = 'N'
)
, true);1. join 문 on 절에 조건을 추가해 사용자를 특정해줬다.
이걸로 행마다 IN 절을 사용할 필요가 없게됐다.
이러면 join 할때부터 사용자의 row에 해당되는 것들만 가져오게 된다.
즉, WHERE 절에서 사용자 ID가 뭔지 신경 쓸 필요가 없다.
2. 수강 기록의 최신성 검증을 1:1 비교로 변경했다.
기존에는 1:n 비교로, 서브쿼리로 유효한 기록 pool을 만든 다음 그 안에서 검색하는 방식이었다.
차라리 SELECT 범위라도 작은게 낫다는 생각에 단일 행 조회로 개선했다.
🎉 이렇게 약 180ms 속도로 만드는데 성공한다!!!! 🥳🥳🥳🥳🥳🥳
하지만 여기서 끝이 아니다...!!!
🥰 2차 튜닝
비약적인 성능 개선을 이루었음에도 여전히 찝찝한 것.
CR.COURSE_REGISTER_ID = (SELECT MAX(COURSE_REGISTER_ID)
FROM COURSE_REGISTER
WHERE COURSE_ID = C.COURSE_ID
AND STUDENT_ID = CR.STUDENT_ID)조건에 붙은 이 서브쿼리 때문이다.
검색 범위를 줄여서 개선했다고는 하나, 서브쿼리로는 쿼리 캐시를 쓸 수 없으니 매 행마다 실행되는 것은 똑같다.
테이블 데이터 크기가 커지면 커질 수록 성능이 나빠질 수 밖에 없는 것이다.
그렇다면 수강 기록 테이블을 최소한만 조회하는 방법은 없을까 ??
쿼리
SELECT DISTINCT *
FROM COURSE C
LEFT JOIN (
SELECT *
FROM COURSE_REGISTER CR
JOIN (
SELECT MAX(COURSE_REGISTER_ID) MAX_ID
FROM COURSE_REGISTER
WHERE STUDENT_ID = ?
GROUP BY COURSE_ID
) CURR_STATE ON CR.COURSE_REGISTER_ID = CURR_STATE.MAX_ID) USER_CR
ON C.COURSE_ID = USER_CR.COURSE_ID
WHERE IF(C.MANDATORY_YN = 'N'
, CR.COURSE_REGISTER_ID IS NULL
OR
CR.REGISTERED_YN = 'N'
, true);그 답은 바로... 유효한 수강 기록 ID 풀로 인라인 뷰를 만들어 left join하는 것이다!!
이러면 행마다 서브쿼리를 새로 실행하지 않아도 된다.
👀 1차 개선의 쿼리와 속도는 비슷했다. (테이블 데이터 크기가 커지면 진가가 나오지 않을까...!)
🧐 고민했던 것
꼭 단일 쿼리로 모두 해결을 봐야할까?
서브쿼리만 분리해서 그 결과를 어플리케이션이 메모리에 가지고 있다가,
그걸 활용하면 되지 않을까?
내 판단 기준은 이랬다.
서브쿼리에 해당하는 쿼리가 쿼리 캐시로 이득을 볼 수 있는 쿼리라면 분리한다.
그럼 더 이상 서브쿼리가 아니게 되니 결과값을 캐싱할 수 있기 때문이다.
👉 쿼리 캐시로 이득을 볼 수 있는 유형
1. INSERT / UPDATE / DELETE 조작 횟수가 적을 것 (업데이트가 일어날 시 해당 테이블의 캐싱 목록은 모두 플러시됨)
2. 결과값이 너무 크지 않을 것 (쿼리 캐시 사이즈의 대부분을 차지해버릴 위험 존재)
아래는 인라인 뷰로 들어간 서브쿼리 부분이다.
SELECT *
FROM COURSE_REGISTER CR
JOIN (
SELECT MAX(COURSE_REGISTER_ID) MAX_ID
FROM COURSE_REGISTER
WHERE STUDENT_ID = ?
GROUP BY COURSE_ID
) CURR_STATE ON CR.COURSE_REGISTER_ID = CURR_STATE.MAX_ID결론부터 말하면, 위 쿼리는 쿼리 캐시로 이득을 보기가 어렵다.
1번 항목을 충족시키지 못하기 때문이다.
수강 기록 테이블은 학생들이 수강을 신청하고, 취소할 때마다 DML 조작이 일어난다.
만약 과목 테이블이었다면 좀 더 적합했을지도 모른다. 과목을 추가/수정/삭제 하는건 '가끔' 일어나기 때문이다.
그래서 최종적으로 2차 튜닝에 있는 쿼리로 업데이트 하는 것으로 마무리했다.
참고자료
