
팀장님이 발표전에 갑자기 연락두절이 되어 급하게 발표자가 저로 바뀌게 되었고... 반나절만에 준비하게 된 내용입니다... 주어진 시간의 한계로 부족한 부분이 많습니다...
발표 대본

안녕하십니까 팀장님이 연락두절되어 갑작스럽게 발표를 맡게 된 위원종입니다. 부족한 부분이 많지만 잘부탁드리며 발표 시작하겠습니다.
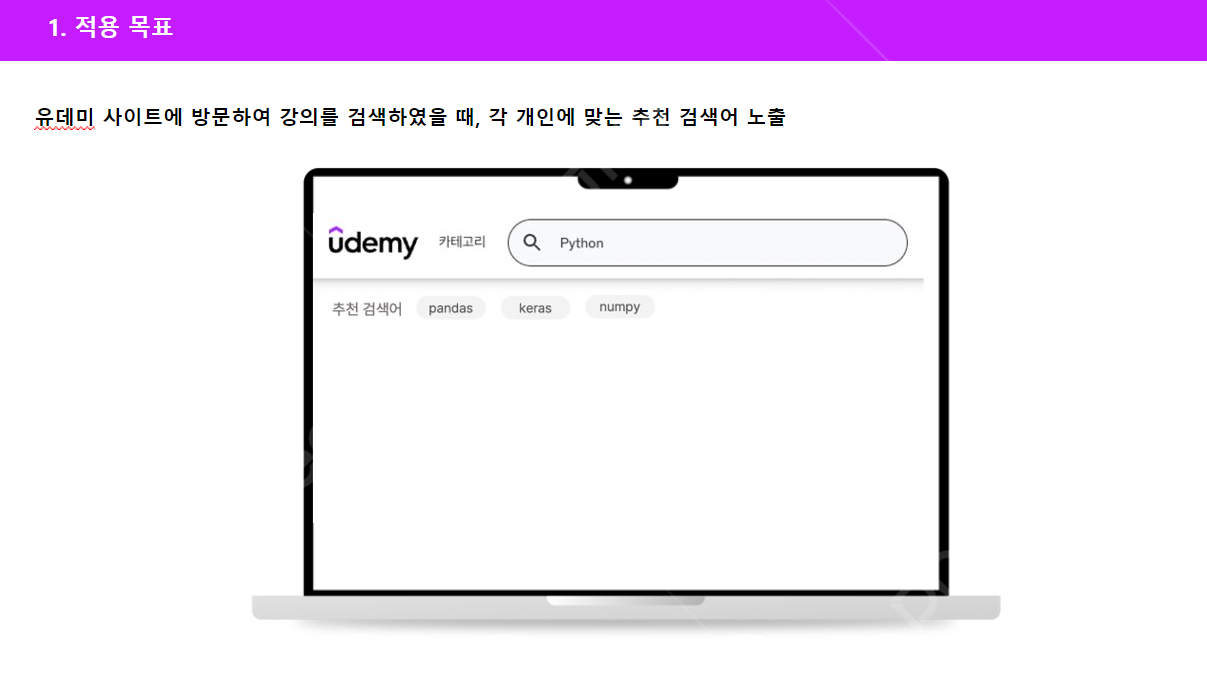
저희가 진행한 프로젝트의 목표는, 유저가 유데미 사이트에 방문하여 강의를 검색하였을 때, 각 개인에 맞는 추천 검색어를 노출해 주는 것입니다. 추천 검색어를 노출하는 데에 있어서 다양한 인공지능(AI) 기술을 활용하였습니다.
저희 프로젝트에서 AI를 어떻게 적용시켰는 지, 그 과정에 대해 설명 드리겠습니다.
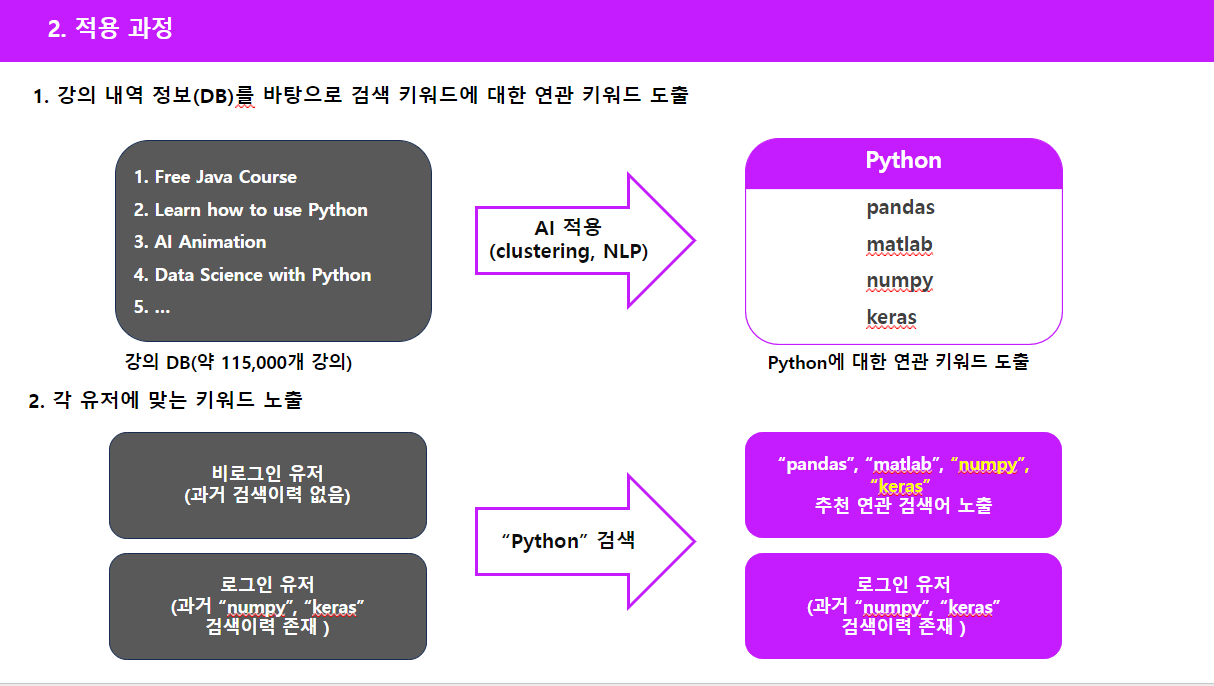
첫 번째로는 유데미에 존재하는 모든 강의들의 정보가 담긴 데이터를 통해 특정 검색 키워드에 대한 연관 키워드를 노출하게 됩니다.
유데미 강의 데이터에는 강의 제목, 강사명, 수업시간 등의 정보가 있으며, 이러한 정보들에 AI를 적용하여 Python을 검색했을 때, python의 연관 키워드들을 찾아 도출해줍니다. 이때 AI 기법으로는 클러스터링과 NLP를 사용했습니다.
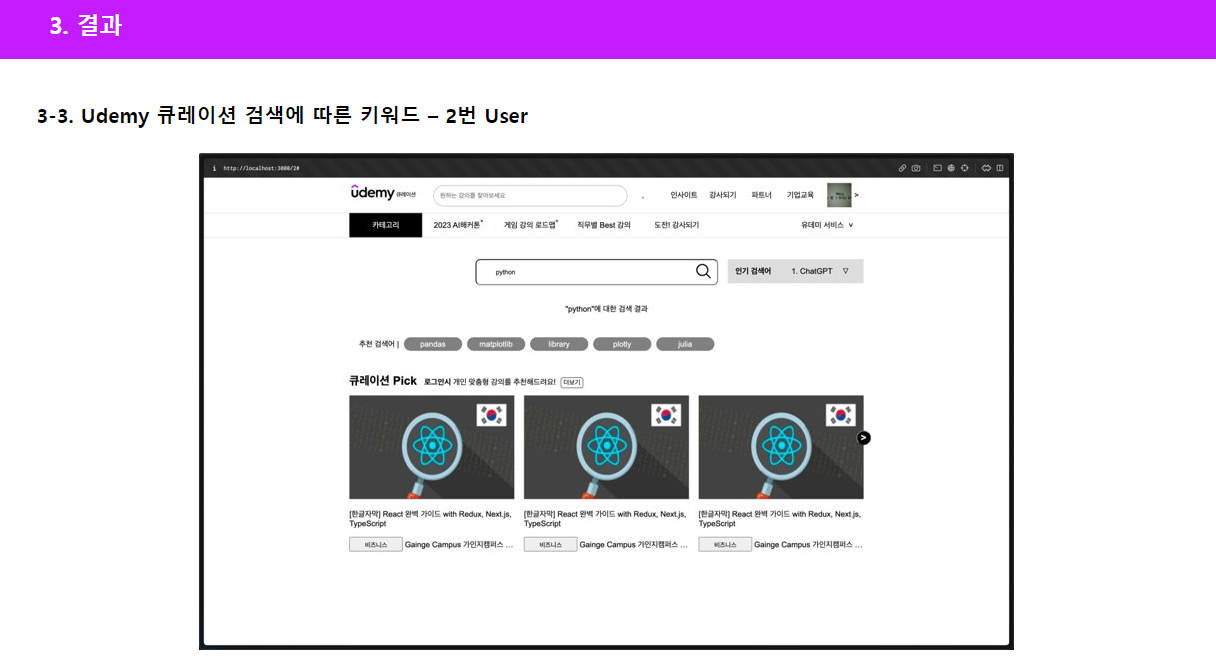
두번째로는, 각 유저의 특성에 따른 키워드를 노출합니다. 다른 각각의 유저가 같은 “Python” 키워드를 입력했어도, 각 개인의 검색이력에 따라 추천 키워드가 달라집니다. 예를 들어, 검색이력이 없는 비로그인 유저 같은 경우에는 python의 연관 키워드를 모두 추천 검색어로 노출시키지만, 검색이력이 있는 로그인 유저는 과거 검색했던 키워드를 제외하고 추천 검색어를 노출하게 됩니다.

우선, 저희가 적용한 AI 기법 중 클러스터링 방법론에 대해 더 자세히 말씀드리겠습니다.
유데미 강의 데이터에는 다양한 형태의 정보가 존재합니다. 강의 제목, 강사명과 같은 텍스트 정보부터 강의 평점, 수강생 수, 강의 시간에 이르기까지 여러 숫자 데이터가 포함되어 있습니다. 저희는 이러한 데이터를 분류하고 패턴을 찾기 위해 클러스터링 기법을 사용하였습니다. 클러스터링은 숫자 데이터들로만 모아서 수행하였으며, 이를 통해 유사한 특성을 지닌 강의들을 클러스터로 묶었습니다.
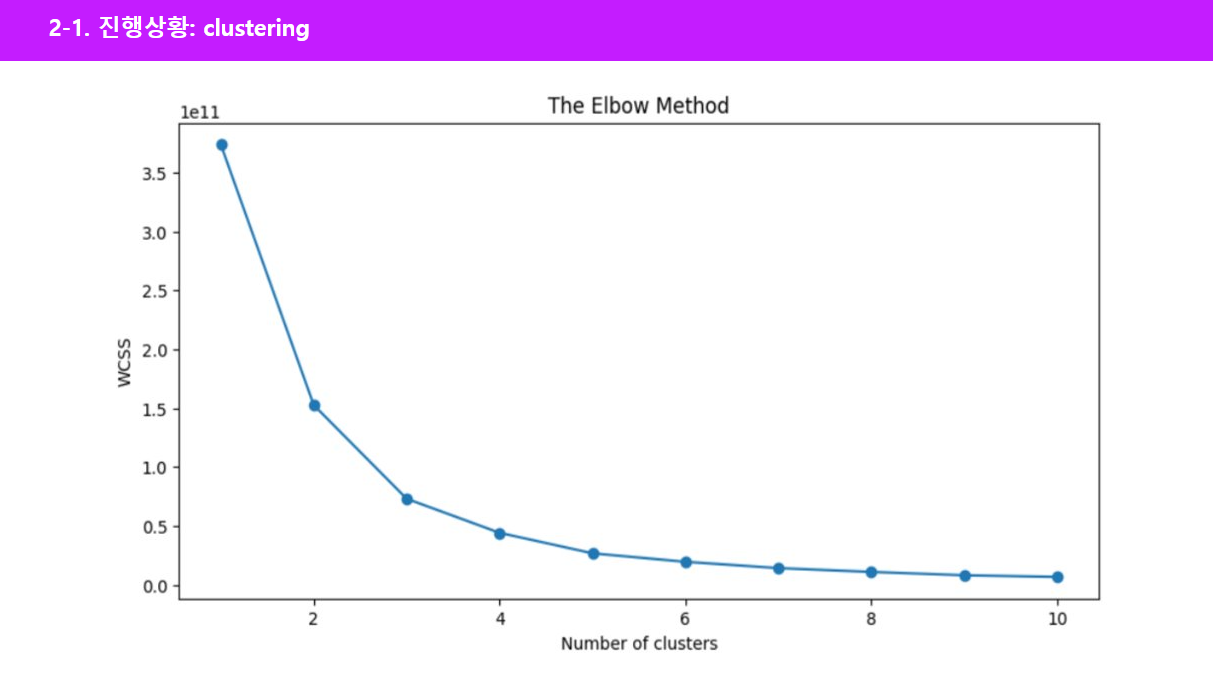
최적의 클러스터 개수를 결정하기 위해 즉 k 값을 정하기 위해서는 엘보우 방법(Elbow Method)이라는 기법을 사용했습니다. 이 방법을 통해 클러스터 내 오차 제곱합의 변화를 살펴봄으로써, 클러스터의 개수가 증가함에 따라 감소하는 오차율이 급격히 변하는 지점을 찾아내어 최적의 클러스터 개수를 결정할 수 있었습니다. 실제 데이터 분석 결과, 클러스터링 개수가 3개일 때 오차율이 급격하게 감소하는 'elbow' 현상을 관찰할 수 있었으며, 이에 따라 데이터를 3개의 클러스터로 나누어 분석을 진행하였습니다.

이어서 AI 적용 기법 중 두번째 단계인 자연어 처리 NLP 기술에 대해 설명 드리겠습니다.
앞서 클러스터링을 통해 형성된 각 그룹에 대해 NLP 기법을 적용하여 중요 키워드를 추출하였습니다.
자연어처리는 텍스트로 된 데이터를 이용하며 저희는 강의 제목만을 사용하였습니다.
Word2vec 모델을 학습시키기 전에, 문장으로 되어있는 강의 제목을 토크나이징 작업을 수행해 키워드 별로 나누고, 이러한 키워드들을 이용하여 word2vec 모델에 적용하여 학습하였습니다.
이를 통해 word2vec은 검색 키워드가 주어졌을 때, 해당 키워드와 비슷한 연관 키워드를 뽑아낼 수 있게끔 학습이 되었습니다.
예시로, Python을 검색 키워드라고 했을 때, 이를 학습된 word2vec 모델에 적용시키면 오른쪽과 같이 pandas, numpy(넘파이)등과 같은 연관 키워드들을 얻을 수 있었습니다.
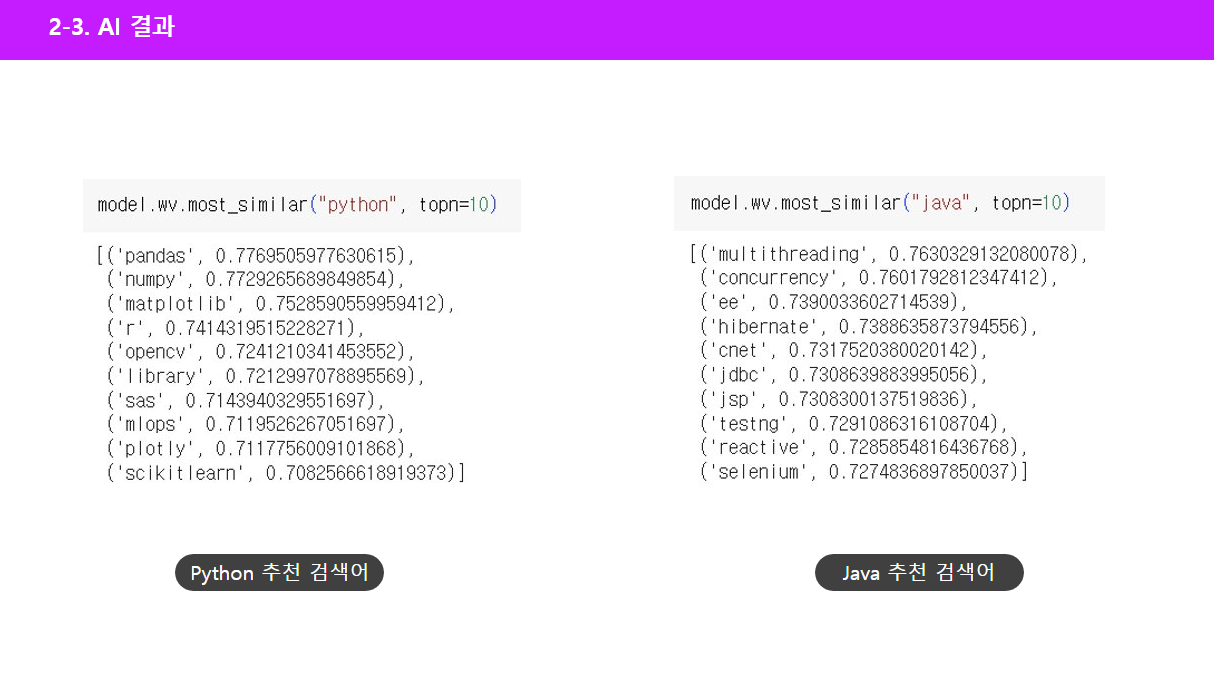
저희 프로젝트의 실제 결과를 보여드리겠습니다.
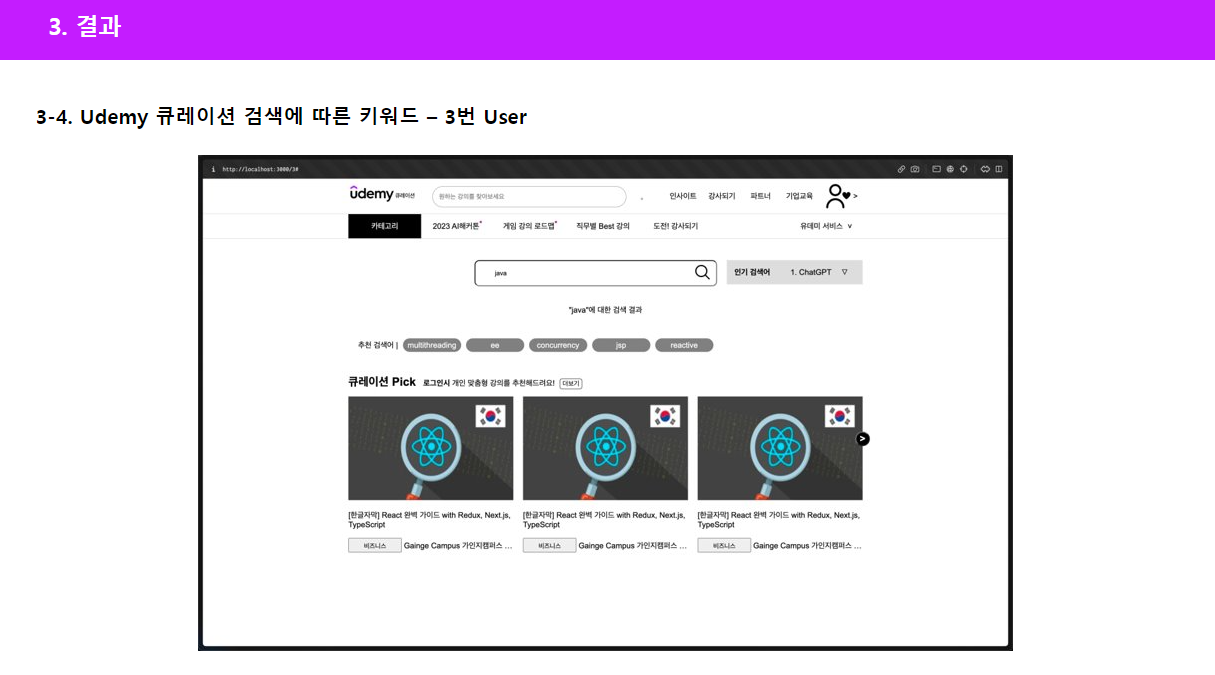
클러스터링과 NLP 과정을 거쳐, Python을 입력했을 때, 가장 연관성이 큰 10개의 키워드들을 다음과 같이 보여주는 모습을 확인할 수 있었고, 아래는 Java가 검색 키워드일 때의 예시입니다.
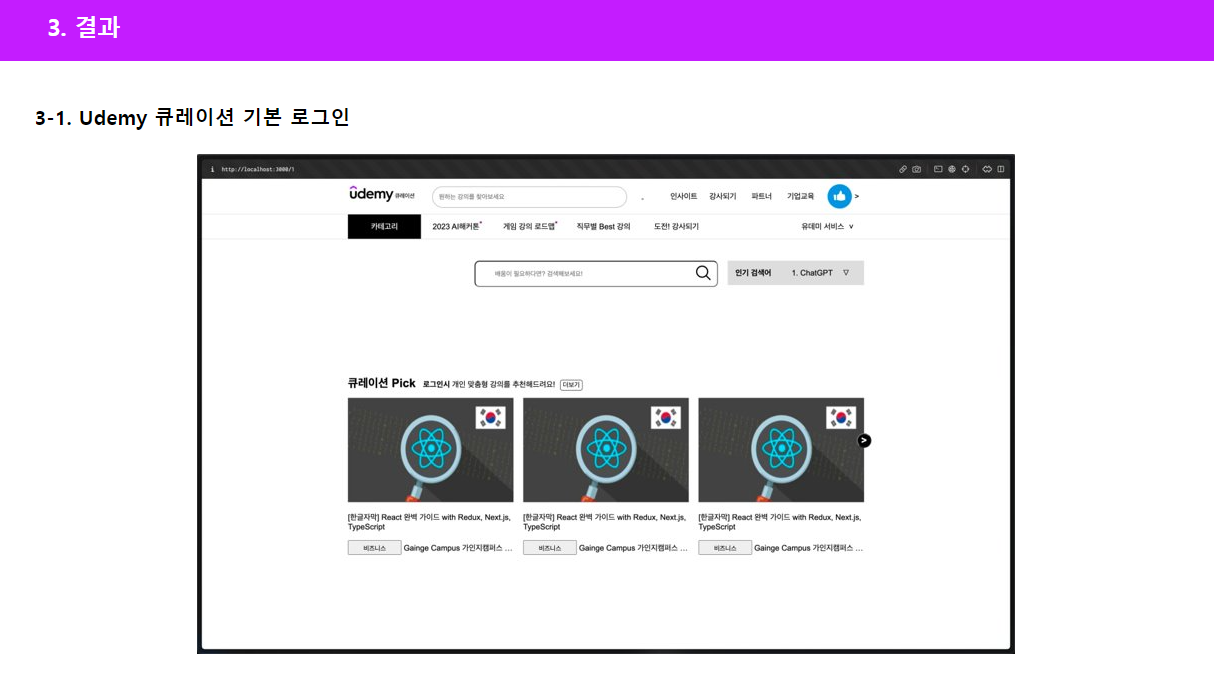
웹 구현 결과도 함께 보여드리겠습니다.
화면과 같이 로그인 기능을 구현 했습니다. JWT토큰 인증 방식을 적용했으며 redis를 이용해 리프래쉬 토큰을 관리하고 엑세스 토큰의 유효시간을 짧게 설정해 보안을 향상시켰습니다.
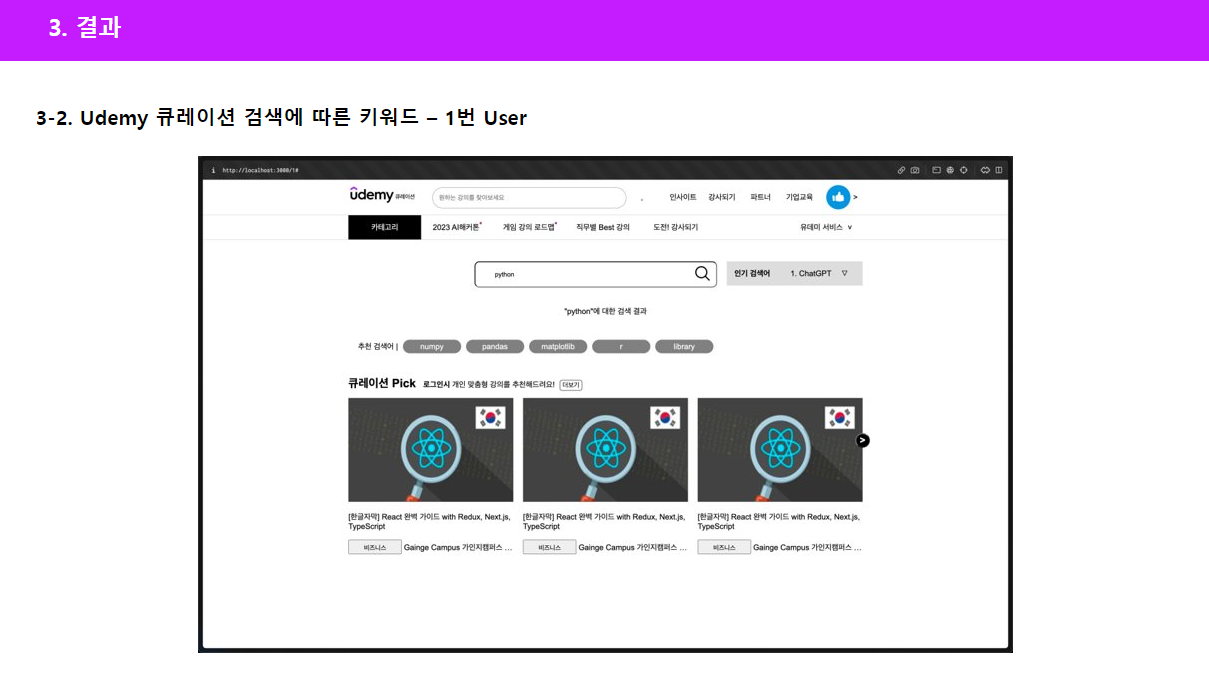
앞서 보여드린 추천 검색어 결과를 프론트단에 넘겨준 모습입니다. 각 회원별로 같은 키워드를 입력해도 다른 추천 검색어 결과가 나온걸 확인하실 수 있습니다.
정리
정리하자면
저희는 평균 평점(avg_rating), 리뷰 수(num_reviews), 그리고 강의 총 길이 값에 기반하여 K-means 클러스터링을 수행했습니다. 이러한 정보들을 바탕으로 비슷한 특성 즉, 좋고 인기 많은 강의들을 기준으로 그룹화했습니다.
이후 NLP의 전처리 단계에서는 강의 제목을 단어 단위로 분리하고 특수 문자를 제거하여 Word2Vec 모델 학습에 적합한 형태로 만들었고 Word2Vec 모델을 사용하여 단어들의 벡터를 학습시킨 후, 특정 검색어에 대해 의미적으로 유사한 단어들을 추천해주도록 만들었습니니다.
추천 시스템의 개인화 부분에서는 사용자가 로그인한 상태와 비로그인 상태를 구분하여, 로그인 사용자에게는 이전에 수강한 강의를 제외한 추천어를 제공했으며며 이 과정은 실제 상황에서 데이터가 균일하게 분포되지 않고 편향될 수 있다는 점을 감안하여 설계했습니다.

제한사항 및 보완할 점
유저 데이터를 제공받지 못해 직접 만들어야 했습니다.
즉, 로그인한 유저일 때 어떤 키워드를 검색하였는 지에 대한 데이터가 존재하지 않아서 추천 검색어를 유저 특성에 맞게 개인화하는 데에 한계가 있었습니다.
그리고 처음 프로젝트를 시작할 때 저희팀은 5명이었지만 어느순간 갑작스럽게 2명이 연락두절이 되어버리고 남은 팀원들도 조기취업 등의 이유로 시간 제약이 있었습니다.
NLP를 진행할 때, 시간 제약 상 강의 제목 정보만을 이용했지만, 추가적으로 강사명까지 포함하여 학습을 진행했다면 좋았을 것 같은데 시간이 충분하지 못해 여기까지 진행하지는 못해 아쉬움이 남습니다.

개념 정리
clustering과 k-means
클러스터링(Clustering)은 데이터를 비슷한 특성을 가진 여러 그룹으로 나누는 머신러닝의 비지도 학습 기법이다. 이 방법은 데이터 내 숨겨진 패턴을 발견하거나 데이터 구조를 이해하는 데 유용하게 사용된다. 클러스터링 알고리즘은 다양한 기준과 방법론을 가지고 있으며, 그 중에서도 k-means는 가장 널리 사용되는 클러스터링 알고리즘 중 하나이다.
k-means 클러스터링은 간단하면서도 효과적인 반복적인 방법을 사용하여 데이터를 k개의 클러스터로 그룹화한다. k는 사용자가 지정하는 클러스터의 수를 의미하며, 각 클러스터는 클러스터 내의 데이터 포인트들과의 거리가 최소가 되는 중심점(centroid)을 가진다.
k-means 알고리즘은 단계
-
초기화: 무작위로 k개의 중심점을 선택한다.
-
할당: 각 데이터 포인트를 가장 가까운 중심점을 기준으로 클 러스터에 할당한다.
-
업데이트: 할당된 데이터 포인트들의 평균을 계산하여 새로운 중심점을 정한다.
-
반복: 할당과 업데이트 단계를 수렴할 때까지 반복한다. 수렴이란 중심점이 더 이상 크게 변하지 않을 때까지를 의미한다.
k-means 알고리즘은 몇 가지 단점도 가지고 있다. 예를 들어, k의 값을 미리 지정해야 한다는 점, 클러스터의 모양이 구형이라고 가정한다는 점, 이상치(outliers)에 민감하다는 점 등이 있다. 이러한 이유로, 실제 문제에 적용하기 전에 데이터를 잘 이해하고 적절한 전처리를 수행하는 것이 중요하다.
k-means 알고리즘 순서도
-
무작위로 k개의 중심점을 선택한다.
-
반복 시작:
a. 각 데이터 포인트를 가장 가까운 중심점에 할당한다.
b. 할당된 데이터 포인트들의 평균을 계산하여 새로운 중심점을 결정한다. -
중심점의 변화가 없을 때까지 a와 b를 반복한다.
-
수렴 시 클러스터링 완료.
elbow method
Elbow method란, 러프하게 예를 들어 for문으로 클러스터링 수를 1에서 10으로 가정하였을 때 각 경우의 수에 대해 클러스터링을 모두 시행해보고, 각각의 경우에서 군집 내 총 제곱합을 구하여 그 제곱합이 사람의 팔꿈치 위치처럼 급격하게 꺾이는 부분의 값을 적절한 클러스터링 그룹 수로 선택하는 것입니다.
Elbow method는 k-means 클러스터링을 수행할 때 적절한 클러스터의 수 k를 결정하는 데 사용되는 방법이다. 이 방법은 클러스터의 수를 증가시키면서 각각의 k 값에 대한 클러스터링의 성능을 평가하여, 클러스터의 수를 어디에서 정할지를 결정하는 데 도움을 준다.
Elbow method의 기본 아이디어는 클러스터의 수가 증가함에 따라 각 데이터 포인트와 해당 클러스터 중심점과의 거리의 제곱합인 Sum of Squared Distances (SSD)가 감소한다는 것이다. 하지만 특정 숫자의 클러스터 이상에서는 이 감소량이 급격히 줄어들어 성능의 개선이 미미해진다. 이 지점을 'Elbow', 즉 '팔꿈치'라고 비유하여 부르는데, 이 지점이 바로 적절한 클러스터의 수로 간주될 수 있다.
Elbow method를 수행하는 단계는 다음과 같다:
-
클러스터의 수 k를 1부터 시작하여 증가시키면서 k-means 클러스터링을 수행한다.
-
각각의 k 값에 대해, 모든 데이터 포인트와 해당 클러스터 중심점과의 거리의 제곱합(SSD)을 계산한다.
-
k 값에 대한 SSD의 값을 그래프로 그린다.
-
그래프에서 SSD의 감소가 완만해지는 지점, 즉 '팔꿈치'와 유사한 모양이 나타나는 지점을 찾는다.
-
이 지점을 최적의 클러스터 수 k로 선택한다.
Elbow method는 시각적인 방법이기 때문에 항상 명확한 '팔꿈치' 지점이 나타나는 것은 아니다. 때문에 다른 방법론과 함께 사용하거나 전문가의 판단이 필요할 수 있다.
NLP
NLP(Natural Language Processing)는 컴퓨터가 인간의 언어를 이해하고 해석하는 데 사용되는 인공지능의 한 분야이다. 이 기술은 언어 데이터를 분석하고 처리하여 컴퓨터가 의미를 추출하고 이해할 수 있도록 하는 다양한 알고리즘과 모델을 포함한다.
NLP에는 다음과 같은 다양한 작업이 포함된다.
-
텍스트 분석(Text Analysis): 문법적 구조, 단어의 빈도수, 주제 등 텍스트의 다양한 요소를 분석한다.
-
언어 이해(Language Understanding): 텍스트가 전달하는 의미와 맥락을 파악한다.
-
언어 생성(Language Generation): 인간이 이해할 수 있는 자연어로 텍스트를 생성한다.
-
음성 인식(Speech Recognition): 오디오 데이터에서 텍스트를 추출한다.
-
기계 번역(Machine Translation): 한 언어를 다른 언어로 번역한다.
-
감정 분석(Sentiment Analysis): 텍스트에서 저자의 의견이나 감정을 분석한다.
NLP는 검색 엔진, 추천 시스템, 감정 분석, 챗봇, 음성 인식 시스템 등 다양한 분야에서 응용되고 있다. 이 분야는 언어의 복잡성과 모호성, 그리고 다양한 형태와 사용 방식으로 인해 여전히 활발하게 연구되고 있는 분야이다.
word2vec
Word2Vec은 자연어 처리(NLP) 분야에서 단어를 벡터로 변환하는 데 사용되는 예측 기반 모델이다. 이 모델은 고차원의 단어를 저차원의 벡터 공간에 매핑함으로써, 단어의 의미를 벡터로 표현한다. Word2Vec의 핵심은 비슷한 맥락에서 사용되는 단어들은 벡터 공간에서도 서로 가까이 위치한다는 점을 기반으로 한다.
Word2Vec에는 두 가지 주요 아키텍처가 있다.
-
Continuous Bag-of-Words (CBOW): CBOW 모델은 주변에 있는 단어들('context words')을 사용하여 중앙에 있는 타깃 단어를 예측한다. 이 모델은 주변 단어의 순서는 무시하며, 모든 주변 단어를 하나의 집합으로 취급하여 타깃 단어를 예측한다.
-
Skip-Gram: Skip-Gram 모델은 타깃 단어를 사용하여 주변의 단어들을 예측한다. 즉, 중앙에 있는 단어로부터 그 단어의 맥락을 형성하는 주변 단어들을 예측하는 방식이다. Skip-Gram은 CBOW에 비해 적은 양의 데이터에서 더 잘 작동하고, 더 많은 양의 훈련 데이터를 가진 경우에는 CBOW가 더 효율적이다.
Word2Vec 모델 특징
-
분산 표현(Distributed Representation): 각 단어는 벡터 공간에서 고유한 위치를 가지며, 이 위치는 단어의 의미를 포착한다.
-
단어 유사성(Word Similarity): 벡터 공간에서의 거리(유클리드 거리 또는 코사인 유사도)를 통해 단어 간 의미적 유사성을 계산할 수 있다.
-
차원 축소(Dimensionality Reduction): 원래 단어를 표현하는 데 필요한 차원보다 훨씬 적은 차원을 사용하여 표현한다.
-
효율적인 학습(Efficient Learning): Word2Vec은 신경망 기반 모델이지만, 효율적인 학습 알고리즘(예: 네거티브 샘플링) 덕분에 대규모 단어 집합에 대해서도 빠르게 학습이 가능하다.
-
Word2Vec은 유사한 단어를 찾거나, 단어 간 관계를 파악하는 데 사용될 수 있으며, 복잡한 NLP 작업에 있어 중요한 전처리 단계로 활용된다.
