[EuroSys'25] CacheBlend: Fast Large Language Model Serving for RAGwithCached Knowledge Fusion
ML System
4월에 EuroSys랑 ASPLOS를 다녀오면서 흥미 있게 들었던 논문 중에 하나다.
이 논문의 경우, EuroSys'25의 베스트 페이퍼로 선택 되었다.
RAG와 KV Cache
우선 CacheBlend는 기존의 Transformer의 KV Cache의 문제점을 지적하면서 시작한다.
Transformer 구조에서 Prefill 단계에서 계산 된 KV는 다음 Prefill과 decoding을 위해서 캐싱이 된다.
특히 자주 사용되는 System Prompt나, 특정 Context의 경우에는 빈번하게 사용 되기 때문에 캐싱을 해두는 것이 LLM의 inference tiem 개선에 큰 도움이 된다. 이렇게 자주 사용 되는 System Prompt / Context를 미리 캐싱을 하는 것을 CacheBlend에서는 Prefix Caching 이라고 부른다.
특히 이러한 사용 방식은 RAG에서 두드러진다. RAG는 보통 문서를 검색해서 검색한 내용을 Prompt 앞단에 패치 시킨다. 따라서 논문에서는 RAG를 타겟으로 Prefix Caching을 할 때의 문제점이 발생 할 수 있다고 주장한다. 아래 그림을 한 번 살펴보자.
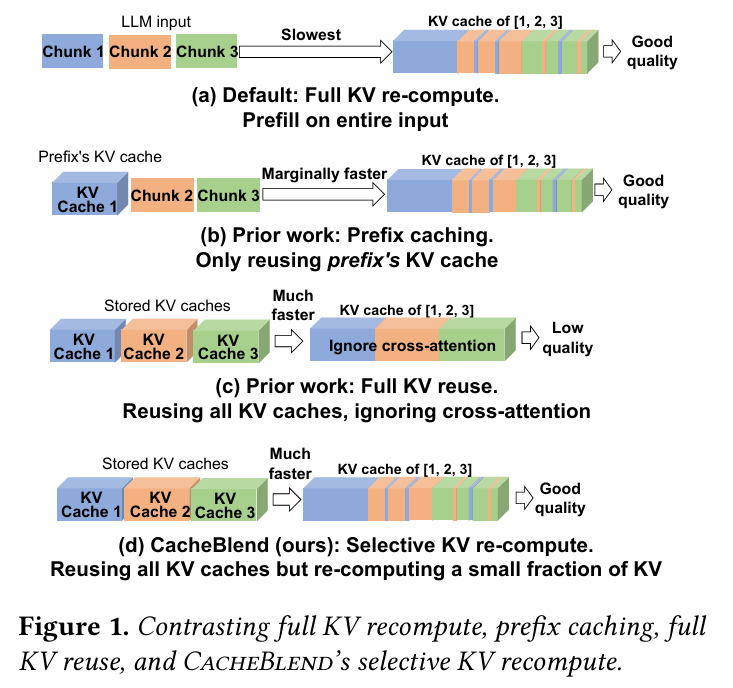
(a)번 그림은 모든 text chunk에 대해 KV cache를 Prefill 과정에서 모두 다시 계산하는 방식이다. 이는 각 text chunk 간의 위치를 다시 고려하여 계산하기 때문에 정상적인 퀄리티의 결과가 발생한다. 하지만 KV cache를 다시 계산하기 때문에 소요되는 시간은 느리다.
(b)번과 (c)번 그림은 이전 연구들이 사용하고 있는 방식에 대한 설명이다.
(b)번은 Prefix caching에 해당 되는데, 이는 첫번째 chunk만 Prefix로 고려하여 캐싱을 한다. 이는 정상적인 결과를 만들어 낼 수는 있지만, 첫번째 chunk만 prefix로 인식 되기 때문에 RAG처럼 text chunk가 많은 경우에는 적합하지 않다.
(c)번은 모든 chunk를 캐싱해버리는 방식이다. text chunk가 prefix가 아닌 경우에도 positional embedding을 조정하여 캐싱을 사용한다. 하지만 이 방식은 chunk들 사이의 cross-attention을 무시해버린다는 문제점이 있다. 그렇기 때문에 (a), (b)에 비해 속도는 빠르지만 결과의 퀄리티가 낮다는 문제가 있다.
따라서 CacheBlend에서 해결하고자 하는 문제는 (d)번 그림과 같다.
- LLM 입력에 여러 개의 text chunk가 포함 되어 있을 때,
- 각 text chunk를 사전에 KV Cache를 계산하고,
- 어떻게 결합해야 전체 prefill 계산을 수행 한 것 (a 그림처럼)과 같은 퀄리티를 뽑아낼 수 있을까?
Fast KV Cache Fusing
KV Deviation
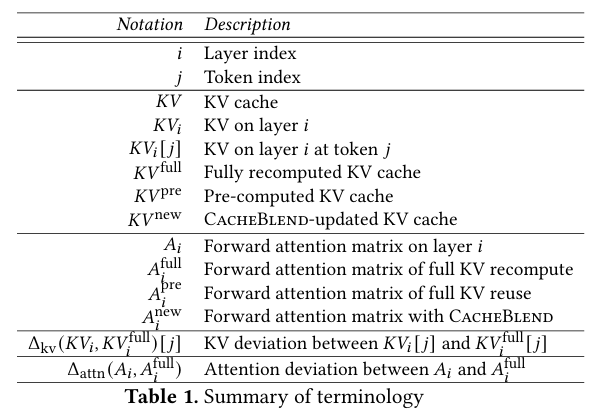
우선 CacheBlend가 어떻게 text chunk 계산을 수행하는지 알아 보기 전에, 몇가지 용어에 대해 이해하여야 한다. 특히 KV Deviation과 Attention Deviation에 대해 알아야 한다.
1) KV Deviation은 어떤 레이어 와 토큰 에 대해서, 주어진 KV 값이 원래 KV cache 값을 full-compute한 값 () 사이에 발생하는 차이를 절대값으로 표현한 지표이다.
즉, "각 토큰의 KV가 전체 prefill한 것과 얼마나 다른가" 를 나타내는 지표이다.
2) Attention Deviation은 레이어 의 forward attention matrix인 에 대해 전체 prefill로 full-compute한 attention인 값 사이의 L2 norm 차이값이다.
즉, "Attention이 full prefill 한 것과 얼마나 다른가" 를 나타내는 지표이다.
Selective Recomputing KV Cache
CacheBlend의 아이디어는 KV Cache를 계산 할 때, 일부 토큰에 대해서만 선별적으로 재계산 하고, 나머지 토큰의 KV cache는 재사용 하는 전략이다.
CacheBlend는 어떤 토큰의 KV cache를 재계산 할 것인지, 아니면 재사용 할 것인지를 결정하기 위한 메트릭으로 앞서 설명한 KV Deviation과 Attention Deviation을 사용한다.
단순하게 생각해본다면, 모든 토큰에 대해 편차를 알아 낼 수만 있다면 그 값이 큰 것을 우선적으로 재계산 하면 될 것이다. (편차가 크다는건 결국 오차가 크다는 말이니까.) 하지만 저자는 이 방식은 결국 전체 prefill 된 KV cache를 알아야 하기 때문에 실제로는 적용하기 어려운 방법이라면서 더 실용적인 방법을 제안한다.
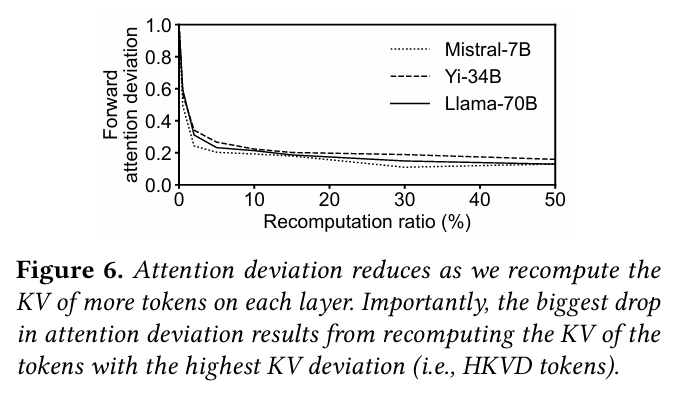
우선 저자들은 각 모델에 대해서 Recomputation 비율을 증가시키면서 Attention deviation을 측정하였다고 한다. 재계산을 수행하는 비율이 커질수록 KV Deviation이 큰 토큰들을 재계산 하기 때문에 당연히 Attention deviation은 점차 낮아지게 된다.
이 과정에서 저자들은 한 가지 인사이트를 발견하게 된다. KV deviation이 큰 토큰일 수록 개선되는 Attention Deviation도 커진다. 따라서 그러한 토큰을 HKVD (High-KV-Deviation) 토큰이라고 정의하기로 한다.
결국 재계산의 타겟이 되는 토큰은 이러한 HKVD 토큰이 될 것이다. 그리고 실험적으로, 10~20% 정도만 HKVD 토큰으로 지정해도 Attention Deviation이 크게 개선이 되는 것을 위 그래프로 알 수 있었다. 그렇다면 왜 이런 현상이 나타나는걸까?
Attention Sparsity
이 내용의 경우에는 CacheBlend에서 이전 연구에 대해 짧게만 설명한다. 결국 Attention Sparsity라는 것 때문에 10~20%의 HKVD 설정으로도 Attention 편차가 크게 감소한다.
Attention Sparsity라는 것은 한 마디로, 일반적으로 높은 Attention 값은 일부 소수의 토큰과 그 토큰이 참조하는 이전 토큰들 간에만 집중 된다는 것이다.
어떻게 보면 당연한 얘기인 것이, 아래 예시로 설명을 하자면,
"오늘은 날씨가 좋아서 기분이 좋다." 라는 문장이 있다고 가정을 하자.
1) 그렇다면 "좋다"이라는 토큰은 "기분"에 강한 attention을 받았을 것이다.
2) 반면에 "오늘은"이라는 토큰에는 약한 attention을 받았을 것이다.
그렇기 때문에 어떤 레이어에서 HKVD가 발생했다면, 그 다음 레이어에서도 그 토큰이 HKVD일 확률이 높다. (개인적으로 이 내용을 듣고 이마를 탁 칠 수 밖에 없었다.)
아래 그래프는 이를 뒷받침 하는 근거로, 각 모델에서 두 레이어 사이의 KV 편차의 상관 관계를 보여준다.
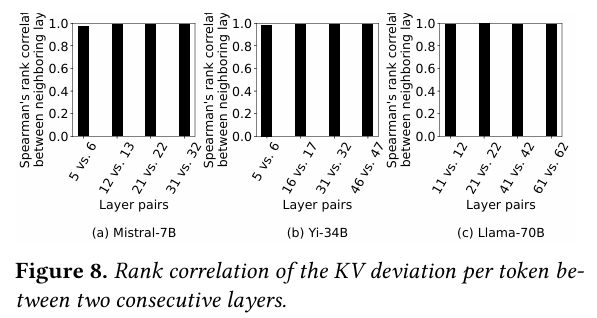
Transformer는 각 레이어에서 추론을 수행 할 때, token의 input embedding의 변화가 작다. KV 값은 이러한 embedding을 Linear Transform을 통해 생성 되기 때문에 KV cache도 레이어 사이에서 유사한 구조를 계속해서 유지하게 된다. 바로 이러한 특성으로 인해 앞 레이어에서 발생한 HKVD 토큰이 뒤에서도 HKVD 토큰이 될 수 있다는 것이다.
단, 이는 레이어가 깊어질수록 상대적으로 얕은 레이어에 비해 input embedding 변화가 클 수 있기 때문에 예측 정확도는 떨어질 수 있다는 유의점이 있다.
CacheBlend Workflow
아래 그림은 기본적인 prefill 계산과 CacheBlend의 Selective Recomputation을 비교한다.
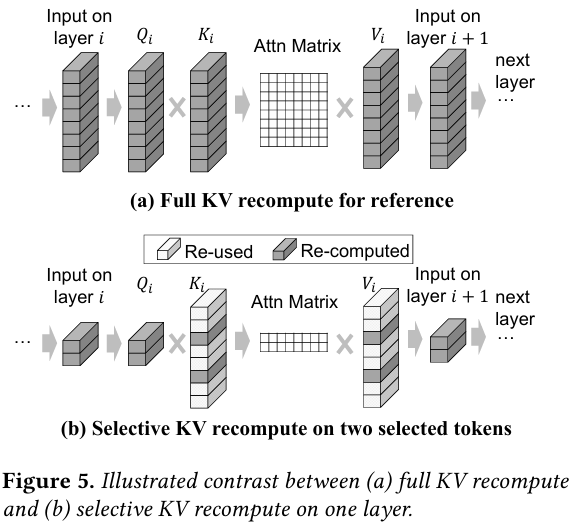
- 먼저 각 레이어의 입력에 대해 masking을 수행하여 HKVD 토큰만 남긴다.
- 1번에 의해 줄어든 입력을 기반으로 Q, K, V 벡터를 만든다. 이 때, K, V 벡터는 선택되지 않은 토큰에 대해서 기존 KV cache를 재사용한다.
- 다음 레이어로 넘어갈 때, 다시 HKVD 토큰만 남긴다.
Selective KV Recomputation Overhead
그렇다면 HKVD를 첫 레이어에서 선별 할 때 발생하는 오버헤드는 어떨까?
기본적으로 Selective Recomputation을 하는 속도가 KV를 GPU 메모리로 로드 하는 속도보다 빠르다면, 두 작업을 pipelining 하는 방식으로 지연을 숨길 수 있다.
이는 토큰 재계산 여부를 결정하는 것은 이전 레이어의 KV deviation이 결정하기 때문이다.
따라서, 어떤 레이어가 KV cache를 로딩 하는 동안, 다음 레이어는 동시에 KV recomputation을 수행할 토큰을 결정하여 KV recomputation을 동시에 수행 할 수 있다.
그렇다면 전제가 뒤바뀌면 어떨까? (KV GPU load time < Selecive Recomputation)
저자는 이를 위해서 Llama-70B 모델에서 실험을 진행하였다. 15% 비율의 recomputation에 7ms가 걸린 반면, 한 레이어의 KV cache를 NVMe SSD -> GPU 방향으로 로딩 할 때 4ms가 소요 되었다고 한다. 그래서 이 경우에 recomputation을 추가적인 latency가 발생했다고 한다. 그렇기 때문에 저자는 추가로 KV cache의 저장 위치를 동적으로 결정 할 수 있는 컨트롤러가 필요하다고 설명했다.
CacheBlend System Design
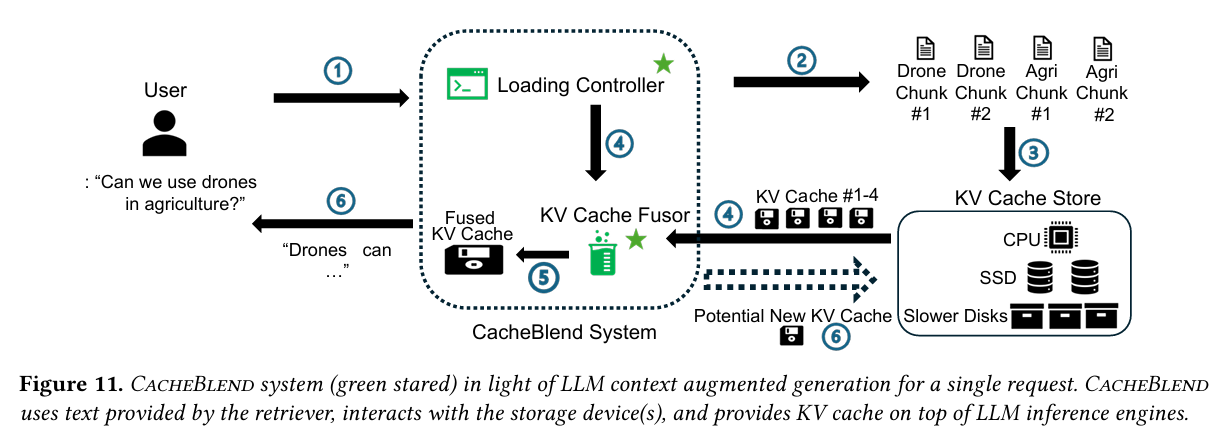
앞서 설명한 KV Cache Load Controller의 필요성과 Selective Recomputation의 메커니즘을 종합하여 CacheBlend는 위와 같이 system design을 구성했다.
각 컴포넌트는 다음과 같은 역할을 수행한다.
Loading Controller
Loading controller는 2가지 역할을 수행한다.
- 각 레이어에서 recompuation을 수행하는 token의 비율을 정한다.
- KV를 저장할 저장 장치를 어떤 것을 사용할지 정한다.
우선 recomputation 비율을 찾기 위해서, Loading contorller는 2개의 delay estimator를 사용하여, recomputation overhead가 KV loading delay와 비슷한 수준이 되도록 하는 비율을 계산한다. 이를 수식으로 다음과 같이 표현한다.
이 때, 각 값은 아래와 같이 산정이 되며, 각 계산 값들은 offline profiling에 의해 값을 추정해낸다.
여기서 은 loading하는 context의 길이 이고, 값이 Loading Controller에서 구하고자 하는 recomputation 비율이다. CacheBlend는 이 값을 품질 저하가 미미한 최소 recomputation 비율인 값과 비교하여 더 큰 값을 선택한다. (값은 15%가 적절하다고 실험적으로 발견하였다고 한다.)
그 다음, KV 저장 장치를 선택하기 위해서, Loading Controller는 configuration을 통해 후보 저장 장치 리스트를 받아서 선택 한다. 고정된 recomputation 비율이 정해져 있다면, Load Controller는 다음 수식과 같은 방식으로 저장 비용을 추정한다.
이 때, 값은 저장 시간을 의미하고, 를 만족하는 저장 장치 중에서 가장 저렴한 저장 장치를 선택한다.
KV Cache Store
KV Cache Store는 LLM의 입력을 여러 개의 text chunk로 분할한다.
예를 들어, RAG 입력의 경우에는 보통 고정된 길이의 검색 된 context chunk와 사용자의 질문으로 구성 된다.
입력 값들의 분할이 완료 되면, 각 chunk는 해시 처리가 되어 KV cache를 찾는다. 이 때 사용하는 해싱 방식은 vLLM과 동일한 Block Hashing을 사용한다.
새로운 chunk라면 Fusor에 의해 생성 된 KV Cache를 저장 장치에 추가되고, 만약 저장 장치가 가득 찬 경우에는 LRU에 의해 eviction이 수행 된다.
Fusor
Cache Fusor는 selective recomputation을 통해 사전에 계산 된 KV cache들을 반영하는 역할을 한다.
어떤 토큰이 재계산 될 지는 앞서 언급했듯이 이전 레이어의 재계산 결과를 따르기 때문에, 이전 레이어의 재계산이 완료 될 때까지 Fusor는 기다려야 한다.
이 후, KV cache가 GPU memory 큐에 로드 되면, Loading Controller에서 계산한 값을 이용하여 selective recomputation을 수행한다. 그리고 이 과정을 모든 레이어에서 재계산 될 때까지 반복한다.
CacheBlend Component Workflow
- 사용자는 LLM에 질문을 던진다. 그러면 retriever를 통해 관련된 text chunk가 조회 된다.
- Loading Controller는 해당 text chunk들의 KV cache가 존재하는지, 어느 저장 장치에 저장 되어 있는지 찾는다.
- Loading Controller는 selective recomputation 비율을 계산한다.
- Fusor는 KV cache들을 GPU 메모리 큐에 로드한다.
- Fuser는 큐에 있는 KV cache들에 대해 재계산을 수행하고, 이를 모든 레이어가 재계산 될 때까지 계속한다.
- fusing이 완료 된 KV cache가 LLM inference engine에 입력이 되고 이를 기반으로 응답을 생성한다.
Evaluation
앞에서 CacheBlend의 각 컴포넌트와 어떻게 KV Cache를 모두 재계산 하지 않고 RAG의 품질을 높일 수 있는지 살펴보았다. Evaluation 섹션에서는 이에 대해 어떻게 실험하고, 정량적으로 어떤 성과를 보였는지 나타내고 있다.
실험에 사용한 모델로는 Mistral-7B, Yi-34B, Llama-70B를 사용하였고, 데이터셋은 2WikiMQA와 Musique, SAMSum, MultiNews를 사용하였다고 한다.
Baselines
CacheBlend의 성능을 비교하기 위해서 사용한 다른 베이스라인들을 다음과 같다.
- Full KV Recomputation : raw text를 LLM에 그대로 입력하는 방식을 사용했다고 한다.
- Prefix Caching : SGLang
- Full KV Cache Reuse : PromptCache
- MapReduce : LangChain에서 사용하는 RAG 기법으로, LLM이 각 chunk를 요약하고 하나로 이어 붙여서 다시 LLM에 입력하는 방식
- MapRerank : LangChain에서 사용하는 또다른 RAG 기법으로, LLM이 각 chunk별로 독립적인 답변을 생성 한뒤, 가장 높은 confidence score를 채택하는 방식
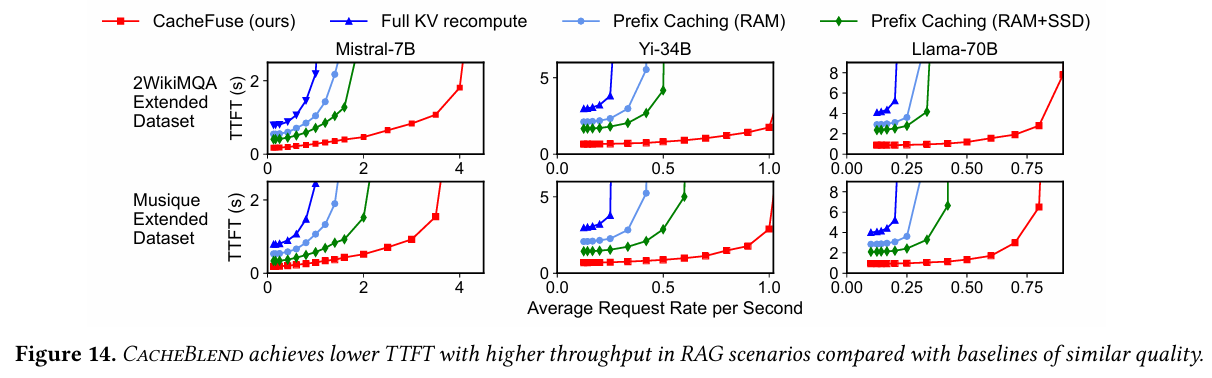
TTFT
TTFT의 경우, 2.2x ~ 3.3x까지 감소 되었다고 한다.
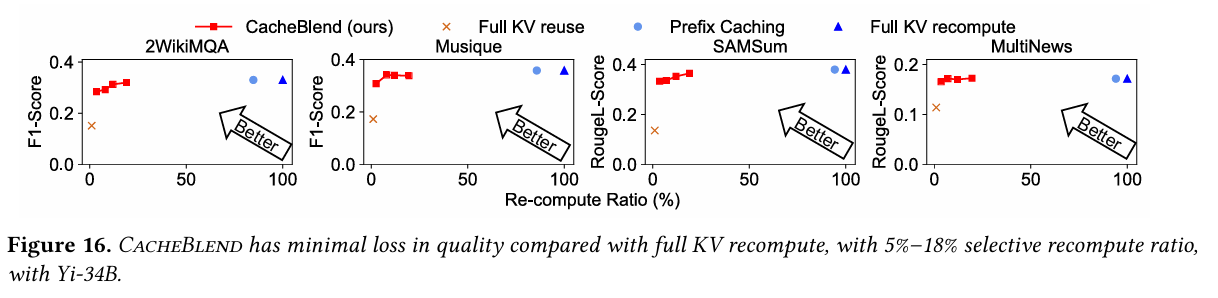
Quality
CacheBlend는 품질 측정을 위해서 F1과 Rouge-L 점수를 사용하였다.
Full KV reuse에 비교해서 0.15 ~ 0.35까지 성능이 향상 되었다. 반면 full computation이나 prefix caching과 비교하여 품질 저하는 0.01 ~ 0.03 수준 밖에 저하 되지 않았다고 한다.
결론 및 고찰
결론적으로 CacheBlend는 모든 KV cache를 재사용하거나 재계산 하지 않고 선택적으로 하는 것, 그리고 그걸 선택하는 기준에 대해서 novelty가 있다고 판단 되어 accept이 된 것으로 보인다.
EuroSys에 막상 가서 이 논문에 대해 들을 때는 KV deviation에 대해 막연하게만 생각했었는데, 막상 글로 작성해보니 생각보다 쉬운 개념인데 비해 이걸 계산하는데 필요한 코스트 최적화를 굉장히 잘 이끌어냈다는 생각이 들었다. (베스트 페이퍼 할만 하다...)
사내 팀에서도 RAG팀과 협업을 하는 부분이 많고, 특히 우리 팀이 LLM serving을 담당하는 만큼 이걸 직접 올려서 사용해보는 것도 나쁘지 않겠다는 생각이 들었다. 근데 과연 사내 LLM이 CacheBlend 호환이 될까..?
CacheBlend는 LMCache라는 오픈소스에 포함이 되어 있고, 이는 vLLM과 연계하여 사용 할 수 있다.
LM Cache Github
https://github.com/LMCache/LMCache
vLLM Document for LMCache
https://docs.vllm.ai/en/latest/examples/others/lmcache.html
