오늘 리뷰 할 논문은 올해 MLSys에 올라온 FlexInfer라는 논문이다. 이 논문은 LLM Serving을 CPU와 GPU로 나누어서 수행하는 방법에 대해 소개 하고 있다. 예전부터 CPU inference 관련해서도 관심이 많았는데, LLM은 대부분 KV cache offloading 외에는 GPU에서 추론 하는 방법 밖에 보지 못한 것 같다. 아무튼 나에게는 너무나도 자극적인 제목이라 보자마자 내용을 정리 해보고 싶었다.
LLM Inference에서 GPU의 한계
아마 TPU나 특수한 NPU를 제외한다면, 현재까지는 GPU를 사용하여 LLM을 학습/추론 하는 것이 유일한 방법일 것이다. 이제는 GPU도 예전과는 다르게 단순히 SIMD 처리를 넘어서, Tensor 연산에 특화 된 Tensor Core를 장착하는 등, ML 워크로드를 최적화 시키기 위해 하드웨어에도 온갖 방법을 때려 넣고 있다.
이러한 연산 속도 개선에도 불구하고, GPU는 여전히 메모리 문제에 시달리고 있다.
만약 GPT 계열 중에 175B의 파라미터를 가진 LLM을 GPU에 로드하기 위해서는 하이엔드급 GPU인 H100이 5장 가량 필요하다. 물론 이는 순전히 모델 로드만을 위한 최소 요구치이다. Batch size, KV cache 할당을 위한 메모리는 절대 조상님이 내려주는 것이 아니다.
Memory Offloading
위와 같은 문제점을 해결하고자, 기존의 논문들은 KV Caching에 사용 되는 메모리를 GPU가 아닌 CPU로 offload 하고, 필요 할 때마다 GPU로 올려서 사용하는 방식들을 적용했다. 그러나 이번에는 PCIe의 bandwidth 문제로 인해 overhead가 발생한다는 문제점이 있었다.
또다시 이를 해결하기 위해서, 계산과 메모리 전송을 overlap 시키는 연구들도 있었지만, 대부분 GPU의 계산 속도가 PCIe 메모리 전송에 비해 굉장히 빠르기 때문에 I/O bottleneck이 여전히 존재했다.
그 예시로, 이 논문의 저자는 당시 offload 기술의 SOTA인 FlexGen을 분석했고, 전체 실행 시간의 96~98% 가량이 PCIe 전송에 소요 되는 것을 발견했다.
다른 해결 방법으로는 Model Parallelism이 있었지만, 이는 모델마다 구현 방식이 달라 배포 비용이 크고, 최적화가 대체로 잘 이루어지지 않는다는 단점이 존재한다.
Intel AMX
이러한 상황 속에서, 저자는 Intel의 AMX라고 불리는 CPU 내 GEMM (General Matrix to Matrix) 연산에 주목했다. 최신 CPU는 CPU 내부에서 GEMM 연산이 가능한 유닛을 통해 추론 부분에서 뛰어난 성능을 보일 수 있음을 입증한 사례가 있었다고 한다.
보통 ML inference의 경우, 대부분의 작업을 GPU에게 실행 시키고 CPU는 놀고 있고, 메모리도 일반적으로 GPU보다 많은 양을 확보 할 수 있기 때문에 저자는 GPU와 CPU를 하이브리드 형태로 LLM 추론에 사용 할 수 있다고 주장한다.
FlexInfer는 이러한 배경에서 시작했다.
Prefill과 Decoding
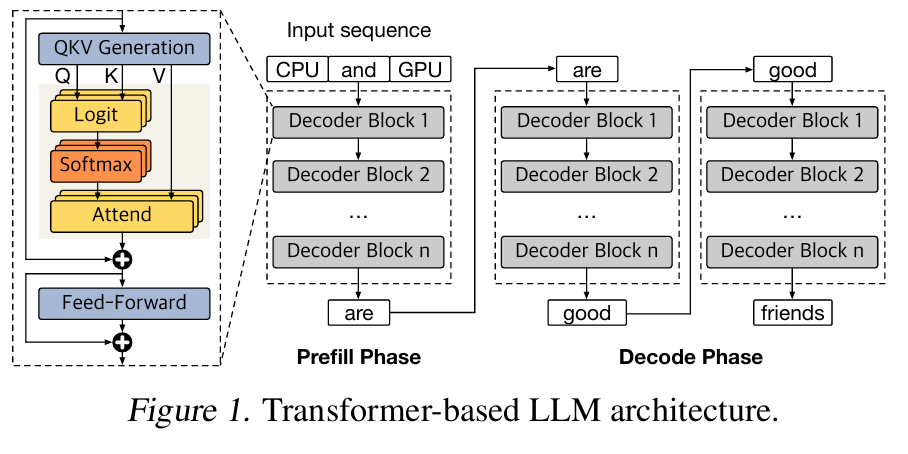
LLM 추론은 Prefill과 Decode, 2가지 단계로 나뉜다. 이에 대한 설명은 이전에 Transformer 리뷰에서 자세하게 다뤘었으니, 오늘은 짧게만 언급 하고 지나가겠다.
Prefill
모델이 처음 입력 프롬프트를 받아서 전체 입력 시퀀스에 대해 Attention을 계산하는 단계이다.
입력 시퀀스 길이에 제곱으로 계산 복잡도가 정의 되고, 전체 입력 시퀀스에 대해 Attention 연산을 수행하기 때문에, Computation-Bound 작업이다.
Decoding
Prefill 완료 후, 모델은 decoding 단계에서 max sequence length에 도달하거나, 특정 stop token을 만들 때까지 한 번에 하나씩 토큰을 생성한다. 이 때, Prefill에서 생성 된 KV cache를 꺼내서 사용하여, 불필요한 Attention 연산을 줄여주게 된다. 이러한 특성으로 인해, decoding 단계는 일반적으로 Memory-bound 성격을 띈다.
CPU Inference
최근 일부 CPU 제조사들은 ML Inference를 위해서 matrix multiplication을 위한 특수한 하드웨어를 탑재 하고 있다. 그 대표 주자 세 곳이, Intel, AMD, IBM이다.
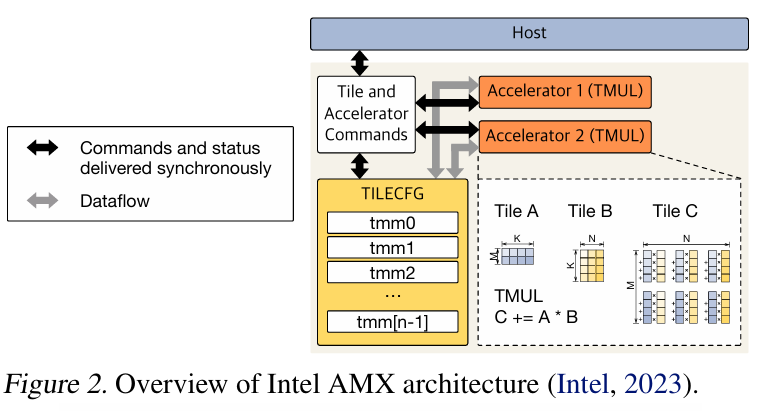
그 중, FlexInfer에서는 Intel의 AMX 아키텍쳐에 대해서만 소개한다.
중요하게 볼 것은 위 그림에서 TMUL라고 불리는 Tile Matrix Multiply Units, 그리고 Tiles라고 되어 있는 부분이다. TMUL은 BF16 및 INT8 데이터 형식에 대한 행렬 연산을 기존의 CPU 코어보다 빠르게 수행 할 수 있는 유닛이다. 그리고 Tile은 기존 CPU 레지스터와 다르게 2차원 행렬 데이터 저장을 위한 전용 레지스터이다.
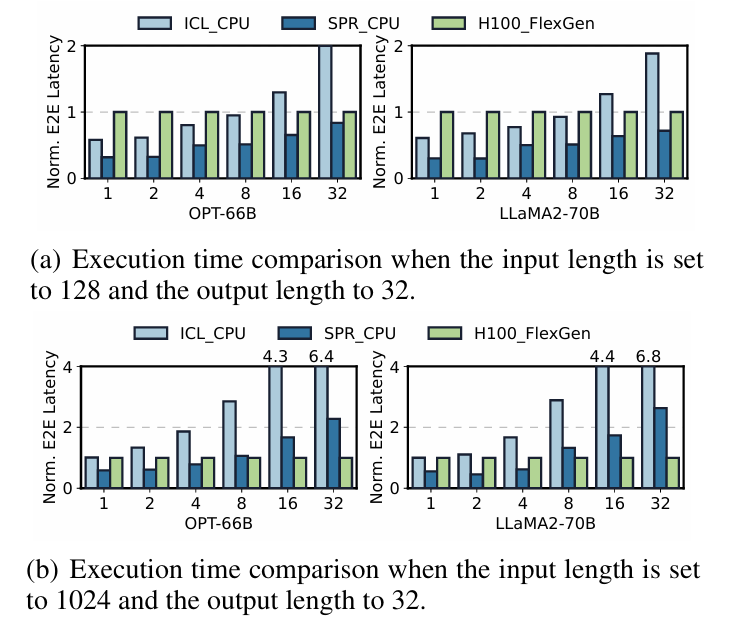
그렇다면 AMX 연산을 이용해서 LLM 추론을 수행하면 GPU 대비해서 얼마나 빨라질까?
이를 수행하기 위해서 논문 저자는 AMX 연산을 지원하지 않는 CPU(ICL)와 지원하는 CPU(SPR), 그리고 이전 연구인 FlexGen과 함께 H100을 사용하여 추론 한 결과를 비교하였다.
Batch size가 작고, input의 길이가 작은 경우에는 FlexGen에 비해 CPU 추론이 상대적으로 빠르지만, Batch size가 커지고 input의 길이가 커지면 H100과 FlexGen의 조합이 더 성능이 좋다. 다만, AMX 연산을 지원하는 CPU의 성능을 봤을 때, batch size가 작은 상황()에서 H100 + FlexGen 조합에 비빌 수 있을만큼 성능이 나오는 것을 볼 수 있었다.
참고로 저 그래프를 보고 H100이랑 CPU가 비빈다고?! 라고 할 수 있을 것 같은데, 이는 어디까지나 CPU offload를 사용하는 FlexGen과 동시에 사용 할 경우이다. 만약 GPU가 모든 KV Cache를 감당 할 수 있을 정도로 메모리가 넘친다면, 아마 H100의 성능이 월등하게 나올 것이다.
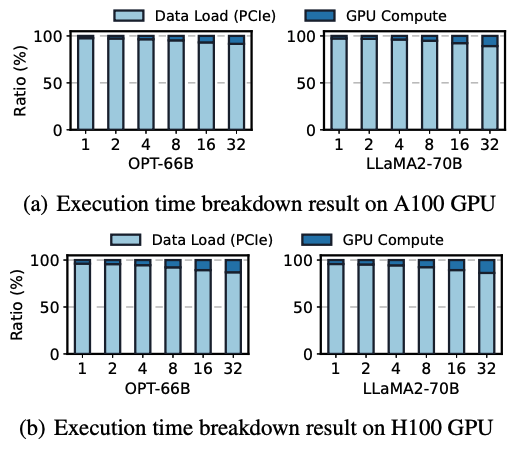
그 예시로, 위 그래프는 FlexGen을 breakdown 시킨 결과인데, 대부분의 경우 PCIe를 이용한 Host <-> Device 간의 메모리 이동에 많은 거의 96%에 가까운 시간을 사용하고 있다.
결론적으로 저자가 말하고 싶은 것은, 일정 조건 하에서 CPU offload를 KV caching에 이용하는 전략을 사용 할 때, CPU 추론이 매우 유용 할 수 있다는 것을 보여준다. CPU가 일반적으로 GPU에 비해 월등하게 큰 메모리를 가지고 있기 때문에 메모리 제약 해소에는 유용하지만, 범용적인 성능은 GPU에 미치지 못하기 때문에, 하이브리드로 접근하는 전략이 필요하다고 제안한다.
Prefill vs Decoding 무엇이 CPU에서 이득을 보는가?
위 내용들을 토대로, LLM 연산에서 다음 조건을 만족 할 때, CPU 연산이 GPU 보다 이득을 보는 사례를 발견했다.
- 모델의 크기가 하나의 GPU 메모리로 커버하기 어려운 경우
- 배치 사이즈가 작고, 입력 길이도 작은 경우
그렇다면 이번에 알아봐야 할 것은, LLM 연산의 어느 부분이 CPU 연산과 GPU 연산 중에 이득을 더 볼 수 있는가다. 앞서, Transformer 구조에는 Prefill과 Decoding 단계로 나눌 수 있고, 각각의 특성이 다르다는 것을 소개했었다. 일반적으로 Prefill의 성능을 측정하기 위해서는 TTFT (Time-To-First-Token) 메트릭을 이용하여 측정 할 수 있고, Decoding의 성능을 측정하기 위해서는 TPOT (Time Per Output Token)을 이용해서 측정 할 수 있다.
다음은 두 메트릭을 이용하여, CPU 연산과 H100 + FlexGen 조합을 측정한 결과이다.
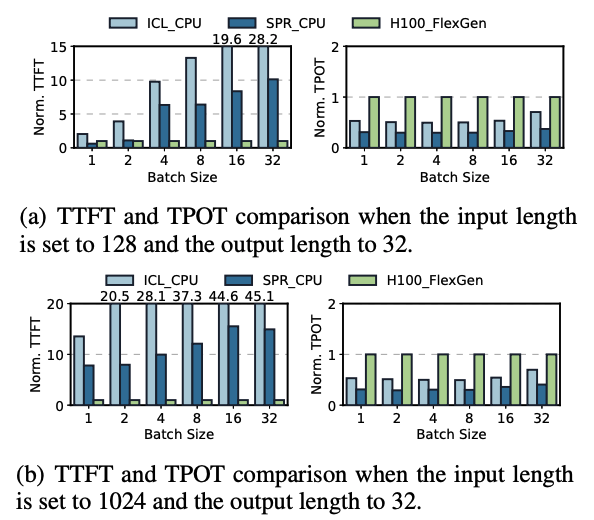
(a) 그래프는 input 길이가 작을 때, TTFT와 TPOT의 경향성을 보여준다. TTFT의 경우, H100 + FlexGen에 비해 CPU 연산의 효율이 굉장히 낮은 것을 볼 수 있다. 반면 TPOT의 경우, CPU 연산의 효율이 좋은 것을 볼 수 있다.
(b) 그래프는 input의 길이가 긴 경우인데, 이 케이스에서도 TTFT와 TPOT의 경향성이 (a)와 유사하게 TTFT에서는 CPU 연산의 효율이 떨어지지만 TPOT에서는 좋다는 것을 발견 할 수 있다.
위 사실을 통해, 논문에서는 다음의 결과를 도출 할 수 있었다.
- Prefill에서는 병렬처리가 가능한 GPU의 연산의 효율이 좋다.
- Decoding에서는 KV Cache의 offload로 인해 발생하는 PCIe 병목으로 인해 CPU 연산의 효율이 좋다.
결국 위 사실들을 조합했을 때, FlexInfer에서 추구하는 CPU와 GPU의 하이브리드 연산 방식은, Prefill 연산은 GPU가 수행하고, Decoding 연산은 CPU에서 사용하자! 일 것이다.
FlexInfer
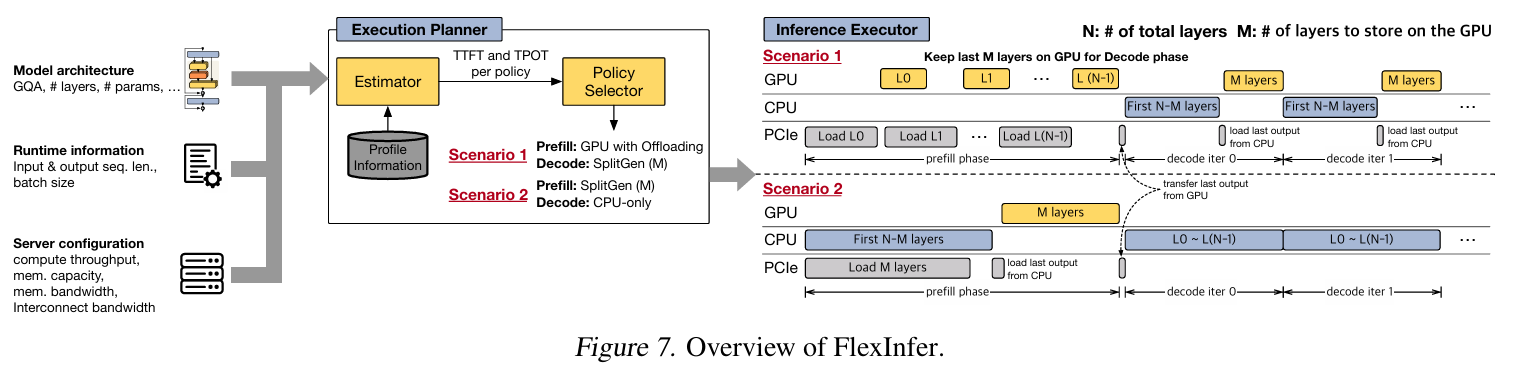
FlexInfer의 구성은 위와 같이 Execution Planner와 Inference Executor로 나누어진다.
우선 각각의 컴포넌트 역할과 동작을 알아보기 전에, FlexInfer에서 지원하는 Execution Policy들을 먼저 알아보자.
Execution Policies
FlexInfer는 GPU와 CPU를 이용하여 하이브리드 연산을 하기 위한 정책을 기본 3가지로 분류하여 사용하고 있다.
- CPU-only
- GPU + offloading
- SplitGen (이라고 부르는 CPU-GPU 정적 분할 정책)
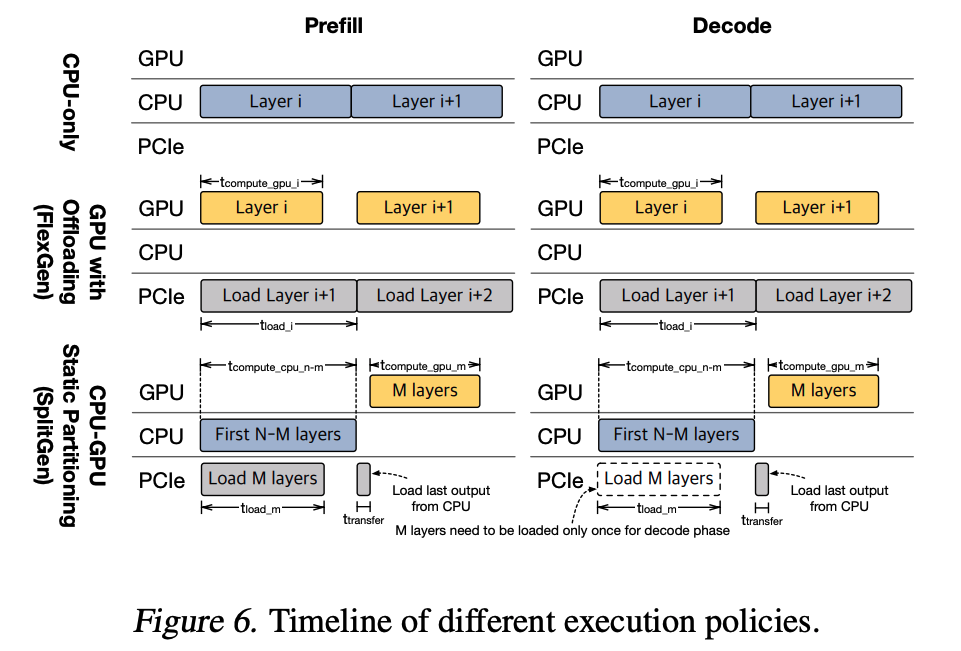
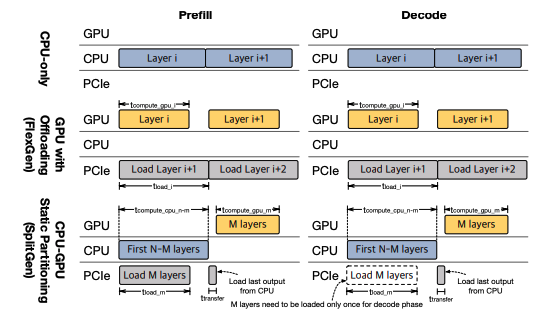
1. CPU-only
CPU-only 정책은 말 그대로 모든 연산이 CPU에서 수행 되는 방식이다.
이 때, 모델의 파라미터 값들과 Activation 값은 물론이고, KV cache까지 CPU memory에 저장 된다. 앞서 언급하였듯, CPU의 계산 처리 능력은 아무리 AMX 연산이 뛰어나다고 하더라고 GPU를 따라 갈 수는 없기 때문에 주로 모델 크기가 매우 크거나, 출력 시퀀스가 매우 긴 상태에서 decode 단계에서 효과적이다.
2. GPU + offloading
GPU와 offloading의 조합 전략은 CPU에 풍부한 메모리를 이용하여 KV cache를 내리고, 필요 할 때 GPU에 PCIe로 올려서 사용하는 방식이다.
FlexInfer에서는 이 방식을 사용하기 위해 FlexGen이라는 논문의 방식을 그대로 사용하였다고 한다. 그래서 CPU -> GPU 방향으로 데이터 전송 속도가 GPU 연산보다 느리기 때문에 데이터 로딩 병목이 발생하고, 계산량이 적은 decoding 단계에서 자주 손해를 볼 수 있다고 한다. 이를 완화하기 위해서 다음 레이어의 메모리 로딩과 현재 레이어의 계산을 최대한 overlap 시키는 방식을 사용한다고 한다.
3. SplitGen
SplitGen 방식은 모델을 CPU와 GPU 사이에 정적으로 나누어서 실행하는 방식이다.
전체 N개의 모델 레이어 중에, 처음 N-M개의 레이어를 CPU에 할당을 하고, 나머지 M개의 레이어를 GPU에 할당한다. 그러면 M 값을 결정하는 것이 문제인데, 이는 GPU의 메모리 크기를 기준으로 결정 되며, 가능한 많은 레이어를 GPU 메모리에 할당한다고 한다. 이 방식은 이전에 GPU + offloading 방식과 다르게 N-M개의 CPU 연산을 수행하는 동안 M개의 레이어의 KV cache를 GPU로 로드하고, activation이 발생하면 GPU에 있는 M개의 레이어를 연산하는 방식이다. 이 방식은 주로 입력 시퀀스가 짧은 prefill이나, CPU-GPU간 통신을 최소화 해야 하는 decoding 단계에서 효과적이다.
Execution Planner
Execution Planner는 모델 아키텍처, 실행 시 정보, 서버 하드웨어 구성을 분석하여 prefill 및 decode 단계 각각에 대해 최적의 실행 정책을 선택한다. 구체적으로는 다음과 같은 사항들을 고려하게 된다.
- LLM 모델
- 입/출력 길이
- 배치 사이즈
- CPU/GPU의 연산량 및 메모리 bandwidth
- CPU-GPU 사이의 interconnect bandwidth
그리고 위 정보들을 토대로 3가지 기본적인 실행 정책 중 하나를 실행하게 된다. 이를 위해 모델과 하드웨어 정보를 기반으로 TTFT와 TPOT을 사전에 계산하게 된다. 또한 TTFT/TPOT 계산을 위해서 FlexInfer는 offline profiler를 이용하고, 이후에 추가로 수행 되는 input 조건들을 추가하여 실제 성능까지 반영 할 수 있다고 한다.
Inference Executor
Inference Executor는 선택된 정책에 따라 추론을 수행한다. 따라서 다음과 같은 역할을 한다.
- CPU / GPU 사이의 데이터 전송이나 통신을 관리한다.
- CPU / GPU 사이의 동기화 작업을 처리하여 데이터 전송과 연산이 병렬로 수행 되게 한다.
재밌는 점은, 이 Executor에서 prefill과 decode가 서로 동일한 정책을 사용 할 수도 있고, 전혀 다른 정책을 사용 할 수 있다는 것이다.
위에 Overview의 시나리오 1은 Prefill은 GPU offload를 사용하고, Decode에서 SplitGen 정책을 사용한 것이다.
1. Prefill 단계에서 L0가 연산을 수행하는 동안 다음 레이어인 L1을 PCIe에서 GPU로 로드 한다.
2. Decode 단계에서 SplitGen 정책에 따라 처음 N-M개의 레이어를 CPU에서 실행한다.
3. CPU에서 생성 된 activation을 GPU로 옮긴다.
4. GPU에서 나머지 M개의 레이어를 처리하여 decoding 1 iteration을 완수한다.
실험 결과
실험에서 사용 된 모델은 OPT와 LLaMA2가 사용이 되었는데, 두 모델 다 H100 (80GB)에는 들어가기 어려울 정도의 사이즈이다. 저자는 실험을 위해서 AMX를 지원하지 않는 CPU-only (ICL_CPU)와 지원하는 (SPR_CPU) 것을 준비하였고, Server 1은 A100(40GB) 클러스터, Server 2는 H100 클러스터였다고 한다.
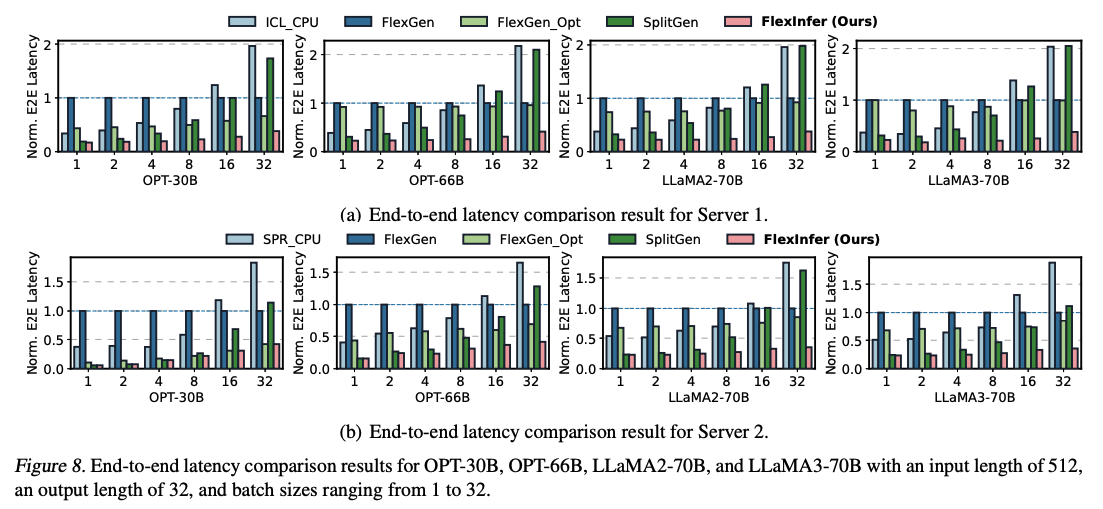
이 실험에서 거의 E2E latency가 SOTA 연구인 FlexGen에 비해 A100 클러스터에서 75%, 그리고 H100 클러스터에서 76%까지 감소했다고 한다. 이에 대해 저자는 2가지 근거를 제시했다.
-
FlexGen은 GPU 메모리 크기 안에서만 PCIe 전송 시간을 줄일 수 있다고 한다. 그래서 GPU 메모리가 상대적으로 빡빡한 A100에서 성능 개선이 미미하다고 한다.
-
SplitGen은 항상 CPU 계산을 포함한다. 그렇기 때문에 Prefill에서 손해를 보게 되고, 이것이 input 시퀀스가 길거나 배치의 크기가 클 수록 더 두드러진다고 한다.
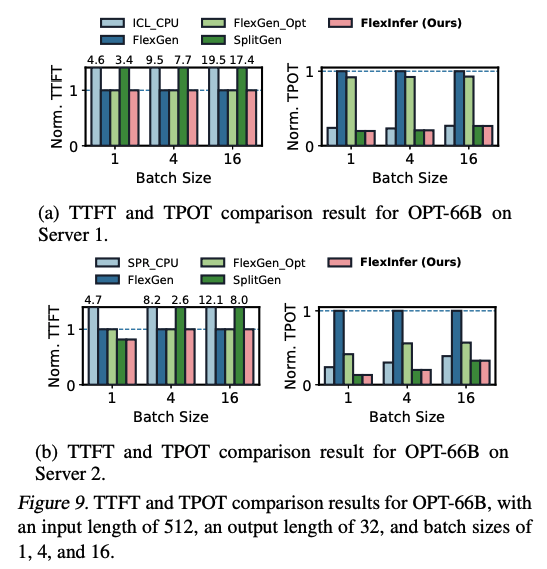
CPU-only, FlexGen, SplitGen이 TTFT나 TPOT에서 모두 동일하게 성능적인 이득을 보지 못하는 반면, FlexInfer는 TTFT와 TPOT 모두 성능적인 이득을 보고 있다. 이에 대해 저자는 한 가지 정책으로 prefill과 decoding을 모두 수행하려고 하기 때문에, 둘 중 하나의 메트릭에서만 이득을 보는 상황이라고 표현했다. 그에 비해 FlexInfer는 여러 방식을 하이브리드로 사용하기 때문에 TTFT와 TPOT이 모두 개선 되었다고 한다.
결론 및 고찰
Prefill과 Decoding을 나누어서 서로 다른 정책을 적용한다는 점이 굉장히 재밌었다.
나는 CPU inference라는 제목에 눈이 돌아가서 충동적으로 읽게 된 논문인데, 이 논문을 접하고 나서 disaggregated inference에 재미를 붙이게 된 것 같다. 이 논문의 related works에도 해당 분야에 대한 다른 논문들이 보였는데, 시간이 되면 읽어보고 싶다. 그리고 문득 예전에 Gaudi2를 사용했던 것이 기억에 났는데, AMX도 인텔 CPU에서 가능하니까, Gaudi2랑 시너지가 날지도 모르겠다는 생각이 들었다. (하지만 이미 내가 Gaudi2를 써본게 2년 전이라 더이상 써볼 수 있는 기회가 있을지는 모르겠다.)
