ML System
1.[EuroSys'25] CacheBlend: Fast Large Language Model Serving for RAGwithCached Knowledge Fusion
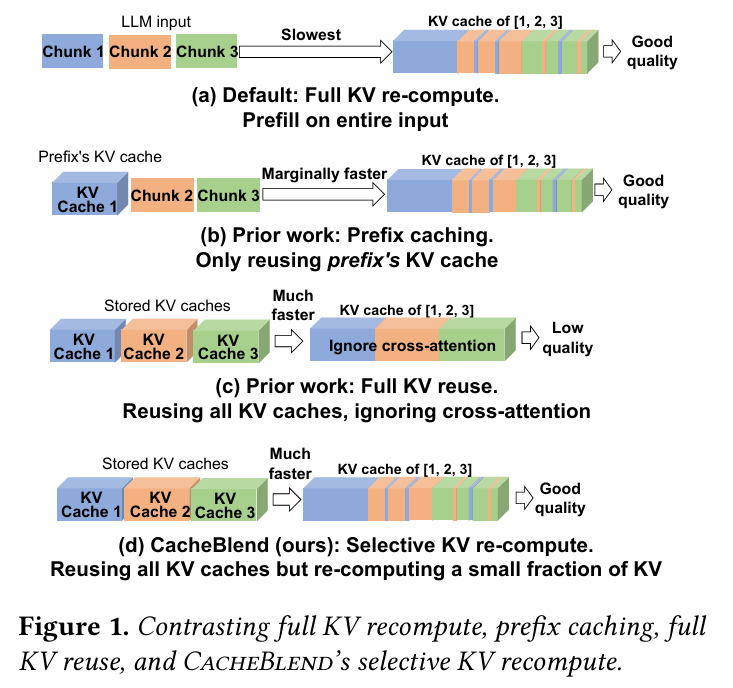
4월에 EuroSys랑 ASPLOS를 다녀오면서 흥미 있게 들었던 논문 중에 하나다.이 논문의 경우, EuroSys'25의 베스트 페이퍼로 선택 되었다.https://dl.acm.org/doi/10.1145/3689031.3696098우선 CacheBlend는
2.[MLSys'25] FlexInfer: Flexible LLM Inference with CPU Computations
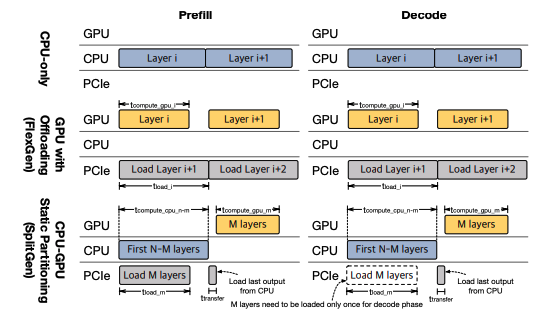
오늘 리뷰 할 논문은 올해 MLSys에 올라온 FlexInfer라는 논문이다. 이 논문은 LLM Serving을 CPU와 GPU로 나누어서 수행하는 방법에 대해 소개 하고 있다. 예전부터 CPU inference 관련해서도 관심이 많았는데, LLM은 대부분 KV cac
3.[SIGCOMM'25] MegaScale-Infer: Serving Mixture-of-Experts at Scale with Disaggregated Expert Parallelism
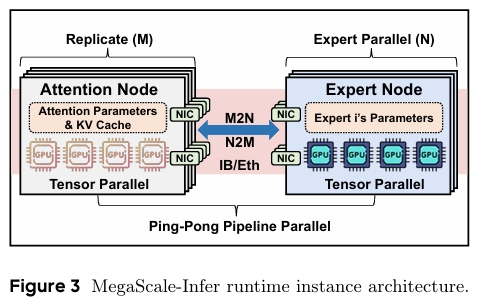
얼마 전 카카오에서 발표한 Kanana-MoE도 그렇고, NVIDIA의 주가를 3% 가량 떨어뜨린 DeepSeek도 그렇고 MoE를 적용한 모델 연구가 계속 이루어지고 있다. 그와 더불어 MoE 자체의 특성을 이용하여 추론에 활용하는 연구도 동시에 진행 되고 있는데,
4.[SOSP'25] PrefillOnly: An Inference Engine for Prefill-only Workloads in Large Language Model Applications
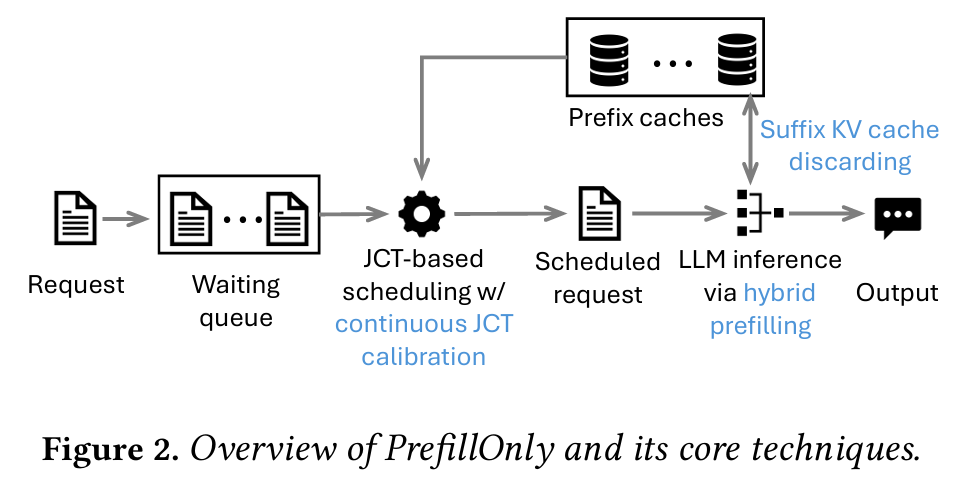
최근에 Agentic AI에 들어가는 Safety 모델을 사내에 도입하면서, 특정 LLM의 경우 binary 결과만 내보내는 모델을 많이 보았다. 특히 카카오에서 만든 kanana safeguard가 그런 예시 중에 하나였다. kanana safeguard의 경우, 들
5.[SOSP'23] Efficient Memory Management for Large Language Model Serving with PagedAttention
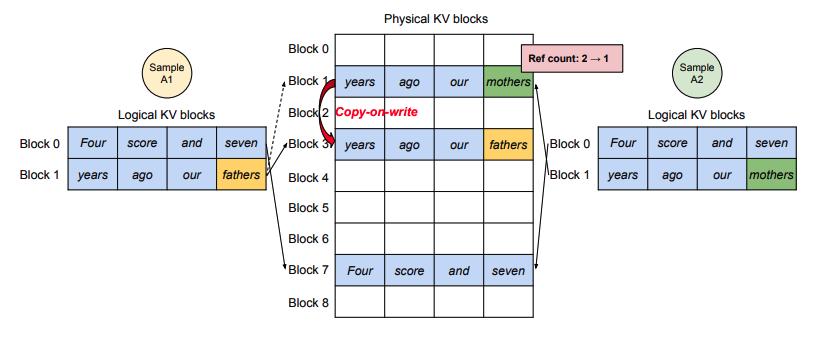
vLLM은 industry/academy를 막론하고 거의 LLM inference의 표준 프레임워크로 자리 잡았다. 사내에 만드는 모든 LLM inference engine으로 vLLM을 사용하고 있고, 내부 코드까지 확인하고 오픈소스 기여까지 시도 할만큼 많은 관심을
6.[ASPLOS'25] vAttention: Dynamic Memory Management for Serving LLMs without PagedAttention
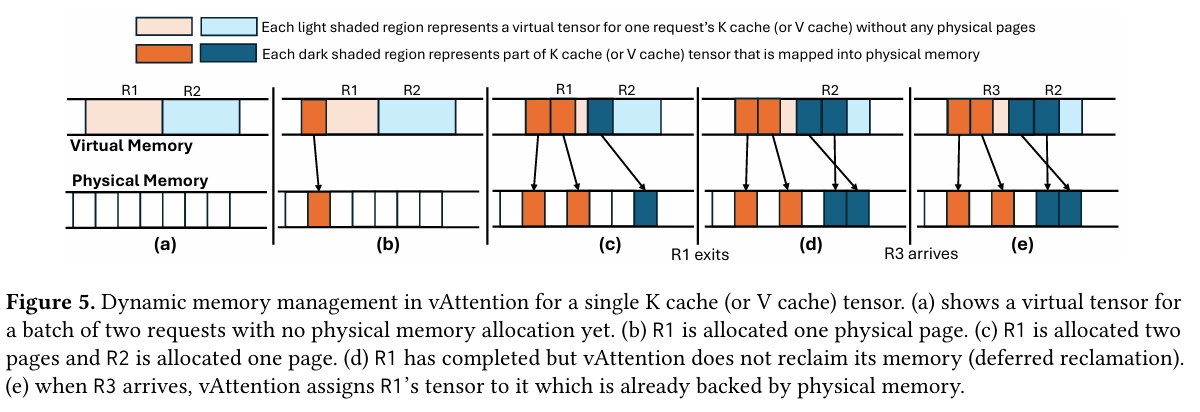
올해 4월 초에 EuroSys와 ASPLOS를 다녀오면서 거기서 꽤 재밌는 논문들을 많이 소개 받았다. 이전에 리뷰 했던 CacheBlend도 재밌었지만 vAttention 역시 굉장히 흥미로운 주제로 느껴졌던 논문이였다. 최근에 vLLM의 근간이 되었던 Paged A
7.[SOSP'25] JENGA: Effective Memory Management for Serving LLM with Heterogeneity
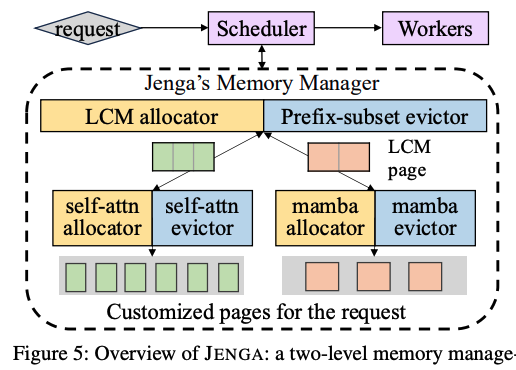
최근 vLLM을 언급한 여러 논문을 보면서, vLLM이 오픈소스로써 가지는 장점에도 불구하고 LLM의 발전으로 인해 모델 포팅에 있어서 여러 제약 사항이 발생하는 것을 보았다. 이전에 vAttention이 언급한 PagedAttention의 메모리 할당 방식이 가지는
8.Utility-Driven Speculative Decoding for Mixture-of-Experts
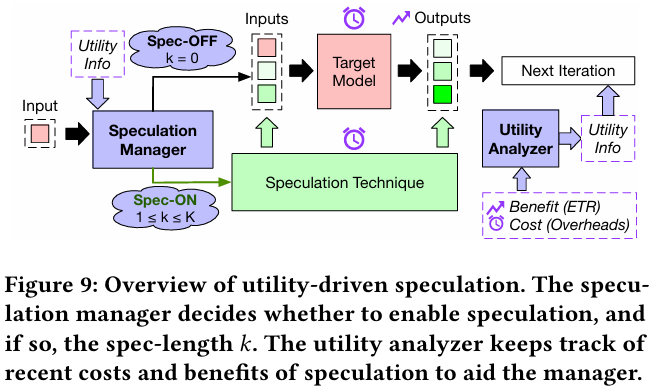
오늘은 간만에 시스템쪽 논문을 가지고 왔다. 한번쯤 speculative decoding 기능을 속도 향상 여부에 따라 on/off를 한다거나, speculative length 파라미터를 동적으로 조정하는 아이디어를 생각해본 적이 있을 것이다. 이 논문은 specul
9.[SOPS'25] IC-Cache: Efficient Large Language Model Serving via In-context Caching
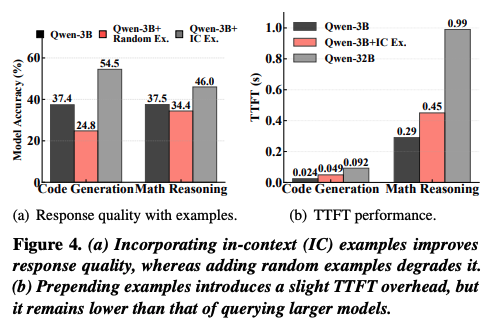
최근 speculative decoding에 주력해서 논문을 읽다보니까 시스템 관련한 논문을 많이 읽지 못한 것 같다. 그래서 오늘은 SOSP에서 context caching 관련하여 논문을 가져왔다. 요새 회사에서 LLM을 클러스터 단위로 서빙해야 할 일이 많다. 그
10.Expert-as-a-Service: Towards Efficient, Scalable, and Robust Large-scale MoE Serving
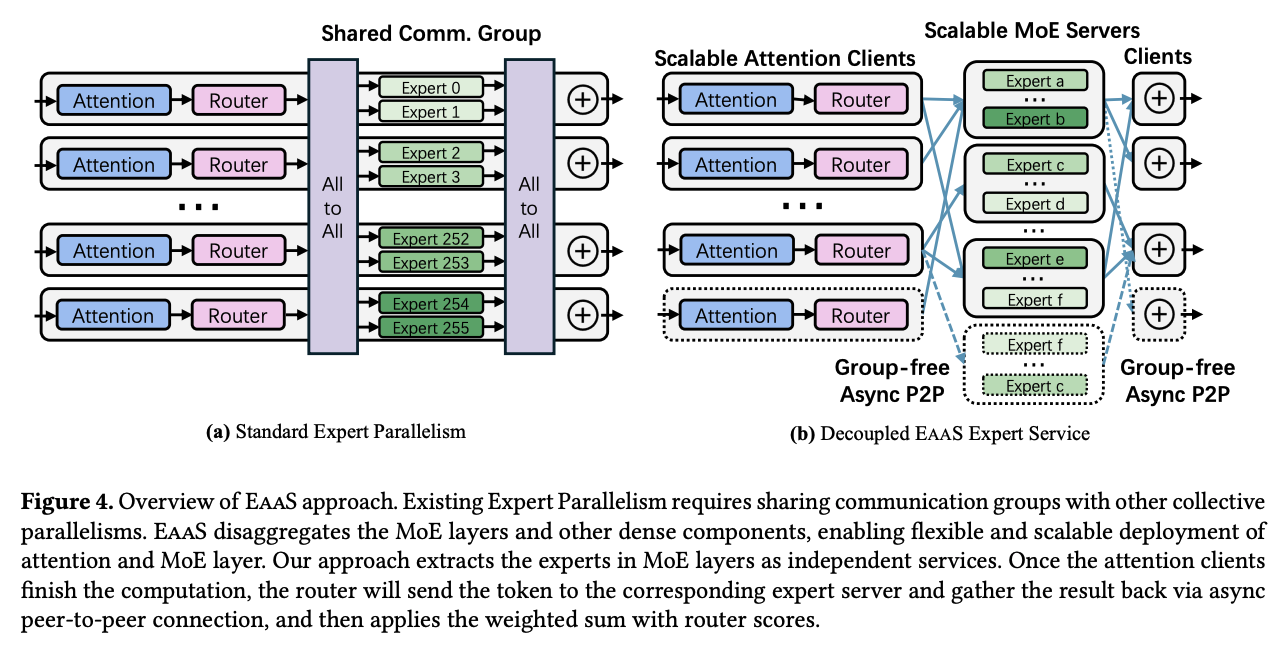
그동안 WBL 작업이랑 ICML 논문 제출로 인해 블로그 관리에 너무 소홀한 것 같다. 그래서 간만에 준비한 내용으로 MoE랑 ML system 관련한 논문을 준비했다. 어딘가 아직 학회에 올라온 내용은 아니고, 아직은 아카이브에만 떠돌고 있는 논문으로, WBL을 하면